论文笔记 - Unsupervised Domain Adaptation by Backpropagation
摘要
- 提出了一个新的深度架构的域自适应方法,可在有大量标记数据的源数据和大量未标记数据的目标域上进行训练
- 该方法促进“深度特征”的出现(深度特征)
- 对于学习任务有主要判别作用的特征
- 关于域之间的移动不变性的特征
1. 介绍
-
常规的深度前馈结构:需要有大量已标记数据,或者用合成等方法获得大量训练数据。深度前馈结构在各种机器学习任务和应用中为最新技术带来了令人印象深刻的进步。(感觉就是基本的训练前馈模型)
-
本文意在将域自适应嵌入特征学习的过程中,以使得最终的分类器是基于 区分性 和 不变性 的特征构建的,这样在源域和目标域上有着相同或相似的分布,得到的网络可以应用于目标域,而不受两个域之间偏移的影响
-
作者关注的特征是既有 区分性 又有 不变性 的
- 区分性:对于该分类任务,特征是类别可区分的
- 不变性:特征对于两个域来说,是相似的
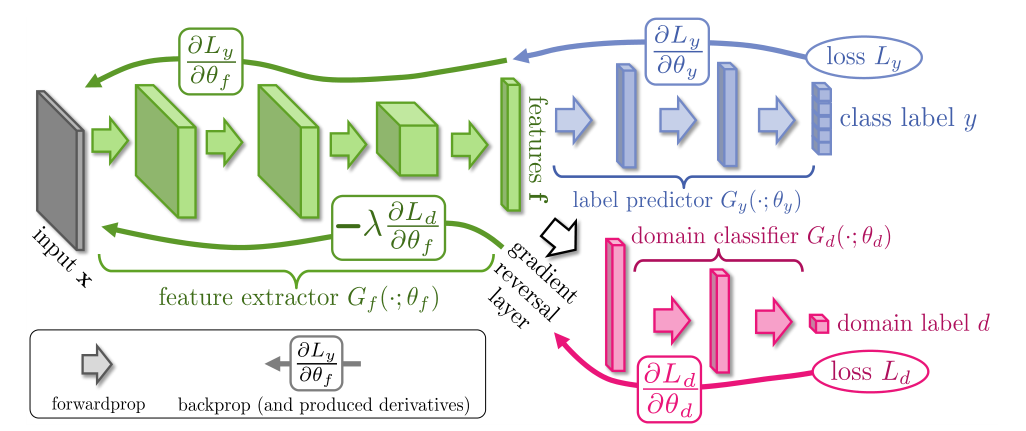
- 模型使用 特征提取层 ,标签预测器 ,域分类器 ,梯度反转层
- 训练域分类器,使其在训练集上误差最小
- 优化特征参数,最小化标签预测器的损失,最大化域分类器的损失
- 使用 梯度反转层 实现,正向传播时保持输入不变,反向传播通过 负号 来反转梯度
2. 相关工作
略
3. 深度域自适应
损失函数
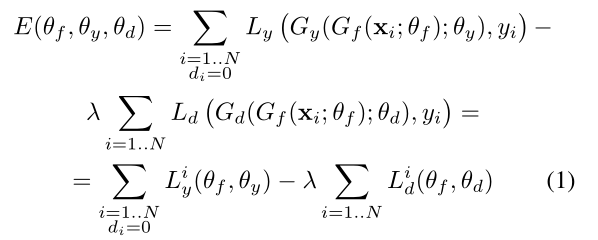
L 为负对数似然损失
Gy - 标签预测器 ; Ly - 标签预测器损失
Gf - 特征提取器
Gd - 域分类器 ; Ld - 域分类器损失
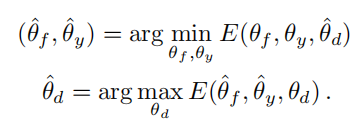
参数(θf , θy),使损失函数 E 最小;参数 θd ,使损失函数 E 最大
带入损失函数公式后,可这么理解:
- (θf , θy)使 E 最小,也就是使 Ly 最小,使 Ld 最大;和文章的思想一致,特征提取器 使 标签预测器 足够好,同时混淆 域分类器
- θd 使 E 最大,也就是使 Ld 最小;它提升域分类器的性能
反向传播优化
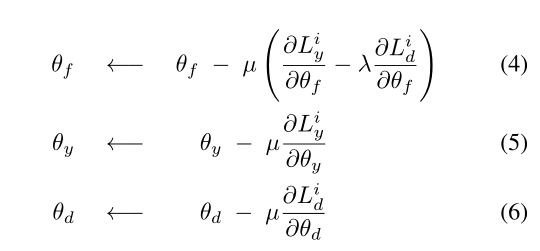
模型的优化和 SGD(随机梯度下降)非常相似,不同在于多了一个 -λ 的系数;这就不能直接作为 SGD 实现了,需要将它更新为 SGD 的形式。这可以用 梯度反转层(GRL) 实现。
GRL 插入在 特征提取器 和 域分类器 之间,当反向传播经过 GRL 时,GRL 将反传过来的偏导乘以 -λ ,继续传给上游。
在公式层面,构造一个伪函数,塞进去(其实一样的)
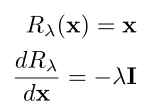
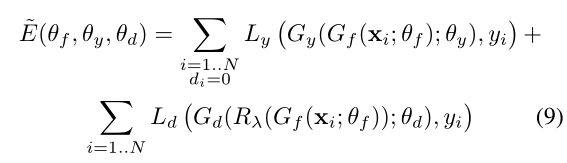
4. 实验
Baselines
Baseline:用于比较的实验模型
实验采用了以下 Baselines:
- 只使用源域样本训练,不考虑目标域样本
- 只使用带标签的目标域样本训练,这个模型作为性能上限(因为这不涉及到域迁移,应该性能最好)
- 此外,本文模型还和 基于子空间对齐(SA)的无监督 DA 方法进行了比较
ps:由于 SA 需要在最后重新训练一遍分类器,为了保证实验的公平,对于其它的方法最后也再训练一遍。
CNN architectures
1.特征提取器:2~3个卷积层
2.域分类器:3个全连接层(x → 1024 → 1024 → 2)
特别的对于MNIST数据集,使用(x → 100 → 2)加速训练
CNN training procedure.
训练批次128 ; 均值减法预处理 ;每批次一半源域一半目标域 ;为了在训练的抑制来自域分类器的噪声,没有固定自适应因子λ,而是用以下式子让它从0到1改变 ;γ设置为10
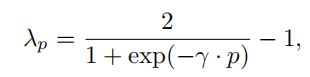
ps:实验结果和具体的结构见论文

 浙公网安备 33010602011771号
浙公网安备 33010602011771号