力扣-430. 扁平化多级双向链表
1.题目
题目地址(430. 扁平化多级双向链表 - 力扣(LeetCode))
https://leetcode.cn/problems/flatten-a-multilevel-doubly-linked-list/
题目描述
你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一个或多个自己的子列表,以此类推,以生成如下面的示例所示的 多层数据结构 。
给定链表的头节点 head ,将链表 扁平化 ,以便所有节点都出现在单层双链表中。让 curr 是一个带有子列表的节点。子列表中的节点应该出现在扁平化列表中的 curr 之后 和 curr.next 之前 。
返回 扁平列表的 head 。列表中的节点必须将其 所有 子指针设置为 null 。
示例 1:
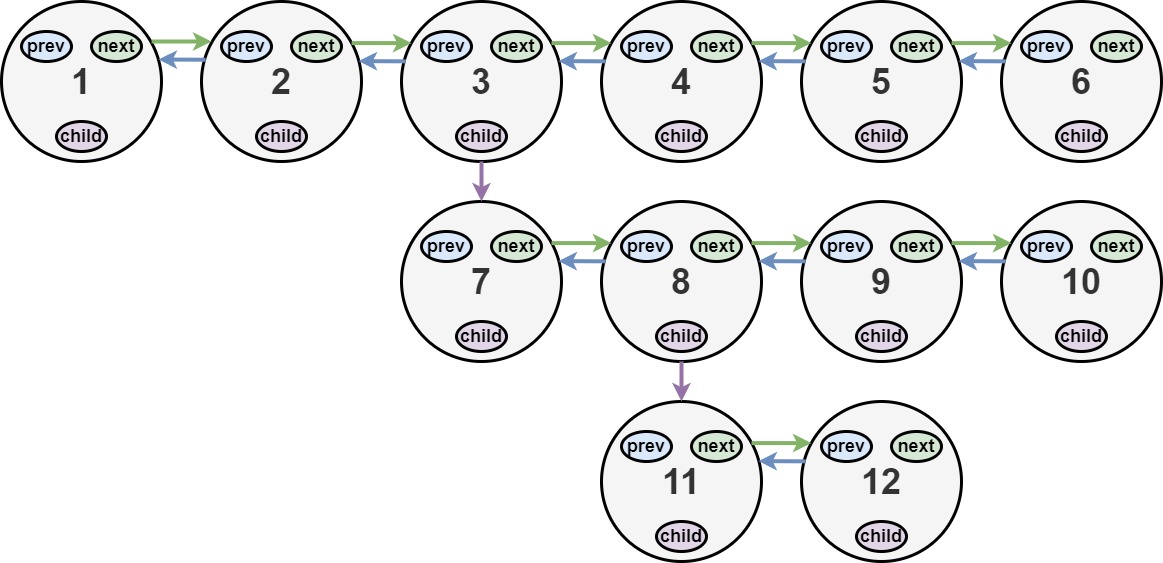
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12] 输出:[1,2,3,7,8,11,12,9,10,4,5,6] 解释:输入的多级列表如上图所示。 扁平化后的链表如下图:
示例 2:

输入:head = [1,2,null,3] 输出:[1,3,2] 解释:输入的多级列表如上图所示。 扁平化后的链表如下图: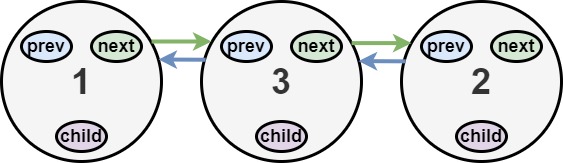
示例 3:
输入:head = [] 输出:[] 说明:输入中可能存在空列表。
提示:
- 节点数目不超过
1000 1 <= Node.val <= 105
如何表示测试用例中的多级链表?
