Python re正则表达式速查

* 文末 re 模块速查表
1. 特殊符号和字符
| . | 任意一个字符 |
| .. | 任意两个字符 |
| .end | end 之前的任意一个字符 |
| f.o | 匹配 f 和 o 之间的任意字符;如 fao、f9o、f#o |
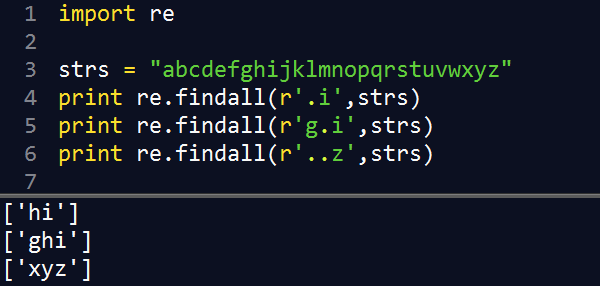
|
| |
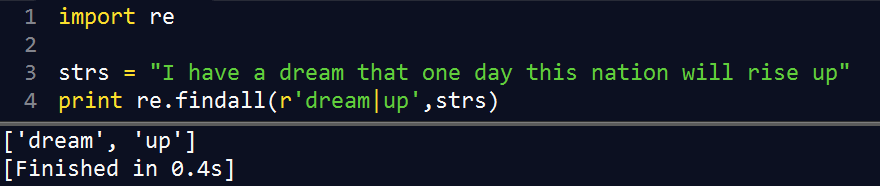
择一匹配的管道符号 <=> [] |
|
at|home |
匹配 at、home |
|
* |
匹配 0 次或多次前面出现的正则表达式 |
|
+ |
匹配 1 次或多次 |
|
? |
匹配 0 次或 1 次 |
|
^ |
匹配字符串起始部分 |
|
$ |
匹配字符串终止部分 |
|
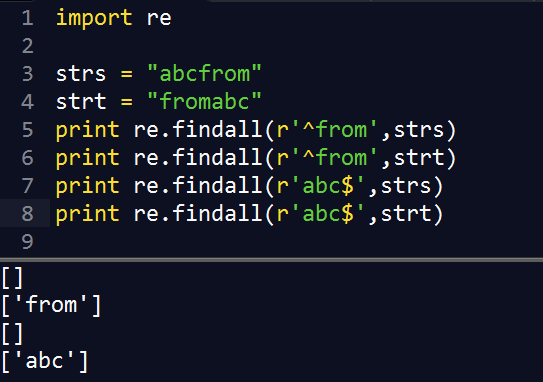
^From |
任何以 From 起始的字符串 |
|
From$ |
任何以 From 结尾的字符串 |
|
^subject:hh$ |
任何由单独的字符串 subject:hh 构成的字符串 |
|
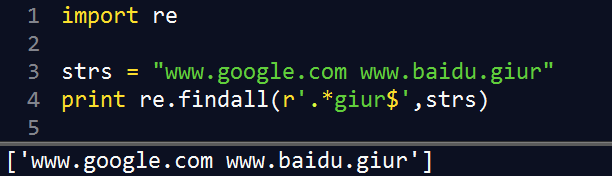
.*giur$ |
以 giur 结尾的字符串 |
特殊字符集
|
特殊字符集 |
|
|
\d |
匹配任何十进制数(\D 相反)<=> [0-9] |
|
\w |
任何字母数字(\W 相反) <=> [A-Za-z0-9] |
|
\s |
任何空格字符(\S 相反) <=> [\n\t\r\v\f] |
|
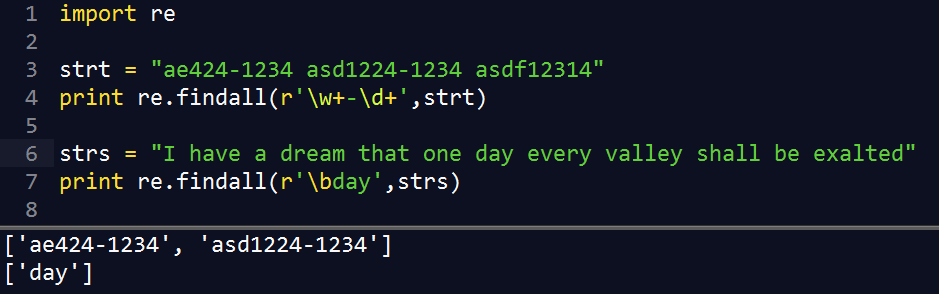
\b |
匹配任何单词边界 (\B 匹配出现在中间的字符串) |
|
\A\Z |
匹配字符串起始和结束 <=> ^$ |
|
\bthe\b |
仅仅匹配单词 the |
|
\Bthe |
任何包含但不以 the 作为起始的字符串 |
|
\w+-\d+ |
任意字母数字+连字符+数字 "asd123424-1234" |
字符集 & 闭包操作
|
字符集 & 闭包操作 |
|
|
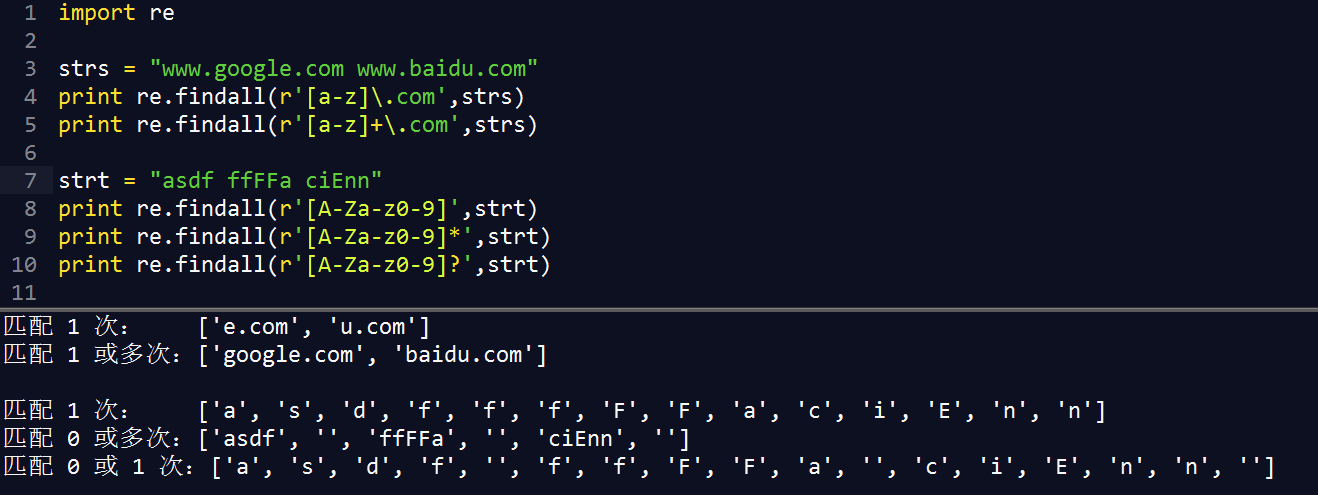
[0-9] |
数字 <=> \d |
|
[a-zA-Z] |
