Map接口
Map接口
HashMap 和 Hashtable 的区别
- 线程安全:hashmap非线性安全,hashtable线性安全(内部基本用synchronized修饰)。
- 效率:hashmap比hashtable效率好一点,hashtable弃用
- 键值对null支持:HashMap可存储 null 的 key, value,但 null 作为键只能有一个,null 作为值可以有多个;HashTable 不允许有 null 键和 null 值,否则会抛出 NullPointerException
- 初始容量大小和每次扩充容量大小的不同 :①
Hashtable默认初始大小为 11,之后每次扩充,变为原来的 2n+1。HashMap默认初始大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小值为2 的幂次方(HashMap中的tableSizeFor()方法保证)。也就是说HashMap总是使用 2 的幂作为哈希表的大小
HashMap 和 HashSet 区别
HashSet 底层就是基于 HashMap 实现的。自己的源码很少。
实现接口不同,一个实现Map,一个实现Set接口。一个存储键值对,一个存储对象。HashMap使用键(Key)计算hashcode,HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以equals()方法用来判断对象的相等性。
HashMap 和 TreeMap 区别
都继承自AbstractMap,TreeMap它还实现了NavigableMap接口(有了对集合内元素的搜索的能力)和SortedMap 接口(对集合中的元素根据键排序的能力)。
public class Person {
private Integer age;
public Person(Integer age) {
this.age = age;
}
public Integer getAge() {
return age;
}
public static void main(String[] args) {
TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person person1, Person person2) {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
}
});
treeMap.put(new Person(3), "person1");
treeMap.put(new Person(18), "person2");
treeMap.put(new Person(35), "person3");
treeMap.put(new Person(16), "person4");
treeMap.entrySet().stream().forEach(personStringEntry -> {
System.out.println(personStringEntry.getValue());
});
}
}
//person1
//person4
//person2
//person3
HashSet 如何检查重复
当添加对象时,HashSet先根据对象的hascode与其他对象的hashcode比较,没有相同的就没有视为该对象没有重复出现。如果相同的对象,这时就会调用equals()方法比较是否真的相同,相同就不会添加成功。
HashSet的add()方法只是简单的调用了HashMap的put()方法。
hashCode()与 equals() 的相关规定:
- 如果两个对象相等,则
hashcode一定也是相同的 - 两个对象相等,对两个
equals()方法返回 true - 两个对象有相同的
hashcode值,它们也不一定是相等的 - 综上,
equals()方法被覆盖过,则hashCode()方法也必须被覆盖 hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
HashMap 的底层实现
扰动函数hash方法,为了防止一些实现比较差的hashCode()方法,也就是减少碰撞。
JDK1.8解决冲突有了一些变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
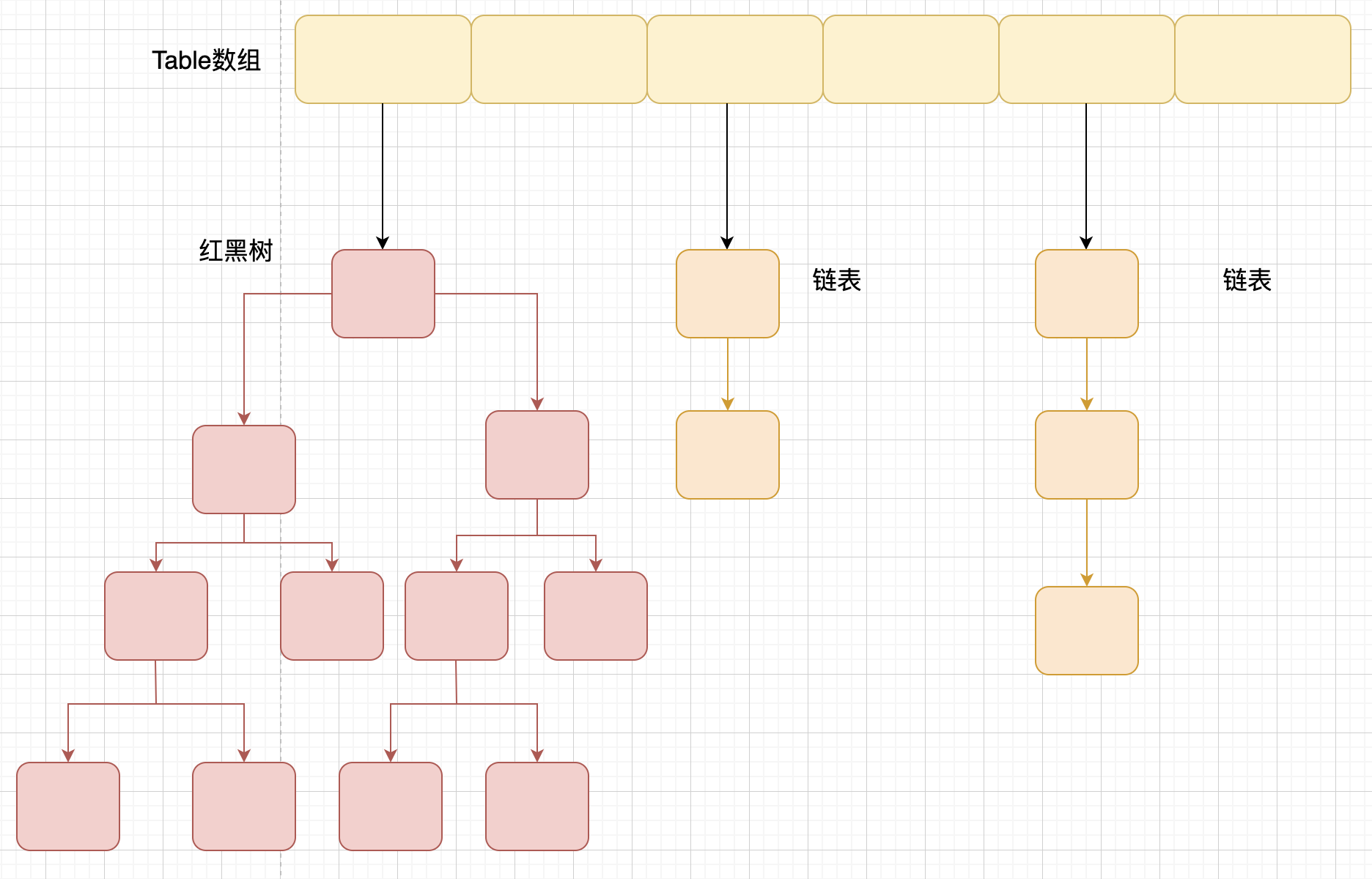
HashMap 的长度为什么是 2 的幂次方
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
ConcurrentHashMap 和 Hashtable 的区别
- 底层数据结构: JDK1.8 的
ConcurrentHashMap底层采用 数组+链表/红黑二叉树 实现。Hashtable底层数据结构采用 数组+链表 的形式。数组是主体,链表则是主要为了解决哈希冲突而存在的。 - 实现线程安全的方式(重要): ① 在 JDK1.7 的时候,
ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后 对synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本;②Hashtable(同一把锁) :使用synchronized保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
JDK1.8 的 ConcurrentHashMap 不在是 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。当冲突链表达到一定长度时,链表会转换成红黑树。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号