5组 需求分析报告
https://www.cnblogs.com/pat-chou-li/p/15483885.html
一、团队基本情况
1.团队项目的整体计划安排
| 时间 | 计划 |
|---|---|
| 团队创建-10.23 | 选题报告及答辩 |
| 10.24-10.31 | 需求分析报告及答辩 |
| 11.1-11.7 | 设计稿成型、前后端接口联调 |
| 11.8-11.14 | 总体框架搭建 |
| 11.15-11.28 | Alpha |
| 11.29-12.12 | Beta |
| 12.13-? | 完善 |
- 团队分工
| 团队成员 | 分工明细 |
|---|---|
| 吴振溢 | 团队规划、博客,文案整理,前端界面实现 |
| 张乐芃 | 原型,logo设计、前端界面实现 |
| 周浩东 | 数据处理 |
| 黄朝威 | 数据收集 |
| 林蒋辉 | 后端框架搭建、后端功能实现 |
| 潘春佳 | 原型设计,各类文案工作 |
| 陈宇扬 | 原型设计,各类文案工作 |
| 周伟杰 | 原型设计,后端功能实现,各类文案工作 |
| 蔡树峰 | 视频导演及剪辑,后端功能实现 |
3.请评估并描述团队中每个人对本次作业的贡献比例,并写入本次博客
| 团队成员 | 分工情况 | 任务比例% |
|---|---|---|
| 吴振溢 | 统筹+需求报告撰写+部分可视化分析模板(uml图)+PPT | 12 |
| 林蒋辉 | 检索模板(uml图) | 9 |
| 黄朝威 | 数据收集(uml图) | 10 |
| 周浩东 | 数据处理(uml图) | 9 |
| 周伟杰 | 用户模块(uml图)+原型设计 | 14 |
