
Scrapy爬虫学习及实战
Scrapy基本功能
1、基本功能
Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
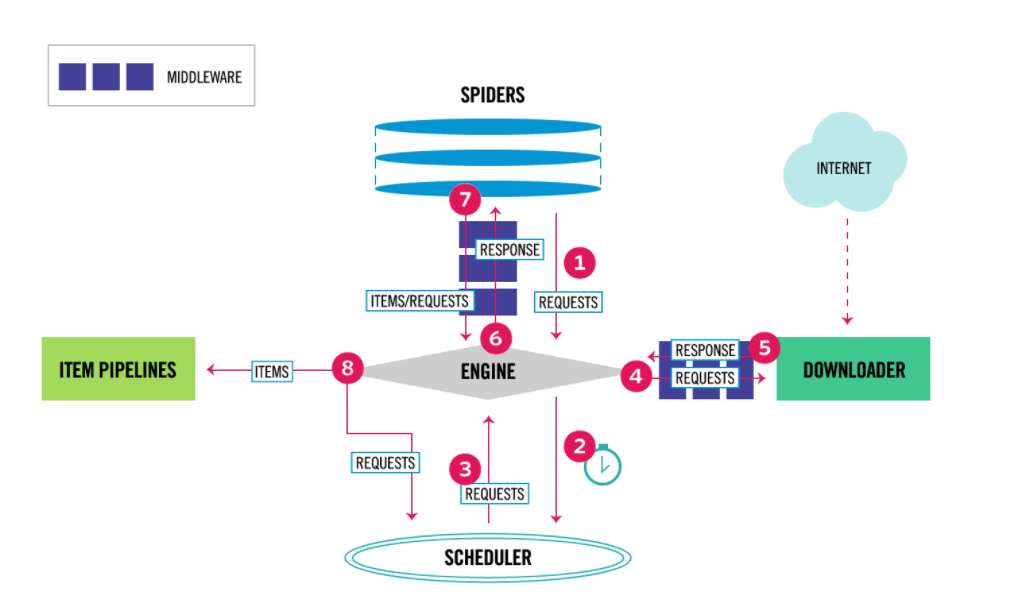
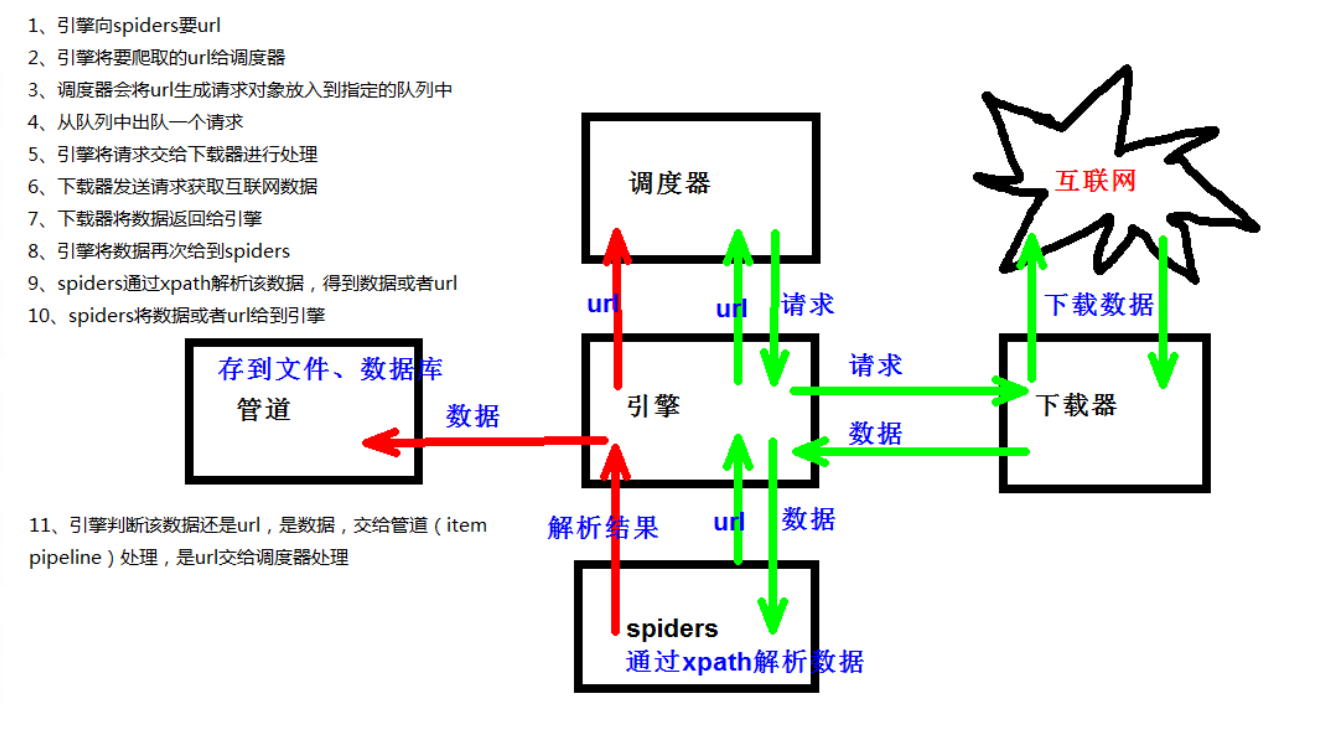
2、架构
- Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。


