正则表达式匹配可以更快更简单 (but is slow in Java, Perl, PHP, Python, Ruby, ...)
source: https://swtch.com/~rsc/regexp/regexp1.html
translated by trav, travmymail@gmail.com
引言
下图是两种正则匹配算法的对比图,其中左边的是许多语言都作为标准使用的算法,而右边的算法则鲜为人知,它是多个版本的awk和grep程序所使用的算法。这两种算法有着惊人的不同表现:

注意到Perl需要大约60秒的时间来匹配长度为29的字符串,而Thompson NFA算法只需要20微秒,两者相差了上百万倍。不仅如此,两者的差距还在继续增长,Thompson NFA算法处理长度为100的字符串只需要不到200微秒,而Perl则需要超过10^15年。(Perl语言只是诸多语言的一个典例,其他包括Python、PHP或Ruby等更多语言的表现都是如此)
这可能非常令人难以置信,也许你在使用Perl的时候并没有发现它表现得如此糟糕。实际上,Perl在大多数情况下已经足够快了,但是当我们拿出丧心病狂的正则表达式来测试Perl的时候,它可以变得异常的慢。相比之下,Thompson NFA算法并感觉不到任何不适。看到这样的对比,你很可能会产生疑问:“为什么Perl不使用Thompson NFA算法呢?”其实Perl可以这样做,也应该这样做,这就是本篇文章要探讨的。
在历史上,正则表达式是一个展示“好的理论产生好的程序”的好例子。计算机理论学家们原本只是将正则表达式作为验证理论的计算模型,但是Ken Thompson在他为CTSS编写的QED文本编辑器里实现了正则表达式,并且把它带入了程序员的世界。Dennis Ritchie同样也在他为GE-TSS编写的QED里实现了正则表达式。Thompson和Ritchie在他们合作制造的Unix里也不忘携带着正则表达式。正则表达式作为Unix系统的关键成员,存在于ed, sed, grep, egrep, awk和lex这些著名的工具中。
在今天,正则表达式同样也是一个展示“忽视理论能做出多差的程序”的典例。今天大多数实现正则表达式的算法比起许多已存在30多年的Unix工具不知道要慢几个数量级。
本文回顾了一些很好的理论:正则表达式、有限自动机以及Thompson于19世纪60年代中期提出的正则表达式搜索算法,并且理论联系实际,描述了一个少于400行的C语言的Thompson算法的实现,这个版本就是上图与Perl进行比较的版本。本文最后讨论了如何在现实世界中将理论转化为实践。
正则表达式
正则表达式描述了一组符合某种特定形式的字符串,当一个字符串满足这种特定形式,我们就称其匹配:
- 最简单的正则表达式是单个字符,字符可以自我匹配,其中有六个操作符
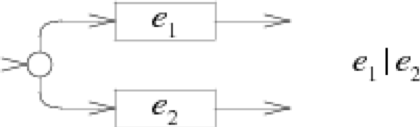
*+?()|需要添加反斜杠\进行转义才能匹配。 - 两个正则表达式可以合并或连接来组成一个新的正则表达式:若e1匹配s,e2匹配t,则e1|e2匹配s或t,则e1e2匹配st。
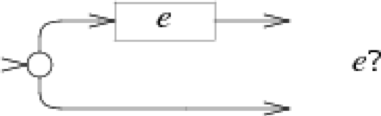
* + ?是重复操作符:e1*匹配0个或多个e1,e1+匹配1个或多个e1,e1?匹配0个或1个e1。- 操作符的优先级为
* > + > ? > 连接 > 合并,其中括号的优先级最高,例如ab|cd等价于(ab)|(cd),ab*等价于a(b*)。
以上描述的规则是传统的Unix egrep正则表达式规则的最小子集,这个子集已经能够描述所有的正则表达式,当然现在出现了许多新的操作符,这些新的操作符同样能被上述子集描述。本文内容只涉及上述操作符。
有限自动机
另一种描述字符串特征的方式就是有限自动机,有限自动机有时又被称为状态机。以下是描述a(bb)+a的有限自动机:

有限自动机由两部分组成,一部分是图中由圆圈表示的状态,另一个部分是连接状态的箭头与箭头上的字符。当有限自动机读入一串字符串时,它会从一个状态转入另一个状态。这种状态机有两种特殊的状态:开始状态s0和终止状态s4。终止状态由双圆圈表示,开始状态由箭头头部指出。
状态机每次从字符串输入流中读取一个字符,并根据箭头方向从一个状态转移到另一个状态。假设读入字符串abbbba,那么状态转移的过程如下:
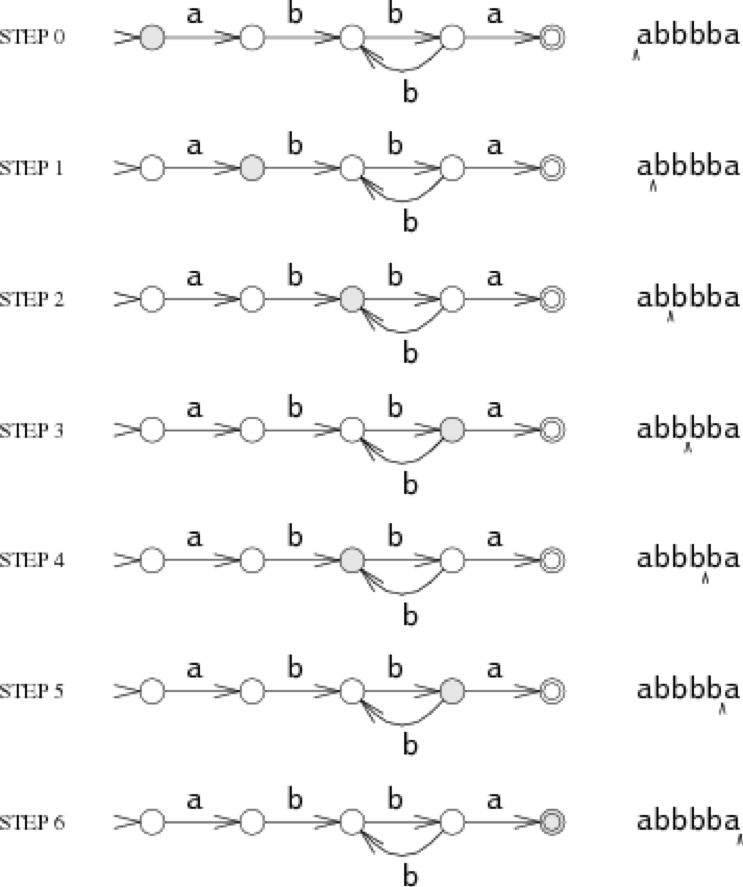
