安装Hadoop
一、安装Linux,MySql
(一)安装前准备
1.安装Linux前需要安装 Oracle VM VirtualBox, 下载 https://www.virtualbox.org/wiki/Downloads 。
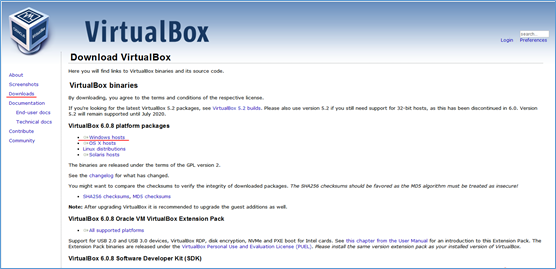
2.安装成功后,打开VirtualBox。

(二)安装Linux
1.新建虚拟机,为虚拟机命名为Ubuntu,类型为Linux,版本为Ubuntu (64位)。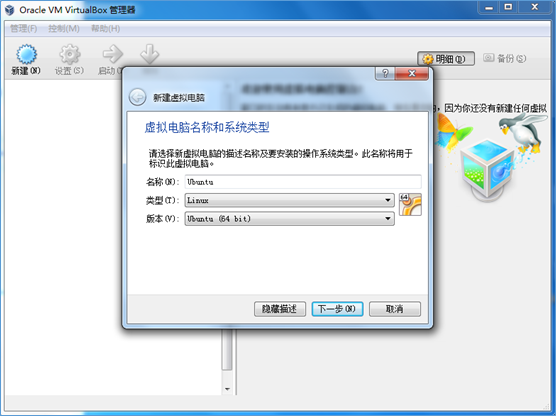
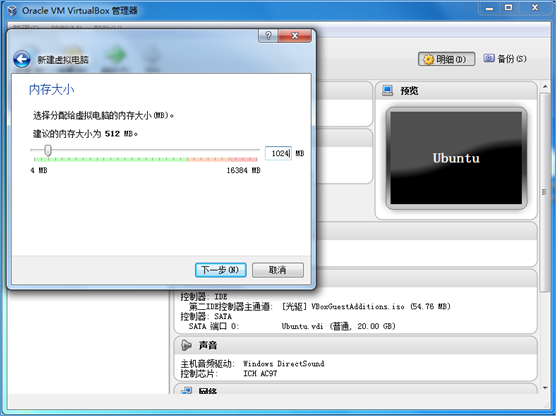
2.分配虚拟机内存大小为1024MB。
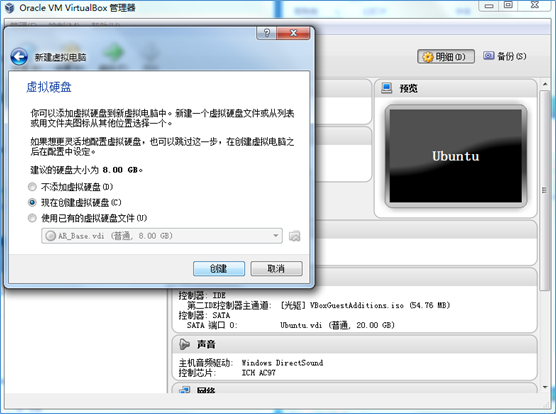
3.创建虚拟硬盘,步骤如下:
(1)选择 现在创建虚拟硬盘(C):
(2)选择 VDI (VirtualBox 磁盘映像):
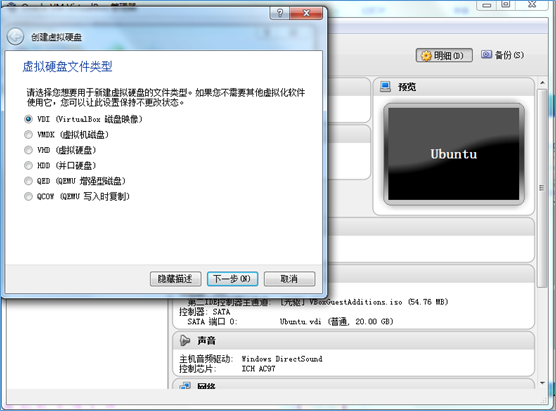
(3)选择 动态分配:

(4)位置默认为 Ubuntu,大小为 20GB:
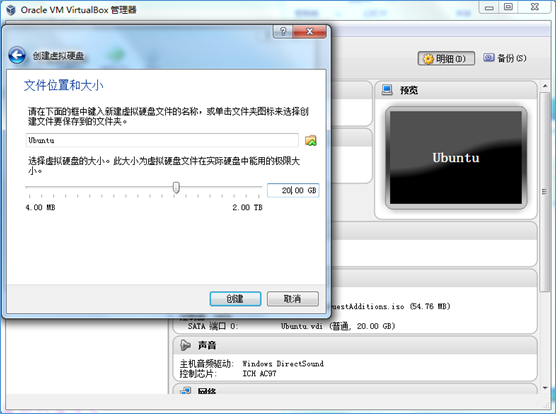
4.选择镜像文件
下载 01 ubuntukylin-16.04-desktop-amd64.iso,https://pan.baidu.com/s/1WtFnpezV2oCel3wZHitQUA,7eti
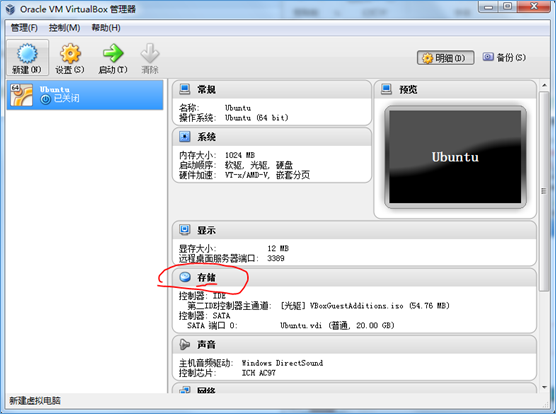
(1)选择 存储:
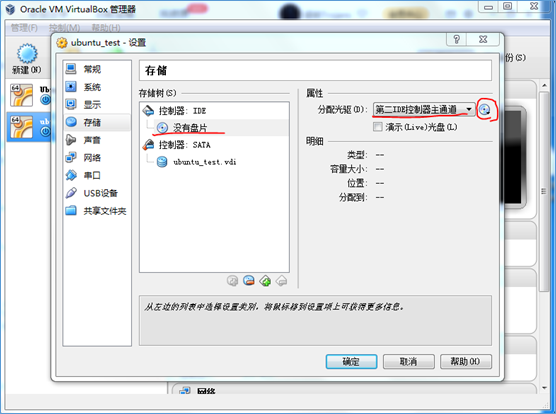
(2)选择 没有光盘—>第二IDE控制器主通道—>选择一个虚拟光盘文件,即 01 ubuntukylin-16.04-desktop-amd64.iso 镜像文件