以 示例 1 为例:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
序列化其中的每一级之后:
[1,2,3,4,5,6,null] [7,8,9,10,null] [11,12,null]
为了将每一级都序列化到一起,我们需要每一级中添加值为 null 的元素,以表示没有节点连接到上一级的上级节点。
[1,2,3,4,5,6,null] [null,null,7,8,9,10,null] [null,11,12,null]
合并所有序列化结果,并去除末尾的 null 。
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
2.题解
2.1 DFS深度优先搜索-返回展平后头结点
思路
由于每次有child子节点,我们优先遍历展开子节点到当前节点cur后,下一个节点next前(如果next存在), 我们很容易想到这是一个DFS深度优先搜索
我们这里选择每次返回子层级展平后的头结点chead,这样的话就可以每次操作head和chead链接; 如果还存在next节点,我们必须就要找到子层级的尾节点,然后链接cend和next才行
代码
class Solution {
public:
Node* flatten(Node* head) {
Node* dummy = new Node(0);
dummy->next = head;
while (head != nullptr) {
if (head->child == nullptr) {
head = head->next;
} else {
Node* next = head->next;
// 处理head和child的链接
Node* chead = flatten(head->child);
head->next = chead;
chead->prev = head;
head->child = nullptr; // 清空child区域
// 寻找尾节点,链接next节点(如果存在)
if (next) {
while (head->next != nullptr)
head = head->next;
if (next != nullptr) {
head->next = next;
next->prev = head;
}
}
}
}
return dummy->next;
}
};
复杂度
\(\begin{aligned}&\bullet\text{ 时间复杂度:最坏情况下,每个节点会被访问 }h\text{ 次( }h\text{ 为递归深度,最坏情况下 }h=n\text{ )。整体复杂度为 }O(n^2)\\&\bullet\text{ 空间复杂度:最坏情况下所有节点都分布在 child 中,此时递归深度为 }n\text{。复杂度为 }O(n)\end{aligned}\)