状态机的结束状态为s4,是终结状态,因此这个字符串被匹配了。如果状态机最终结束的状态不是终结状态,那么就不匹配。如果在字符串匹配过程中,出现了意外的字符导致状态不能继续转移,那么也是不匹配,此时状态机会提早结束了事。
我们上述讨论的是确定的有限自动机(DFA),其特征就是对于某个特定的输入,只有至多一个确定的转移状态。我们也可以制作出不确定的有限自动机(NFA),其特征是对某个特定的输入,其转移状态可能有多个。下图给出一个与之前DFA等价的NFA:

在状态s2时,读入一个字符b,其转移状态可能为s1,也可能为s3,所以这就是不确定自动机。因为自动机无法预测未来,因此它不知道转移到哪种状态才有最正确的选择。在这种情况下,一个有趣的事情就是如何让自动机总是做出正确的选择,或者说是每次都猜对答案。总之,这样的自动机就被称为不确定的有限自动机。
有时候,在NFA中设置无字符的箭头是一件好事。在一个NFA中,一个状态在任何时候都可以顺着无字符的箭头转移到另一个状态。例如下图等价的NFA:

状态s3指向s1的无符号箭头能够更清晰更简单的描述a(bb)+a
正则表达式转为NFA
正则表达式与NFA是完全等价的,一个正则表达式一定有对应的NFA,反之亦然。历史上有非常多种将正则表达式转化为NFA的方法,我们这里描述的方法是由Thompson在1968年的CACM论文中提出的。
一个最终的NFA是由多个部分的局部NFA组合而成的,局部的NFA没有状态转移,而是由一个或多个空箭头表示。最终我们会把这些局部的NFA通过他们的空箭头连接起来。
- 单字符正则表达式对应的NFA:

- 表示连接关系的NFA:
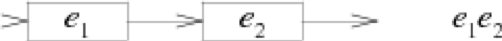
- 表示合并关系的NFA:
e?对应的NFA:
e*对应的NFA:
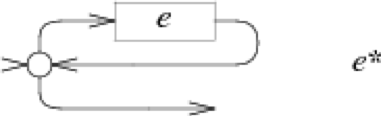
e+对应的NFA:
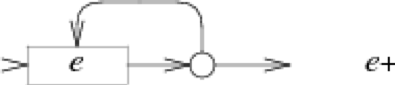
细数上面的对应关系可以发现,我们需要为每个操作符都新建一个NFA,其中不包括括号操作符,因此一个完整的NFA包含的状态数至多与原正则表达式的长度相等。
你可以在这些局部的NFA中发现许多无符号的箭头,正如我们上一节末尾所说的,为NFA设置一些无符号的箭头是合理的(我们的算法就是这样干的),同时这些无符号的箭头会帮助我们阅读和理解,并且让我们的C语言代码更简洁。
正则表达式搜索算法
现在我们有了匹配正则表达式的方法:首先将正则表达式转化为NFA,然后将待匹配字符串作为输入,运行NFA,查看结果。在面对多种状态转移的选择时,我们需要NFA有做出正确选择的能力,因此我们必须寻找一种可靠的方式来模拟NFA的猜测过程。
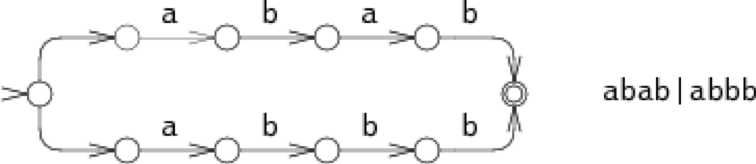
一种方式就是:尝试其中一个选项,如果这条路走不通,那就选择另一条路。例如,考虑abab|abbb的NFA在匹配字符串abbb的过程:
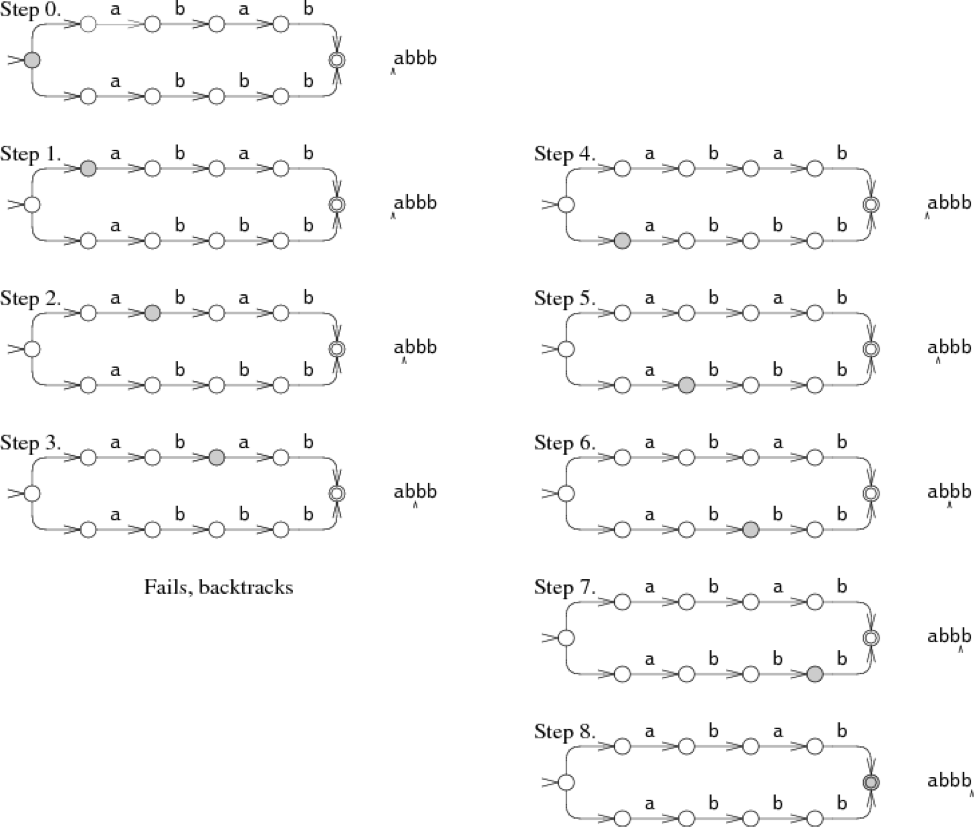
在step 0中,我们必须选择往上走还是往下走,往上走匹配abab,往下走匹配abbb。在图中,NFA尝试往上走,结果在step 3失败了,于是便回溯到了step 0,尝试往下走,从step 4到step 8完成了匹配。这种回溯的方式可以通过简单的递归实现。但是,我们容易发现,当一个不匹配的字符串输入时,自动机将会尝试所有的可能。在这个例子中,NFA仅仅尝试了两条路,但是在更糟糕的情况中,自动机将会做出大量的尝试,这就导致了自动机变得异常缓慢。
另一个更高效但更复杂的方式就是同步地进行尝试。这种方式允许自动机一次可以进入多种状态,当读入一个字符时,自动机会同时转移到所有可能的状态。
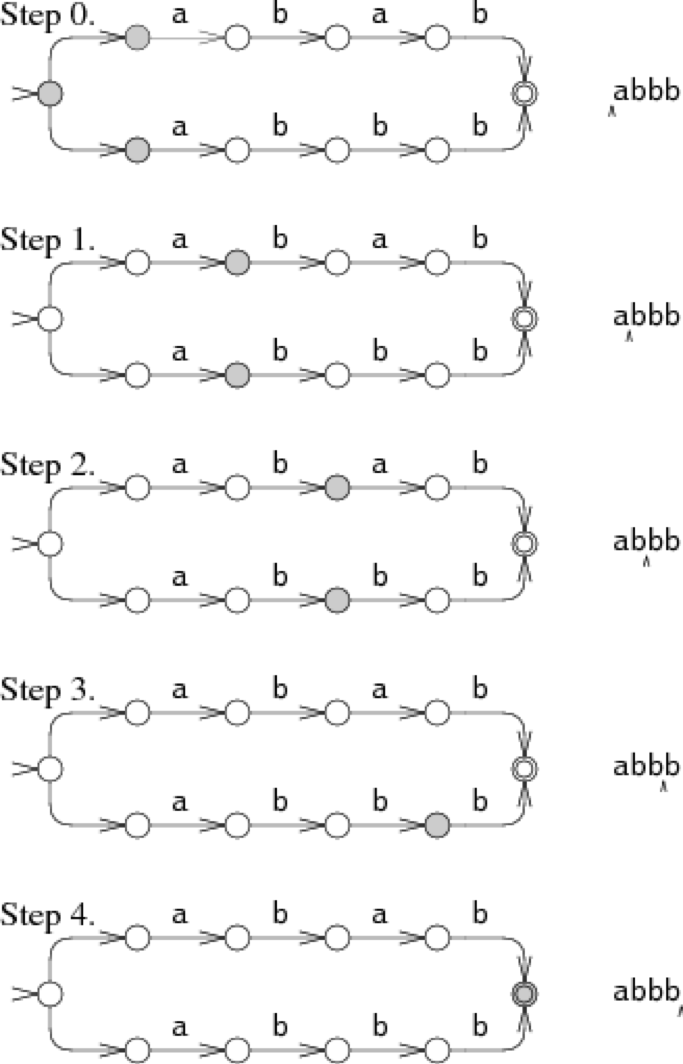
如图所示,在匹配字符串的过程中,自动机会同时尝试两条路径,在step 3时,仅剩下一条亦然匹配成功的路径。这种多状态并存的方式可以在同一时间尝试两种可能,也仅仅读取输入的字符串一次。即使在最坏的情况下,NFA也许会同时尝试所有状态,但是这也仅仅花费O(1)的时间,因此任意长的字符串也能在O(N)的时间内解决。这种方式把回溯花费的指数时间降为线性时间,是一种巨大的提升。效率的提升在于,这种方式尝试的是所有可能的状态,而不是所有可能的路径。在一个有N个结点的自动机里,每一步最多有N个转移状态,但是却有2^n条路。
