爬取全部的校园新闻
一、从新闻url获取点击次数,获取新闻发布时间及类型转换,并整理成函数
- 获取新闻URL点击次数
1 # 获取新闻点击次数 2 def get_click_num(arg_news_url): 3 click_id = re.findall("(\\d{1,5})", arg_news_url)[-1] # findall函数返回正则表达式在字符串中匹配的结果列表 4 click_url = "http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80".format(click_id) 5 response = requests.get(click_url) 6 news_click_num = int(response.text.split('.html')[-1].lstrip("('").rstrip("');")) # lstrip,rstrip函数分别去除相应匹配的头,尾字符 7 return news_click_num
- 获取新闻发布时间及类型转换
1 # 获取新闻发布时间及类型转换 2 def get_news_date(showinfo): 3 news_date = showinfo.split()[0].split(':')[1] 4 news_time = showinfo.split()[1] 5 news_dt = news_date + " " + news_time 6 dt = datetime.strptime(news_dt, "%Y-%m-%d %H:%M:%S") 7 return dt
二、从新闻url获取新闻详情
1 # 获取相应URL的新闻标题,调用获取新闻发布时间、新闻的点击次数的函数 2 def get_news_detail(arg_news_url): 3 news_detail = {} 4 response = requests.get(arg_news_url) 5 response.encoding = 'utf-8' 6 soup = BeautifulSoup(response.text, 'html.parser') 7 news_detail['NewsTitle'] = soup.select('.show-title')[0].text 8 showinfo = soup.select('.show-info')[0].text 9 news_detail['NewsDateTime'] = get_news_date(showinfo) 10 news_detail['NewsClickNum'] = get_click_num(arg_news_url) 11 return news_detail
三、从列表页的url获取新闻url
1 # 获取22~32页所有新闻的详情信息并形成列表 2 def get_news_list(): 3 news_list = [] 4 page_urls = get_page_urls() 5 for page_url in page_urls: 6 sleep() 7 response = requests.get(page_url) 8 response.encoding = 'utf-8' 9 soup = BeautifulSoup(response.text, 'html.parser') 10 for news in soup.select('li'): 11 if len(news.select('.news-list-title')) > 0: 12 news_url = news.select('a')[0]['href'] # 链接 13 news_desc = news.select('.news-list-description')[0].text # 描述 14 news_dict = get_news_detail(news_url) 15 news_dict['NewsUrl'] = news_url 16 news_dict['Description'] = news_desc 17 news_list.append(news_dict) 18 return news_list
四、获取所有页的URL,再用页的url并获取全部新闻
1 # 获取校园新闻第22~32页的URL,并存到列表里 2 def get_page_urls(): 3 page_urls = [] 4 for i in range(22, 32): 5 page_url = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) 6 page_urls.append(page_url) 7 return page_urls
五、设置合理的爬取间隔
1 def sleep(): 2 time.sleep(random.random() * 3) 3 return
六、用pandas做简单的数据处理并保存
1 def save_file(): 2 news_df = pd.DataFrame(get_news_list()) 3 print(news_df) 4 news_df.to_csv(r'f:news.csv') # 生成csv文件保存到f盘 5 return
七、运行效果
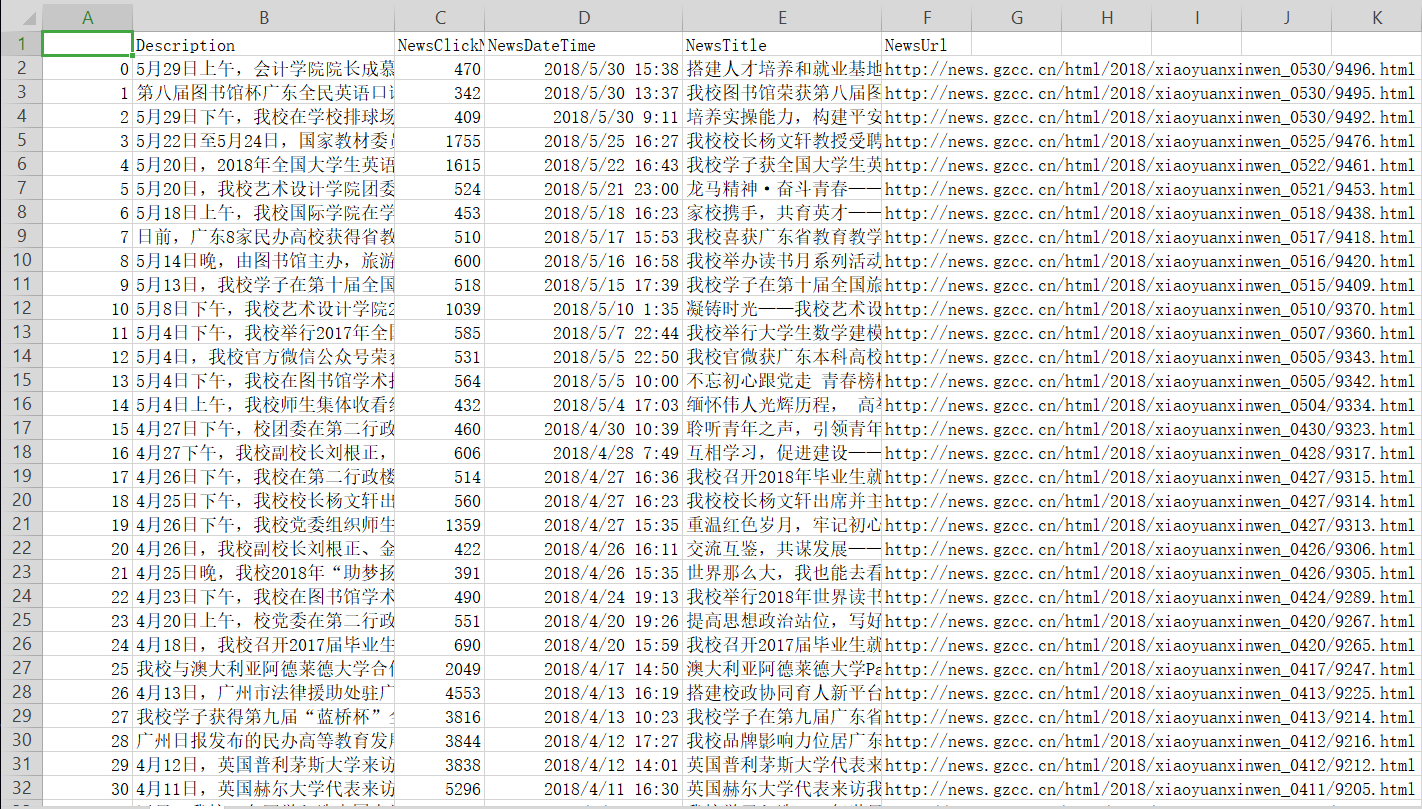 |
八、完整源码


