结对编程作业
https://github.com/trainKing-star/PigGame
| 姓名 | 学号 | 博客链接 | 项目类型 |
|---|---|---|---|
| 周浩东 | 031902332 | 结对编程作业 | 单人项目 |
项目已部署在云服务器,电脑点击访问试玩,不过服务器带宽小、作品需要加载的资源太大,初次加载会有需要游览器缓存资源,可能存在一些bug
一、原型设计
1. 原型作品
设计灵感来自NS版世界游戏大全51猪尾巴游戏,以这个游戏的UI界面为原型,详情见B站视频链接
各个页面使用简洁风格,游戏间使用大量的动画增强交互感,页面有设置背景音乐,因此决定设计内容:
- 项目以Web页面形式开发
- 游戏界面向B站视频中演示UI靠齐,力求还原
- 游戏界面、游戏元素都有背景音乐或者音效
- 游戏元素响应鼠标事件,能响应动画
2. 原型开发工具
3. 开发原型界面
(1)主界面
主界面逻辑:
- 用户进入页面,页面背景为黑色,等待4s后页面内容全部加载,设置有动画
- 4s内界面逐渐从黑色变为设置的颜色,透明度从0逐渐到1过度
- 4s内页面牌堆开始加载并逐步演示牌堆动画
- 4s后如页面全部元素加载完毕,中间的牌堆和猪猪设置有连续的上下浮动动画

- 页面设置有背景音乐,当音乐文件加载完毕便开始循环播放音乐,音乐选择了轻松愉悦的纯音乐《菊次郎的夏天》
- 页面右下方的选项按钮,设置有当获取到鼠标访问时会有变色效果
(2)游戏界面
游戏界面逻辑:
- 用户进入页面,页面背景为黑色,等待4s后页面内容全部加载,设置有动画
- 4s内界面逐渐从黑色变为设置的颜色,透明度从0逐渐到1过度并且过程中背景会逐渐被拉近
- 4s内页面牌堆开始加载,并会在游戏背景中按顺便排成一个扇形
- 4s后如页面全部元素加载完毕,默认时左下角的玩家先手,左下角玩家头像会变大并且开始有规律的闪烁
- 页面设置有背景音乐,元素也有特有音效
- 在出牌阶段,出牌的玩家头像会变大并且有规律的闪烁
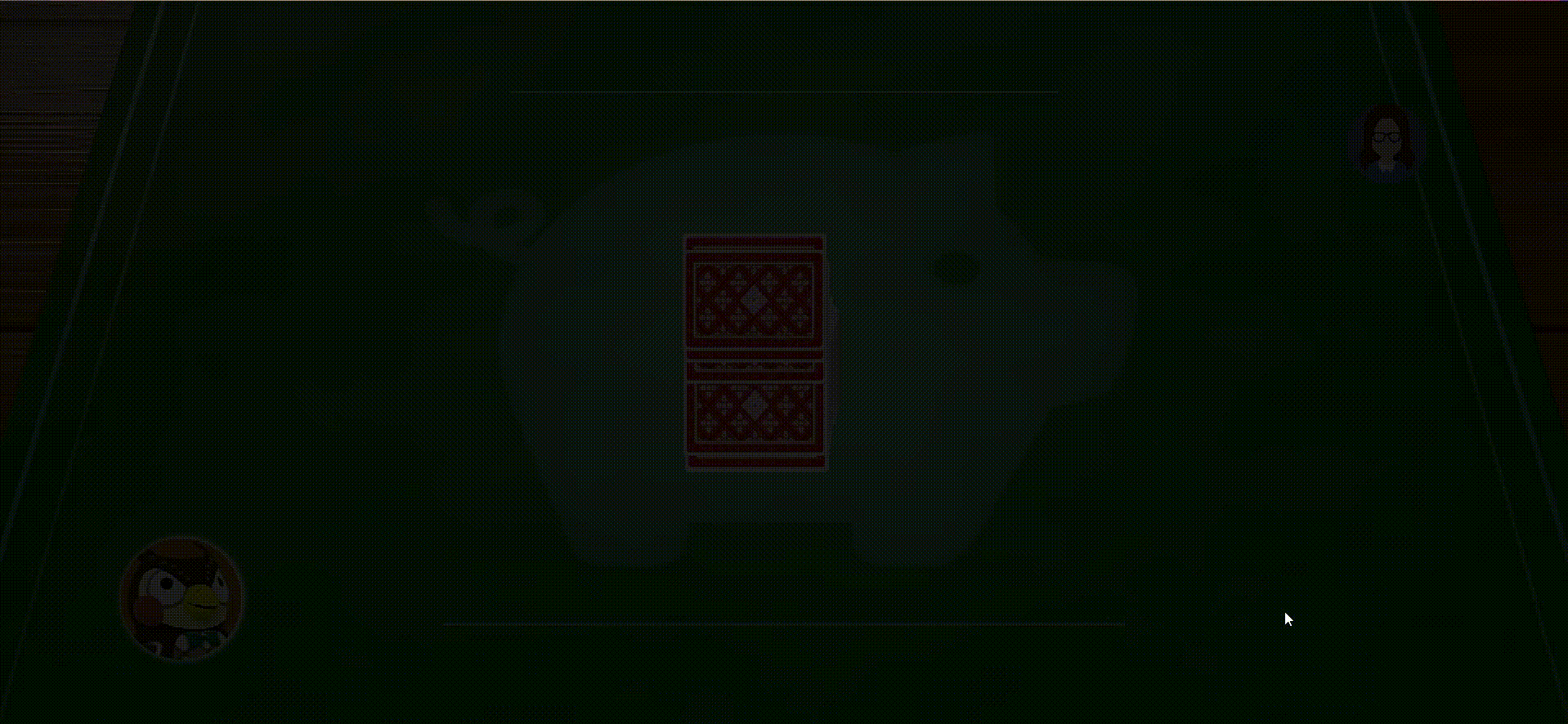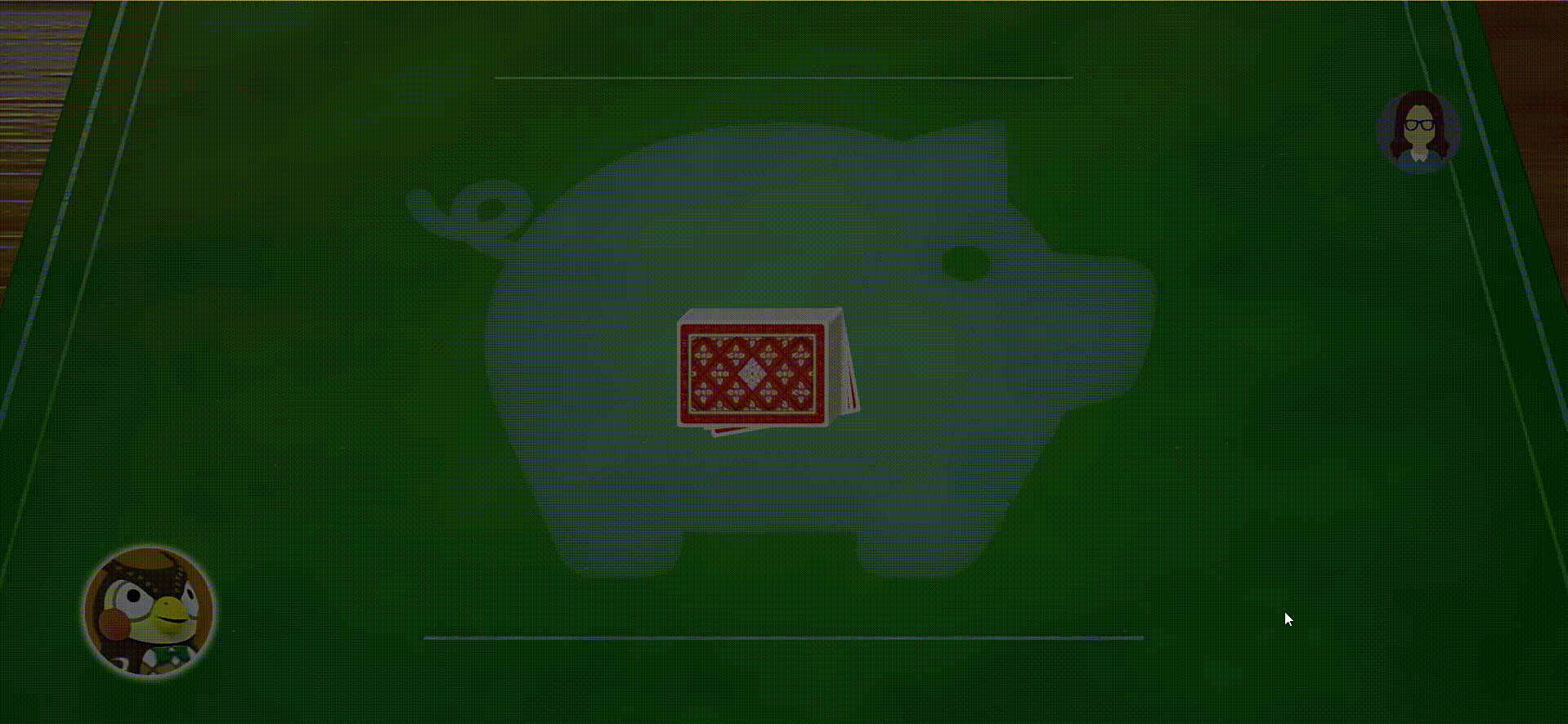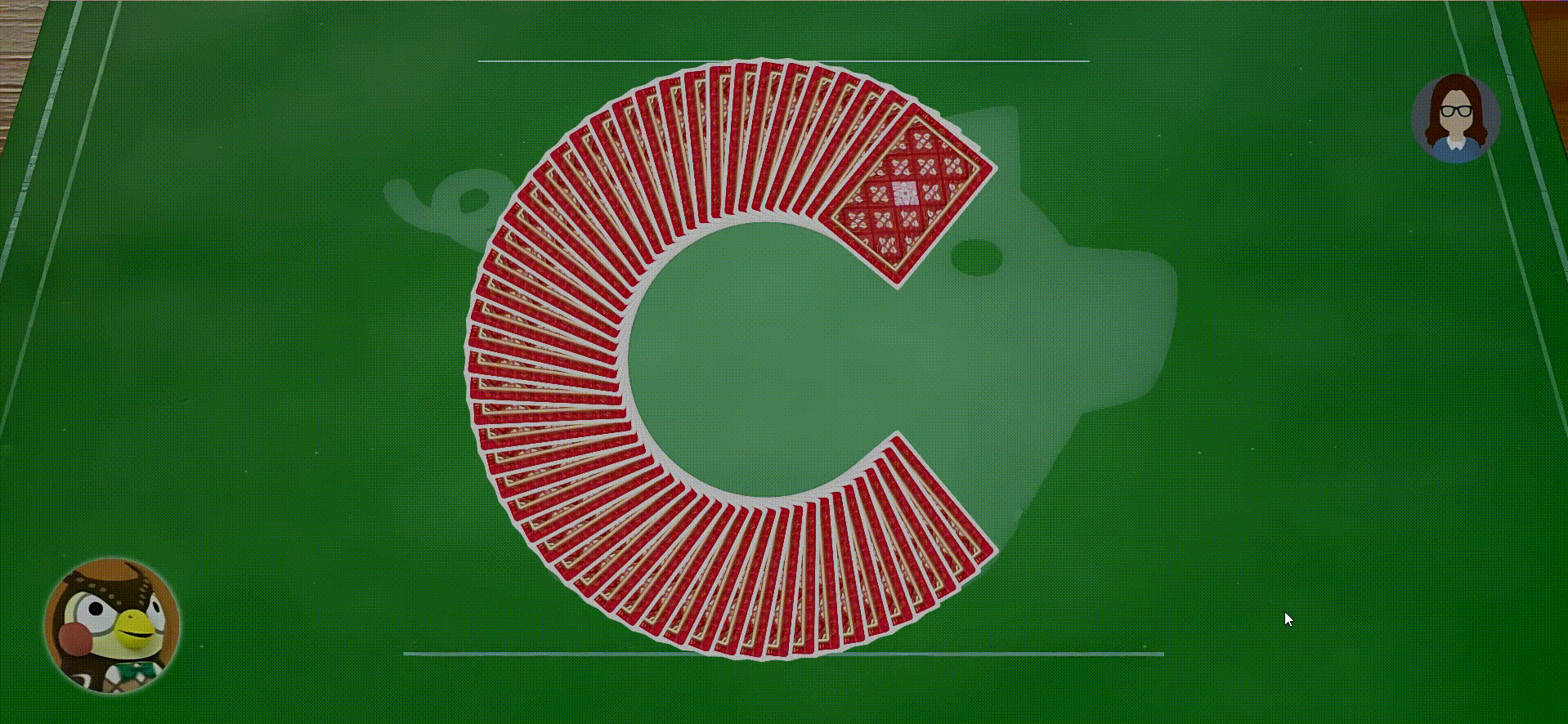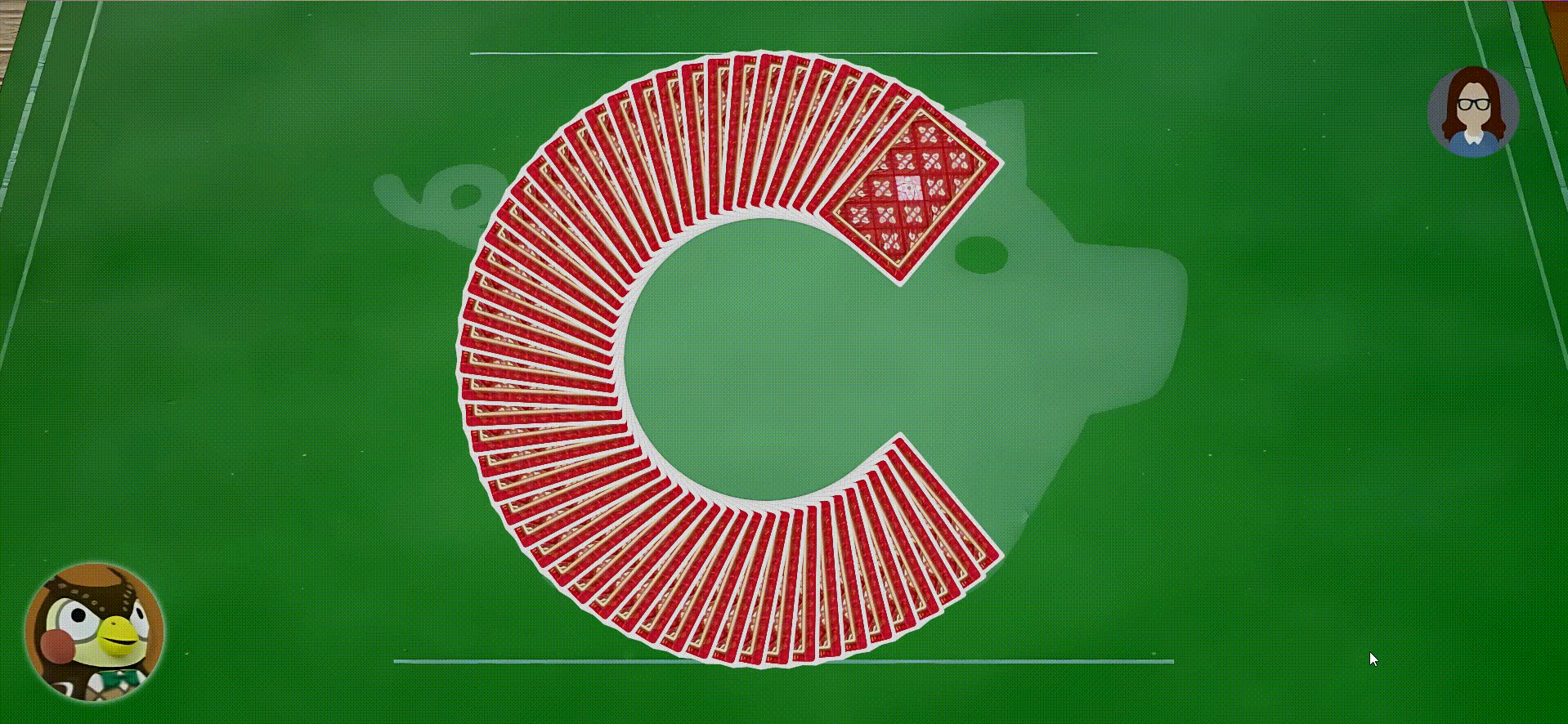
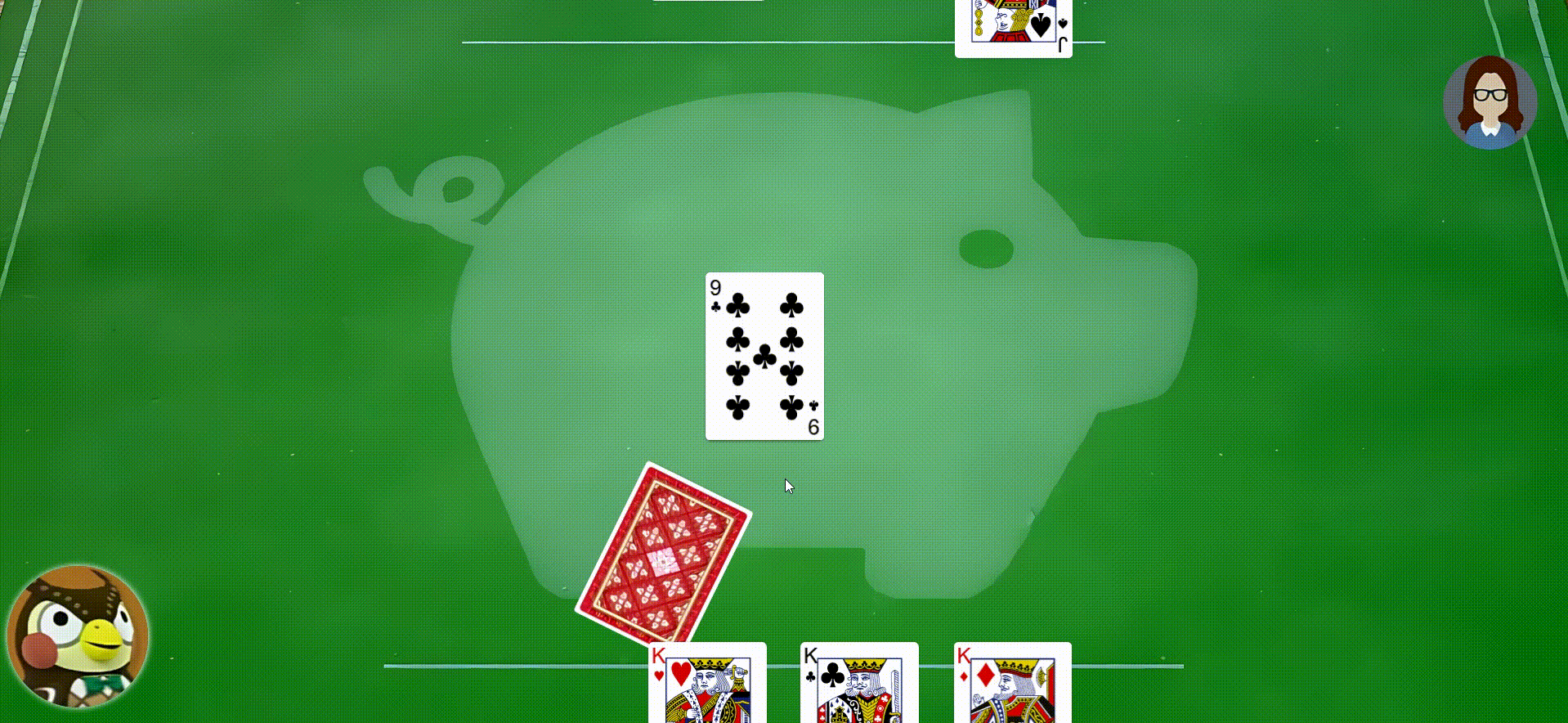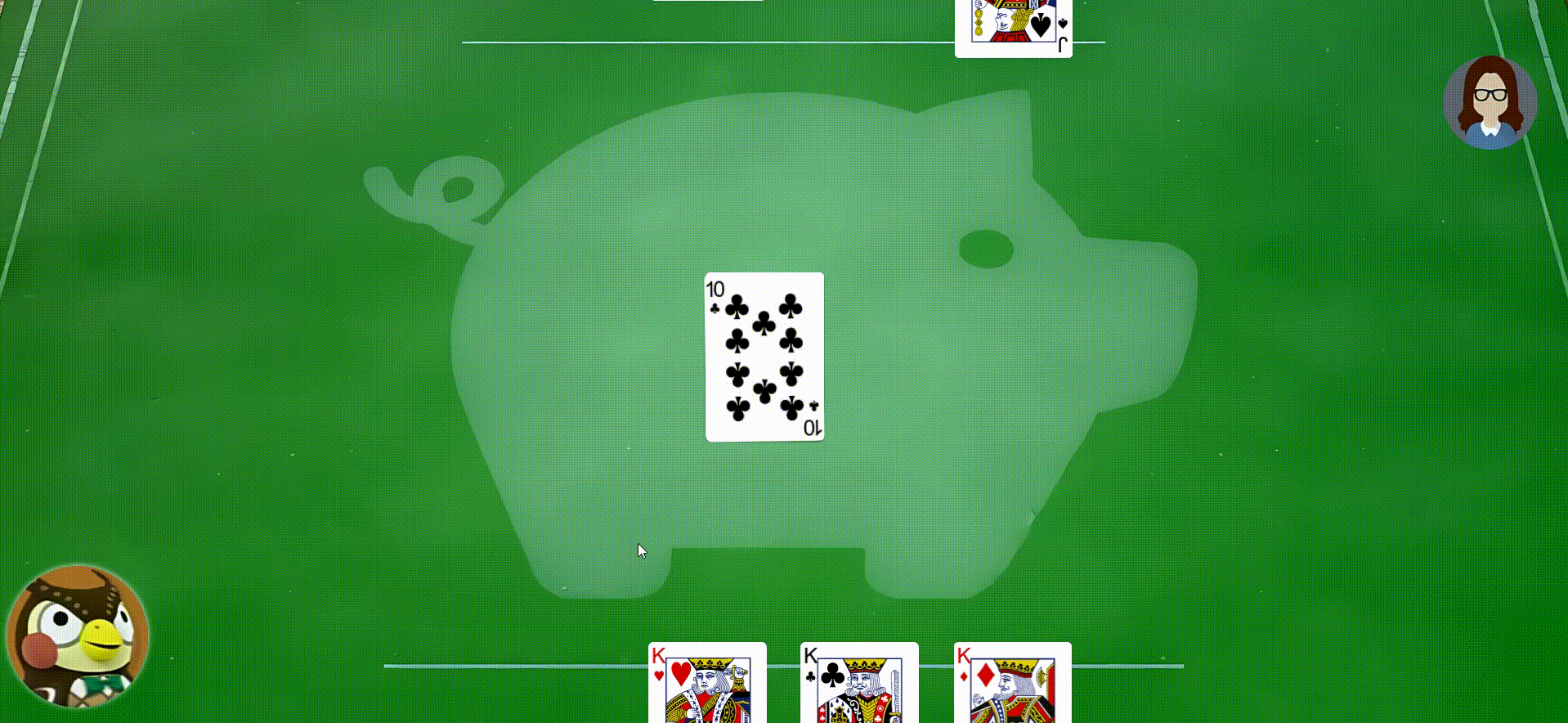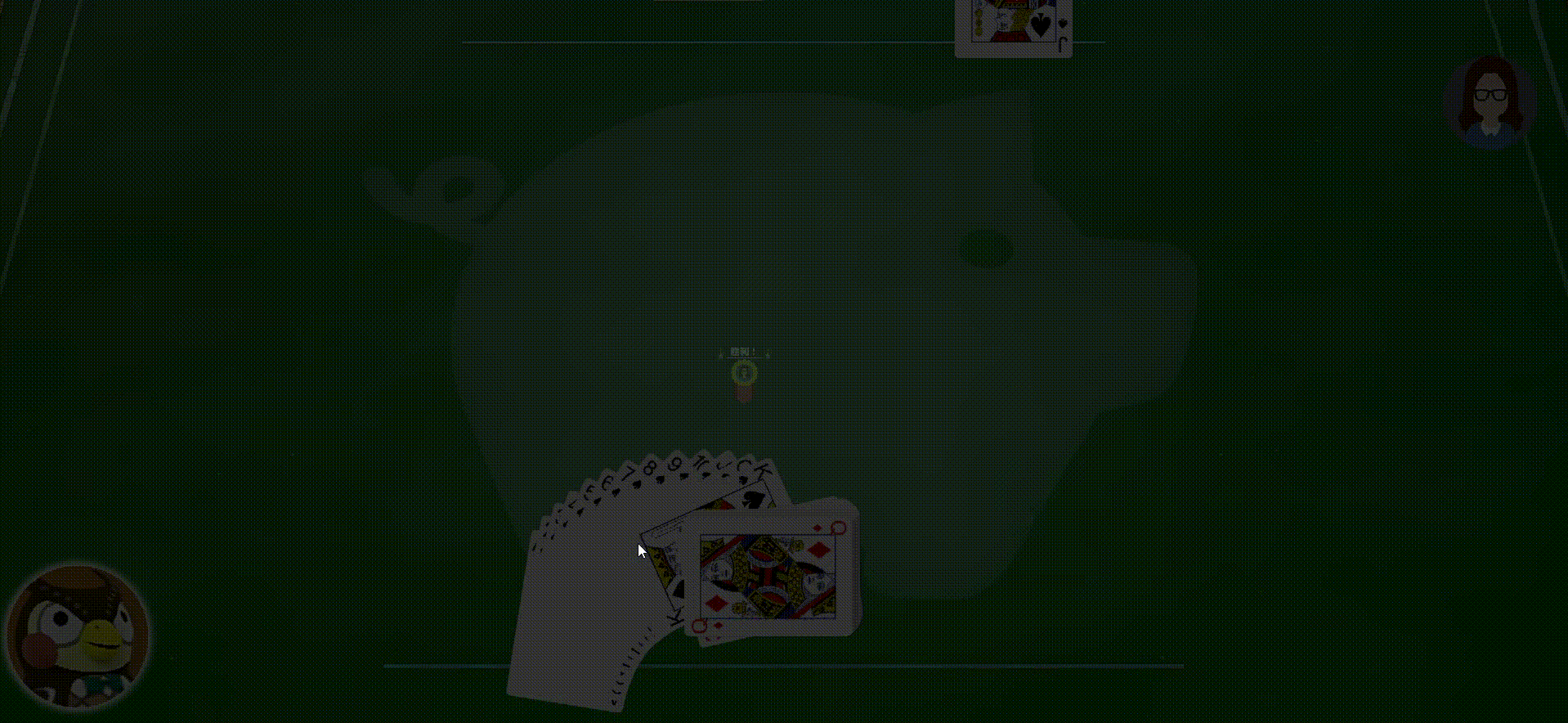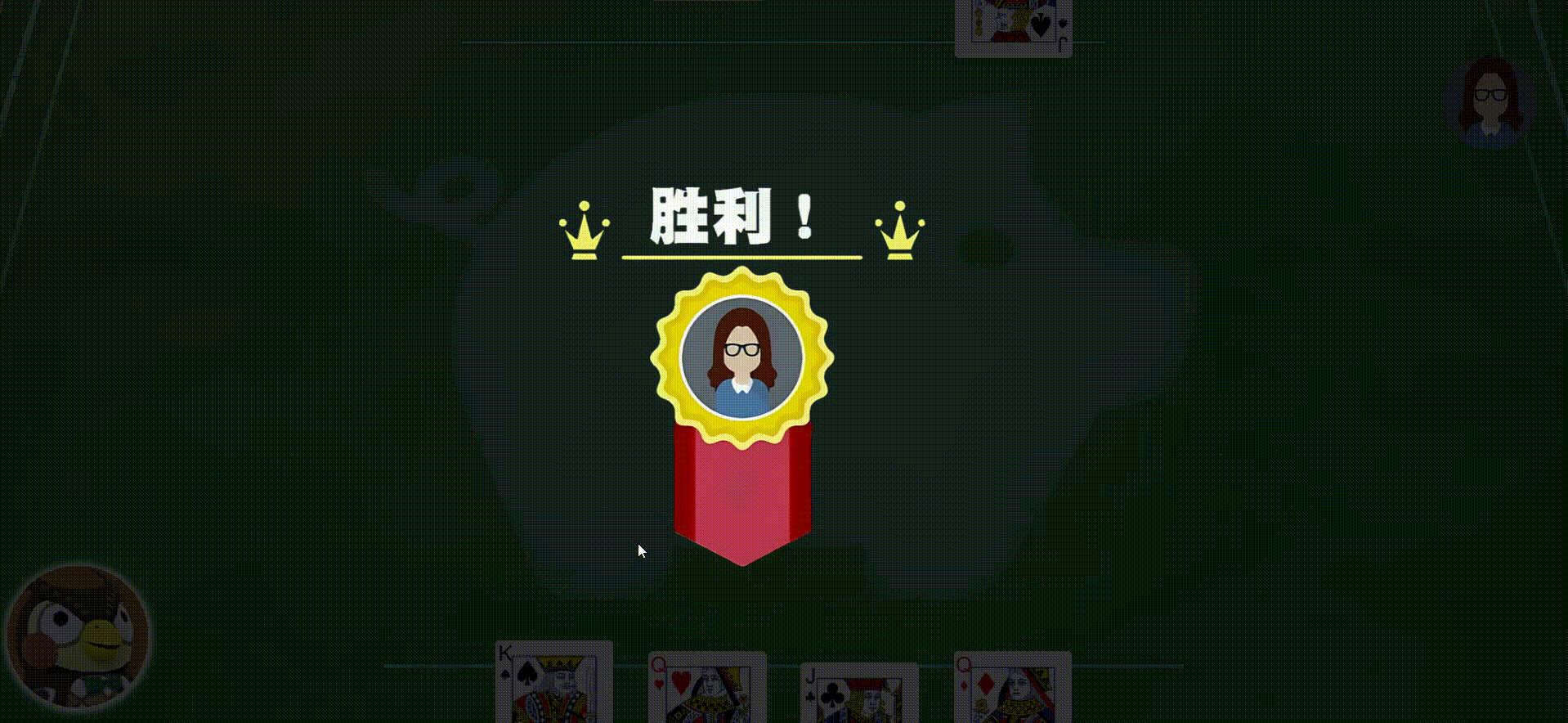
- 扇形牌堆可以响应鼠标事件,当鼠标移动到牌上,牌会提高Z轴并且视图变大,点击牌,牌将进行动画移动到扇形中间区域

- 用户打出的牌与翻开的牌堆顶部牌同花色时,翻开牌堆的牌将消失并且会进行一系列的动画出现在对应玩家的手牌区域

- 用户点击用户的手牌区域将动画弹出用户的手牌,如果是自己的手牌则在自己的出牌阶段可以从手牌打出,打出时牌会从手牌消失并且动画出现在翻过牌堆,再次点击手牌区将会把弹出的手牌弹回手牌区


(3)游戏结束界面
结束界面逻辑:
- 当扇形牌堆最后一张牌被打出,进入游戏结束界面,一层透明淡黑色背景覆盖原页面
- 首先出现两个玩家的手牌数量对比,如果两者手牌不相等则逐渐出现对应的胜利图案,其间有胜利的音效,一段时间后回到主界面
4. 困难及解决方法
| 问题 | 解决方案 |
|---|---|
| UI原型来自B站视频,没有图片、音频等资源 | 通过在线PS、抠图,图像超分、图片修正等工具和技术获取到想要的所有资源 |
| 扑克牌本身的对象集合以及翻转、排序难以自主实现 | github上选定了一个开源第三方js包,富有一些想要的功能,这也是我选择web端开发的重要原因 |
| 原生js实现起来复杂 | 原生js和js框架Jquery结合使用 |
| 原生js实现动画困难 | 使用CSS3和HTML5动画进行开发 |
| B站UI原型为3D版本,本人技术上没有头绪 | 改成2D版本 |
5. 收获
- HTML、CSS、Javascript啥都能做
- 互联网时代啥都有,在线PS、视频编辑、音频编辑,图像超分、图像修正等,只有你想不到没有它做不到
- 技术上有困难、遇事不决,找Github,啥都有
- 框架越来越简化开发,项目逻辑比技术更重要
二、原型设计实现
1. 前端代码实现思路
项目中有实现由人机对战、AI对战、本地玩家对战四个对局类型,四个对局类型延用一套游戏逻辑
本地玩家对战是原始的模板,人机对战和AI对战在模板上基于编写的后端接口,请求后端服务进行AI对战响应
- 通过HTML进行页面基本布局
- 通过CSS编写动画,添加样式以及设置元素位置信息
- 通过Javascript加载牌堆,编写内部游戏逻辑,编写定时函数以及动画加载
- 通过Python编写AI模型、加载AI模型、后端接口等服务
- 单人项目方便调试调优,进行前后端不分离开发,由后端渲染前端界面响应资源请求
前端开发采用到的开发第三方包:
- deck-of-cards:扑克牌包,拥有初始化一副扑克牌并且设置有几种扑克牌事件,如翻转、扇形、排序、打乱等
- Reflection.js:生成图片倒影,首页的小猪倒影用它来实现
- jPlayer:背景音乐第三方包,通过这个包可以设置web前端音乐或者音效
- Jquery:js框架,简化开发
(1)前端首页
主要部分通过Javascript加载牌堆并进行牌堆出现动画并加载背景音乐
// 首页js代码
$(document).ready(function(){
//初始化系统信息
var $container = document.getElementById('container');
// 初始化牌堆
var deck = Deck();
// 绑定标签
deck.mount($container);
// 牌堆牌面翻转
deck.flip();
// 牌堆出现效果
deck.intro();
// 加载背景音乐,循环执行
background_index();
setInterval(background_index, 154 * 1000);
// 加载背景音乐
function background_index(){
let playerc = $("#jplayer");
if (playerc.data().jPlayer && playerc.data().jPlayer.internal.ready === true) {
playerc.jPlayer("setMedia", {
mp3: "static/static/background_index.mp3"
}).jPlayer("play");//jPlayer("play") 用来自动播放
}else {
playerc.jPlayer({
ready: function() {
$(this).jPlayer("setMedia", {
mp3: "static/static/background_index.mp3" //同上
}).jPlayer("play");//同上
},
swfPath: "static/node_modules/jPlayer/dist/jplayer/jquery.jplayer.swf",
supplied: "mp3"
});
}
}
});
(2)前端本地玩家对战
内部逻辑代码通过Javascript加载牌堆并进行牌堆出现动画并加载背景音乐,CSS负责编写动画内容提供给js代码调用
/*CSS动画资源代码实例,之后大多以此为模板*/
@keyframes body {
0% {
opacity: 0;
transform: scale(1);
background:url(../static/background.png) no-repeat;
width:100%;
height:100%;
background-size:100% 100%;
filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(src='bg-login.png',sizingMethod=scale);
}
100% {
opacity: 1;
transform: scale(1.2);
background:url(../static/background.png) no-repeat;
width:100%;
height:100%;
background-size:100% 100%;
filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(src='bg-login.png',sizingMethod=scale);
}
}
.main{
animation-name: body;
animation-duration: 4s;
animation-fill-mode: forwards;
display: flex;
justify-content: space-between;
}
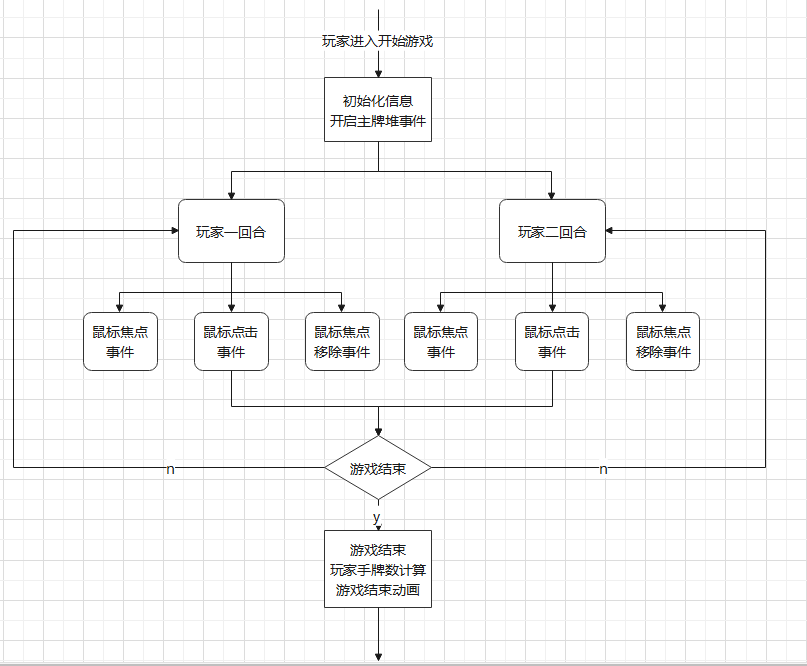
本地玩家对战中核心的代码是玩家的鼠标事件、牌堆的初始化、牌堆与手牌的交互、手牌触发区的交换实现
- 页面加载时,牌堆开始加载并展开成扇形
- 页面首先初始化对局信息,开启对于牌堆的鼠标事件,响应用户的操作,牌堆按使用和未使用分成两部分
