『笔记』BEVFusion-MIT
『笔记』BEVFusion
1 Introduction
We propose BEVFusion to unify multi-modal features in a shared bird’s-eye view (BEV) representation space for task-agnostic learning. [...] BEVFusion breaks the long-standing belief that point-level fusion is the best solution to multi-sensor fusion
2. Related work
LiDAR-Based 3D Perception.
Researchers have designed single-stage 3D object detectors [VoxelNet, PointPillars, SECOND, CBGS, 3DSSD, MVF (dynamic voxelization)] that extract flattened point cloud features using PointNets [PointNet++] or SparseConvNet [submanifold sparse convolutional networks] and perform detection in the BEV space.
Later, Yin et al. [CenterPoint] and others [HorizonLiDAR3D, Object as Hotspots, Offboard, RangeDet, PolarStream, Object DGCNN] have explored anchor-free 3D object detection.
Another stream of research [PointRCNN, Fast Point R-CNN, Part-A^2, PV-RCNN, PV-RCNN++, LiDAR R-CNN] focuses on two-stage object detection, which adds an RCNN network to existing one-stage object detectors.
There are also U-Net like models specialized for 3D semantic segmentation [submanifold sparse convolutional networks, 4D Spatio-Temporal ConvNets, Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution, PVNAS, Cylindrical and Asymmetrical 3D Convolution Networks], an important task for offline HD map construction.
Camera-Based 3D Perception.
FCOS3D [FCOS3D] extends image detectors [FCOS] with additional 3D regression branches, which is later improved in terms of depth modeling [Probabilistic and Geometric Depth, EPro-PnP].
Instead of performing object detection in the perspective view, DETR3D [DETR3D], PETR [PETR] and Graph- DETR3D [Graph- DETR3D] design DETR [Deformable DETR, Anchor DETR]-based detection heads with learnable object queries in the 3D space.
Inspired by the design of LiDAR-based detectors, another type of camera-only 3D perception models explicitly converts the camera features from perspective view to the bird's-eye view using a view transformer [Cross-View Semantic Segmentation, Orthographic Feature Transform, Pyramid Occupancy Networks, LSS]. BEVDet [BEVDet] and M2 BEV [M\(^2\)BEV] effectively extend LSS [LSS] and OFT [OFT] to 3D object detection, achieving state-of-the-art performance upon release. CaDDN [CaDDN] adds explicit depth estimation supervision to the view transformer. BEVDet4D [BEVDet4D], BEVFormer [BEVFormer] and PETRv2 [PETRv2] exploit temporal cues in multi-camera 3D object detection, achieving significant improvement over single-frame methods. BEVFormer, CVT [CVT] and Ego3RT [Ego3RT] also study using multi-head attention to perform the view transformation.
Multi-Sensor Fusion.
Recently, multi-sensor fusion arouses increased interest in the 3D detection community. Existing approaches can be classified into proposal-level and point-level fusion methods.
MV3D [MV3D] creates object proposals in 3D and projects the proposals to images to extract RoI features. F-PointNet [F-PointNet], F-ConvNet [F-ConvNet] and CenterFusion [CenterFusion] all lift image proposals into a 3D frustum. Lately, FUTR3D [FUTR3D] and TransFusion [TransFusion] define object queries in the 3D space and fuse image features onto these proposals. Proposal-level fusion methods are object-centric and cannot trivially generalize to other tasks such as BEV map segmentation.
Point-level fusion methods, on the other hand, usually paint image semantic features onto foreground LiDAR points and perform LiDAR-based detection on the decorated point cloud inputs. As such, they are both object-centric and geometric-centric. Among all these methods, PointPainting [PointPainting], PointAugmenting [PointAugmenting], MVP [MVP], FusionPainting [FusionPainting], AutoAlign [AutoAlign] and FocalSparseCNN [FocalSparseCNN] are (LiDAR) input-level decoration, while Deep Continuous Fusion [27] and DeepFusion [DeepFusion] are feature-level decoration.