| 张乐芃 | 部分可视化分析模板(uml图)+项目logo | 10 |
| 潘春佳 | 思维导图+需求报告撰写 | 12 |
| 陈宇扬 | 原型设计+PPT | 14 |
| 蔡树峰 | 视频导演、视频剪辑 | 10 |
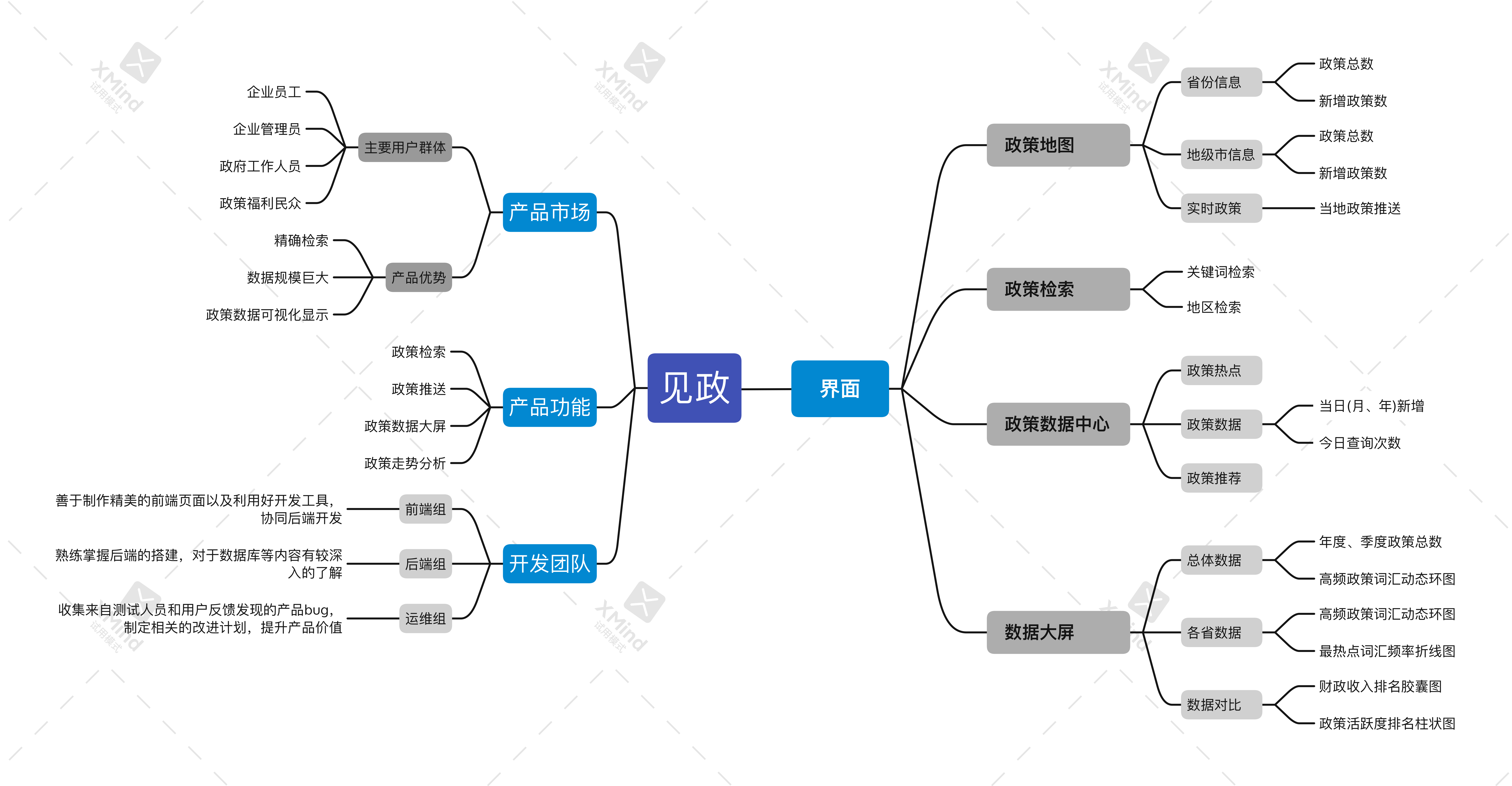
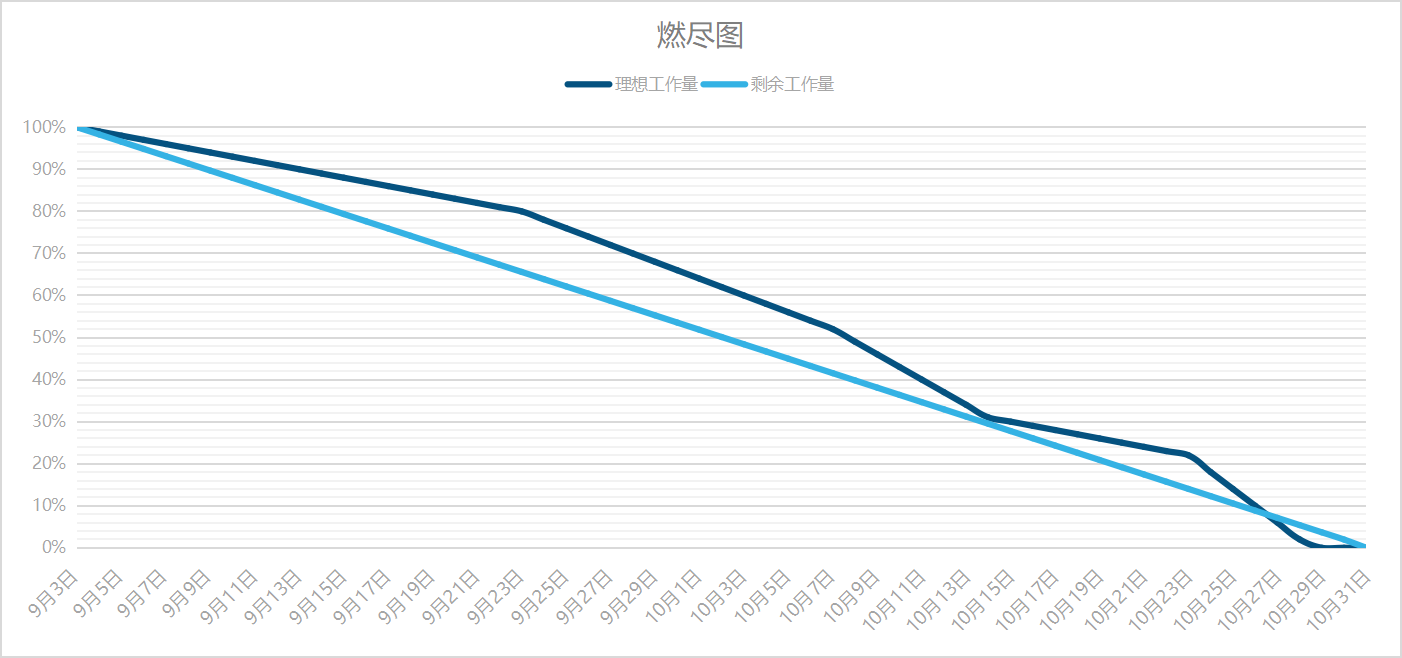
4.画出整个项目思维导图和燃尽图
思维导图:
燃尽图:
二、根据自己所负责的项目的部分画UML
-
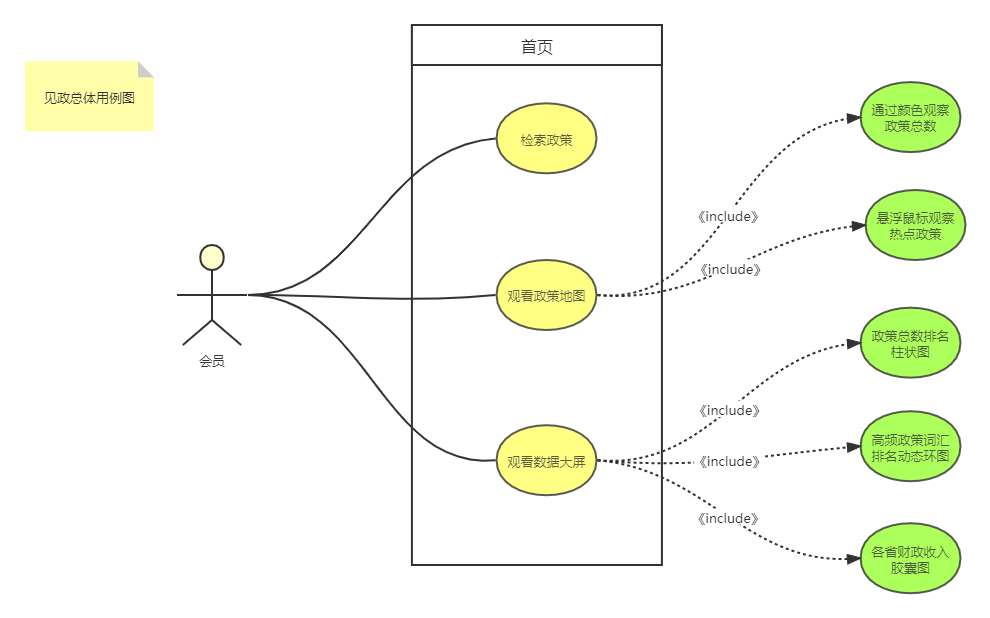
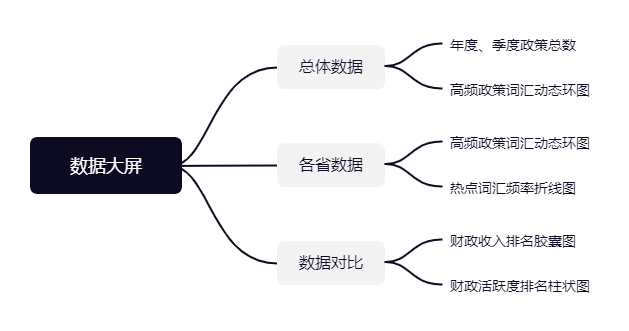
可视化模块:
-
负责人:张乐芃,吴振溢
-
描述:该部分用于显示政策推荐信息以及用户活跃度,并按搜索热度,区域等分梯度排列
