第一次个人编程作业
https://github.com/trainKing-star/FZUSoftwareEngineering
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1180 | 945 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 200 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 600 | 500 |
| · Code Review | · 代码复审 | 60 | 70 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| Reporting | 报告 | 100 | 120 |
| · Test Repor | · 测试报告 | 60 | 80 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1290 | 1075 |
二、计算模块接口
1. 计算模块接口的设计与实现过程
项目中包括以下几个部分:
-
trie_node_model.py——树节点模型模块,有TrieNode树节点类、TrieNode2广搜节点类,用于建立后续关键词算法模型,包含敏感词、拼音、繁简体字等模型
- TrieNode——树节点类,记录节点索引、所在树层、字符代表的十进制整数、子节点列表、对应的关键词等信息
- TrieNode2——广搜节点类,记录周围可到达的节点列表、节点列表中字符十进制树的最大值和最小值、节点对应的关键词等信息
-
words_search.py——广搜算法实现模块,有一个IndexSearch搜索类
- IndexSearch搜索类,类中最主要的有两个方法SetKeywords()和FindAll()
- SetKeywords()方法,将输入的关键词列表转化为树结构,再将整棵树转化为广搜树
- FindAll()方法,通过SetKeywords()方法生成的广搜树,快速查找文本中对应的敏感词节点
- IndexSearch搜索类,类中最主要的有两个方法SetKeywords()和FindAll()
-
simplified_translate.py——繁简体字转换模块,有一个Translate繁简体字转换类
- Translate繁简体字转换类,最主要的方法是ToSimplifiedChines(),通过类中已经记录的大量繁简体字,使用IndexSearch搜索类生成简体广搜树,将繁体文本转化为简体文本
-
pin_yin_translate.py——汉字拼音转换模块,有一个Pinyin汉字拼音转换类
- Pinyin汉字拼音转换类,核心方法是GetPinyinList(),通过类中已经记录的大量汉字拼音对应字符,使用IndexSearch搜索类生成拼音广搜树,将汉字文本转化为拼音文本
-
data_preprocess.py——数据预处理模块,拥有扩充关键词、输入文本预处理、中英文区别判断、敏感词搜索处理功能
- expand_keywords()——扩充关键词函数:包括扩充谐音替代、拼音替代、拼音首字母代替
- characters_preprocess()——输入文本预处理函数:将输入文本中字母转化为小写,删除所有字母、汉字、换行符以外的字符,将文本中与关键词中字谐音的字转化为与该字谐音的关键字
- judge_chinese_english()——中英文区别判断函数:根据搜索的文本段是英文还是中文返回不同的信息
- search_message_from_origin_text()——敏感词搜索处理函数:从原输入文本中搜索查找到的敏感词信息,选择同开始索引但结束索引更大的敏感词文本输出
-
exceptions.py——异常处理模型,记录了一些项目中的自定义异常处理类,有一个自定义的文件处理异常类FileProcessException
- FileProcessException类,,用于进行输入路径是否存在以及输入路径是否为文件等判断
-