3 Method
3.1 Unified Representation

To Camera: project the LiDAR point cloud to the camera plane and render the 2.5D sparse depth. However, this conversion is geometrically lossy. Two neighbors on the depth map can be far away from each other in the 3D space. This makes the camera view less effective for tasks that focus on the object/scene geometry, such as 3D object detection.
To LiDAR: semantically lossy. Camera and LiDAR features have drastically different densities, resulting in only less than 5% of camera features being matched to a LiDAR point (for a 32-channel LiDAR scanner). Giving up the semantic density of camera features severely hurts the model’s performance on semantic-oriented tasks (such as BEV map segmentation). Similar drawbacks also apply to more recent fusion methods in the latent space (e.g., object query) [FUTR3D, TransFusion].
To BEV: We adopt the bird’s-eye view (BEV) as the unified representation for fusion.
总得来说,相比选择其它view,采取BEV的原因有:
- keeps both geometric and semantic information
- friendly to almost all perception tasks
- lidar to bev by height compression is fine, camera to bev by unprojecting results in dense map
3.2 Efficient Camera-to-BEV Transformation
Following LSS and BEVDet, we explicitly predict the discrete depth distribution of each pixel. We then scatter each feature pixel into D discrete points along the camera ray and rescale the associated features by their corresponding depth probabilities. This generates a camera feature point cloud of size \(NHWD\), where \(N\) is the number of cameras and \((H,W)\) is the camera feature map size. Such 3D feature point cloud is quantized along the \(x, y\) axes with a step size of \(r\) (e.g., 0.4m). We use the BEV pooling operation to aggregate all features within each \(r × r\) BEV grid (所以其实就是pillar) and flatten the features along the z-axis.
To lift the efficiency bottleneck, we propose to optimize the BEV pooling with precomputation and interval reduction
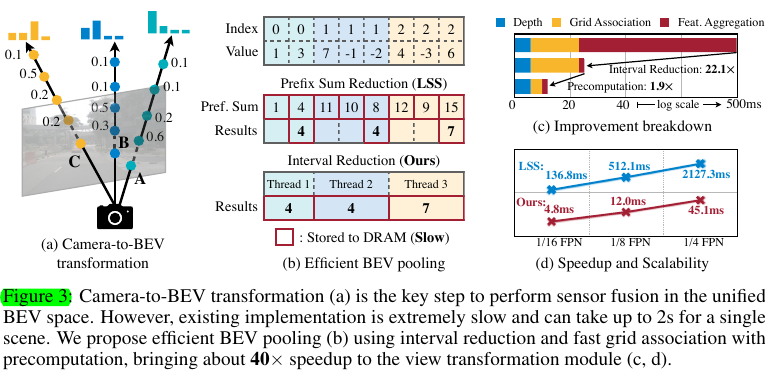

个人理解:总体来说,本文章的contribution就是在这里,从implementation的角度实现了更高效的"splat"过程,也就是把已经lift好的相机稠密的三维空间的特征做pillar内pooling的操作。
在LSS中,该过程为1. associate每个point的特征的bev grid id,然后sort,然后2. "CumSum trick",从小到大累积着求和,减去各自边界处的结果就是该grid内的求和值
但是,对于1,在看LSS代码时我们已经发现其实frustum grids早早就可以确定了,因为根据预设的hyper-params,我们已经定好了去预测哪些depth位置的点特征,所以它们的bev id和排序本身就是fixed的,于是BEVFusion做precomputation来提前计算好id和rank们。对于2,在cumsum trick的过程中a. 由于sum结果的output之间有dependency,需要multi-level tree reduction(是什么?),而且b. 需要计算大量的partial sums,也就是每个sub-grid点的value累加都有,要存储到DRAM(是什么?)中。于是BEVFusion写了一个gpu kernel,给每个grid都单独分配一个gpu thread来单独计算sum,实现了interval reduction
3.3 Fully-Convolutional Fusion
With all sensory features converted to the shared BEV representation, we can easily fuse them together with an elementwise operator (such as concatenation)
3.4 Multi-Task Heads
We apply multiple task-specific heads to the fused BEV feature map
- Detection: CenterPoint head
- Segmentation: different map categories may overlap (e.g., crosswalk is a subset of drivable space). Therefore, we formulate this problem as multiple binary semantic segmentation, one for each class. Follow CVT
5 Analysis
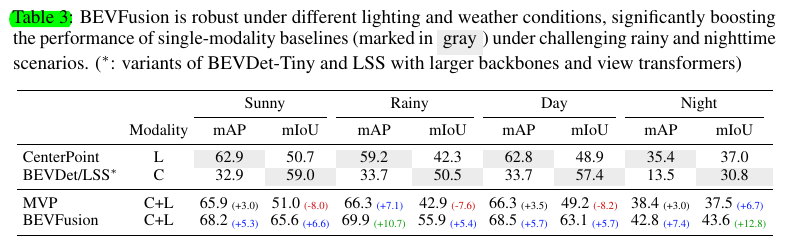
Weather and Lighting.