字母 <=> \w |
|
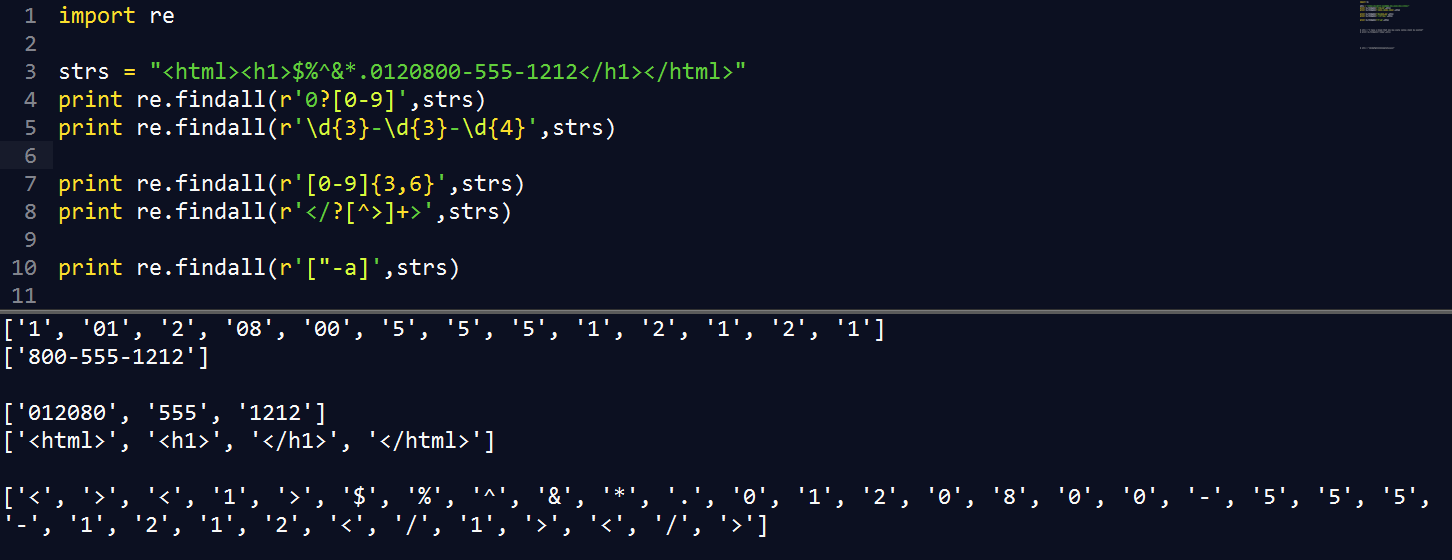
["-a] |
ASCII 中的字符 |
|
b[aeiu]t |
匹配 bat、bet、bit、but |
|
[cr][23][dp][o2] |
匹配 c2do、r3p2、r2d2、c3po |
|
[r-u][env-y][us] |
r|s|t|u 跟 e|n|v|w|x|y 跟 u|s |
|
[^aeiou] |
非 a|e|i|o|u 字符 |
|
[^\t\n] |
不匹配制表符或 \n |
|
[dn]ot? |
do、no、dot、not |
|
0?[0-9] |
任意数字,可前置 0 |
|
[0-9]{15,16} |
匹配 15 或 16 个数字 |
|
</?[^>]+> |
匹配所有 html 标签 |
|
\d{3}-\d{3}-\d{4} |
电话号码格式 "800-555-1212" |
圆括号指定分组
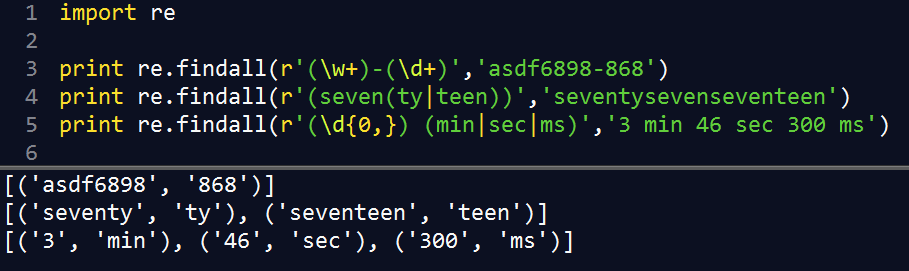
一对圆括号可以实现对正则表达式进行分组、匹配子组
圆括号分组匹配使得findall返回元组,元组中,几对圆括号就有几个元素,保留空匹配
扩展表示法 **
尽管有圆括号,但只有 (?P<name>) 表述一个分组匹配,其他的都没有创建一个分组
|
扩展表示法 ** |
|
|
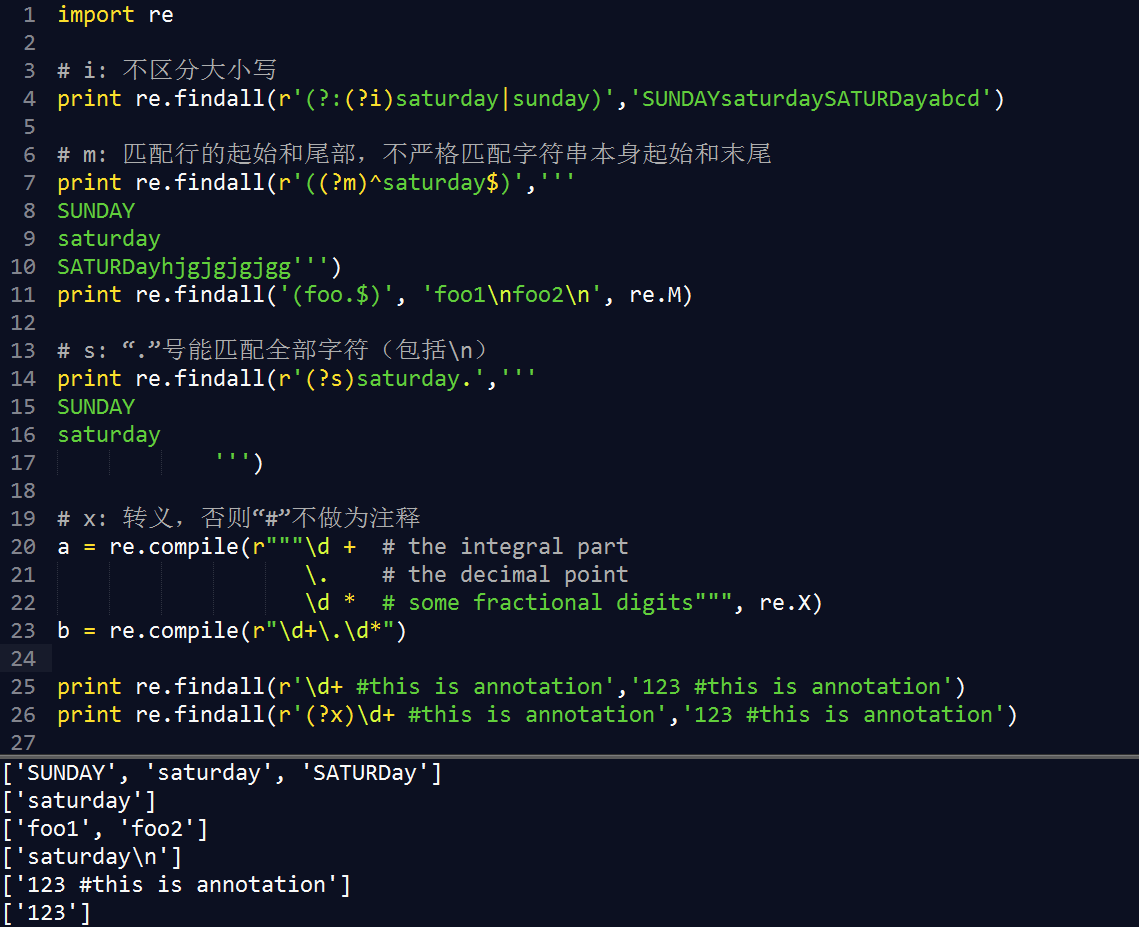
(?iLmsux) |
编译选项指定,可以写在findall或compile的参数中,也可以写在正则式里 |
|
(?#...) |
表示注释,所有内容被忽略 |
|
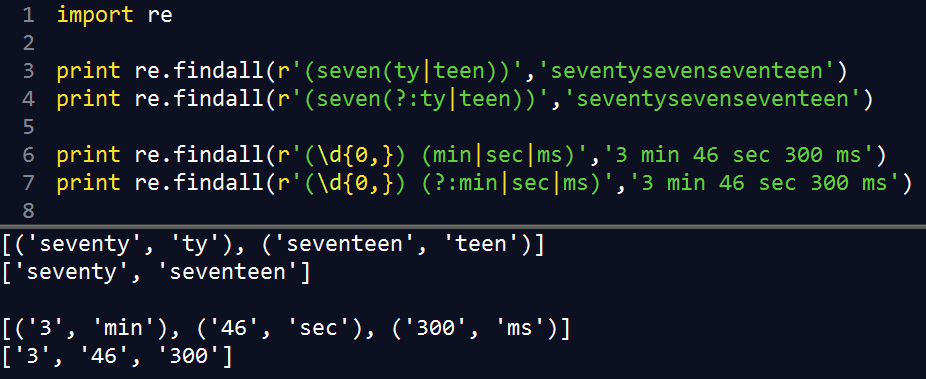
(?:...) |
表示一个匹配不用保存的分组 |
|
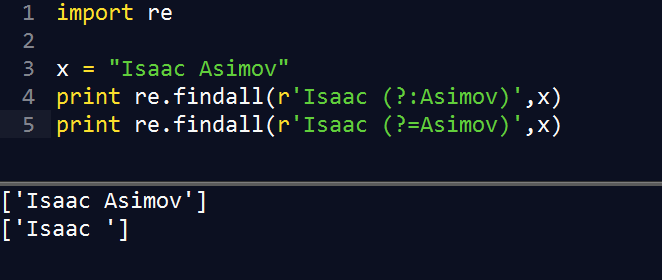
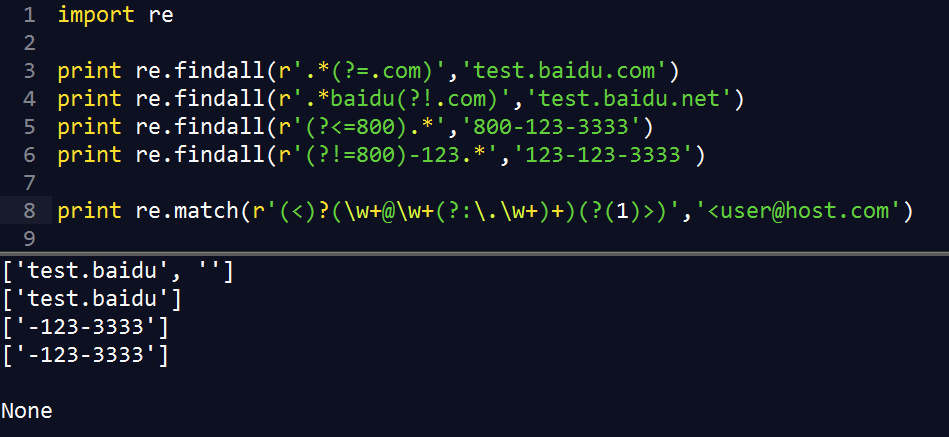
(?=...) |
如果 ... 出现在要匹配字符串的后面 例如:Isaac (?=Asimov) 只匹配 'Isaac ' 后面跟 'Asimov'的字符串 |
|
(?!...) |
如果 ... 不出现在要匹配字符串后面 |
|
(?<=...) |
