『论文』VoxelNet
『论文』VoxelNet
2. VoxelNet
2.1. VoxelNet Architecture
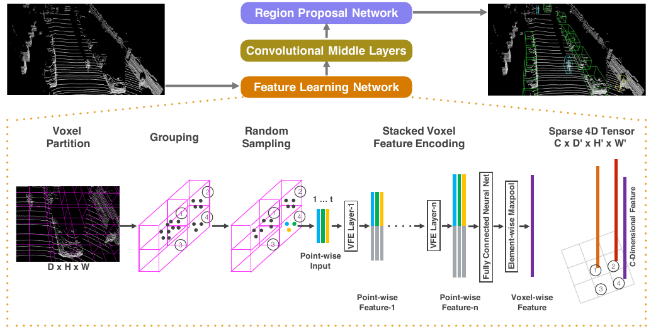
2.1.1 Feature Learning Network
Voxel Partition + Grouping + Random Sampling
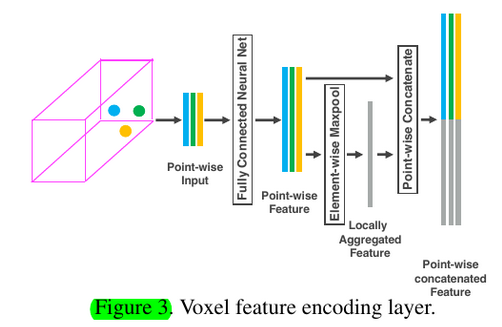
Stacked Voxel Feature Encoding
Sparse Tensor Representation
2.1.2 Convolutional Middle Layers
Each convolutional middle layer applies 3D convolution, BN layer, and ReLU layer sequentially.
2.1.3 Region Proposal Network
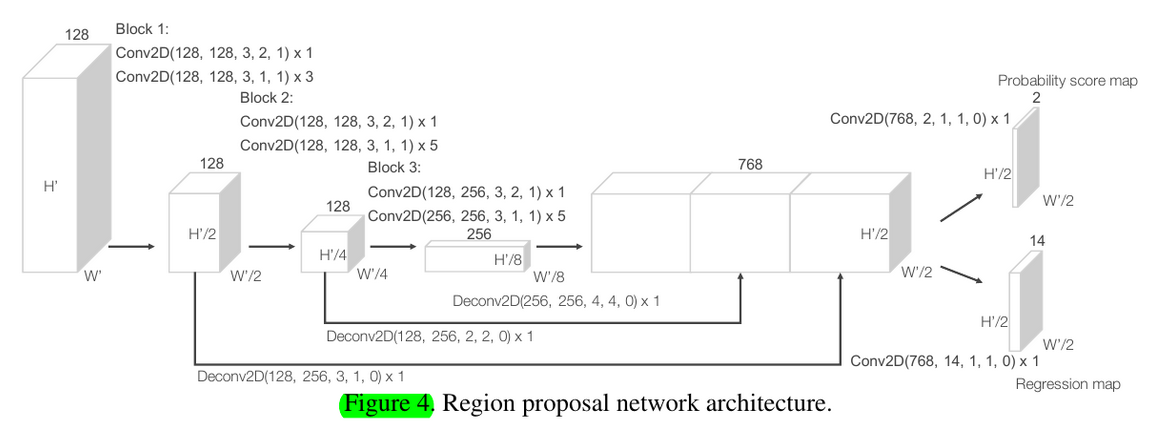
总结而言,VoxelNet和SECOND,乃至PointPillars其实是一个方法,它们都是 - 先voxelization,然后VFE(多层FCN三件套得到point-wise features + max pooling along channels得到voxel-wise channels;或者说类PointNet)。
到这里,PointPillars直接scatter回bev了,这和它pillar的设计有一定关系,因为不存在z方向的voxel划分,前面一直在学的就是bev下竖直pillar的feature。
对于VoxelNet和SECOND,现在就往下接了3D convolution,去对目前组织好的voxel-wise features继续学,伴随着voxel feature channel的升高和voxel fmp尺寸的减小。在学完之后,还是要到bev,SECOND里通过接一个view把z方向上的channels放到了一起来做的(height compression)。
一点思考:所以其实个人感觉,对于VoxelNet和SECOND,从传播上来说,也是完全不用3D convolution的,毕竟这部分从维度上来说是没有变化的,都是voxel-wise features,但,通过学这样的过程,也是随着随着voxel feature channel的升高和voxel fmp尺寸的减小,把数据整体和局部的一些特征泛化了,感受了,使得最后的bev height compression也合理了(实际上,SECOND的3D convolution结束后的fmp的z方向只有两个bins,这样的compression无伤大雅),而如果真的直接不做3D convolution来压缩维度,直接生成bev下的features,由于其使用的是一个一个小的voxel,这样的特征肯定是很weak的。而PointPillars不用做的可能的一点就是,其一开始就认准了搞bev,voxel都不在竖直方向上切了直接pillar,使一步scatter到bev变得合理了。
2.2. Loss Function

与后面SECOND和PointPillars不同的是,这里的classification没有用focal来解决正负样板imbalance的问题,而是较为简单地使用weight term。另外,这里也印证了classification是binary CE
2.3. Efficient Implementation
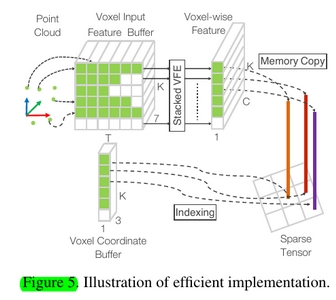
可以看到,这种组织为voxel features & coords的输入就是在VoxelNet这里首先开始用的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号