JS破解--天X查股权穿透图
上个月有网友问我一道爬虫笔试题,是爬取某网站的股权穿透图
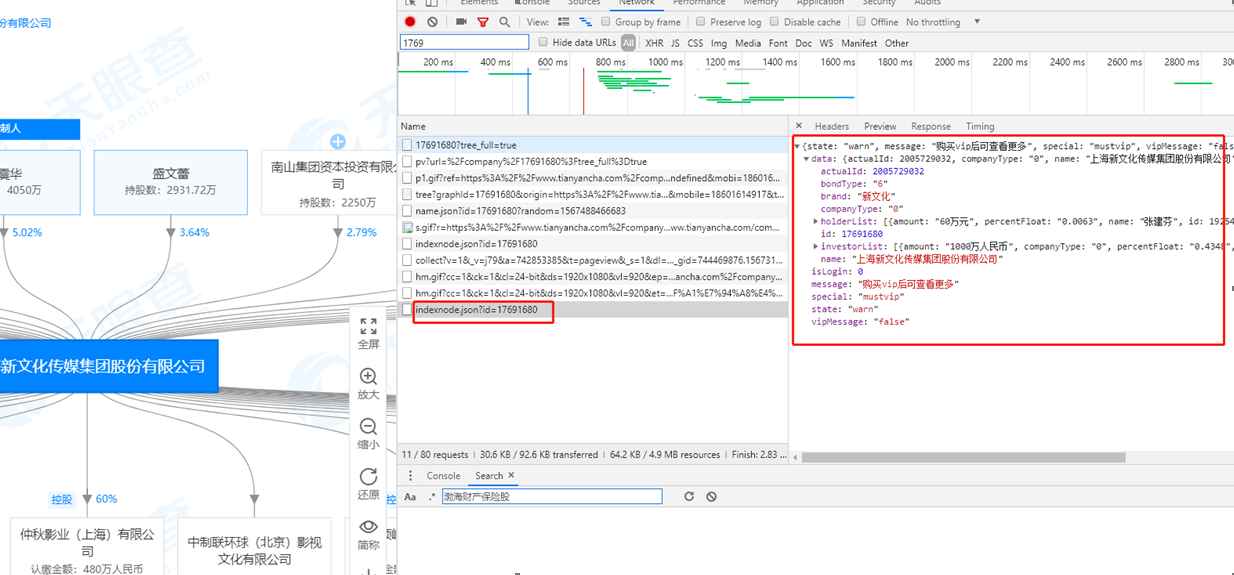
当时觉得抓包数据的头部改变不是很多,cookie里只有两个值不同,分别是cloud_token和cloud_utm,但是那会忙,没有帮他具体看一下,今天闲下来看了看。
首先,它是一个aoixs请求,是前台发给后台的请求,因为抓包明显看到发起两次请求,分别是option和get。直接去发起GET请求会403
接下来找请求的js,是走缓存的一个js,这里对它debug可能会有些卡
接下来打断点调试,获得两个参数的值
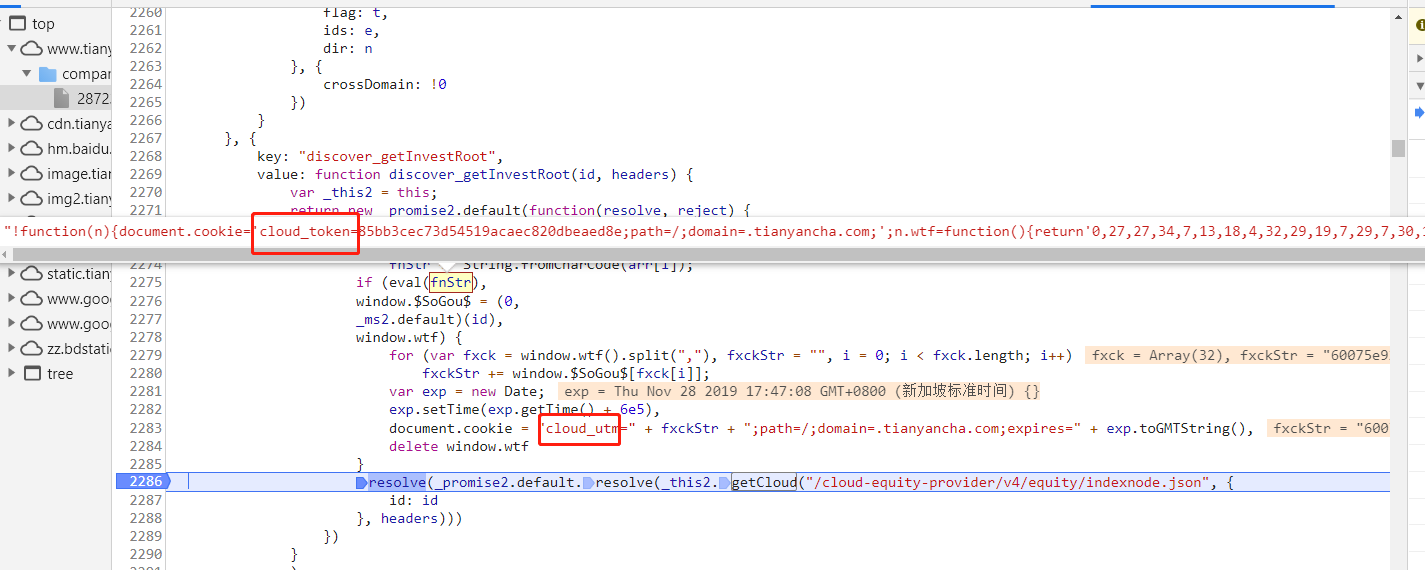
这里逻辑会有点乱,有大量混乱的换行,还好我重新进行编辑了一下,已经找到该有的信息了,接下来找对它们的生成方法就可以了
function discover_getInvestRoot(id, headers) { var _this2 = this; return new _promise2.default(function(resolve, reject) { _this2.pre_relation_company(id).then(function(res) { for (var data = res.data, arr = data.v.split(","), fnStr = "", i = 0; i < arr.length; i++) fnStr += String.fromCharCode(arr[i]); if (eval(fnStr), window.