- 开始收牌时,进行牌堆和手牌的转化,共有三个牌堆,主牌堆和两个玩家的专属牌堆
// 以下为游戏初始化的信息
// 主牌堆
let deck_container = init("container");
// 两个玩家的专属牌堆
let player1 = null, player2 = null;
// 牌堆乱序并且展开成扇形
deck_container.shuffle();
deck_container.fan();
// 对局信息,记录上一步的信息和当前对局的玩家回合
let record = 0, record_suit = null;
let GAME = 0;
// 主牌堆初始化
function init(label) {
// 获取标签
let $label = document.getElementById(label);
// 绑定标签
let deck = Deck();
deck.mount($label);
return deck
}
// 主牌堆、两个玩家的鼠标事件,三个牌堆的鼠标事件实现类似以玩家一的鼠标事件作为例子
// 玩家鼠标点击事件
function p1_mouseenter(card){
// 鼠标移到牌上将会z轴上升并且变大
let vw = $(window).width();
let origin = card.currentTarget.style.transform;
card.currentTarget.style["z-index"] = parseInt(card.currentTarget.style["z-index"]) + 200;
card.currentTarget.style.transform = origin + "perspective(" + vw * 0.8 + "px) translateZ(" + vw * 0.10 + "px)";
event.stopPropagation()
}
function p1_mouseleave(card){
// 鼠标移出牌上将会z轴下降并且变回原大小
let origin = card.currentTarget.style.transform.split(" ");
origin = origin.slice(0, origin.length - 2).join(" ");
card.currentTarget.style["z-index"] = parseInt(card.currentTarget.style["z-index"]) - 200;
card.currentTarget.style.transform = origin;
event.stopPropagation()
}
let chick_mp1 = 0;
function p1_mousedown(){
// 鼠标点击事件,信号量参数判断是不是可以行动
if(GAME === 1 || chick_mp1 === 1) return;
chick_mp1 = 1;
// 加载点击音效
background_move();
let t = $(this);
// 遍历玩家牌堆,获取到鼠标点击的牌并进行响应的操作
player1.cards.forEach(function (card) {
// 获取到鼠标点击的牌
if (card.$el.className === t.attr("class")) {
card.unmount();
let label = null;
deck_container.cards.forEach(function (c) {
if(c.i === card.i){
label = c;
return false
}
});
// 主牌堆出现一张已使用的牌
label.mount($("#container .deck")[0]);
label.$el.style["z-index"] = parseInt(label.$el.style["z-index"]) + 200;
// 点击事件结束,逻辑判断并加载对应动画,判断是否结束游戏
function f() {
let end = 1;
deck_container.cards.forEach(function (card){
if(card.$el.className === "card") {
end = 0;
return true;
}
if(card.$el.style["z-index"] >= 200){
if(record_suit==null) record_suit = card;
else if(card.i !== record_suit.i && card.suit === record_suit.suit){
// 是否满足收牌条件,进行玩家收牌
if(GAME === 0) player1 = player_one_init("player1");
else player2 = player_one_init("player2");
record_suit = null;
}
// z轴回归,让新打出牌置于久牌顶
else record_suit = card;
card.$el.style["z-index"] = record;
record++;
c_click = 0;
// 下一回合相应的玩家动画
if (GAME === 0 ) {
GAME = 1;
action_add("div.bgImg2.footer.player2");
action_remove("div.bgImg1.header.player1");
}
else {
GAME = 0;
action_remove("div.bgImg2.footer.player2");
action_add("div.bgImg1.header.player1");
}
return false;
}
});
// 游戏结束
if(end === 1) {
$(".end").css("display", "");
let p1 = 0;
// 玩家的手牌计算
player1.cards.forEach(function (card){
if(card.$root != null) p1++;
});
let p2 = 0;
player2.cards.forEach(function (card){
if(card.$root != null) p2++;
});
// 显示玩家手牌数
$("p.text1").text(p1);
$("p.text2").text(p2);
// 跳转回首页
function index() {
window.location.href = "http://127.0.0.1:5000";
}
// 加载结束动画
function s1() {
$(".success1").css("display", "");
$(".photo").css("display", "none");
}
function s2() {
$(".success2").css("display", "");
$(".photo").css("display", "none");
}
// 定时器设定,保持函数有序执行
if(p1>p2) setInterval(s2, 2000);
else if(p1<p2) setInterval(s1, 2000);
setInterval(index, 5000);
return false;
}
chick_mp1 = 0;
}
setTimeout(f, 2000);
return false;
}
});
// 禁止事件向上冒泡
event.stopPropagation();
}
// 触发区鼠标事件
let click_f = 0;
// 加载尾部触发区动画并且进行主牌堆的事件禁止和开启
$("#footer").mousedown(function (){
if(click_f === 0){
// 加载动画
$("#player1").css({
"animation-name": "player1_change_end",
"animation-duration":"2s",
"animation-fill-mode":"forwards"
});
// 禁止主牌堆的事件开启
$("#container .card").off("mouseenter", c_seen);
$("#container .card").off("mouseleave", c_leave);
$("#container .card").off("mouseup", mouseup);
click_f = 1;
}
else if(click_f === 1){
// 加载动画
$("#player1").css({
"animation-name": "player1_change_start",
"animation-duration":"2s",
"animation-fill-mode":"forwards"
});
// 开启主牌堆的事件
click_f = 0;
$("#container .card").on("mouseenter", c_seen);
$("#container .card").on("mouseleave", c_leave);
$("#container .card").on("mouseup", mouseup);
}
});
let click_h = 0;
