[Think In Java]基础拾遗3 - 容器、I/O、NIO、序列化
目录
第十一章 持有对象
第十七章 容器深入研究
第十八章 Java I/O系统
第十一章 持有对象
1. java容器概览
java容器的两种主要类型(它们之间的主要区别在于容器中每个“槽”保存的元素个数):Collection和Map。
(1)Collection是一个独立元素的序列,这些元素都服从一条或者多条规则。Collection概括了序列的概念——一种存放一组对象的方式。
- List:按照插入的顺序保存元素(ArrayList,LinkedList)
- Set:不能有重复元素(HashSet,TreeSet,LinkedHasSet)
- Queue:按照排队规则来确定对象产生的顺序(按排队时间长短即FIFO、按优先级高低)
(2)Map是一组成对的“键值对”对象,允许使用键来查找值。
- HashMap:无序
- TreeMap:按照比较结果的升序保存键
- LinkedHashMap:按照插入顺序保存键
2. 相关工具类java.util.Arrays类和java.util.Collections类。
(1)添加一组元素
Arrays.asList();
Collections.asList();
(2)容器的打印
Arrays.toString();
3. 迭代器
遍历容器而不关心容器的具体类型。迭代器也是一种设计模式。(和C++中的迭代器类似)
Collection接口有一个iterator()方法返回一个Iterator对象,也就是说每个继承自Collection的容器都可以迭代(Collection接口继承自Iterable接口)。Iterator有如下方法:
boolean hasNext() :如果仍有元素可以迭代,则返回 true。
E next() :返回迭代的下一个元素。
void remove() :从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作,不是所有的容器都实现了该方法)。
4. ListIterator
ListIterator继承自Iterator。Iterator只能向前移动,但是ListIterator可以双向移动,ListIterator只能用于各种List。
5. Set
将两个相同的对象放入Set中是不行的。Set是基于对象的值来确定归属性的。
HashSet:基于hash函数;TreeSet:基于红黑树;LinkedHashSet:hash函数+链表。
TreeSet 使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。
String类有一个比较器String.CASE_INSENSITIVE_ORDER;
6. PriorityQueue
一个基于优先级堆的无界优先级队列。优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法。
7. 简单的容器分类

第十七章 容器深入研究
1. 完整的容器分类法
下图展示了Java容器类库的完备图,包括抽象类和遗留构件(不包括Queue的实现)。
常用的容器用黑色粗线框表示,点线框表示接口,虚线框表示抽象类,实线框表示类,空心箭头表示实现关系。Produce表示任意的Map对象可以生成Collection对象,任意的Collection对象可以生成Iterator对象。

2. 容器总结
下面以表格的形式总结List、Set、Map接口及各实现类的特性:
|
特性 |
实现类 |
实现类特性 |
对放置的元素的要求 |
|
|
List |
线性、有序的存储容器,可通过索引访问元素get(n) |
ArrayList |
数组实现。非同步。 |
|
|
Vector |
类似ArrayList,同步。 |
|
||
|
LinkedList |
双向链表。非同步。 |
|
||
|
Set |
元素不能重复,元素必须定义equals()方法
|
HashSet |
为快速查找设计的Set |
元素必须定义hashCode() |
|
TreeSet |
保持次序的Set,底层为树结构 |
元素必须实现Comparable接口 |
||
|
LinkedHashSet |
内部使用链表维护元素的顺序(插入的次序) |
元素必须定义hashCode() |
||
|
Map |
保存键值对成员,Map中的所有键必须定义equals()方法 |
HashMap |
基于哈希表的 Map 接口的实现,满足通用需求 |
键必须有恰当的hashCode(),如果修改了equals方法,需同时修改hashCode方法 |
|
TreeMap |
默认根据自然顺序进行排序,或者根据创建映射时提供的 Comparator进行排序 |
键成员要求实现caparable接口,或者使用Comparator构造TreeMap。键成员一般为同一类型。 |
||
|
LinkedHashMap |
类似于HashMap,但迭代遍历时取得“键值对”的顺序是其插入顺序或者最近最少使用的次序 |
与HashMap相同 |
||
|
IdentityHashMap |
使用==取代equals()对“键值”进行比较的散列映射 |
成员通过==判断是否相等 |
||
|
WeakHashMap |
弱键映射,允许释放映射所指向的对象 |
|
||
|
ConcurrentHashMap |
线程安全的Map |
|
说明:
(1)各种Queue和Stack的行为,完全可以LinkedList提供支持,上述表格不包含Queue。
(2)但凡是和hash相关的,必然会设计到hashCode方法,因为要根据返回的哈希码去计算该对象在哈希表中的位置;但凡是和Tree相关的,必然会设计到Comparable接口,因为要涉及到排序。
(3)如果要进行大量的随机访问,就是用ArrayList;如果要经常从表中间插入或删除元素,则应该用LinkedList。遍历的时候,对于ArrayList优先选择get方式,LinkedList优先选择iterator方式。
(4)Collection继承了Iterable接口,故所有的Collection对象都可以使用foreach方式,对元素进行遍历。所有的Collection对象都hiuforeach循环可以与任何实现了Iterable接口的对象一起工作。
(5)自定义类作为HashMap/HashSet/LinkedHashMap/LinkedHashSet的键时,必须同时重写equals()和hashcode()方法。
3. hashcode()方法的编写步骤