如果 ... 出现在之前的位置,则匹配 |
|
(?<!...) |
如果 ... 不出现在之前的位置,则匹配 |
|
(?(id/name)yes-pattern|no-pattern) |
如果 group 中的 id/name 存在匹配 yes-pattern,否则 no-pattern 例如:(<)?(\w+@\w+(?:\.\w+)+)(?(1)>)只会匹配 <user@host.com> 或者 user@host.com 不会匹配 <user@host.com |
|
(?<!192\.168) |
如果一个字符串之前不是 192.168. 才做匹配 |
(?P<name>)和(?P=name)可以同时使用,前者除了原有的编号外再指定一个额外的别名,后者引用别名为<name>的分组匹配到字符串
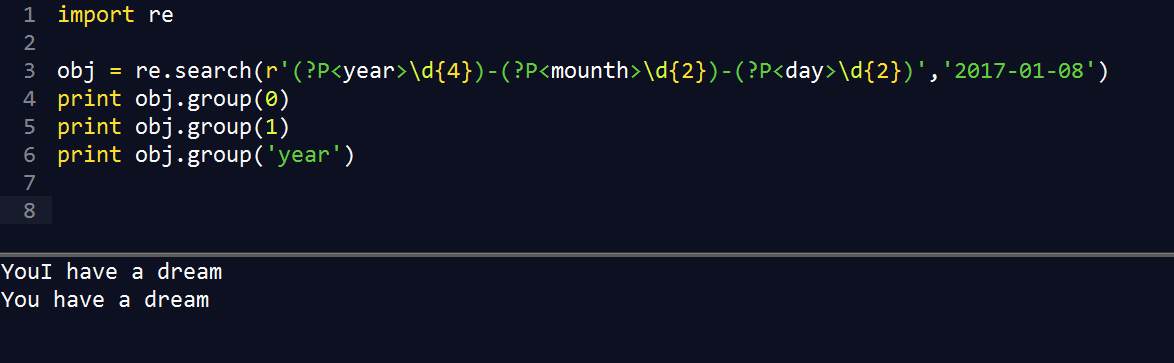
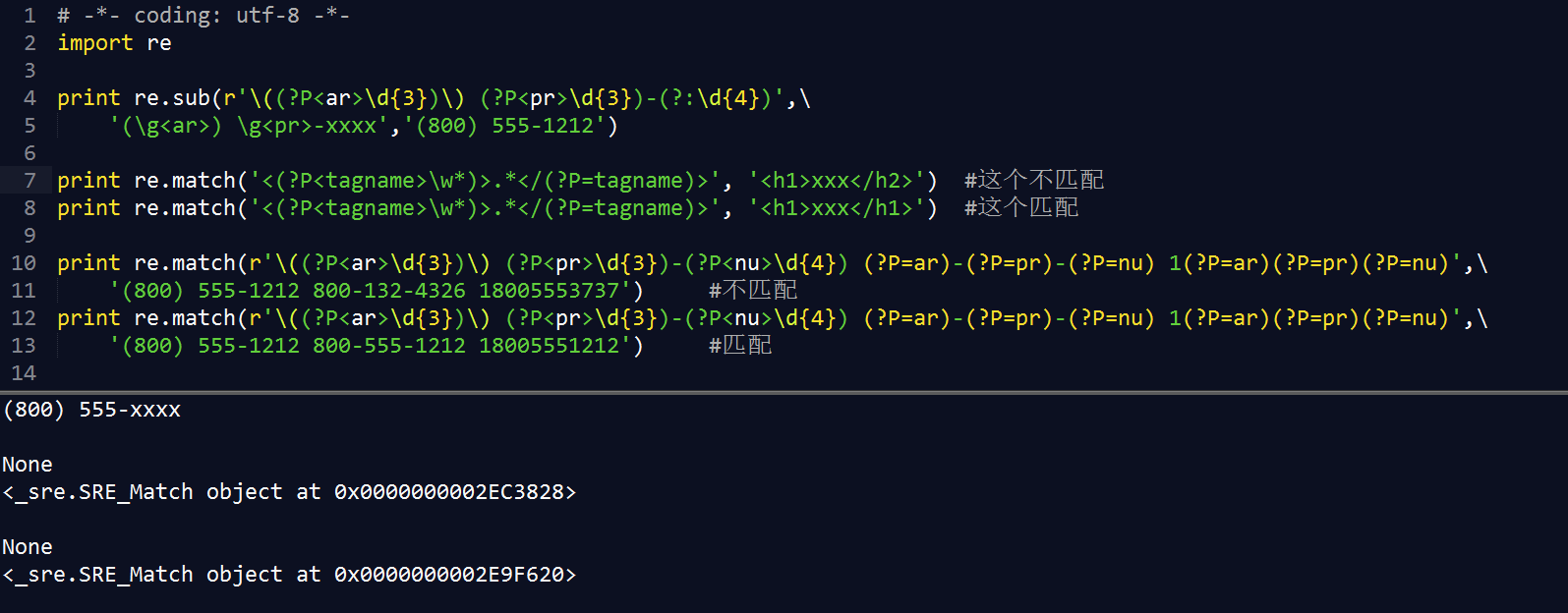
2. re 常见属性
2.1 compile()
编译正则表达式模式,返回一个对象的模式。
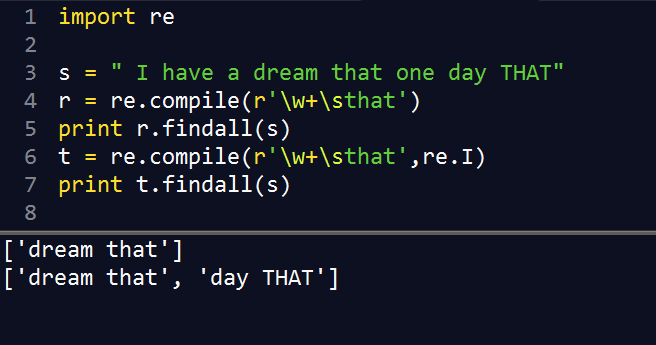
2.2 match()
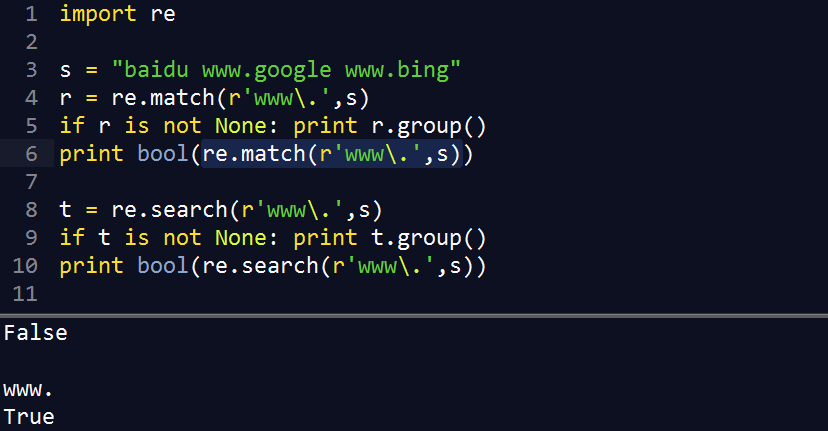
match()从字符串起始对模式进行匹配,匹配对象的 group() 用于显示成功的匹配
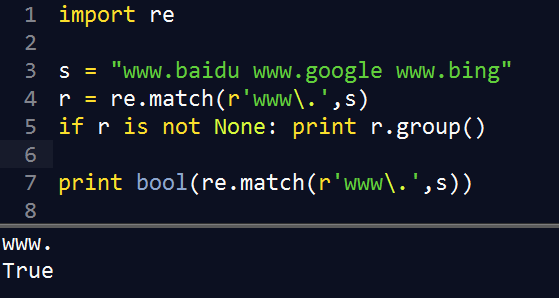
2.3 search()
扫描字符串查找正则表达式模式产生匹配的第一个位置,并返回MatchObject实例,否则返回None
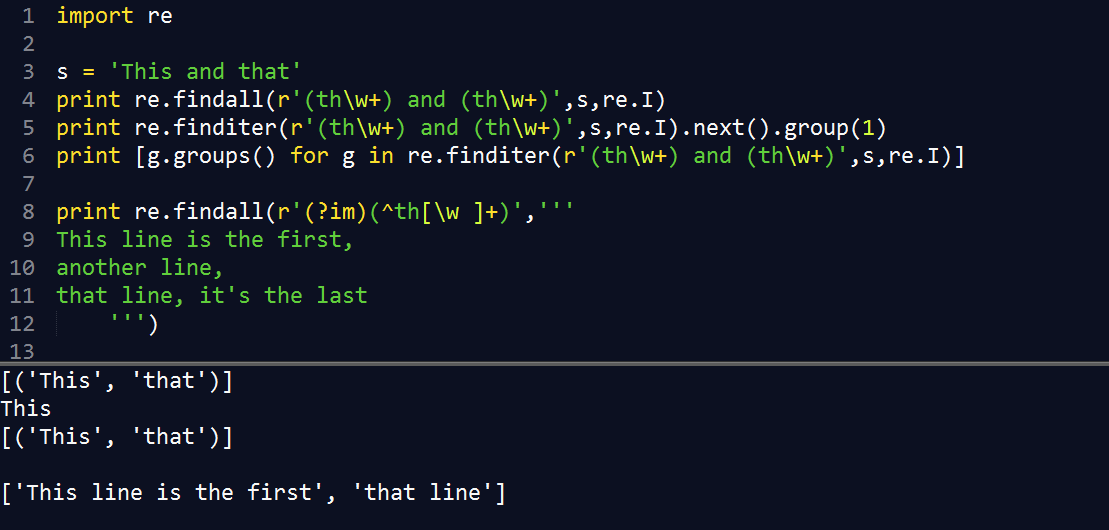
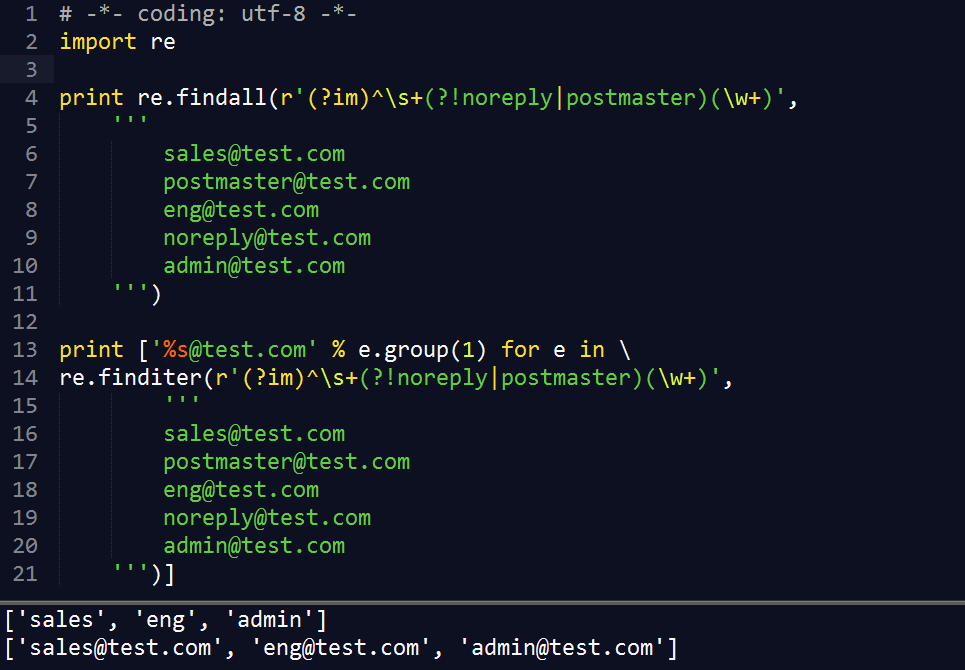
2.4 findall & finditer()
findall() 查询字符串中某个模式全部的非重复出现情况
finditer() 在匹配对象中迭代,找到 RE 匹配的所有子串,并把它们作为一个迭代器返回
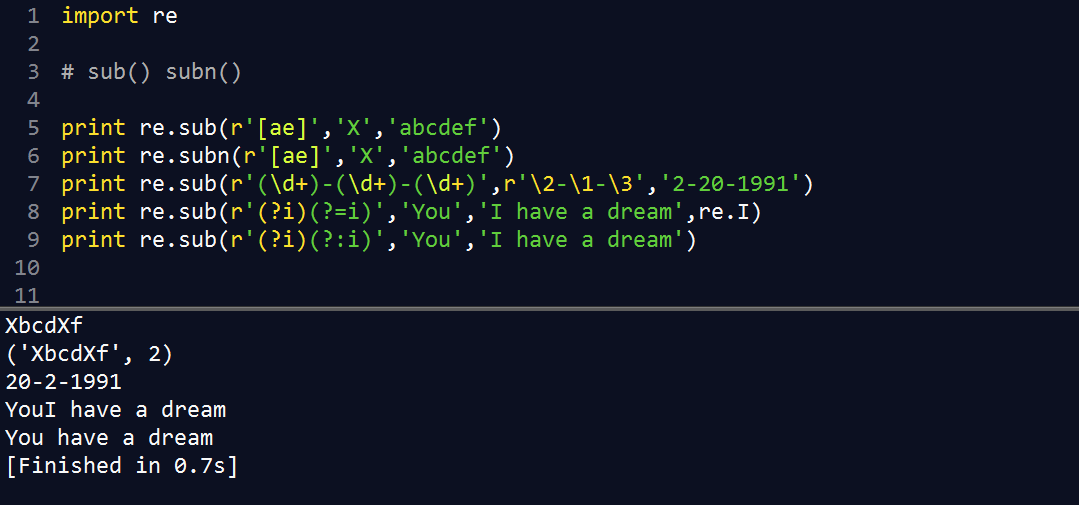
2.5 sub() subn()
将某字符串中所有匹配正则表达式的部分进行某种形式的替换
sub()返回替换后的字符串
subn()返回替换后的字符串和替换总数组成的元组