// 加载头部触发区动画并且进行主牌堆的事件禁止和开启
$("#header").mousedown(function (){
if(click_h === 0){
// 加载动画
$("#player2").css({
"animation-name": "player2_change_end",
"animation-duration":"2s",
"animation-fill-mode":"forwards"
});
// 禁止主牌堆事件
click_h = 1;
$("#container .card").off("mouseenter", c_seen);
$("#container .card").off("mouseleave", c_leave);
$("#container .card").off("mouseup", mouseup);
}
else if(click_h === 1){
// 加载动画
$("#player2").css({
"animation-name": "player2_change_start",
"animation-duration":"2s",
"animation-fill-mode":"forwards"
});
// 开启主牌堆事件
click_h = 0;
$("#container .card").on("mouseenter", c_seen);
$("#container .card").on("mouseleave", c_leave);
$("#container .card").on("mouseup", mouseup);
}
});
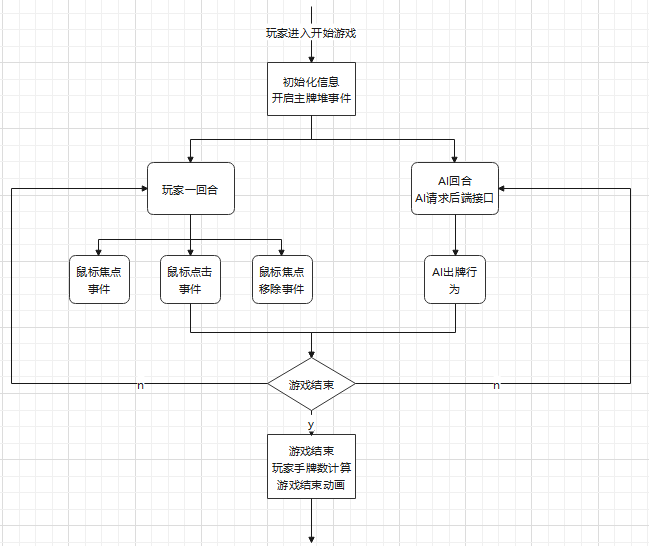
(3)前端人机对战和AI对战
人机对战、AI对战继承了玩家对战的代码模板,添加了前端向后端请求AI接口,处理响应信息并针对AI请求对玩家对战的模板进行了更改
- 前端向后端请求接口,使用了ajax进行请求
- 针对AI操作,取消一个玩家的鼠标事件,改为自动执行函数
// AI行为请求和AI鼠标点击事件函数
function AI_action() {
// 初始化传入请求的字典
let data_dict = {
"pokers_total":0, "pokers_0":0, "pokers_1":0, "pokers_2":0, "pokers_3":0,
"used_total":0, "used_0":0, "used_1":0, "used_2":0, "used_3":0, "used_head":0,
"player_one_total":0, "player_one_0":0, "player_one_1":0, "player_one_2":0, "player_one_3":0,
"player_two_total":0, "player_two_0":0, "player_two_1":0, "player_two_2":0, "player_two_3":0
};
// 计算主牌堆数据
deck_container.cards.forEach(function (card) {
if(card.$el.style["z-index"] >= 200) {
data_dict["used_head"] = card.suit;
}
if(card.$root && card.$el.className === "card"){
data_dict["pokers_total"] += 1;
data_dict["pokers_" + card.suit] += 1;
}
else if(card.$root && card.$el.id === "show"){
data_dict["used_total"] += 1;
data_dict["used_" + card.suit] += 1;
}
});
// 计算玩家一数据
if(player1){
player1.cards.forEach(function (card) {
if(card.$root){
data_dict["player_one_total"] += 1;
data_dict["player_one_" + card.suit] += 1;
}
});
}
// 计算玩家二数据
if(player2){
player2.cards.forEach(function (card) {
if(card.$root){
data_dict["player_two_total"] += 1;
data_dict["player_two_" + card.suit] += 1;
}
});
}
// 进行ajax post请求并传入json数据
$.ajax({
type: 'POST',
url: "http://127.0.0.1:5000/play",
contentType: "application/json",
data: JSON.stringify(data_dict),
success: success,
dataType: "json"
});
// 请求成功回调函数
function success(data, textStatus, jqXHR) {
let action = data["action"];
if(action === 0 || player2 == null || data_dict["player_two_total"] === 0) {
let array = new Array();
// 获取主牌堆位置信息
deck_container.cards.forEach(function (card) {
if(card.$root && card.$el.className === "card"){
array.push(card.pos);
}
});
// 随机选择一个节点
let index = Math.floor(Math.random() * array.length);
let z = deck_container.cards[array[index]].$el;
// 对这个节点进行动画更新
let vw = $(window).width();
let origin = z.style["transform"];
z.style["z-index"] = parseInt(z.style["z-index"]) + 200;
z.style["transform"] = origin + "perspective(" + vw * 0.8 + "px) translateZ(" + vw * 0.10 + "px)";
// 让这个节点执行属于这个节点的鼠标事件
AI_mouseup(z);
}
else{
// 针对请求的数据进行额外处理
if(data_dict["player_two_" + (action - 1)] === 0){
let array = new Array();
player2.cards.forEach(function (card) {
if(card.$root && card.$el.className !== "card"){
array.push(card.pos);
}
});
let index = Math.floor(Math.random() * array.length);
let z = player2.cards[array[index]].$el;
// 执行属于这个节点的点击事件
p2_mousedown(z);
return false;
}
player2.cards.forEach(function (card) {
if(card.$root && card.$el.className !== "card" && card.suit === (action - 1)){
p2_mousedown(card.$el);
return false;
}
});
}
}
}
// AI主动执行的点击事件
function AI_mouseup(t){
background_move();
// 关闭主牌堆事件
$("#container .card").off("mouseenter");
$("#container .card").off("mouseleave");
$("#container .card").off("mouseup");
// z节点牌翻面
deck_container.cards.forEach(function (card){
if(card.$el.style["z-index"] === t.style["z-index"]){
card.setSide('front');
}
});
t.id = "show";
function f() {
let end = 1;
deck_container.cards.forEach(function (card){
if(card.$el.className === "card") {
end = 0;
return true;
}
// 获取已使用的牌顶牌,并进行判断
if(card.$el.style["z-index"] >= 200){
if(record_suit==null) record_suit = card;
else if(card.i !== record_suit.i && card.suit === record_suit.suit){
// 进行牌堆和玩家手牌的初始化
