xhtmlrenderer 将html转换成pdf,完美css,带图片,手动分页,解决内容断开的问题
之前用itext7将html导出为pdf,比较方便,代码较少,而且支持base64的图片。但是itext7是收费的,所以换成了xhtmlrenderer。
xhtmlrenderer自动引入依赖包itext2.0.8,而且不能再引入其他版本的itext,因为itext2.0.8是已经被废弃的,里面的很多方法在新版本已经没有了。
itext导出pdf最重要的4个难点:
1.css样式
2.中文不显示
3.图片(itext7支持比较好,不过要收费)
4.分页时内容断开的问题(itext7不会出现这种问题,不过要收费)
一、首先引入包
只需要这个就够了,它会自动引入itext2.0.8
<dependency>
<groupId>org.xhtmlrenderer</groupId>
<artifactId>core-renderer</artifactId>
<version>R8</version>
</dependency>
二、页面css样式的采集
看过很多篇itext的文章,都没有达到想象中要求。大多是说将css路径改为绝对路径,或者将css写在页面中,这都不现实。真正的项目中,你的项目经理是不会让你这么做的。
所以我找到一个能将页面所有css采集起来的js方法。传入你的标签的id,返回一个包含该id的区域的所有css样式 ,加上html,head和body标签,组成一个html的字符串。将字符串传给后台去生成pdf。值得注意的是我加了这个字体body{font-family: SimSun;},这个字符是中文字体,后端必须与前端一致。且看后面。
function getElementChildrenAndStyles(selector) { var html = $(selector).prop("outerHTML"); selector = selector.split(",").map(function(subselector){ return subselector + "," + subselector + " *"; }).join(","); elts = $(selector); var rulesUsed = []; //文档的所有样式表 sheets = document.styleSheets; for(var c = 0; c < sheets.length; c++) { // rules 和 cssRules 的计数方法也是不一样的!rules 是第几个选择器;cssRules 是第几条规则, // 分别用于IE7和chrome var rules = sheets[c].rules || sheets[c].cssRules; for(var r = 0; r < rules.length; r++) { //selectorText: $节点 var selectorText = rules[r].selectorText; var matchedElts = $(selectorText); //找到dom节点里所有节点,并将其push到数组里 for (var i = 0; i < elts.length; i++) { if (matchedElts.index(elts[i]) != -1) { rulesUsed.push(rules[r]); break; } } } } //重组style var style = rulesUsed.map(function(cssRule){ if (cssRule.style) { var cssText = cssRule.selectorText+'{'+cssRule.style.cssText.toLowerCase()+'}'; } else { var cssText = cssRule.selectorText+'{'+cssRule.cssText+'}'; } return cssText; }).join("\n"); return "<html><head><meta charset='UTF-8'/> <style>\n"
+ style
+"\n td{background:white!important;}"
+"\n body{font-family: SimSun;} \n</style>\n\n</head><body>"
+ html+"</body></html>"; }
今天解决了分页的时候会断开内容的问题,解决方案就是手动分页,用js计算高度然后超过页面高度的就换页,这样就不会出现自动换页的时候内容断开了。
1.我将需要显示的元素都添加class= ‘pdf-page-range’
2. class='pageNext' .pageNext{page-break-after: always;} 这个css表示下一个元素将会换页,转pdf的时候itext会自动识别。
3.在前面的基础上插入以下代码即可,需要图片转换之后执行,
注意:这个修改了网页内容,如果想保留原网页内容,自行想办法 -。-!