(3)启动
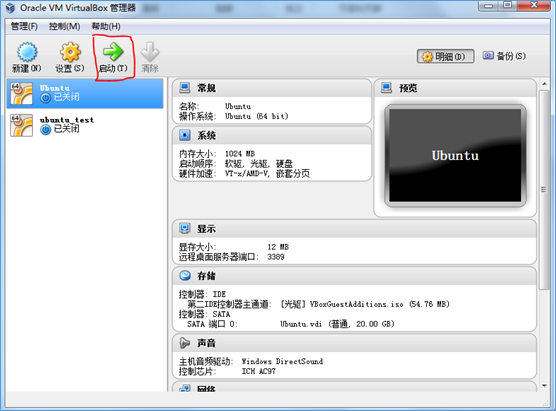
(4)安装Ubuntu
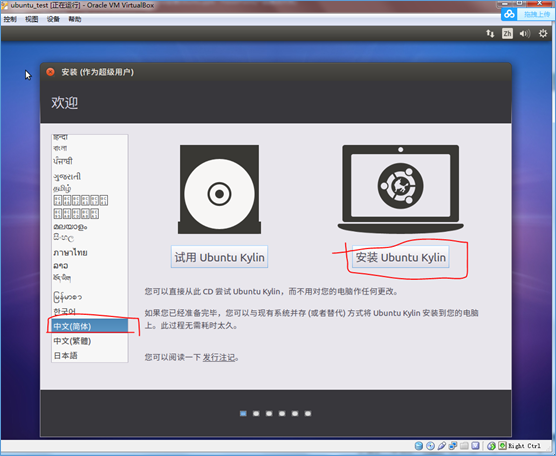
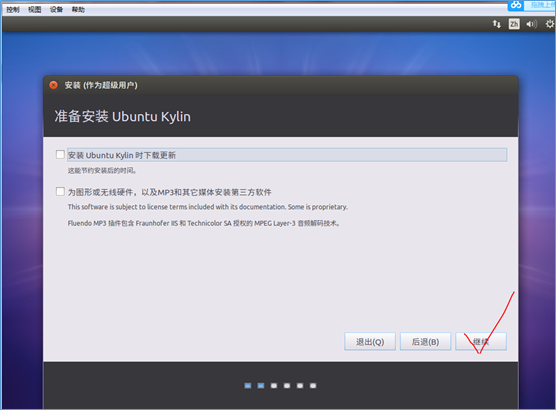
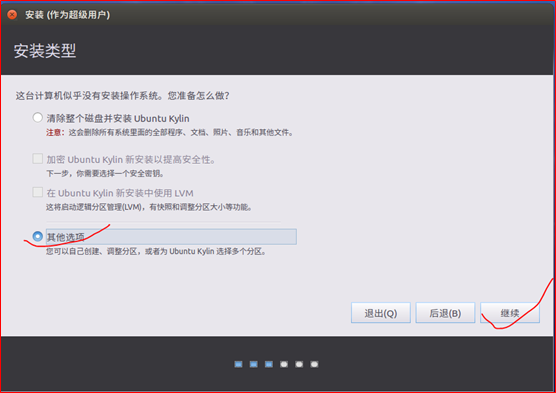
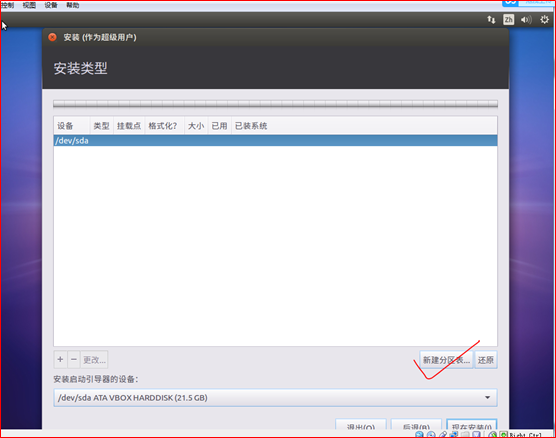
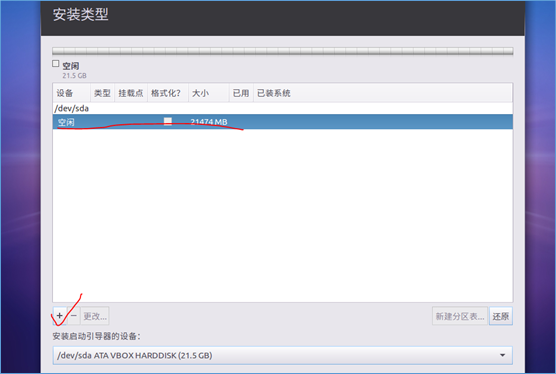
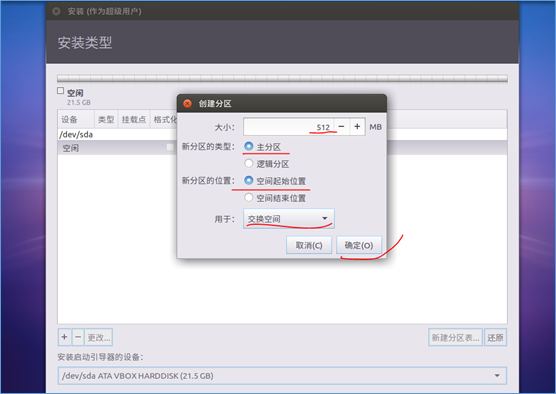
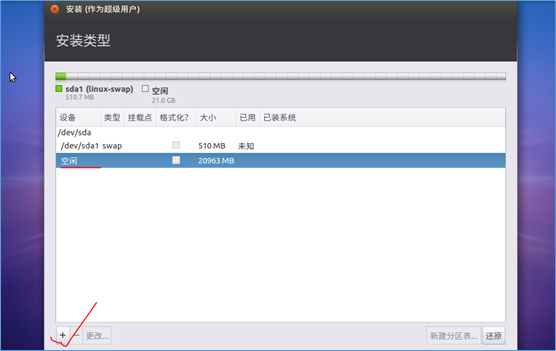

