『笔记』手撕代码
『笔记』手撕代码
手写iou
def compute_iou(box1, box2):
# 两box对应位置的相反值, 小的位置(1)就是取max, 大的位置(2)就是取min
xx1 = max(box1[0], box2[0])
yy1 = max(box1[1], box2[1])
xx2 = min(box1[2], box2[2])
yy2 = min(box1[3], box2[3])
size_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
size_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
intersect = max(xx2 - xx1, 0) * max(yy2 - yy1, 0)
union = size_box1 + size_box2 - intersect
iou = intersect / union
return iou
# 在这里首先标好: x1, y1, x2, y2
box1 = [1, 1, 3, 3]
box2 = [2, 2, 4, 4]
print(compute_iou(box1, box2))
box1 = torch.tensor(box1).unsqueeze(0)
box2 = torch.tensor(box2).unsqueeze(0)
print(torchvision.ops.box_iou(box1, box2).item())
如果问2d rotated iou或者3d iou,难点肯定就是rotated这个事情了,以3d iou为例,思路为:
首先,结果可以拆分成2d bev下带rotation的IoU与height交叉高度相乘。于是,问题的关键其实在于2d rotated iou这件事。计算2d rotated iou:
- 根据box信息计算corners(基于box center,先得到local的角点坐标,并将corners编码为顺时针顺序,然后旋转加平移得到绝对坐标)
- 求两box范围的所有交点,于是得到polygon。交点虽然不规则,但总不会超过八个点,于是可以预先分配buffer。分为a. 在对方box内的点 b. 边与边的交叉点
- 根据polygon中心点对角点进行排序,使其满足逆时针方向
- 计算多边形面积。采用累计计算三角形面积(利用叉乘)的方式(由于夹角逐渐增大,与第一个点构成的三角形面积一定是在同侧的符号相同)
手写nms
import numpy as np
def nms(boxes, scores, nms_thresh):
'''
boxes: (N, 4) x_min, y_min, x_max, y_max
scores: (N,)
'''
# 按照降序对bbox的得分进行排序
score_descending_order = np.argsort(scores)[::-1]
# 作为循环时要参与计算iou的值, 提前计算保存好
sizes = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
# 保存经过筛的输出box结果
ans = []
while score_descending_order.shape[0] > 0:
# 得到当前score最高的box, 加入结果
i = score_descending_order[0]
ans.append(i)
# 计算当前box和所有剩余box的iou们
xx1s = np.maximum(boxes[:, 0][i], boxes[:, 0][score_descending_order[1:]]) # maximum: Element-wise maximum
yy1s = np.maximum(boxes[:, 1][i], boxes[:, 1][score_descending_order[1:]])
xx2s = np.minimum(boxes[:, 2][i], boxes[:, 2][score_descending_order[1:]])
yy2s = np.minimum(boxes[:, 3][i], boxes[:, 3][score_descending_order[1:]])
intersects = np.maximum(0, xx2s - xx1s) * np.maximum(0, yy2s - yy1s)
unions = sizes[i] + sizes[score_descending_order[1:]] - intersects
ious = intersects / unions
# 仅保留剩余box与当前box的iou值小于阈值的, 更新order, 准备进行下一次循环
# 注意, 这几步的操作主体在计算角点时就已经是未更新order从位置1往后的slice后的array了, 即剩余的box们
# 于是, 得到该部分order的inds后, 用来更新order时, 整体都需要加一
inds = np.flatnonzero(ious <= nms_thresh)
score_descending_order = score_descending_order[inds + 1]
return ans
boxes = np.array([[187, 82, 337, 317], [150, 67, 305, 282], [246, 121, 368, 304]])
scores = np.array([0.9, 0.75, 0.8])
print(nms(boxes, scores, 0.5))
boxes = torch.tensor(boxes).type(torch.float64)
scores = torch.from_numpy(scores).type(torch.float64)
print(torchvision.ops.nms(boxes, scores, 0.5))
手写conv2d
import numpy as np
def conv2d(x, kernel, stride, padding, bias):
C, H, W = x.shape
# 做pad
x_padded = np.zeros((C, H + 2 * padding, W + 2 * padding))
x_padded[:, padding: H + padding, padding : W + padding] = x
x = x_padded
# 做conv
Nk, _, Hk, Wk = kernel.shape
Hout, Wout = (H - Hk + 2 * padding) // stride + 1, (W - Wk + 2 * padding) // stride + 1
