docker - image/layer 文件管理
Dockerfile由多条指令构成,随着深入研究Dockerfile与镜像的关系,很快大家就会发现,Dockerfile中的每一条指令都会对应于Docker镜像中的一层。
继续以如下Dockerfile为例:
FROM ubuntu:14.04 ADD run.sh / VOLUME /data CMD ["./run.sh"]
通过docker build以上Dockerfile的时候,会在Ubuntu:14.04镜像基础上,添加三层独立的镜像,依次对应于三条不同的命令。镜像示意图如下:
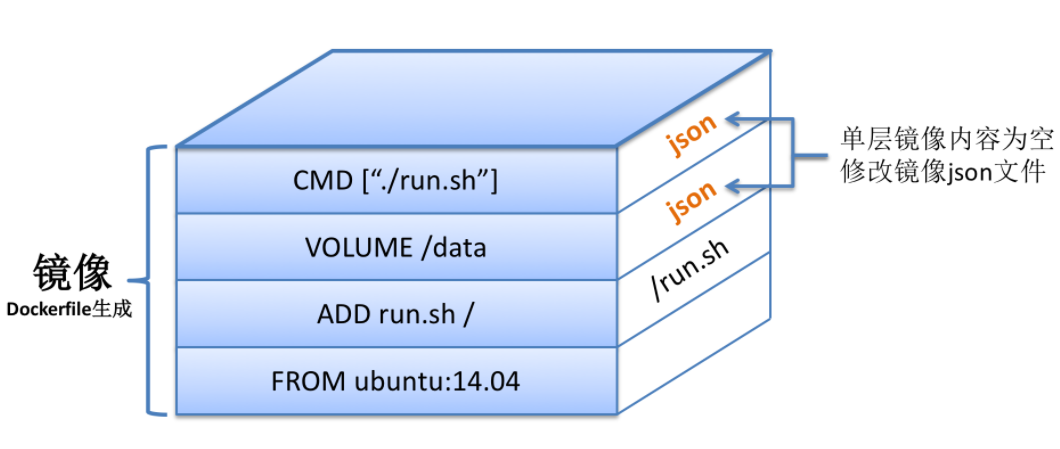
Dockerfile中命令与镜像层一一对应,那么是否意味着docker build完毕之后,镜像的总大小=每一层镜像的大小总和呢?答案是肯定的。依然以上图为例:如果ubuntu:14.04镜像的大小为200MB,而run.sh的大小为5MB,那么以上三层镜像从上到下,每层大小依次为0、0以及5MB,那么最终构建出的镜像大小的确为0+0+5+200=205MB。
虽然最终镜像的大小是每层镜像的累加,但是需要额外注意的是:Docker镜像的大小并不等于容器中文件系统内容的大小(不包括挂载文件,/proc、/sys等虚拟文件)。个中缘由,就和联合文件系统有很大的关系了。
假设本地镜像存储中只有一个ubuntu:14.04的镜像,我们以两个Dockerfile来说明镜像复用:
FROM ubuntu:14.04 RUN apt-get update FROM ubuntu:14.04 ADD compressed.tar /
假设最终docker build构建出来的镜像名分别为image1和image2,由于两个Dockerfile均基于ubuntu:14.04,因此,image1和image2这两个镜像均复用了镜像ubuntu:14.04。 假设RUN apt-get update修改的文件系统内容为20MB,最终本地三个镜像的大小关系应该如下:
ubuntu:14.04: 200MB
image1:200MB(ubuntu:14.04)+20MB=220MB
image2:200MB(ubuntu:14.04)+100MB=300MB
如果仅仅是单纯的累加三个镜像的大小,那结果应该是:200+220+300=720MB,但是由于镜像复用的存在,实际占用的磁盘空间大小是:200+20+100=320MB,足足节省了400MB的磁盘空间。在此,足以证明镜像复用的巨大好处。
下面具体分析一下docker image 文件系统:
docker支持多种graphDriver,包括vfs、devicemapper、overlay、overlay2、aufs等等,其中最常用的就是aufs了,但随着linux内核3.18把overlay纳入其中,overlay的地位变得更重目前docker默认的存储类型就是overlay2,docker版本是1.8,如下
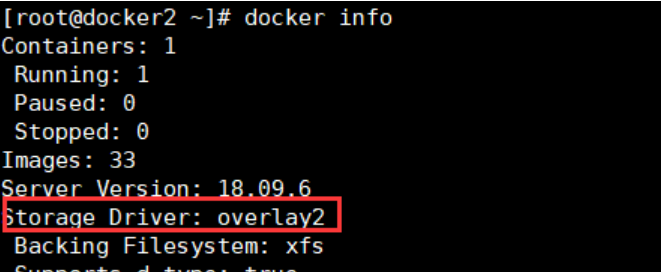
docker默认的存储目录是/var/lib/docker,我们