实现
Thompson在1968年的论文里介绍了这种多状态并存的方式,在他的实现方案中,NFA的状态被表示为一组机器码序列,下一步可能的转移状态被表示为一组函数调用。实质上,Thompson是将正则表达式编写为一组聪明的机器码。四十年之后,计算机已经变得非常快了,他那种机器码的方式已经不在需要了。在接下来的章节中,我们会看到一个不到400行的C语言版本的代码。source code
实现NFA
第一步就是将正则表达式转化为等价NFA。在代码中,状态的数据结构如下:
struct State
{
int c;
State *out;
State *out1;
int lastlist;
};
状态有三种表示,具体依赖与c的值:
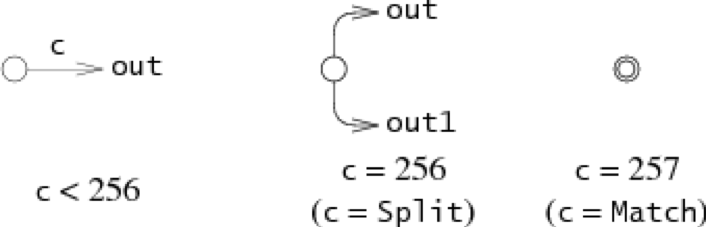
(lastlist字段在运行时使用,我们会在下一节介绍)
依照Thompson的论文,接下去需要将中缀的正则表达式转化为后缀的正则表达式,再从后缀的正则表达式转化为NFA。在其后缀表达式中,新增加一个操作符dot(.),用来表示连接。函数re2post将一个中缀表达式a(bb)+a转化为等价的后缀表达式abb.+.a.。(在这里,需要区分现实中正则表达式的操作符dot(.)。在现实中,我们会使用dot(.)来表示某个字符,但是在这里我们用来表示连接。在实际工作中,我们也许直接使用中缀表达式来转为NFA,但是,这种后缀表达式的版本也十分便捷,并且也是最符合Thompson的论文的。)
当程序扫描后缀表达式时,它会维护一个栈,栈中会存储NFA片段。普通的字符会产生一个新的NFA片段,然后入栈。遇到操作符则会将栈中的片段pop出,然后组合成一个新的片段再入栈。例如,在处理abb之后,栈中的内容是a,b,b的片段,遇到了dot(.)之后,就会弹出两个b片段,然后组合成一个bb片段重新压入栈中。NFA片段的结构如下:
struct Frag
{
State *start;
Ptrlist *out;
};
其中start指针指向片段的开始状态,out指针指向一个指针链表,指针链表中指针分别指向其他的State*指针。当然指针链表中的指针现在还没有指向具体的内容,我们称其为悬挂的指针,这些指针形象地表示了NFA片段中的空箭头。
一些辅助函数如下:
Ptrlist *list1(State **outp);
Ptrlist *append(Ptrlist *l1, Ptrlist *l2);
void patch(Ptrlist *l, State *s);
list1函数创建一个新只包含outp指针的指针链表。append函数将两个链表连接起来。patch函数为上面提到的悬挂的指针赋值,让l中悬挂的指针指向状态s:它会设置l链表中所有的指针指向s。
有了这些工具,我们的程序只是通过一个简单的循环体来依次处理每个后缀表达式中的字符。最终,栈里只剩下最后一个片段,将这个片段与matchstate进行patch,说明最终的状态为终结状态,即完成了转化。
State*
post2nfa(char *postfix)
{
char *p;
Frag stack[1000], *stackp, e1, e2, e;
State *s;
#define push(s) *stackp++ = s
#define pop() *--stackp
stackp = stack;
for(p=postfix; *p; p++){
switch(*p){
/* compilation cases, described below */
}
}
e = pop();
patch(e.out, &matchstate);
return e.start;
}
一些片段情况如下:
- 单个字符:
default:
s = state(*p, NULL, NULL);
push(frag(s, list1(&s->out));
break;
- 连接:
case '.':
e2 = pop();
e1 = pop();
patch(e1.out, e2.start);
push(frag(e1.start, e2.out));
break;

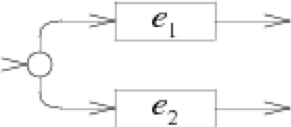
- 合并:
case '|':
e2 = pop();
e1 = pop();
