『论文』FCOS
『论文』FCOS
注意:基本完全拷贝kissrabbit的文章内容,因此仅有备份意义
为什么选FCOS来讲呢?其实,FCOS 出来的那一年,也有很多其他anchor-free的工作,不过,我很喜欢FCOS提出的那一套多尺度分配的方案,在yolo-v1的时候,它只用了最后输出的那个feature map,也就是单一尺度,配合上“网格”的这种,自然而然就有一个问题:当两个物体落在同一个网格中,怎么办?所以,早期单尺度的anchor-free碰到这个问题就完蛋了,后来靠着anchor box来解决。有了FPN后,我们就可以用多个feature map来解决。不过,这同时也有一个问题,哪些物体分配到哪个fmap上去呢?对此,FCOS 则是从pixel-wise的角度来决定的。后面我们会仔细说一下的,这篇文章我不打算放到我的专栏《目标检测——基础与实践》中了,另外,我也会去复现这个工作,当然不是百分百复现,FCOS 本身结构很大,输入的图像也是800x1000左右的,手里的资源不够,所以,我尝试复现一个轻量化版本的,努努力,不行就放弃,啊哈哈哈哈!
我认为FCOS这篇工作的最大亮点就是在于多尺度分配的方法,解决了anchor-free情况下物体遮挡的问题。因此,在说它之前,让我们先来简单地回顾下YOLO-v1和anchor box的发展史。
Note: [作者开始说相声,R-CNN, Fast R-CNN, YOLOv1, Faster R-CNN, YOLOv2, ... YOLOv3!] 话再说回来,无论这场纷争多么激烈,大家都有一个不变的内核,那就是anchor box。不管各家门派的武功是多么花里胡哨,其内在,仍是共通。anchor-based的时代也够久了,该让让位了。一股暗流,开始涌动。某处,有人已经盯上了anchor box,因为这个统治江湖多年的内核却有着内在的弊端:
- anchor box需要人工设计长宽比,面积,数量。纵然YOLO-v2给出了kmeans方法,却也不过是将人力换成了计算机算力,换汤不换药。这些超参数为OD带来了不必要的冗余;
- 无论多么精心设计anchor box,只要这个模型训练完了,这一切就成了定数,一旦遇到他从未遇见的数据(与训练数据的分布有较大的偏差),anchor box的泛化问题就不可避免了;
- 为了提高recall值,各大门派通常都会增加anchor box的数量,这无疑会对内存占用和计算力消耗带来负担。
- 这么多anchor box,后处理(post-process)的压力也大啊!
在意识到anchor box的种种弊端之后,沉睡许久的anchor-free,再一次苏醒。2019年,代表着旧势力的FCOS(Fully Convolutional One-Stage Object Detection)以全新的样貌强势回归,在这场OD争夺战中,脱颖而出!在这之前,anchor-free这一one-stage的开山流派的消沉主要有以下几点原因: - 问题1:首先是YOLO-v1。在YOLO-v1中,positive sample只有中心点所在的网格,其他都是negative sample,这对recall带来了很不好的影响。
- 问题2:物体重叠。这是个老问题,后来被anchor box解决了,但是,anchor-free就真的解决不了这个问题吗?
