

黑马点评4:商户查询缓存
1. 什么是缓存
缓存就是数据交换的缓冲区(称作Cache),是存储数据的临时地方,一般读写性能较高。
浏览器缓存 ——> tomcat应用层缓存 ——> 数据库缓存 ——>CPU缓存
——>磁盘缓存
缓存的作用:
- 降低后端负载
- 提高读写效率,降低响应时间
缓存的成本:
- 数据一致性成本
- 代码维护成本
- 运维成本
GEOSEARCH要Redis6.2+。。。
2. 添加商户缓存
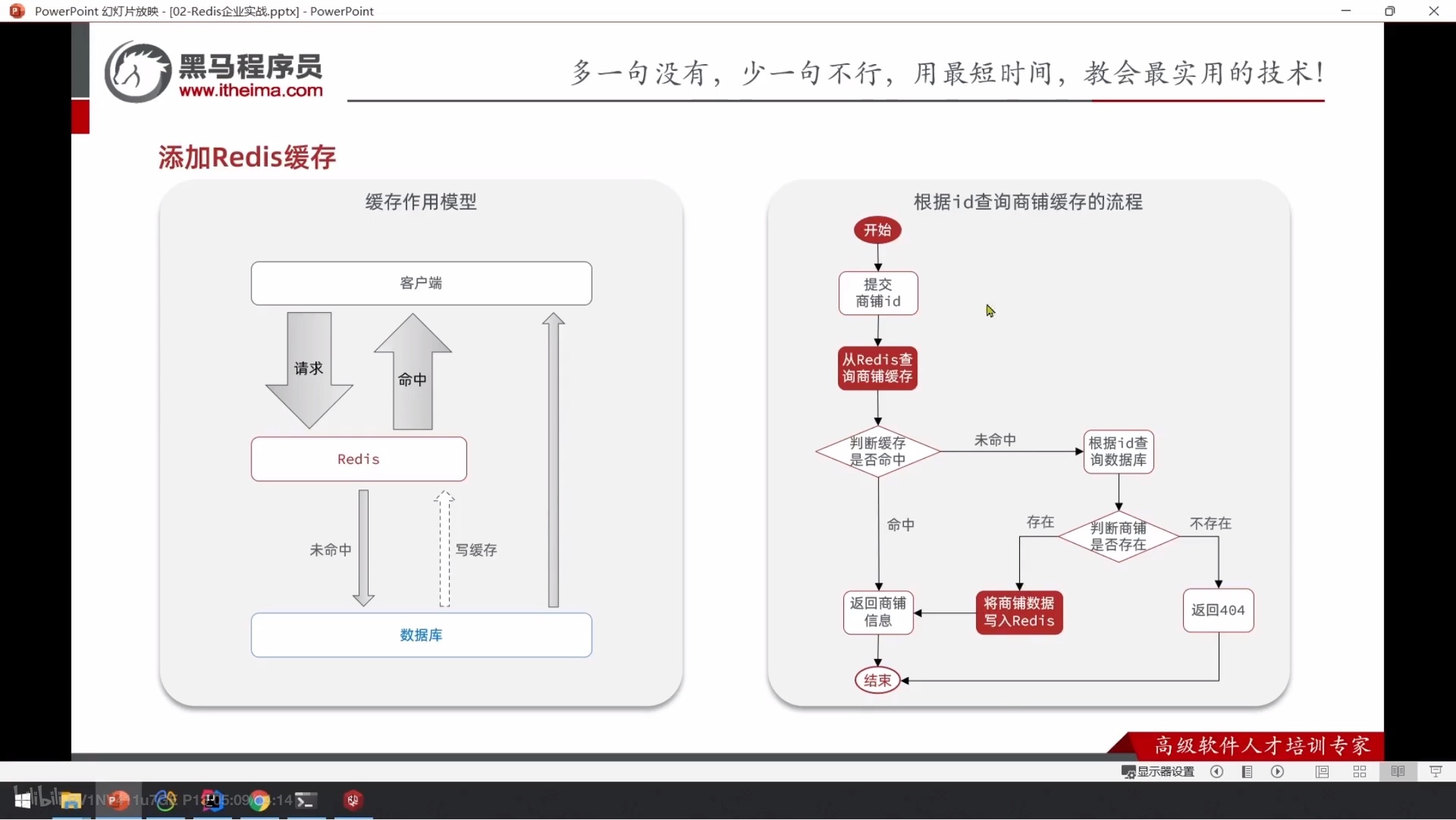
src/main/java/com/hmdp/controller/ShopController.java
src/main/java/com/hmdp/service/IShopService.java
src/main/java/com/hmdp/service/impl/ShopServiceImpl.java
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY+ id;
// 1. 从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2. 判断是否存在
if(StrUtil.isNotBlank(shopJson)){
// 3. 存在,直接返回
JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shopJson);
