
shell正则表达式和awk
一、正则表达式
注意事项:使用正则表达式必须加引号。
主要用来匹配字符串(命令结果,文本内容)
通配符匹配文件(而且是已存在的文件)
-
基本正则表达式
-
扩展正则表达式
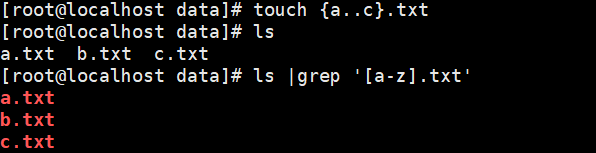
1 2 3 4 5 6 7 8 9 10 11 12 | 1、元字符[root@pc1 data]#grep -o r.t /etc/passwd #过滤passwd文件中开头为r中间任意单个字符结尾为t的内容ratratrat[root@pc1 data]#grep -o r..t /etc/passwd #过滤passwd文件中开头为r中间任意2个字符结尾为t的内容rootrootrootrootr/ft[root@pc1 data]#grep -o r...t /etc/passwd #过滤passwd文件中开头为r中间任意3个字符结尾为t的内容rtkit |
. 匹配任意单个字符,可以是一个汉字
[] 匹配指定范围内的任意单个字符,示例:[zhou] [0-9] [] [a-zA-Z] [:alpha:]
[^] 匹配指定范围外的任意单个字符,示例:[^zhou] [^a.z] [a.z]
| [:alnum:] | 字母和数字 |
| [:alpha:] | 代表任何英文大小写字符,亦即 A-Z, a-z |
| [:lower:] | 小写字母,示例:[[:lower:]],相当于[a-z] |
| [:upper:] | 大写字母 |
| [:blank:] | 空白字符(空格和制表符) |
| [:space:] | 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广 |
| [:cntrl:] | 不可打印的控制字符(退格、删除、警铃...) |
| [:digit:] | 十进制数字 |
| [:xdigit:] | 十六进制数字 |
| [:graph:] | 可打印的非空白字符 |
| [:print:] | 可打印字符 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | [root@pc1 data]#echo AB12ab | grep -o '[[:alpha:]]' #过滤输出内容的字母ABab[root@pc1 data]#echo AB12ab | grep -o '[[:alnum:]]' #过滤输出内容的字母和数字AB12ab[root@pc1 data]#echo AB12ab | grep -o '[[:lower:]]' #过滤输出内容的小写字母ab[root@pc1 data]#echo AB12ab | grep -o '[[:upper:]]' #过滤输出内容的大写字母AB |
2、表示次数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | ①*:表示匹配前面字符任意次,包括0次。[root@pc1 ~]#echo ac |grep 'ab*c' #ab之间不输入b可匹配ac[root@pc1 ~]#echo abc |grep 'ab*c' #ab之间输入1个b可匹配abc[root@pc1 ~]#echo abbc |grep 'ab*c'#ab之间输入2个b可匹配abbc②.*:表示匹配前面字符任意次,不包括0次。[root@pc1 ~]#echo ac |grep 'ab.*c' #ac之间不输入b匹配不到[root@pc1 ~]#echo abc |grep 'ab.*c' #ac之间输入1个b可以匹配abc[root@pc1 ~]#echo abbc |grep 'ab.*c' #ac直接输入2个b可以匹配abbc③\?:表示匹配前面的字符1次或0次,即可有可无。[root@pc1 ~]#echo ac | grep 'ab\?c' #ac之间不输入b可以匹配ac[root@pc1 ~]#echo abc | grep 'ab\?c' #ac之间输入1个b可以匹配abc[root@pc1 ~]#echo abbc | grep 'ab\?c' #ac之间输入2个b匹配不到④\+:表示匹配前面的字符最少1次。[root@pc1 ~]#echo ac | grep 'ab\+c' #ac之间不输入b匹配不到[root@pc1 ~]#echo abc | grep 'ab\+c' #ac之间输入1个b可以匹配abc[root@pc1 ~]#echo abbbbc | grep 'ab\+c' #ac之间输入多个b可以匹配abbbbc⑤\{n\}:表示匹配前面的字符n次。[root@pc1 ~]#echo abbbc |grep 'ab\{3\}c' #输出abbbc匹配ac之间b字符出现3次可以匹配abbbc[root@pc1 ~]#echo abbbbc |grep 'ab\{3\}c' #输出abbbbc匹配ac之间b字符出现3次匹配不到⑥\{m,n\}:表示匹配前面的字符最少m次最多n次。[root@pc1 ~]#echo abc |grep 'ab\{1,3\}c' #输出abc匹配ac之间b出现最少1次最多3次可以匹配abc[root@pc1 ~]#echo abbc |grep 'ab\{1,3\}c' #输出abbc匹配ac之间b出现最少1次最多3次可以匹配abbc[root@pc1 ~]#echo abbbc |grep 'ab\{1,3\}c'#输出abbbc匹配ac之间b出现最少1次最多3次可以匹配abbbc[root@pc1 ~]#echo abbbbc |grep 'ab\{1,3\}c'#输出abbbbc匹配ac之间b出现最少1次最多3次匹配不到⑦\{m,\}:表示匹配前面的字符最少m次。⑧\{,n\}:表示匹配前面的字符最多n次。 |
