
hash算法原理及常见函数
一、简介
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。
散列表,它是基于快速存取的角度设计的,也是一种典型的“空间换时间”的做法。顾名思义,该数据结构可以理解为一个线性表,但是其中的元素不是紧密排列的,而是可能存在空隙。
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
二、hash函数的选择
哈稀函数按照定义可以实现一个伪随机数生成器(PRNG),从这个角度可以得到一个公认的结论:哈希函数之间性能的比较可以通过比较其在伪随机生成方面的比较来衡量。
一般来说,对任意一类的数据存在一个理论上完美的哈希函数。这个完美的哈希函数定义是没有发生任何碰撞,这意味着没有出现重复的散列值。在现实中它很难找到一个完美的哈希散列函数,而且这种完美函数的趋近变种在实际应用中的作用是相当有限的。在实践中人们普遍认识到,一个完美哈希的哈希函数,就是在一个特定的数据集上产生的的碰撞最少哈希的函数。
我们所能做的就是通过试错方法来找到满足我们要求的哈希函数。可以从下面两个角度来选择哈希函数:
- 数据分布
一个衡量的措施是考虑一个哈希函数是否能将一组数据的哈希值进行很好的分布。要进行这种分析,需要知道碰撞的哈希值的个数,如果用链表来处理碰撞,则可以分析链表的平均长度,也可以分析散列值的分组数目。 - 哈希函数的效率
另个一个衡量的标准是哈希函数得到哈希值的效率。通常,包含哈希函数的算法的算法复杂度都假设为O(1),这就是为什么在哈希表中搜索数据的时间复杂度会被认为是"平均为O(1)的复杂度",而在另外一些常用的数据结构,比如图(通常被实现为红黑树),则被认为是O(logn)的复杂度。
一个好的哈希函数必须在理论上非常的快、稳定并且是可确定的。通常哈希函数不可能达到O(1)的复杂度,但是哈希函数在字符串哈希的线性的搜索中确实是非常快的,并且通常哈希函数的对象是较小的主键标识符,这样整个过程应该是非常快的,并且在某种程度上是稳定的。
在这篇文章中介绍的哈希函数被称为简单的哈希函数。它们通常用于散列(哈希字符串)数据。它们被用来产生一种在诸如哈希表的关联容器使用的key。这些哈希函数不是密码安全的,很容易通过颠倒和组合不同数据的方式产生完全相同的哈希值。
三、hash方法学
-
基于加法和乘法的散列
这种方式是通过遍历数据中的元素然后每次对某个初始值进行加操作,其中加的值和这个数据的一个元素相关。通常这对某个元素值的计算要乘以一个素数。
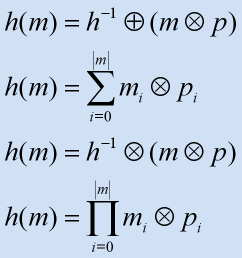
-
基于移位的散列
和加法散列类似,基于移位的散列也要利用字符串数据中的每个元素,但是和加法不同的是,后者更多的而是进行位的移位操作。通常是结合了左移和右移,移的位数的也是一个素数。每个移位过程的结果只是增加了一些积累计算,最后移位的结果作为最终结果。
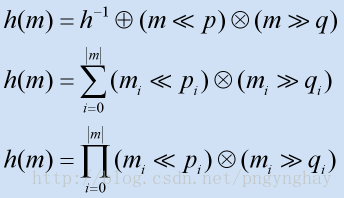
四、hash构造方法
- 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a?key + b,其中a和b为常数(这种散列函数叫做自身函数)
- 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
- 平方取中法:取关键字平方后的中间几位作为散列地址。
- 折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。
- 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p, p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
五、hash冲突及解决
hash冲突在所难免,解决冲突是一个复杂问题。冲突主要取决于:
(1) 与散列函数有关,一个好的散列函数的值应尽可能平均分布。
(2) 与解决冲突的哈希冲突函数有关。
(3) 与负载因子的大小。太大不一定就好,而且浪费空间严重,负载因子和散列函数是联动的。
解决冲突的办法:
(1) 开放定址法:线性探查法、平方探查法、伪随机序列法、双哈希函数法。