main.py——主执行模块,有一个函数data_load_process()
- data_load_process(),负责加载数据、调用其他模块处理数据、将处理结果写入文件
-
test——单元测试包,里面包含了五个测试模块,进行对上述几个模块中大部分函数的单元测试
- test_simplified.py——测试繁简体模块
- test_search.py——测试搜索类模块
- test_pinyin.py——测试汉字拼音转换模块
- test_exception.py——测试自定义异常处理模块
- test_data_preprocess.py——测试数据预处理以及主执行模型
最后项目的完成结果
(1)words_search.py——广搜算法实现模块
words_search.py是整个项目的核心模块,每一个模块都会用到这个模块的IndexSearch搜索类,这个类中搜索算法是使用的广搜算法
(2)simplified_translate.py——繁简体字转换模块
simplified_translate.py模块中的Translate类,对外提供的函数是ToSimplifiedChinese(),内部通过__GetWordsSearch()类选择使用哪种内部资源初始化IndexSearch搜索类,再通过TransformationReplace()方法搜索简体文本并完成替换,最后由ToSimplifiedChinese()方法输出简体字文本
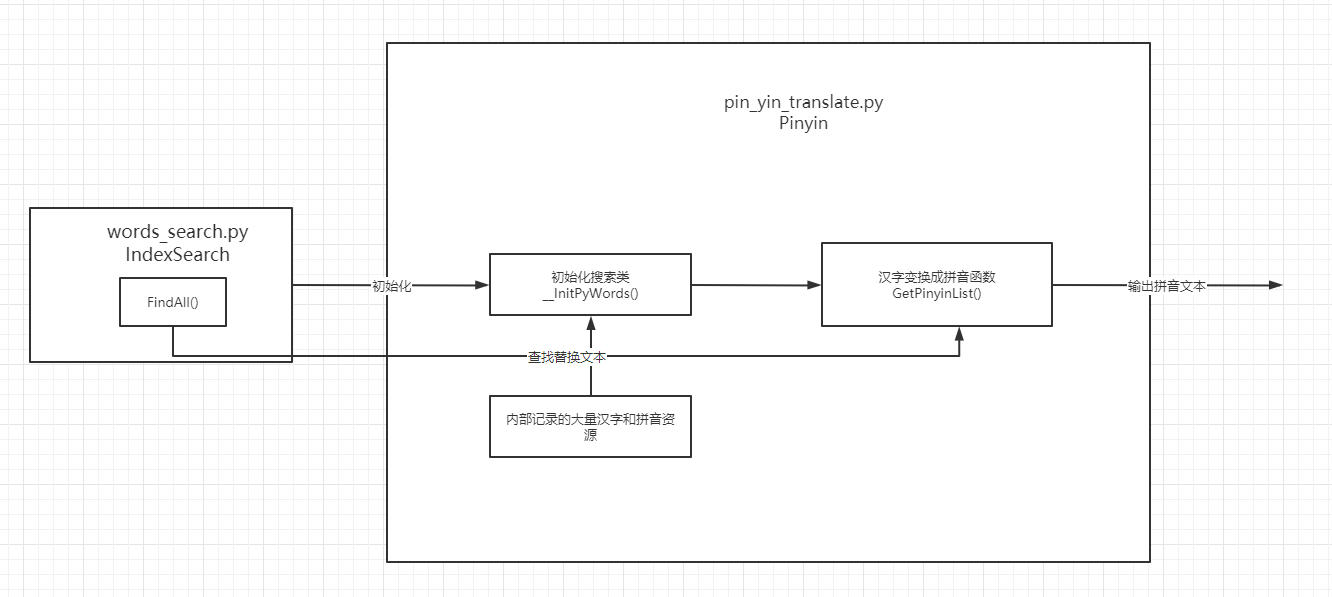
(3) pin_yin_translate.py 汉字拼音转换模块
与simplified_translate.py类似,pin_yin_translate.py 结合内部资源初始化IndexSearch类,由核心方法GetPinyinList()去调用搜索拼音和替换文本,最后输出处理好的拼音文本
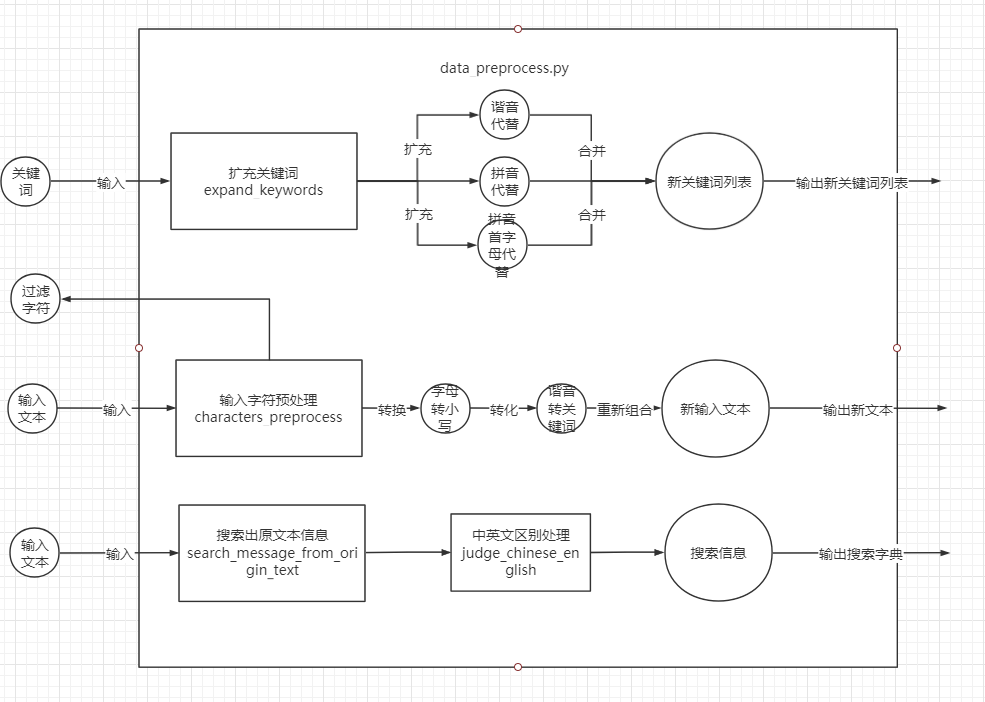