-
该部分面临的问题:如何美观优雅的展示数据
-
解决的问题:选择有效的信息进行显示,提高推荐精度,增加用户粘性
-
附:UML图
-

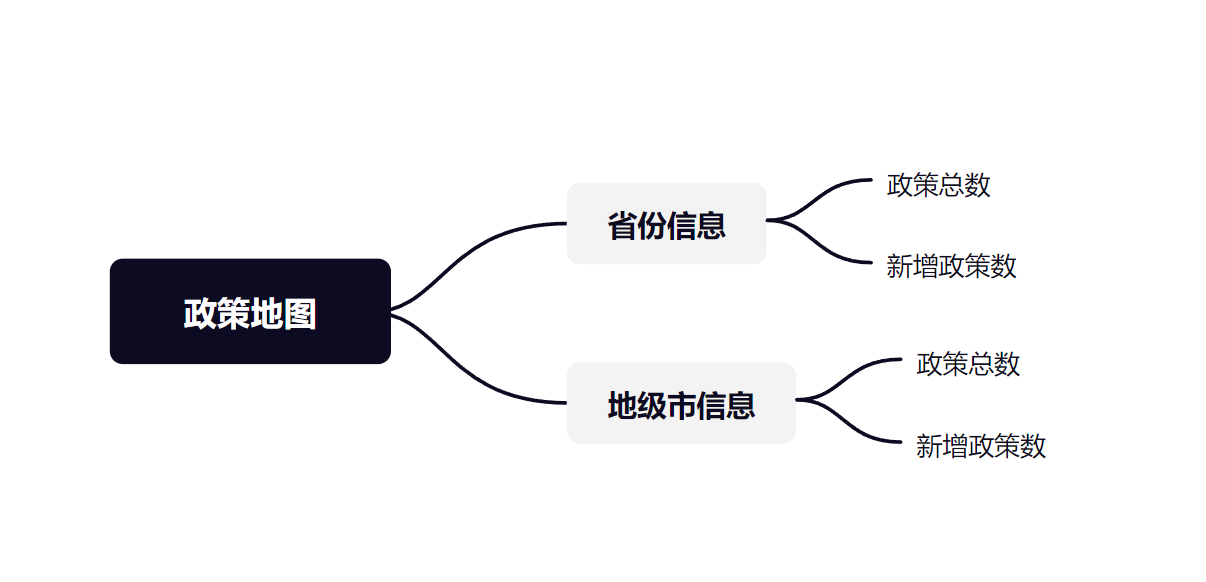
-
数据收集模块:
-
负责人:黄朝威
-
描述:尽可能全面的收集数据,并简单进行数据处理交付给后台
-
该部分面临的问题:面对可能的加密,不同的前端样式,需要不同的代码进行爬取
-
解决的问题:重写各类代码,在尽可能多复用的前提下编写hardcode来爬取所有政策
-
附:UML图
-
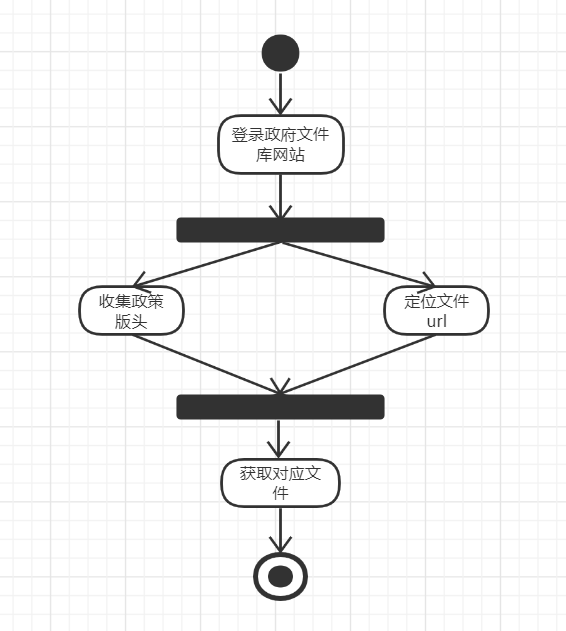
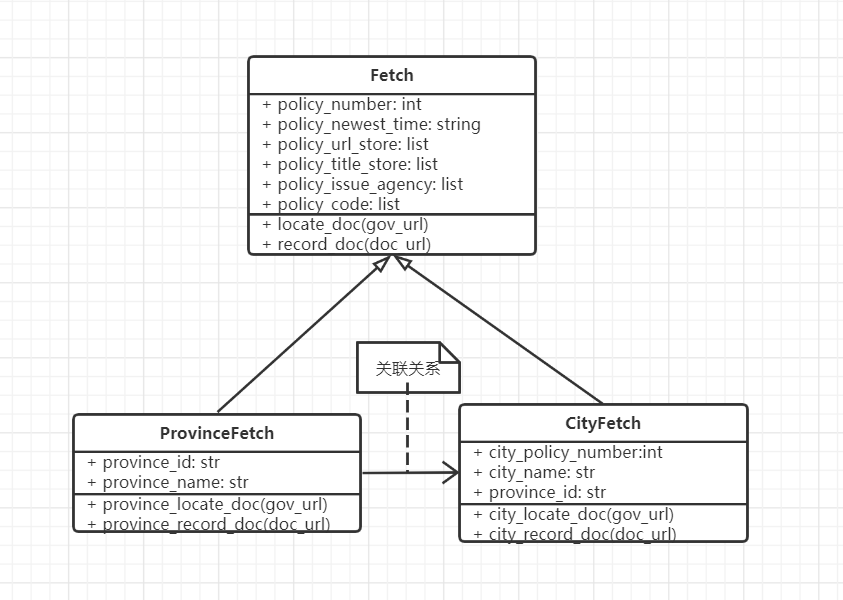

-