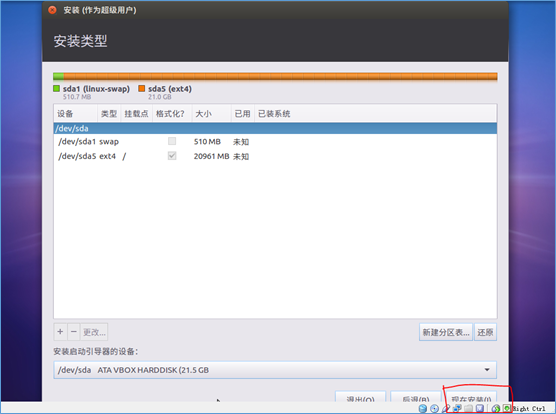
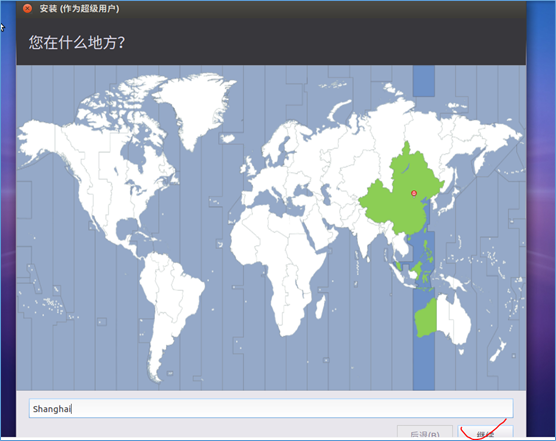
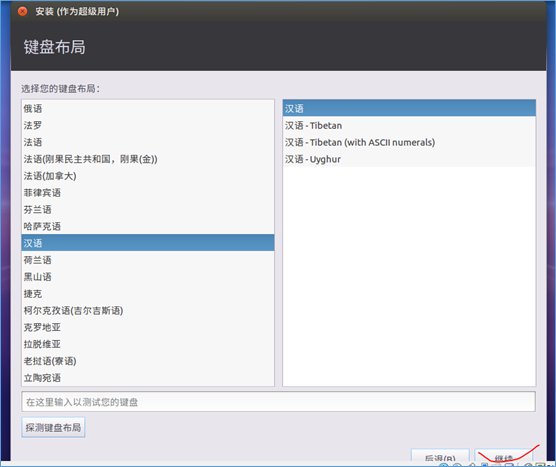
(5)设置登陆时的用户名和密码:

(6)不要点击跳过
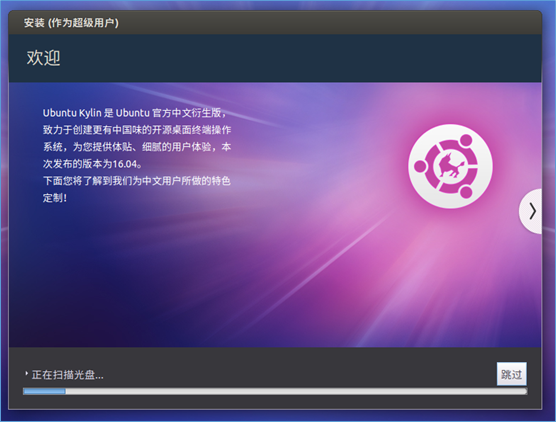
(7)登陆

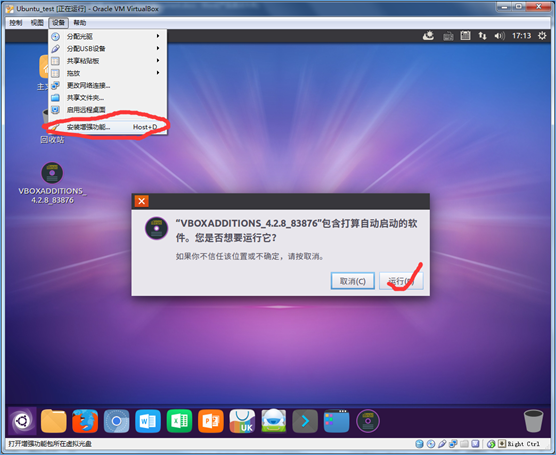
(8)安装增强功能
(三)安装MySql
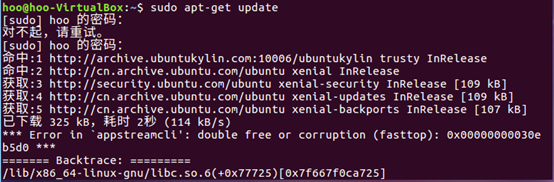
1.更新apt
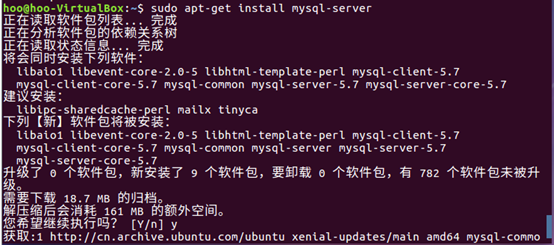
2.安装mysql-server
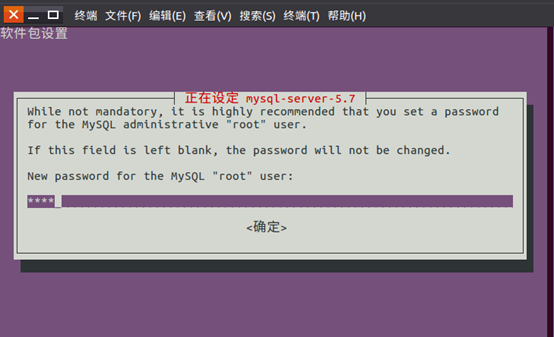
3.设置MySql用户root的密码,如root
4.启动MySql服务,需要输入用户登陆密码给予授权
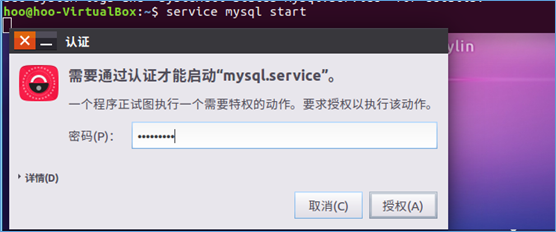
5.关闭MySql服务,同样需要输入用户登陆密码给予授权
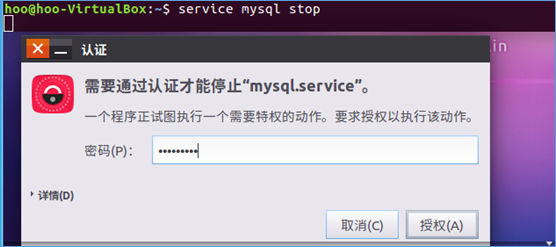
6.确认是否登陆成功,MySql节点处于LISTEN状态表示启动成功呢

7.进入MySql shell界面,需要输入MySql登陆密码root
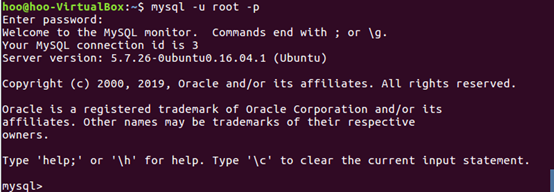
8.显示数据库
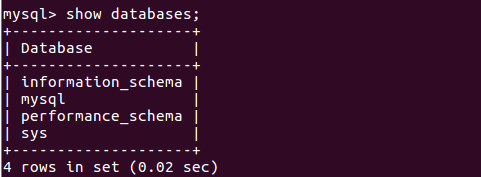
9.显示数据库中的表

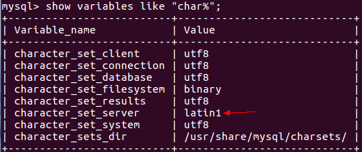
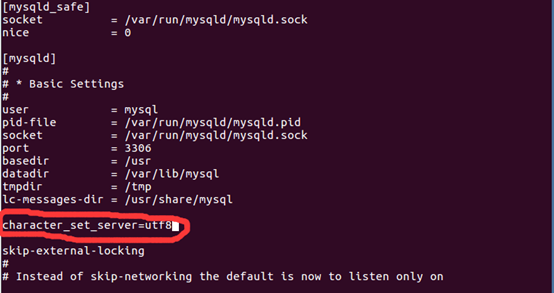
10.编辑配置文件防止导入时中文乱码,配置文件内容添加 character_set_server=utf8

11.重启MySql服务
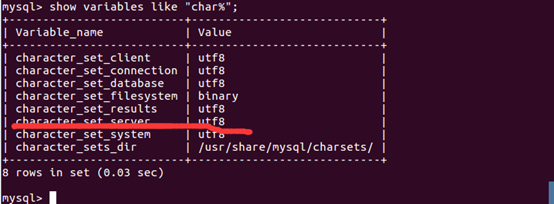
12.查看修改结果
二、windows 与 虚拟机互传文件
参考网址:https://www.cnblogs.com/dong-blog/p/7207831.html
(一)在windows本机新建一个共享文件夹并命名为 s,这是一个用于与Ubuntu交互的文件夹
(二)在Ubuntu中,点击左上角的设备,点击共享文件夹,选择添加共享文件夹,选择其他,选择在windows本机创建的共享文件夹 s,选择固定分配(一定不要选择自动挂载)