s = state(Split, e1.start, e2.start);
push(frag(s, append(e1.out, e2.out)));
break;
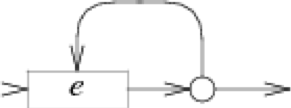
?:
case '?':
e = pop();
s = state(Split, e.start, NULL);
push(frag(s, append(e.out, list1(&s->out1))));
break;
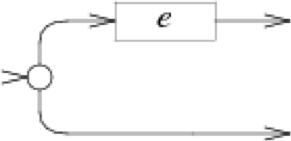
*:
case '*':
e = pop();
s = state(Split, e.start, NULL);
patch(e.out, s);
push(frag(s, list1(&s->out1)));
break;
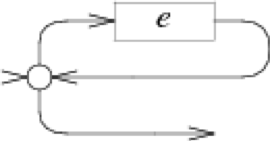
+:
case '+':
e = pop();
s = state(Split, e.start, NULL);
patch(e.out, s);
push(frag(e.start, list1(&s->out1)));
break;
模拟NFA
现在已经有NFA了,接下去我们需要模拟运行它,模拟的过程需要遍历状态集合,也就是状态链表:
struct List
{
State **s;
int n;
};
模拟过程需要两个链表:clist是当前的状态集合,nlist是下一步可能转移的状态集合。循环体首先将clist初始化为只包含开始状态,然后每次循环向前走一步。(C语言没有集合的概念,因此只能使用链表来表示集合)
int
match(State *start, char *s)
{
List *clist, *nlist, *t;
/* l1 and l2 are preallocated globals */
clist = startlist(start, &l1);
nlist = &l2;
for(; *s; s++){
step(clist, *s, nlist);
t = clist; clist = nlist; nlist = t; /* swap clist, nlist */
}
return ismatch(clist);
}
为了避免每次循环都要重新分配一个链表,match函数在每次循环结束前会交换clist和nlist,并在下一次执行前将nlist初始化。
最后,如果clist中包含终结状态,则说明输入字符串匹配。
int
ismatch(List *l)
{
int i;
for(i=0; i<l->n; i++)
if(l->s[i] == matchstate)
return 1;
return 0;
}
addstate函数将一个状态加入到链表中,如果这个状态已经存在于链表中,那么不做任何操作。从头到尾扫描一遍链表是很低效的,取而代之,我们使用一个变量listid表示链表的迭代数。当addstate函数将状态s添加到链表中,它同时将s->lastlist赋值为listid。如果s->lastlist和listid之前已经相同,那么说明状态s早就已经被添加入当前链表中。如果s是一个split状态(|?*+操作符都会产生一个split状态,参见上一节),那么addstate会同时将s指向的两个状态加入到当前链表中,而不加入s状态(可以将split状态理解为一个空的状态)。
void
addstate(List *l, State *s)
{
if(s == NULL || s->lastlist == listid)
return;
s->lastlist = listid;
if(s->c == Split){
/* follow unlabeled arrows */
addstate(l, s->out);
addstate(l, s->out1);
return;
}
l->s[l->n++] = s;
}
startlist函数创建一个初始化状态链表,其中只包含开始状态:
List*
startlist(State *s, List *l)
{
listid++;
l->n = 0;
addstate(l, s);
return l;
}
最后,step函数在接受一个字符后递进,并使用clist来计算nlist:
void
