浅尝ptmalloc源码
浅尝ptmalloc源码(仅有关malloc)
这篇文章写的有点乱(毕竟本人太菜了/-_-\),如果就只是想看源码分析请师傅直接从核心结构体分析这一步看,后续会更新有关其他的源码分析
引入
在这里我们要知道什么是动态内存管理。
我们在学习c语言时可以知道到了堆的创建和销毁(程序员可以用malloc()free()),关于malloc()和free(),c语言知识规定了他们要实现的功能,并没有对实现方式进行详细的描述和限制。
比如free()函数,它规定一旦一个内存区域被释放掉,那么就不应该对其进行任何引用,任何对释放区域的引用都会导致不可预知的后果。那么到底是什么的不可预知的后果?这取决于内存管理器(memory allocator)使用的算法。
ptmalloc简述
ptmalloc 实现了 malloc(),free()以及一组其它的函数. 以提供动态内存管理的支持。
内存分布
在了解ptmalloc之前。我们先了解一下内存分布
32位的
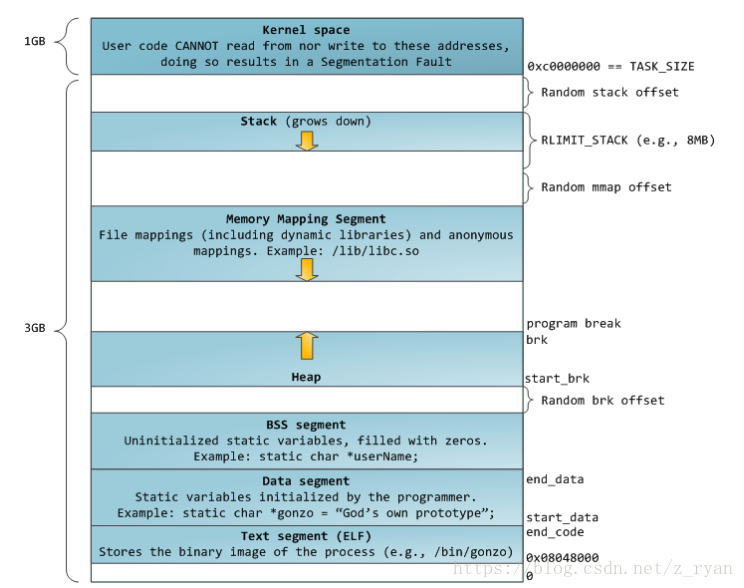
从上图中我们可以总结为下面几个点(栈,堆,mmap)
1、栈从高地址向低地址扩展
2、堆从低地址向高地址扩展
3、mmap 映射区域置顶向下扩展,直至耗尽虚拟地址中剩余的区域。
代码段在下,数据段在上(包括date和bss)
从数据段的顶部end_data到堆栈段地址的下沿这个中间区域则是一个巨大的空洞,这就是可以在运行时动态分配的空间
start_stack是进程堆栈段起始地址,start_brk是进程动态内存分配起始地址(堆的起始地址)
操作系统内存分配的相关函数
heap和mmap映射区域都可以给用户程序提供虚拟内存空间。
brk(sbrk)和mmap函数
linux系统向用户提供申请内存的有brk和mmap函数
brk
heap操作有两个函数
brk()为系统调用,sbrk()为C库函数。
如果把malloc想象成零售,brk则是批发。mmap是产源地
mmap
用于申请更大的堆,就本人所见只有所申请的大小大于topchunk才会调用这个函数
内存管理数据结构概述
main_arena和non_main_arena
每个进程只有一个主分配区,可以有多个非主分配区,ptmalloc 根据系统对分配区 的争用情况动态增加非主分配区的数量,分配区的数量一旦增加,就不会再减少了。主分配 区可以访问进程的 heap 区域和 mmap 映射区域
chunk的组织
不管内存是在哪里被分配的,用什么方法分配,用户请求分配的空间在 ptmalloc 中都使 用一个 chunk 来表示。用户调用 free()函数释放掉的内存也并不是立即就归还给操作系统, 相反,它们也会被表示为一个 chunk,ptmalloc 使用特定的数据结构来管理这些空闲的 chunk。
chunk的格式(malloc_chunk details:)

我们可以发现上面有两个指针
1、chunk指向一个chunk的开始(一个chunk中不仅有数据,还有相关的控制信息)
2、mem所指向的是真正返回用户的内存指针
一个 chunk 的大小是 chunk 到 next chunk 之间。而通过 malloc 返回的是 mem 指向的地址。为了方便管理,ptmalloc 给用户分配的内存前后都加了控制信息。现在来介绍一下这些控制信息
1)size of previous chunk
这是前面一个 chunk 的大小,这里的前面一个指的是低地址的那一个
其实这里用了空间复用的知识来提高空间的利用率(当本chunk正在使用中,那么下一个(低地址的chunk的size of previous chunk 就不能被使用,难道就浪费掉这8个字节吗(64位),显然并不是,它会当作本chunk的数据区的一部分)
2)size of chunk
这个 chunk 的大小。而且这个 chunk 的大小一定是 8 的倍数。所以低三位是 0,由于低三位是 0,是固定值,可以将这些固定值,用来表示其他的含义,反正计算大小的时候,统一把他们当成 0 就好了。下面从高到低介绍这些标志的意思
A:是不是「主分配区」分配的内存 1 表示不是主分配区分配的,0 表示是主分配区分配的
M:是不是 Memory Mapped 分配的内存,1 表示是,0 表示是 heap
P:表示前一个 chunk 是否在使用,在初始化的时候通常为 1,防止使用不能访问的内存
空闲的chunk

当 chunk 空闲时,其 M 状态不存在,只有 AP 状态,原本是用户数据区的地方存储了四 个指针,(不同的chunk存在的指针不同)
指针 fd 指向后一个空闲的 chunk,(指向的是上一个free的chunk,如图)
bk 指向前一个空闲的 chunk,ptmalloc 通过这 两个指针将大小相近的 chunk 连成一个双向链表。
对于 large bin 中的空闲 chunk,还有两个 指针,fd_nextsize 和 bk_nextsize,这两个指针用于加快在 large bin 中查找最近匹配的空闲 chunk。不同的 chunk 链表又是通过 bins 或者 fastbins 来组织的
