mongodb持久化
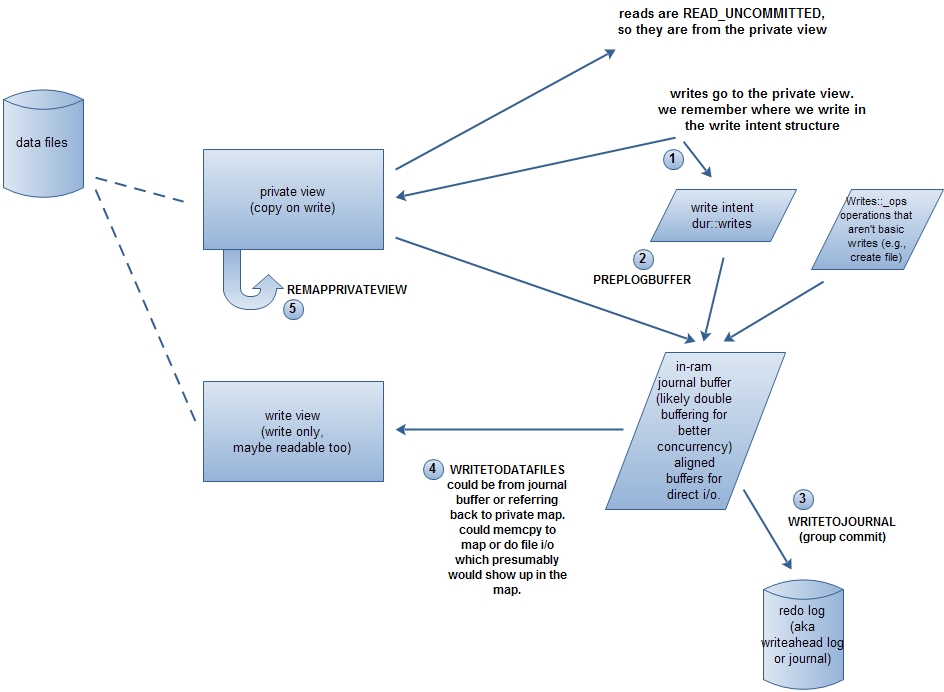
先上一张图(根据此处重画),看完下面的内容应该可以理解。
mongodb使用内存映射的方式来访问和修改数据库文件,内存由操作系统来管理。开启journal的情况,数据文件映射到内存2个view:private view和write view。对write view的更新会刷新到磁盘,而对private view的更新不刷新到磁盘。写操作先修改private view,然后批量提交(groupCommit),修改write view。
WriteIntent
发生写操作时,会记录修改的内存地址和大小,由结构WriteIntent表示。


/** Declaration of an intent to write to a region of a memory mapped view * We store the end rather than the start pointer to make operator< faster * since that is heavily used in set lookup. */ struct WriteIntent { /* copyable */ void *p; // intent to write up to p unsigned len; // up to this len void* end() const { return p; } bool operator < (const WriteIntent& rhs) const { return end() < rhs.end(); } // 用于排序 };
查看代码会发现大量的类似调用,这就是保存WriteIntent。
getDur().writing(..)
getDur().writingPtr(...)
CommitJob
CommitJob保存未批量提交的WriteIntent和DurOp,目前只使用一个全局对象commitJob。对于不修改数据库文件的操作,如创建文件(FileCreatedOp)、删除库(DropDbOp),不记录WriteIntent,而是记录DurOp。
ThreadLocalIntents
由于mongodb是多线程程序,同时操作CommitJob需要加锁(groupCommitMutex)。为了避免频繁加锁,使用了线程局部变量
/** so we don't have to lock the groupCommitMutex too often */ class ThreadLocalIntents { enum { N = 21 }; std::vector<dur::WriteIntent> intents; };
WriteIntent先存放到intents里,当intents的大小达到N时,就添加到CommitJob里,这时候要才需要加锁。添加intents到CommitJob时,会对重叠的内存地址段进行合并,减少WriteIntent的数量。当然,CommitJob也会对添加的WriteIntent进行检查是否重复添加。这里有一个问题,如果intents的大小没有达到N,是不是永远都不添加到CommitJob里呢?不会。因为每次写操作,必须先获得'w'锁(库的写锁)或者'W'锁(全局写锁),当释放锁的时候,也会把intents添加到全局的数组里。
何时groupCommit
写操作会先修改private view,并保存WriteIntent到CommitJob。但是private view是不持久化的,CommitJob保存的WriteIntent何时groupCommit?
