
Graph-WaveNet 训练数据的生成加代码注释
1.训练数据的获取
1. 获得邻接矩阵
运行gen_adj_mx.py文件,可以生成adj_mx.pkl文件,这个文件中保存了一个列表对象[sensor_ids 感知器id列表,sensor_id_to_ind (传感器id:传感器索引)字典,adj_mx 邻接矩阵 numpy数组[207,207]],注意,这个文件的运行需要节点距离文件distances_la_2012.csv和节点id文件graph_sensor_ids.txt,该文件代码注释如下:
def get_adjacency_matrix(distance_df, sensor_ids, normalized_k=0.1): """ :param distance_df: 距离的DataFrame,其中有3列:【from, to, distance】 :param sensor_ids: 感知器id列表 :param normalized_k: 一个阀值,如果邻接矩阵中元素小于这个值,被置为0 :return: 1.sensor_ids 感知器id列表 2.sensor_id_to_ind (传感器id:传感器索引)字典 3.adj_mx 邻接矩阵 numpy数组【207,207】 """ num_sensors = len(sensor_ids) dist_mx = np.zeros((num_sensors, num_sensors), dtype=np.float32) dist_mx[:] = np.inf # 构建 传感器id:传感器索引 字典 形如:{'773869': 0, '767541': 1, '767542': 2} sensor_id_to_ind = {} for i, sensor_id in enumerate(sensor_ids): sensor_id_to_ind[sensor_id] = i # 填充距离矩阵dist_max,规则为:只有from传感器的id和to传感器的id都存在于id列表中,才填充 for row in distance_df.values: if row[0] not in sensor_id_to_ind or row[1] not in sensor_id_to_ind: continue dist_mx[sensor_id_to_ind[row[0]], sensor_id_to_ind[row[1]]] = row[2] # 利用距离矩阵中所有非无穷大的数的标准差,构建邻接矩阵adj_mx,注意这是非对称矩阵,其中,节点到自身的值为1,形如: """ [[1.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00] [0.0000000e+00 1.0000000e+00 3.9095539e-01 1.7041542e-05 1.6665361e-05] [0.0000000e+00 7.1743792e-01 1.0000000e+00 6.9196528e-04 6.8192312e-04] [0.0000000e+00 9.7330502e-04 2.4218364e-06 1.0000000e+00 6.3372165e-01] [0.0000000e+00 1.4520076e-03 4.0022201e-06 6.2646437e-01 1.0000000e+00]] """ distances = dist_mx[~np.isinf(dist_mx)].flatten() std = distances.std() adj_mx = np.exp(-np.square(dist_mx / std)) # Make the adjacent matrix symmetric by taking the max. # adj_mx = np.maximum.reduce([adj_mx, adj_mx.T]) # 将邻接矩阵中小于这个阀值的元素置为0,形如: """ [[1. 0. 0. 0. 0. ] [0. 1. 0.3909554 0. 0. ] [0. 0.7174379 1. 0. 0. ] [0. 0. 0. 1. 0.63372165] [0. 0. 0. 0.62646437 1. ]] """ adj_mx[adj_mx < normalized_k] = 0 print(adj_mx[:5, :5]) return sensor_ids, sensor_id_to_ind, adj_mx if __name__ == '__main__': # 设置参数: # sensor_ids_filename: 传感器id文件的路径 # distances_filename: 传感器距离文件的路径 # output_pkl_filename: 输出的邻接矩阵文件的路径 # normalized_k: parser = argparse.ArgumentParser() parser.add_argument('--sensor_ids_filename', type=str, default='data/sensor_graph/graph_sensor_ids.txt', help='File containing sensor ids separated by comma.') parser.add_argument('--distances_filename', type=str, default='data/sensor_graph/distances_la_2012.csv', help='CSV file containing sensor distances with three columns: [from, to, distance].') parser.add_argument('--normalized_k', type=float, default=0.1, help='Entries that become lower than normalized_k after normalization are set to zero for sparsity.') parser.add_argument('--output_pkl_filename', type=str, default='data/sensor_graph/adj_mx.pkl', help='Path of the output file.') args = parser.parse_args() # 获取感知器id存入sensor_ids列表中 with open(args.sensor_ids_filename) as f: sensor_ids = f.read().strip().split(',') # 读取csv距离文件,数据格式如下 """ from to cost 0 1201054 1201054 0.0 1 1201054 