『记录』简单调试mmdet3d的训练流程
『记录』简单调试mmdet3d的训练流程
调试流程
主要流程:train.py,train_model函数,train_detector函数,runner.run
在train.py主流程,和进入的train_detector中管理了外部事务。进入所构建的runner.run(),开始训练。
在mmcv的epoch_based_runner.py中定义了runner的操作。run函数包装好了epoch的管理,包括了调用关于run前run后的hook,并根据设定的workflow进行各epoch的执行。其中根据所传入的mode,用getattr(self, mode)调用了具体执行的是train()还是val()
在train()中,便是我们真正的一个epoch的过程,不过其也是个包装,包括了调用关于当前epoch和iter相关的hook,并使用run_iter执行,而run_iter中又调用当前具体model的train_step或val_step执行。所以,最基层的纯粹的执行当前步的训练,应该就是在model自己的train_step中的
(通过查看代码,train_step是定义在mmdet的BaseDetector类的,mmdet3d用BaseDetector3D继承它,然后各类模型又继承我mmdet3d中的这个基类。另外,train_step其实是只执行forward,得到loss,在里面其实是执行了这样一行:losses = self(**data),而不执行optimizer的bp和update)
"""The iteration step during training.
This method defines an iteration step during training, except for the
back propagation and optimizer updating, which are done in an optimizer
hook. Note that in some complicated cases or models, the whole process
including back propagation and optimizer updating is also defined in
this method, such as GAN.
"""
不过首先,train函数中进行了当前epoch对dataloader的遍历,于是有获取batch的过程,进入了dataset的getitem,以此为开始看一下
数据集:开始__getitem__,以及在其中通过整个pipeline进行transform
进入Custom3DDataset的getitem,根据mode,进入了self.prepare_train_data(idx)
在prepare_train_data中主要执行三步,首先get_data_info把当前idx对应data相关路径和标签读取,首次放入了我们的dict,开始了我们的旅程。注意gt box的存放是一个mmdet3d转换的自己的LiDARInstance3DBoxes实例。这个dict也将存储各种东西在整个流程中,然后pre_pipeline,作为预准备,把一些后面会或者可能会用到的key创建好,置空list。至此得到
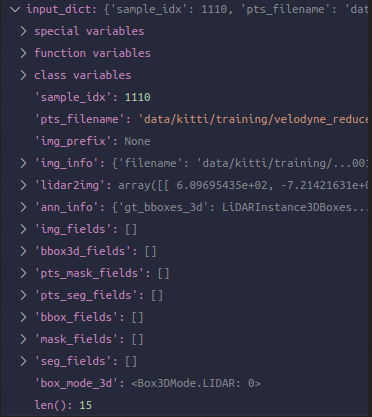
然后第三步正式开始执行self.pipeline(input_dict),自然就是调用我们对应于config中定义好的pipeline所生成的一系列变换Compose,此时进入Compose的call,即遍历自己顺序定义好的各种transform和操作,通过pipeline,开始准备数据
训练数据pipeline:开始通过
后来发现官网竟然也有这部分的解释,有这么一张图:
不过自己既然写了,也是很有用的,接下来看一下流程
-
第一个:LoadPointsFromFile的call,其中加载这个核心操作如果mmcv的fileclient可用的话就用。另外一点是mmdet3d将所加载的点根据指定的类型处理为自己定义的点相关的类,于是这里就是一个LiDARPoints实例。完成后,dict多了个key
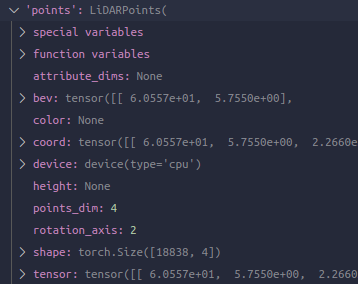
-
第二个:LoadImageFromFile,其是在mmdet定义的,这里在mmdet3d中自然搜不到,不过只看一下效果即可,多了这5个key。img_fields也多了img这个字符串
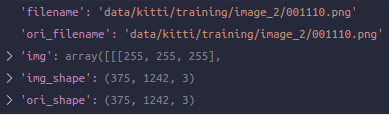
-
第三个:LoadAnnotations3D的call,很明显是加载我们的标签相关。根据传入的arg指定要加载的类型调用不同的类内加载函数,我们在这里是with_bbox_3d=True, with_label_3d=True。其实呢,在一开始加载data的时候这部分就蕴涵放在了前面的几个key里,这里是把它们提取了一下放在了新key里,毕竟方便用一些。得到如下两个key,label说的不过就是单单类别。另外,bbox_3d_fields这个list也有了gt_bboxes_3d这个字符串,于是可以猜测,带fields就是为了保存当前dict中有这个东西的key的名字都是什么,方便根据这个去找

-
第四个:Resize,这里也是mmdet的pipeline,这里贴一下链接就可以了。这两个量得到更新:

-
第五个:GlobalRotScaleTrans,根据参数中给定的限制范围,这里对点云以及box进行augmentation操作:R/S/T,由于点云和bbox在mmdet3d中都已经是自己定义好的类别了,这里进行的操作其实是调用它们的类内函数如.rotate,.scale,.translate进行的。另外得到了如下keys