if(GAME === 0) player1 = player_one_init("player1");
else player2 = player_one_init("player2");
record_suit = null;
}
// 让新牌置于牌堆顶
else record_suit = card;
card.$el.style["z-index"] = record;
record++;
return false;
}
});
// 结束动画
if(end === 1) {
$(".end").css("display", "");
let p1 = 0;
player1.cards.forEach(function (card){
if(card.$root) p1++;
});
let p2 = 0;
player2.cards.forEach(function (card){
if(card.$root) p2++;
});
$("p.text1").text(p1);
$("p.text2").text(p2);
function index() {
window.location.href = "index.html";
}
function s1() {
$(".success1").css("display", "");
$(".photo").css("display", "none");
}
function s2() {
$(".success2").css("display", "");
$(".photo").css("display", "none");
}
background_get_success();
if(p1>p2) setInterval(s2, 2000);
else if(p1<p2) setInterval(s1, 2000);
setInterval(index, 5000);
return;
}
c_click = 0;
if (GAME === 0 ) {
GAME = 1;
action_add("div.bgImg2.footer.player2");
action_remove("div.bgImg1.header.player1");
}
else {
GAME = 0;
action_remove("div.bgImg2.footer.player2");
action_add("div.bgImg1.header.player1");
}
// 开启主牌堆事件
$("#container .card").on("mouseenter", c_seen);
$("#container .card").on("mouseleave", c_leave);
$("#container .card").on("mouseup", mouseup);
}
setTimeout(f, 2000);
}
2. 后端代码实现思路
后端代码包括AI模型开发、Web前端渲染、后端接口等,后端开发采用Python的Flask框架,AI开发采用Pytorch框架,以下为使用的主要使用的第三方包
- Flask:Python的Web后端框架,简单快捷方便
- Pytorch:深度学习框架,同样简单快捷高效
- Transformers:Hugging Face开发的自然语言处理框架,简化自然语言模型开发
- Pandas:Python的一个数据分析包,处理数据很方便
- Flask-Socketio:flask集成socket长连接功能
(1)后端AI实现
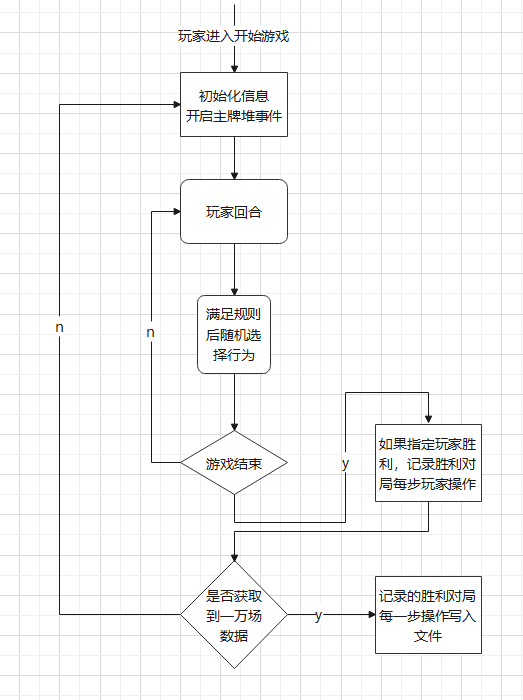
AI实现思路:
- 编写猪尾巴游戏的游戏逻辑,使用随机数参与游戏选择,记录下每局胜利玩家的对局数据,用作AI训练
- 为了方便,我指定只获取玩家一胜利时候的对局数据
- 重复获取了一万场胜利场数,总共获取到六十多万对局决策数据
class Record:
"""
数据生成过程中的记录类,运行过程中记录下胜利场数中玩家的每一步操作
"""
def __init__(self):
"""
初始数据定义
"""
self.data = pd.DataFrame(columns=["pokers_total", "pokers_0", "pokers_1", "pokers_2", "pokers_3",
"used_total", "used_0", "used_1", "used_2", "used_3", "used_head",
"player_one_total", "player_one_0", "player_one_1", "player_one_2",
"player_one_3",
"player_two_total", "player_two_0", "player_two_1", "player_two_2",
"player_two_3",
"label", "number"])
def transform(self, pokers, used, pokers_one, pokers_two, label):
"""
将输入数据转换为记录
:param pokers: 主体扑克牌集合
:param used: 被使用但没有被玩家收集的扑克牌集合
:param pokers_one:玩家一的手牌集合
:param pokers_two:玩家二的手牌集合
:param label:玩家的选择,出手牌或者翻牌堆
"""
self.data = self.data.append({
"pokers_total": self.get_poker_len(pokers),
"pokers_0": pokers["0"],
"pokers_1": pokers["1"],
"pokers_2": pokers["2"],
"pokers_3": pokers["3"],
"used_total": self.get_poker_len(used),
"used_0": used["0"],
"used_1": used["1"],
"used_2": used["2"],
"used_3": used["3"],
"used_head": used["head"],
"player_one_total": self.get_poker_len(pokers_one),
"player_one_0": pokers_one["0"],
"player_one_1": pokers_one["1"],
"player_one_2": pokers_one["2"],
"player_one_3": pokers_one["3"],
"player_two_total": self.get_poker_len(pokers_two),
"player_two_0": pokers_two["0"],
"player_two_1": pokers_two["1"],
"player_two_2": pokers_two["2"],
"player_two_3": pokers_two["3"],
"label": label
}, ignore_index=True)
self.data["number"] = self.data["pokers_total"] + self.data["used_total"] \
+ self.data["player_one_total"] + self.data["player_two_total"]
def to_csv(self):
"""
重复行删除,nan行填充,写入文件
:return:
"""
self.data = self.data.drop_duplicates()
self.data = self.data.fillna(0)
self.data.to_csv("data.csv", index=False)
def get_poker_len(self, poker):
"""
返回输入的扑克牌集合的牌数
:param poker:输入的扑克牌集合
:return: 扑克牌的有效数量
"""
len = 0
for k, v in poker.items():
if k == 'head':
continue
len += v
return len
class Game:
"""
游戏对局类,通过随机模拟出真实对局的情况
"""
def __init__(self, recode_csv):
"""
初始化参数
:param recode_csv:输入的记录类实例
"""
# 主体牌堆
self.pokers = {"0": 13, "1": 13, "2": 13, "3": 13}
# 已使用牌堆
self.used = {"0": 0, "1": 0, "2": 0, "3": 0, "head": None}
# 玩家一手牌
self.player_one_pokers = {"0": 0, "1": 0, "2": 0, "3": 0}
# 玩家二手牌
self.player_two_pokers = {"0": 0, "1": 0, "2": 0, "3": 0}
# 玩家回合
self.LEADER = 0
# 对局记录
self.recode = []
# 全局胜利对局记录
self.csv_recode = recode_csv
def start(self):
"""
游戏开始类
:return:返回游戏局是否是设置玩家胜利
"""
while True:
# 游戏结束判断
if self.game_over():