空闲的chunk容器bins
free掉的chunk并不是马上归还与系统,ptmalloc会统一管理heap和mmap中映射的chunk,当用户进行下一次分配请求时,ptmalloc 会首先试图在空闲的 chunk 中挑选一块给用户,这样就避免了频繁的系统调用,降低了内存分配的开销。ptmalloc 将相似大小的 chunk 用双向链表链接起来,这样的一个链表被称为一个 bin。Ptmalloc 一共 维护了 128 个 bin,并使用一个数组来存储这些 bin(如下图所示)。
- 根据bin链成员的大小不同,分为以下几类:
- fast bin是单链表,其他都是双向链表。
- Unsorted bin。
- Small bin。
- Large bin。
分配 chunk 时必须以 2*SIZE_SZ 对齐,
unsorted bin
Unsorted bin 可以看作是 small bins 和 large bins 的 cache,只有一个 unsorted bin,以双 向链表管理空闲 chunk,空闲 chunk 不排序,所有的 chunk 在回收时都要先放到 unsorted bin 中, 也就是说只能从unsortbin中进入到smallbin和largebin。
fast bin
从0x20到0x80(64位),且在放进fsatbin中不会进行合并也就是他的prev_insuer一直为零
smallbin
小于1024字节(0x400)的chunk称之为small chunk,small bin就是用于管理small chunk的。
small bin链表的个数为62个。
就内存的分配和释放速度而言,small bin比larger bin快,但比fast bin慢。
largebin
大于等于1024字节(0x400)的chunk称之为large chunk,large bin就是用于管理这些largechunk的。
large bin链表的个数为63个,被分为6组。
largechunk使用fd_nextsize、bk_nextsize连接起来的。
核心结构体分析
glibc内部的malloc()函数只是__libc_malloc()函数的一个别名,而___libc_malloc的·主要工作是有_int_malloc完成的
__libc_malloc()
1.atomic_forced_read()函数
返回malloc_hook的地址(malloc_hook可以看作为提供一个可以写自定义分配函数的地方)在进入_int_malloc前会检查malloc_hook的内面是否为空,如果不为空就去执行
void *(*hook) (size_t, const void *)
= atomic_forced_read (__malloc_hook);//将__malloc_hook的地址放入任意寄存器(r)再取出. 先获取__malloc_hook的地址
if (__builtin_expect (hook != NULL, 0))//这里进行判断,如果__malloc_hook不为空,就将其执行
return (*hook)(bytes, RETURN_ADDRESS (0));
进入_int_malloc
victim = _int_malloc (ar_ptr, bytes);
_int_malloc
首先是一些变量的定义
INTERNAL_SIZE_T nb; /* normalized request size */
unsigned int idx; /* associated bin index */
mbinptr bin; /* associated bin */
mchunkptr victim; /* inspected/selected chunk */
INTERNAL_SIZE_T size; /* its size */
int victim_index; /* its bin index */
mchunkptr remainder; /* remainder from a split */
unsigned long remainder_size; /* its size */
unsigned int block; /* bit map traverser */
unsigned int bit; /* bit map traverser */
unsigned int map; /* current word of binmap */
mchunkptr fwd; /* misc temp for linking */
mchunkptr bck; /* misc temp for linking */
const char *errstr = NULL;
将申请的内存大小转化为申请的chunk大小
checked_request2size (bytes, nb)
检查分配的area是否为零
if (__glibc_unlikely (av == NULL))//如果没有找到arena,就调用sysmalloc通过mmap来获取chunk