1201066 2610.9 2 1201054 1201076 2822.7 3 1201054 1201087 2911.5 4 1201054 1201100 7160.1 """ distance_df = pd.read_csv(args.distances_filename, dtype={'from': 'str', 'to': 'str'}) normalized_k = args.normalized_k _, sensor_id_to_ind, adj_mx = get_adjacency_matrix(distance_df, sensor_ids, normalized_k) # 将上面的返回值保存成列表对象, protocol=2表示以2进制方式保存,pickle模块用来实现对象的序列化和反序列化 with open(args.output_pkl_filename, 'wb') as f: pickle.dump([sensor_ids, sensor_id_to_ind, adj_mx], f, protocol=2)
2.获得训练集、测试集和验证集
终端中运行以下命令:
# METR-LA python generate_training_data.py --output_dir=data/METR-LA --traffic_df_filename=data/metr-la.h5 # PEMS-BAY python generate_training_data.py --output_dir=data/PEMS-BAY --traffic_df_filename=data/pems-bay.h5
产生的数据集维度情况:
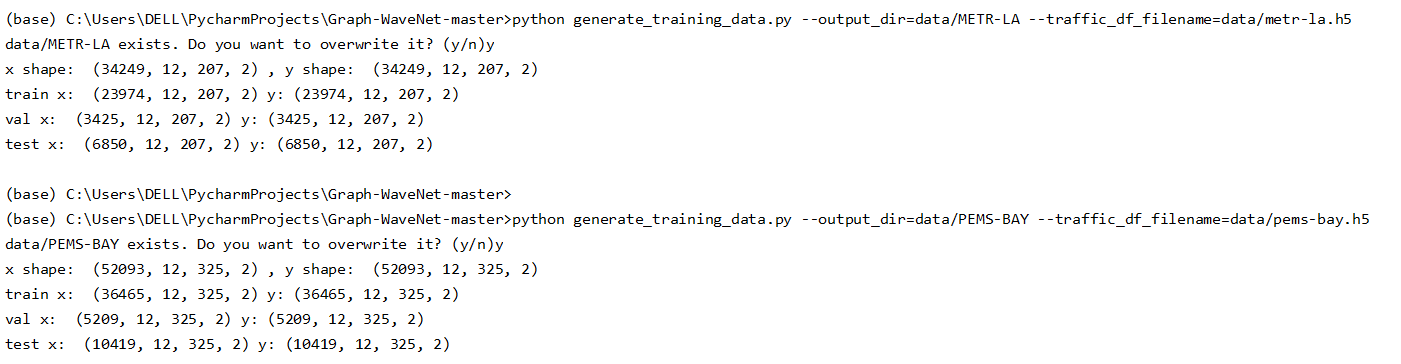
该文件代码注释如下:
def generate_graph_seq2seq_io_data( df, x_offsets, y_offsets, add_time_in_day=True, add_day_in_week=False, scaler=None ): """ 产生输入数据和输出数据,形状【样本数,序列长度(12),节点数(207),特征数(2)】,函数generate_train_val_test中有解释 :param df: :param x_offsets: 输入数据的索引偏置 :param y_offsets: 输出数据的索引偏置 :param add_time_in_day: 将时间转为以天为单位,函数generate_train_val_test有解释 :param add_day_in_week: :param scaler: :return: 输入数据和输出数据 # x: (epoch_size, input_length, num_nodes, input_dim) # y: (epoch_size, output_length, num_nodes, output_dim) """ num_samples, num_nodes = df.shape # 将二维数组[M,207]扩张成三维[M,207,1],数据格式如下 """ [[[64.375 ], [67.125 ], ..., [61.875 ]], ..., [[55.88888889], [68.44444444], [62.875 ]]] """ data = np.expand_dims(df.values, axis=-1) feature_list = [data] if add_time_in_day: # 这个语句将日期转为以天为单位,形如[0. 0.00347222 0.00694444 0.01041667 0.01388889 0.01736111 # 0.02083333 0.02430556 0.02777778 0.03125 ] time_ind = (df.index.values - df.index.values.astype("datetime64[D]")) / np.timedelta64(1, "D") time_in_day = np.tile(time_ind, [1, num_nodes, 1]).transpose((2, 1, 0)) feature_list.append(time_in_day) if add_day_in_week: dow = df.index.dayofweek dow_tiled = np.tile(dow, [1, num_nodes, 1]).transpose((2, 1, 0)) feature_list.append(dow_tiled) # 将当前样本的时间加入到了特征中,所有特征变成了:速度+时间,形状变成[M,207,2],形如 """ [[[6.43750000e+01 0.0000], [6.76250000e+01 0.0000], [6.71250000e+01 0.0000], ..., [5.92500000e+01 0.0000]], ..., [[6.90000000e+01 0.9653], [6.18750000e+01 0.99653], ..., [6.26666667e+01 0.99653]]] """ data = np.concatenate(feature_list, axis=-1) x, y = [], [] min_t = abs(min(x_offsets)) max_t = abs(num_samples - abs(max(y_offsets))) # Exclusive for t in range(min_t, max_t): # t is the index of the last observation. x.append(data[t + x_offsets, ...]) y.append(data[t + y_offsets, ...]) x = np.stack(x, axis=0) y = np.stack(y, axis=0) return x, y def generate_train_val_test(args): """ 输入参数,产生训练集、测试集和测试集,比例为:0.7:0.2:0.1,保存在METR-LA文件夹中 最终数据集的形状为【M,12,207,2】,M表示数据集/样本长度, 【12,207,2】为单个输入数据或输出数据,其中12表示时间序列长度,207表示节点数量,2表示节点特征(一个是速度,另一个为当前数据的时间) 并且这个时间它是用天表示的,比如8月12号0点5分,和8月13号0点5分是一样的,都是(5/60/24)=0.0034722天 :param args: 输入参数,里面包括了历史数据序列长度、要预测的时间长度,5分钟为一个单位 :return: 无 """ # 输入的时间序列长度和输出的预测时间序列长度 seq_length_x, seq_length_y = args.seq_length_x, args.seq_length_y # 读取metr-la.h5文件,其中列索引为传感器节点id,行索引为时间,间隔为5分钟,形如: """ 773869 767541 ... 