复合数据类型,英文词频统计
一、列表,元组,字典,集合的增、删、改、查以及遍历。
1.列表


1 pi = ['3', '.', '1', '4', '1', '5', '9', '2', '6', '5', '3', '5'] # 初始化 pi 列表 2 add = ['7', '9'] # 初始化 add 列表 3 4 # 增 5 pi.insert(12, '8') # 在列表索引号为12的位置增加元素'8' 6 pi.append('9') # 在列表末尾添加新元素‘9’ 7 pi.extend(add) # 在pi列表的末尾添加add列表里的元素 8 9 # 删 10 del pi[14:16] # 删除列表索引值为15、16的元素 11 pi.remove('8') # 删除列表中第一个与元素 '8' 相同的元素 12 pi.pop() # 删除列表最后一个元素 13 del pi[10] # 删除列表索引号为 10 的元素'5' 14 15 # 改 16 pi[10] = '3' # 把列表索引号为 10 的元素修改成 '3' 17 18 # 查 19 print(pi[10]) # 查询列表索引号为 10 的元素的值 20 21 # 遍历 22 for word in pi: # 遍历 pi 列表的所有元素 23 print(word)
2.元祖
1 pi = ('3', '.', '1', '4', '1', '5', '9', '2', '6', '5', '3', '5') # 初始化 pi 元组 2 add = ('8', '9') # 初始化 add 元组 3 4 # 增 5 pi = pi + add # 元组不可以添加元素,但可以拼接元组 6 print(pi) 7 8 # 删 9 del pi # 不能删除元组里的元素,但可以删除整个元组 10 11 # 改 12 pi = pi[0:3] # 不可以改变元组的元素,但可以通过截取元组的片段来组成新的元组 13 add = add[0:1] 14 pi = pi + add 15 16 # 查 17 print(pi[2]) # 查询元组索引号为 2 的元素的值 18 19 # 遍历 20 for word in pi: # 遍历 pi 元组的所有元素 21 print(word)
3.字典
1 province = {'11': '北京市', '12': '天津市', '13': '河北省', '14': '山西省'} # 初始化 province 字典 2 add = {'44': '广东省', '45': '广西壮族自治区', '46': '海南省'} # 初始化 add 字典 3 4 # 增 5 province['53'] = '云南省' # 通过给新的键值名赋值来添加新的键值对 6 province.update(add) # 把add字典的键值对添加到province字典中 7 8 # 删 9 del province['13'] # 通过删除key(键值名)来删除字典的键值对 10 # del province # 删除整个字典 11 province.pop('14') # 通过删除key(键值名)来删除字典的键值对 12 13 # 改 14 province['53'] = '53' # 将key为 '53' 的值改为 '53' 15 16 # 查 17 print(province['12']) # 查询key为‘12’的值 18 province.keys() # 查询字典所有的key,以列表返回 19 province.values() # 查询字典所有的value,以列表返回 20 province.items() # 查询字典所有的键值对,以列表返回 21 22 # 遍历 23 for key in province: # 遍历 pi 字典的所有key 24 print(key)
4.集合
1 pi = {'3', '.', '1', '4', '1', '5', '9', '2', '6', '5', '3', '5'} # 初始化 pi 集合 2 add = {'8', '9', '7', '9'} # 初始化 add 集合 3 4 # 增 5 pi.add('8') # 给 pi 集合添加元素 '8',若集合已存在该元素则不添加 6 print(pi) 7 8 # 删 9 pi.clear() # 删除pi集合的所有元素 10 pi.difference_update(add) # 删除pi、add两个集合都存在的元素 11 pi.discard('.') # 删除元素'.',无论集合存不存在元素'.',编译器都不会报错 12 pi.remove('.') # 删除元素'.',若集合不存在元素'.',则编译器会报错 13 pi.pop() # 随机删除集合的一个元素 14 print(pi) 15 16 # 改 17 pi.update(add) # 添加新元素或集合到当前集合中,集合元素不重复 18 19 # 查 20 print('1' in pi) # 查询集合是否存在元素'1' 21 22 # 遍历 23 for word in pi: # 遍历 pi 集合的所有元素 24 print(word) 25 26 # 求并集 27 pi.union(pi, add) # 求两集合的并集
二、列表,元组,字典,集合的联系与区别。
| 括号 | 有序无序 | 可变不可变 | 可重复不可重复 | 存储与查找方式 | |
| 列表(list) | [ ] | 有序 | 可变 | 可重复 | 值的方式存储,索引查找 |
| 元组(tuple) | ( ) | 有序 | 不可变 | 可重复 | 值的方式存储, 索引查找 |
| 字典(dict) | { } | 无序 | (key)不可变 | 不可重复 | 键值对方式存储,key查找 |
| 集合(set) | { } | 无序 | 不可变 | 不可重复 | 键方式存储,key查找 |