cat 573040df70596555bbbbd2bb113272101b4d7c873b8eed075fcbc0a951636094 | python -mjson.tool
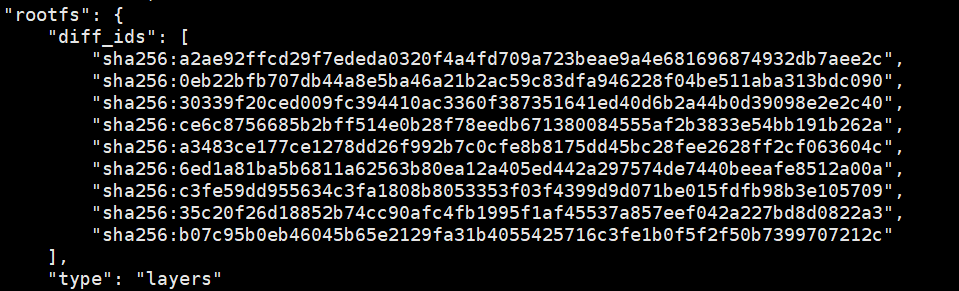


echo -n "sha256:a2ae92ffcd29f7ededa0320f4a4fd709a723beae9a4e681696874932db7aee2c sha256:0eb22bfb707db44a8e5ba46a21b2ac59c83dfa946228f04be511aba313bdc090" |sha256sum -
这个时候,你能看到4cbc0ad7007fe8c2dfcf2cdc82fdb04f35070f0e2a04d5fa35093977a3cc1693这个layer层的目录了吧?依次类推,我们就能找出所有的layerID的组合。
但是上面我们也说了,/var/lib/docker/image/overlay2/layerdb存的只是元数据,那么真实的rootfs到底存在哪里呢?其中cache-id就是我们关键所在了。我们打印一擦cat /var/lib/docker/image/overlay2/layerdb/sha256/4cbc0ad7007fe8c2dfcf2cdc82fdb04f35070f0e2a04d5fa35093977a3cc1693/cache-id:

引申一下:
docker save:
Produces a tarred repository to the standard output stream. Contains all parent layers, and all tags + versions, or specified repo:tag, for each argument provided.
docker load:
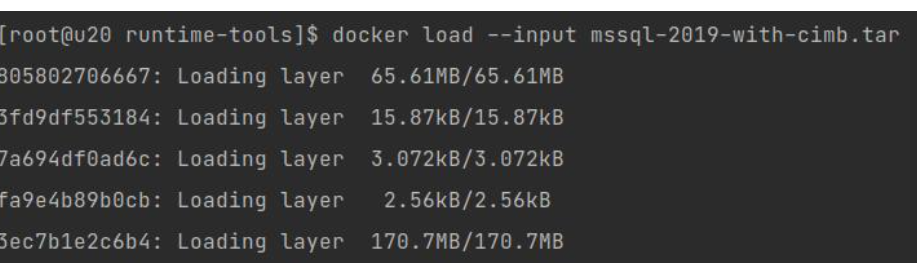
如果load前有相同的layer层,实际还会导入这么多吗,例如多个jar程序,都是基于java镜像构建。
Docker的“层”解释了为什么Docker镜像只在第一次下载时那么慢,而之后的镜像都很快,并且明明每份镜像看起来都几百兆,但是最终机器上的硬盘缺没有占用那么多的原因。更小的磁盘空间、更快的加载速度,让Docker的复用性有了非常显著的提升。
参考:
https://blog.51cto.com/u_12182612/2476386
https://blog.csdn.net/shlazww/article/details/47375009
https://www.cnblogs.com/powertoolsteam/p/14954314.html
posted on 2021-09-14 20:43 TrustNature 阅读(1365) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号