output = np.zeros((Nk, Hout, Wout))
for i in range(0, Hout):
for j in range(0, Wout):
output[:, i, j] = np.sum(np.multiply(kernel, x[:, i*stride: i*stride + Hk, j*stride: j*stride + Wk]), axis=(1, 2, 3)) + bias
return output
x = np.random.random((16, 6, 6))
kernel = np.ones((25, 16, 3, 3))
Nk, _, Hk, Wk = kernel.shape
bias = np.zeros((Nk,)) # bias的尺寸就是输出通道尺寸, 即卷积核个数
stride = 3
padding = 0
output = conv2d(x, kernel, stride, padding, bias)
print("input {}".format(x.shape))
print("kenerls {}, stride {}".format(kernel.shape, stride))
print("output {}".format(output.shape))
print(x[0])
print(output[0])
print(np.sum(x[:, :3, :3]))
print(np.sum(x[:, -3:, -3:]))
手写maxpooling
import numpy as np
def maxpooling(x, kernel_size, stride, padding):
C, H, W = x.shape
# 做pad
x_padded = np.zeros((C, H + 2 * padding, W + 2 * padding))
x_padded[:, padding: H + padding, padding : W + padding] = x
x = x_padded
# 做pooling
Hk, Wk = kernel_size
Hout, Wout = (H - Hk + 2 * padding) // stride + 1, (W - Wk + 2 * padding) // stride + 1
output = np.zeros((C, Hout, Wout))
for i in range(0, Hout):
for j in range(0, Wout):
output[:, i, j] = np.max(x[:, i*stride: i*stride + Hk, j*stride: j*stride + Wk], axis=(1, 2))
return output
x = np.random.random((16, 6, 6))
kernel_size = (2, 2)
stride = 1
padding = 0
output = maxpooling(x, kernel_size, stride, padding)
print("input {}".format(x.shape))
print("kenerls {}, stride {}".format(kernel_size, stride))
print("output {}".format(output.shape))
print(x[0])
print(output[0])
手写maxpooling反向传播
def max_pool_backward_naive(dout, cache):
x, pool_param = cache
N, C, H, W = x.shape
HH, WW, stride = pool_param['pool_height'], pool_param['pool_width'], pool_param['stride']
H_out = (H-HH)/stride+1
W_out = (W-WW)/stride+1
dx = np.zeros_like(x)
for i in range(H_out):
for j in range(W_out):
x_masked = x[:,:,i*stride : i*stride+HH, j*stride : j*stride+WW]
max_x_masked = np.max(x_masked,axis=(2,3))
temp_binary_mask = (x_masked == (max_x_masked)[:,:,None,None])
dx[:,:,i*stride : i*stride+HH, j*stride : j*stride+WW] += temp_binary_mask * (dout[:,:,i,j])[:,:,None,None]
手写resnet
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1)
self.bn3 = nn.BatchNorm2d(64)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64, 10)
def forward(self, x):
identity = self.conv3(x)
identity = self.bn3(identity)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# print(out.shape)
# print(identity.shape)
out += identity
out = self.relu(out)
out = self.avgpool(out)
out = torch.flatten(out, start_dim=1)
out = self.fc(out)
return out
img = torch.ones((4, 3, 224, 224))
label = torch.ones((4,)).type(torch.LongTensor)
net = Net()
criterion = nn.CrossEntropyLoss()
for name, param in net.named_parameters():
print(name, param.shape)
if name.startswith('conv2'):
param.requires_grad = False
# for name, buffer in net.named_buffers():
# print(name, buffer.shape)
optimizer = torch.optim.SGD(net.parameters(), lr=1e-3)