1 import re 2 import time 3 import random 4 import requests 5 import pandas as pd 6 from bs4 import BeautifulSoup 7 from datetime import datetime 8 9 10 # 获取新闻点击次数 11 def get_click_num(arg_news_url): 12 click_id = re.findall("(\\d{1,5})", arg_news_url)[-1] # findall函数返回正则表达式在字符串中匹配的结果列表 13 click_url = "http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80".format(click_id) 14 response = requests.get(click_url) 15 news_click_num = int(response.text.split('.html')[-1].lstrip("('").rstrip("');")) # lstrip,rstrip函数分别去除相应匹配的头,尾字符 16 return news_click_num 17 18 19 # 获取新闻发布时间及类型转换 20 def get_news_date(showinfo): 21 news_date = showinfo.split()[0].split(':')[1] 22 news_time = showinfo.split()[1] 23 news_dt = news_date + " " + news_time 24 dt = datetime.strptime(news_dt, "%Y-%m-%d %H:%M:%S") 25 return dt 26 27 28 # 获取相应URL的新闻标题,调用获取新闻发布时间、新闻的点击次数的函数 29 def get_news_detail(arg_news_url): 30 news_detail = {} 31 response = requests.get(arg_news_url) 32 response.encoding = 'utf-8' 33 soup = BeautifulSoup(response.text, 'html.parser') 34 news_detail['NewsTitle'] = soup.select('.show-title')[0].text 35 showinfo = soup.select('.show-info')[0].text 36 news_detail['NewsDateTime'] = get_news_date(showinfo) 37 news_detail['NewsClickNum'] = get_click_num(arg_news_url) 38 return news_detail 39 40 41 # 获取校园新闻第22~32页的URL,并存到列表里 42 def get_page_urls(): 43 page_urls = [] 44 for i in range(22, 32): 45 page_url = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) 46 page_urls.append(page_url) 47 return page_urls 48 49 50 # 获取22~32页所有新闻的详情信息并形成列表 51 def get_news_list(): 52 news_list = [] 53 page_urls = get_page_urls() 54 for page_url in page_urls: 55 sleep() 56 response = requests.get(page_url) 57 response.encoding = 'utf-8' 58 soup = BeautifulSoup(response.text, 'html.parser') 59 for news in soup.select('li'): 60 if len(news.select('.news-list-title')) > 0: 61 news_url = news.select('a')[0]['href'] # 链接 62 news_desc = news.select('.news-list-description')[0].text # 描述 63 news_dict = get_news_detail(news_url) 64 news_dict['NewsUrl'] = news_url 65 news_dict['Description'] = news_desc 66 news_list.append(news_dict) 67 return news_list 68 69 70 def sleep(): 71 time.sleep(random.random() * 3) 72 return 73 74 75 def save_file(): 76 news_df = pd.DataFrame(get_news_list()) 77 print(news_df) 78 news_df.to_csv(r'f:news.csv') # 生成csv文件保存到f盘 79 return 80 81 82 save_file()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号