step(List *clist, int c, List *nlist)
{
int i;
State *s;
listid++;
nlist->n = 0;
for(i=0; i<clist->n; i++){
s = clist->s[i];
if(s->c == c)
addstate(nlist, s->out);
}
}
性能表现
尽管我们在编写C语言版本的过程中,并没有考虑任何的性能优化,但是即便如此,我们的算法性能也依旧比那些流行的指数级算法要快得多。通过测试一些主流的语言可以更好的证明这一点。
考虑我们在开篇提出的正则表达式a?nan,对于一个使用回溯进行匹配的算法来说,在处理?操作符时有两种选择,对于a?n则一共有2n种可能,时间复杂度为O(2n)。
相比之下,Thompson算法中的状态链表长度至多为n,若输入字符串的长度为m,则时间复杂度为O(mn)。(这个时间复杂度十分接近线性复杂度,因为如果我们把正则表达式的n保持为一个常数,比如25,则对于任意长度为m的字符串,其匹配时间为O(25m))
下图为不同算法的匹配时间对比:(注意到y轴的间隔不是等距离间隔,而是对数间隔,用对数划分能够更好地比较他们的区别)
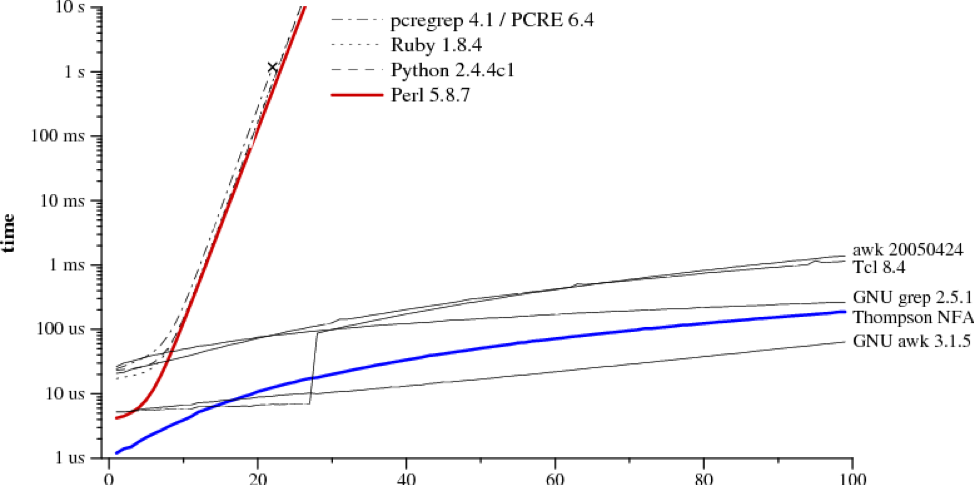
从图中我们可以看出,Perl, PCRE, Python和Ruby全都使用递归回溯算法。尽管这里没有评估Java,但是Java使用的也是递归回溯算法,而PHP使用的也是PCRE库。
优化:NFA转为DFA
DFA的效率比NFA更高,因为DFA中,在任意时刻你只能处于一个状态,只有一种选择,绝不可能有第二种选择。任何一个NFA都可以转化为与之相对应的DFA,每个DFA中的状态是原来NFA的一组状态集合。
例如,如下是abab|abbb的NFA:
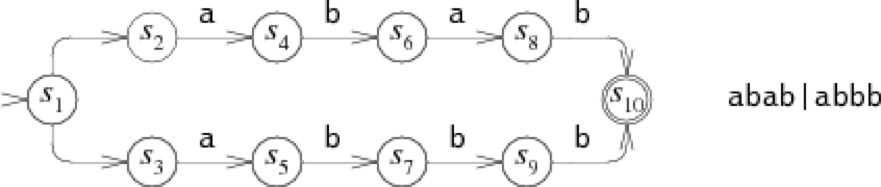
其等价DFA:
可以看到,DFA的状态都是NFA中状态的集合。
读者可以想象,其实Thompson NFA算法就是在处理其等价的DFA,不是吗?我们知道在匹配算法中,会维护一个clist和nlist,无论是clist还是nlist,不都是一组状态的集合吗?因此,Thompson算法实际上是在运行时动态构造了DFA,也就是,只在需要时构造,而不是一次性就讲NFA构造为DFA。
与其在每一步进行时动态地计算下一步该往哪走,下一步可以去往的状态是哪些,我们可以提早地将这些可能的去向、可能的状态放在缓冲区中。在这一节中,我们将展示一个不到100行的C语言算法来实现这样的操作。
source code
为了实现缓存,我们首先引入新的数据结构来表示DFA的状态:
struct DState
{
List l;
DState *next[256];
DState *left;
DState *right;
};
一个Dstate结构保存了List结构的副本(比如clist, nlist的副本),next数组保存了输入字符对应的下一个转移状态,比如d->next[c]就是在处理字符c时,d状态会转移的状态。如果d->next[c]是null,那么表示对应的转移状态还没有计算,这时我们调用Nextstate函数来计算其转移状态。
检查正则匹配的函数会重复地跟随d->next[c]的方向转移,在需要时调用nextstate函数来计算下一个状态:
int
match(DState *start, char *s)
{
int c;
DState *d, *next;
d = start;
for(; *s; s++){
c = *s & 0xFF;
if((next = d->next[c]) == NULL)
next = nextstate(d, c);
d = next;
}
return ismatch(&d->l);
}
我们使用一个二叉搜索树来保存Dstate,并将list作为节点的键值。为了实现这样一棵二叉搜索树,首先将list作为参数输入,并且对list中的状态进行排序,然后将其作为键值插入二叉树中。dstate函数会返回给定list对应的dstate。(这样做的原因在于,在一些DFA中可能会有回环,遇到回环时我们可以直接在二叉树中找到,并且直接返回)
DState*
dstate(List *l)
{
int i;
DState **dp, *d;
static DState *alldstates;
