
【学习笔记】后缀自动机 SAM
一. 后缀自动机的定义
SAM(Suffix Automaton) 是一种有限状态自动机,仅可以接受一个字符串的所有后缀。
如果您不懂自动机,那么换句话说:
SAM 是一个有向无环图。
称每个结点为状态,边为状态间的转移,每个转移标有一个字母,同一节点引出的转移不同。
SAM 存在一个源点 ,称为初始状态,其它各结点均可从源点出发到达。也存在一个或多个终止状态 ,每一条从 出发至 的路径所组成的字符串即为字符串的后缀。而对于这个字符串的每个后缀也必定在 SAM 的某条从 至 的路径上。
满足条件的同时,SAM 的点数是最少的。
接下来展示一个简单的 SAM:(以 abbb 为例)

红点为源点,蓝点为终止节点。箭头全部从左向右。
abbb 的所有后缀:
b: 1->5
bb: 1->5->6
bbb: 1->5->6->7
abbb: 1->2->3->4->7
二. 数组
设 ,表示对于字符串 的任意一个非空字符串 ,每一个 在 中出现的位置的右端。
如 abaabacaab,。
显然会出现有两个不同子串 ,而 ,如 abaabacaab,。
那么我们称在 abaabacaab 里,ab,b 为同一个 等价类。
对于 ,有几个引理:
引理 对于一个字符串中的两个子串 ,若 ,那么一个将是另一个的后缀
显然成立。因为若 不是 的后缀,那么必定有一个 的最后一位字符就必然不等于 的最后一位字符。
例子:
aabab
endpos(b)=endpos(ab)={3,5}
u=ab,v=b
引理 对于一个字符串的子串 ,那么必然有 或
即要么其中一个的 包含另一个的,要么两者的 没有交集。
显然有可能 两者无交集。而若两者的 有交集,那么不妨设 被 包含且不被 包含,那么由于两者 有交集,那么 的必然为 后缀,那么显然 必然被 包含。
例子:
原串:abacabbacabca
//example1:
u=aba,v=aca
endpos(u)={3}
endpos(v)={5,10}
//example2:
u=aca,v=ca
endpos(u)={5,10}
endpos(v)={5,10,13}
引理 每个 等价类里的子串升序排序后长度连续,且前一个串是这个串的后缀。
也很显然。若字符串 在同一个 等价类里,且 的长度严格小于 的长度且 长度不连续。由引理 显然 是 的后缀,那么 中间的那部分子串减去某个前缀后加上 显然亦为同一个 等价类里。
例子:
原串:acabaacbacaba
u=aba
v=acaba
endpos(u)=endpos(v)={5,13}
w=(c)+aba=caba,endpos(w)={5,13}
三.
虽然 还有引理,不过涉及到 ,就必要先讲这个。
考虑对于一个字符串 ,如果我们在 前面加上一个字符 ,那么会将 分成若干份(也可能是一份)。
举个例子,还是 acabaacba,对于 ba,。我们发现我们可以在 ba 前面加上 a 或 c,那么就变为 aba、cba,而 ,正好将 分成两份。
由于引理 ,那么两个非后缀关系的子串的 必无交集,所以考虑对于一个字符串的子串的 等价集为节点,那么这些分割关系构成了树形结构。