(2) 拉链法:把所有同义词,即hash值相同的记录,用单链表连接起来。
六、哈希函数和素数
没有人可以证明素数和伪随机数生成器之间的关系,但是目前来说最好的结果使用了素数。伪随机数生成器现在是一个统计学上的东西,不是一个确定的实体,所以对其的分析只能对整个的结果有一些认识,而不能知道这些结果是怎么产生的。
围绕着哈希函数中的素数的使用的基本的概念是,利用一个素数来改变处理的哈希函数的状态值,而不是使用其他类型的数。处理这个词的意思就是对哈希值进行一些简单的操作,比如乘法和加法。这样得到的一个新的哈希值一定要在统计学上具有更高的熵,也就是说不能有为偏向。简单的说,当你用一个素数去乘一堆随机数的时候,得到的数在bit这个层次上是1的概率应该接近0.5。没有具体的证明这种不便向的现象只出现在使用素数的情况下,这看上去只是一个自我宣称的直觉上的理论,并被一些业内人士所遵循。
决定什么是正确的,甚至更好的方法和对散列素数的使用最好的组合仍然是一个很有黑色艺术。没有单一的方法可以宣称自己是最终的通用散列函数。最好的一所能做的就是通过试错演进和获得适当的散列算法,以满足其需要的统计分析方法。
七、应用领域
哈希是一个在现实世界中将数据映射到一个标识符的工具,下面是哈希函数的一些常用领域:
- 字符串哈希
在数据存储领域,主要是数据的索引和对容器的结构化支持,比如哈希表。 - 加密哈希
用于数据/用户核查和验证。一个强大的加密哈希函数很难从结果再得到原始数据。加密哈希函数用于哈希用户的密码,用来代替密码本身存在某个服务器撒很难过。加密哈希函数也被视为不可逆的压缩功能,能够代表一个信号标识的大量数据,可以非常有用的判断当前的数据是否已经被篡改(比如MD5),也可以作为一个数据标志使用,以证明了通过其他手段加密文件的真实性。 - 几何哈希
这个哈希表用于在计算机视觉领域,为在任意场景分类物体的探测。最初选择的过程涉及一个地区或感兴趣的对象。几何散列包括各种汽车分类的重新检测中任意场景的目的,典型的例子。检测水平可以多种多样,从刚检测是否是车辆,到特定型号的车辆,在特定的某个车辆。 - 布隆过滤器
布隆过滤器允许一个非常大范围内的值被一个小很多的内存锁代表。在计算机科学,这是众所周知的关联查询,并在关联容器的核心理念。
Bloom Filter的实现通过多种不同的hash函数使用,也可通过允许一个特定值的存在有一定的误差概率会员查询结果的。布隆过滤器的保证提供的是,对于任何会员国的查询就永远不会再有假阴性,但有可能是假阳性。假阳性的概率可以通过改变控制为布隆过滤器,并通过不同的hash函数的数量所使用的表的大小。
随后的研究工作集中在的散列函数和哈希表以及Mitzenmacher的布隆过滤器等领域。建议对这种结构,在数据被散列熵最实用的用法有助于哈希函数熵,这是理论成果上缔结一项最佳的布隆过滤器(一个提供给定一个最低的进一步导致假阳性的可能性表的大小或反之亦然)提供假阳性的概率定义用户可以建造最多也作为两种截然不同的两两独立的哈希散列函数已知功能,大大提高了查询效率的成员。
布隆过滤器通常存在于诸如拼写检查器,字符串匹配算法,网络数据包分析工具和网络/ Internet缓存的应用程序。 - Hash算法在信息安全方面的应用主要体现在以下的3个方面:
(1) 文件校验
我们比较熟悉的校验算法有奇偶校验和CRC校验,这2种校验并没有抗数据篡改的能力,它们一定程度上能检测并纠正数据传输中的信道误码,但却不能防止对数据的恶意破坏。
MD5 Hash算法的"数字指纹"特性,使它成为目前应用最广泛的一种文件完整性校验和(Checksum)算法,不少Unix系统有提供计算md5 checksum的命令。
(2) 数字签名
Hash 算法也是现代密码体系中的一个重要组成部分。由于非对称算法的运算速度较慢,所以在数字签名协议中,单向散列函数扮演了一个重要的角色。 对 Hash 值,又称"数字摘要"进行数字签名,在统计上可以认为与对文件本身进行数字签名是等效的。而且这样的协议还有其他的优点。
(3) 鉴权协议
如下的鉴权协议又被称作挑战--认证模式:在传输信道是可被侦听,但不可被篡改的情况下,这是一种简单而安全的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号