const unsigned UncommittedBytesLimit = (sizeof(void*)==4) ? 50 * 1024 * 1024 : 100 * 1024 * 1024;
- durThread线程定期groupCommit,间隔时间可以由journalCommitInterval选项指定。默认是100毫秒(journal文件所在硬盘分区和数据文件所在硬盘相同)或者30毫秒。另外,如果有线程在等待groupCommit完成,或者未commit的字节数大于UncommittedBytesLimit / 2,会提前commit。
- 调用commitIfNeeded。如果未commit的字节数不小于UncommittedBytesLimit,或者是强制groupCommit,则执行groupCommit。
groupCommit的过程
1.PREPLOGBUFFER
首先是生成写操作日志(redo log)。对WriteIntent从小到大排序,这样可以对前后的WriteIntent进行重叠、重复的合并。对每个WriteIntent的地址,和每个数据文件的private view的基地址进行比较(private view的基地址已经排序,查找很快),找出其隶属的数据文件的标号。WriteIntent的地址减掉private view的基地址得到偏移,再从private view把修改的数据复制下来。这样数据文件标号、偏移、数据,形成一个JEntry。
2.WRITETOJOURNAL
把写操作日志压缩并写入journal文件。这一步完成之后,即使mongodb异常退出,数据也不会丢失了,因为可以根据journal文件中的写操作日志重建数据。关于journal文件可以参见这里。
3.WRITETODATAFILES
把所有写操作更新到write view中。后台线程DataFileSync会定期把write view刷新到磁盘中,默认是60秒,由syncdelay选项指定。
4.REMAPPRIVATEVIEW
private view是copy on write的,即在发生写时开辟新的内存,否则是和write view共用一块内存的。如果写操作很频繁,则private view会申请很多的内存,所以private view会remap,防止占用内存过多。并不是每次groupCommit都会remap,只有持有'W'锁的情况下才会remap。
durThread线程的定期groupCommit有三种情况会remap
- privateMapBytes >= UncommittedBytesLimit
- 前面9次groupCommit都没有ramap
- durOptions选项指定了DurAlwaysRemap
调用commitIfNeeded发生的groupCommit,如果持有持有'W'锁则remap。
remap的一个问题
在_REMAPPRIVATEVIEW()函数中,有这样一段代码
#if defined(_WIN32) || defined(__sunos__) // Note that this negatively affects performance. // We must grab the exclusive lock here because remapPrivateView() on Windows and // Solaris need to grab it as well, due to the lack of an atomic way to remap a // memory mapped file. // See SERVER-5723 for performance improvement. // See SERVER-5680 to see why this code is necessary on Windows. // See SERVER-8795 to see why this code is necessary on Solaris. LockMongoFilesExclusive lk; #else LockMongoFilesShared lk; #endif
执行remap时,需要LockMongoFiles锁。win32下,这把锁是排他锁;而其他平台下(linux等)是共享锁。write view刷新到磁盘的时候,也需要LockMongoFiles共享锁。这样,在win32下,如果在执行磁盘刷新操作,则remap操作会被阻塞;而在执行remap之前,已经获得了'W'锁,这样会阻塞所有的读写操作。因此,在win32平台下,太多的写操作(写操作越多,remap越频繁)会导致整个数据库读写阻塞。
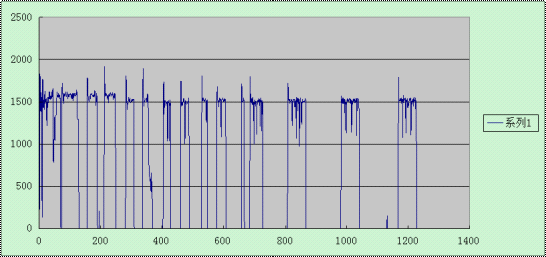
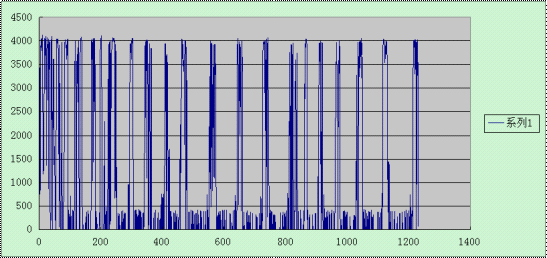
在win32和linux下做了一个测试,不停的插入大小为10k的记录。结果显示如下:上图win32平台,下图为linux平台;横坐标为时间轴,从0开始;纵坐标为每秒的插入次数。很明显的,linux平台的性能比win32好很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号