『论文』DETR
『论文』DETR
End-to-End Object Detection with Transformers
3.1 Object detection set prediction loss#
首先,DETR实现目标检测的思路为,我infer一大堆predictions,是一个固定的数量N个,同时ground truth也以定义no object扩充为N个。这样我们有两个大小都为N的set:1. prediction set 2. ground-truth set. 要学习的目标就是让我们的prediction set越来越像gt set. 而不同于我们以往目标检测常用的object之间的关系(e.g., anchor到其positive gt),现在这个“set-to-set”的过程,就在object-to-object上多了一层先把这两个set进行最优匹配(计算一下最优的object-to-object们)的步骤。于是总得来说,loss就是,在两个相等大小集合二分图的最优匹配下的,匹配的object之间loss的和
DETR infers a fixed-size set of N predictions, in a single pass through the decoder, where N is set to be significantly larger than the typical number of objects in an image
Our loss produces an optimal bipartite matching between predicted and ground truth objects, and then optimize object-specific (bounding box) losses.
第一步:计算当前prediction set和ground truth set的最优匹配:matching cost + Hungarian algorithm#
也就是说在当前输出来的这一堆prediction情况下,尽量帮助它往ground truth set去靠,得到这set这一堆最好也就是这样的预测情况,认为后面loss最低也就是这样了
Optimal assignment问题定义为:

其中i是gt的id,
(符号理解:
其中用来衡量匹配边的cost,也就是matching cost定义为:

也就是如果该gt是no object,matching loss为0,如果该gt确实是个object,纳入当前prediction对gt的class的probability,纳入box差距,即组成matching cost
最优匹配问题已经定义好,使用Hungarian algorithm对其求解即可。
总得来说,匈牙利算法的思想大概总结为:每个点从另一个集合里挑对象,没冲突的话就先安排上,要是冲突了仍然是优先满足当前结点需求的那个点,构建增广路径(头尾均为非匹配边的,非匹配边和匹配边不断交替的路径),取反,得到重新匹配的结果。如此,由于增广路径的非匹配边永远比匹配边多1,通过找到这样的路径并取反,路径里的匹配数就比原来多1个。重复上述思路,直到所有的点都找到对象,或者找不到对象也找不到增广路。
相关链接:
- https://zhuanlan.zhihu.com/p/208596378
- https://liam.page/2016/04/03/Hungarian-algorithm-in-the-maximum-matching-problem-of-bigraph/
第二步:在已经完成的最优匹配们上计算set prediction loss#
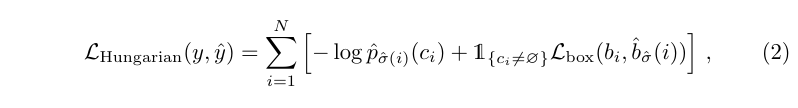
这一步也就依然很像我们以往计算loss的形式了,用negative log probability算classification,以及计算box regression loss
实际情况下,no object时的classification loss会被down-weight by a factor 10
另外,两步都用到的box loss定义为:
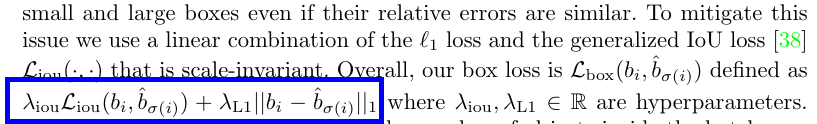
Unlike many detectors that do box predictions as a ∆ w.r.t. some initial guesses, we make box predictions directly. 这样常用的l1就会有scaling的issue,于是用了l1和G-IoU loss (scale-invariant)的linear combination
于是,DETR通过以上的范式来定义了怎么去求一个目标检测问题
3.2 DETR architecture#
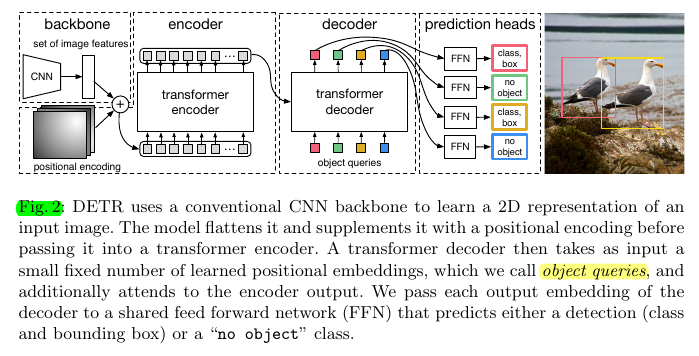
- Backbone: (3, H0, W0) -> (C, H, W), C=2048, H,W = H0/32, W0/32
- Transformer encoder: (C, H, W) -> conv1x1 -> (d, H, W) -> collapse -> (d, H*W) -> transformer encoder (multi-head self-attention + FFN)
- Position embedding: fixed positional encodings added to the input of each attention layer
- Transformer decoder: decodes the N objects in parallel at each decoder layer.
- Input embeddings: learnt positional encodings that we refer to as object queries
- FFNs: The FFN predicts the normalized center coordinates, height and width of the box w.r.t. the input image, and the linear layer predicts the class label using a softmax function
- Auxiliary decoding losses: add prediction FFNs and Hungarian loss after each decoder layer. All predictions FFNs share their parameters. We use an additional shared layer-norm to normalize the input to the prediction FFNs from different decoder layers.
关于Input embeddings#
关于input positional embeddings主要有两种形式:1. fixed embedding: 使用不同频率的sin和cos分别对每个位置H, W生成d/2 dim的encoding,最后再cat,以及2. learned embeddings