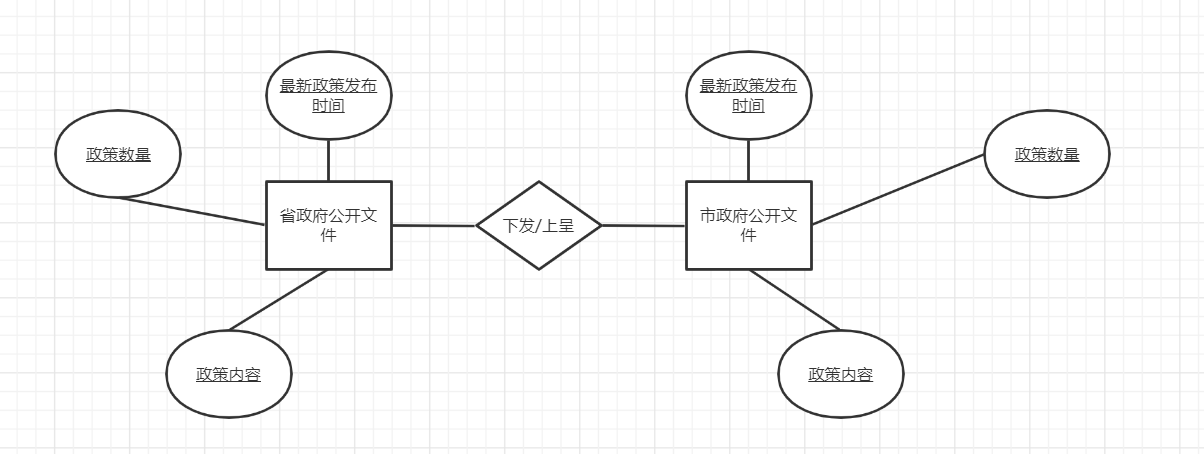
数据处理模块:
-
负责人:周浩东
-
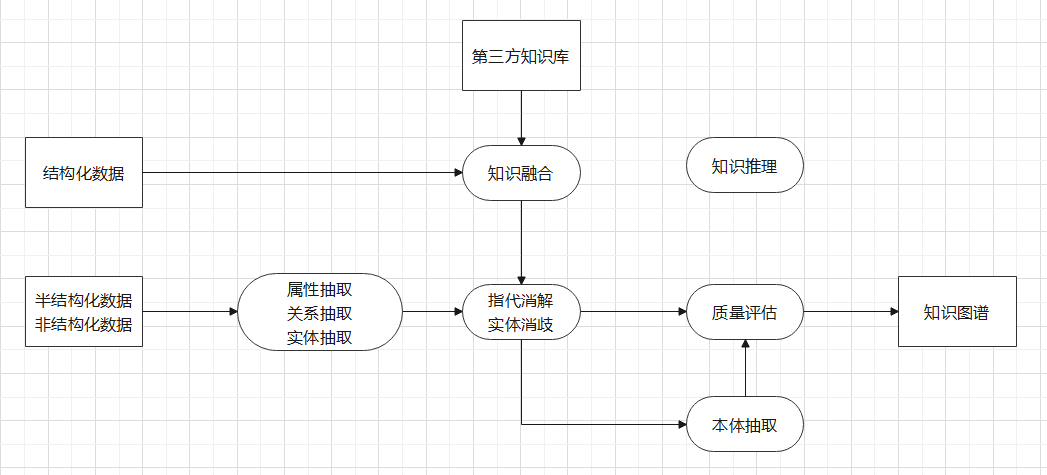
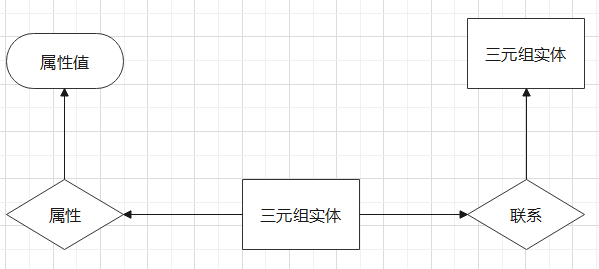
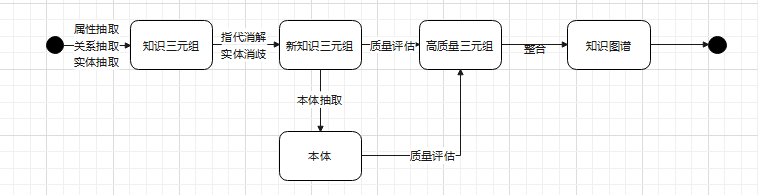
描述:处理数据并形成知识图谱,搭建出后端检索,前端大数据展示的基础。
-
该部分面临的问题:形成知识图谱需要的算法,超大规模数据下的快速处理
-
解决的问题:分布式进行并发数据处理,在尽可能短时间内将数据处理完毕
-
附:UML图
-

-
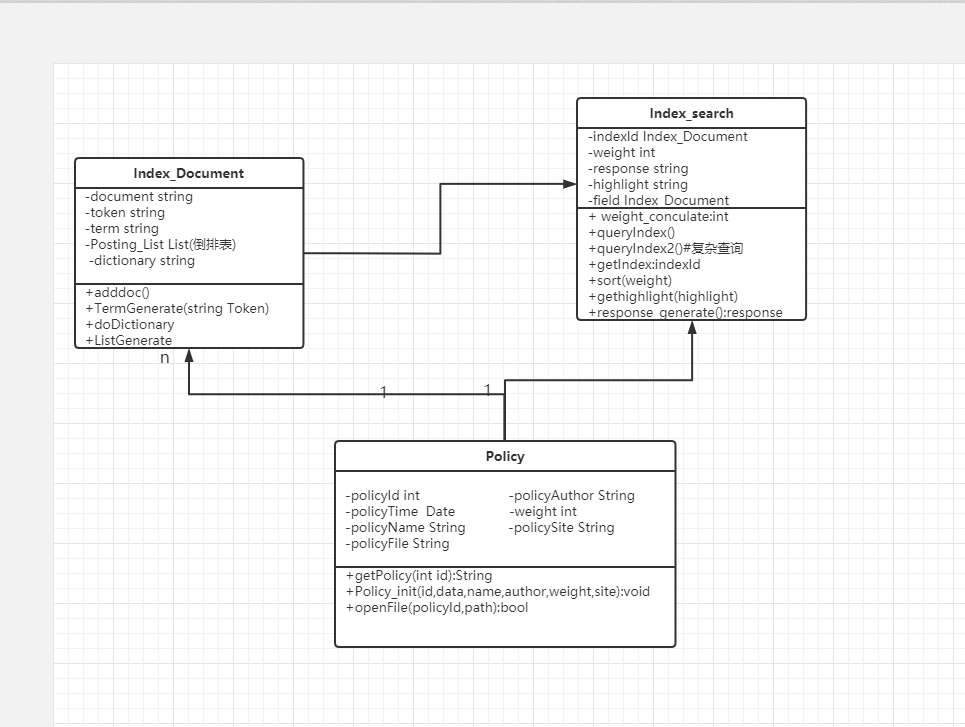
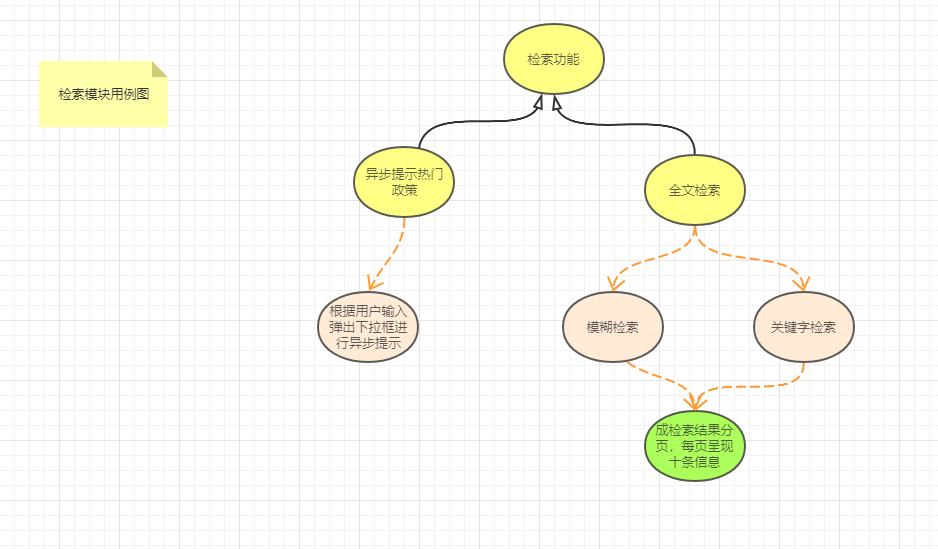