}
// 4. 不存在,根据ID查询数据库
Shop shop = getById(id);
// 5. 不存在,返回错误
if(shop != null){
return Result.fail("店铺不存在!");
}
// 6. 存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
// 7. 返回
return Result.ok(shop);
}
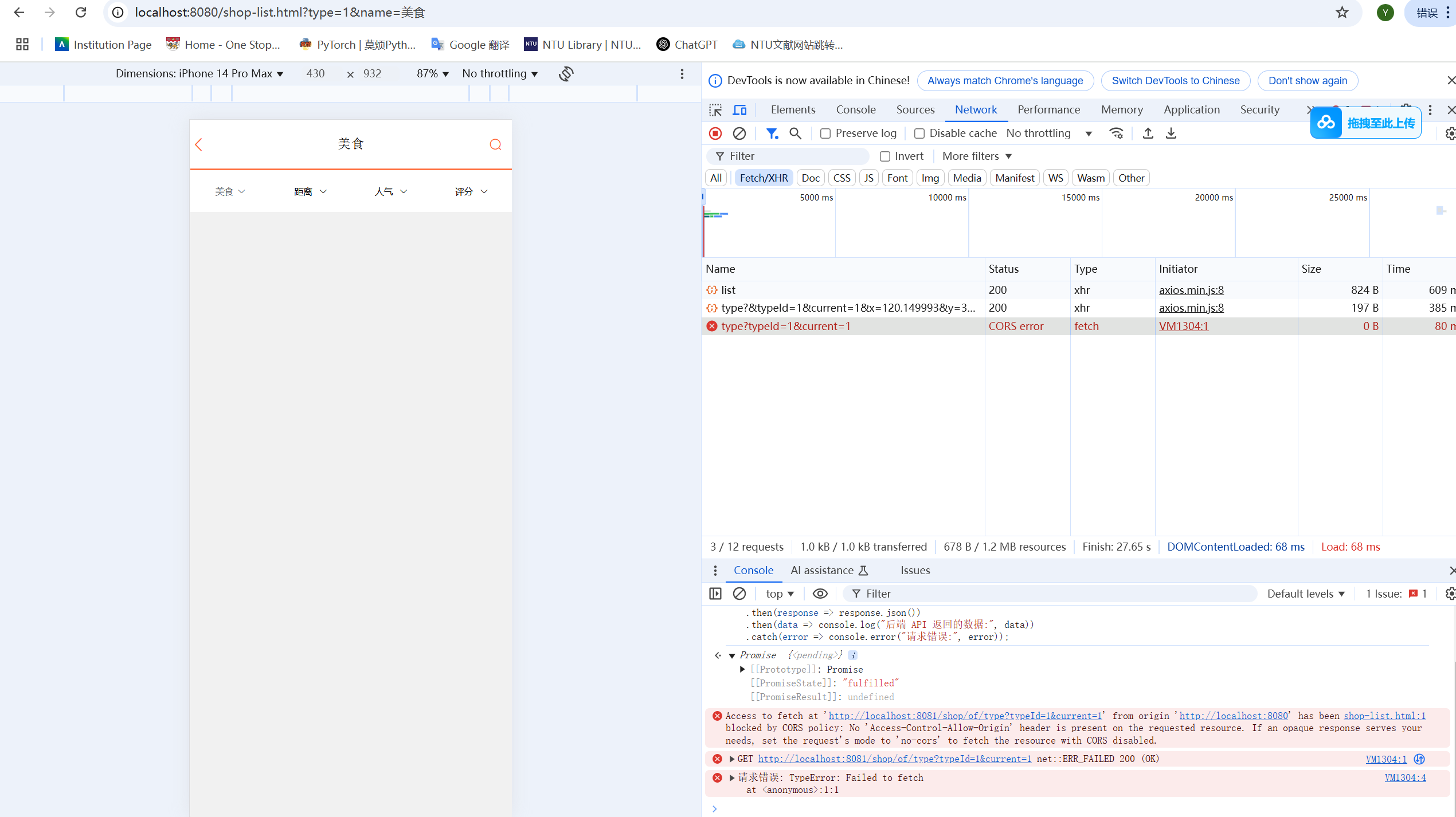
前端有点问题,卡在这里了。。。
前端点击“美食”后的页面还是存在跨域问题(CORS Policy Blocked),实在不会前端,检查了是有JSON数据的,后端应该没问题,其它页面好像也没问题,先搁置在这里。。。
3. 缓存更新策略

主动更新策略:
- Cache Aside Pattern旁路缓存模式:由缓存的调用者,在更新数据库的同时更新缓存(企业中用得最多的)
- Read/Write Through Pattern读写穿透:缓存与数据库整合为一个服务,由服务来维护一致性。调用者调用该服务,无需关心缓存一致性问题。
- Write Behind Caching Pattern异步缓存写入:调用者只操作缓存,由其它线程异步地将缓存数据持久化到数据库,保证最终一致。

先删除缓存,再操作数据库的正常情况:
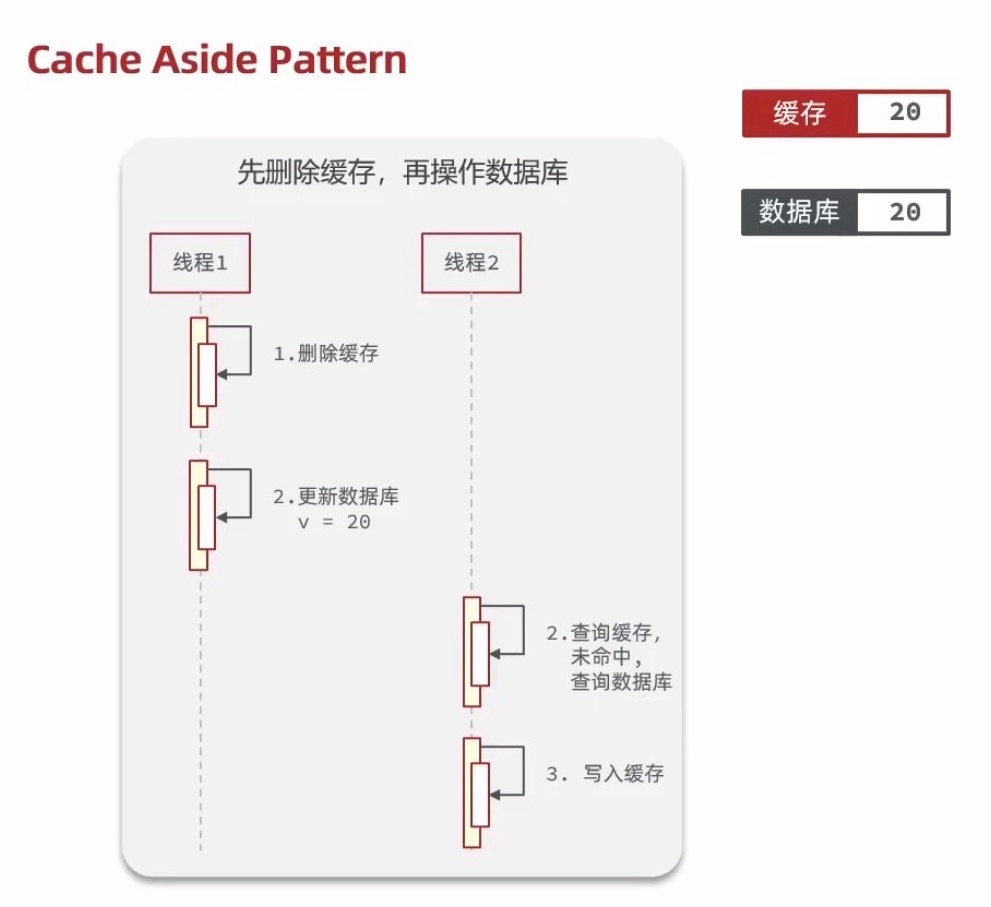
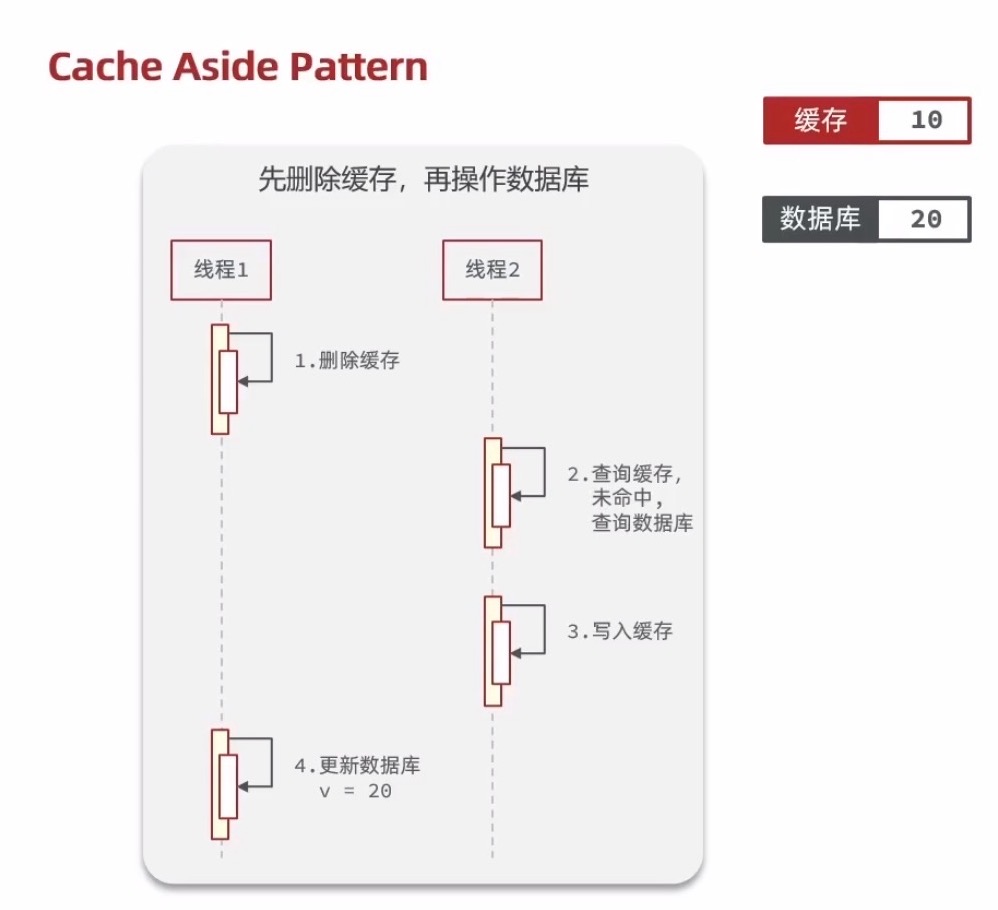
先删除缓存,再操作数据库的异常情况:更新数据库过程中,第二次缓存
先操作数据库,再删除缓存的正常情况:
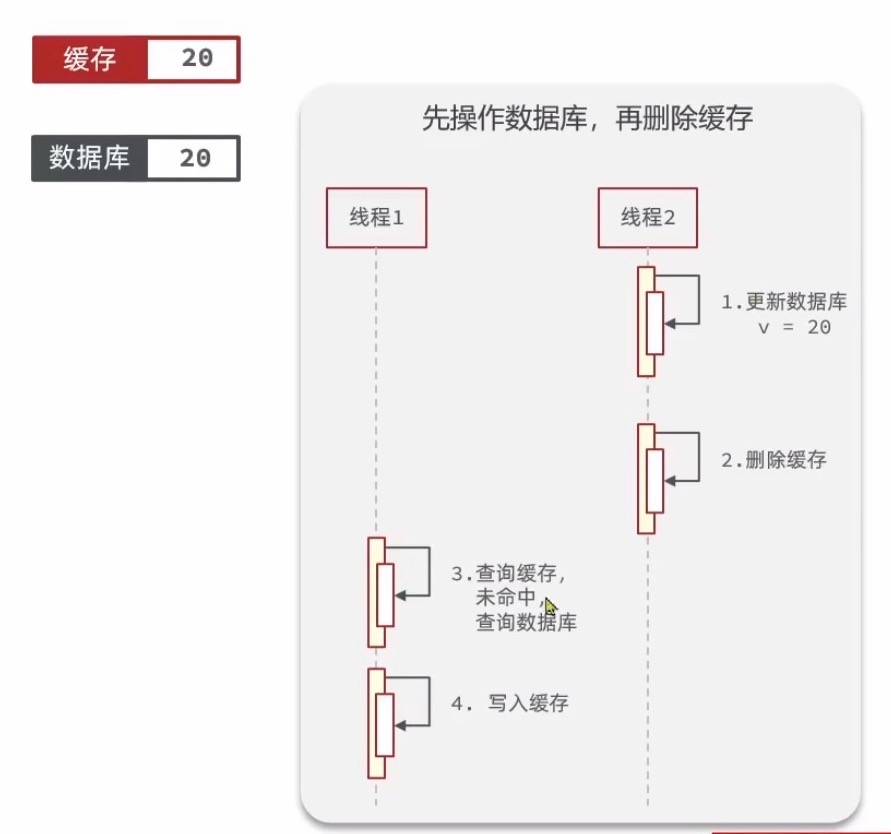
先操作数据库,再删除缓存的异常情况:线程1查询的时候恰好缓存失效,同时查完写缓存的微秒级别内突然来了更新数据库的线程2(这种可能性太小了,胜出)

总结:

4. 实现商铺缓存与数据库的双写一致
案例:给查询商铺的缓存添加超时剔除和主动更新的策略
修改ShopController中的业务逻辑,满足下面的需求:
- 根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
- 根据id修改店铺时,先修改数据库,再删除缓存
查询的业务修改:
src/main/java/com/hmdp/service/impl/ShopServiceImpl.java
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY+ id;
// 1. 从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2. 判断是否存在