3、scrapy项目的结构
项目名字
项目的名字
spiders文件夹(存储的是爬虫文件)
init
自定义的爬虫文件 核心功能文件
init
items 定义数据结构的地方 爬虫的数据都包含哪些
middleware 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 robots协议 ua定义等
工作流程
以爬取http://quotes.toscrape.com/网站数据为例,原视频教程参考:https://www.bilibili.com/video/BV1To4y1C7eh/?p=42
请继续往下看。。。
创建 Spider
- Spider是自己定义的类,Scrapy用它从网页里抓取内容,并解析抓取后的结果;
- Spider类必须是继承Scrapy提供的Spider类scrapy.Spider;
- 要定义Spider的名称和起始请求,以及怎样处理抓取后的结果的方法。
比如,使用命令创建一个名为:tutorial的爬虫项目:
scrapy startproject tutorial
再创建Spider,起名为Quotes,则通过以下命令:
cd tutorial
scrapy genspider quotes
定义Spider, 将quotes.py修改如下:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
pass
创建 Item
- item是保存爬取数据的容器;
- 与字典相比,item多了额外的保护机制,可以避免拼写错误或定义字段错误;
- 创建item需要继承 scrapy.Item类,并且定义类型为 scrapy.Field的字段;
- 观察目标网站,可以获取到的内容有 text, author, tags
定义Item, 将items.py修改如下:
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
解析 Response
- parse 方法的参数 response 是 start_urls的链接爬取后的结果;
- 在 parse 方法中,可以直接对response变量包含的内容进行解析;
- 比如浏览请求结果的网页源代码, 或者进一步分析源代码的内容;
- 或者找出结果中的链接而得到下一个请求。
此时,我们用chrome打开地址:http://quotes.toscrape.com/
使用CSS选择器进行选择,parse方法改写如下:
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags::text').extract()
对于这一段代码,解释如下:
这段代码是使用CSS选择器从网页中提取数据,通常用于网络爬虫或数据提取应用。这些代码的含义如下:
text = quote.css('.text::text').extract_first():
quote 是一个用于CSS选择的选择器对象。
css('.text::text') 选择了所有类名为 text 的元素,并提取了这些元素的纯文本内容,是一个长度为1的列表,所以要用extract_first() 方法,提取选中元素的第一个实例的文本内容。最终,text 变量被赋值为提取的文本内容,即第一个匹配到的类名为 text 的元素的文本。
author = quote.css('.author::text').extract_first():
css('.author::text') 选择了所有类名为 author 的元素,并提取了这些元素的纯文本内容。
extract_first() 方法用于提取选中元素的第一个实例的文本内容。
最终,author 变量被赋值为提取的文本内容,即第一个匹配到的类名为 author 的元素的文本。
tags = quote.css('.tags::text').extract():
css('.tags::text') 选择了所有类名为 tags 的元素,并提取了这些元素的纯文本内容。
extract() 方法用于提取选中元素的所有实例的文本内容,并返回一个包含这些文本的列表。
最终,tags 变量被赋值为提取的文本内容的列表,即所有匹配到的类名为 tags 的元素的文本。
parse方法对以下代码进行分析的过程

quote.css('.text')的结果如下:

quote.css('.text::text')的结果如下:

quote.css('.text::text').extract()的结果如下:

quote.css('.text::text').extract_first()的结果如下:

使用Item
Item可以理解为一个字典,在声明的时候需要实例化。然后依次用刚才解析的结果赋值给Item的每一个字段,最后将Item返回。
因此,代码就变成了:
import scrapy
from tutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags::text').extract()
yield item
后续 Request (下一页的内容如何抓取?)
思路:
要从当前的页面找到信息来生成下一个请求,然后在下一个请求的页面里找到信息,再构造下一个请求,依次循环往复迭代。
构造请求时需要用到 scrapy.Request, 这里传递两个参数: url 和 callback
url:是请求链接
callback:是回调函数,当指定了该回调函数的请完成之后,获取到响应,引擎会将该响应作为参数传递给这个回调函数,回调函数进行解析或生成下一个请求,回调函数如上文的parse()所示。
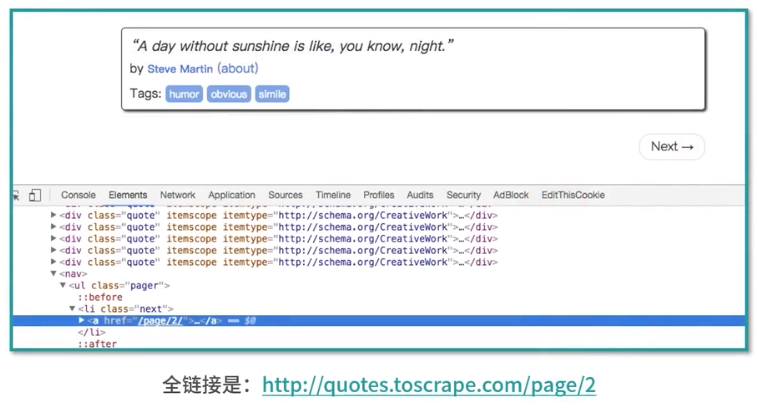
利用选择器得到下一页链接并生成请求,在parse方法后追加如下代码
next = response.css('.pager.next a::attr(herf)').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)
运行
进入目录,运行命令: scrapy crawl quotes
保存到文件
Scrapy 提供的 Feed Exports 可以轻松将抓取结果输出。
例如,将上面的结果保存到JSON文件
scrapy crawl quotes -o quotes.json
也可以每一个Item输出一行JSON, 输出后缀为jl, 为jsonline的缩写
scrapy crawl quotes -o quotes.jl
或
scrapy crawl quotes -o quotes.jsonlines
输出格式还支持 csv, xml, pickle, marshal等,还支持 ftp, s3等远程输出
另外,可以通过自定义的 ItemExporter来实现其他的输出。

使用 Item Pipeline 输出到 MongoDB数据库
如果想进行更复杂的操作,比如将结果保存到MongoDB数据库,可以定义Item Pipeline来实现,Item Pipeline为项目管道,当Item生成后它会自动被送到Item Pipeline进行处理。实现Item Pipeline, 只需要定义一个类并实现 process_item方法即可。
Item Pipeline的作用:
- 清洗HTML数据;
- 验证爬取数据,检查爬取字段;
- 查重并丢弃重复内容;
- 将爬取结果储存到数据库
process_item方法必须返回包含数据的字典或Item对象,或抛出 DropItem异常。
process_item方法有两个参数:
- item, 每次Spider生成的Item都会作为参数传递过来;
- spider, 是Spider的实例。
视频演示代码地址:
https://github.com/Python3WebSpider/ScrapyTutorial
Scrapy Shell用法
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据,但是一般使用的不多。感兴趣的查看官方文档:
官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.html
Scrapy Shell根据下载的页面会自动创建一些方便使用的对象,例如 Response 对象,以及 Selector 对象 (对HTML及XML内容)。
当shell载入后,将得到一个包含response数据的本地 response 变量,输入 response.body将输出response的包体,输出 response.headers 可以看到response的包头。
输入 response.selector 时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用 response.selector.xpath()或response.selector.css() 来对 response 进行查询。
Scrapy也提供了一些快捷方式, 例如 response.xpath()或response.css()同样可以生效(如之前的案例)。Selectors选择器 “Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制”
Selector有四个基本的方法,最常用的还是xpath:
- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
- extract(): 序列化该节点为字符串并返回list
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
- re(): 根据传入的正则表达式对数据进行提取,返回字符串list列表
XPATH语法及用法
参考资料:
基础入门:https://zhuanlan.zhihu.com/p/35355747
https://www.w3school.com.cn/xpath/index.asp
https://www.runoob.com/xpath/xpath-syntax.html
https://developer.mozilla.org/zh-CN/docs/Web/XPath
实战
从原理到实战,一份详实的 Scrapy 爬虫教程
Scrapy实战 | 带大家写个大众点评小爬虫吧~
百度地图接口:https://lbsyun.baidu.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号