『笔记』深度学习面试题
『笔记』深度学习面试题
Part 1
BN/LN/IN/GN
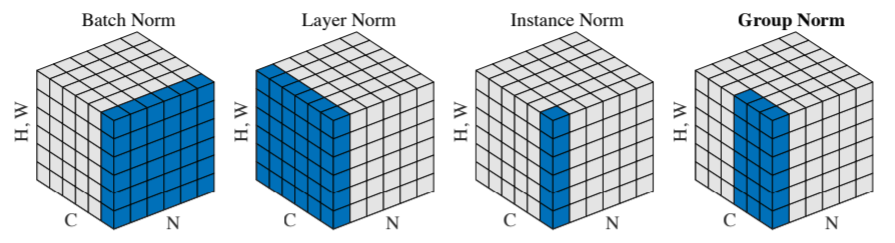
个人总结:
BN:per C over N
LN:per N over C over spatial
GN:per N grouped C over spatial
IN:per N per C over spatial
展示Batch Normalization的意义

https://arxiv.org/pdf/1805.11604.pdf
一种解释:Batchnorm降低ICS(被质疑)
Currently, the most widely accepted explanation of BatchNorm’s success, as well as its original motivation, relates to so-called internal covariate shift (ICS). Informally, ICS refers to the change in the distribution of layer inputs caused by updates to the preceding layers. It is conjectured that such continual change negatively impacts training. The goal of BatchNorm was to reduce ICS and thus remedy this effect.
Our point of start is demonstrating that there does not seem to be any link between the performance gain of BatchNorm and the reduction of internal covariate shift. Or that this link is tenuous, at best. In fact, we find that in a certain sense BatchNorm might not even be reducing internal covariate shift.
从empirical证明Batchnorm带来的作用
Ioffe and Szegedy identify a number of additional properties of BatchNorm. These include 1. prevention of exploding or vanishing gradients, 2. robustness to different settings of hyperparameters such as learning rate and initialization scheme, and 3. keeping most of the activations away from saturation regions of non-linearities.
通过下面关于smooth的讨论和其他的信息,还有:
- it stabilises optimisation allowing much higher learning rates and faster training
- it injects noise (through the batch statistics) improving generalisation
一种解释:Batchnorm让landscape更平滑(作为我的主要理解)
We identify the key impact that BatchNorm has on the training process: it reparametrizes the underlying optimization problem to make its landscape significantly more smooth.
Firstly, Non zero mean is a phenomenon where data is not distributed around the value of 0, but the data has most values greater than zero, or less than zero. Combined with the high variance problem, data becomes very large or very small. This problem is common when training neural networks with deep layer numbers. The fact that the feature is not distributed within stable intervals (small to large values) will have an effect on the optimization process of the network.
As we all know, optimizing a neural network will need to use derivative calculations. Assuming a simple layer calculation formula is y = (Wx + b), the derivative of y from w looks like: dy = dWx. Thus the value of x directly affects the value of the derivative (of course, the concept of gradients in neural network models cannot be so simple but theoretically, x will affect the derivative). Therefore, if x brings unstable changes, the derivative may be too big, or too small, resulting in an unstable learning model. And that also means we can use higher learning rates during training when using Batch Normalization.
