
字符编码
1 定义: 记录人类字符与数字对应关系的数据(类似战争中破译电报用的编码表)
# 特点:只跟文本和字符串有关,与图片文件,视频文件无关
# 背景:计算机只识别二进制,为了能让计算机识别人类语言字符而发明对应的字符编码
2 发展史
总结: 现在默认使用的编码是utf8
三阶段: 1 一家独大 ASCII码 美国编码表:里边记录了英文字符与数字的对应关系 A~Z:65~90 (必须记) a~z:97~122 (必须记) 2 群雄割据 中国 GBK码:记录了 中文英文与数字的对应关系 日本 shift_GIS码: 记录了日文英文与数字的对应关系 韩国 Eur_Kr码:记录了韩文英文与数字的对应关系 3 大一统 unicode(万国码) 统一使用两个及以上字符记录字符与数字的对应关系 万国码的优化版本,英文还是用一个字节存储,中文用三个字节起存储
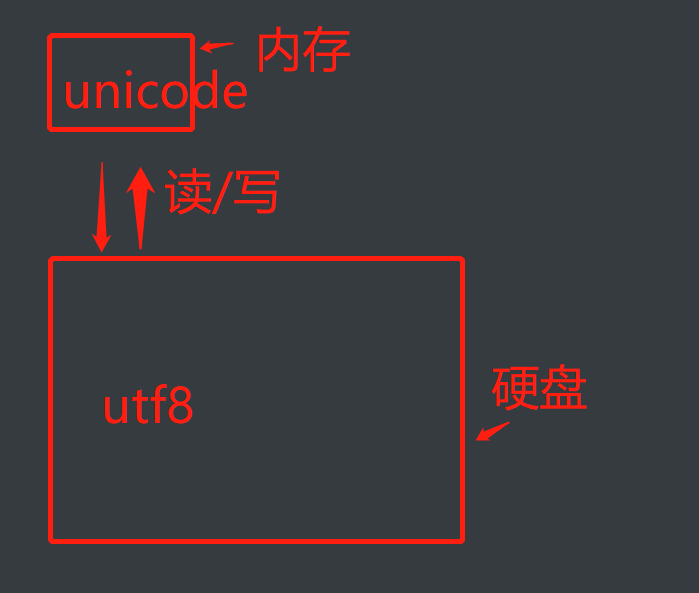
Unicode与utf8各自在哪起作用:
配合起作用:utf8 存在于硬盘中,只与内存中unicode交流的
3 编码与解码
编码:
将人类能读懂的语言字符按照编码表转换成二进制数的过程
s = '华为是谁' print(s.encode()) # b'\xe5\x8d\x8e\xe4\xb8\xba\xe6\x98\xaf\xe8\xb0\x81'
# 编码补充:
# 十六进制字符串转bytes
key_hex = '1bd1730a373e4cf28200691a3900af22'
key_bytes = bytes.fromhex(key_hex)
# base64编码的字符串转bytes
text_base64 = 'sbjDiXxsQlYswEf+UXSzwPil2clGDIYP976NEGxud1g='
text = base64.b64decode(text_base64)
解码:
将二进制数按编码表转换成人类能读懂的语言字符的过程
# s1 = b'\xe5\x8d\x8e\xe4\xb8\xba\xe6\x98\xaf\xe8\xb0\x81' # print(s1.decode()) # 华为是谁
快捷方式: 字符串中只含字母和数字时,前边加字母b 相当于 变量名.encode()
# 例 s = 'hello123' print(s.encode()) # 等价于 print(b'hello123')
其他案例:
二进制数据bytes转换为不同的编码方式(如: 将二进制转换为十六进制hex、Base64和UTF-8编码)
import base64 data = b'hello' data_hex = data.hex() data_base64 = base64.b64encode(data).decode('utf-8') data_utf8 = data.decode('utf-8') print(f'data_hex:{data_hex};len:{len(data_hex)};type:{type(data_hex)}') print(f'data_base64:{data_base64};len:{len(data_base64)};type:{type(data_base64)}') print(f'data_utf8:{data_utf8};len:{len(data_utf8)};type:{type(data_utf8)}') """ data_hex:68656c6c6f;len:10;type:<class 'str'> data_base64:aGVsbG8=;len:8;type:<class 'str'> data_utf8:hello;len:5;type:<class 'str'> """
4 要打印原始的汉字而不是转义字符
import json data = json.dumps({'key': '你好'}) print(f'data:{data}') # {"key": "\u4f60\u597d"} # 要打印原始的汉字而不是转义字符(要将形如 "\u4f60\u597d" 的编码后的字符串转换为汉字) # 方案1: 可以使用 ensure_ascii=False 参数来禁用 ASCII 转义 data1 = json.dumps({'key': '你好'}, ensure_ascii=False) print(f'data1:{data1}') # {"key": "你好"} # 方案2 使用 unicode_escape 编码对字符串进行解码 data2 = json.dumps({'key': '你好'}) data2 = data2.encode('utf-8').decode('unicode_escape') # 当我们调用 data.encode('utf-8') 时,我们将字符串 data 编码为 UTF-8 字节序列 # 调用 .decode('unicode_escape') 方法对 UTF-8 编码的字节序列进行解码 # unicode_escape 是一种 Python 中的编码方式,它可以将形如 "\uXXXX" 的 Unicode 转义字符序列解码为对应的字符 print(f'data2: {data2}')
5 其他
1) 字典转bytes
先转字符串, 然后字符串编码 : dict1_bytes = bytes(str(dict1), 'utf-8')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号