爬虫综合大作业
一、把爬取的校园新闻内容保存到数据库
(一)保存到sqlite3
1 # 保存到sqlite3数据库 2 def save_in_sqlite(): 3 news_df = save_file() 4 with sqlite3.connect('gzccnewsdb.sqlite')as db: 5 news_df.to_sql('gzccnews', con=db) 6 df2 = pd.read_sql_query('select * from gzccnews', con=db) 7 print(df2) 8 return
(二)保存到MySQL数据库
1 # 保存到MySQL数据库 2 def save_in_mysql(): 3 coninfo = 'mysql+pymysql://root:155651@localhost:3306/gzccnews?charset=utf8' 4 engine = create_engine(coninfo) 5 df = pd.read_csv(r'f:news.csv') 6 df.to_sql(name='news', con=engine, if_exists='append', index=False, index_label=False) 7 return
二、爬虫综合大作业
爬取2019年中国各省份地区人口数量:http://www.chamiji.com/2019chinaprovincepopulation
(一)设置合理的User-Agent、Cookie和proxies
导入fake_useragent库来随机获取User-Agent,在爬取的网页中获取对应的Cookie,网上搜索免费可用的代理IP。
1 headers = { 2 'User-Agent': UserAgent().random, 3 'Cookie': 'Hm_lvt_698c91320a52b33ef4dc3d5e0325a2c5=1557403230,1557404018,1557635503,1557635778;' 4 ' Hm_lpvt_698c91320a52b33ef4dc3d5e0325a2c5=1557635798' 5 } 6 ip_list = ['183.30.204.180:9999', '163.204.243.52:9999', '163.204.240.35:9999'] 7 proxies = { 8 "http": '183.30.204.180:9999', 9 "https": '183.30.204.180:9999' 10 }
获取Cookie:点击鼠标右键—>检查—>Network—>Doc—>Ctrl + R—>Headers—>得到Cookie
(二)设置合理爬取时间间隔
1 # 设置合理的爬取时间间隔 2 def sleep(): 3 time.sleep(random.random() * 3) 4 return
(三)获取中国各省人口数量的数据
导入可以处理数据的Beautifulsoup库,模拟浏览器向服务器发送请求,获取html数据并对获取的数据进行处理,得到中国各省份地区的人口数量的数据
1 def get_census_data(): 2 sleep() 3 url = 'http://www.chamiji.com/2019chinaprovincepopulation' 4 res = requests.get(url, headers=headers) 5 res.encoding = 'utf-8' 6 soup = BeautifulSoup(res.content, 'html.parser') 7 data = [] 8 9 for i in soup.select('.article-content')[0].select('tbody')[0].select('tr'): 10 province = i.select('td')[1].text 11 temp = i.select('td')[2].text 12 population = temp.replace('\xa0', '') 13 if '.' in list(population) and '万' in list(population): 14 float_num = str(re.findall("(\\..*)", population)[0]) 15 if len(float_num) - 2 == 2: 16 population = population.replace('.', '').replace('万', '00') 17 if len(float_num) - 2 == 1: 18 population = population.replace('.', '').replace('万', '000') 19 if '万' in list(population): 20 population = population.replace('万', '0000') 21 data.append([province, population]) 22 data.pop(0) 23 data.pop(0) 24 return data
