
DataFrame concat/join/merge 用法
1 concat
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False)
参数说明
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
join:连接的方式 inner,或者outer
1.1 相同字段的表首尾相接
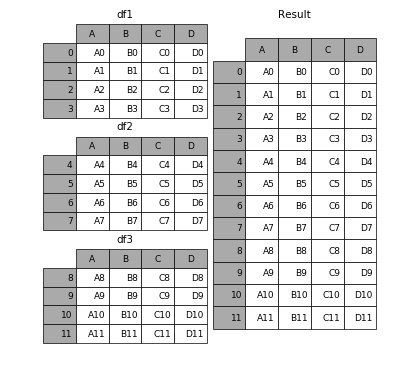
三个 df 使用以下命令合并:
result = pd.concat([df1, df2, df3])
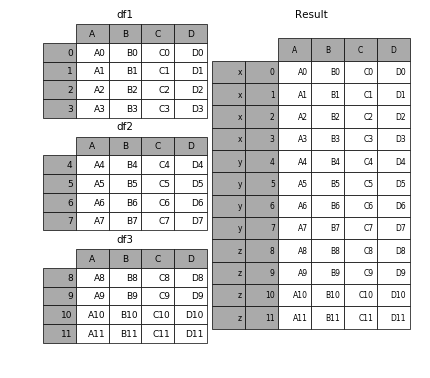
如果要在相接的时候在加上一个层次的key来识别数据源自于哪张表,可以增加key参数
result = pd.concat(frames, keys=['x', 'y', 'z'])
效果如下
1.2 横向表拼接(行对齐)
1.2.1 axis
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
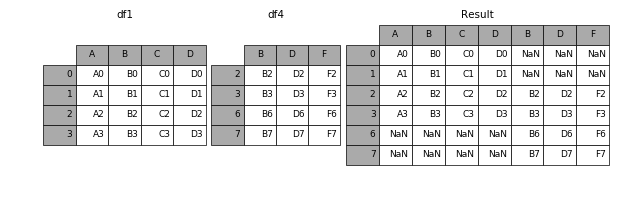
result = pd.concat([df1, df4], axis=1)
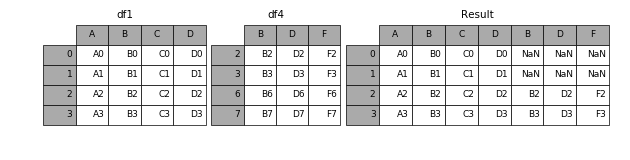
1.2.2 join
加上join参数的属性,如果为’inner’得到的是两表的交集,如果是outer,得到的是两表的并集。

result = pd.concat([df1, df4], axis=1, join='inner')
1.2.3 join_axes (该参数已停用)
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
1.3 append
append是series和dataframe的方法,使用它就是默认沿着列进行凭借(axis = 0,列对齐)

result = df1.append(df2)
1.4 无视index的concat
如果两个表的index都没有实际含义,使用ignore_index参数,置true,合并的两个表就睡根据列字段对齐,然后合并。最后再重新整理一个新的index。
这里写图片描述

1.5 合并的同时增加区分数据组的键
前面提到的keys参数可以用来给合并后的表增加key来区分不同的表数据来源
1.5.1 可以直接用key参数实现

result = pd.concat(frames, keys=['x', 'y', 'z'])
1.5.2 传入字典来增加分组键
pieces = {'x': df1, 'y': df2, 'z': df3}

result = pd.concat(pieces)
1.6 在dataframe中加入新的行
append方法可以将 series 和 字典就够的数据作为dataframe的新一行插入。
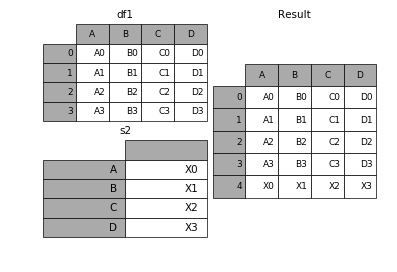
s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
result = df1.append(s2, ignore_index=True)
表格列字段不同的表合并
如果遇到两张表的列字段本来就不一样,但又想将两个表合并,其中无效的值用nan来表示。那么可以使用ignore_index来实现。
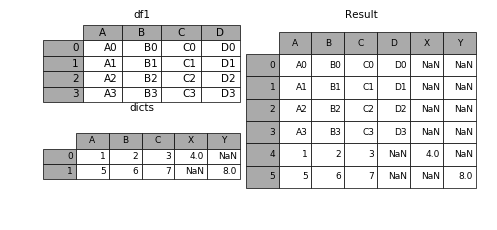
dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
{'A': 5, 'B': 6, 'C': 7, 'Y': 8}]result = df1.append(dicts, ignore_index=True)
merge
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
left︰对象
right︰另一个对象
on︰要加入的列(名称)。必须在左、右综合对象中找到。如果不能通过left_index和right_index是假,将推断DataFrames中的列的交叉点为连接键
left_on︰从左边的综合使用作为键列。可以是列名或数组的长度等于长度综合
right_on︰从正确的综合,以用作键列。可以是列名或数组的长度等于长度综合
left_index︰如果为True,则使用索引(行标签)从左综合作为其联接键。在与多重(层次)的综合,级别数必须匹配联接键从右综合的数目
right_index︰相同用法作为正确综合left_index
how︰之一'左','右','外在'、'内部'。默认为内部。每个方法的更详细说明请参阅︰
sort︰综合通过联接键按字典顺序对结果进行排序。默认值为True,设置为False将提高性能极大地在许多情况下
suffixes︰字符串后缀并不适用于重叠列的元组。默认值为('_x','_y')。
copy︰即使重新索引是不必要总是从传递的综合对象,复制的数据(默认值True)。在许多情况下不能避免,但可能会提高性能/内存使用情况。可以避免复制上述案件有些病理但尽管如此提供此选项。
indicator︰将列添加到输出综合呼吁_merge与信息源的每一行。_merge是绝对类型,并对观测其合并键只出现在'左'的综合,观测其合并键只会出现在'正确'的综合,和两个如果观察合并关键发现在两个right_onlyleft_only的值。
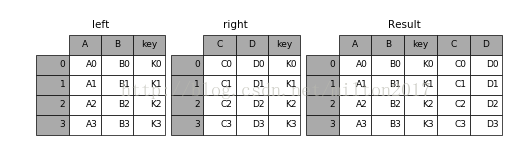
result = pd.merge(left, right, on='key')
result = pd.merge(left, right, on=['key1', 'key2'])
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
join
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True, how='left', sort=False)
result = left.join(right, on='key')
result = left.join(right, on=['key1', 'key2'])
result = left.join(right, on=['key1', 'key2'], how='inner')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号