//后端低版本的itext对分页的处理非常不友好,所以前端页面强制分页。
//我将需要显示的元素都添加class= ‘pdf-page-range’
//class='pageNext' .pageNext{page-break-after: always;} 这个css表示下一个元素将会换页。
function pdfPageRange(){ var heigth= 0; $(".pdf-page-range").each(function(){ var $this = $(this); var $table = $this.find('table'); var $next = $this.next(); var $prevPage = $this.prev('.pageNext'); index = $(".pageNext").length; var tagName = $this[0].tagName; var element_tag; if($table&&$table.length>0){ element_tag = $table[0]; } if(tagName=='table'||tagName=='TABLE'){ element_tag = $this[0]; } if(element_tag){ heigth = tablePage($(element_tag),heigth) return true; } //不是table的处理 heigth += $this[0].offsetHeight; if(heigth>1000){ $this.before("<div class='pageNext' ></div> "); heigth = $this[0].offsetHeight; } }); } //table单独算高度 function tablePage($table,heigth){ var $trList = $table.find('tr'); var $thead = $table.find('tr.thead'); $trList.each(function(){ heigth += $(this)[0].offsetHeight; if(heigth>1000){ $(this).before($thead.prop("outerHTML")); $thead_add = $(this).prev().prev(); $thead_add.addClass('pageNext'); heigth = $(this)[0].offsetHeight+$thead_add[0].offsetHeight; } }); return heigth; } });
三、图片的支持
项目中有很多Echarts做的图表,这个生成的图表都是canvas标签,而itext是不支持canvas标签的。所以要把图表全部换成base64的img标签。这里引入一个js。
html2canvas.js,它能将制定区域截图。请看以下。
注意:
1.html2canvas()方法返回的是Promise类型,为什么要将所有 html2canvas()方法的返回值集中起来然后使用Promise.all(canvasArray).then()方法。因为html2canvas()是异步的,你的下面的js已经处理完了,它可能还没截图完成。Promise.all(canvasArray).then()方法,会在所有截图已经完成之后执行。所以我把ajax请求放在里面。(请看代码)
2. img标签闭合的问题,img标签是自闭合标签。正常情况下,浏览器不会去识别你的img的闭合标签,即使你的img标签有</img>或<img src="" />,浏览器最后显示还是<img>, 所以我用一个字符串代替“/”, 后台再用“/”代替这个字符串,你也可以前端就替换。(请看代码)
3.必须给img加上宽度和高度,不然被后台转换之后尺寸会变得很小。
$("#itextpdf").click(function(){
var canvasArray = [];
$(".charts").each(function(){
var $this=$(this);
var canvasIndex = html2canvas(
$this,
{ scale: 5
,background: '#FFFFFF'
,onrendered:function(canvas){
var imgBase64 = canvas.toDataURL('image/jpeg', 1.0);
$this.html("");
// 标签被jquery获取后,自定义属性closingtags会变成closingtags="",你可以加个css将图片隐藏起来,然后在html字符串里面再加一个显示的css。
$this.append ("<img class=“hidden” alt='' src='"+ imgBase64+"' closingtags > ")
}
}
);
canvasArray.push(canvasIndex);
});
Promise.all(canvasArray).then(function () {
var str = getElementChildrenAndStyles('#basket');
$.post("/ecloud/sa/saerrorquestions/exportpdf.do",{"str":str },function(r){
});
});
});
四、后台代码
项目中引入中文字体,html字符串中也必须引入。我的字体css是 body{font-family: SimSun;}
package cn.myc.ykt3.util; import java.io.FileOutputStream; import java.io.OutputStream; import org.xhtmlrenderer.pdf.ITextFontResolver; import org.xhtmlrenderer.pdf.ITextRenderer; import com.lowagie.text.pdf.BaseFont; public class ItextHtmlTopdf { /** * * @param htmlStr html字符串 * @return * @throws Exception */ public String exportpdf(String htmlStr ) throws Exception { if (StringUtils.isBlank(htmlStr)) { return null; } htmlStr = htmlStr.trim().replaceAll("<","<").replaceAll( ">",">").replaceAll("<br/>","\n|\r\n|\r" ) .replaceAll(" "," "); htmlStr= htmlStr.replace("closingtags=\"\"", "/"); String classpath = this.getClass().getResource("/").getPath().replaceFirst("/", ""); String webappRoot = classpath.replaceAll("/target/classes", "/src/main/webapp"); //-----版本2.0.8 ITextRenderer