由于此时是个森林,考虑用一个超级根聚合起森林。
而空串的等价集为全集(它无处不在),所以用空寂作为超级根。
那么,我们以 abcabstrstrs 为原串建一个 :
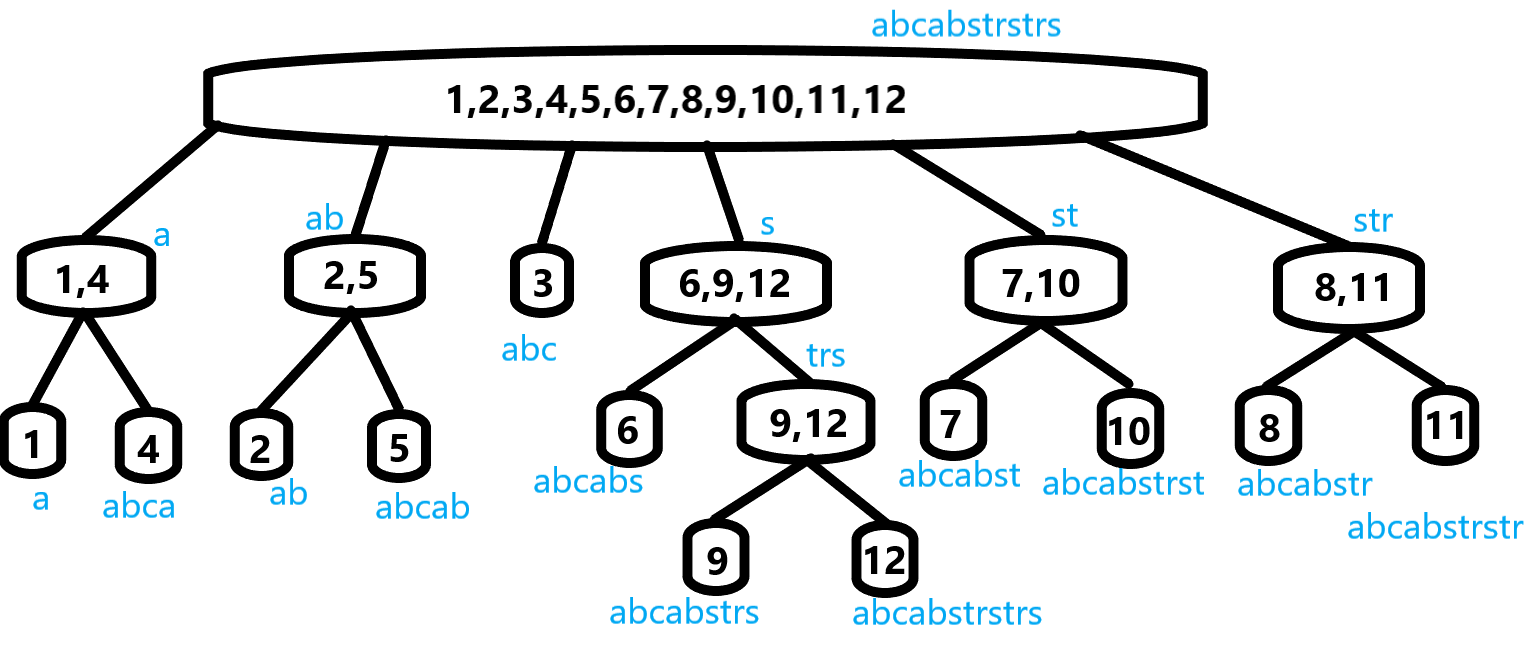
引入一个概念:我们称等价类 中的最长子串 指的是:该等价类 的所有子串中长度最长的子串。
那么每个节点旁边蓝色的就是代表当前节点(等价类)的最长子串。
结点中的数字为 集。
这时,我们就引出新的 引理:
引理 :若两个等价类 , 在 上是 的父亲,那么 的最长子串的长度 ,等于 的最短子串的长度。
我们考虑在一个等价类中的某个子串前再添加一个字符,显然,若选择的子串是这个等价类中的最长子串,形成的字符串就归于其儿子的等价类中,否则就仍在这个等价类中。
如果选择的是最长子串,那这个新形成的字符串肯定这个儿子等价类 中最短的一个。
引理 等价类的数量是 级别的。
如果说在一张图上表示一个字符串的所有子串,那么显然可以建 trie。
但是 trie 的节点数是 的。
考虑 的节点数量。
对于一个原串中的等价类,其中的最长子串 ,在 前添加一个字符且新字符串仍为原串子串,那么对于新的字符串 ,必然会得到若干个新的等价类,这一过程相当于 在 中将父亲分裂成儿子。
考虑在 前加入两个不同字符,成为新字符串 ,那么必定 ,因为 和 必定不被包含。
所以,对于每个等价类集,最多分割出的大小不会超过原字符串集合大小。由于 一共只有 个叶子结点,所以是 的。
四. 后缀自动机的构建
后缀自动机的本质,是通过 来维护的。
我们用 表示在 中 的直接父亲。
我们之前在 已经知道了在子串前面加字符的做法,那么现在讨论关于在后面加字符的做法。
用 表示在 结点对应的等价类的最长子串后面加上一个字符 ,形成的新字符串所属的等价类对应的结点。
也就是
可能有点绕,举个例子:
abcabstrs 的等价类在 节点,我们给它加上 t,就变成了 abcabstrst,其等价类在 节点。那么 。
SAM 的一个合法的连边方案应该满足,从源点出发到达点 经过的边形成的字符串,应该是点 的等价类的一个字符串,也就意味着,形成的字符串应该是点 的字符串的后缀。
我们先以 AABAB 为例子。
由于单张图片上传大小太大,所以我直接画出整个自动机 AABAB。显然现在的自动机有误,待会解释。
下图蓝色表示边上转移的字符,灰色表示点。

首先将空节点 加入。
然后加入字符 A,即 号节点。
加入 AA,即 号节点。由于 A 是 AA 的后缀,所以直接从 ,转移为 A。
的后缀:
A: 1->2
AA: 1->2->3
加入 AAB,即 号节点。先连接 ,转移是 B。但是 号节点都没有字符为 B 的出边,于是连接 ,转移是 B。
的后缀:
B: 1->4
AB: 1->2->4
AAB: 1->2->3->4
加入 AABA,即 号节点。直接连接 。
的后缀:
A: 1->2
BA: 1->4->5
ABA: 1->2->4->5
AABA: 1->2->3->4->5