FCOS解决第一个问题:样本匹配策略
我们不应该只看中心点的网格,只要这个网格处于gt box的框内,我们就应该都视为positive sample.因此,FCOS 不再只学习预测中心点,对于每个位置,我们学习预测它到gt box的上,下,左,右的四个距离tblr

这里需要注意一点的是,上面的计算是在feature map的尺度上计算的,因此,为了判断fmap上一个位置是否在gt box,需要将其映射到原图大小上去,在原图中的位置如下式:
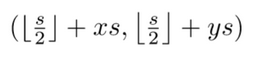
其中的 s 就是feature map所对应的 stride 。这个公式使用了“亚像素的概念”,即在特征图的坐标x加上一个0.5,然后再乘以stride映射回原图。若是stride不是2的倍数,就会出现向下取整的符号了,也就和论文中的公式对上了。不过,通常我们的网络的降采样倍数都是2的整数次幂,也就没有这个担忧了。
- Note: 为什么不把gt投过来呢,不是说计算是在feature map上进行的吗。去看了下论文,应该确实tblr就是预测feature map上的tblr,因为其把ground-truth boxes都定义成了一个set,每个feature map layers都有自己的一组。可能这个方法是能更好地判断吧

确定了当前特征图上的位置是在原图上对应的位置后,再计算四个距离。显然,这四个数都是非负的,出现负数就说明不在gt框里了。于是,FCOS 使用指数函数来输出这四个量。当然,网络在回归边界框的时候,并不是去学习四个距离,而是使用计算IoU,使用IoU损失去回归,因此,算出来的这四个量不会直接参与到损失中。
对于正样本的划分,FCOS 采用简单而直观的方式,将真实框所覆盖的所有网格都视作正例,每个正例去学习分类和回归。即FCOS是一种“one-to-many”的匹配策略,这种匹配策略的好处就是训练收敛的速度很快,而且可以有效提高模型的recall。
所谓的收敛速度快,即仅使用“1x”的训练策略。以COCO的train2017训练集为例,如果把batchsize设为16,那么1x的训练策略就是迭代90K次,约等于12个epoch。如果改变batchsize,那么1x的90K次也要做等比例的变换(建议这么做,以示“公平”),如64的1x对应22.5K。这是常用的训练策略。那为什么YOLOv3要训练那么久,将近300个epoch呢?这是因为YOLOv3采取的是“one-to-one”匹配策略,即一个目标只有一个正样本,所以训练速度慢。通常,为了实验结果看起来更能打,往往也会延长训练时间,如“2x”和“3x”,尤其是在加了一大堆“武器”:X101、DCN等等,就为了拼SOTA,那么这个时候延长训练时间是有必要的。但即便延长到“6x”,也就是大约72个epoch。言归正传。
每个正例都去预测自己所在的位置相较于真实框的四个边界的距离,并通过IoU损失去做回归。其实,仔细想一下这一点,不难发现,FCOS 虽然打着anchor free的旗号,却还是有着anchor的概念:每个正例都预测自己所在的位置相较于真实框的四个边界的距离。换言之,FCOS 的边界框检测结果来源于特征图上的每个位置的距离预测,因此,FCOS 的检测模式和YOLO、SSD、RetinaNet 是没有实质差别的,都是沿着特征图的spatial维度去获取每个位置的预测结果。再换言之,FCOS的本质就是把原先放置在每个anchor处的k个anchor box拿掉了,每个位置只负责一个预测,这就相当于每个anchor处只放一个不会提供任何先验信息的、尺寸为 1x1 的anchor box了。
后来的ATSS工作把这一点挑明了:不论是所谓的anchor-based还是anchor-free,二者实质差别就在于样本匹配策略上。换言之,现在所谓的anchor-free它还是anchor-based。因此,相较于anchor-free这个称呼,我倒是觉得anchor box free这个称呼更加合适。anchor 仍在,anchor box不在了。但也许是FCOS工作的影响力太大的缘故,anchor-free这一称呼就这么流传下来了。
FCOS解决问题2:物体重叠
虽然问题1解决了,但是这种方法下,物体重叠的问题反而加重了,以前的YOLO-v1只是担心物体的中心点重叠,只要中心点不重叠,两个物体的gt box怎么重叠都无所谓。但是,由于FCOS的这种思想,一旦两个gt box发生重叠,那么重叠区域的样本应该作为谁的正例呢?