$SoGou$ = (0,_ms2.default)(id),window.wtf) { for (var fxck = window.wtf().split(","), fxckStr = "", i = 0; i < fxck.length; i++) fxckStr += window.$SoGou$[fxck[i]]; var exp = new Date; exp.setTime(exp.getTime() + 6e5), document.cookie = "cloud_utm=" + fxckStr + ";path=/;domain=.tianyancha.com;expires=" + exp.toGMTString(), delete window.wtf } resolve(_promise2.default.resolve(_this2.getCloud("/cloud-equity-provider/v4/equity/indexnode.json", {id: id}, headers))) })
}) }
首先这里传入的res为之前请求的name.json的返回值,这里可以直接模拟请求,但是要留意一个CLOUDID的值,这个在之后也需要用到
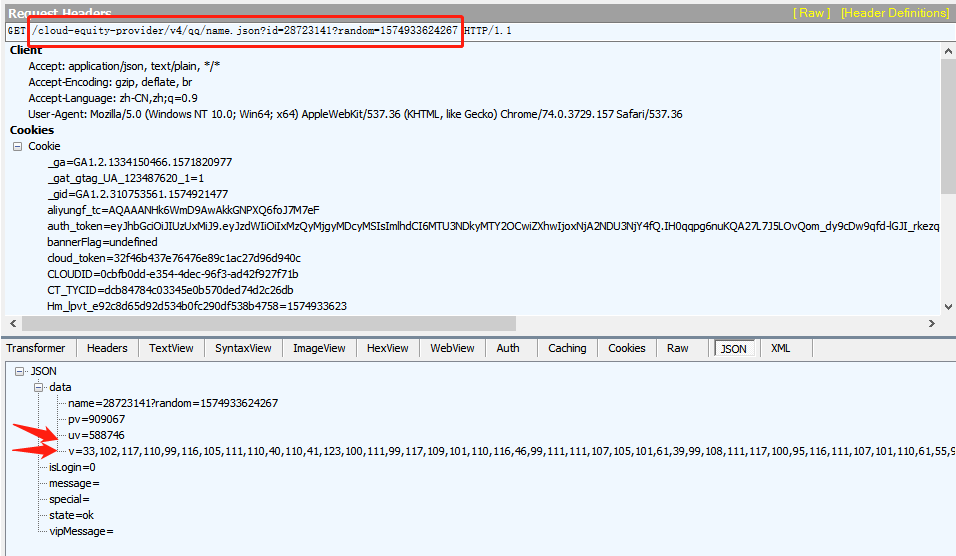