加入 AABAB,此时与 时同理,连接 。
的后缀:
B: 1->6
AB: 1->2->6
BAB: 1->4->6
ABAB: 1->2->4->5->6
AABAB: 1->2->3->4->5->6
检查一下这个自动机。从 号点出发,有两条字符为 B 的边,显然不符合 SAM 的性质。
我们考虑新建一个节点 ,其字符串为 节点的最长公共后缀,即 AB。

我们考虑关于 的连边。
首先 ,转移为 。然后连接 ,转移为 A。这样,保证了 也满足。
的后缀:
4:
B: 1->7
AB: 1->2->7
AAB: 1->2->3->4
5:
A: 1->2
BA: 1->7->5
ABA: 1->2->7->5
AABA: 1->2->3->4->5
6:
B: 1->7
AB: 1->2->7
BAB: 1->7->5->6
ABAB: 1->2->7->5->6
AABAB: 1->2->3->4->5->6
我们看看 AABABA 的 SAM:

五. SAM 的代码实现
刚才我们已经模拟出了一个 SAM,现在我们考虑它如何用代码实现。
先放代码。代码中的 等如上文,只是用结构体表示第一维。
#include<bits/stdc++.h>
using namespace std;
const int N=2e6+3;
int n,last=1,tot=1,ans;
char s[N];
struct SAM{
int len,fa;
int ch[26];
SAM(){memset(ch,0,sizeof(ch));len=0;}
}sam[N];
inline void add(int c){
int p=last,np=++tot;
last=np;
sam[np].len=sam[p].len+1;
while(p&&!sam[p].ch[c]){
sam[p].ch[c]=np;
p=sam[p].fa;
}
if(!p)sam[np].fa=1;
else{
int q=sam[p].ch[c];
if(sam[q].len==sam[p].len+1)sam[np].fa=q;
else{
int nq=++tot;
sam[nq]=sam[q];
sam[nq].len=sam[p].len+1;
sam[q].fa=sam[np].fa=nq;
while(p&&sam[p].ch[c]==q){
sam[p].ch[c]=nq;
p=sam[p].fa;
}
}
}
}
int main(){
scanf("%s",s+1);
n=strlen(s+1);
for(int i=1;i<=n;i++)add(s[i]-'a');
return 0;
}
一步一步讲解。
struct SAM{
int len,fa;
int ch[26];
SAM(){memset(ch,0,sizeof(ch));len=0;}
}sam[N];
inline void add(int c){
int p=last;
np=++tot;
last=np;
sam[np].len=sam[p].len+1;
//......