718141 769373 2012-03-01 00:00:00 64.375000 67.625000 ... 69.000000 61.875 2012-03-01 00:05:00 62.666667 68.555556 ... 68.444444 62.875 2012-03-01 00:10:00 64.000000 63.750000 ... 69.857143 62.000 2012-03-01 00:15:00 0.000000 0.000000 ... 0.000000 0.000 2012-03-01 00:20:00 0.000000 0.000000 ... 0.000000 0.000 """ df = pd.read_hdf(args.traffic_df_filename) # 获取输入数据的索引偏置,为 numpy一维数组:[-11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0], # 这个函数应该不用这么复杂,直接np.arange(-(seq_length_x - 1), 1, 1)应该就可以了 x_offsets = np.sort(np.concatenate((np.arange(-(seq_length_x - 1), 1, 1),))) # 输出数据也就是预测数据标签的索引偏置,为numpy一维数组:[1 1 2 ... 12] y_offsets = np.sort(np.arange(args.y_start, (seq_length_y + 1), 1)) # 得到了输入数据x和对应标签数据y # x: (num_samples, input_length, num_nodes, input_dim) # y: (num_samples, output_length, num_nodes, output_dim) x, y = generate_graph_seq2seq_io_data( df, x_offsets=x_offsets, y_offsets=y_offsets, add_time_in_day=True, add_day_in_week=args.dow, ) print("x shape: ", x.shape, ", y shape: ", y.shape) # 利用numpy保存数据进.npz文件中,每个文件中都包含输入数据、标签数据、输入数据索引偏置、标签数据索引偏置, # 和上面说的差不多,只是形状变成了[12,1]的二维数组 num_samples = x.shape[0] num_test = round(num_samples * 0.2) num_train = round(num_samples * 0.7) num_val = num_samples - num_test - num_train x_train, y_train = x[:num_train], y[:num_train] x_val, y_val = ( x[num_train: num_train + num_val], y[num_train: num_train + num_val], ) x_test, y_test = x[-num_test:], y[-num_test:] for cat in ["train", "val", "test"]: _x, _y = locals()["x_" + cat], locals()["y_" + cat] print(cat, "x: ", _x.shape, "y:", _y.shape) np.savez_compressed( os.path.join(args.output_dir, f"{cat}.npz"), x=_x, y=_y, x_offsets=x_offsets.reshape(list(x_offsets.shape) + [1]), y_offsets=y_offsets.reshape(list(y_offsets.shape) + [1]), ) if __name__ == "__main__": parser = argparse.ArgumentParser() # 设置参数, # output_dir:数据输出文件夹路径 # traffic_df_filename:交通流量数据文件路径,这个文件类似于excel表,有207列,列标签是传感器id,有34249行,每一行的行索引是时间,间隔为5分钟,行和列对应的数据为速度? # seq_length_x: 输入数据的时间序列长度,默认为12,因此表示当前时刻之前1个小时的历史数据 # seq_length_y: 输出数据的时间序列长度,默认为12,因此表示预测未来1小时内的流量 parser.add_argument("--output_dir", type=str, default="data/METR-LA", help="Output directory.") parser.add_argument("--traffic_df_filename", type=str, default="data/metr-la.h5", help="Raw traffic readings.", ) parser.add_argument("--seq_length_x", type=int, default=12, help="Sequence Length.", ) parser.add_argument("--seq_length_y", type=int, default=12, help="Sequence Length.", ) parser.add_argument("--y_start", type=int, default=1, help="Y pred start", ) parser.add_argument("--dow", action='store_true', ) args = parser.parse_args() # 是否覆盖文件,不重要 if os.path.exists(args.output_dir): reply = str(input(f'{args.output_dir} exists. Do you want to overwrite it? (y/n)')).lower().strip() if reply[0] != 'y': exit else: os.makedirs(args.output_dir) # 产生训练数据 generate_train_val_test(args)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号