4. HashMap的性能因子
几个术语:
(1)容量:表中的桶位数
(2)初始容量:表在创建时所拥有的桶位数。可以在HashMap和HashSet的构造器中指定初始容量。
(3)尺寸:表中当前存储的项数。
(4)负载因子:尺寸/容量。
HashMap和HashSet都有能指定负载因子的构造器,表示当负载情况达到该负载因子的水平时,容器将自动增加其容量(桶位数),实现方式是使容量大致加倍,并重新将现有对象分布到新的桶位集中(再散列)。
HashMap使用的默认负载因子是0.75。
5. 快速报错(fail-fast)
Java容器有一种保护机制,能够防止多个进程同时修改同一个容器的内容。Java容器类类库采用快速报错(fail-fast)机制,它会探查容器上的任何除了你的进程所进行的操作以外的所有变化,一旦它发现其他进程修改了容器,就会立刻抛出ConcurrentModificationException异常。这就是“快速报错”的意思——即,不是使用复杂的算法在事后来检查问题。
ConcurrentHashMap、CopyOnWriteArrayList和CopyOnWriteArraySet都使用了可以避免ConcurrentModificationException的技术。
6. 持有引用
如果想继续持有某个对象的引用,希望以后还能够访问到该对象,但是也希望能够允许GC释放它,这时候就应该使用Reference对象。这样,你就可以继续使用该对象,而在内存消耗殆尽的时候又允许释放该对象。
以Reference对象作为你和普通引用之间的媒介(代理),另外,一定不能有普通引用指向那个对象,这样就能达到上述目的。(普通引用指的是没有经过Reference对象包装过的引用。)如果GC发现某个对象通过普通引用是可获得的,该对象就不会被释放。
[这有点类似于C++中的shared_ptr的角色,并且创建Reference对象的时候也有点类似于RAAI。]
A a = new A(); //a引用(普通引用)的对象不能被回收
Reference b = new Reference(new A()); //b应用的对象可以被回收,因为这个对象(往往是一大对象)一出生就被包裹了,没其他普通引用指向它,可以被回收
SoftReference、WeakReference、PhantomReference有强到弱排列,对应不同级别的“可获得性”。
第十八章 Java I/O系统
1. InputStream
此抽象类是表示字节输入流的所有类的超类。
[结合linux下C语言中的文件流指针struct FILE来理解就好了。在Linux下一切IO设备都是文件,所以这样的一个结构体表示了系统中各种各样的数据源,但在Java中具体的各种数据源由InputStream的子类来表示,比如AudioInputStream, ByteArrayInputStream, FileInputStream, PipedInputStream,SequenceInputStream, StringBufferInputStream等。]
具体如下表:
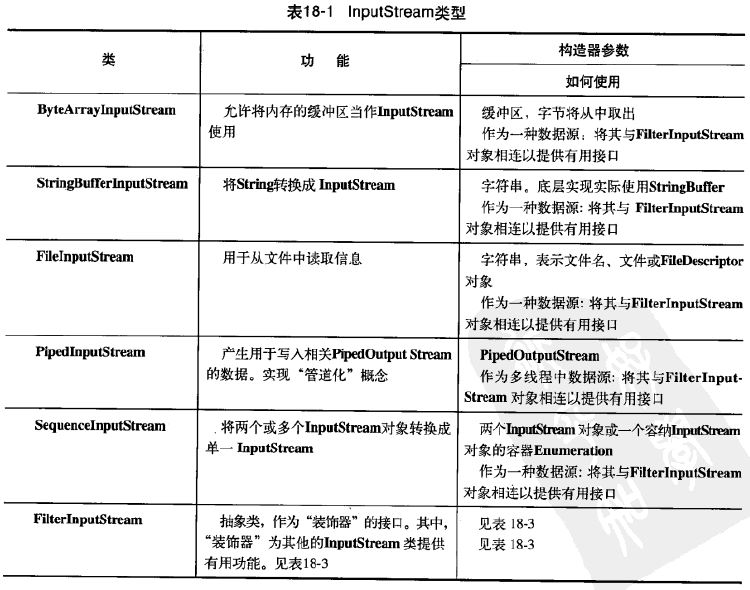
2. OutputStream
与InputStream类似的理解。如下表