# 是否是指定玩家胜利
if self.get_poker_len(self.player_one_pokers) >= self.get_poker_len(self.player_two_pokers):
return 0
# 写入记录类
for r in self.recode:
self.csv_recode.transform(r[0], r[1], r[2], r[3], r[4])
return 1
# 游戏主体过程
self.select()
def record_list(self, label):
"""
通过深拷贝复制对象,写入记录类实例
:param label: 玩家操作,出手牌或者翻牌堆
"""
self.recode.append((copy.deepcopy(self.pokers),
copy.deepcopy(self.used),
copy.deepcopy(self.player_one_pokers),
copy.deepcopy(self.player_two_pokers),
label))
def select(self):
"""
玩家主体游戏过程
"""
# 判断是否有能力出手牌,没有就翻牌堆
if self.LEADER == 0 and self.get_poker_len(self.player_one_pokers) == 0:
self.record_list(0)
self.select_poker(self.pokers)
return
elif self.LEADER == 1 and self.get_poker_len(self.player_two_pokers) == 0:
self.select_poker(self.pokers)
return
random.seed(int(round(time.time() * 1000000)))
domain = random.randint(0, 1)
# 随机过程模拟用户是出手牌还是翻牌堆
if domain == 0:
self.record_list(0)
self.select_poker(self.pokers)
elif self.LEADER == 0:
self.select_poker(self.player_one_pokers, 1)
elif self.LEADER == 1:
self.select_poker(self.player_two_pokers)
def select_poker(self, pokers, main=0):
"""
从输入的扑克牌集合中按照规则随机收取牌
:param pokers: 输入的扑克牌集合
:param main: 是否是指定玩家出手牌
"""
# 随机从扑克牌集合出牌
while True:
random.seed(int(round(time.time() * 1000000)))
index = random.randint(0, 3)
if pokers[str(index)] == 0:
return 0
if main == 1 and self.LEADER == 0:
# 是指定玩家出手牌,记录
self.record_list(index + 1)
# 更新牌堆首牌信息
pre_head = self.used["head"]
pokers[str(index)] -= 1
# 更新已使用牌堆信息
self.enter_used(str(index))
break
if (index + 1) == pre_head:
# 出牌与过去的牌堆首牌同花色,玩家收牌
self.collect_card()
if self.LEADER == 0:
self.LEADER = 1
elif self.LEADER == 1:
self.LEADER = 0
return 1
def game_over(self):
"""
游戏结束
:return: 是否游戏结束
"""
# 获取主体牌堆有效牌数
poker_len = self.get_poker_len(self.pokers)
# 牌堆无牌则游戏结束
if poker_len <= 0:
return True
return False
def enter_used(self, index):
"""
更新已使用牌堆信息
:param index: 花色编号
"""
self.used[index] += 1
self.used["head"] = int(index) + 1
def clean_used(self):
"""
清空已使用牌堆
"""
self.used = {"0": 0, "1": 0, "2": 0, "3": 0, "head": None}
def collect_card(self):
"""
玩家收牌
"""
if self.LEADER == 0:
play = self.player_one_pokers
else:
play = self.player_two_pokers
# 玩家手牌加入已使用牌堆所有牌
for k, v in self.used.items():
if k == "head":
continue
play[k] += v
self.clean_used()
def get_poker_len(self, poker):
"""
获取输入牌堆有效牌数
:param poker: 输入牌堆
:return: 牌堆有效牌数
"""
len = 0
for k, v in poker.items():
len += v
return len
if __name__ == "__main__":
csv_recode = Record()
total_num = 0
# 获取一万条胜利数据
while True:
game = Game(csv_recode)
total_num += game.start()
if total_num > 1e4:
break
csv_recode.to_csv()
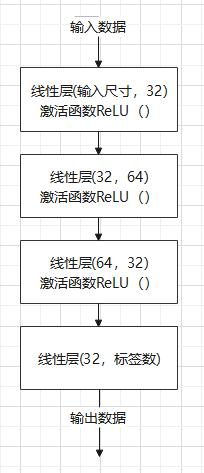
- 编写AI模型,AI模型我采用一种简单的神经网络模型,并针对模型的层数和参数进行测试,最终使用了一个四层的神经网络模型
class MyModel(nn.Module):
"""
简单神经网络模型
"""
def __init__(self, input_size, num_labels, device):
"""
模型初始化
:param input_size:输入尺寸
:param num_labels: 输出标签数
:param device: 在哪种设备运行
"""
super(MyModel, self).__init__()
self.device = device
# 交叉熵损失函数
self.criterion = nn.CrossEntropyLoss()
# 网络模型
self.start = nn.Sequential(
nn.Linear(input_size, 32),
nn.ReLU(),
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, num_labels)
)
def forward(self, data, label=None):
"""
模型执行函数
:param data:输入数据
:param label: 数据对应的标签,None就是测试节点
:return: 损失和标签预测分数 或 标签预测分数
"""
probabilities = self.start(data)
if label is not None:
loss = self.criterion(probabilities, label)
return loss, probabilities
return probabilities
- 编写训练代码,设置优化算法、参数等信息,保存训练结果
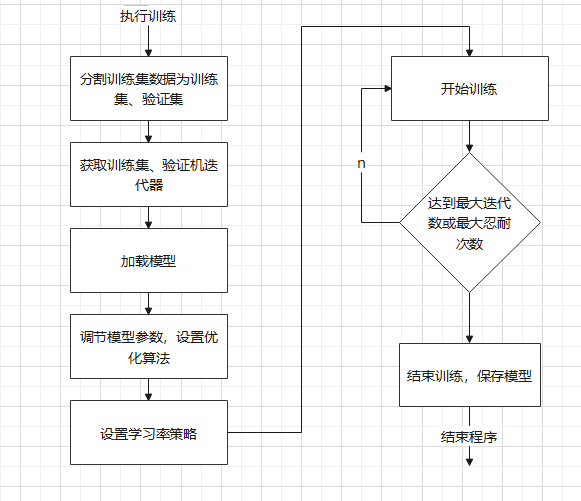
def main(train_file, target_dir,
input_size=21,
num_labels=5,
epochs=100,
batch_size=512,
lr=2e-03,
patience=10,
max_grad_norm=10.0,
checkpoint=None):
"""
训练函数
:param train_file: 训练数据集文件
:param target_dir: 输出文件目录
:param input_size: 出入尺寸
:param num_labels: 输出标签数
:param epochs: 执行迭代数
:param batch_size: 输入数据批量大小
:param lr: 学习率
:param patience: 忍耐次数,达到忍耐次数退出循环
:param max_grad_norm: 参数裁剪力度
:param checkpoint: 模型参数检查点路径
"""
device = torch.device("cuda")
print(20 * "=", "准备训练 ", 20 * "=")
# 保存模型的路径
if not os.path.exists(target_dir):
os.makedirs(target_dir)
# -------------------- 数据加载 ------------------- #
print("\t* 开始分割数据集...")