print(net.conv1.weight.requires_grad)
print(net.conv1.bias.requires_grad)
print(net.conv2.weight.requires_grad)
print(net.conv2.bias.requires_grad)
print(net.conv3.weight.requires_grad)
print(net.conv3.bias.requires_grad)
for i in range(2):
output = net(img)
loss = criterion(output, label)
print(net.conv1.weight.grad_fn)
print(net.conv1.bias.grad_fn)
print(net.conv2.weight.grad_fn)
print(net.conv2.bias.grad_fn)
print(net.conv3.weight.grad_fn)
print(net.conv3.bias.grad_fn)
print(net.conv1.weight.grad.shape if net.conv1.weight.grad is not None else None)
print(net.conv1.bias.grad.shape if net.conv1.weight.grad is not None else None)
print(net.conv2.weight.grad.shape if net.conv2.weight.grad is not None else None)
print(net.conv2.bias.grad.shape if net.conv2.bias.grad is not None else None)
print(net.conv3.weight.grad.shape if net.conv3.weight.grad is not None else None)
print(net.conv3.bias.grad.shape if net.conv3.bias.grad is not None else None)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print(torch.max(output, 1)[1])
手写RANSAC
import numpy as np
from matplotlib import pyplot as plt
import random
# 生成数据集
inliers = 30
outliers = 20
x_inliers = np.linspace(0, 10, inliers)
y_inliers = x_inliers * 5 + 10 + np.random.randn(*x_inliers.shape)
x_outliers = np.random.random((outliers,)) * 10
y_outliers = np.random.random((outliers,)) * 50
x_data = np.array(np.concatenate([x_inliers, x_outliers]))
y_data = np.array(np.concatenate([y_inliers, y_outliers]))
plt.scatter(x_data, y_data)
plt.show()
n = x_data.shape[0]
k = 100
eps = 3
best_param = None
best_param_ab = None
min_error = 1e7
for _ in range(k):
curr_picked = np.random.random_sample((2,)) * n
curr_picked = curr_picked.astype(np.int32)
x1, y1 = x_data[curr_picked[0]], y_data[curr_picked[0]]
x2, y2 = x_data[curr_picked[1]], y_data[curr_picked[1]]
a = (y2 - y1) / (x2 - x1)
b = y1 - a * x1
A = a
B = -1
C = b
curr_inliers = 0 #当前内点数量
curr_error = 0
for i in range(n):
xi, yi = x_data[i], y_data[i]
dist = abs(A * xi + B * yi + C) / np.sqrt(A**2 + B**2)
if dist <= eps: #符合内点距离
curr_inliers += 1
curr_error += dist
if curr_inliers / n > 0.7: #记录最大内点数与对应的参数
if curr_error < min_error:
min_error = curr_error
best_param = [A, B, C]
best_param_ab = [a, b]
if curr_inliers / n > 0.95: #内点数大于设定的阈值,跳出循环
break
plt.scatter(x_data, y_data)
x_line = np.linspace(0, 10, 2)
y_line = best_param_ab[0] * x_line + best_param_ab[1]
plt.plot(x_line, y_line, c = 'r')
plt.show()
点到直线距离公式:\(\frac{|Ax_0+ By_0 + C|}{\sqrt{A^2 + B^2}}\)
点到平面距离公式:\(\frac{|Ax_0+ By_0 + Cz_0 + D|}{\sqrt{A^2 + B^2 + C^2}}\)
手写transformer
class BasicSelfAttention(nn.Module):
def forward(self, x):
# x: shape (b, t, k)
b, t, k = x.shape
x_t = torch.transpose(x, 1, 2)
w_prime = torch.bmm(x, x_t)
w = F.softmax(w_prime, dim=2)
y = torch.zeros((b, t, k))
y = torch.bmm(w, x)
return y
class SelfAttention(nn.Module):
"""
Self-attention operation with learnable key, query and value embeddings.