}
int main(){
scanf("%s",s+1);
n=strlen(s+1);
for(int i=1;i<=n;i++)add(s[i]-'a');
return 0;
}
构建 SAM 的方法是增量法,即 SAM 每次吞进一个字符,对于这个字符而改变内部结构,再吞进下一个字符,以此类推。
每次吞字符的行为之间需要传递一些信息,除了以上提到的 和 照例保留外,还需要传递一个 变量,表示上一次添加字符后的串 所属的等价类。
显然,上一次加完字符后的串 ,一定是 这个等价类的最长子串。
所以在最长子串 后加上了一个字符 形成了一个新串 ,根据引理 , 将会归到一个新的等价类里。
所以我们开一个新点 ,表示 所属的新等价类对应的结点。
struct SAM{
int len,fa;
int ch[26];
SAM(){memset(ch,0,sizeof(ch));len=0;}
}sam[N];//将len、ch、fa存进结构体
inline void add(int c){
int p=last;//当前最长子串所在的等价类
np=++tot;//新等价类
last=np;//更新 last
sam[np].len=sam[p].len+1;//引理4得
//......
}
int main(){
scanf("%s",s+1);
n=strlen(s+1);
for(int i=1;i<=n;i++)add(s[i]-'a');//增量法
return 0;
}
inline void add(int c){
//......
while(p&&!sam[p].ch[c]){
sam[p].ch[c]=np;
p=sam[p].fa;
}
//......
}
遍历新串后缀,到第一个出现过的子串为止。
每当我们加入一个新字符,可能之前某些子串的出现位置(即 中的元素)就会变多。
比如当前加到第 位,有些新子串从来没出现过,需要多开一个 的等价类包含它们;有些新子串曾经出现过,它们的 中就多一个 。
这一段就是找到这些新子串的出现位置。对于新子串 ,它必然是加上新字符前的原字符串的某后缀,再拼接上我们现在加的这个字符 。
既然是后缀关系,对于拼上 的新串 ,一定存在某长度的后缀,使得长度小于它的其它后缀都出现过。
比如 ABCABSTRSTR,给它加上一个 S,那么 只有ABCABSTRSTRS,BCABSTRSTRS,CABSTRSTRS...TRS,RS,S 以及 的 会发生改变。
然而,在这些子串中,TRS,RS,S 和 在之前就出现过,所以它们在它们原有的 的基础上加上 ;而其余的就直接归类于 。
为了区分这些子串之前有没有出现过,考虑遍历后缀,找到这个第一个出现过的后缀。
又因为在一个字符串前面加一个字符等价于将其 分裂,即在 上分裂出子树。
反过来看,相当于删去前面的字符,那么就相当于在 上原地不动(不发生分裂)或者往上跳 。
所以通过跳 来遍历后缀。
inline void add(int c){
//......
while(p&&!sam[p].ch[c]){//p的判断表示防止跳出parent tree;!sam[p].ch[c] 表示p+'c'的最长子串是否曾经出现过
sam[p].ch[c]=np;//如果没有出现过,那么它的endpos直接为np
p=sam[p].fa;//跳fa操作
}
//......