3. Java中的IO类与装饰器模式
Java IO类库的设计使用了装饰器模式。
先看看装饰器模式的UML图:(具体可参考维基百科)

java IO对应的UML图

FilterInputStream和FilterOutputStream起到的是抽象装饰者的角色,它们的子类是具体的装饰者。
如下表:


4. Reader和Writer
与面向字节IO的InputStream和OutputStream不同,Reader和Writer提供兼容Unicode与面向字符IO的功能。
设计Reader和Writer继承层次结构主要是为了国际化。因为InputStream和OutputStream仅支持8位字节流,并不能很好地处理16位的Unicode字符。
5. IO中的适配器类
(1)InputStreamReader:字节——>字符(2个字节)
InputStreamReader 是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。它使用的字符集可以由名称指定或显式给定,或者可以接受平台默认的字符集。
每次调用 InputStreamReader 中的一个 read() 方法都会导致从底层输入流读取一个或多个字节。
为了达到最高效率,可要考虑在 BufferedReader 内包装 InputStreamReader。例如: BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
(2)OutputStreamWriter:字符(2个字节)——>字节
OutputStreamWriter 是字符流通向字节流的桥梁:可使用指定的 charset 将要写入流中的字符编码成字节。它使用的字符集可以由名称指定或显式给定,否则将接受平台默认的字符集。
【记忆误区纠正】:之前一直将OutputStreamWriter记成了是将字节编码成字符。可以这样来纠正记忆:
(1)从OutputStreamWriter的构造函数来看:
OutputStreamWriter需要一个OutputStream对象,所以从形式上看就感觉是将字节流转换成了字符流,实则不然。构造函数需要OutputStream只是因为OutputStreamWriter需要借助OutputStream来完成具体的输出操作。
(2)从函数调用关系上来看:OutputStreamWriter.writer(字符char) ——> OutputStream.write(字节byte)
调用OutputStreamWriter之后我们得到的是一个Writer,而Writer的write()方法的参数都是字符。可以想象我们调用OutputStreamWriter的write()函数写入的字符,最后还得转化成字节流由内部的OutputStream对象来具体负责写出。所以这个OutputStreamWriter 类实际上是将字符编码成字节。
6. Java中标准IO重定向
System类的如下静态方法:setErr()、setOut()和setIn()可重定向IO,这些函数的参数的都是字符流。
7. 进程控制
Java中涉及到进程控制的有两个类:Process 和 ProcessBuilder。后者用来创建操作系统进程,返回一个前者的实例。
8. Java NIO
思想类似于Linux下的IO复用的,具体参考《NIO 入门》
9. 对象序列化
(1)概念:java的对象序列化就是将那些实现了Serializable接口的对象转换成一个字节序列,并能够在以后将这个字节序列完全恢复为原来的对象。
(2)为什么需要对象序列化?
对象序列化的概念加入到语言中是为了支持两种主要特性。一是Java的RMI,当向远程对象发送消息时,需要通过对象序列化来传递参数和返回值。二是对JavaBean来说,对象序列化也是必须的。需要在设计阶段保存它的状态信息,程序启动后进行后期恢复。
(3)具体步骤:让待序列化类实现一个标记接口Serializable,那么这个类的对象就是可序列化的了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号