
python下的数据拼接
使用pandas拼接
1. pd.merge()
功能:用于通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN。
语法如下:
merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False,
sort=True, suffixes=('_x', '_y'), copy=True, indicator=False)
应用场景是:把主键相同,字段不同的两张表合并到一张表里。结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量。
on=None 用于显示指定列名(键名),如果该列在两个对象上的列名不同,则可以通过 left_on=None, right_on=None 来分别指定。或者想直接使用行索引作为连接键的话,就将 left_index=False, right_index=False 设为 True。
how='inner' 参数指的是当左右两个对象中存在不重合的键时,取结果的方式:inner 代表交集;outer 代表并集;left 和 right 分别为取一边。
suffixes=('_x','_y') 指的是当左右对象中存在除连接键外的同名列时,结果集中的区分方式,可以各加一个小尾巴。
对于多对多连接,结果采用的是行的笛卡尔积。
参数说明:
left与right:两个不同的DataFrame
how:指的是合并(连接)的方式有inner(内连接),left(左外连接),right(右外连接),outer(全外连接);默认为inner
on : 指的是用于连接的列索引名称。必须存在右右两个DataFrame对象中,如果没有指定且其他参数也未指定则以两个DataFrame的列名交集做为连接键
left_on:左则DataFrame中用作连接键的列名;这个参数中左右列名不相同,但代表的含义相同时非常有用。
right_on:右则DataFrame中用作 连接键的列名
left_index:使用左则DataFrame中的行索引做为连接键
right_index:使用右则DataFrame中的行索引做为连接键
sort:默认为True,将合并的数据进行排序。在大多数情况下设置为False可以提高性能
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x','_y')
copy:默认为True,总是将数据复制到数据结构中;大多数情况下设置为False可以提高性能
indicator:将列添加到输出综合呼吁_merge与信息源的每一行。_merge是绝对类型,并对观测其合并键只出现在'左'的综合,观测其合并键只会出现在'正确'的综合,
和两个如果观察合并关键发现在两个right_onlyleft_only的值。在 0.17.0中还增加了一个显示合并数据中来源情况;如只来自己于左边(left_only)、两者(both)
我们先上实例,再分析解说
df1=DataFrame({'key':['a','b','b'],'data1':range(3)})
df2=DataFrame({'key':['a','b','c'],'data2':range(3)})
pd.merge(df1,df2)
结果:
df1
Out[3]:
key data1
0 a 0
1 b 1
2 b 2
df2
Out[4]:
key data2
0 a 0
1 b 1
2 c 2
df
Out[5]:
key data1 data2
0 a 0 0
1 b 1 1
2 b 2 1
注意,pandas拼接的要求是,有一列相同,每列长度相同。长度不同时,会提示:raise ValueError("arrays must all be same length")
如果:把上面的数据改一下,会得到什么呢?
df1=pd.DataFrame({'key':['a','b','b'],'data1':range(3)})
df2=pd.DataFrame({'key':['x','y','z'],'data2':range(3)})
df=pd.merge(df1,df2)
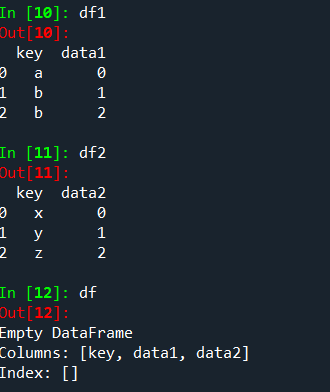
将上面的语句修改一下:
df=pd.merge(df1,df2,how='outer',on='key')
df
Out[33]:
key data1 data2
0 a 0.0 NaN
1 b 1.0 NaN
2 b 2.0 NaN
3 x NaN 0.0
4 y NaN 1.0
5 z NaN 2.0
如果觉得这样得到的结果不好看,把NaN用0代替,可以用下面的语句
df1=pd.merge(df1,df2,how='outer',on='key').fillna(0)
df1
Out[35]:
key data1 data2
0 a 0.0 0.0
1 b 1.0 0.0
2 b 2.0 0.0
3 x 0.0 0.0
4 y 0.0 1.0
5 z 0.0 2.0
pandas.merge()的outer连接
right=pd.DataFrame({'key1':['foo','foo','bar','bar'],
'key2':['one','one','one','two'],
'lval':[4,5,6,7]})
left=pd.DataFrame({'key1':['foo','foo','bar'],
'key2':['one','two','one'],
'lval':[1,2,3]})
df_outer= pd.merge(left,right,on=['key1','key2'],how='outer')
得到:
####right
Out[18]:
key1 key2 lval
0 foo one 4
1 foo one 5
2 bar one 6
3 bar two 7
####left
Out[19]:
key1 key2 lval
0 foo one 1
1 foo two 2
2 bar one 3
####df_outer
Out[21]:
key1 key2 lval_x lval_y
0 foo one 1.0 4.0
1 foo one 1.0 5.0
2 foo two 2.0 NaN
3 bar one 3.0 6.0
4 bar two NaN 7.0
如果两个对象的列名不同,可以分别指定,例:pd.merge(df1,df2,left_on='lkey',right_on='rkey')
df3=pd.DataFrame({'key3':['foo','foo','bar','bar'], #将上面的right的key 改了名字