{
void *p = sysmalloc (nb, av);
if (p != NULL)
alloc_perturb (p, bytes);
return p;
}
fastbin中查找
首先根 据所需 chunk 的大小获得该 chunk 所属 fast bin 的 index,根据该 index 获得所需 fast bin 的空 闲 chunk 链表的头指针。
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
{
idx = fastbin_index (nb);
mfastbinptr *fb = &fastbin (av, idx);
mchunkptr pp = *fb;
}
为了加 快从 fast bins 中分配 chunk,处于 fast bins 中 chunk 的状态仍然保持为 inuse 状态,避免被 相邻的空闲chunk合并,从fast bins中分配chunk,只需取出第一个chunk
检查fastbin中有没有,如果有就按照LIFO的规则取出来,并将链表头设置为取之前的第二个chunk的地址,没有就退出
do
{//这里将chunk按照LIFO的规则取出来,并将链表头设置为取之前的第二个chunk的地址
//(也就是第一个chunk的下一个chunk)
victim = pp;//pp相当于头指针
if (victim == NULL)
break;
}
while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim))!= victim);/*pp = victim == victim 导致循环退出*/
/*作用为从刚刚得到的空闲chunk链表指针中取出第一个空闲的chunk(victim),并将链表头设置为该空闲chunk的下一个chunk(victim->fd)*/
下一步就是做分配给用户前的检查
1、大小检查
2、返回用户指针
3、指明用户输入的地址和大小
if (victim != 0)/*此时的victim是是刚刚那条链上第一个chunk的地址*/
{
if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0))/*检查我们取出的chunk的size是否与我们申请的fastbin的大小相同*/
*/
{
errstr = "malloc(): memory corruption (fast)";
errout:
malloc_printerr (check_action, errstr, chunk2mem (victim), av);
return NULL;
}
check_remalloced_chunk (av, victim, nb);//开启调试的话,才会启用这个函数,否则无用
void *p = chunk2mem (victim);//将堆块头指针返回成用户指针
alloc_perturb (p, bytes);/*这里就是向p(chunk的地址)+0x10填充字符(大小是我们申请的大小)*/
return p;
}
}
在samllbin中取出
如果分配的 chunk 属于 small bin,首先查找 chunk 所对应 small bins 数组的 index,然后 根据 index 获得某个 small bin 的空闲 chunk 双向循环链表表头
if (in_smallbin_range (nb))
{
idx = smallbin_index (nb);//这个跟fast bin类似,也是通过大小来获取索引 索引与大小的关系 size=2*SIZE_SZ*index
bin = bin_at (av, idx);//这个宏会返回索引对应的链表头指针
}
将最后一个 chunk 赋值 给 victim,如果 victim 与表头相同,表示该链表为空,(个人理解就是检查头指针和尾指针是否互相指着,因为链表是空的话,头指针和尾指针是互相指着的,好吧这是我胡说的,他的意思就是如果链表头的fd指向自己就说明这个链表为空)
if ((victim = last (bin)) != bin)
{
if (victim == 0)
malloc_consolidate (av);//如果victim为NULL,则调用malloc_consolidate完成堆的初始化
}
如果不为零
会有以下操作
1、进行一个链表的单向检查
2、脱链
else
{
bck = victim->bk;/*获取此chunk的下一个chunk的地址,也就是倒数第二个堆块*/
if (__glibc_unlikely (bck->fd != victim))
{
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
set_inuse_bit_at_offset (victim, nb);//victim的下一个堆块(高地址)的prev_inuse位设置为1
bin->bk = bck;//将victim脱链