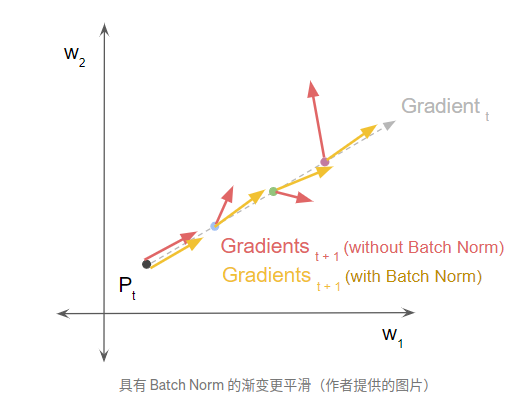
https://towardsdatascience.com/batch-norm-explained-visually-why-does-it-work-90b98bcc58a0
其中展示了一个小实验,以带不带BN的两种设置下,分别按从小到大三个lr步长做step,然后看新位置上的loss和gradient方向大小。BN的使用确实让optimization的过程变得比较稳定,平滑
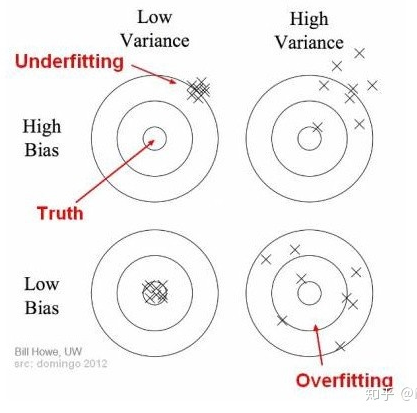
介绍偏差(bias)和方差(variance)的概念和trade-off?
什么是偏差? 可以理解,偏差是当前模型的平均预测和我们需要预测的实际结果之间的差异。 一个高偏差的模型表明它不太注重训练数据。 这使得模型过于简单,在训练和测试中都不能达到很好的准确率。 这种现象也被称为欠拟合(underfitting)。
方差可以简单的理解为数据点上模型输出的分布(或聚类)。 方差越大,模型越有可能密切关注训练数据,而不能在从未遇到的数据上泛化。 结果表明,该模型在训练数据集上取得了很好的效果,但在测试数据集上效果很差。 这就是过拟合(overfitting)现象。
偏差和方差值之间的平衡是必要的。 如果我们的模型过于简单,只有很少的参数,那么它可能有很高的偏差和低方差。另一方面,如果我们的模型有大量的参数,那么它将有高的方差和低的偏差。
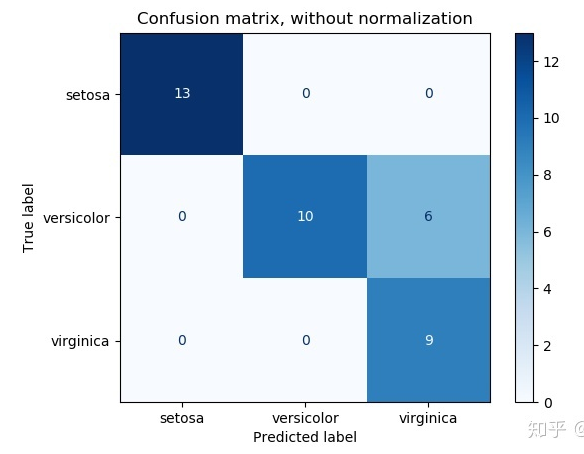
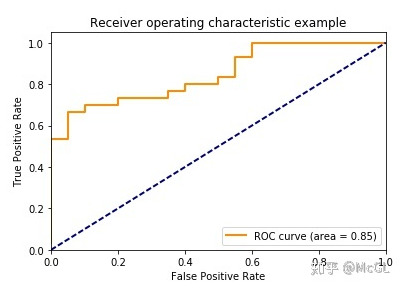
在分类问题上,准确率指标是否完全可靠? 你通常使用哪些指标来评估你的模型?
对于一个分类问题,有许多不同的评价方法。 在准确率方面,公式简单地采用正确预测数据点数除以总数据的方法。 这听起来很合理,但是在现实中,对于不平衡的数据问题,这个数量是不够明显的。(想到之前自己用binary classification检测笔头笔尾的那个方法,background特别多,预测都是对的,但是没什么用)
confusion matrix
ROC (Receiver Operating Characteristic) curve
你如何理解反向传播? 请解释作用机制
激活函数的意义是什么? 激活函数的饱和点是什么?
激活函数的产生是为了打破神经网络的线性。 这些函数可以简单地理解为一个过滤器,用来决定信息是否通过神经元。然而,我们需要理解的是,这些非线性函数的性质使神经网络有可能学习更复杂的函数表示,而不仅仅是使用线性函数。 大多数激活函数是连续可微的函数。也就是说,如果输入有一个小的可微变化(在其定义域的每个点上都有一个导数) ,输出就会有一个小的变化。
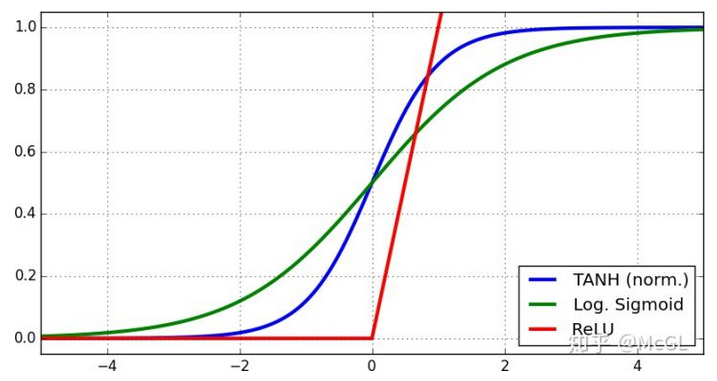
非线性激活函数如 Tanh、 Sigmoid 和 ReLU 函数都有饱和区间。很容易理解,触发函数的饱和范围是即使输入值改变,其输出值也不变的区间。 变化区间存在两个问题,1. 在神经网络的前向时,层的值进入激活函数饱和状态后,会逐渐产生许多相同的输出值。这将在整个模型中产生相同的数据流。 这就是covariance shifting现象。2. 在后向时,导数在饱和区域为零,因此网络几乎不会学到任何东西。 这就是为什么我们需要将值范围设置为0均值的原因,正如Batch Normalization小节中提到的那样。
当输入图像大小增加一倍时,CNN 参数的数量会增加多少倍? 为什么?
CNN 模型的参数数量取决于滤波器的数量和大小,而不是输入图像。 因此,将图像的大小加倍并不会改变模型的参数数量。当然,如果是全卷积神经网络确实不会增加参数量,但是如果有全连接层之类的还是会增加参数量的
如何处理不均衡的数据?
选择正确的度量来评估模型
重采样训练数据集
不同模型的集成(ensemble):通过生成更多的数据来泛化模型在实践中并不总是可行的。 例如你有两个类,一个包含1000个数据的稀有类,一个包含10,000个数据样本的大类。 因此,与其试图找到9000个罕见类的数据样本来做模型训练,我们可以考虑一个10个模型的训练解决方案。 每个模型由1000个稀有类和1000个大类训练而成。 然后利用集成技术获得最佳效果
成本函数:在成本函数中使用惩罚技术严惩数量多的类,以帮助模型自身更好地学习稀有类的数据。 这使得损失函数的值在各类中更加全面
Part 2
https://zhuanlan.zhihu.com/p/40590443
推导反向传播算法
Relu在零点不可导,那么在反向传播中怎么处理?
relu函数仅仅在0点处不可导,这个时候在0点人为设置一个导数值即可,一般设为0(其实就是左侧导数)。导数的本质其实就是在函数的某个点处求切线,在relu的0点有2条切线,会不知道选哪条,这个时候只要人工指定就可以了。
如何处理神经网络中的过拟合问题?
- L1/L2正则化
- dropout
- data argumentation
- early stop
各种方法本身以及为什么他们能够解决过拟合问题,需要牢记
Relu激活函数的优缺点?
Dropout在训练的过程中会随机去掉神经元,那么在编码过程中是怎么处理的呢?
在编码中不需要改变网络结构,只需要每次计算完之后完成以下操作
d3 = np.random.rand(a3.shape[0],a3.shape[1]) < keep-prob
A3 = np.multiply(A3, d3)
dropout的训练过程需要做rescale,这个过程是什么样子的呢?