三、词频统计
- 下载一长篇小说,存成utf-8编码的文本文件 file
- 通过文件读取字符串 str
- 对文本进行预处理
- 分解提取单词 list
- 单词计数字典 set , dict
- 按词频排序 list.sort(key=lambda),turple
- 排除语法型词汇,代词、冠词、连词等无语义词,自定义停用词或用stops.txt输出TOP(20)
- 可视化:词云,排序好的单词列表word保存成csv文件
- 线上工具生成词云:
1 from nltk.corpus import stopwords 2 import nltk 3 import pandas as pd 4 nltk.download("stopwords") 5 6 7 # 读取歌词文本 8 def read_text(): 9 text = open("C:The_three_body.txt", "r", encoding="UTF-8-sig").read().lower() 10 print(text) 11 print("\n") 12 return text 13 14 15 # 修改格式 16 def modify_text(): 17 changes = {',', '.', 'don\'t', '\n', 'i\'ve'} 18 text = read_text() 19 for change in changes: 20 if change == 'don\'t': 21 text = text.replace(change, 'do not') 22 elif change == 'I\'ve': 23 text = text.replace(change, 'I have') 24 else: 25 text = text.replace(change, ' ') 26 return text 27 28 29 # 计数、排序 30 def count_sort(): 31 exclude = {'”', 'one', 'two', 'three', 'like', 'ye', '“you’ re', 'wouldn’t', '“that', '“do', 32 '“there’s', 'coast’s', '“now', 'pan’s', 'would', 'said','even', 'red', 'could', 'shi', 33 'know', 'also', 'first', '*', 'long', 'wang', 'saw', 'it’s', 'turned', '…', 'many', 34 '“i', 'don’t', '“if', 'we’re', '“of', 'go','wasn’t', 'us', 'take','made','came', 35 'want','tell','four','get','went','later','half','new','couldn’t','didn’t','yang', 36 'coast','still','see','asked','though','back','day','years','already','much','around', 37 'another','took','away','never','must','seemed','way','right','“what','i’m','thought', 38 'people','great','work','you’re','come','got','that’s','told','last','make','research', 39 'every','“you','“it’s','filled','anything','nothing','began','da','without','man', 40 'woman','really','looked','left','“the','next','soon','think','became','night','large', 41 'light','look','within','finally','someone','use','eyes','body'} # 自定义停用词 42 string = modify_text() # 获取修改后的字符串 43 word_list = string.split() # 分割单词形成列表 44 stops = stopwords.words("english") # 获取 nltk 英文停用词 45 word_set = set(word_list) - set(stops) - exclude # 列表转成集合,去掉停用词集合 46 word_dict = {} # 初始化字典 47 for word in word_set: # 计算词频 48 word_dict[word] = word_list.count(word) 49 word_sort = list(word_dict.items()) # 将字典转变成可排序的列表 50 word_sort.sort(key=lambda x: x[1], reverse=True) # 排序 51 print(word_sort) 52 return word_sort 53 54 55 # 生成CSV文件 56 def generate_csv(): 57 word_csv = count_sort() 58 pd.DataFrame(data=word_csv[0:20]).to_csv('The_three_body.csv', encoding='UTF-8') 59 return 60 61 62 generate_csv()
获取前20单词:
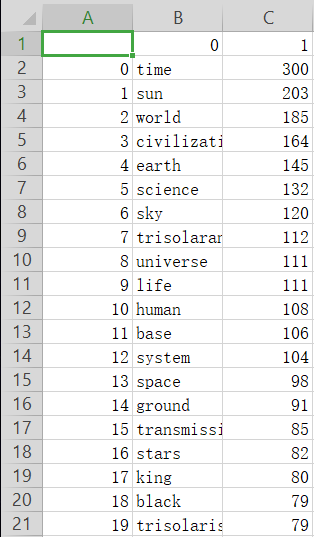
三体小说(英文版)词云生成效


 浙公网安备 33010602011771号
浙公网安备 33010602011771号