『笔记』CVT
『笔记』CVT
Cross-view Transformers for real-time Map-view Semantic Segmentation
CVPR2022 oral的文章。方法的结构十分简练,为我们展现了一个关于使用transformer(具体来说,是cross-(view-)attention)将image转bev系列思想的非常直接的核心思路,即bev position embedding作为query模板来索另外的features,这样类似DETR思路的范式。文章的task是bev map的image segmentation
使用transformer将image转bev的类DETR思路,就是可由该图表示:
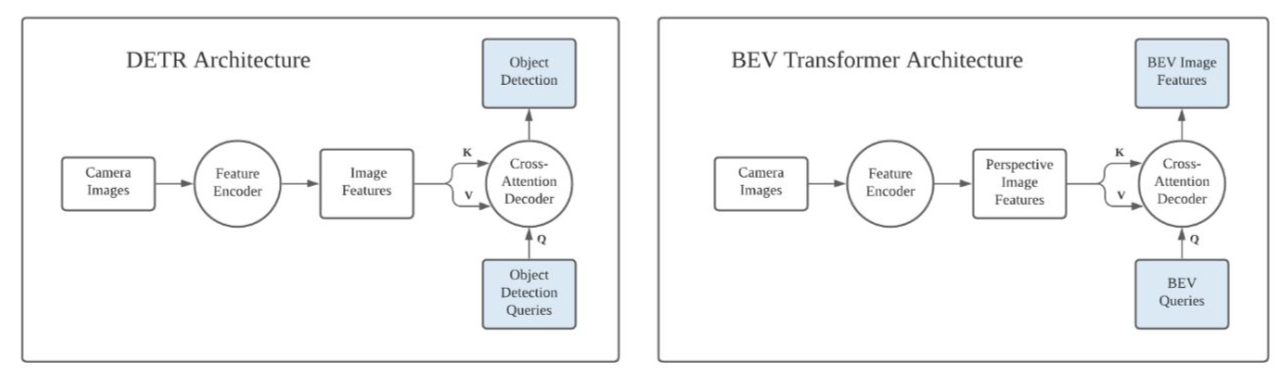
3. Cross-view transformers

3.1. Cross-view attention
The goal of cross-view attention is to link up a map-view representation with image-view features
文章所依据的主要idea和原理支持为:

Without an accurate depth estimate in camera view or height-above- ground estimate in map-view, the world coordinate \(x(W)\) is ambiguous. We do not learn an explicit estimate of depth but encode any depth ambiguity in the positional embeddings and let a transformer learn a proxy for depth
rephrasing the geometric relationship:

个人理解:我们知道,所谓现在很火的bev的方法,也就是将所有信息表示在bev视角下,而对于我们,问题就是在于相机,讨论怎么把相机坐标系的perspective view的信息转换在bev下,而显而易见,这个事情的关键依然是老生常谈的depth. 我们知道,3d到相机2d pixel无非就是那个经典的(extrinsic) homogeneous transform + (instrinsic) perspective projection,知道了这个,一切都不是问题。所以,像LSS流派方法,就是explicitly预测这个depth,具体而言就是生成frustum 3d grids,预测depth,然后height compression落到bev实现这个转换。而在这里,对于transformer流派,这篇文章方法提供的intuition就是,我把这个投影关系写成来自相机2d和世界坐标系3d两方面信息来源的值,以一个类似reprojection error的感觉写成两个本应该相等的值的similarity形式,即上面公式的分子两项。在理想情况下,两项相等,这个similarity就会大(毕竟意义就是相似度),而如果传递过程中有error,或者本就不是对应位置,相似度就会比较小。这样一来,区分度就出来了,attention的意义也就体现了出来,能学到这样正确的关系,就为网络配备了转换的能力。可以想象,参与这个attention的元素就需要有1. postion embeddings (融入了calibration matrices信息),很明显这是重要的prior信息,或者也可以说,把depth这个主要解决对象从geometric information中解藕出来 2. image features,我们当然需要图像特征来作为原材料,depth不是凭空变出来的 3. 考虑相机数量
最终设计的方法,以及cross-attention所依据的核心similarity构造为:
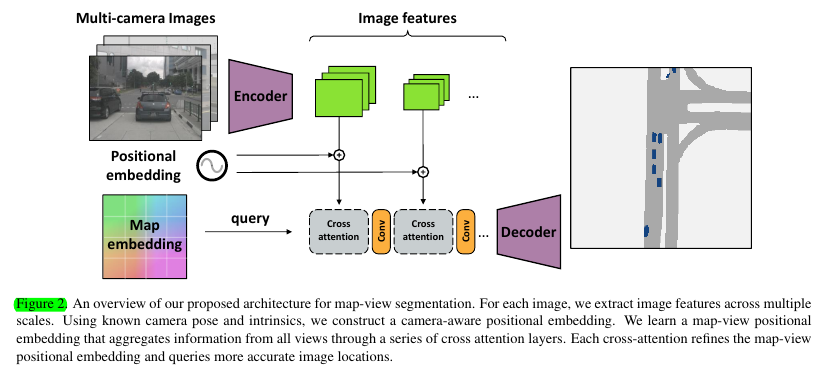
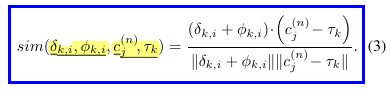
在image这一侧,将image每个2d pixel通过matrices inverse projection,得到一个向量,取depth为1的位置的这个“单位”向量过一个mlp处理一下维度(d=128)作为其position embedding. 将该position embedding和image features做sum后,也就组成了key. 而image features自己当然是value.
This allows cross-view attention to use both appearance and geometric cues to reason about correspondences across the different views.


在bev map这一侧,很明显bev的初始化就是一个learned positional embedding,对应我们的interpretation,其就是扮演了一个预测每个bev grid位置可能出现的点的3d空间位置。另外,平移的calibration vector同样是通过mlp处理了维度

另外,本文同样也是有multi-level的attention模块,同样是有一个本次输出结果作为下次query这样一个范式。不同级别用的kv信息就是不同level的image feature map
个人理解:不难发现,最后呈现的效果,就是很经典的拿bev embedding当query,拿其它features信息往这个“模板”上面套的像是DETR的范式。或者说,这就是transformer方法在bev这个application这里的用法。但是,这篇文章从这个投影关系rephrase为similarity的方式来解释了这个操作的大致意义所在
We train all layers using ground truth semantic map-view annotations and a focal loss [19].

 浙公网安备 33010602011771号
浙公网安备 33010602011771号