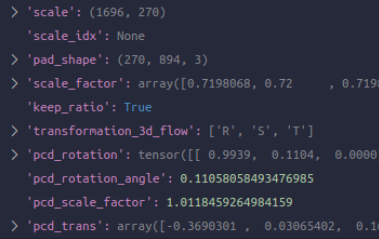
-
第六个:RandomFlip3D,执行flip。值得注意的是这个类是集成mmdet对于图像的RandomFlip类,而且这里也和图像有关系,在call时第一句就是传dict给调用父类的call,也就是执行一下是不是flip一下图像(如果有的话),另外初始化时指定是否sync_2d,如果是的话,跟随已经对图像执行了的是否flip了的结果对点云flip。我这次执行完恰好没有flip
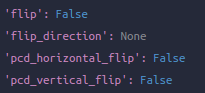
-
第七个:PointsRangeFilter,根据config指定的range过滤一下点云
-
第八个:ObjectRangeFilter,同样过滤一下bbox。经过这两步points和gt_bboxes_3d这两个key得到更新
-
第九个:PointShuffle,很明显是shuffle一下点云,points得到更新
-
第十个:Normalize,很明显是mmdet的,对图像的。img得到更新,同时,config中传入的指定这一步norm的参数也保存在了一个新key中

-
第十一个:Pad,很明显是mmdet的,对图像的。链接在这里。img得到更新,同时,pad后的shape(这就是现在img的shape)以及另外的信息也保存在了新key中

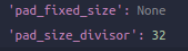
-
第十二个:DefaultFormatBundle3D。这里是mmdet3d对dict中多项常用数据的统一的形式处理,在其类描述中写得很清楚为:
"""Default formatting bundle. It simplifies the pipeline of formatting common fields for voxels, including "proposals", "gt_bboxes", "gt_labels", "gt_masks" and "gt_semantic_seg". These fields are formatted as follows. - img: (1)transpose, (2)to tensor, (3)to DataContainer (stack=True) - proposals: (1)to tensor, (2)to DataContainer - gt_bboxes: (1)to tensor, (2)to DataContainer - gt_bboxes_ignore: (1)to tensor, (2)to DataContainer - gt_labels: (1)to tensor, (2)to DataContainer """至于这个DataContainer,是mmcv定义的一种存数据的通用类,其描述为:
"""A container for any type of objects. Typically tensors will be stacked in the collate function and sliced along some dimension in the scatter function. This behavior has some limitations. 1. All tensors have to be the same size. 2. Types are limited (numpy array or Tensor). We design `DataContainer` and `MMDataParallel` to overcome these limitations. The behavior can be either of the following. - copy to GPU, pad all tensors to the same size and stack them - copy to GPU without stacking - leave the objects as is and pass it to the model - pad_dims specifies the number of last few dimensions to do padding """后面记得再研究。这里得到更新为:
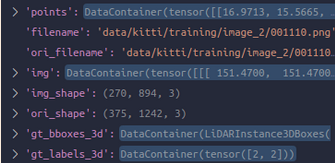
可以想象,前面我们对点云和bbox都用了mmdet3d两个不同的特色类,但是现在看来那个就是为了在pipeline中好操作的,现在马上就要结束准备,前面的transformation们也已经方便地做完,即将开始输入了。现在就把它们都回归正常tensor就可以了,所以对于这里,也就是mmcv对于tensor数据的包装DataContainer -
第十三个:Collect3D,这一步其实很简单,就是用于pipeline的最后一步,其根据我们初始化时候给它指定的meta_keys,为了我们具体的任务搞出来所需要的整顿好,把dict中我们已经存下的这么多东西进行自定义的收集,放入img_metas这个key中,其是一个包含了我们所收集的内容的DataContainer。