qsort(l->s, l->n, sizeof l->s[0], ptrcmp);
/* look in tree for existing DState */
dp = &alldstates;
while((d = *dp) != NULL){
i = listcmp(l, &d->l);
if(i < 0)
dp = &d->left;
else if(i > 0)
dp = &d->right;
else
return d;
}
/* allocate, initialize new DState */
d = malloc(sizeof *d + l->n*sizeof l->s[0]);
memset(d, 0, sizeof *d);
d->l.s = (State**)(d+1);
memmove(d->l.s, l->s, l->n*sizeof l->s[0]);
d->l.n = l->n;
/* insert in tree */
*dp = d;
return d;
}
nextstate函数调用NFA的step函数,并且返回对应的dstate:
DState*
nextstate(DState *d, int c)
{
step(&d->l, c, &l1);
return d->next[c] = dstate(&l1);
}
在最后,DFA的开始状态也对应与NFA的开始状态集:
DState*
startdstate(State *start)
{
return dstate(startlist(start, &l1));
}
(就像NFA中的clist和nlist一样,这里的ll也是预先分配空间的list)
我们在运行时动态地构造DFA的状态,而不是一开始就将NFA对应的整个DFA计算出来。尽管一开始就构造DFA可能会匹配得快一些,不过内存消耗以及启动时间比较高。
大家可能会担心这种动态构造DFA的算法会遇到内存瓶颈,不过我们可以在缓存空间过大时直接丢弃整棵二叉树,并重新构造一颗二叉树。这种缓存策略的实现并不困难,只需要不到50行额外的内存管理代码。source code(grep也使用了限制缓存大小的策略,其大小限制为32个state的大小,这就解释了为什么在n=28的时候,线段发生了一次跳跃,见上图)
由正则表达式转化过来的NFA会不断的计算新的状态集,由于状态集会有重复,这让缓存是值得的。遇到重复的状态时,可以直接从缓存中取出,而不用做多余的计算。真实的基于DFA的算法可以做出更多优化,让算法效率更高。我们将在下一篇文章中讨论。
现实世界中的正则表达式
在现实生产环境中,我们遇到的正则表达式会更复杂,不是我们上述提出的方案能够解决的。在这一节中,我们会讨论一些常见的复杂情况,其他更复杂的情况已超出本文范围。
字符集(character classes):一个字符集,不论是[0-9]还是\w或事dot(.),都只是更精确的表示了|操作。字符集可以被翻译为|然后再处理,但是在NFA中引入一个新的操作符会更精确更有效。POSIX将字符集定义为[[:upper:]],不过其含义取决于上下文,它困难的部分在于搞清楚它的含义,而不是将其编码为NFA。
转移字符:现实开发中,正则表达式需要使用反斜杠\来转移某些操作符。
可数次重复:很多正则表达式提供一种可数次重复的操作符{n},可以让字符串重复n次。{n,m}可以重复n到m次,{n,}可以重复n次及以上。递归回溯算法可以通过一个循环来实现这个操作符,而NFA或基于DFA的算法就需要显示地扩展表达式后,才能进行下一次处理,比如e{3}需要先扩展为eee,e{3,5}扩展为eeee?e?,e{3,}扩展为eee+。
提取子串:正则表达式可以用来划分字符串,比如使用([0-9]+-[0-9]+-[0-9]+) ([0-9]+:[0-9]+)来匹配日期时间的字符串(date time),很多正则表达式引擎可以提取匹配的子串,例如Perl:
if(/([0-9]+-[0-9]+-[0-9]+) ([0-9]+:[0-9]+)/){
print "date: $1, time: $2\n";
}
如何区分子串的边界这个问题,被大多数理论学家所忽视。区分子串边界是最适合使用递归回溯算法来解决的问题。然而,Thompson算法也能在不放弃性能的情况下解决问题。Unix regexp(3)库的第八个版本使用算法就是Thompson算法,然而知道它的人很少。