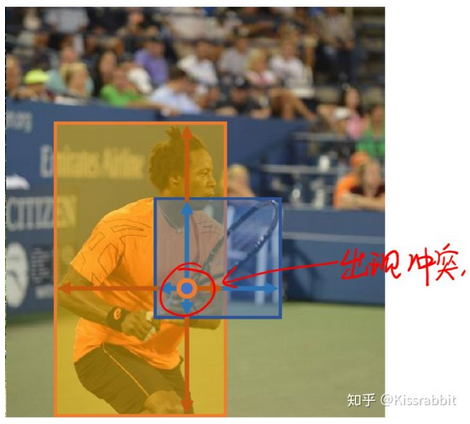
FCOS 对此早有对策,原文中一开始提到了个很naive的方法来解决这个问题,不过,既然naive,咱就不提了,毕竟FCOS后面给了个更好的办法!说到这个问题之前,我们再回顾一下YOLO,YOLO-v1只用到了最后一个feature map,YOLO-v2也是,而后来FPN的工作问世,告诉了大家:我们可以在多个feature map上去做预测,并且不同尺度( stride 不同)的feature map可以预测不同尺度的物体
比如, stride=8 可以预测小物体; stride=16可以预测中物体; stride=32可以预测大物体。于是,FCOS 就想到可以用FPN的这套路子来解决重叠问题,具体来说:

为什么这样就可以保证多尺度了呢?我们以上图的蓝框和黄框为例,很明显,更小的蓝框中算出来的所有的 m 中最大的 M 也不会超过框的最大边,即 M ≤ max(b_h, b_w) 。蓝框中的点,也就更多地会被映射到更小的阈值范围中去,从而,这些点都会在 stride 比较小的fmap中,;同理,更大的黄框所包含的正例更多地会落在大的阈值范围中,因此黄框的正例也就多数集中在 stride 比较大的fmap上去,不过,也很容易想到,一个gt box中包含的点,不都落在同一个fmap上去,也就是说,可能多个fmap都会检测到同一个物体。
Note: 也就是说,根据对于每个feature map预设的阈值范围,这个范围对于越浅-/也就是越大-/也就是越期望检测小物体-的feature map越小(我只允许你检测小物体!),预测的tblr在阈值内才在该feature map上是正例,于是小尺寸的预测,也就是预测的小物体就更分配到了更期望于预测小物体的feature map上。总之,各不同尺寸的预测/object就分别在不同的feature map显露,而在别的是负样本。
Note: 怎么听这意思,这tblr又是在统一的image尺寸上了?不然阈值怎么直接用,还64,512啥的,不管了,这个到底是在哪个图上操作的事他妈的不管到哪就没见喜欢说清楚的
因此,FCOS 不仅有了多尺度预测的能力,还很漂亮地解决了物体重叠的问题。
Center-ness
一个gt box中这么多点,它们的贡献都应该是一样的吗?bounding box的作用其实是想告诉我们目标在图像中的哪个地方。按照FCOS的思想,不包含目标的像素也会成为正例,就比如上面图中的左上角小部分,都是背景,没有人的像素,因此,FCOS认为,这样地方的预测应该贡献小一些,而包含物体的像素应该贡献大一些。在这个很自然的想法的驱使下,FCOS又加了个新装备:center-ness:

center-ness的作用就是加大中心点附近的贡献,离中心点越远,贡献越小。其实,仔细想想,这就是YOLO-v1的中心点即正例的soft版本——我不只取中心点,但我也不是很想要离中心点远的样本,可是呢,也不能就这么扔了它们,于是,hard变为soft,既然不能舍弃你们,那就让你们的贡献小一些吧。对于每个位置,其centerness的标签如下:
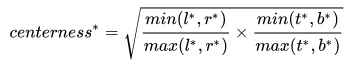
由于这个值的范围是在0,1之间,因此,FCOS就用BCE来学它。center-ness相对于对每个位置预测的bbox的置信度,因此,在test的时候,将预测的center-ness的值乘到类别置信度上去,用二者的乘积作为最终的 score 去做NMS处理。AP提升的效果还是很明显的。
最后的Loss 函数中,类别损失使用Focal Loss,bbox损失用IoU,center-ness损失用BCE。
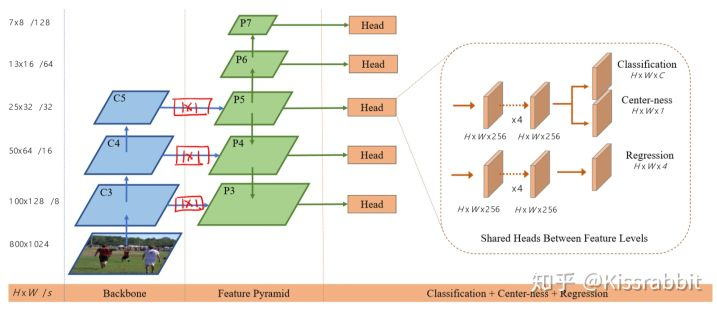
这里还有个小细节需要说一下,FCOS所使用的backbone是ResNet-50,而所有的fmap的detection head部分是权重共享的,但是,FCOS考虑到了一个问题:不同尺度的fmap预测的物体大小也不同,从bbox预测的角度来讲,这种共享合理吗?FCOS给出的答案是不合理,为了缓和这个问题,在每个尺度负责预测bbox四个参数的 exp(x) 中,分别加入了一个可学习的参数 s_i ,即 exp(s_i * x) ,通过学习这个 s_i 来适应各个尺度的bbox预测。而head的其他参数依旧是共享的。
就这样,anchor-free的大旗再一次被扛起,FCOS在江湖中混得是风生水起,OD的格局又一次被重新洗牌。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号