2.2 DFS深度优先搜索-返回尾节点
思路
上面一种方法由于每次存在next节点的时候,均要遍历出子层级的尾节点,导致我们的时间复杂度居高不下
另一方面我们发现,我们在head和子层级头部的链接中,只需要利用存在的head->child,便可以轻易完成链接,不需要返回值提供的子层级头结点信息
那我们换一种思路, 能否将返回值从我们不需要的头结点信息转换为尾节点信息呢? 答案是可以的
1.返回条件
我们肯定要遍历完并展开当前层所有节点, 所以返回条件也就是 cur == nullptr;
2.执行操作
- 2.1 我们想要将子节点头部和当前节点cur构成双向链接很简单,我们交换一下next和prev即可
- 2.2 我们该如何将child子层节点尾部接到next呢?换言之,我们该如何获得该尾部节点呢?
我们很容易发现当前层结束条件是cur == nullptr, cur遍历时必然会经过最后一个节点,那我们如果在之前用一个指针last保存住了该节点,然后作为返回值返回给上一层,就是可以直接获得子层的尾部节点了!
我们可以每次去判断是不是最后一个节点再去用last保存,也可以在每次完成一次操作就更新一次last。
这里的last有两种情况:
1.如果当前节点cur没有节点,他自己cur就是最后一个;
2.如果有子节点,那么就进行DFS深度优先搜索,找到子节点的末尾节点,该节点为展开后链表的尾节点
3.返回值
返回当前层的尾部节点, 便于上一层链接next
代码
- 语言支持:C++
C++ Code:
/*
// Definition for a Node.
class Node {
public:
int val;
Node* prev;
Node* next;
Node* child;
};
*/
class Solution {
public:
Node* DFS(Node* node) {
Node* cur = node;
Node* last = nullptr; // 记录末尾位置
while (cur != nullptr) {
Node *next = cur->next; // 记录当前节点下一个节点位置
// 如果当前节点存在子节点
if(cur->child){
Node *child_last = DFS(cur->child);
cur->next = cur->child;
cur->child->prev = cur;
if(next != nullptr){
child_last->next = next;
next->prev = child_last;