(三)在Ubuntu中,打开终端,创建 share 作为文件共享文件夹

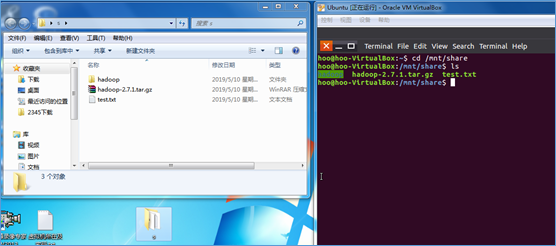
(四)将windows本机的 s 文件挂载到Ubuntu的 /mnt/share 挂载点

(五)在windows把需要的文件放进 s 文件夹里,到 Ubuntu 查看共享文件是否共享成功
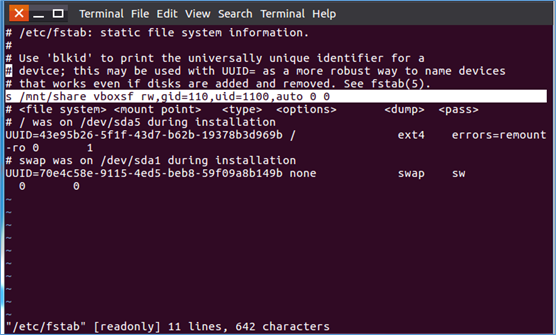
(六)在共享目录下使用命令:vi /etc/fstab,在文本中添加一行命令:s /mnt/share vboxsf rw,gid=110,uid=110,auto 0 0,设置成自动挂载,确保重启虚拟机后系统共享仍在

(七)编辑文本,然后保存退出
三、安装Hadoop
(一)创建Hadoop用户
1.创建hadoo用户

2.为Hadoop用户设置密码

3.为Hadoop用户添加管理员权限

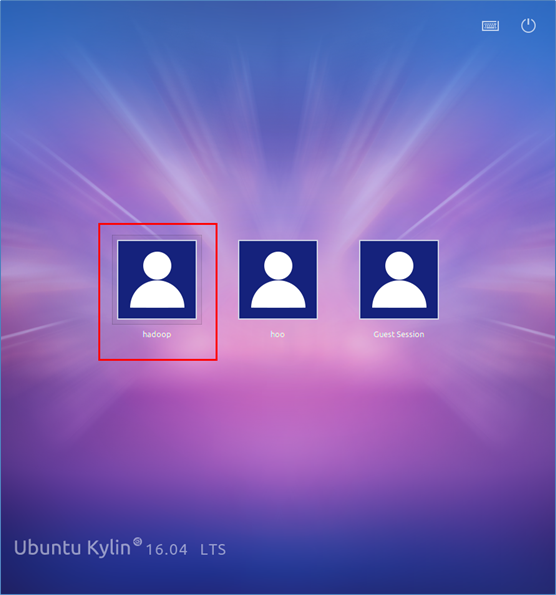
4.登陆Hadoop用户
(二)实现无密码登录
1.打开终端,使用命令:sudo apt-get update 更新apt,不更新apt可能某些软件安装不了

2.集群、单节点模式都需要用到SSH登陆(类似于远程登陆),Ubuntu默认安装了SSH client,另外还需要安装SSH server

3.安装SSH server 后,可使用ssh localhost命令登录,exit命令退出
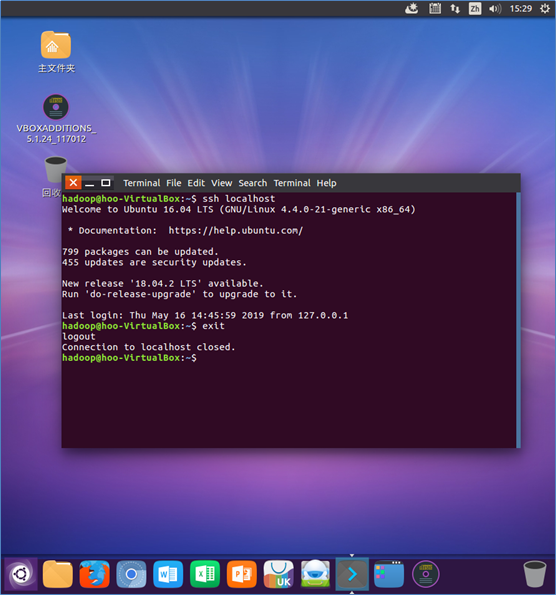 4.使用命令cd ~/.ssh/,若没有该目录,请先执行一次 ssh localhost 命令,然后exit
4.使用命令cd ~/.ssh/,若没有该目录,请先执行一次 ssh localhost 命令,然后exit