Args:
k: embedding dimension
"""
def __init__(self, k):
super(SelfAttention, self).__init__()
# These compute the queries, keys and values
self.tokeys = nn.Linear(k, k, bias=False)
self.toqueries = nn.Linear(k, k, bias=False)
self.tovalues = nn.Linear(k, k, bias=False)
def forward(self, x):
# Get tensor dimensions: batch size, sequence length and embedding dimension
b, t, k = x.size()
# x: shape (b, t, k)
b, t, k = x.shape
queries = self.toqueries(x)
keys = self.tokeys(x)
keys_t = torch.transpose(keys, 1, 2)
# NOTE: 公式中的转置当然是行向量,本来是列向量,所以在程序中反而列向量需要转置,行向量不用
w_prime = torch.bmm(queries, keys_t) / k**(1/2)
w = F.softmax(w_prime, dim=2)
values = self.tovalues(x)
y = torch.bmm(w, values)
return y
class MultiHeadAttention(nn.Module):
"""
Wide mult-head self-attention layer.
Args:
k: embedding dimension
heads: number of heads (k mod heads must be 0)
"""
def __init__(self, k, heads=8):
super(MultiHeadAttention, self).__init__()
self.heads = heads
# These compute the queries, keys and values for all
# heads (as a single concatenated vector)
self.tokeys = nn.Linear(k, k * heads, bias=False)
self.toqueries = nn.Linear(k, k * heads, bias=False)
self.tovalues = nn.Linear(k, k * heads, bias=False)
# This unifies the outputs of the different heads into
# a single k-vector
self.unifyheads = nn.Linear(k * heads, k)
def forward(self, x):
b, t, k = x.size()
h = self.heads
# 写完这个也能感受到利用reshape和transpose来玩弄维度的手段
queries = self.toqueries(x).reshape(b, t, h, k).transpose(1, 2).reshape(b*h, t, k)
keys = self.tokeys(x).reshape(b, t, h, k).transpose(1, 2).reshape(b*h, t, k)
keys_t = torch.transpose(keys, 1, 2)
w_prime = torch.bmm(queries, keys_t) / k**(1/2)
w = F.softmax(w_prime, dim=2)
values = self.tovalues(x).reshape(b, t, h, k).transpose(1, 2).reshape(b*h, t, k)
y = torch.bmm(w, values)
y = y.reshape(b, h, t, k).transpose(1, 2).reshape(b, t, h*k)
y = self.unifyheads(y)
return y
class TransformerBlock(nn.Module):
def __init__(self, k, heads, dropout=0.1):
"""
Basic transformer block.
Args:
k: embedding dimension
heads: number of heads (k mod heads must be 0)
"""
super(TransformerBlock, self).__init__()
self.att = MultiHeadAttention(k, heads=heads)
self.norm1 = nn.LayerNorm(k)
self.ff = nn.Sequential(
nn.Linear(k, 4 * k),
nn.ReLU(),
nn.Linear(4 * k, k))
self.norm2 = nn.LayerNorm(k)
def forward(self, x):
attended = self.att(x)
x = self.norm1(attended + x)
fedforward = self.ff(x)
y = self.norm2(fedforward + x)
return y
class Transformer(nn.Module):
def __init__(self, k, heads=8, num_layers=2, input_length=40,
num_inputs=256, num_outputs=10):
"""
Transformer architecture.
Args:
k: embedding dimension
heads: number of attention heads
num_layers: number of transformer blocks in network
input_length: length of input sequence
num_inputs: input dimension
num_outputs: ouput dimension
"""
super(Transformer, self).__init__()
# Embedding layers for input and position
self.input_embedding = nn.Embedding(num_inputs, k)
self.position_embedding = nn.Embedding(input_length, k)
# Create transformer blocks
blocks = [TransformerBlock(k, heads) for _ in range(num_layers)]
self.blocks = nn.Sequential(*blocks)
# Projects the output to desired output size
self.output_projector = nn.Linear(k, num_outputs)
def forward(self, x):
"""
Forward pass of trasformer model.