(4)data_preprocess.py——数据预处理模块
如图所示,expand_keywords()函数将扩充敏感词包括扩充谐音替代、拼音替代、拼音首字母代替,characters_preprocess()将进行信息过滤和信息提取,search_message_from_origin_text()将从精炼信息又扩大到原本的输入,是一种用少量信息表示大量信息的方法
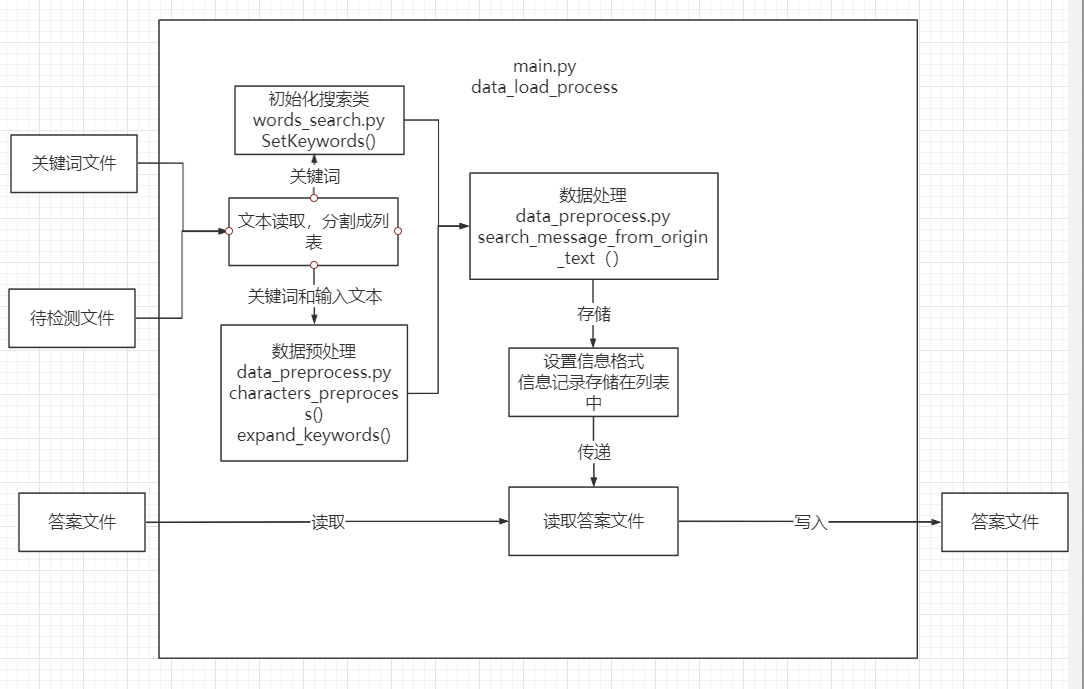
(5) main.py——主执行模块
main.py主执行模块中的data_load_process()函数整合之前的内容对数据进行处理后,按照指定的格式将数据输出到答案文件
(6)总结
- 问题:中文敏感词可能进行一些伪装,在敏感词中插入除字母、数字、换行的若干字符仍属于敏感词
- 解决方法:进行输入文本过滤,精简输入文本,设置精简输入文本对应原输入文本的索引列表,只需要在精简输入文本中找到中文敏感词即可扩大信息到原文本中,检测出包含包含干扰字符的敏感词信息
- 问题:中文文本中存在部分谐音替换、拼音替代、拼音首字母替代的敏感词(拼音不区分大小写)
- 解决方法:
- 中文关键词通过拼音、拼音首字母组合替换,扩大中文关键词列表,例如:福州,扩充有['fzhou', 'fu州', 'fz', 'fuzhou', '福z', '福州', 'fuz', '福zhou', 'f州']
- 输入文本处理时,将输入文本中字符与关键词列表中关键字谐音的字,替换为该谐音的关键字,如:抚州替换为福州
- 问题:中文文本中还存在少部分较难检测变形如繁体、拆分偏旁部首(只考虑左右结构)等
- 解决方法:从在py文件中记录了大量繁简体对应字的列表中,通过广搜搜索繁体对应的简体,将繁体替换成简体
- 问题:英文文本不区分大小写,在敏感词中插入若干空格、数字等其他符号(换行、字母除外),也属于敏感词
- 解决方法:输入文本预处理全部字母转为小写,精简输入文本后,借助第三方包判断搜索出敏感词的文本对应的敏感词是不是英文,进行中英文分别处理。例如:判断是中文则允许字符间有数字,判断为英文则不允许字符间有数字