5.利用 ssh-keygen 生成秘钥,并将秘钥加入授权
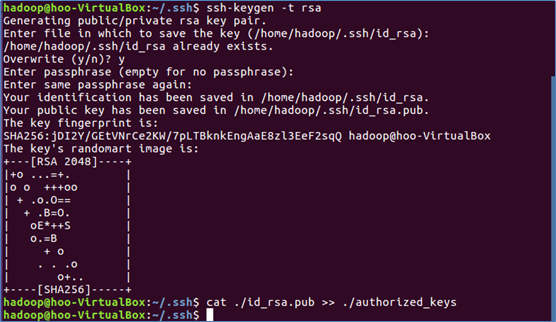
6.再用ssh localhost 命令,就可以实现无密登陆了:

7.使用 ps -e |grep ssh 查看是否安装成功:

(三)配置java环境
1.安装Java环境(需要联网)

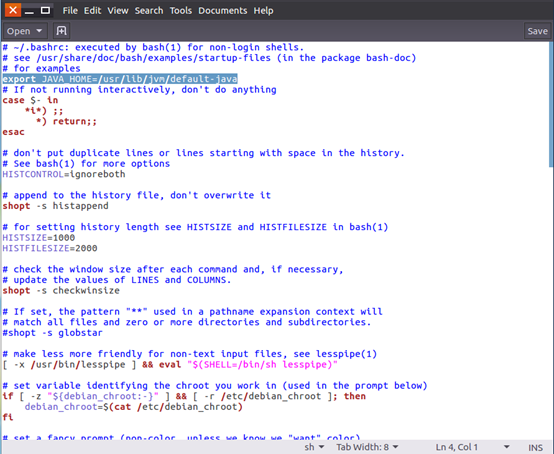
2.使用命令 gedit ~/.bashrc 配置环境变量文件.bashrc

3.配置Java的环境变量,在文件最前面或最后面添加如下一行(等号前后不能有空格),然后保存退出
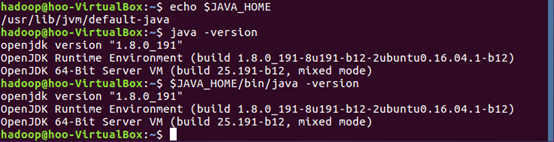
4.使用 source ~/.bashrc 命令使环境变量生效:

5.使用一下命令检查是否配置是否正确:
(四)安装Hadoop
下载 hadoop-2.7.1.tar 压缩文件:https://pan.baidu.com/s/1gRhbNRwOoOtHFHg5YiHQPg fg8w
1.将 hadoop-2.7.1.tar 压缩文件解压并重命名为hadoop,然后放到windows的 s 共享文件中,在Ubuntu的shell中使用命令 sudo cp /mnt/share/hadoop /usr/local 将hadoop文件复制到 /usr/local 目录下

2.查看文件是否复制成功

3.修改文件权限

4.查看修改结果
5.检查Hadoop是否可用
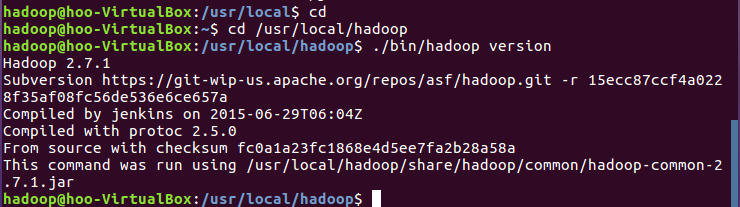
(五)运行Hadoop单机模式的例子
1.创建输入文件