bck->fd = bin;
/*bin是头指针 bck->fd = bin victim下一个chunk的fd设置为链表头地址*/
if (av != &main_arena)//如果不是主分配区,就将victim设置NON_MAIN_ARENA
victim->size |= NON_MAIN_ARENA;
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);//将堆块头指针返回成用户指针
alloc_perturb (p, bytes);
return p;
}
如果没有初始化就会调用调用 malloc_consolidate()函数将 fast bins 中的 chunk 合并放进unsortbin中
else
//如果没有进入到small bin那个if里面(就是说申请的堆块大小不属于small bin的范围)那么就将fast bin里的堆块进行合并
{
idx = largebin_index (nb);
if (have_fastchunks (av))
/*have_fastchunks这个宏判断fast bin中是否存在chunk,如果存在chunk,那arena结构体中flags将设置为0,反之为1 标记 fastbins 是否为空的是分配区管理的一个数据成员 flags
#define FASTCHUNKS_BIT (1U)
#define have_fastchunks(M) (((M)->flags & FASTCHUNKS_BIT) == 0)
*/
malloc_consolidate (av);
*/
}
否则,将 victim 从 small bin 的双向循环链表中取出,
1、检查victim的下一个堆块的fd指针是否是victim,
其他就跟fastbin的差不多
else
{
bck = victim->bk;/*获取此chunk的下一个chunk的地址,也就是倒数第二个堆块*/
if (__glibc_unlikely (bck->fd != victim))
//这里检查了victim的下一个堆块的fd指针是否是victim,类似于unlink的检查
//如果通过伪造链表头指针->bk (也就是victim),那么在碰到这个检查的时候就无法正常通过。
{
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
set_inuse_bit_at_offset (victim, nb);//victim的下一个堆块(高地址)的prev_inuse位设置为1
bin->bk = bck;//将victim脱链
bck->fd = bin;
/*bin是头指针 bck->fd = bin victim下一个chunk的fd设置为链表头地址*/
if (av != &main_arena)//如果不是主分配区,就将victim设置NON_MAIN_ARENA
victim->size |= NON_MAIN_ARENA;
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);//将堆块头指针返回成用户指针
alloc_perturb (p, bytes);
return p;
}
在unsortbin中取出
其实就是一个大循环,在查找有没有合适的chunk的同时,把unsortbin中的chunk归类到smallbin或largebin中
for (;; )
{
...
}
检查unsortbin中有没有chunk,如果有就进入,检查是否符合chunk正常的大小
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
{
bck = victim->bk;
if (__builtin_expect (victim->size <= 2 * SIZE_SZ, 0)
|| __builtin_expect (victim->size > av->system_mem, 0))
//遍历unsorted bin的时候,去检查每个chunk是否合法(chunk的大小应该大于2 * SIZE_SZ,并且小于system_mem)
//因为正常申请再释放掉的堆块大小一定是大于2*SIZE_SZ,并且小于系统调用申请出来的内存大小
//如果将victim的size进行伪造的话,就有可能会不满足这个正常的范围,从而报错
malloc_printerr (check_action, "malloc(): memory corruption",
chunk2mem (victim), av);
size = chunksize (victim);
if (in_smallbin_range (nb) &&bck == unsorted_chunks (av) &&
victim == av->last_remainder &&(unsigned long) (size) > (unsigned long) (nb + MINSIZE))
{
...
