
[学习记录]python正则表达式
1.首先先介绍常见的元字符
| 表示法 | 描述 | 示例 |
| literal | 匹配字符串的字面值literal | python |
| re1|re2 | 匹配re1或re2 | python|java |
| . | 匹配\n之外的任意字符 | pyth.n |
| ^ | 匹配字符串起始部分 | (^begin)(得到的是begin开头) |
| $ | 匹配字符串终止部分 | (end$) |
| * | 匹配0次或多次前面的表达式 | h* |
| + | 匹配1次或多次前面的表达式 | h+ |
| ? | 匹配0次或1次前面的表达式 | h? |
| {N} | 匹配N次前面的表达式 | h{5} |
| {N,M} | 匹配N~M次前面的表达式 | h{4,6} |
| [abcde] | 匹配字符集中的任意单一字符 | [abcde] |
| [a-zA-Z] | 匹配范围内的任意单一字符 | [0-9a-zA-Z] |
| [^] | 不匹配此字符集内的或范围内的任意字符 | [^abcd1-9] |
| (*,+,?,{})? | 在上述匹配条件的后面加?,表示非贪婪匹配(尽可能少匹配) | a*?,a+?,a??,a{2}? |
| () | 内部可视为独立的正则表达式,另存为子组 | ([0-9].)[a-z] |
| \d | 匹配任何十进制数字,[0-9],\D与之相反 | \d |
| \w | 匹配任何字母与数字,[0-9a-zA-Z],\W与之相反 | \w |
| \s | 匹配任何空格字符,[\n\t\r\v\f],\S与之相反 | \s |
| \b | 匹配任何单词边界,\B与之相反 | the\b , \bthe ,但\B的位置并不影响结果 |
| \c | 匹配c的字面含义(转义) | \\,\. ,\* |
| \A | 匹配字符串开头,^ | \A |
| \Z | 匹配字符串结尾 ,& | \Z |
2.python中的re模块以及方法
re.match(pattern,string,flags=0) 尝试匹配,如果成功返回匹配对象,失败则返回none,其中flag可以选择为 re.I 即不区分大小写

re.search(pattern,string,flags=0) 使用可选标记搜索字符串中第一次出现的正则表达式模式,成功返回匹配对象,失败则返回none

re.findall(pattern,string,flags=0),查找所有符合条件的正则表达式模式,并返回一个列表
re.finditer(pattern,string,flags=0)同上,但返回的是一个迭代器
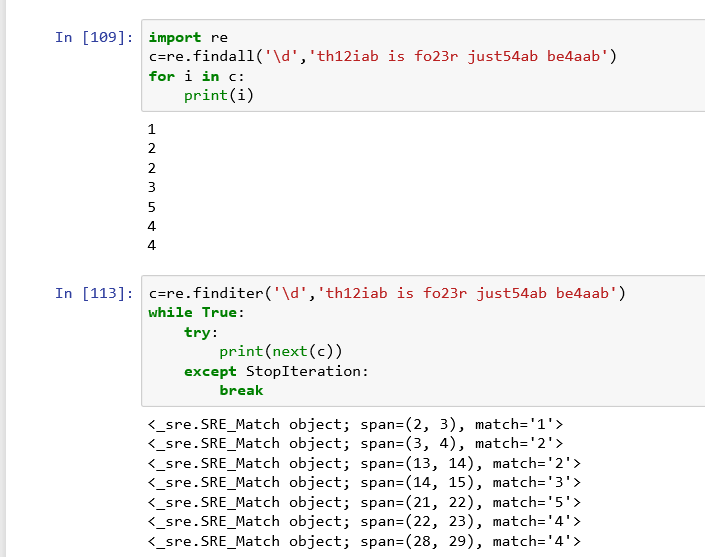
子串group

groups()则可以直接以元组形式返回

re.sub(pattern,replace,string,count=0)将string中符合pattern模式的字符串替换为replace,返回新字符串
re.subn与sub几乎一样,只是返回的时候多返回替换次数这个值