if(StrUtil.isNotBlank(shopJson)){
// 3. 存在,直接返回
JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shopJson);
}
// 4. 不存在,根据ID查询数据库
Shop shop = getById(id);
// 5. 不存在,返回错误
if(shop != null){
return Result.fail("店铺不存在!");
}
// 6. 存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_KEY,TimeUnit.MINUTES);//这里增加了时间限制
// 7. 返回
return Result.ok(shop);
}
更新的业务修改:
src/main/java/com/hmdp/controller/ShopController.java
/**
* 更新商铺信息
* @param shop 商铺数据
* @return 无
*/
@PutMapping
public Result updateShop(@RequestBody Shop shop) {
// 写入数据库
return shopService.update(shop);
}
src/main/java/com/hmdp/service/impl/ShopServiceImpl.java
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为空");
}
// 1.更新数据库
updateById(shop);
// 2.删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}
5. 缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
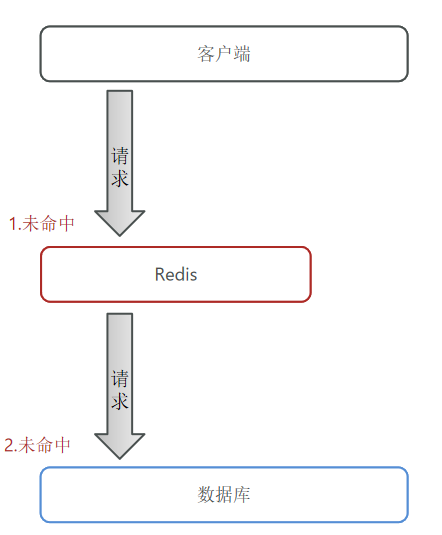
常见的两种解决方案:
- 缓存空对象
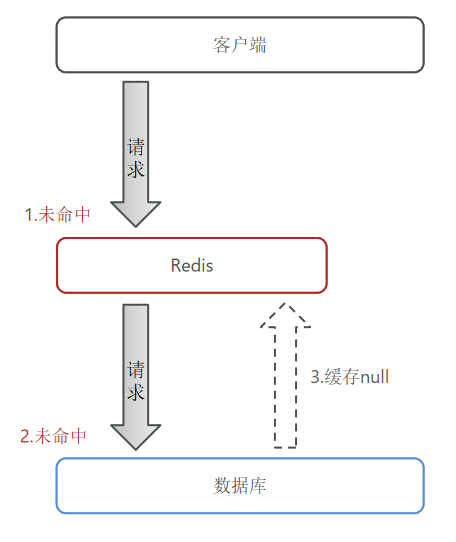
- 优点:实现简单,维护方便
- 缺点:额外的内存消耗(设置TTL);
可能造成短期的不一致(控制TTL的时间可以缓解)。
- 布隆过滤:前置加一层过滤
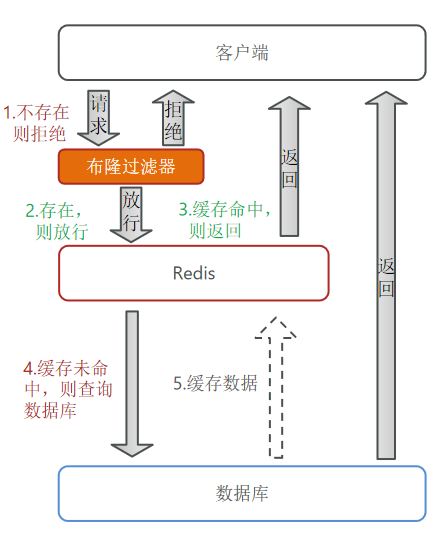
- 优点:内存占用较少,没有多余key
- 缺点:实现复杂;
存在误判可能。
6. 解决商铺查询的缓存穿透问题

src/main/java/com/hmdp/service/impl/ShopServiceImpl.java
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY+ id;
// 1. 从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2. 判断是否存在
if(StrUtil.isNotBlank(shopJson)){
// 3. 存在,直接返回
JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shopJson);
}
// 判断命中的是否是空值
if(shopJson != null){
// 返回一个错误信息
return Result.fail("店铺信息不存在!");
}
// 4. 不存在,根据ID查询数据库
Shop shop = getById(id);
// 5. 不存在,返回错误
if(shop != null){
// 将空值写入Redis
stringRedisTemplate.opsForValue().set(key, "",CACHE_NULL_KEY,TimeUnit.MINUTES);// CACHE_NULL_KEY为2min
// 返回错误信息
return Result.fail("店铺不存在!");
}
// 6. 存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_KEY,TimeUnit.MINUTES);//这里增加了时间限制CACHE_SHOP_KEY为30min
// 7. 返回
return Result.ok(shop);
}
总结:
缓存穿透产生的原因是什么?