Args:
x: input with shape of (b, t)
"""
b, t = x.shape
# Embed input
x = self.input_embedding(x) # x: (b, t: time seq)-> (b, k: word2vec)
# Add positional embedding
p = torch.arange(t, device=x.device).view(1, t).expand(b, t)
p = self.position_embedding(p) # -> (b, k)
x = x + p
# Compute transformer output
x = self.blocks(x)
# Average-pool over dimension t
x = x.mean(dim=1)
# Project output to desired size
x = self.output_projector(x)
return x
手写深度可分离卷积
https://zhuanlan.zhihu.com/p/382560930
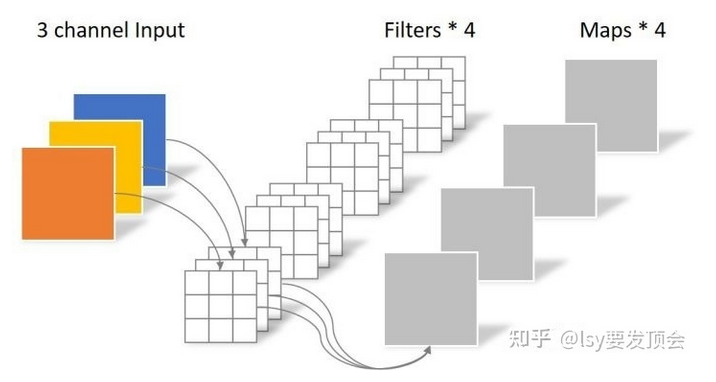
我们常规的卷积,如经过卷积核为3的卷积变为4通道,其中训练的参数量为3 * 3 * 3 * 4 = 108,而深度可分离卷积,1. 先逐通道卷积,参数量为 3乘以3乘以3 = 27,这种逐通道卷积没有考虑到相同空间位置像素之间的关联。2. 再逐点卷积,把相同空间位置的像素加起来,参数量为1乘以1乘以3乘以4等于12,所以总的参数量为12+27 = 39大约为108的三分之一。
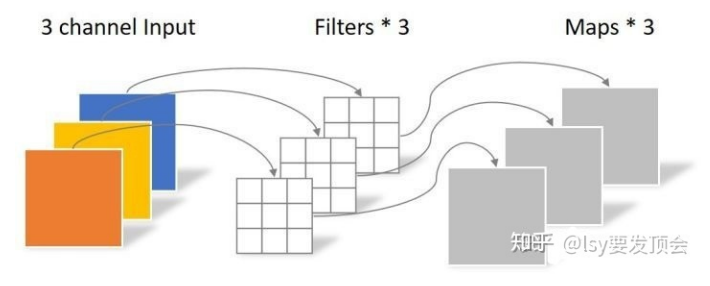
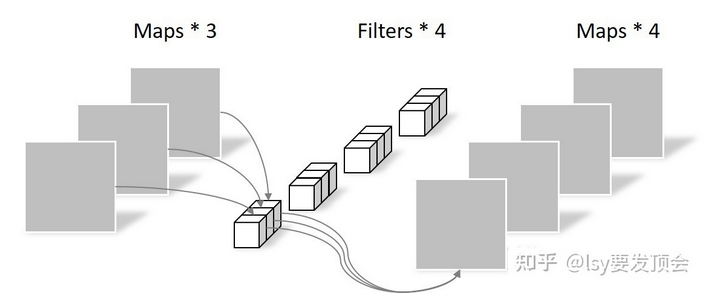
我们知道,pytorch定义conv2d的时候的groups参数就是定义了分多少个group做conv kernel,默认就是1,大家整个通道一起做,于是这里的第一步也就是传入和输入通道数相等,大家都完全各做各的。
class DEPTHWISECONV(nn.Module):
def __init__(self,in_ch,out_ch):
super(DEPTHWISECONV, self).__init__()
# 也相当于分组为1的分组卷积
self.depth_conv = nn.Conv2d(in_channels=in_ch,
out_channels=in_ch,
kernel_size=3,
stride=1,
padding=1,
groups=in_ch)
self.point_conv = nn.Conv2d(in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
stride=1,
padding=0,
groups=1)
def forward(self,input):
out = self.depth_conv(input)
out = self.point_conv(out)
return out
手写optimizer


 浙公网安备 33010602011771号
浙公网安备 33010602011771号