对于learned embeddings的一个例子也就是在看Transfusion的时候看到的,很明显,输入为(bs, pos, seq),通过conv1d + kernel size 1这样的操作将每个位置进行fc得到即将同后面features一样特征维度的position embedding
self.position_embedding_head = nn.Sequential(
nn.Conv1d(input_channel, num_pos_feats, kernel_size=1), #2, 128
nn.BatchNorm1d(num_pos_feats),
nn.ReLU(inplace=True),
nn.Conv1d(num_pos_feats, num_pos_feats, kernel_size=1)) #128, 128
关于DETR中的object queries:具体来说是什么#
文章最后附录给了一段代码,其中中self.query_pos的初始化为nn.Parameter(torch.rand(100, hidden_dim)),可以了解到object queries就是随机初始化,并在Training过程中学到的embedding
关于NMS-free以及后处理#

在官方repo中有两个issues作者的相关回复:
DETR doesn't need NMS by definition, as we explain in the paper. Our current postprocessor basically just perform softmax and box conversion (so that it is in [x0,y0,x1,y1] format in absolute coordinates).
Q: So all you have to do is, out of the 100 detections, remove the ones with the 'nothing' class?
You have two choices: 1. use our postprocessor, which always returns a valid object class for all the 100 proposals, even if "no-object" is the class with highest score (note the :-1 in prob[..., :-1].max(-1) . This improves recall on COCO detection, as it will also have classes with low probabilities. This implies that you need to set a threshold for visualizations. 2. you can take the "no-object" while computing the max scores, and discard those with "no-object" classes. There is no hyperparameters to set in this case, and everything is handled by the transformer, but this might be suboptimal if you want to have highest mAP, as we will be dropping potential detections (imagine no-obj has a probability of 0.51 and "dog" 0.49, this case we would miss the "dog").
来自 https://www.zhihu.com/question/455837660/answer/2263340890 :
"我的理解是,因为Detr学会了将bbox去和GD或no_object去一一匹配。也就是说一个GD A只会对应到一个bbox A,如果另一个bbox B和bbox A和靠近,计算损失时,bbox B也不会和GD A进行匹配,而会和其它GD或no_object进行匹配,会导致loss很大,那么随着训练的进行,这个bbox B会慢慢地远离bbox A。总之,DETR会学会在一个GD附近只对应生成一个bbox。"
其它#
- https://zhuanlan.zhihu.com/p/267156624
- https://www.zhihu.com/question/397692959/answer/1258046044
- https://www.zhihu.com/question/455837660
另外,文章附录中事无巨细地给出了原transformer的介绍和包括G-IoU在内的loss的介绍,可以作为基础知识看。并有一张更为详细的图在这里:
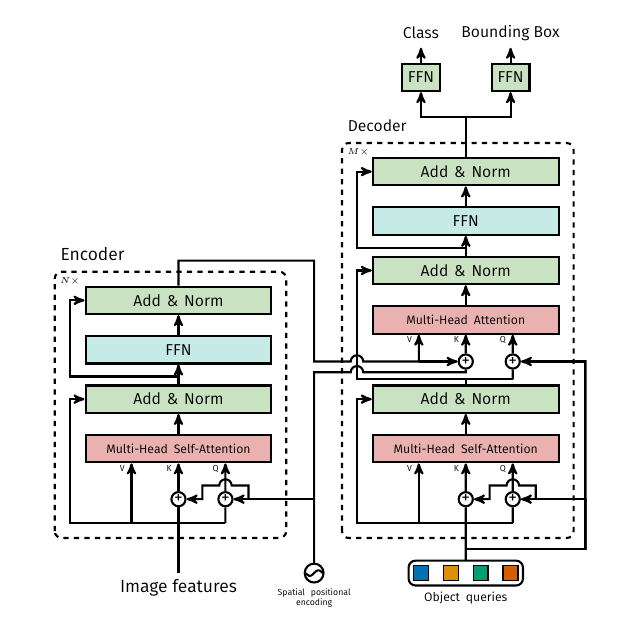
作者:traviscui
出处:https://www.cnblogs.com/traviscui/p/16412832.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话