}
if (size == nb)
{
...
}
}
申请空间 nb 在 smallbins 范围内
unsortedbin 仅有唯一一个空闲 chunk
唯一的一个空闲 chunk 是 last_remainder
唯一一个空闲 chunk 的大小可以进行切割
if (in_smallbin_range (nb) &&
bck == unsorted_chunks (av) &&
victim == av->last_remainder &&
(unsigned long) (size) > (unsigned long) (nb + MINSIZE))
{
//如果通过了上面的if检查,就要面临切割chunk了,主要就是切割remainder并把新的remainder放到unsortedbin上
}
//如果unsorted bin中有完全合适的chunk,就直接拿
if (size == nb)
{
...
}
/*若上一个步骤没有成功,则将victim置于对应的bin中*/
if (in_smallbin_range (size))
{
把大小属于smallbin的chunk链到smallbin中
}
如果不在smallbin范围内,就是在largebin范围内
else
{
把大小属于largebin的chunk链到smallbin中
}
if (++iters >= MAX_ITERS)
break;
在lagerbin中查找
在largebin中寻找有没有合适的chunk
if (!in_smallbin_range (nb))
{
主要内容是找到一个大于用户请求的chunk,判断在切割给用户后,剩下的是否满足最小chunk的要求,满足则将,剩下部分插入到unsortedbin中,不满足的话将整个chunk分配给用户
}
for(;;)
{
大循环的最后一部分,首先会从top chunk中尝试分配内存;如果失败,就检查fasbin是否有空闲内存(其他线程释放的内存),
合并fastbin中的chunk放入small bin或large bin,继续进大循环。如果没有fastbin则尝试通过sysmalloc从操作系统申请内存。
}
}
大循环的最后一部
for(;;)
{
大循环的最后一部分,首先会从top chunk中尝试分配内存;如果失败,就检查fasbin是否有空闲内存(其他线程释放的内存),
合并fastbin中的chunk放入small bin或large bin,继续进大循环。如果没有fastbin则尝试通过sysmalloc从操作系统申请内存。
}
malloc_consolidate()函数
第一次调用时get_max_fast()为0(也就是global_max_fast),因此进入else,然后触发了set_max_fast将global_max_fast改变
/再调用的时候由于global_max_fast为fast bin的最大值了,所以就可以进入if了
if (get_max_fast () != 0)
{
}
第一次循环
检查fastbin数组是否为零
do
{
p = atomic_exchange_acq (fb, 0);//将fb的值给p,也就是将fb解引用
if (p != 0) {
do{
..
}
}while (fb++ != maxfb);
}
第二个循环:
在进行合并之前会有一些准备
1、获得fd指向的chunk地址和大小
2、获得相邻高地址chunk的地址和大小
向低地址合并
然后检查p的previnuse位是否为0,通过减p->prev_size找到相邻低地址chunk的开始位置,把p指向的块进行脱链,把p指向相邻低地址chunk位置,
if (!prev_inuse(p)) {
prevsize = p->prev_size;
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(p, bck, fwd);
}
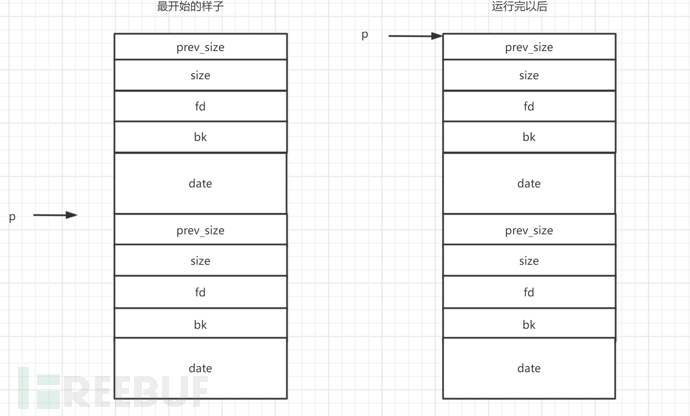
向高地址循环
if (nextchunk != av->top)先检查下一个chunk是不是topchunk
如果是则执行下面的else语句
size字段直接加上topchunk的size,并且设置p的size位,然后将top指针指向p,这样就完成了topchunk的融合。
else {
//如果p和top chunk,那么p将会合并到top chunk中
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
}
如果不是topchunk
就会获得这个chunk的prev_inuser检查是不是0
if (!nextinuse) {//如果高地址的prev_inuse为是0
size += nextsize;//就把高地址的大小加起来
unlink(av, nextchunk, bck, fwd);//将nextchunk脱链(并非将p脱链)
//因为p和nextchunk合并了,而p在低地址,将p加上nextchunk的size再重新接回链上,此时就完成了p和nextchunk的合并
}
不是零就把高地址的chunk的prev_inuser置零表示上一个chunk处于空闲状态,并把这个chunk放进unsortbin中