3、位置锚定
①^表示以什么字符开头的行。
②$表示以什么字符为结尾的行。
③^PATTERN$ 表示用于模式匹配整行 (单独一行 只有PATTERN字符)。
④^$ 表示空行。
⑤\< 或 \b #词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)。
⑥\> 或 \b #词尾锚定,用于单词模式的右侧。
⑦\<PATTERN\> #匹配整个单词。
4、分组
()将多个字符捆绑在一起当做一个整体处理
[root@pc1 ~]#echo abcccc |grep "abc\{4\}" #匹配输出内容c出现4次
abcccc
[root@pc1 ~]#echo abcccc |grep "\(abc\)\{4\}" #abc字符加()分组匹配输出内容abc出现4次,无abc出现4次匹配不到
[root@pc1 ~]#echo abcabcabcabc |grep "\(abc\)\{4\}" #abc字符加()分组匹配输出内容abc出现4次匹配成功
abcabcabcabc
5、扩展正则表达式
①使用方法
grep -E选项加正则表达式内容,与正常正则表达式区别在于不用在匹配时添加 \
②表示次数
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
{,n} #匹配前面的字符至多n次,<=n,n可以为0
{n,} #匹配前面的字符至少n次,<=n,n可以为0
③表示分组
() 分组
三、文本三剑客之AWK
1、awk
awk为流编辑器,即读取文件一行处理一行。不同于vi编辑器等是将文件整个缓存在内容中处理。
2、使用格式
awk [选项] '处理模式{处理动作}'
'{ }'为固定格式
3、处理动作
①基本格式:awk [选项] '处理模式{处理动作}'
②print动作:打印,打印'{print $1}'即为打印第一列,'{print $n}'即打印为第n列,'{print $n,$m}'即为打印第n列和第m列。
③print打印顺序:'BEGIN{print "1"} END {print "2"} {print "3"} ',首先打印BEGIN后的print 1,然后打印print 3 最后打印END后的print 2,BEGIN表示第一个打印,END表示最后打印
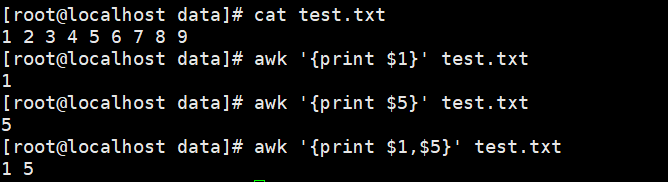
1 2 3 4 5 6 7 8 9 | 举例1:[root@pc1 data]#cat test.txt #创建文件1 2 3 4 5 6 7 8 @test.txt 文件内容[root@pc1 data]#awk '{print $1}' test.txt #使用awk处理文件test.txt打印第1列1[root@pc1 data]#awk '{print $5}' test.txt #使用awk处理文件test.txt打印第5列5[root@pc1 data]#awk '{print $1,$5}' test.txt #使用awk处理文件test.txt打印第1列和第5列1 5 |
1 2 3 4 5 | 举例2:[root@pc1 data]# awk 'BEGIN{print "1"} END{print "$2"} {print "3"}' test.txt132 |

4、选项
①基本格式:awk [选项] '处理模式{处理动作}'
②选项若不写默认为以空格为分隔符处理,且会将空格自动压缩。
③-F 选项 指定分隔符,即指定以什么为分隔符处理内容
举例:
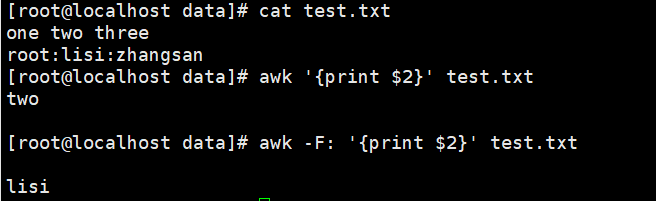
[root@pc1 data]#cat test.txt #编辑test.txt内容
one two three
root:lisi:zhangsan
[root@pc1 data]#awk '{print $2}' test.txt #默认过滤test内容以空格为分隔符打印出第2列为two
two
[root@pc1 data]#awk -F : '{print $2}' test.txt #使用-F选项指定以:为分隔符打印出第2列为lisi
lisi
本文作者:twistfate123
本文链接:https://www.cnblogs.com/trist-commot/p/17092462.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步