『论文』PointNet
『论文』PointNet
1. Introduction
To perform weight sharing and other kernel optimizations, most researchers typically transform such data to regular 3D voxel grids or collections of images (e.g, views).
This data representation transformation, however, renders the resulting data unnecessarily voluminous, while also introducing quantization artifacts that can obscure natural invariances of the data
We focus on a different input representation for 3D geometry using simply point clouds. Pointclouds are simple and unified structures that avoid the combinatorial irregularities and complexities of meshes, and thus are easier to learn from
- Pointcloud is just a set of points and therefore invariant to permutations of its members, necessitating computation certain symmetrizations in the net
- pointcloud is a cananical way (meshes, voxels or other formats can be tranformed between)
- ...
The key contributions of our work are as follows:
- We design a novel deep net architecture suitable for consuming unordered point sets in 3D
- We show how such a net can be trained to perform 3D shape classification, shape part segmentation and scene semantic parsing tasks
- We provide thorough empirical and theoretical analysis on the stability and efficiency of our method
- We illustrate the 3D features computed by the selected neurons in the net and develop intuitive explanations for its performance
3. Problem Statement
- Point clouds: \(\{P_i|i=1, ..., n\}\) , each \(P_i\) contains(x, y, z). We could have extra feature channels like color, normal, etc, but here for simplicity and clarity
- For object classification task: outputs k scores for all the k candidate classes
- For semantic segmentation: output n x m scores for each of the n points and m semantic subcategories
4. Deep Learning on Point Sets
4.1. Properties of Point Sets in R^n
- Unordered: Unlike pixel arrays in images or voxel arrays in volumetric grids, point cloud is a set of points without specific order. In other words, a network that consumes N 3D point sets needs to be invariant to N! permutations of the input set in data feeding order
- Interaction among points: neighboring points form a meaningful subset
- Invariance under transformations: the learned representation of the point set should be invariant to certain transformations
4.2. PointNet Architecture
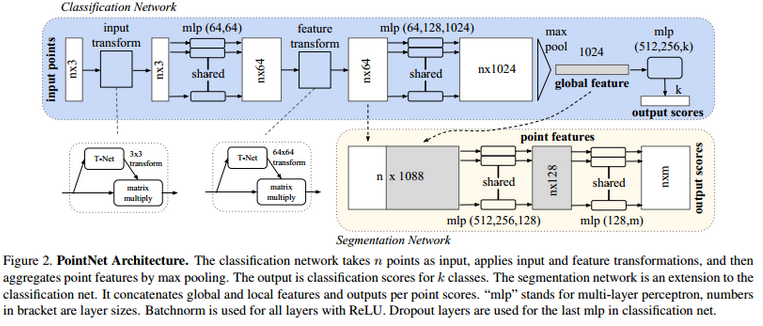
Our network has three key modules:
Symmetry Function for Unordered Input
In order to make a model invariant to input permutation, three strategies exist:
- sort input into a canonical order
- treat the input as a sequence to train an RNN, but augment the training data by all kinds of permutations
- use a simple symmetric function to aggregate the information from each point
Here, a symmetric function takes n vectors as input and outputs a new vector that is invariant to the input order. For example, + and ∗ operators are symmetric binary functions.
(The authors tested 1) and 2) in Fig 5 and shows that they are with problems)
Mathematically, the nn is just a function. so in the function view the permutation invariant corresponds to the symmetric function, so for any ordering of the arguments, the function value is always the same

Local and Global Information Aggregation
The output from the above section forms a vector [f1; ... ; fK], which is a global signature of the input set. We can easily train a SVM or multi-layer perceptron classifier on the shape global features for classification
However, point segmentation requires a combination of local and global knowledge.
Our solution: After computing the global point cloud feature vector, we feed it back to per point features by concatenating the global feature with each of the point features
With this modification our network is able to predict per point quantities that rely on both local geometry and global semantics. For example we can accurately predict per-point normals (fig in supplementary), validating that the network is able to summarize information from the point’s local neighborhood
Joint Alignment Network
The semantic labeling of a point cloud has to be invariant if the point cloud undergoes certain geometric transformations, such as rigid transformation.
We predict an affine transformation matrix by a mini-network (T-net in Fig 2) and directly apply this transformation to the coordinates of input points
This idea can be further extended to the alignment of feature space. However, transformation matrix in the feature space has much higher dimension than the spatial transform matrix. We constrain the feature transformation matrix to be close to orthogonal matrix
4.3. Theoretical Analysis
Universal approximation

The key idea is that in the worst case the network can learn to convert a point cloud into a volumetric representation, by partitioning the space into equal-sized voxels
- 个人小结:总之,作者找到了这样一种方法来构造一个symmetric function,也就是先对每个\(x_i\)都过一遍h,然后过element-wise (along each channel?)的MAX,得到一个vector,再过gamma,这样操作便能够近似于得到了一个在所有\(x_i\)的集合S上做symmetric function的结果,即所表达的无论epsilon是多少,总有一个h和g(gamma*MAX)能够满足
- Note: f is symmetric as long as g is symmetric
https://www.youtube.com/watch?v=Cge-hot0Oc0
Bottleneck dimension and stability
We find that the expressiveness of our network is strongly affected by the dimension of the max pooling layer
The following theorem tells us that small corruptions or extra noise points in the input set are not likely to change the output of our network
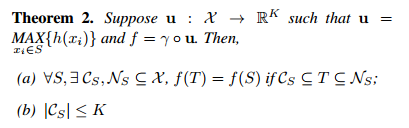
(a) says that f(S) is unchanged up to the input corruption if all points in CS are preserved; it is also unchanged with extra noise points up to NS. (b) says that CS only contains a bounded number of points, determined by K
\(C_S\): critical point set of S, K: the bottleneck dimension of f
The robustness is gained in analogy to the sparsity principle in machine learning models. Intuitively, our network learns to summarize a shape by a sparse set of key points
5. Experiment
直接去看我当时seminar presentation的对应部分就行了,看speaker notes。以及前面关于architecture介绍的部分,感觉自己准备得挺不错的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号