2.6 split()
在限定模式上使用split()分隔字符串
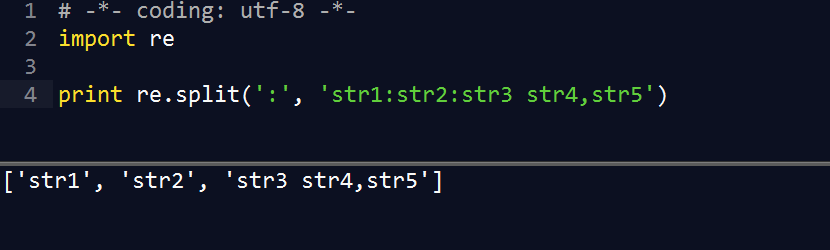
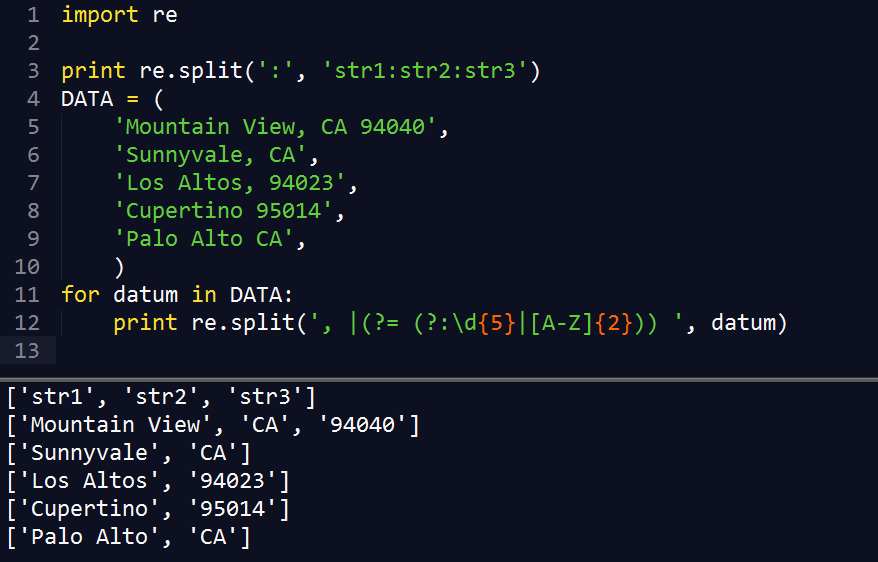
此示例 DATA 为用户输入,输入内容可能是城市和州名,或城市加上ZIP编码,或者三者同时输入
3. 正则表达式示例
3.1 通过正则表达式检测日志中的注入
get.txt 保存正则表达式规则
\.\./ \:\$ \$\{ select.+(from|limit) (?:(union(.*?)select)) having|rongjitest sleep\((\s*)(\d*)(\s*)\) benchmark\((.*)\,(.*)\) base64_decode\( (?:from\W+information_schema\W) (?:(?:current_)user|database|schema|connection_id)\s*\( (?:etc\/\W*passwd) into(\s+)+(?:dump|out)file\s* group\s+by.+\( xwork.MethodAccessor (?:define|eval|file_get_contents|include|require|require_once|shell_exec|phpinfo|system|passthru|preg_\w+|execute|echo|print|print_r|var_dump|(fp)open|alert|showmodaldialog)\( xwork\.MethodAccessor (gopher|doc|php|glob|file|phar|zlib|ftp|ldap|dict|ogg|data)\:\/ java\.lang \$_(GET|post|cookie|files|session|env|phplib|GLOBALS|SERVER)\[ \<(iframe|script|body|img|layer|div|meta|style|base|object|input) (onmouseover|onerror|onload)\=
regexRules.py 把规则加载为 json