word_train, word_dev, label_train, label_dev = load_dev("train", train_file)
print("\t* 加载训练数据...")
train_data = DataPrecessForSentence(word_train, label_train)
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)
print("\t* 加载验证数据...")
dev_data = DataPrecessForSentence(word_dev, label_dev)
dev_loader = DataLoader(dev_data, shuffle=False, batch_size=batch_size)
# -------------------- 模型定义 ------------------- #
print("\t* 建立模型 分类:{}".format(num_labels))
model = MyModel(input_size=input_size, num_labels=num_labels, device=device).to(device)
# -------------------- 预训练 ------------------- #
# 待优化的参数
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{
'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay': 0.01
},
{
'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay': 0.0
}
]
# 设置优化函数AdamW
optimizer = AdamW(optimizer_grouped_parameters, lr=lr)
# 设置学习率策略
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode="max",
factor=0.85, patience=0)
best_score = 0.0
start_epoch = 1
# 损失曲线绘制的数据
epochs_count = []
train_losses = []
valid_losses = []
# 如果将一个检查点作为参数,则从检查点继续训练
if checkpoint:
checkpoint = torch.load(checkpoint)
start_epoch = checkpoint["epoch"] + 1
best_score = checkpoint["best_score"]
print("\t* 训练将继续在 epoch 的现有模型上进行 {}...".format(start_epoch))
model.load_state_dict(checkpoint["model"])
optimizer.load_state_dict(checkpoint["optimizer"])
epochs_count = checkpoint["epochs_count"]
train_losses = checkpoint["train_losses"]
valid_losses = checkpoint["valid_losses"]
# 在开始(或恢复)训练之前计算损失和准确度
_, valid_loss, valid_accuracy = validate(model, dev_loader)
print("\t* 训练之前的验证集loss: {:.4f}, accuracy: {:.4f}%".format(valid_loss, (valid_accuracy * 100)))
# -------------------- 训练迭代 ------------------- #
print("\n", 20 * "=", "训练模型时设备: {}".format(device), 20 * "=")
patience_counter = 0
for epoch in range(start_epoch, epochs + 1):
epochs_count.append(epoch)
print("* 训练epoch {}:".format(epoch))
epoch_time, epoch_loss, epoch_accuracy = train(model, train_loader, optimizer, max_grad_norm)
train_losses.append(epoch_loss)
print("-> 训练time: {:.4f}s, loss = {:.4f}, accuracy: {:.4f}%"
.format(epoch_time, epoch_loss, (epoch_accuracy * 100)))
print("* 验证epoch {}:".format(epoch))
epoch_time, epoch_loss, epoch_accuracy = validate(model, dev_loader)
valid_losses.append(epoch_loss)
print("-> 验证time: {:.4f}s, loss: {:.4f}, accuracy: {:.4f}%\n"
.format(epoch_time, epoch_loss, (epoch_accuracy * 100)))
# 使用调度器更新优化器的学习率
scheduler.step(epoch_accuracy)
# 早期验证精度上停止
if epoch_accuracy < best_score:
patience_counter += 1
else:
best_score = epoch_accuracy
patience_counter = 0
torch.save({"epoch": epoch,
"model": model.state_dict(),
"best_score": best_score,
"optimizer": optimizer.state_dict(),
"epochs_count": epochs_count,
"train_losses": train_losses,
"valid_losses": valid_losses},
os.path.join(target_dir, "best.pth.tar"))
if patience_counter >= patience:
print("-> 提前停止:达到限制极限,停止...")
break
最后出现的问题是用户不出牌的标签占了全部标签的60%以上,导致训练的结构过拟合偏向不出牌,我重新拆分了数据集使得每一个分类都平衡在5.3万数据,因此更新后总数据量为26.3万,最终训练结果为接近30%的正确率

(2)后端接口实现
后端接口包括两个部分,此部分使用Flask开发:
- 前后端不分离开发,因此存在一个渲染前端项目的接口
- 请求AI服务接口
- websocket服务接口,用于在线对战,不过在线对战停工了
app = Flask(__name__)
# 允许跨域
cors = CORS(app)
# 允许socket
socket = SocketIO(app, cors_allowed_origins="*")
# 加载模型
model = load_model("models/best.pth.tar")
# 因为python的特性,所有这个a是线程安全的
client = 0
@socket.on('connect', namespace='/game')
def connect():
"""
socket连接函数,连接大于两个就会自动断开新连接
"""
global client
if client > 2:
socket.emit("disconnect")
print("进入连接")
@socket.on('join', namespace='/game')
def join(data):
"""
响应客户端的加入房间请求
:param data: 请求数据
"""
global client
# 抽取出房间号
room = data["room"]
join_room(room)
# 客户端数+1
client += 1
if client == 2:
# 发送初始化信息到客户端
socket.emit("init", 1, namespace="/game")
# 发送开始对局信息到客户端
socket.emit("start", broadcast=True, room=room, namespace="/game")
else:
# 发送初始化信息到客户端
socket.emit("init", 0, namespace="/game")
@socket.on('disconnect', namespace='/game')
def disconnect():
"""
客户端连接断开
"""
# 客户端-1
global client
client -= 1
@app.route("/", methods=["GET"])
def index():
"""
渲染HTML主页
"""
return render_template("index.html")
@app.route("/play", methods=["POST"])
def play():
"""
接收AI玩家的操作请求
"""
# 处理传入的数据
dict_json = request.data
json_dict = json.loads(dict_json)
# 使用模型得到数据并且返回处理信息
result = use_model(model=model, json_dict=json_dict)
return jsonify({"action": result})
对于AI接口,封装了将浏览器请求信息转化成模型可输入信息的过程,相关代码如下:
def load_model(checkpoint_file,
input_size=21,
num_labels=5,
device="cpu"):
"""
加载模型
:param checkpoint_file: 模型参数检查点路径
:param input_size: 输入尺寸
:param num_labels: 输出标签数
:param device: 使用设备
:return: 加载参数后的可用模型
"""
model = MyModel(input_size=input_size, num_labels=num_labels, device=device).to(device)
checkpoint = torch.load(checkpoint_file, map_location=device)
model.load_state_dict(checkpoint["model"])
return model
def use_model(model, json_dict):
"""
使用模型进行预测
:param model: 输入可用的模型
:param json_dict: 输入的字典数据
:return:
"""
# 字典数据转化为列表
data_list = json_transform_data(json_dict)
# 转化为模型可用数据并输入模型
data = torch.tensor(data_list, dtype=torch.float32).reshape(1, -1)
output = model(data).argmax(dim=1).item()
if output != 0 and json_dict["player_one_" + str(output - 1)] == 0:
return 0
return output
def json_transform_data(data):
"""
将输入的字典信息转为列表数据
:param data: 输入的字典
:return: 可用列表数据
"""
data_list = [
data["pokers_total"],
data["pokers_0"],
data["pokers_1"],
data["pokers_2"],
data["pokers_3"],
data["used_total"],
data["used_0"],
data["used_1"],
data["used_2"],
data["used_3"],
data["used_head"],
data["player_one_total"],
data["player_one_0"],
data["player_one_1"],
data["player_one_2"],
data["player_one_3"],
data["player_two_total"],
data["player_two_0"],
data["player_two_1"],
data["player_two_2"],
data["player_two_3"]
]
return data_list
(3)后端在线AI实现
在线AI对战通过Python的requests包进行远程接口请求,通过本次作业提供的API实现了在线AI对战,不过在和室友的对局中发现,通过随机获取到的数据,既是数据量很大但仍然没有好效果,因此编写了实时模型训练微调的功能。
在每一场对局的结束,会将胜利玩家的对局数据写入本地CSV文件中,用于训练微调
def login(student_id, password):
"""
用户登录接口
:param student_id:学号
:param password: 密码
:return: token
"""
data = {"student_id": student_id, "password": password}
result = requests.post(url="http://172.17.173.97:8080/api/user/login", data=data)
output = json.loads(result.content)
if result.status_code == 200 and output["status"] == 200:
print("登录成功")
else:
print("登录失败")
return output["data"]["token"]
def create_root(token, private=True):
"""
创建房间
:param token: 登录签名
:param private: 是否公开
:return: 房间id
"""
data = {"private": private}
header = {"Authorization": "Bearer " + token}
result = requests.post(url="http://172.17.173.97:9000/api/game", data=data, headers=header)
output = json.loads(result.content)
if result.status_code == 200 and output["code"] == 200:
print("创建房间成功,房间号{}".format(output["data"]["uuid"]))
else:
print("创建房间失败")