"""Collect data from the loader relevant to the specific task. This is usually the last stage of the data loader pipeline. Typically keys is set to some subset of "img", "proposals", "gt_bboxes", "gt_bboxes_ignore", "gt_labels", and/or "gt_masks". The "img_meta" item is always populated. The contents of the "img_meta" dictionary depends on "meta_keys". By default this includes: - 'img_shape': shape of the image input to the network as a tuple (h, w, c). Note that images may be zero padded on the bottom/right if the batch tensor is larger than this shape. - 'scale_factor': a float indicating the preprocessing scale - 'flip': a boolean indicating if image flip transform was used - 'filename': path to the image file - 'ori_shape': original shape of the image as a tuple (h, w, c) - 'pad_shape': image shape after padding - 'lidar2img': transform from lidar to image - 'depth2img': transform from depth to image - 'cam2img': transform from camera to image - 'pcd_horizontal_flip': a boolean indicating if point cloud is flipped horizontally - 'pcd_vertical_flip': a boolean indicating if point cloud is flipped vertically - 'box_mode_3d': 3D box mode - 'box_type_3d': 3D box type - 'img_norm_cfg': a dict of normalization information: - mean: per channel mean subtraction - std: per channel std divisor - to_rgb: bool indicating if bgr was converted to rgb - 'pcd_trans': point cloud transformations - 'sample_idx': sample index - 'pcd_scale_factor': point cloud scale factor - 'pcd_rotation': rotation applied to point cloud - 'pts_filename': path to point cloud file. Args: keys (Sequence[str]): Keys of results to be collected in ``data``. meta_keys (Sequence[str], optional): Meta keys to be converted to ``mmcv.DataContainer`` and collected in ``data[img_metas]``. Default: ('filename', 'ori_shape', 'img_shape', 'lidar2img', 'depth2img', 'cam2img', 'pad_shape', 'scale_factor', 'flip', 'pcd_horizontal_flip', 'pcd_vertical_flip', 'box_mode_3d', 'box_type_3d', 'img_norm_cfg', 'pcd_trans', 'sample_idx', 'pcd_scale_factor', 'pcd_rotation', 'pts_filename') """于是最后,整体上就剩这5个key:
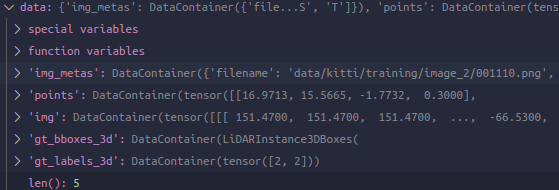
其中img_meta中的data包括:
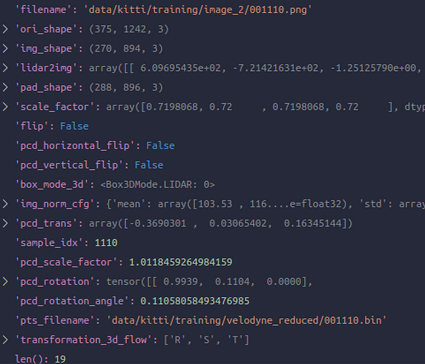
也就是说,Collect3D初始化指定的时候的keys就是我们想拿来直接用的,会被直接放在dict下,而第二个参数meta_keys指定将要被拿出来一起构造入dict中img_metas这个key的DC中,Collect3D默认参数就定义了一些,基本上可以直接用默认的这些
另外,结束退出来之后,如果数据集初始化的时候指定了filter_empty_gt,还进行一下过滤,如果gt_labels_3d这个key没有一个不是-1,就返回None。至此,pipeline通过结束,数据部分就已经准备好了。再次退到getitem,其实这部分是有是否None的一个处理的,在while循环中调刚才的prepare_train_data,如果返回来的是None,就rand another一个idx再continue一次
模型:开始forward
Base3DDetector中定义forward为调用forward_train或者forward_test,这里我们进入MVXTwoStageDetector的forward_train。看一下进入之后的batch:
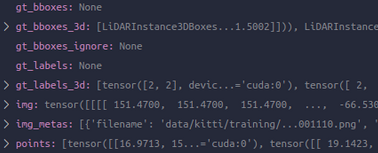
可以看到数据都恢复了原来的样子,而不是DC,另外以list格式组织着。这里发生了什么?哪一步进行的还原
提取图像特征图:ResNet + FPN