2.将配置文件作为输入文件

3.运行grep例子
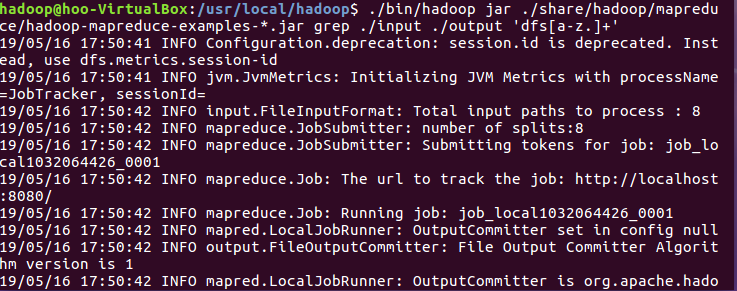
4.查看实例运行结果

5.Hadoop默认不会覆盖结果文件,再次运行上面实例会提示错误,需要现将 ./output 删除

(六)Hadoop伪分布式配置
下载Hadoop伪分布式配置文件的主要内容:https://pan.baidu.com/s/1YB3fjT4XZbhbjHWUzm0rsw ,u3mz
1.Hadoop配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改配置文件有 core-site.xml 和 hdfs-site.xml 。
(1)修改配置文件 core-site.xml :

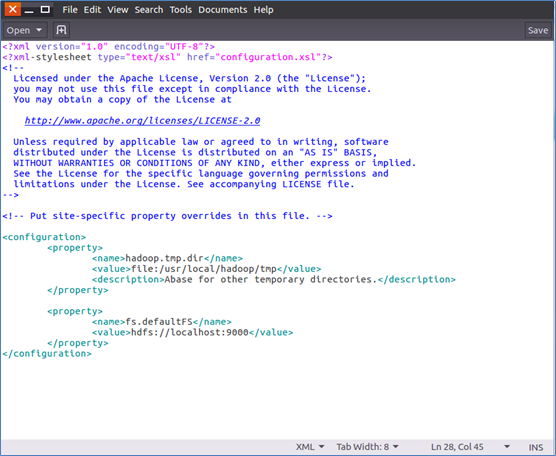
(2)修改配置文件 hdfs-site.xml :

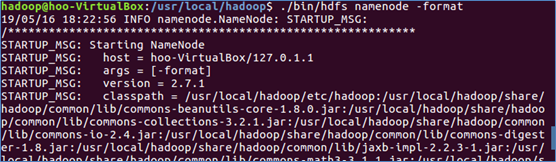
2.文件配置完成后,执行NameNode格式化
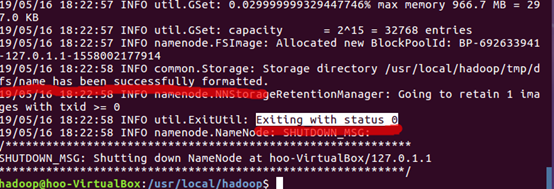
3.成功会有以下提示
4.开启NameNode和DataNode的守护进程

5.若出现SSH提示,输入yes即可

6.通过jps命令来判断是否启动成功(若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”,如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。)。如果DataNode无法启动,先删除hadoop.tmp.dir(路径为 /usr/local/hadoop/tmp目录, 再执行hadoop namenode -format

7.运行Hadoop伪分布式实例
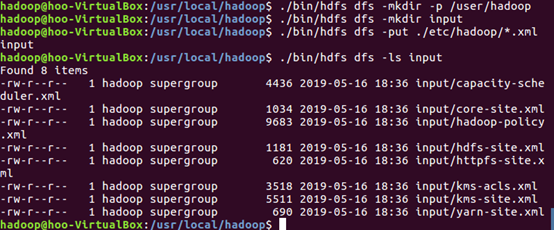
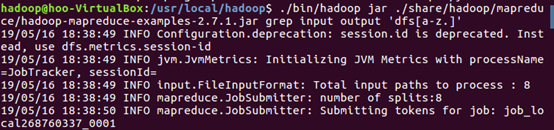
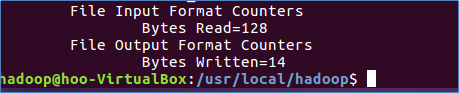
8.查看位于HDFS中的输出结果

9.将结果取回本地
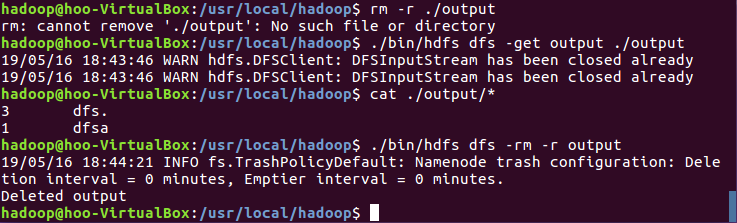
10.关闭Hadoop


11.再次启动Hadoop时,无需再对NameNode进行初始化,只要运行 ./sbin/start-dfs.sh 开启 NameNode 和 DataNode 守护进程即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号