这里先利用返回的data里的v,通过 String.fromCharCode 进行遍历获得unicode值对应的字符串,拼接在一起就是fnStr,这也就是我们经常请求后发现这个返回的v总是有固定的数值的原因,因为这串fnStr需要被执行,从而固定的位置必须要能拼接为js的关键字。
这里window.wtf()就是fnstr内带有的wtf函数的返回值,而window.$SoGou$就是通过一个函数计算得到的,传入要查公司的id

这里window.$SoGou$的计算函数,这里我们传的id固定的话,所返回的值也是一定的。最后返回的是
return r = r.length > 1 ? r[1] : r, n._ff(r)
不要被换行所迷惑,这个网站JS好多恶意换行
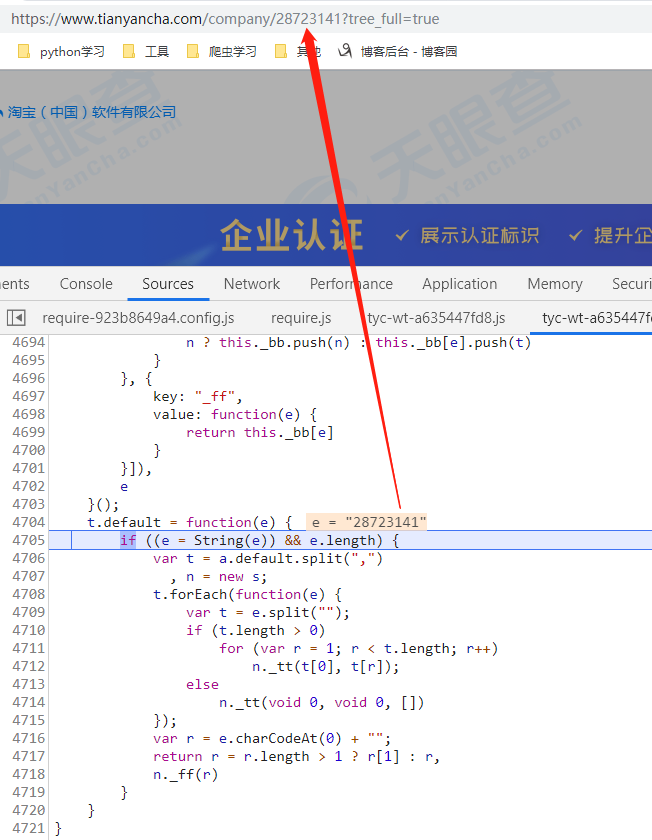
还是得讲一下这个函数,因为写代码时差点被绕进去了,这里传的e为要查公司的id,但是这里只要e正确,真正使用e的地方是4716行的这个e.charCodeAt(0)。那么之前那个function(e)是如何来的?其实这段JS里有个默认值default,这段逻辑是以,分割默认值default,再遍历这个数组,取第一位之后的值进行添加入数组,最后得到10个数组,每个长度为37,这个与wtf()的返回值长度对应。也就是说只要我们的默认值default不变,则this._bb就不变,就是这段其实我们可以不进行python代码复写,可以直接当作常量进行计算.