中间匹配(Unanchored matches):我们在文章中所谈的正则表达式都从最左边开始向右进行匹配,而我们有时需要在字符串中间进行匹配,这可以理解为是提取子串的特殊情况。比如我们要中间匹配e,那么就相当于匹配.*(e).*,即字符串中间只要出现e的样式,就算匹配成功。(hellovello可以匹配.*(love).*)
非贪婪匹配:传统的正则表达式匹配的都是最长字符串,采用的都是贪婪匹配的方式。Perl语言引入了新的操作符?? *? +?来进行最短字符串匹配。当用(.+?)(.+?)匹配字符串abcd时,第一个(.+?)仅匹配a,第二个匹配bcd(而传统的贪婪匹配策略第一个匹配abc,第二个匹配d)。由定义可以看出,非贪婪匹配并不影响整个字符串的匹配,而是影响匹配的过程。回溯算法可以先匹配短的,再匹配长的,来实现最短匹配。而使用Thompson算法也可以解决这个问题。
总结
正则表达式表达式本可以更简单,更快的完成匹配,而基于有限自动机的算法就能够胜任这项工作,这项技术已然存在几十年,然而即使到了现在,诸如Perl, PCRE, Python, Ruby, Java等编程语言仍然使用的是基于递归的回溯算法,这种算法尽管便于理解、容易编写,但是运行速度异常缓慢。除了backreferences这样的操作符,其他可以使用回溯算法解决的问题,都可以使用基于有限自动机的算法解决。
History and References
Michael Rabin and Dana Scott introduced non-deterministic finite automata and the concept of non-determinism in 1959 [7], showing that NFAs can be simulated by (potentially much larger) DFAs in which each DFA state corresponds to a set of NFA states. (They won the Turing Award in 1976 for the introduction of the concept of non-determinism in that paper.)
R. McNaughton and H. Yamada [4] and Ken Thompson [9] are commonly credited with giving the first constructions to convert regular expressions into NFAs, even though neither paper mentions the then-nascent concept of an NFA. McNaughton and Yamada's construction creates a DFA, and Thompson's construction creates IBM 7094 machine code, but reading between the lines one can see latent NFA constructions underlying both. Regular expression to NFA constructions differ only in how they encode the choices that the NFA must make. The approach used above, mimicking Thompson, encodes the choices with explicit choice nodes (the Split nodes above) and unlabeled arrows. An alternative approach, the one most commonly credited to McNaughton and Yamada, is to avoid unlabeled arrows, instead allowing NFA states to have multiple outgoing arrows with the same label. McIlroy [3] gives a particularly elegant implementation of this approach in Haskell.