clear_inuse_bit_at_offset(nextchunk, 0);//清空nextchunk的prev inuse位,也就是说明p此时变成了空闲堆块
first_unsorted = unsorted_bin->fd;//将p放入unsorted bin中 /* 要链接的块 */
unsorted_bin->fd = p;/*将p放到unsorted bin中*/
first_unsorted->bk = p;
检查在不在smallbin中,如果不在,就是在largebin中,而largebin中有4指针,需要清空指针
if (!in_smallbin_range (size)) {
//如果堆块不属于small bin的范围,那就清空fd_nextsize和bk_nextsize两个指针
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}


上面是我找到的两个图,第一个 额没看懂,先放着,第二个是有关largebin的
下面是对__libc_malloc和_int_malloc整个过程的简化
__libc_malloc
void *(*hook) (size_t, const void *)
= atomic_forced_read (__malloc_hook);//将__malloc_hook的地址放入任意寄存器(r)再取出. 先获取__malloc_hook的地址
if (__builtin_expect (hook != NULL, 0))//这里进行判断,如果__malloc_hook不为空,就将其执行
return (*hook)(bytes, RETURN_ADDRESS (0));
arena_get (ar_ptr, bytes);//寻找一个合适的arena来分配内存 如果获取成功参数av是获得地址的分配指针
victim = _int_malloc (ar_ptr, bytes);//内存分配的核心是int_malloc
后面就是如果用_int_malloc分配失败,并且我们之前能够找到一个可用arena,可以用另一个arena重试。
if (!victim && ar_ptr != NULL)
{
....
}
malloc_hook_ini
static void *
malloc_hook_ini (size_t sz, const void *caller)
{
__malloc_hook = NULL;
ptmalloc_init ();
return __libc_malloc (sz);
}
ptmalloc_init 函数
ptmalloc_init 的定义在 arena.c 文件里面,它里面有这样的一些操作:
ptmalloc_init用来对整个ptmalloc框架进行初始化,
static void
ptmalloc_init (void)
{
if (__malloc_initialized >= 0)
return;
__malloc_initialized = 0;
// 初始化 ptmalloc 操作
...
...
__malloc_initialized = 1;
}
_int_malloc
第一步
通过两个if完成用户申请内存的转换
static void *
_int_malloc (mstate av, size_t bytes)
{
首先是一些变量的定义
.....
然后是判断申请的arena是不是零,是不执行,没有则调用sysnalloc获得
if (__glibc_unlikely (av == NULL))
{
void *p = sysmalloc (nb, av);
if (p != NULL)
alloc_perturb (p, bytes);
return p;
}
首先在fastbin中寻找有没有合适的
fastbin采用的是先进后出的单链表方式
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
{
...
执行查找(主要就是chunk的控制信息的修改,和fastbin取出的过程)
如果有就
return p
}
如果在fsatbin中找不到,进入smallbin中查找
smallbin采用的是先进先出的双链表方式
//small bin的范围是0x20 ~ 0x3F0(64位程序)
if (in_smallbin_range (nb))
{
执行查找(主要就是chunk的控制信息的修改,和smallbin取出的过程)
如果有就
return p
}
//如果没有进入到small bin那个if里面(就是说申请的堆块大小不属于small bin的范围)那么就将fast bin里的堆块进行合并
else
{
idx = largebin_index (nb);
if (have_fastchunks (av))/*have_fastchunks这个宏判断fast bin中是否存在chunk
malloc_consolidate (av);//将fast bin中chunk进行了合并,然后将其放到了unsorted bin中
}
进入unsortedbin中去寻找
for (;; )
{
....