return output["data"]["uuid"]
def join_root(token, room_id):
"""
加入房间
:param token: 用户签名
:param room_id: 房间id
:return: 是否加入房间成功
"""
header = {"Authorization": "Bearer " + token}
result = requests.post(url="http://172.17.173.97:9000/api/game/" + room_id, headers=header)
output = json.loads(result.content)
if result.status_code == 200 and output["code"] == 200:
print("加入房间成功")
return True
print("加入房间失败")
return False
def emit_action(token, room_id, type, card=None):
"""
提交用户的操作到服务器
:param token: 用户签名
:param room_id: 房间id
:param type: 抽牌或出手牌
:param card: 卡牌名
:return: 打牌字符串或者布尔值
"""
header = {"Authorization": "Bearer " + token}
data = None
if type == 0:
data = {"type": type}
elif type == 1 and card is not None:
data = {"type": type, "card": card}
else:
print({"type": type, "card": card}, "出现错误")
result = requests.put(url="http://172.17.173.97:9000/api/game/" + room_id, data=data, headers=header)
output = json.loads(result.content)
if result.status_code == 200 and output["code"] == 200:
last_code = output["data"]["last_code"].split(" ")
return last_code
print("[错误]:", output)
return False
def get_last(token, room_id):
"""
获取上一步
:param token: 用户签名
:param room_id: 房间id
:return: 上一步操作接口的信息
"""
header = {"Authorization": "Bearer " + token}
while True:
result = requests.get(url="http://172.17.173.97:9000/api/game/{}/last".format(room_id), headers=header)
output = json.loads(result.content)
if result.status_code == 200 and output["code"] == 200:
last_code = output["data"]["last_code"].split(" ")
your_true = output["data"]["your_turn"]
last_msg = output["data"]["last_msg"]
return last_code, your_true, last_msg
elif output["code"] == 403:
print(output["data"]["err_msg"])
time.sleep(1)
continue
elif output["code"] == 400:
print(output["data"]["err_msg"])
winner(token, room_id)
return None, None, None
def handle_response(response, player, used):
"""
控制牌堆的变化,包括清空、增加、收牌
:param response: 接口的返回信息
:param player: 玩家的手牌
:param used: 已使用的牌堆
"""
head = {"S":1, "H":2, "C":3, "D":4}
if response[1] == "1":
player[response[2][0]].remove(response[2])
used[response[2][0]].append(response[2])
if used["head"] == 0:
used["head"] = head[response[2][0]]
elif used["head"] == head[response[2][0]]:
for k, v in player.items():
player[k].extend(used[k])
used[k] = []
used["head"] = 0
else:
used["head"] = head[response[2][0]]
def get_poker_len(poker):
"""
返回输入的扑克牌集合的牌数
:param poker:输入的扑克牌集合
:return: 扑克牌的有效数量
"""
length = 0
for k, v in poker.items():
if k == 'head':
continue
length += len(v)
return length
def transform_use_model(used, player_one, player_two, model, csv_one, csv_two, r):
"""
将输入转化为可以被模型接收的输入
:param used: 已使用的牌堆
:param player_one: 玩家一的手牌
:param player_two: 玩家二的手牌
:param model: AI模型
:param csv_one: 玩家一代表的CSV文件,用户对战结束记录胜利一方的数据进行实时训练
:param csv_two: 玩家二代表的CSV文件,用户对战结束记录胜利一方的数据进行实时训练
:param r: 代表玩家一回合还是玩家二回合
:return: type和card
"""
data = {
"pokers_total": 52 - get_poker_len(used) - get_poker_len(player_one) - get_poker_len(player_two),
"pokers_0": 13 - len(used["S"]) - len(player_one["S"]) - len(player_two["S"]),
"pokers_1": 13 - len(used["H"]) - len(player_one["H"]) - len(player_two["H"]),
"pokers_2": 13 - len(used["C"]) - len(player_one["C"]) - len(player_two["C"]),
"pokers_3": 13 - len(used["D"]) - len(player_one["D"]) - len(player_two["D"]),
"used_total": get_poker_len(used),
"used_0": len(used["S"]),
"used_1": len(used["H"]),
"used_2": len(used["C"]),
"used_3": len(used["D"]),
"used_head": used["head"],
"player_one_total": get_poker_len(player_one),
"player_one_0": len(player_one["S"]),
"player_one_1": len(player_one["H"]),
"player_one_2": len(player_one["C"]),
"player_one_3": len(player_one["D"]),
"player_two_total": get_poker_len(player_two),
"player_two_0": len(player_two["S"]),
"player_two_1": len(player_two["H"]),
"player_two_2": len(player_two["C"]),
"player_two_3": len(player_two["D"])
}
action = use_model(model, data)
data["label"] = action
if r == 1:
csv_one.data = csv_one.data.append(data, ignore_index=True)
else:
csv_two.data = csv_two.data.append(data, ignore_index=True)
init = ["S", "H", "C", "D"]
head = {"S": 1, "H": 2, "C": 3, "D": 4}
if action != 0:
label = init[action - 1]
if len(player_one[label]) == 0 and get_poker_len(player_one) != 0:
for k, v in player_one.items():
if len(v) != 0 and head[k] != used["head"]:
element = random.choice(v)
return 1, element
return 0, None
elif action != used["head"]:
v = player_one[label]
element = random.choice(v)
return 1, element
return 0, None
else:
return 0, None
def winner(token, room_id):
"""
获取胜利者接口
:param token: 用户签名
:param room_id: 房间id
:return: 胜利者
"""
header = {"Authorization": "Bearer " + token}
result = requests.get(url="http://172.17.173.97:9000/api/game/{}".format(room_id), headers=header)
output = json.loads(result.content)
if result.status_code == 200 and output["code"] == 200:
win = output["data"]["winner"]
if win == 0:
print("1P胜利了!")
else:
print("2P胜利了!")
return win
else:
print("未知错误")
def run(token, room_id, used, player_one, player_two, model, csv_one, csv_two):
"""
游戏执行程序
:param token: 用户签名
:param room_id: 房间id
:param used: 已使用的牌堆
:param player_one: 玩家一的牌堆
:param player_two: 玩家二的牌堆
:param model: AI模型
:param csv_one: 玩家一对应的CSV文件
:param csv_two: 玩家二对应的CSV文件
"""
# 循环直到游戏结束
while True:
pre_response = None
r = None
# 循环请求上一步的接口,等待另一个玩家完成操作
while True:
response, your_true, last_msg = get_last(token, room_id)
# 游戏结束返回
if response is None and your_true is None and last_msg is None:
return
# 游戏刚开始如果是自己的回合就跳出,不是就下一次循环
if len(response) == 1 and your_true:
break
elif len(response) == 1 and not your_true:
continue
# 作用是多次循环同样的请求时,只有第一次请求会更新所有的牌堆
if response[2] == pre_response:
continue
if pre_response is None:
pre_response = response[2]
# 更新对应玩家的牌堆,是自己的回合就跳出,不是就下一次循环
if your_true:
print(last_msg)
r = 0
handle_response(response, player_two, used)
break
elif not your_true:
print(last_msg)
r = 1
handle_response(response, player_one, used)
# 通过模型转化为type和card
type, card = transform_use_model(used, player_one, player_two, model, csv_one, csv_two, r)
# 执行自己的操作请求
response = emit_action(token, room_id, type=type, card=card)
# 游戏结束,跳出循环
if not response:
print("游戏结束,退出")
break
def to_csv(csv):
"""
将玩家对应的CSV内容写入文件中
:param csv: 玩家的CSV文件内存
"""
# 读取总数据集
data = pd.read_csv("../data/play.csv")
# 链接数据集
data = pd.concat([data, csv], axis=0)
# 丢弃重复行
data = data.drop_duplicates()
# nan填充为0
data = data.fillna(0)
# 重新写入文件
data.to_csv("../data/play.csv", index=False)
if __name__ == "__main__":
student_id = input("请输入你的学号:")
password = input("请输入你的密码:")
# 玩家一牌堆
player_one = {"S": [], "H": [], "C": [], "D": []}
# 玩家二牌堆
player_two = {"S": [], "H": [], "C": [], "D": []}
# 已使用的牌堆
used = {"S": [], "H": [], "C": [], "D": [], "head": 0}
# 加载模型
model = load_model("../models/origin.tar")