ResNet和FPN的forward:先执行img_feats = self.img_backbone(img),再进行img_feats = self.img_neck(img_feats)。输入图像是:[2, 3, 288, 896],经过backbone的生成了四个尺度的feature map,分别为:[2, 256, 72, 224],[2, 512, 36, 112],[2, 1024, 18, 56],[2, 2048, 9, 28],然后经过neck后,得到的为:[2, 256, 72, 224],[2, 256, 36, 112],[2, 256, 18, 56],[2, 256, 9, 28]。最后输出的还有一个[2, 256, 5, 14],总共5个尺度特征图
提取以及融合图像特征,得到点云特征图:Voxelization + DynamicVFE + PointFusion & SparseEncoder & SECOND + SECONDFPN
-
Voxelization的forward:执行voxelize。归根结底利用的当然就是mmcv的voxelization的ops,具体则是对应了类内pts_voxel_layer这个module的初始化,其是mmcv包装好的使用了该ops的一个nn.module类Voxelization,现在也就是用这个模块的forward。这个模块初始化时,config这里我们是传的-1-1,所以是自动会成为dynamic的voxelization。目前的输入中points是tensor的list,包含有[17743, 4]和[17360, 4],经过Voxelization后可以分别得到[17743, 3]和[17360, 3],举个例子来说如图
这里执行的是类内新定义的voxelize函数,作用是处理一下batch,总之最终是得到points为cat后的[35103, 4],coors为[35103, 4],其中第一列代表该voxel所属的batch id,后三个是coords位置。
值得注意的是,返回到extract_pts_feat,这个points竟然直接被命名为了voxels,这也间接说明了自己之前的一个疑问,也就是DV中voxel没有点的维度,就一个特征维度,就像只有一个点一样。看来DV里就是一个点一个voxel,然后coords照常代表该voxel位置。但是万一有不止一个点在一个voxel了呢?
(HV输出的features是MxNxC,有num_points保存每个voxel实际有多少个点,以及coords是Mx(1+NDim)。而DV则返回的是features NxC,没有num_points,以及coords Nx(1+NDim)。具体为什么voxel内部只有一个点这样的C呢?)注:自己在后面得到了解答 -
DynamicVFE的forward:point geometric decoration以及进入vfe layers的forward。第一步也就是decorate points的geometric features,经过操作之后得到features为[35103, 10],然后进行第二步,做fc+bn1d+relu三件套(类PointNet)操作,比如经过第一层后得到[35103, 64]。然后,使用一个特别的类内vfe_scatter实例,将其scatter成voxel_features得到[29468, 64]和voxel_coors [29468, 4]
(scatter过程使用经过vfe_scatter定义而使用max,于是就是一个符合自己理解的完整的vfe layer(类PointNet)了,这个新的64就是一个经过完整vfe layer的features了)
现在不是最后一层,于是为了下一层point-wise层面的vfe layer的forward,再次把刚刚得到的features搞回point层面,用类内函数map_voxel_center_to_point得到feat_per_point [35103, 64],并且把这个新features和原point features给cat,得到 [35103, 128]- 在这里,仔细思考了所谓DV的思想,以及HV和DV的区别。总得来说,对于HV,其在voxelize时就已经是组织好在voxel内的points了,于是后面的操作就是1. 在decoration的时候比较好计算 2. 在vfe layer的时候也是直接forward就行了,但缺点也就是所谓HV的缺点,既然已经组织好在voxel内,有的被舍弃了,有的zero-pad了,都是在vfe layer里一起forward的,信息质量相对比较差
- 而DV,关键就是在于它vfe layer这里提取特征的时候特别精简和有效。总得来说,我认为其核心在于两部分,第一个是dynamic voxelize的时候,我就是纯纯记录每个点所根据voxel设定所在的voxel的coords,voxel features就是原点云features,coords是每个voxel位置(也即每个点所在voxel位置)(可以想象,coords是可以重复的,也就是在同一个voxel的点的coords都单独记录了下来)。一开始总是在疑惑这个voxelize并没有实现DV的操作,但其实这只是第一部分,实际上和第二部分配合使用。
- 第二部分也就是dynamic scatter操作,其是另外一个mmcv中叫做DynamicScatter的类,像voxelization一样也是包装了ops的模块。给定points和它们的coords,指定一个reduce策略(mean或者max),voxel设定已初始化在类中,输出这些point features所对应的voxel的features,即将同一个voxel的point的features按照reduce策略得到该voxel的feature.将这两步操作配合使用,中间夹一个vfe layer的forward,也就实现了无voxel组织情况下vfe layer对point features的extraction了!