Sizes and Distances.
Sparser LiDARs.
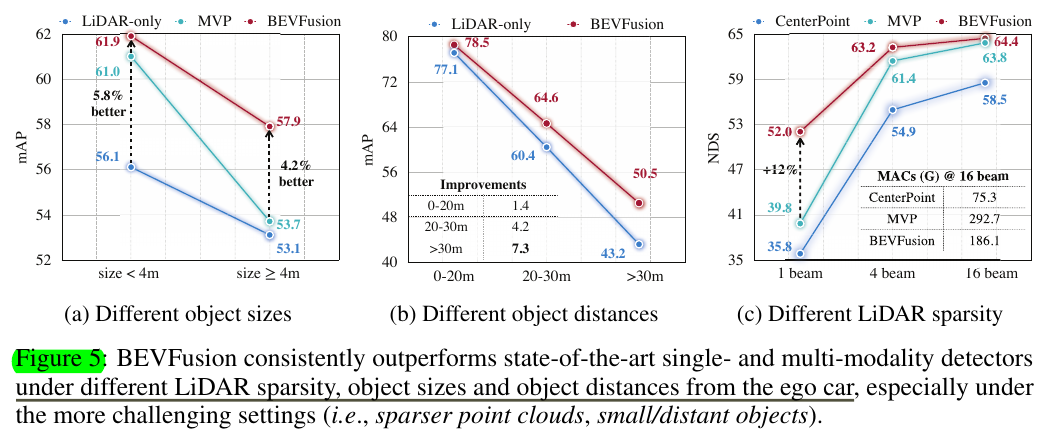
值得注意的是,相比于point-level的fusion,bevfusion在物体size变大了一些的时候依然能够有比较明显的提升
Multi-Task Learning.
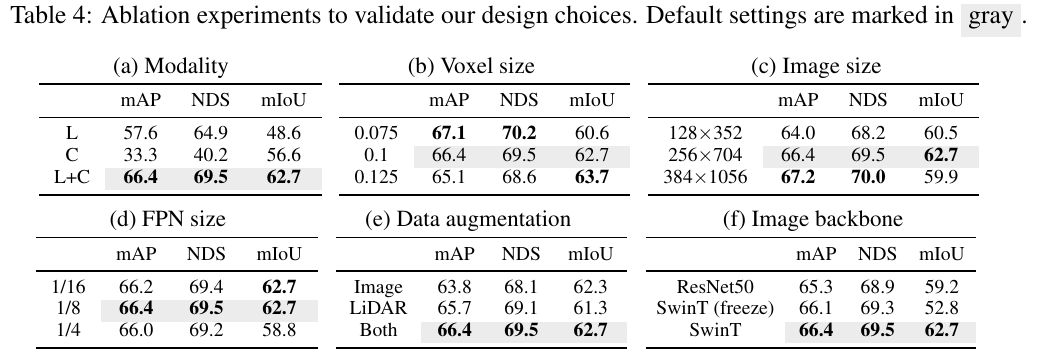
Ablation Studies.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号