regexes = { "regex": { "get": [], "post":[] }, "update": "20170828" } fp = open("get.txt") regexRule = fp.readlines() for reg in regexRule: regexes["regex"]["get"].append({"reg":reg.rstrip('\n')}) # print regexes fp.close()
logAnalys.py 主函数,读取每条日志,逐条规则进行匹配
# -*- coding: UTF-8 -*- import re import sys import urllib from regexRules import regexes reload(sys) sys.setdefaultencoding('utf8') #-----------------search bad data---------------- def checkData(uri): uri = unicode(str(uri), errors='ignore') uri = urllib.unquote(uri).lower() regexList=regexes["regex"]["get"] for i in range(len(regexList)): regRule=regexList[i] try: pattern = re.compile(r'%s'%(regRule["reg"])) except: print regRule["reg"] match = pattern.search(uri) if match: return 1 #-------------Reduce useless param-------------- def reduParam(url): try: values = url.split('?',1)[1] return values except: pass #---------------------main---------------------- def analysLog(logPath): index = 0 fp = open(logPath) while 1: line = fp.readline() if not line: break index += 1 tmpValue = reduParam(line) if tmpValue: if(checkData(tmpValue)): print '%s - - %s'%(index,line) if __name__ == '__main__': analysLog('access.log')
常见正则表达式符号和特殊字符