renderer = new ITextRenderer(); OutputStream os = new FileOutputStream("C:/Users/Administrator/Desktop/createSamplePDF3.pdf"); // 如果携带图片则加上以下两行代码,将图片标签转换为Itext自己的图片对象,Base64ImgReplacedElementFactory为图片处理类 renderer.getSharedContext().setReplacedElementFactory(new Base64ImgReplacedElementFactory()); renderer.getSharedContext().getTextRenderer().setSmoothingThreshold(1); renderer.setDocumentFromString(htmlStr); ITextFontResolver fontResolver = renderer.getFontResolver(); // 解决中文支持问题,参数为字体的路径,html页面也必须引入字体 fontResolver.addFont(webappRoot+"static/sanalysis/simsun.ttf", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); renderer.layout(); renderer.createPDF(os); os.close(); return null; } }
Base64ImgReplacedElementFactory图片处理类
package cn.myc.ykt3.util; import java.io.IOException ; import org.w3c.dom.Element ; import org.xhtmlrenderer.extend.FSImage ; import org.xhtmlrenderer.extend.ReplacedElement ; import org.xhtmlrenderer.extend.ReplacedElementFactory ; import org.xhtmlrenderer.extend.UserAgentCallback ; import org.xhtmlrenderer.layout.LayoutContext ; import org.xhtmlrenderer.pdf.ITextFSImage ; import org.xhtmlrenderer.pdf.ITextImageElement ; import org.xhtmlrenderer.render.BlockBox ; import org.xhtmlrenderer.simple.extend.FormSubmissionListener ; import com.lowagie.text.BadElementException ; import com.lowagie.text.Image ; import com.lowagie.text.pdf.codec.Base64 ; public class Base64ImgReplacedElementFactory implements ReplacedElementFactory { /** * 实现createReplacedElement 替换html中的Img标签 * * @param c 上下文 * @param box 盒子 * @param uac 回调 * @param cssWidth css宽 * @param cssHeight css高 * @return ReplacedElement */ public ReplacedElement createReplacedElement(LayoutContext c, BlockBox box, UserAgentCallback uac, int cssWidth, int cssHeight) { Element e = box.getElement(); if (e == null) { return null; } String nodeName = e.getNodeName(); // 找到img标签 if (nodeName.equals("img")) { String attribute = e.getAttribute("src"); FSImage fsImage; try { // 生成itext图像 fsImage = buildImage(attribute, uac); } catch (BadElementException e1) { fsImage = null; } catch (IOException e1) { fsImage = null; } if (fsImage != null) { // 对图像进行缩放 if (cssWidth != -1 || cssHeight != -1) { fsImage.scale(cssWidth, cssHeight); } return new ITextImageElement(fsImage); } } return null; } /** * 将base64编码解码并生成itext图像 * * @param srcAttr 属性 * @param uac 回调 * @return FSImage * @throws IOException io异常 * @throws BadElementException BadElementException */ protected FSImage buildImage(String srcAttr, UserAgentCallback uac) throws IOException, BadElementException { FSImage fsImage; if (srcAttr.startsWith("data:image/")) { String b64encoded = srcAttr.substring(srcAttr.indexOf("base64,") + "base64,".length(), srcAttr.length()); // 解码 byte[] decodedBytes = Base64.decode(b64encoded); fsImage = new ITextFSImage(Image.getInstance(decodedBytes)); } else { fsImage = uac.getImageResource(srcAttr).getImage(); } return fsImage; } /** * 实现reset */ public void reset() { } @Override public void remove(Element arg0) {} @Override public void setFormSubmissionListener(FormSubmissionListener arg0) {} }
我的页面
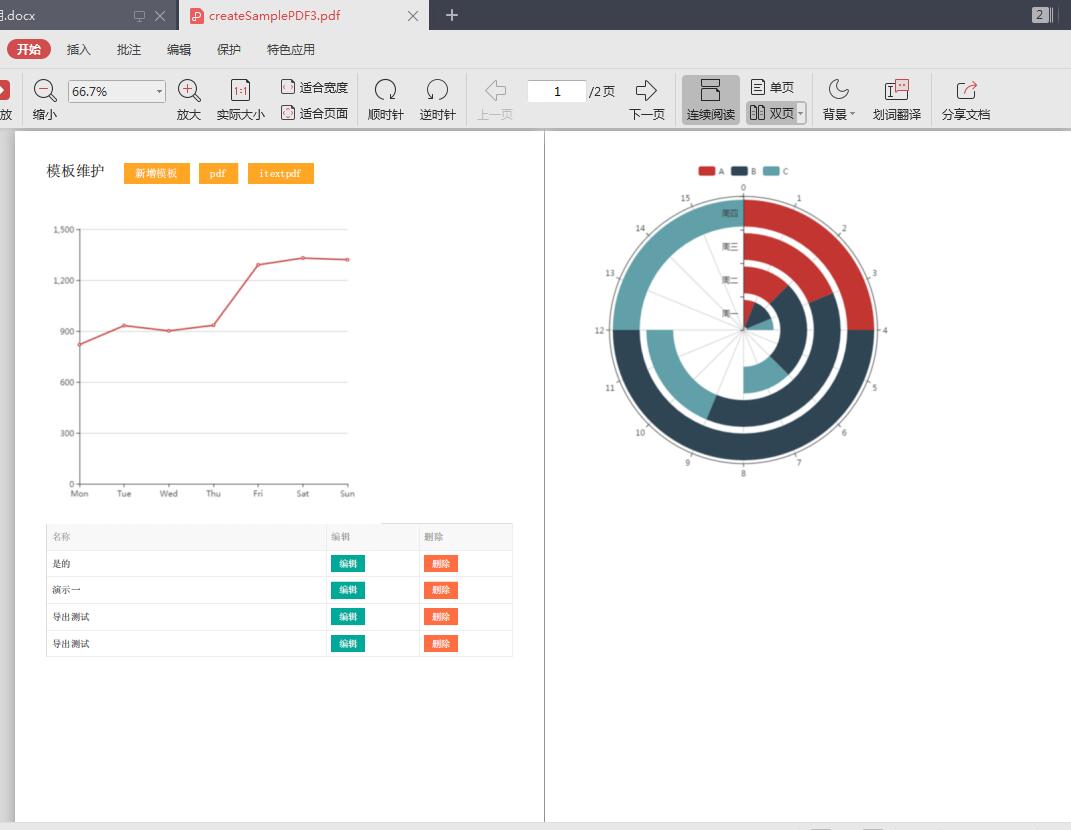
导出的pdf效果,自动分页,并且分页不会强制裁剪图片区域。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号