- 在这种情况下经过了scatter操作我认为才算一次完整的vfe layer,毕竟有max,所以其实还有一个重要操作则是把这些voxel features给映射回对应points的features,我愿意叫做map voxel features to points该函数在类内叫做map_voxel_center_to_point,输入voxel features和其coords,以及points的coords,就可以把在那个voxel内的points的features置为voxel的features
- 所以回顾在这里的流程,就是points的Nx3(已经经过dynamic voxelization得到各points所在voxel corrds,作为后续所需要的基础重要信息),经vfe三件套得到Nx64,然后scatter回voxel得到分voxel内max pooling下的Mx64,然后map to point再得到Nx64,再把这两个features给cat得到Nx128,完成一层vfe layer的forward
- 另外值得一提的是,在DV下,前面decoration关于voxel内mean point的features的时候,也不像HV一样简单可以直接操作,也需要先scatter再map to point。这下,基本就对这个地方清楚了,真的很妙。个人认为,核心就是在于三个操作dynamic voxelize,dynamic scatter,map voxel features to points
进行第二层,同样第一步forward第二层的vfe,得到[3103, 64],然后这是最后一层vfe,我们又有fusion layer,进行fusion。于是这部分进入PointFusion的forward。对代码已经进行了基本阅读和注释,总得来说,传入多尺度的图像特征图,点云特征图,原始点云以及img_metas
首先类内定义了一组lateral convs对传来的image features做处理,都降成128维,得到feature map尺寸为:[2, 128, 72, 224],[2, 128, 36, 112],[2, 128, 18, 56],[2, 128, 9, 28],[2, 128, 5, 14]
开始核心步骤:利用img_metas所存储的一路走来对点云的transformation相关信息对点云进行InverseAug,然后对点云投影至图像,然后根据图像尺度以及图像的tranformation得到最终正确的图像2维坐标。使用F.grid_sample取出对应位置图像特征图上的对应特征,于是获得了图像特征。代码在这里的处理是一帧一帧的,然后再cat,同一帧点云,在图像各尺度特征图上索到的也是cat在一起的,比如对于这里的第一帧点云,索到的features为[17743, 640]。batch的最终索好的image features返回为[35103, 640]
然后各自经过一组fc+bn1d处理一下特征维度,得到图像而来的[35103, 128](640降到128)和点云的[35103, 128](64升到128)。然后这里的一步fuse使用了相加(论文里应该说的是cat),做了relu,然后输出这个将经过vfe layers的point features与image features融合了的features
然后返回,仍然dynamic scatter得到voxel的features和coords,得到[29468, 128]和[29468, 4]。因为是最后一层vfe,不需要map to point features了。终于,这两个就是最终的输出! -
SparseEncoder的forward。这一步也就是3d backbone/convolution,调用了spconv库进行三维的稀疏卷积,不过在mmdet3d中其名字定义为了SparseEncoder。根据voxel size和point cloud range可以知道voxel map的尺寸应该会为[40, 1600, 1408],实际上SparseEncoder这里初始化的时候传入的为sparse_shape [41, 1600, 1408]。依然,构造sparse tensor玩传播,完事后用.dense()返回成正常的input_sp_tensor = SparseConvTensor(voxel_features, coors, self.sparse_shape, batch_size) ... spatial_features = out.dense()卷积完,输出为[2, 128, 2, 200, 176],然后height compression(openpcdet中的叫法,其实就是把高度和channels维度给view到了一个维度,全都保存了)得到[2, 256, 200, 176],也就是本步的输出
目前这一步并没有深入调试,毕竟是调用spconv库,感觉原理是更重要的,后面总结。 -
SECOND的forward。根据指定的layer nums的长度我们知道有两个尺度的feature map,所以这一步得到两个输出:[2, 128, 200, 176]和[2, 256, 100, 88] -
SECONDFPN的forward。config中本来就是配合上面SECOND的参数,现在得到一个[2, 512, 200, 176]的输出,显然,和想的一样是两个[2, 256, 200, 176]的cat
点云特征图通过head得到输出:AnchorHead3D
由于之前在openpcdet中也算详细调试了普通anchor head的过程,在这里不再耗费时间一点点调试,仅希望通过mmdet3d的api官方描述了解如何编写这里AnchorHead3D的config
- AnchorHead3D的forward:仍然记得,head的主要工作都在初始化的时候的生成anchors以及forward之后算loss的时候的target assignment了,forward这里其实没什么。输出为:cls_score [2, 18, 200, 176],bbox_pred [2, 42, 200, 176],dir_cls_preds [2, 12, 200, 176],也是可以回忆起来的,18是每个grid位置的共3个类的各2个anchor共6个anchor的对于classification的3维one-hot输出,42是这6个anchor的各7-d vector输出,12是6个anchor各两个分类角度所在区间的one-hot

 浙公网安备 33010602011771号
浙公网安备 33010602011771号