
概念:有监督、无监督、半监督、弱监督、自监督学习
来源:
机器学习算法盘点 - ranjiewen - 博客园
http://www.cnblogs.com/ranjiewen/p/6235388.html
弱监督和半监督区别
https://aistudio.baidu.com/aistudio/projectdetail/5489657
机器学习的算法很多。很多算法是一类算法,而有些算法又是从其他算法中延伸出来的。这里从两个方面来给大家介绍,第一个方面是学习的方式,第二个方面是算法的类似性。
一、学习方式
根据数据类型的不同,对一个问题的建模有不同的方式。在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。在机器学习领域,有几种主要的学习方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。
1、监督式学习
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)。
2、非监督式学习
3、半监督式学习
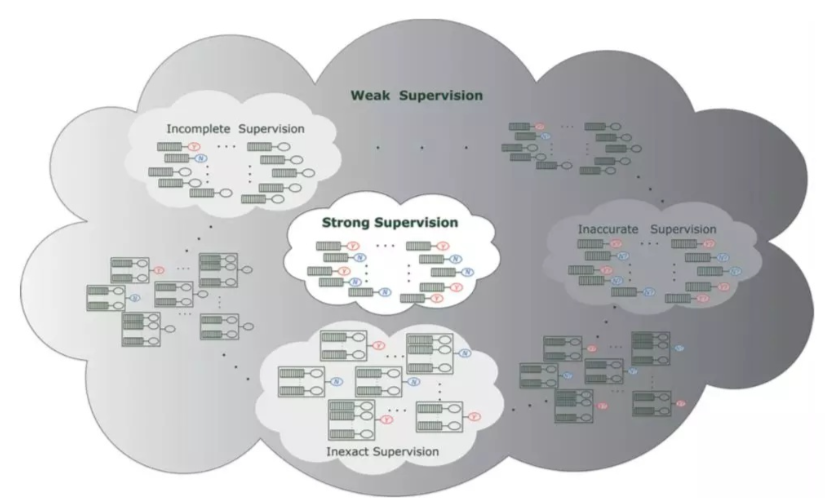
5、弱监督式学习
弱监督是半监督的一个分支,相对于半监督学习,弱监督学习把数据集里的噪声问题进行了解决。
1、不完全监督(incomplete supervision),即,只有训练集的一个(通常很小的)子集是有标签的,其他数据则没有标签。这种情况发生在各类任务中。例如,在图像分类任务中,真实标签由人类标注者给出的。从互联网上获取巨量图片很容易,然而考虑到标记的人工成本,只有一个小子集的图像能够被标注或者是A卡的用户有很多会先被风控引擎等切掉一部分,导致这部分样本无法拥有好坏用户的标签。
2、不确切监督(inexact supervision),即只有粗粒度的标签,例如,某些图像问题只有人工打标的粗粒度的标签,这在tabular数据中也较为常见,例如社交网络用户,给这个用户打标签,用户可能是多标签的,但是在标注的过程中仅标注了一个大范围的标签,一个典型直观的例子就是给 猫打标为“猫”而没有细致到打标猫的品种,粗粒度的标签对于细粒度的任务来说帮助很有限。
3、不准确的监督(inaccurate supervision),模型给出的标签不总是真实的。出现这种情况的常见原因有,图片标注者的失误,或者某些图片就是难以分类,评分卡的定义都是比较明确的,而在反欺诈、异常检测的应用中,样本的标注往往是模糊的。
弱监督学习是一个总括性的术语,涵盖了尝试通过较弱的监督来学习并构建预测模型的各种研究。关于弱监督学习和传统的有监督学习以及上述的三种弱监督的联系可见下图:
4、强化学习
二、算法类似性
根据算法的功能和形式的类似性,我们可以把算法分类,比如说基于树的算法,基于神经网络的算法等等。当然,机器学习的范围非常庞大,有些算法很难明确归类到某一类。而对于有些分类来说,同一分类的算法可以针对不同类型的问题。这里,我们尽量把常用的算法按照最容易理解的方式进行分类。
1、回归算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号