}
}
for (;; )
{
int iters = 0;
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
//如果unsortedbin中有chunk
{
if (in_smallbin_range (nb) &&bck == unsorted_chunks (av) &&
victim == av->last_remainder &&(unsigned long) (size) > (unsigned long) (nb + MINSIZE))
{
0x400
free----unsortbin
0x200
0x20
即满足四个条件:
申请空间 nb 在 smallbins 范围内
unsortedbin 仅有唯一一个空闲 chunk
唯一的一个空闲 chunk 是 last_remainder
唯一一个空闲 chunk 的大小可以进行切割
主要内容就是有关切割后让last_remainder重新指向新的remainder
}
//如果unsorted bin中有完全合适的chunk,就直接拿
if (size == nb)
{
...0x50 0x50
}
/*若上一个步骤没有成功,则将victim置于对应的bin中*/
if (in_smallbin_range (size))
{
把大小属于smallbin的chunk链到smallbin中
}
如果不在smallbin范围内,就是在largebin范围内
else
{
把大小属于largebin的chunk链到largebin中
}
if (++iters >= MAX_ITERS)
break;
}
在largebin中寻找有没有合适的chunk
if (!in_smallbin_range (nb))
{
主要内容是找到一个大于用户请求的chunk,判断在切割给用户后,剩下的是否满足最小chunk的要求,满足则将,剩下部分插入到unsortedbin中,不满足的话将整个chunk分配给用户
}
for(;;)
{
大循环的最后一部分,首先会从top chunk中尝试分配内存;如果失败,就检查fasbin是否有空闲内存(其他线程释放的内存),
合并fastbin中的chunk放入small bin或large bin,继续进大循环。如果没有fastbin则尝试通过sysmalloc从操作系统申请内存。
}
}
如果在bins链(不包括fastbin)中存在freechunk时,当我们去malloc的时候,malloc的请求大小比freechunk的大小小,
那么arena就会切割这个freechunk给malloc使用,那么切割之后剩余的chunk就被称为“last remainder”
当产生last remainder之后,表示arena的malloc_state结构体中的last_remainder成员指针就会被初始化,并且指向这个last remainder
大概顺序是
fastbin--->smallbin--->unsortedbin--->largebin----->topchunk------>sysmalloc
总结
_int_malloc的思路如下:
第一步:如果从heap中分配内存失败,就通过sysmalloc从操作系统分配内存。
第二步:从fastbin查找对应大小的chunk并返回,如果失败进入第三步。
第三步:从smallbin查找对应大小的chunk并返回,或者将fastbin中的空闲chunk合并放入unsortedbin中,如果失败进入第四步。
第四步:遍历unsortedbin,从unsortedbin中查找对应大小的chunk并返回,根据大小将unsortedbin中的空闲chunk插入smallbin或者largebin中。进入第五步。
第五步:从largebin指定位置查找对应大小的chunk并返回,如果失败进入第六步。
第六步:从largebin中大于指定位置的双向链表中查找对应大小的chunk并返回,如果失败进入第七步。
第七步:从topchunk中分配对应大小的chunk并返回,topchunk中没有足够的空间,就查找fastbin中是否有空闲chunk,如果有,就合并fastbin中的chunk并加入到unsortedbin中,然后跳回第四步。如果fastbin中没有空闲chunk,就通过sysmalloc从操作系统分配内存。
最后在说一下area与线程之间的关系,简单查了一下在下面说一下,对,在linux系统中不分线程和进程,即每个线程就是一个进程
arena数量限制
一个线程都会有自己的arena。这里有一个arena个数的限制:
对于32位操作系统:arena的个数=2 * 处理器核心数+1
对于64位操作系统:arena的个数=8 * 处理器核心数+1
arena管理
假如我area数量有3个,我们已经开了三个线程(1到3),又开启一个线程4,它会遍历所有area有没有空闲的,假设1号线程此时并不使用area,就会把一号线程的area分配给4,为了放置3号线程突然又使用这个area,会把这个area上锁,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号