(四)保存爬取到的数据,生成CSV文件
1 # 保存成.csv文件 2 def save_file(): 3 data_df = pd.DataFrame(get_census_data(), columns=('地区', '人口数')) 4 data_df.to_csv(r'f:/Python/census.csv', index=0) # 去除索引列,并生成csv文件保存到f:/Python 5 return
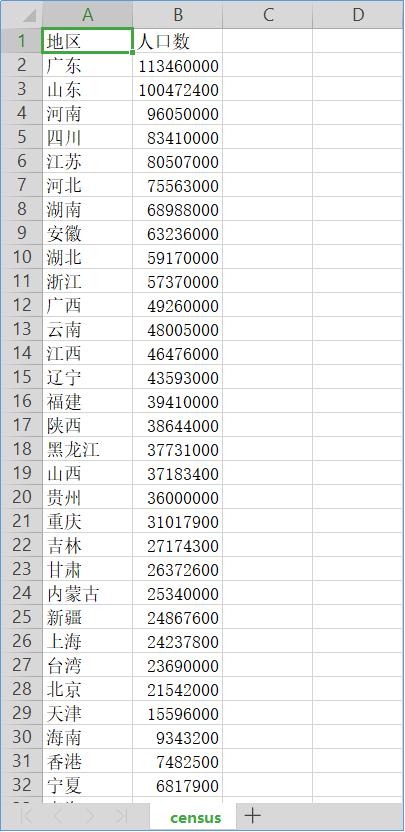
由2019年中国各省地区人口数据生成的CSV文件:
(五)将数据保存到MySQL数据库
1 # 将各省人口数据保存到MySQL数据库 2 def save_in_mysql(df): 3 coninfo = 'mysql+pymysql://root:155651@localhost:3306/censusdb?charset=utf8' 4 engine = create_engine(coninfo) 5 df.to_sql(name='census', con=engine, if_exists='append', index=False, index_label=False) 6 return
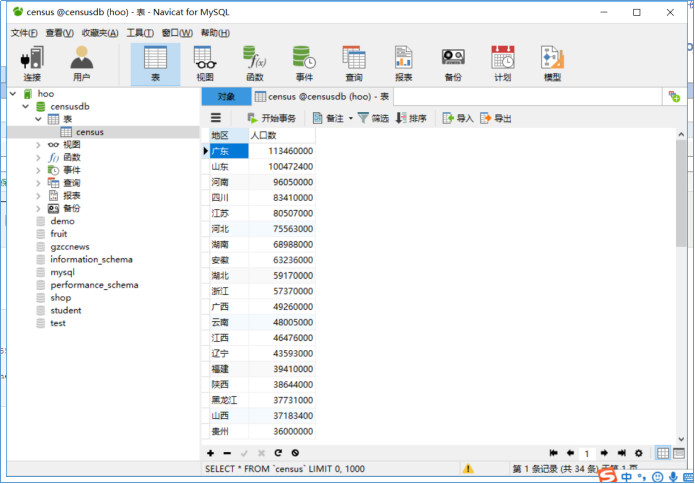
保存到数据库:
(六)将获取的数据生成词云
导入WordCloud库,把中国各省份地区人口数量最多的前15名省份地区生成词云:
1 def generate_word_cloud(census_list): 2 census_list.sort(key=lambda x: x[1], reverse=True) # 根据值进行排序 3 list = pd.DataFrame(data=census_list[0:15]).values.tolist() 4 mywc = WordCloud(font_path="C:/Windows/Fonts/msyh.ttc", background_color='black', margin=2, width=1800, height=800, 5 random_state=42).generate(str(list)) 6 plt.imshow(mywc, interpolation='bilinear') 7 plt.axis("off") 8 plt.tight_layout() 9 mywc.to_file('population.png') # 生成词云图片 10 plt.show() 11 return
人口数量最多的前15名省份地区生成的词云:

(七)把各省份地区的人口数量以热力图的方式显示
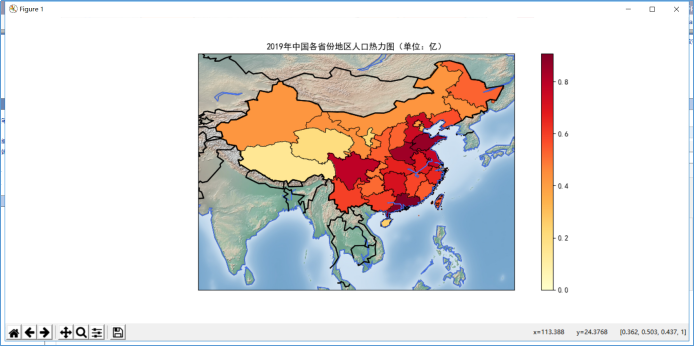
绘制中国地图前先引入相应的库(如matplotlib、Basemap等),定义地图的大小,描绘海岸线,指定经纬度绘制中国地图,读取中国地图的shape文件(其中没有台湾的shape文件,需要另外读取,pyecharts不需要),台湾是中国不可或缺的一部分,读取台湾的shape文件,然后就是为地图上色,这里是根据各省地区人口数量来为各省地区上色的,人数越多,颜色越深。
1 def china_map(df): 2 fig = plt.figure(figsize=(16, 8)) 3 ax1 = fig.add_subplot(1, 1, 1) 4 ax1.set_title("2019年中国各省份地区人口热力图(单位:亿)") 5 mpl.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文字体 6 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 7 map = Basemap( 8 llcrnrlon=70, 9 llcrnrlat=5, 10 urcrnrlon=137, 11 urcrnrlat=55 12 ) 13 map.drawcoastlines() 14 map.drawcountries(linewidth=1.5) 15 map.shadedrelief() 16 17 map.readshapefile(r'f:/Python/gadm36_CHN_shp/gadm36_CHN_1', 'states', drawbounds=True) # 获取中国省份地区的shape 18 df['省名'] = df.