'key4':['one','one','one','two'],
'lval':[4,5,6,7]})
df_on=pd.merge(left,df3,left_on='key1',right_on='key3') #键名不同的连接
得到:
left
Out[19]:
key1 key2 lval
0 foo one 1
1 foo two 2
2 bar one 3
df3
Out[24]:
key3 key4 lval
0 foo one 4
1 foo one 5
2 bar one 6
3 bar two 7
df_on
Out[25]:
key1 key2 lval_x key3 key4 lval_y
0 foo one 1 foo one 4
1 foo one 1 foo one 5
2 foo two 2 foo one 4
3 foo two 2 foo one 5
4 bar one 3 bar one 6
5 bar one 3 bar two 7
join 拼接列,主要用于索引上的合并
join方法提供了一个简便的方法用于将两个DataFrame中的不同的列索引合并成为一个DataFrame
join(self, other, on=None, how='left', lsuffix='', rsuffix='',sort=False)
其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how=left
1.默认按索引合并,可以合并相同或相似的索引,不管他们有没有重叠列。
2.可以连接多个DataFrame
3.可以连接除索引外的其他列
4.连接方式用参数how控制
5.通过lsuffix='', rsuffix='' 区分相同列名的列
concat 可以沿着一条轴将多个对象堆叠到一起
concat方法相当于数据库中的全连接(UNION ALL),可以指定按某个轴进行连接,也可以指定连接的方式join(outer,inner 只有这两种)。
与数据库不同的时concat不会去重,要达到去重的效果可以使用drop_duplicates方法
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True)
轴向连接 pd.concat() 就是单纯地把两个表拼在一起,这个过程也被称作连接(concatenation)、绑定(binding)或堆叠(stacking)。
因此可以想见,这个函数的关键参数应该是 axis,用于指定连接的轴向。
在默认的 axis=0 情况下,pd.concat([obj1,obj2]) 函数的效果与 obj1.append(obj2) 是相同的;
而在 axis=1 的情况下,pd.concat([df1,df2],axis=1) 的效果与 pd.merge(df1,df2,left_index=True,right_index=True,how='outer') 是相同的。
可以理解为 concat 函数使用索引作为“连接键”。
本函数的全部参数为:
objs 就是需要连接的对象集合,一般是列表或字典;
axis=0 是连接轴向join='outer' 参数作用于当另一条轴的 index 不重叠的时候,只有 'inner' 和 'outer' 可选(顺带展示 ignore_index=True 的用法)
concat 一些特点:
1.作用于Series时,如果在axis=0时,类似union。axis=1 时,组成一个DataFrame,索引是union后的,列是类似join后的结果。
2.通过参数join_axes=[] 指定自定义索引。
3.通过参数keys=[] 创建层次化索引
4.通过参数ignore_index=True 重建索引。
===
数据量大时生成DataFrame,应避免使用append方法
因为:
与python列表中的append和extend方法不同的是pandas的append方法不会改变原来的对象,而是创建一个新的对象。当然,这样的话会使效率变低而且会占用更多内存,所以如果你有很多数据需要append,建议使用列表,然后传给DataFrame。
建议直接用空列表依次装好各列的数据,再统一生成总的dataframe表,如下例所示。
import pandas as pd
import numpy as np
from datetime import datetime
# 模拟生成较大批次量的数据
df_list = [pd.DataFrame({
'a': [np.random.rand() for _ in range(20000)],
'b': [np.random.rand() for _ in range(20000)]
}) for i in range(800)]
# %% 第一种方式(运行时间最长——1分钟,内存占用一般)
start1 = datetime.now()
res1 = pd.DataFrame()
for df in df_list:
res1 = res1.append(df)
print('append耗时:%s秒' % (datetime.now() - start1))
# %% 第二种方式(运行时间相对第一种少一些——46秒,但内存接近溢出)
start2 = datetime.now()
dict_list = [df.to_dict() for df in df_list]
combine_dict = {}
i = 0
for dic in dict_list:
length = len(list(dic.values())[0])
for idx in range(length):
combine_dict[i] = {k: dic[k][idx] for k in dic.keys()}
i += 1
res2 = pd.DataFrame.from_dict(combine_dict, 'index')
print('dict合并方式耗时:%s秒' % (datetime.now() - start2))
# %% 第三种方式:list装好所有值(运行时间最短——4秒多,内存占用低)
start3 = datetime.now()
columns = ['a', 'b']
a_list = []
b_list = []
4
for df in df_list:
a_list.extend(df['a'])
b_list.extend(df['b'])
res3 = pd.DataFrame({'a': a_list, 'b': b_list})
print('list装好所有值方式耗时:%s秒' % (datetime.now() - start3))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号