}
// last = child_last;
cur->child = nullptr;
if(!cur->next) last = child_last;
}else{
// last = cur;
if(!cur->next) last = cur;
}
cur = next;
}
return last;
}
Node* flatten(Node* head) {
DFS(head);
return head;
}
};
复杂度分析
时间复杂度:O(n),其中 n 是链表中的节点个数。
空间复杂度:O(n)。上述代码中使用的空间为深度优先搜索中的栈空间,如果给定的链表的「深度」为 d,那么空间复杂度为 O(d)。
在最坏情况下,链表中的每个节点的 next 都为空,且除了最后一个节点外,每个节点的 child 都不为空,整个链表的深度为 n,因此时间复杂度为 O(n)。
2.3 迭代
思路
自然也能够使用迭代进行求解。
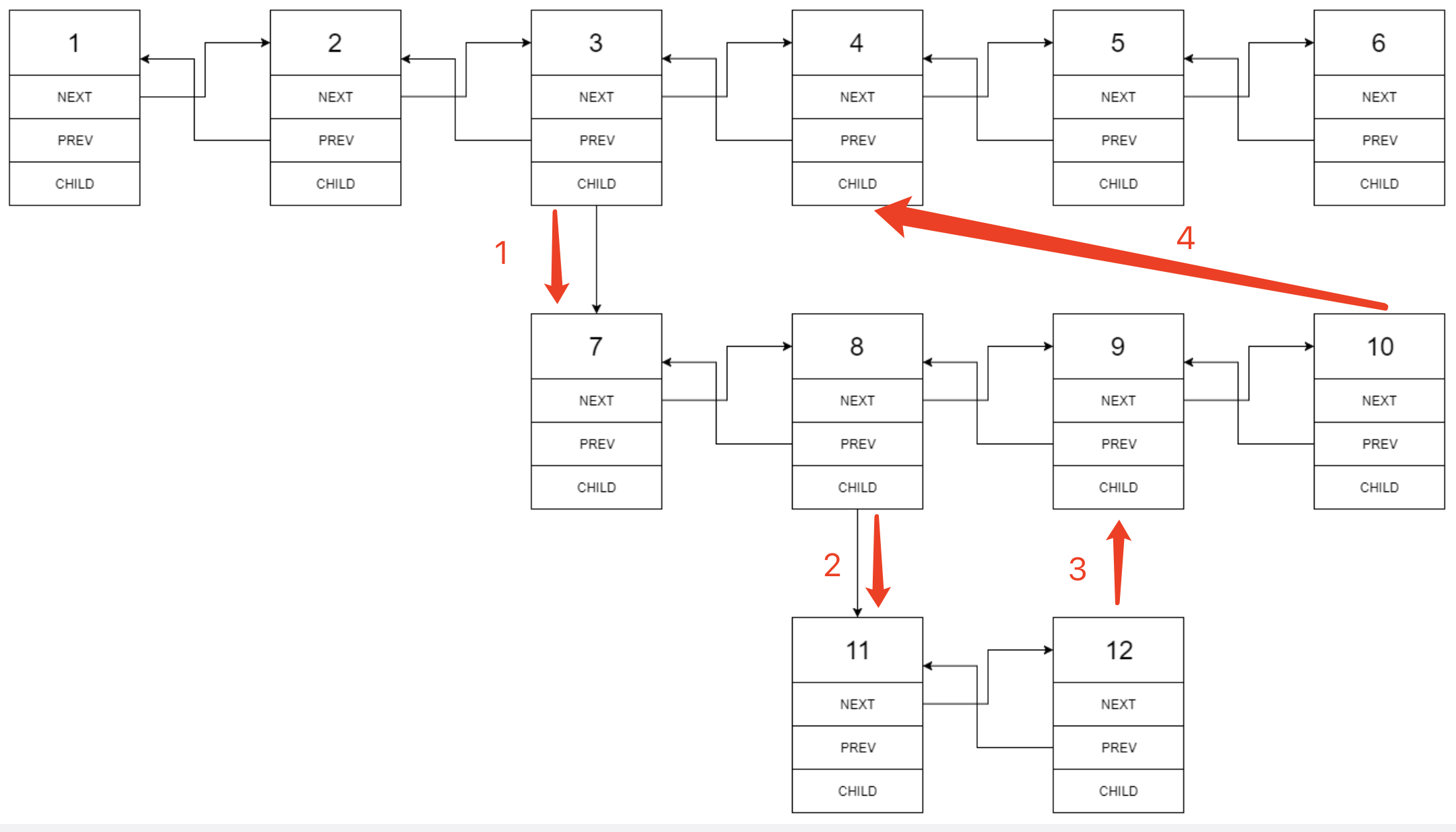
与「递归」不同的是,「迭代」是以“段”为单位进行扁平化,而「递归」是以深度(方向)进行扁平化,这就导致了两种方式对每个扁平节点的处理顺序不同。
递归的处理节点(新的 nextnextnext 指针的构建)顺序为:
迭代的处理节点(新的 nextnextnext 指针的构建)顺序为:
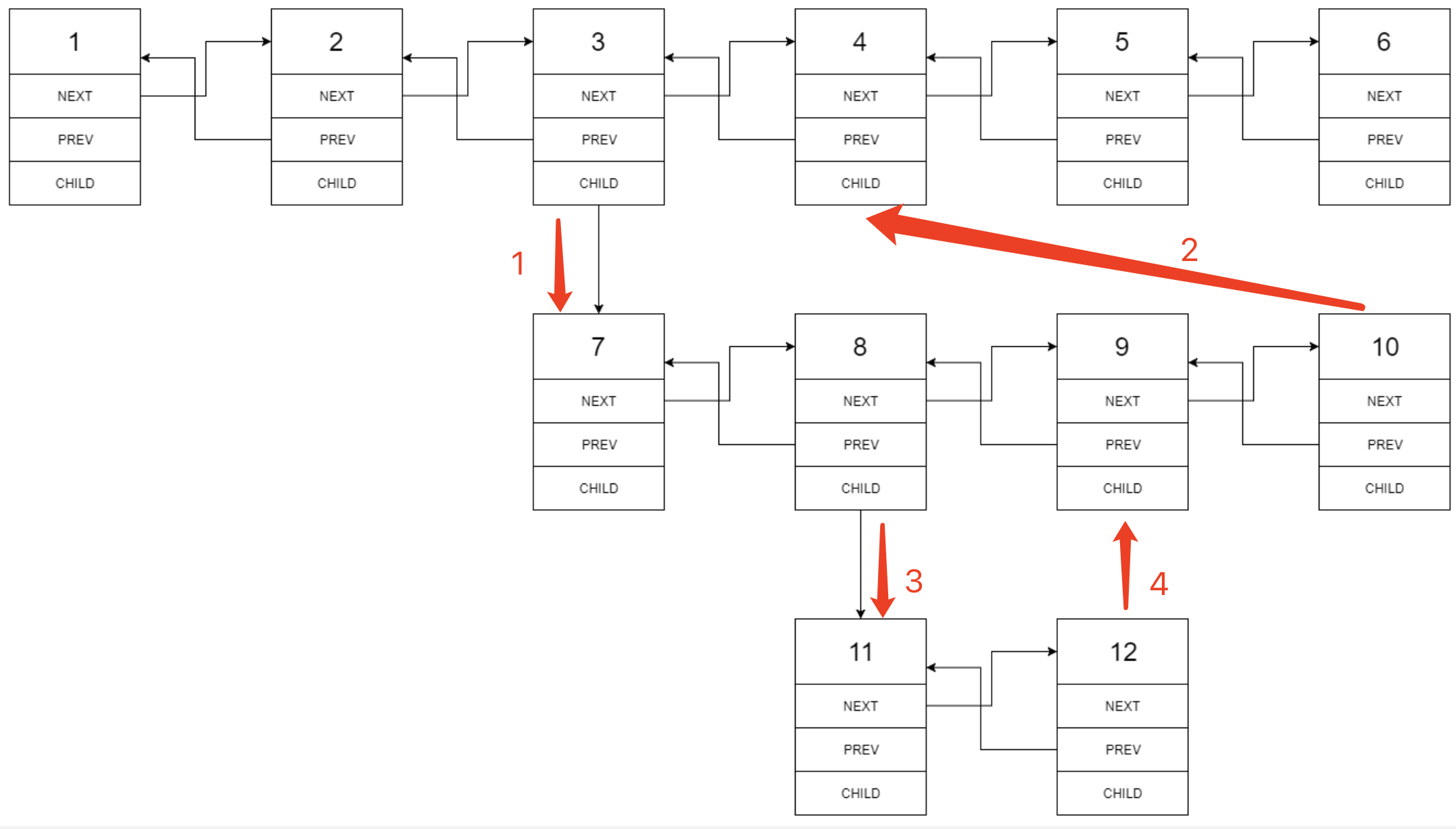
也就是我们先将7,8,9,10加到3和4中间, 但是接下来遍历的下一个节点并不是4(递归), 而是7(迭代),8, 在遇到8的时候,将11,12插入8,9之间,再遍历11,12,9,10,4,5,6
代码
class Solution {
public:
Node* flatten(Node* head) {
Node* dummy = new Node(0);
dummy->next = head;
for (Node* cur = head; cur != nullptr; cur = cur->next) {
Node* next = cur->next;
if (cur->child) {
cur->next = cur->child;
cur->child->prev = cur;
cur->child = nullptr;
if (next) {
Node* last = cur;
while (last->next != nullptr){
last = last->next;
}
next->prev = last;
last->next = next;
}
}
}
return dummy->next;
}
};