2. 计算模块接口部分的性能改进
(1)性能分析
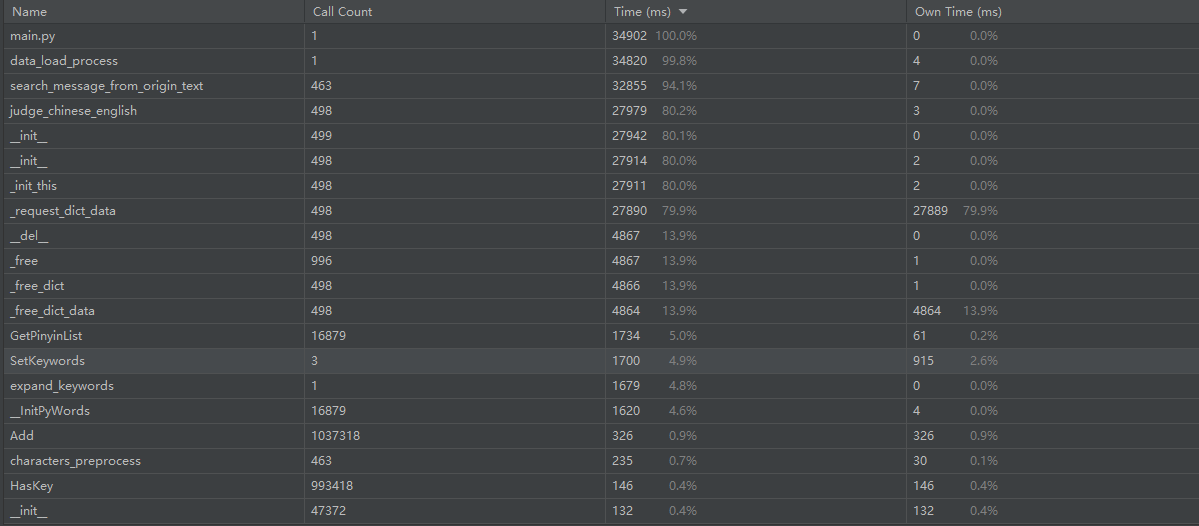
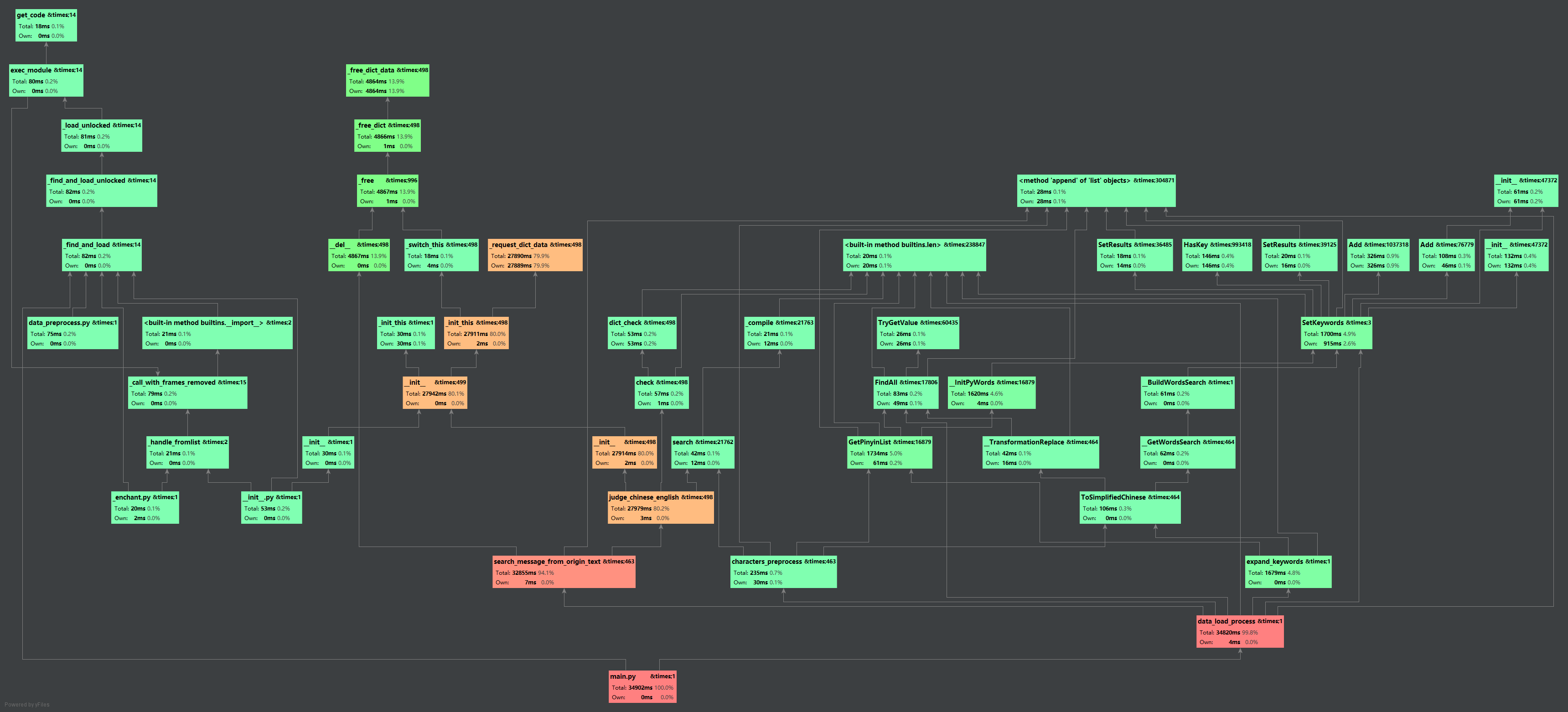
执行主执行文件代码后的消耗时间状况如图,根据下面两张图可以分析得到
- 大量的时间集中在search_message_from_origin_text()和judge_chinese_english()上
- 根据pycharm的调用关系图可以发现对搜索结束后的信息进行加工处理会花费更多的时间
- 对数据的加工会花费较大的时间,如扩充关键词、中英文分别处理
- 建立节点树和广搜树,进行繁简体转化、汉字拼音转化等用的时间占比很少
(2)优化方案
根据性能分析,得到了两个性能优化的方案
- 更改核心搜索算法,采用其他更高效率的算法
- 修改核心搜索算法,原算法对例如:敏感词min和ming,输入文本ming。会输出两个敏感词min和ming,但我们只需要更大范围的ming。我没有修改原算法,而是通过对原算法的加工处理修正了结果,这降低了效率。因此修改核心算法可以提高效率
- 考虑使用多线程方式处理数据
3. 计算模块部分单元测试展示
项目中采用了pytest第三方包作为单元测试,pytest可以检测项目包下的test为首的文件并自动执行test为首的函数或者Test为首的类
项目中设置了一个单元测试包test,里面有五个单元测试模块
(1)test_simplified.py
test_simplified.py模块针对simplified_translate.py模块中Translate类的核心方法ToSimplifiedChinese()进行测试,测试代码如下
# 输入文本
origin_text = "福州大學,拼音稱呼fuzhou大學,首字母簡稱fz大學,全簡稱FZDX。" \
"zhd現在正在做的這個項目是爲了在fz大學的軟件工程課上更happy的學習!"