检索模块:
-
负责人:林蒋辉
-
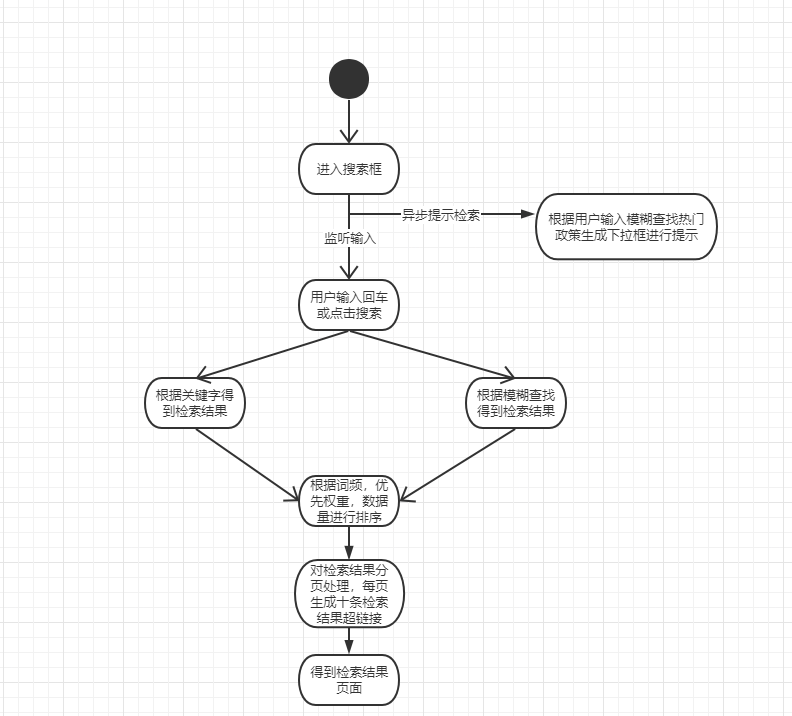
描述:提供数据检索接口
-
该部分面临的问题:在庞大的数据库中检索所需内容,并进行多权重排序。
-
解决的问题:尽量不太慢的返回排序好的数据。
-
附:UML图
-

-
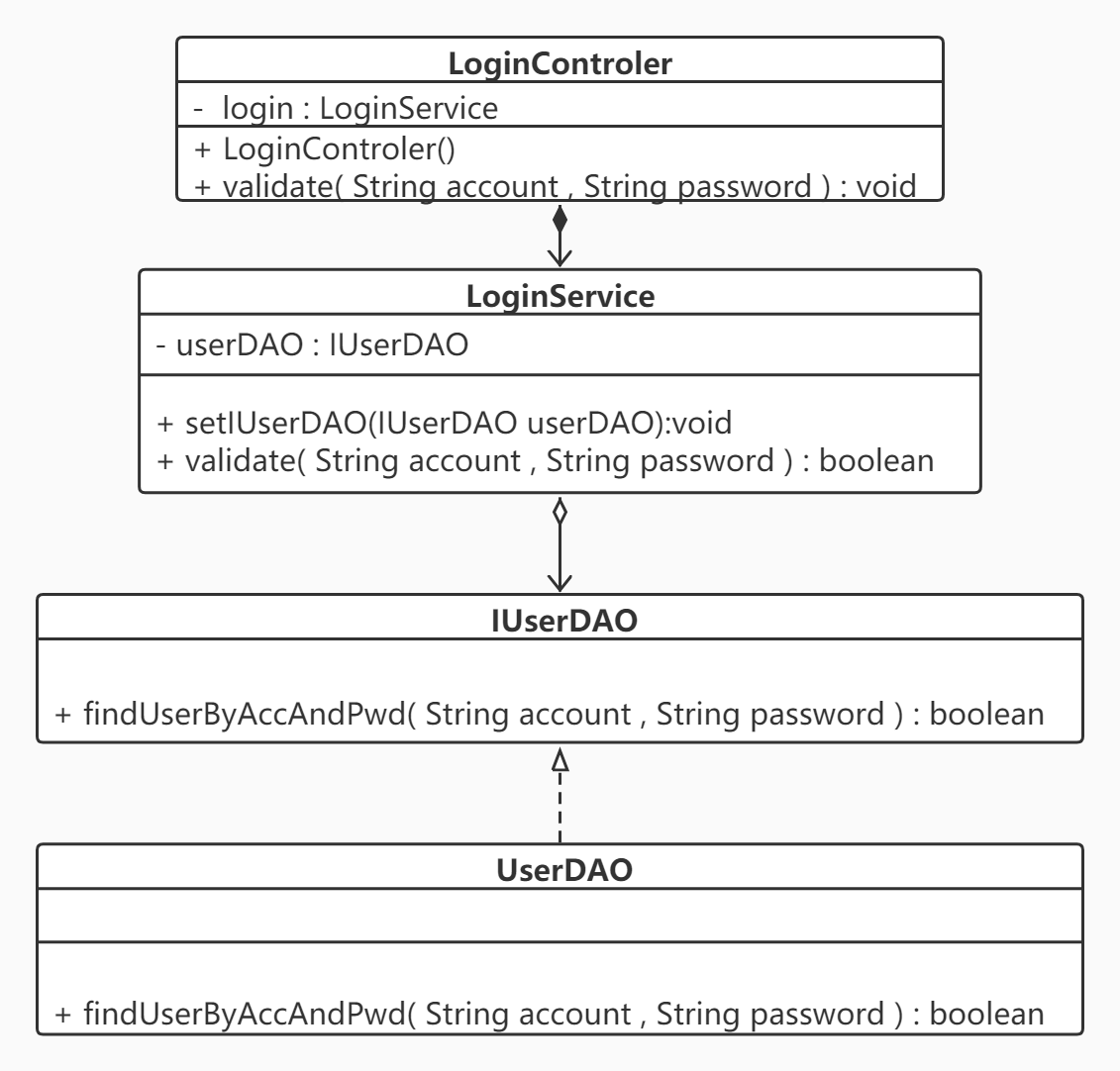
用户模块:
-
负责人:周伟杰
-
描述:提供登录、注册、收藏等功能,为构建用户画像,完成个性化推荐打下基础。
-
该部分面临的问题:数据库安全性问题
-
解决的问题:使用安全级别高的数据库存储用户敏感信息
-
附:UML图
-




三、作业记录相关
1.UML设计工具的选择、选择的理由和使用后对工具的评价:
基本全组使用了Process On。(备注:有位猛男直接windows自带画图,实在是令人敬佩)