用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力
缓存穿透的解决方案有哪些?
- 缓存null值
- 布隆过滤
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
7. 缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,,导致大量请求到达数据库,带来巨大压力

解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
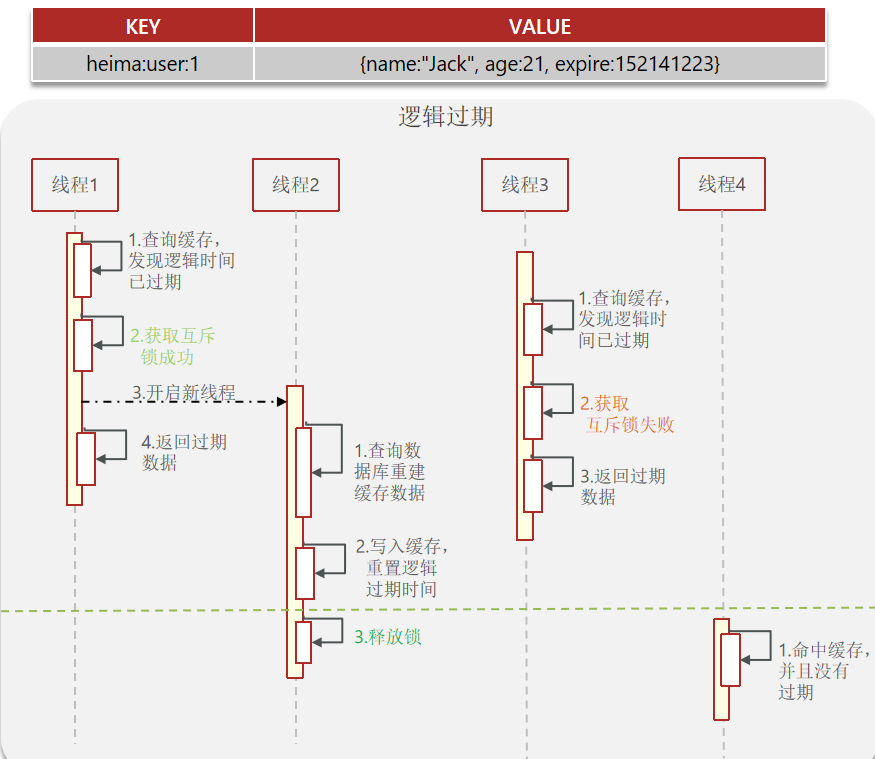
8. 缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击