|
表示法 |
描述 |
正则表达式示例 |
|
符号 |
||
|
re1|re2 |
匹配正则表达式re1或re2 |
foo|bar |
|
. |
匹配任意除换行符"\n"外的字符 |
a.c |
|
^ |
匹配字符串开头,在多行模式中匹配每一行的开头 |
^Dear |
|
$ |
匹配字符串末尾,在多行模式中匹配每一行的末尾 |
/bin/*sh$ |
|
* |
匹配前一个字符0或多次 |
[A-Za-z0-9]* |
|
+ |
匹配前一个字符1次或多次 |
[a-z]+\.com |
|
? |
匹配一个字符0次或1次 |
goo? |
|
{} |
{m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次 |
[0-9]{3} ,[0-9]{5,9} |
|
[...] |
匹配字符集中的任意单个字符 |
[aeiou] |
|
[^...] |
不匹配字符集中的任意一个字符 |
[^aeiou],[^A-Za-z0-9] |
|
[x-y] |
X~y范围中的任何一个字符 |
[b-x] |
|
() |
匹配封闭的正则,存为子组,从表达式左边开始每遇到一个分组的左括号“(”,编号+1 |
([0-9]{3})?,f(oo|u)bar |
|
特殊字符 |
||
|
\d |
匹配任何十进制数(\D 相反)<=> [0-9] |
data\d+.txt |
|
\w |
任何字母数字(\W 相反) <=> [A-Za-z0-9] |
[A-Za-z]\w+ |
|
\s |
任何空格字符(\S 相反) <=> [\n\t\r\v\f] |
of\sthe |
|
\b |
匹配任何单词边界(\B相反) |
\bThe\b |
|
\A(\Z) |
匹配字符串起始(结束) <=> ^($) |
\ADear |
|
扩展表示法 |
||
|
(?iLmsux) |
编译选项指定,可以写在findall或compile的参数中,也可以写在正则式里 |
(?x), (?im) |