var r = e.charCodeAt(0) + "";
这句话意思是取 e的第0个位置字符的 ascii编码,转为字符串,也就是我们这里‘2’所对应的字符串编码为50
return r = r.length > 1 ? r[1] : r, n._ff(r)
这句话意思是 r.length永远大于1,因为r所对应的ascii编码只有个位数的那些都是特殊标识符,这些不可能作为id的首个字符,所以这里是恒取r[1]传入n._ff(r)中
这里我们返回的是"0",["6", "b", "t", "f", "2", "z", "l", "5", "w", "h", "q", "i", "s", "e", "c", "p", "m", "u", "9", "8", "y", "k", "j", "r", "x", "n", "-", "0", "3", "4", "d", "1", "a", "o", "7", "v", "g"]
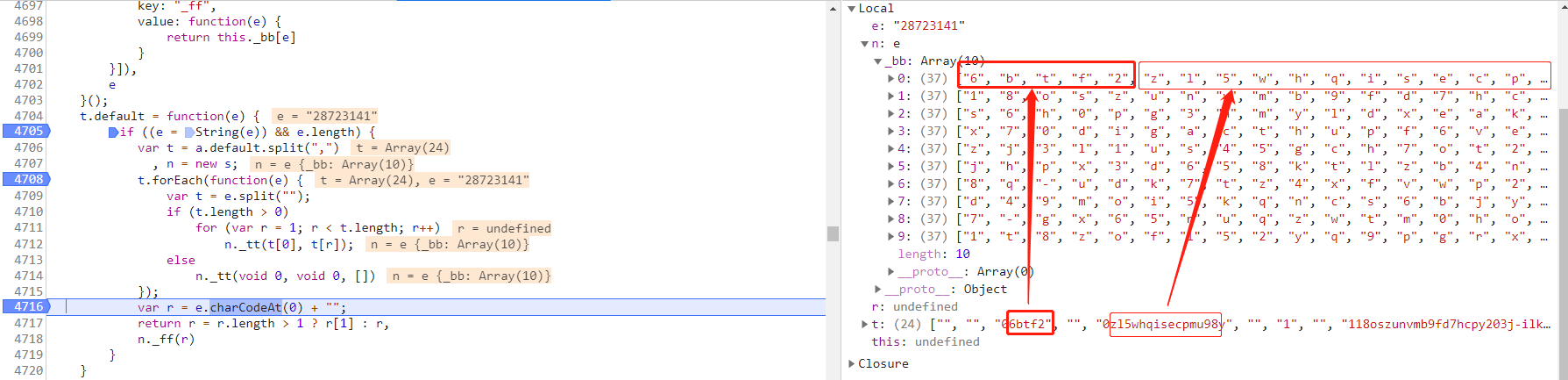
接下来拿到这个37位的数组之后因为游标问题window.wtf()应该都是37以内,进行遍历取值,得到window.wtf()长度的cloud_num
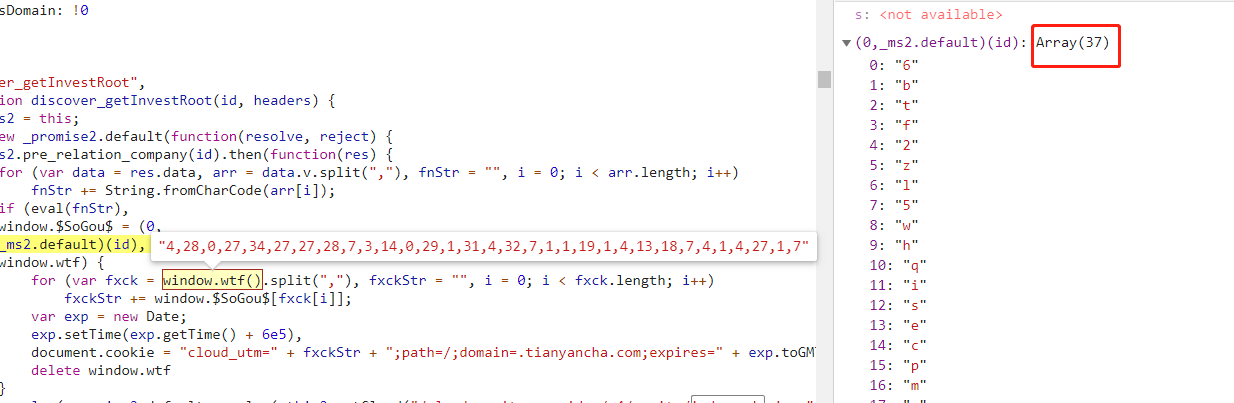
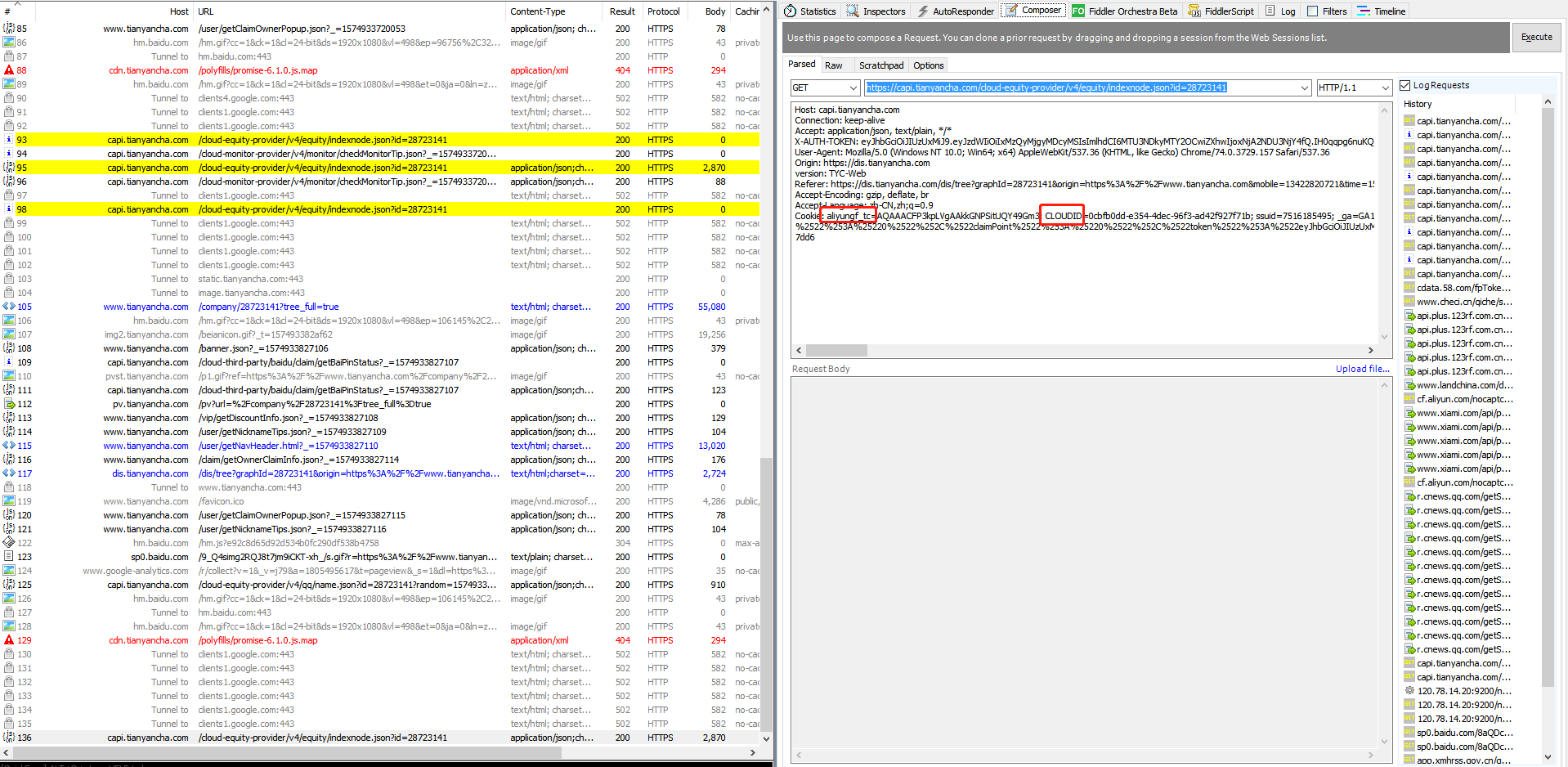
这样两个参数都找齐了,在控制台输入document.cookiem,然后可以试着进行请求,记得先发option后发get,在get请求时加上CLOUDID以及option后塞入的aliyungf_tc,这样就会返回200的数据了
import json import re import time import requests # 需要查找的id id = '3007689648' s = requests.Session() # 一个cookie过期时间还未定 headers = { "Host": "capi.tianyancha.com", "Connection": "keep-alive", "Origin": "https://dis.tianyancha.com", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36", "Accept": "application/json, text/plain, */*", "Referer": "https://dis.tianyancha.com/dis/tree?graphId={}&origin=https%3A%2F%2Fwww.tianyancha.com&mobile=&time=15753515647237b28&full=1".format( id), "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Cookie": "TYCID=d9727140157e11eaab41691f9a51d2ed; undefined=d9727140157e11eaab41691f9a51d2ed; ssuid=8686323904; bannerFlag=undefined; RTYCID=26963f4845324e7f8aaf1c9ca2159104; Hm_lvt_e92c8d65d92d534b0fc290df538b4758=1575344515; aliyungf_tc=AQAAAG/4CAKdyAcAnUEYdNm5vLgCnTNI; CLOUDID=756cffe2-228f-42ef-8e3f-528816e86384; CT_TYCID=20b71739a88447dd98725c23c08efc0f; _ga=GA1.2.199777249.1575344515; _gid=GA1.2.1748072841.1575344515; _gat_gtag_UA_123487620_1=1; Hm_lpvt_e92c8d65d92d534b0fc290df538b4758=1575351565;" } # js里有段默认值t.default,这里直接debug拿到默认值转换的数组 