dropout方法在预测过程中需要如何处理?
在训练过程中做了scale,那么在预测过程中就不需要做dropout,设置keep_prob = 1即可
softmax的公式是什么?实际使用中会有什么问题?如何解决?

梯度消失和梯度爆炸的问题是如何产生的?如何解决?
答:第一个问题相对简单,由于反向传播过程中,前面网络权重的偏导数的计算是逐渐从后往前累乘的,如果使用sigmoid或者tanh激活函数的话,由于导数小于1,因此累乘会逐渐变小,导致梯度消失,前面的网络层权重更新变慢;如果权重本身比较大,累乘会导致前面网络的参数偏导数变大,产生数值上溢。
sigmoid 导数最大为1/4,故只有当abs(w)>4时才可能出现梯度爆炸,因此最普遍发生的是梯度消失问题。
解决方法通常包括
- 使用ReLU等激活函数,梯度只会为0或者1,每层的网络都可以得到相同的更新速度
- M进行梯度裁剪(clip), 如果梯度值大于某个阈值,我们就进行梯度裁剪
- 限制在一个范围内使用正则化,这样会限制参数的大小,从而防止梯度爆炸
- 设计网络层数更少的网络进行模型
- 训练batch normalization
交叉熵损失与KL散度的区别?
关于这几个概念的理解自己在CS4240的总结里已经搞得比较清楚了,不过这个回答依然提供了不错的解释(与我个人的总结和理解是一致的),在这里作为辅助理解和总结

另外这个是一个单独的帖子理解:https://zhuanlan.zhihu.com/p/73780894

 浙公网安备 33010602011771号
浙公网安备 33010602011771号