# 测试标准结果
target_text = "福州大学,拼音称呼fuzhou大学,首字母简称fz大学,全简称FZDX。" \
"zhd现在正在做的这个项目是为了在fz大学的软件工程课上更happy的学习!"
class TestSimplified:
def test_Simplified(self):
global origin_text
global target_text
print("测试全局搜索")
translate = Translate()
text = translate.ToSimplifiedChinese(origin_text)
assert text == target_text
print("全局搜索正常")
(2) test_search.py
test_search.py模块针对words_search.py模块中的IndexSearch类所有方法进行测试
test_search = IndexSearch()
# 输入测试关键词案例
test_keyword = ["福州大学", "软件工程", "FZDX", "zhd", "happy", "fz大学", "fuzhou大学"]
# 输入测试文本
test_text = "福州大学,拼音称呼fuzhou大学,首字母简称fz大学,全简称FZDX。" \
"zhd现在正在做的这个项目是为了在fz大学的软件工程课上更happy的学习!"
class TestSearch:
def test_set_keyword(self):
global test_search
global test_keyword
print("测试初始化搜索类")
test_search.SetKeywords(test_keyword)
print("初始化搜索类正常")
def test_find_all(self):
global test_search
global test_text
print("测试全局搜索")
all = test_search.FindAll(test_text)
assert all[0]["Keyword"] == "福州大学"
assert all[1]["Keyword"] == "fuzhou大学"
assert all[2]["Keyword"] == "fz大学"
assert all[3]["Keyword"] == "FZDX"
assert all[4]["Keyword"] == "zhd"
assert all[5]["Keyword"] == "fz大学"
assert all[6]["Keyword"] == "软件工程"
assert all[7]["Keyword"] == "happy"
assert len(all) == 8
print("全局搜索正常")
(3)test_pinyin.py
test_pinyin.py模块针对pin_yin_translate.py模块中的Pinyin类的GetPinyin()方法进行测试,这个方法包含了Pingyin类的核心方法并对核心方法输出的结果进行拼接字符串处理
# 输入测试文本
origin_text = "福州大学,拼音称呼fuzhou大学,首字母简称fz大学,全简称FZDX。" \
"zhd现在正在做的这个项目是为了在fz大学的软件工程课上更happy的学习!"
# 输入测试标准文本
target_text = "FuZhouDaXue,PinYinChengHufuzhouDaXue,ShouZiMuJianChengfzDaXue,QuanJianChengFZDX。" \
"zhdXianZaiZhengZaiZuoDiZheGeXiangMuShiWeiLeZaifzDaXueDiRuanJianGongChengKeShangGenghappyDiXueXi!"