地区.str[:2] 19 df.set_index('省名', inplace=True) 20 state_names = [] 21 cmap = plt.cm.YlOrRd 22 vmax = 110000000 23 vmin = 500000 24 for shapedict in map.states_info: 25 state_name = shapedict['NL_NAME_1'] 26 p = state_name.split('|') 27 if len(p) > 1: 28 s = p[1] 29 else: 30 s = p[0] 31 s = s[:2] 32 if s == '黑龍': 33 s = "黑龙" 34 state_names.append(s) 35 pop = df['人口数'][s] 36 # 映射颜色 37 colors[s] = cmap(np.sqrt((pop - vmin) / (vmax - vmin)))[:3] 38 ax = plt.gca() 39 40 # 循环各省,为各省描色 41 for nshape, seg in enumerate(map.states): 42 color = rgb2hex(colors[state_names[nshape]]) # rgb与hex互换 43 poly = Polygon(seg, facecolor=color, edgecolor=color) 44 patches.append(poly) 45 ax.add_patch(poly) 46 47 # 为地图添加台湾的shape 48 map.readshapefile(r'f:/Python/gadm36_TWN_shp/gadm36_TWN_1', 'taiwan', drawbounds=True) 49 for nshape, seg in enumerate(map.taiwan): 50 color = rgb2hex(colors[state_names[nshape]]) 51 poly = Polygon(seg, facecolor=color, edgecolor=color) 52 patches.append(poly) 53 ax.add_patch(poly) 54 55 # 添加渐变色条 56 color_bar = [i[1] for i in colors.values()] 57 color_votes = plt.cm.YlOrRd 58 p = PatchCollection(patches, cmap=color_votes) 59 p.set_array(np.array(color_bar)) 60 pylab.colorbar(p) 61 62 map.drawcoastlines(color='#4876FF') # 绘制海岸线 63 map.drawcountries(linewidth=1.5) # 绘制国界 64 plt.savefig(r'f:/Python/heat_map.png') # 保存地图 65 plt.show() # 显示地图 66 return
2019年中国各省份地区的人口热力图:
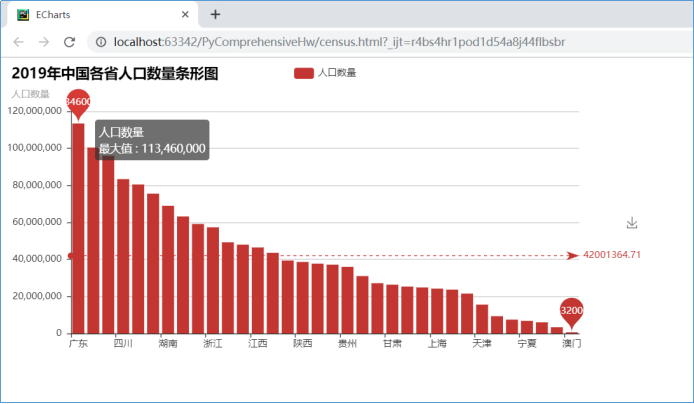
(八)柱形图方式显示数据
导入pyecharts库,导入Bar,以柱形图方式显示各省人口数量,标出最多、最少人口的省份地区
1 # 生成人口数量柱形图 2 def generate_bar(list): 3 data = [] 4 columns = [] 5 for i in list: 6 columns.append(i[0]) 7 data.append(i[1]) 8 bar = Bar('2019年中国各省人口数量条形图', '人口数量', ) 9 bar.add('人口数量', columns, data, mark_line=['average'], mark_point=['max', 'min']) 10 bar.render('census.html') 11 return
2019年各省地区人口数量柱形图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号