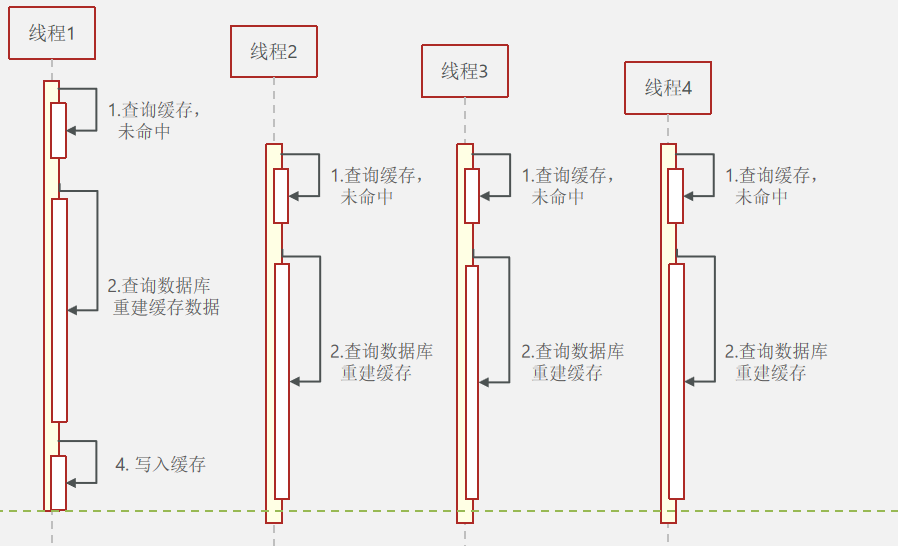
常见的两种解决方案:
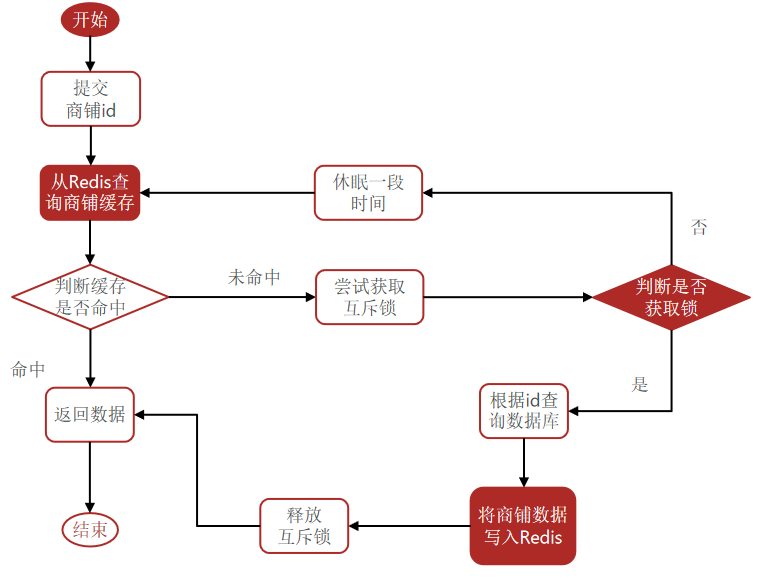
- 互斥锁
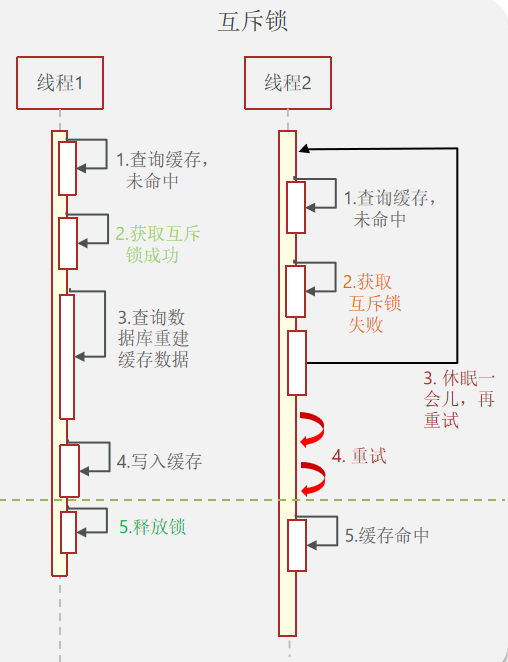
- 逻辑过期
| 优点 | 缺点 | |
|---|---|---|
| 互斥锁 | 1. 没有额外的内存消耗 2. 保证一致性 3. 实现简单 |
1. 线程需要等待,性能受影响 2. 可能有死锁风险 |
| 逻辑过期 | 1. 线程无需等待,性能较好 | 1. 不保证一致性 2. 有额外内存消耗 3. 实现复杂 |
9. 基于互斥锁方式解决缓存击穿问题
案例:修改根据id查询商铺的业务,基于互斥锁方式来解决缓存击穿问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