『笔记』PyTorch中transformer相关类的使用
PyTorch中transformer相关类的使用
目的是大概了解一下pytorch中用transformer是什么样的逻辑。
Attention
-
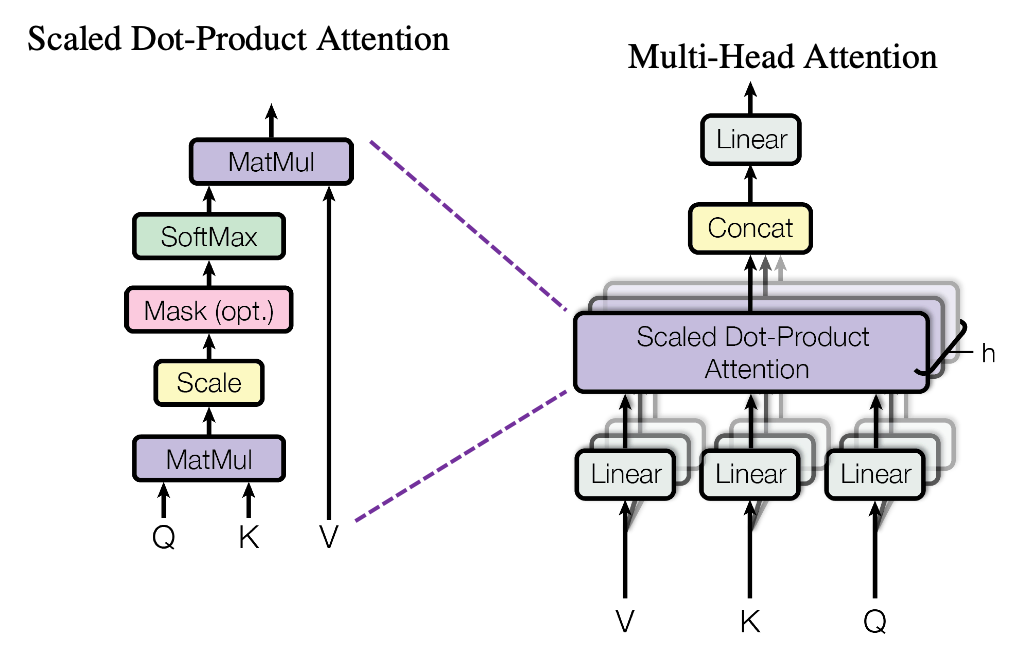
multi_head_attention_forward函数:通过一步一步看源码的调用发现其实最基本的进行attention的操作其实在这里,不过并没有在官网doc中有很好的页面,尽管代码中的注释是很完备的。其中主要调用了in_projection和_scaled_dot_product_attention这样的两个函数,当然,也包括很多额外操作的管理
-
MultiheadAttention类:包装好各种设置的变量,在执行时主要就是调用上面的函数。初始化为(embed_dim, num_heads),即k和h,forward时传入qkv
Q:在初始化时可以指定kdim和vdim,它们将在初始化做in-projection的weights的时候起作用,Parameter(torch.empty((embed_dim, kdim),但kdim难道可以和q的不同吗。通过查看multi_head_attention_forward内部发现在执行_scaled_dot_product_attention的时候已经想通了,但是没发现in-projection到这一步中间是发生了什么变回去的
Encoder和decoder
-
TransformerEncoderLayer类:基础的transformer (encoder) block(self-attention + FFN),初始化为(d_model, nhead, dim_feedforward=2048),即k,h,和FFN中hidden的中间的那个维度数量(毕竟最后是要回到k的)。
输入encoder的sequence称为src

-
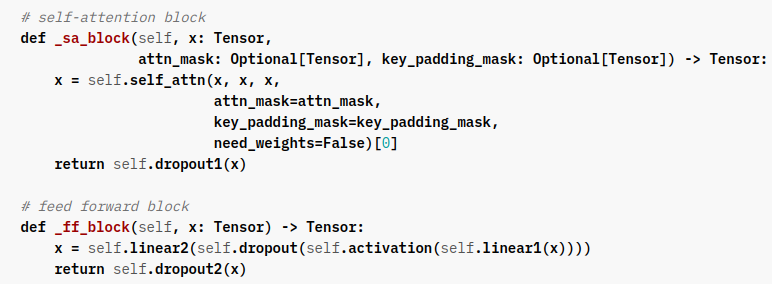
TransformerDecoderLayer:基础的transformer decoder block(self-attn + self-attn + FFN),初始化参数和encoderlayer完全一样。
其中第一个self-attn的输入就是decoder这一边的输入,qkv和encoder一样是(x, x, x),第二个的输入是刚刚前面第一个的输出作为q,侧面来的外部的sequence作为k和v,即(x, memory, memory)
输入decoder的称为tgt(毕竟它决定了最终output的形状),侧面来的sequence称为memory