选择理由:方便上手,免费的情况下不加水印。
对工具的评价:对于第一次画UML图的大家来说十分友好,界面交互简洁方便并且富有人性化,即使直接使用也能很快找到自己想用的功能在哪。
2.遇到的困难及解决方法
-
数据爬取:
- 问题:数据量过于巨大,一个省份就至少有十几万个文件,这也会给数据库构建和数据处理带来麻烦,同时不同省的样式不一样,需要编写不同的爬虫代码来应对,增大了工作量。个别省份会做一些简单的加密,不知用意如何。
- 解决方案:尽量提高代码的复用程度,但是不同省市需要编写不同代码的问题基本无法解决。加密已完成破解,希望不会被查水表。
-
前端兼容
-
问题:这里指的不是浏览器兼容。我们已经打算不兼容IE了。
前端采用Vue3.x+Sass+typeScript+vite+naiveUI+echarts+dataV进行搭建,这些框架和组件库中,有些东西已经具有一定年代感了,和新生的vue3.x在兼容性上出了很多问题。
-
解决方案:改源码。已经改好了。
-
3.学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 500 | 500 | 12 | 12 | 确认最终选题,做好开题报告,爬虫选择性爬取个别省份数据确定数据收集可行性,AI确认算法,前端选择框架和组件库。 |
| 2 | 1200 | 1700 | 16 | 28 | 完成需求分析报告,后端前端AI大致确定类图,前端解决组件库和框架兼容问题,爬虫持续进行中,已有十万条政策文件数据。 |
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 |