default_list = [ ["6", "b", "t", "f", "2", "z", "l", "5", "w", "h", "q", "i", "s", "e", "c", "p", "m", "u", "9", "8", "y", "k", "j", "r", "x", "n", "-", "0", "3", "4", "d", "1", "a", "o", "7", "v", "g"], ["1", "8", "o", "s", "z", "u", "n", "v", "m", "b", "9", "f", "d", "7", "h", "c", "p", "y", "2", "0", "3", "j", "-", "i", "l", "k", "t", "q", "4", "6", "r", "a", "w", "5", "e", "x", "g"], ["s", "6", "h", "0", "p", "g", "3", "n", "m", "y", "l", "d", "x", "e", "a", "k", "z", "u", "f", "4", "r", "b", "-", "7", "o", "c", "i", "8", "v", "2", "1", "9", "q", "w", "t", "j", "5"], ["x", "7", "0", "d", "i", "g", "a", "c", "t", "h", "u", "p", "f", "6", "v", "e", "q", "4", "b", "5", "k", "w", "9", "s", "-", "j", "l", "y", "3", "o", "n", "z", "m", "2", "1", "r", "8"], ["z", "j", "3", "l", "1", "u", "s", "4", "5", "g", "c", "h", "7", "o", "t", "2", "k", "a", "-", "e", "x", "y", "b", "n", "8", "i", "6", "q", "p", "0", "d", "r", "v", "m", "w", "f", "9"], ["j", "h", "p", "x", "3", "d", "6", "5", "8", "k", "t", "l", "z", "b", "4", "n", "r", "v", "y", "m", "g", "a", "0", "1", "c", "9", "-", "2", "7", "q", "e", "w", "u", "s", "f", "o", "i"], ["8", "q", "-", "u", "d", "k", "7", "t", "z", "4", "x", "f", "v", "w", "p", "2", "e", "9", "o", "m", "5", "g", "1", "j", "i", "n", "6", "3", "r", "l", "b", "h", "y", "c", "a", "s", "0"], ["d", "4", "9", "m", "o", "i", "5", "k", "q", "n", "c", "s", "6", "b", "j", "y", "x", "