|
(?#...) |
表示注释,所有内容被忽略 |
(?#comment) |
|
(?:...) |
表示一个匹配不用保存的分组 |
(?:\w+\.) |
|
(?=...) |
如果 ... 出现在要匹配字符串的后面 例如:Isaac (?=Asimov) 只匹配 'Isaac ' 后面跟 'Asimov'的字符串 |
(?=.com) |
|
(?!...) |
如果 ... 不出现在要匹配字符串后面 |
(?!.net) |
|
(?<=...) |
如果 ... 出现在之前的位置,则匹配 |
(?<=800-) |
|
(?<!...) |
如果 ... 不出现在之前的位置,则匹配 |
(?<!192\.168\.) |
|
(?(id/name)yes-pattern|no-pattern) |
如果 group 中的 id/name 存在匹配 yes-pattern,否则 no-pattern 例如:(<)?(\w+@\w+(?:\.\w+)+)(?(1)>)只会匹配 <user@host.com> 或者 user@host.com 不会匹配 <user@host.com |
(?(1)y|x) |
|
(?P<name>...) |
分组,除了原有的编号外再指定一个额外的别名 |
(?P<id>abc){2} |
|
(?P=name) |
引用别名为<name>的分组匹配到字符串 |
(?P<id>\d)abc(?P=id) |
常见的正则表达式属性
|
函数/方法 |
描述 |
|
re模块函数 |
|
|
re.compile(pattern, flags=0) |
使用可选的标记编译正则表达式的模式,返回一个正则表达式对象,可以提高正则的匹配速度,重复利用正则表达式对象。 |
|
re模块函数和正则表达式对象方法 |
|
|
re.match(pattern,string, flags=0) |
如果字符串开头的零个或多个字符与正则表达式模式匹配,则返回相应的MatchObject实例,否则返回None |
|
re.search(pattern, string, flags=0) |
扫描字符串查找正则表达式模式产生匹配的第一个位置,并返回MatchObject实例,否则返回None |
|
re.findall(pattern, string, flags=0) |
