2021——Python记录一
一、关于数据类型、变量及运算符
自己以前的记录也蛮详尽,用来复习。
https://www.cnblogs.com/tsembrace/p/8722281.html
二、字符串和编码
*字符编码
ASCII为最初的计算机编码,只有一个字节。无法包纳全世界各种语言各种符号,比如对应中文就无法使用ASCII码,因为就一个字节的容量,只能由最多255个字符,对汉字来说显然是不够的。中国就制定了GB2312编码集;类似的,日本、韩国也各自制定了本国文字的编码集。编码集的繁杂带来通用问题,因此Unicode标准字符集应运而生,它采用两个字节,可以容纳65535个字符。
但我们又发现新的问题,比如字母A,其ASCII码为01000001,其Unicode码为00000000 01000001
对于这种单字节即可表示的字符,Unicode的编码规则是在高位字节补全0,但这样又会浪费存储空间和传输资源。
于是,“可变长编码”UTF-8出现了:UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
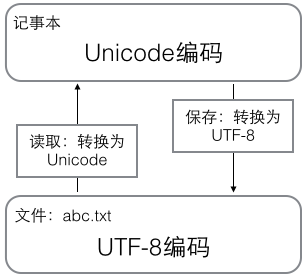
总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
*Python的字符串
Python 3版本中,字符串是以Unicode编码的,即:Python的字符串支持多语言。
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符
>>> ord('A')
65 ----即字符A的Unicode码为:00000000 01000001/0x0065
>>> ord('中')
20013----即汉字中的Unicode码为:01001110 00101101/0x0065
>>> chr(66)
'B'
>>> chr(25991)
'文'
len()函数用来计算字符串中包含的字符数:
print (len('I am chinese!')) #输出 13

 浙公网安备 33010602011771号
浙公网安备 33010602011771号