l", "a", "v", "3", "t", "u", "h", "-", "r", "z", "2", "0", "7", "g", "p", "8", "f", "1", "w", "e"], ["7", "-", "g", "x", "6", "5", "n", "u", "q", "z", "w", "t", "m", "0", "h", "o", "y", "p", "i", "f", "k", "s", "9", "l", "r", "1", "2", "v", "4", "e", "8", "c", "b", "a", "d", "j", "3"], ["1", "t", "8", "z", "o", "f", "l", "5", "2", "y", "q", "9", "p", "g", "r", "x", "e", "s", "d", "4", "n", "b", "u", "a", "m", "c", "h", "j", "3", "v", "i", "0", "-", "w", "7", "k", "6"], ] def getfnstr(data): fnstr = "" for i in data.split(','): fnstr += chr(int(i)) return fnstr def getSogo(default_list, id): r = str(ord(id[0])) return default_list[int(r[1])] def getfxckStr(fxck, window_sogo): fxckStr = "" for i in fxck.split(','): fxckStr += window_sogo[int(i)] return fxckStr # 获取前置参数 random为13位时间戳 res1 = s.get("https://capi.tianyancha.com/cloud-equity-provider/v4/qq/name.json?id={}?random={}".format(id, str( int(time.time() * 1000))), headers=headers) data_dict = json.loads(res1.content)["data"] # 调用加密函数,获取cloud_token 以及cloud_utm fnstr = getfnstr(data_dict.get('v')) cookie_token = re.search('cookie=\'cloud_token\=(.*?)\;', fnstr).group(1) wtf_return = re.search('return\'(.*?)\'', fnstr).group(1) window_sogo = getSogo(default_list, id) # cloud_utm fxckStr = getfxckStr(wtf_return, window_sogo) headers["Cookie"] = headers["Cookie"] + " cloud_utm=" + fxckStr + "; cloud_token=" + cookie_token + ';' res2 = s.get('https://capi.tianyancha.com/cloud-equity-provider/v4/equity/indexnode.json?id={}'.format(id), headers=headers) text = json.loads(res2.text) print(text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号