返回字符串中模式的所有非重叠匹配,作为字符串列表返回 |
|
re.finditer(pattern, string, flags=0) |
与findall()函数相同,但返回的是一个迭代器,对于每一次匹配,迭代器都返回一个匹配对象 |
|
re.split(pattern, string, maxsplit=0, flags=0) |
根据正则表达式的模式分隔符,split函数将字符串分割为列表,返回成功匹配的列表,分隔最多操作maxsplit次 |
|
re.sub(pattern, repl, string, count=0, flags=0) |
使用re替换string中每一个匹配的子串后返回替换后的字符串 |
|
re.subn(pattern, repl, string, count=0, flags=0) |
返回替换的总数 |
|
re.escape(pattern) |
把pattern中,除了字母和数字以外的字符,都加上反斜杆 |
|
re.purge() |
清除隐式编译的正则表达式模式 |
|
常见的匹配对象方法 |
|
|
group(num=0) |
返回匹配对象 |
|
groups(default=None) |
返回一个包含所有匹配子组的元组 |
|
groupdict(default=None) |
返回一个包含所有匹配的命名子组的字典 |
|
常见的模块属性 |
|
|
re.I 、 re.IGNORECASE |
不区分大小写 |
|
re.L 、 re.LOCALE |
根据本地语言环境通过\w\W\b\B\s\S实现匹配 |
|
re.M 、 re.MULTILINE |
多行匹配,影响^和$ |
|
re.X 、 re.VERBOSE |
转义,否则#无法实现注释功能 |
|
re.S 、 re.DOTALL |
使.匹配包括换行在内的所有字符 |
|
re.U |
根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B |
# References
https://docs.python.org/2/library/re.html
http://www.cnblogs.com/tina-python/p/5508402.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号