
C#网络下载器
之前学习了一部分的C#基础,但是感觉会的不多,很多地方依然需要通过做一点小Demo来进行巩固,那么这个C#的网络下载器,就来了
原理讲解
首先我们编写代码之前,我们需要了解下网络下载的原理到底是什么?
学习过C#中IO流部分的知识,或者你有其它的语言的基础,学习过其它语言的文件IO的基础,肯定了解过我们计算机中的数据都是二进制,那么网络中传输的数据本质上也是一样的。
我们在学习文件IO中,都会学习文件的读写操作,读操作(Output),将文件中的二进制数据读出来,写操作(Input)将内存中的二进制数据写入到硬盘中的文件中。
那么网络下载的本质就是文件的读写,其步骤分为以下几步:
- 向服务器发起请求
- 服务器接收到请求,返回响应,而这个响应是一个文件流数据
- 程序接收到响应,读取响应体中的二进制数据(读文件的操作)
- 将读取的文件二进制数据写入到磁盘中
代码实现
现在已经了解了原理,那么就开始代码实现吧!
namespace WebDownLoad
{
// 一个下载任务类
public class DownLoadTask
{
public async Task Start(string url,string targetUrl)
{
try
{
// 1.先创建一个HttpClient连接
// 由于HttpClient实现了IDispose接口,所以我们可以回收它的资源
using HttpClient client = new HttpClient();
// 1.1.某些网站会反爬,所以我们需要设置一些参数
client.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61");
// 2.进行异步请求
HttpResponseMessage response = await client.GetAsync(url);
// 3.请求成功
if (response.IsSuccessStatusCode)
{
// 3.1.读取文件的类型
string? type = response.Content.Headers.ContentType?.MediaType;
// 3.2.文件的总大小
long? totalSize = response.Content.Headers.ContentLength;
// 3.3.获取文件流
// 缓存区的大小为 10 kb
// 当前下载的大小
long downloadSize = 0;
int length = 0;
using BufferedStream bufferedStream = new BufferedStream(
await response.Content.ReadAsStreamAsync());
// 缓冲区大小 0.5KB
byte[] bufferSize = new byte[1024];
IEnumerable<byte> targetBuffer = new List<byte>();
string suffix = GetType(type);
while ((length = bufferedStream.Read(bufferSize, 0, bufferSize.Length)) != 0)
{
downloadSize += length;
long? progress = downloadSize * 100 / totalSize ;
targetBuffer = targetBuffer.Concat(bufferSize.ToList());
await Console.Out.WriteAsync($"\r下载中{progress}%");
}
await Console.Out.WriteLineAsync();
File.WriteAllBytes(targetUrl + Random.Shared.Next(10, 10000) + suffix, targetBuffer.ToArray());
}
// 4.请求失败
else
{
Console.WriteLine("请求下载失败");
}
}catch (HttpRequestException e)
{
Console.WriteLine($"请求下载失败:{e.Message}");
}
}
// 检测文件的类型
private string GetType(string type) {
string suffix = "";
if (type.Contains("jpeg"))
{
suffix = ".jpg";
}
else if (type.Contains("application/octet-stream"))
{
suffix = ".exe";
}
else if (type.Contains("png"))
{
suffix = ".png";
}
else if (type.Contains("mp4"))
{
suffix = ".mp4";
}
else if (type.Contains("avi"))
{
suffix = ".avi";
}
else if (type.Contains("mp3"))
{
suffix = ".mp3";
}
else if (type.Contains("mpeg"))
{
suffix = ".m4a";
}
return suffix;
}
}
}
我上面的这段代码,其实有点累赘,大家可以写的更好,不必看我的写法,我对C#的很多类不太熟悉,所以,整体代码的缺点还是很多的。
这里其实为了做出一个正在下载的效果,让控制台用户有体验,做了很多不必要的操作
这里为了使得可以一次性下载多个文件使用异步的操作,来提升程序的下载接收量,其实大家也可以不用异步操作,使用线程来实现
最后实验一下
using WebDownLoad;
namespace WebDownLoad
{
public class Program
{
public async static Task Main(string[] args) {
while (true)
{
Console.WriteLine("请输入下载地址(如果输入0退出):");
string url = Console.ReadLine();
if ("0".Equals(url))
{
break;
}
DownLoadTask task = new DownLoadTask();
task.Start(url, "E:\\网络下载\\");
}
}
}
}
当前的文件夹中是没有东西的

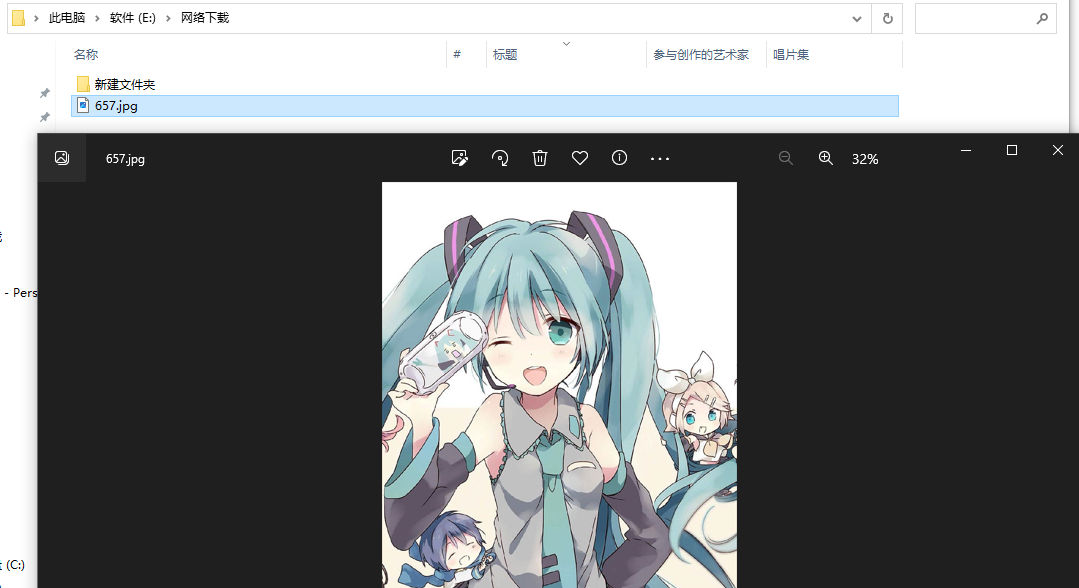
这里还可以继续下载,同时还有一个问题,我们需要了解,就是在C#中,其实异步并不会新开一个线程,C#底层实现异步其实本质上是使用switch goto 来进状态跳转,也就是它并不会实际上加快处理速度,但是可以加大程序的接收速度,也就是接收很快,但是处理不变,要加快处理还是得开线程,我们线程本身就是带有异步性的,所以这个程序使用线程实现可能是更好的