}
inline void add(int c){
//...
if(!p)sam[np].fa=1;
else{
int q=sam[p].ch[c];
if(sam[q].len==sam[p].len+1)sam[np].fa=q;
else{
int nq=++tot;
sam[nq]=sam[q];
sam[nq].len=sam[p].len+1;
sam[q].fa=sam[np].fa=nq;
while(p&&sam[p].ch[c]==q){
sam[p].ch[c]=nq;
p=sam[p].fa;
}
}
}
}
分三个部分。
- 根作为它的父节点
if(!p)sam[np].fa=1;
这种比较容易,从 向上爬,如果一直爬到了根还没有 break,那么说明没有节点能做它的 ,那么只有根可以,那么直接认根做父节点。
int q=sam[p].ch[c];
else if(sam[q].len==sam[p].len+1)sam[np].fa=q;
设 ,我们需要知道 的最长子串 是否是 的最长子串。
换句话说:
在第一个有 边的祖先停下了, 即为 的 出边到达的节点。
其中一种情况是 的最长子串 就是 的最长子串。
因为这个串是最长子串,显然同等价类的其它子串都是它的后缀。所以它的后缀也会添加 。
那么我们直接令这整个集合 成为 (它对应 等价类)的 即可。
举个例子:
比如现在到了 ABCABSTRS,要加入 T, 的最长子串即为 ABCABSTRST,在等价类 。
然后我们通过跳 ,算出了最长的曾经出现过的后缀 ST。
那么 即为 ,然后这个等价类最长子串就是 ST,所以 ,也就是在 上 ST 是 ABCABSTRST 的父亲,也就是说 是 父亲。
int q=sam[p].ch[c];//取出q
else if(sam[q].len==sam[p].len+1)//q的最长子串=p的最长子串+c,即q的长度=p长度+1
sam[np].fa=q;//q成为np的fa
else{
int nq=++tot;
sam[nq]=sam[q];
sam[nq].len=sam[p].len+1;
sam[q].fa=sam[np].fa=nq;
while(p&&sam[p].ch[c]==q){
sam[p].ch[c]=nq;
p=sam[p].fa;
}
}
比如像 号节点。
显然 不总是一定为 。
既然我们需要一个可以做 的父亲的点,那么我们就构造一个 的父节点,设它为 。
所以 的最长子串就是 的最长子串 。
在分裂以前与 的差别在且仅在于 ,而在后面加一个字符能转移到哪里,就不在 决定的范围内了。
考虑 ,它表示的是在后面加字符后归在的等价类,显然 和 其实没有区别。那么直接令 继承 的 。
最后是 。 之前和 在树上成父子关系,根据引理 ,当时的 必然等于 最小子串长度。
而 的最小子串在 等价类里。
举个例子:
aabab 在加入第二个 b 时子串 ab 已经存在,所以 ab 的 集合变为 ,这样原来第一个 b 表示 aab,ab,b,它们的 都是 ,而现在只能表示 aab 的 是,而 ab,b 的 是 ,所以需要一个新的点来维护,同时这样操作也保证了如果在后面加入 c,只会增加 c,bc,abc 的 而不会增加 aabc 的 。
但是有些结点的 指向的是 ,而分裂后,这些 需要指向 。
所以考虑对于 不断往上 。判断条件为 。
即 的 不包含 ,而 的最长子串 的 包含 。
所以令这条边连向新的节点 ,不断操作即可。
的出边就是 的出边,然后 的所有除地面上地链上地入边都搬到了 上面去。
这就讲完了代码部分。
六. 复杂度
七. 练习题目
给你一个长为 的字符串,求不同的子串的个数。
对于一个给定的长度为 的字符串,求出它的第 小子串。
本文作者:trsins
本文链接:https://www.cnblogs.com/trsins/p/17970738
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
2022-01-17 【做题记录】Ynoi2018 天降之物
2022-01-17 【学术】连分数
2022-01-17 【做题记录】Ynoi2015 盼君勿忘
2022-01-17 【做题记录】BJOI2016 水晶
2022-01-17 【做题记录】P4965 薇尔莉特的打字机
2022-01-17 【做题记录】POI2011 Lightning Conductor
2022-01-17 【做题记录】CF961G Partitions