Thompson's regular expression implementation was for his QED editor running on the CTSS [10] operating system on the IBM 7094. A copy of the editor can be found in archived CTSS sources [5]. L. Peter Deutsch and Butler Lampson [1] developed the first QED, but Thompson's reimplementation was the first to use regular expressions. Dennis Ritchie, author of yet another QED implementation, has documented the early history of the QED editor [8] (Thompson, Ritchie, and Lampson later won Turing awards for work unrelated to QED or finite automata.)
Thompson's paper marked the beginning of a long line of regular expression implementations. Thompson chose not to use his algorithm when implementing the text editor ed, which appeared in First Edition Unix (1971), or in its descendant grep, which first appeared in the Fourth Edition (1973). Instead, these venerable Unix tools used recursive backtracking! Backtracking was justifiable because the regular expression syntax was quite limited: it omitted grouping parentheses and the |, ?, and + operators. Al Aho's egrep, which first appeared in the Seventh Edition (1979), was the first Unix tool to provide the full regular expression syntax, using a precomputed DFA. By the Eighth Edition (1985), egrep computed the DFA on the fly, like the implementation given above.
While writing the text editor sam [6] in the early 1980s, Rob Pike wrote a new regular expression implementation, which Dave Presotto extracted into a library that appeared in the Eighth Edition. Pike's implementation incorporated submatch tracking into an efficient NFA simulation but, like the rest of the Eighth Edition source, was not widely distributed. Pike himself did not realize that his technique was anything new. Henry Spencer reimplemented the Eighth Edition library interface from scratch, but using backtracking, and released his implementation into the public domain. It became very widely used, eventually serving as the basis for the slow regular expression implementations mentioned earlier: Perl, PCRE, Python, and so on. (In his defense, Spencer knew the routines could be slow, and he didn't know that a more efficient algorithm existed. He even warned in the documentation, “Many users have found the speed perfectly adequate, although replacing the insides of egrep with this code would be a mistake.”) Pike's regular expression implementation, extended to support Unicode, was made freely available with sam in late 1992, but the particularly efficient regular expression search algorithm went unnoticed. The code is now available in many forms: as part of sam, as Plan 9's regular expression library, or packaged separately for Unix. Ville Laurikari independently discovered Pike's algorithm in 1999, developing a theoretical foundation as well [2].
Finally, any discussion of regular expressions would be incomplete without mentioning Jeffrey Friedl's book Mastering Regular Expressions, perhaps the most popular reference among today's programmers. Friedl's book teaches programmers how best to use today's regular expression implementations, but not how best to implement them. What little text it devotes to implementation issues perpetuates the widespread belief that recursive backtracking is the only way to simulate an NFA. Friedl makes it clear that he neither understands nor respects the underlying theory.
Acknowledgements
Lee Feigenbaum, James Grimmelmann, Alex Healy, William Josephson, and Arnold Robbins read drafts of this article and made many helpful suggestions. Rob Pike clarified some of the history surrounding his regular expression implementation. Thanks to all.
References
[1] L. Peter Deutsch and Butler Lampson, “An online editor,” Communications of the ACM 10(12) (December 1967), pp. 793–799. http://doi.acm.org/10.1145/363848.363863
[2] Ville Laurikari, “NFAs with Tagged Transitions, their Conversion to Deterministic Automata and Application to Regular Expressions,” in Proceedings of the Symposium on String Processing and Information Retrieval, September 2000. http://laurikari.net/ville/spire2000-tnfa.ps
[3] M. Douglas McIlroy, “Enumerating the strings of regular languages,” Journal of Functional Programming 14 (2004), pp. 503–518. http://www.cs.dartmouth.edu/~doug/nfa.ps.gz (preprint)
[4] R. McNaughton and H. Yamada, “Regular expressions and state graphs for automata,” IRE Transactions on Electronic Computers EC-9(1) (March 1960), pp. 39–47.
[5] Paul Pierce, “CTSS source listings.” http://www.piercefuller.com/library/ctss.html (Thompson's QED is in the file com5 in the source listings archive and is marked as 0QED)
[6] Rob Pike, “The text editor sam,” Software—Practice & Experience 17(11) (November 1987), pp. 813–845. http://plan9.bell-labs.com/sys/doc/sam/sam.html
[7] Michael Rabin and Dana Scott, “Finite automata and their decision problems,” IBM Journal of Research and Development 3 (1959), pp. 114–125. http://www.research.ibm.com/journal/rd/032/ibmrd0302C.pdf
[8] Dennis Ritchie, “An incomplete history of the QED text editor.” http://plan9.bell-labs.com/~dmr/qed.html
[9] Ken Thompson, “Regular expression search algorithm,” Communications of the ACM 11(6) (June 1968), pp. 419–422. http://doi.acm.org/10.1145/363347.363387 (PDF)
[10] Tom Van Vleck, “The IBM 7094 and CTSS.” http://www.multicians.org/thvv/7094.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号