显然_sa_block和_ff_block同encoder中的,多出来的第二个attention为:
-
TransformerEncoder类:多组TransformerEncoderLayer类实例。初始化就是you are expected to传入一个已经建好的实例,并指定block个数,类内会对传入的做clone. 于是参数为(encoder_layer, num_layers)
-
TransformerDecoder类:同上,多组TransformerDecoderLayer类实例。
值得注意的是,依然是decoder的forward逻辑,这个侧面来的memory会作为每个decoder block的forward的输入,一次又一次。
Transformer
-
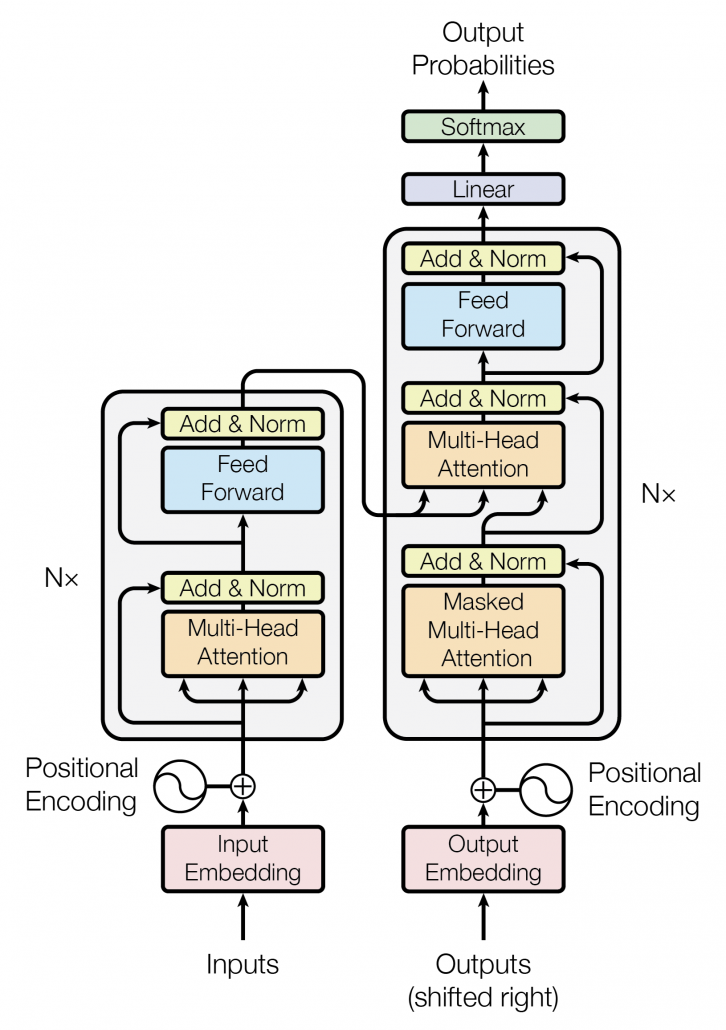
Transformer类:拼接TransformerEncoder和TransformerDecoder的最终完全体,encoder的输出即作为decoder的侧面外部sequence输入(即memory)

主要的初始化为(d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048),其他参数有

另外,之前在encoder和decoder的layer中跳过介绍了:其实self-attention的类forward其实除了传qkv,还可以optionally传attention mask,表示哪些位置不会参与attention. 这个地方后面根据具体例子写一下。总得来说,forward的参数总共有:

它们的形状为:

不难发现,transformer类在初始化时只需要保证后面的输入的特征维度是一致的,也就是这里的512,其他都是design choice,包括sequence的长度。这里甚至所有的参数都有默认值。而output的形状将随decoder自己的输入tgt保持一致
另外值得注意的是,pytorch使用时其batch size的位置默认是在sequence长度后的,也就是(t, b, k)而不是自己之前熟悉的(b, t, k)。使用example:
transformer_model = nn.Transformer(nhead=16, num_encoder_layers=12) src = torch.rand((10, 32, 512)) tgt = torch.rand((20, 32, 512)) out = transformer_model(src, tgt)
其它
https://jalammar.github.io/images/t/transformer_decoding_2.gif

 浙公网安备 33010602011771号
浙公网安备 33010602011771号