# 初始化CSV记录类
csv_one = Record()
csv_two = Record()
# 登录
token = login(student_id, password)
# 创建房间
room_id = create_root(token)
# 执行游戏
run(token, room_id, used, player_one, player_two, model, csv_one, csv_two)
# 获取胜利结果
win = winner(token, room_id)
# 根据胜利结果,将胜利玩家的每步操作写入数据集
if win == 0:
to_csv(csv_one.data)
else:
to_csv(csv_two.data)
# 进行微调
main("../data/play.csv", "../models", checkpoint="../models/origin.tar", epochs=1)
3. 性能分析
因为前端使用HTML、CSS、JavaScript编写没有找到相关的性能分析工具或者测试工具,选择前后端不分离开发,因此这次的性能分析主要分析后端方面,后端方面性能既是包括了渲染前端页面、响应前端资源以及响应AI请求等功能
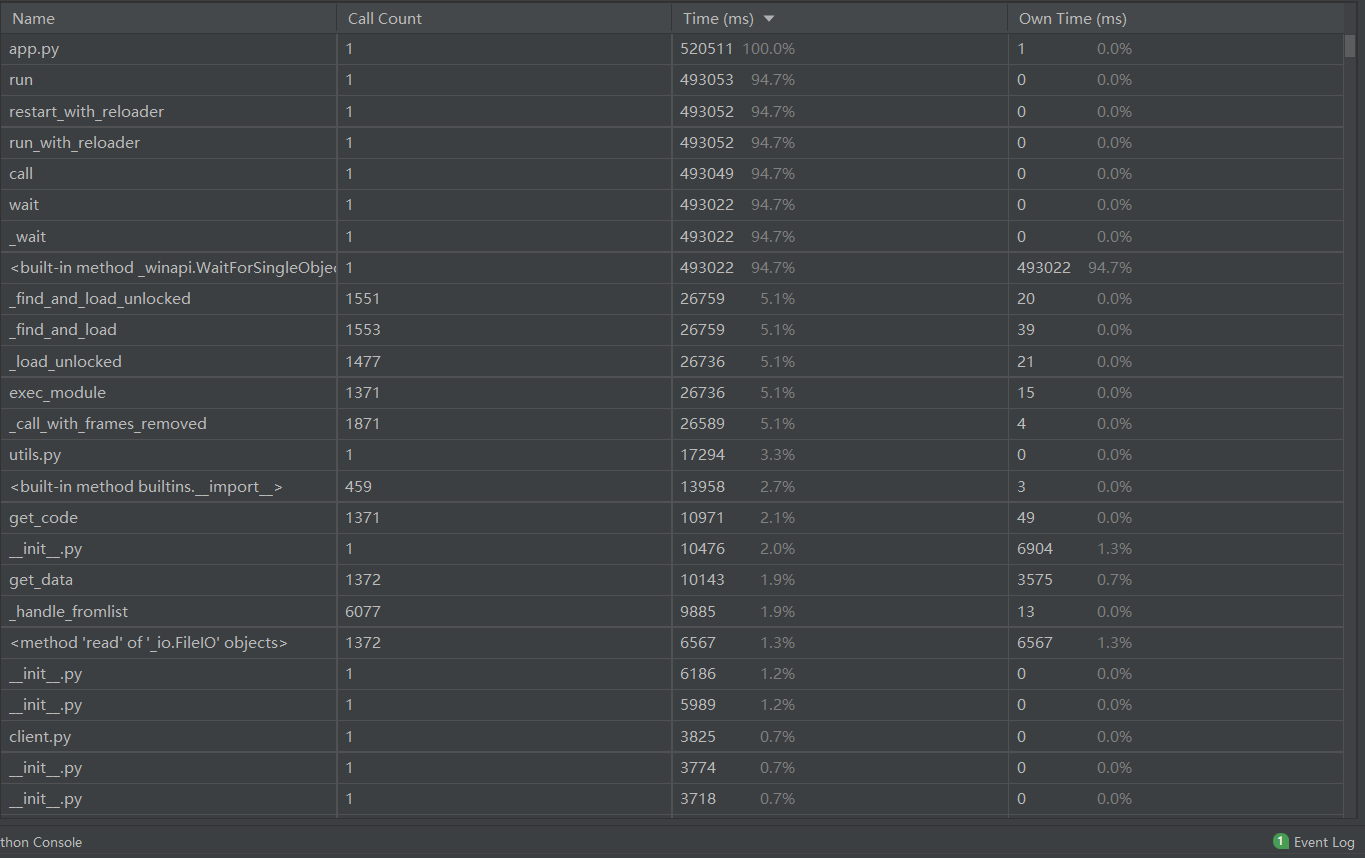
选择使用了在线AI对战游戏类型,让两个AI进行对战直至游戏结束,获取整个游戏从开始到结束的性能分析
(1)性能分析图
(2)性能分析
由图分析,性能影响主要在请求和响应服务,项目中其他函数没有明显影响性能,分析大概会影响性能的原因
- 前端后端不分离,前端请求资源,有些资源过大导致响应缓慢,可以考虑使用较小的资源或者调低资源的质量
- 性能中使用有很多wait等待函数,猜想可能和前端有使用大量的定时器有关
- 其他方面无明显影响性能,本次主要的AI模型采用简单神经网络,模型很小,参数比较少因此响应也比较快
4. 单元测试
因为Web前端用原生语言编写,不能像Python、JAVA一样运行,暂时没有找到测试前端的工具,因此本次编写针对后端AI接口的单元测试
通过获取程序运行时多次请求的输入值以及响应的输出值作为单元测试的原始数据,单元测试时将原始数据输入模型得到目标输出,判断目标输出是否与原始输出相同,测试模型是否还稳定
from AI.utils import use_model, load_model
def test_model():
"""
针对AI接口的单元测试,测试模型是否还稳定
"""
json_dict = [
{'pokers_total': 51, 'pokers_0': 12, 'pokers_1': 13, 'pokers_2': 13, 'pokers_3': 13, 'used_total': 1,
'used_0': 1, 'used_1': 0, 'used_2': 0, 'used_3': 0, 'used_head': 0, 'player_one_total': 0, 'player_one_0': 0,
'player_one_1': 0, 'player_one_2': 0, 'player_one_3': 0, 'player_two_total': 0, 'player_two_0': 0,
'player_two_1': 0, 'player_two_2': 0, 'player_two_3': 0},
{'pokers_total': 50, 'pokers_0': 11, 'pokers_1': 13, 'pokers_2': 13, 'pokers_3': 13, 'used_total': 0,
'used_0': 0, 'used_1': 0, 'used_2': 0, 'used_3': 0, 'used_head': 0, 'player_one_total': 0, 'player_one_0': 0,
'player_one_1': 0, 'player_one_2': 0, 'player_one_3': 0, 'player_two_total': 2, 'player_two_0': 2,
'player_two_1': 0, 'player_two_2': 0, 'player_two_3': 0},
{'pokers_total': 49, 'pokers_0': 10, 'pokers_1': 13, 'pokers_2': 13, 'pokers_3': 13, 'used_total': 1,
'used_0': 1, 'used_1': 0, 'used_2': 0, 'used_3': 0, 'used_head': 0, 'player_one_total': 0, 'player_one_0': 0,
'player_one_1': 0, 'player_one_2': 0, 'player_one_3': 0, 'player_two_total': 2, 'player_two_0': 2,
'player_two_1': 0, 'player_two_2': 0, 'player_two_3': 0},
{'pokers_total': 41, 'pokers_0': 8, 'pokers_1': 12, 'pokers_2': 10, 'pokers_3': 11, 'used_total': 0,
'used_0': 0, 'used_1': 0, 'used_2': 0, 'used_3': 0, 'used_head': 0, 'player_one_total': 11, 'player_one_0': 5,
'player_one_1': 1, 'player_one_2': 3, 'player_one_3': 2, 'player_two_total': 2, 'player_two_0': 2,
'player_two_1': 0, 'player_two_2': 0, 'player_two_3': 0},
{'pokers_total': 41, 'pokers_0': 8, 'pokers_1': 12, 'pokers_2': 10, 'pokers_3': 11, 'used_total': 1,
'used_0': 1, 'used_1': 0, 'used_2': 0, 'used_3': 0, 'used_head': 0, 'player_one_total': 11, 'player_one_0': 5,
'player_one_1': 1, 'player_one_2': 3, 'player_one_3': 2, 'player_two_total': 1, 'player_two_0': 1,
'player_two_1': 0, 'player_two_2': 0, 'player_two_3': 0},
{'pokers_total': 41, 'pokers_0': 8, 'pokers_1': 12, 'pokers_2': 10, 'pokers_3': 11, 'used_total': 1,
'used_0': 1, 'used_1': 0, 'used_2': 0, 'used_3': 0, 'used_head': 0, 'player_one_total': 10, 'player_one_0': 4,
'player_one_1': 1, 'player_one_2': 3, 'player_one_3': 2, 'player_two_total': 1, 'player_two_0': 1,
'player_two_1': 0, 'player_two_2': 0, 'player_two_3': 0}
]
origin = [
{'action': 0},
{'action': 0},
{'action': 0},
{'action': 1},
{'action': 1},
{'action': 1}
]
# 加载模型
model = load_model("../models/best.pth.tar")
for index in range(len(json_dict)):
result = use_model(model=model, json_dict=json_dict[index])
# 判断模型输出是否符合原模型输出
assert result == origin[index]["action"]
本次单元测试的覆盖率如下,因为只是针对AI接口的单元测试,所以训练时的代码并没有被覆盖,前端方面的内容同样也没有被覆盖

5. Github代码签入记录
6. 困难及解决方法
| 问题 | 解决方案 |
|---|---|
| 前端扑克牌乱序后之前写的按编号处理失效 | 重新选择一个指标作为新的编号进行处理 |
| 原生js编写动画困难 | 使用CSS进行动画编写,js调用CSS动画 |
| 前端代码中定时器太多,出现类似死锁、读写冲突等情况 | 通过设置类似信号量机制的方法,同步数据 |
| 前端修改代码后,页面渲染不及时导致后续获取的数据出错 | 设置定时器,进行一段事件等待 |
| 前端某些元素难以设置有序的进行移动、出现、消失多个元素的联合动画 | 放弃这个想法,设置成在一个元素中的动画 |
| AI训练没有训练数据 | 通过模拟游戏过程,使用随机数进行胜利对局数据获取 |
| AI模型训练的效果不是很好 | 增加数据预处理,例如进行数据归一化,修改网络结构多次尝试选个最优的 |
| 在线对战涉及的改动太多,事情太多 | 放弃在线对战 |
7. 收获
- 熟悉了HTML、CSS、JS的配合,做了一个老早就想做但是都没时间做的动画项目
- 首次通过AI训练游戏数据,虽然效果不是很好但勉强可用
- 体验了许多线程死锁、读写冲突等的BUG,丰富了作为计算机专业的烦恼体验
- 一个人开发了项目,完成了之前的一个小小念想进行前后端的全栈开发
- 找到了许许多多的在线工具,互联网上啥都有
- 找到了一些其他神奇的第三方包
- 总之很肝、很痛苦、很耗时,但满足了一个想法,不过下次拒绝这么肝
8. 评价我的队友
单人项目没有队友,这两分是不是可以全给我了?
老实说一个人开发效率很快,我懂我要做什么、我会什么、我多久可以做完,因此整个项目都按照我的想法大部分要求都能快速完成,但果然还是ddl的时候才开始做,最后还有在线对战还没有完成。一个人做我可以做到足够满意,但没有做到很满意,不过我觉得多加一个人可能也不能够把在线对战做出来吧,在我的项目里要涉及更改的代码有点多。
下次我一定要找好多个队友,躺着做项目,绝不熬夜绝不肝
9. PSP和学习进度条
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1180 | 945 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 200 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 600 | 500 |
| · Code Review | · 代码复审 | 60 | 70 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| Reporting | 报告 | 100 | 120 |
| · Test Repor | · 测试报告 | 60 | 80 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1290 | 1075 |
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 1500 | 1500 | 24 | 24 | 复习HTML、CSS、js、Jquery,编写动画以及前端游戏逻辑 |
| 2 | 880 | 2380 | 24 | 48 | 首次训练游戏AI,调整网络结构,进行前后端不分离开发 |
三、心得
本次项目我重新拾起好久都没动过的前端,因为之前学习的时候就吃了很多BUG,所以这次我直接使用Flex响应式布局,拒绝使用float属性果然BUG少了,开发流畅了,人也清爽了。同样之前踩坑这次直接使用js和Juqery,动画绝不死磕js选择使用CSS的动画属性实现,舒服多了。
我刚开始的时候是在想一个人组队,随便做做就行了因为这几周我也很忙,要做的事情很多,还有就是那时候没有一个UI参考和一些把最核心复杂的东西解决的工具或包,做不出我心目中的好东西,所以我不想浪费时间反而自己做了个垃圾项目,明明都准备摆烂了、放弃了、躺着了,却在github上找抄袭目标的时候,发现了一个扑克牌的第三方包deck-of-cards,直接把我项目中最复杂最核心的扑克牌事件集合解决了......不久后又又发现一个猪尾巴小游戏的视频,UI精美、简约......懂了,看来这次不能如愿摆烂,燃起来了!
基于deck-of-cards和视频UI我找到在线PS、抠图等工具,从原始视频上获取资源并通过其他的AI模型获取到了高清的SVG资源,白嫖党一路白嫖获取了所有想要的资源,再次感叹科技的强大,人工智能真的改变了很多东西。
前端开发过程中最让我耗时和痛苦的莫过于读写冲突和死锁问题,大量动画和定时器的应用造成了大量的问题,为了解决这些问题又设置了大量的定时器,最终还是通过信号量机制设置一些变量用于控制函数功能才得以解决,这时候我体会到了js语言的麻烦,即使使用了很好的IDE依然没有完整的代码补全、函数补全功能并且模块化还贼麻烦,怀恋VUE可惜这次没有决定使用VUE,果然Python才是天下第一的语言!
上一周一整周全在写前端的东西,也熬了一整天周的夜十分痛苦,有违我的生活习惯,执着了,发现我还是能写些高级一点的页面的。项目中我原本打算使用响应式开发,但有两个前端东西最后我没有做成响应,一个是首页猪的倒影、一个deck包的扑克牌,即使他们有自己写了一些响应式的东西但都是初次加载的时候固定了,只有再次让他们初始化或者刷新才能改变,其他的响应式做得差不多,打算在手机上也能访问。最后部署后发现,服务器带宽太小加载资源的速度太慢,手机上就更慢了并且手机上的触屏不被判断为鼠标事件!!!猪和扑克牌都太大了,手机上玩还任重道远。
后端方面主要就是AI开发,原本打算使用循环神经网络,但存在一些问题最后不想解决就直接使用了简单的神经网路实现。获取数据采用的是模拟游戏随机获取操作实现,用上了华为云服务器因为随着数据不断增多所以会越来越慢,为了不弄坏我的电脑选择上华为云用了上次白嫖的代金券,但也用了一个晚上才获取到一万局的胜利数据,最后获取到了六十万的操作数据,不清楚pandas是不是把记录的数据写入了内存,应该是吧,六十万也才100M以下。
接下来是本次项目可能改进的地方,当然写的时候我改不动了,立个flag下次一定:
- 前端模块化,将重复的代码抽离,高内聚低耦合,进行代码复用
- AI换成循环神经网络,因为打牌对局本身就有时序性,可以试试理论上会不会有准确率的提升
- 通过socket进行在线对战
- 编写更多的单元测试
- 编写更多的异常处理,因为项目中有很多地方需要数据一致性,所以会需求很多的异常处理
- 优化部署在服务器上的速度,不过我感觉只能通过换个更大的服务器实现,改变资源大小可以优化,因为我提供的资源全是高清资源
- 修复前端代码里面的读写冲突和线程死锁问题
综合来说这次项目我很满意,做了一直想做的东西,很满意了大三这一年还能自己全栈做个东西,虽然之前我想做个记录我个人生活的,以后给小孩子看。下次软工实践我的工作很专一,这次23点后,什么事情都与我无瓜,我只想睡觉。最后的最后,我还是想要一次难得的团队经历。