class TestPinyin:
def test_pinyin(self):
global origin_text
global target_text
print("测试拼音替换")
pinyin = Pinyin()
text = pinyin.GetPinyin(origin_text)
assert text == target_text
print("拼音替换正常")
(4)test_exception.py
test_exception.py模块针对exceptions.py模块中的所有自定义异常处理类进行测试,目前只有一个自定义的文件异常处理类
class TestExceptions:
def test_file_exist(self):
# 测试目录
test_path = ["E:/1", "E:/2", "E:/3"]
print("开始测试文件异常类")
try:
# 目录不存在或不是文件则抛出错误
for path in test_path:
if not os.path.exists(path) or not os.path.isfile(path):
raise FileProcessException("输入的关键词路径不存在或不是文件")
elif not os.path.exists(path) or not os.path.isfile(path):
raise FileProcessException("输入的待检测路径不存在或不是文件")
raise BaseException
except FileProcessException as e:
print(e.message)
print("测试文件异常类正常")
(5) test_data_preprocess.py
test_data_preprocess.py模块针对data_preprocess.py和main.py模块中的所有方法进行了测试,对main.py模块核心方法data_load_process()让其读入测试关键词文件、测试待检测文件、测试答案文件进行100行文本的答案测试,测试其输入输出以及结果正确功能
class TestDataPreprocess:
def test_expand_keywords(self):
global keywords
global keywords_expand_results
print("开始测试扩展敏感词")
for index, keyword in enumerate(keywords):
test_keywords, test_expand_results = expand_keywords([keyword])
for test_k in test_keywords:
assert test_k in keywords_expand_results[index][0]
for test_k, test_v in test_expand_results.items():
assert test_expand_results[test_k] == keywords_expand_results[index][1][test_k]
print("扩展敏感词正常")
def test_characters_preprocess(self):
global keywords
global char_text
global char_text_result_1
global char_text_result_2
print("开始测试输入文本预处理")
test_text, test_index = characters_preprocess(char_text, keywords)
test_text = "".join(test_text)
assert test_text == char_text_result_1
assert test_index == char_text_result_2
def test_judge_c_z(self):
global judge_test
print("开始测试中英文区分判断")
for i in range(len(judge_test)):
assert judge_test[i][2] == judge_chinese_english(judge_test[i][0], judge_test[i][1])
print("测试中英文区分判断正常")
def test_data_load_process(self):
global keywords_file
global input_file
global output_file
global compare_file
print("开始测试主程序运行")
data_load_process(keywords_file, input_file, output_file)
with open(output_file, "r", encoding="utf8") as f:
output_list = f.read().splitlines()
with open(compare_file, "r", encoding="utf8") as f:
compare_list = f.read().splitlines()
for i in range(len(output_list)):
assert output_list[i] == compare_list[i]
print("测试主程序运行正常")
keywords = ["福州大学", "happy"]
keywords_expand_results = [
(['fuzhoudxue', 'fuzhoudaxue', 'fuzhou大xue', '福州大学', '福州dx', 'fzhoudxue', 'fu州大学',
'fuzdxue', 'fzhoudaxue', 'fuzhouda学', '福zhou大学', '福zhou大xue', 'fu州da学', '福州da学',
'fzd学', '福州daxue', 'f州dx', 'fu州大xue', '福zdx', 'fuzhoudx', 'fzdx', 'fuzdax', 'fzhoudax',
'福zd学', 'fzdax', '福zhoudaxue', 'fuzhou大学', 'fzdxue', 'fzhoudx', 'fu州daxue', 'f州大x', 'fz大学',
'fuzdx', 'fuzhoudax', 'f州d学', 'fz大x', '福州大x', 'f州大学', '福z大x', '福zhouda学', '福州d学', '福州大xue',
'fzdaxue', '福z大学', 'fuzdaxue'],
{'福州大学': '福州大学', 'fu州大学': '福州大学', 'f州大学': '福州大学', 'fzhoudaxue': '福州大学', '福zhou大学': '福州大学',
'福z大学': '福州大学', 'fuzdaxue': '福州大学', '福州da学': '福州大学', '福州d学': '福州大学', 'fuzhoudxue': '福州大学',
'福州大xue': '福州大学', '福州大x': '福州大学', 'fuzhoudax': '福州大学', 'fuzhou大学': '福州大学', 'fz大学': '福州大学',
'fzdaxue': '福州大学', 'fu州da学': '福州大学', 'f州d学': '福州大学', 'fzhoudxue': '福州大学', 'fu州大xue': '福州大学',
'f州大x': '福州大学', 'fzhoudax': '福州大学', '福zhouda学': '福州大学', '福zd学': '福州大学', 'fuzdxue': '福州大学',
'福zhou大xue': '福州大学', '福z大x': '福州大学', 'fuzdax': '福州大学', '福州daxue': '福州大学', '福州dx': '福州大学',
'fuzhoudx': '福州大学', 'fuzhouda学': '福州大学', 'fzd学': '福州大学', 'fzdxue': '福州大学', 'fuzhou大xue': '福州大学',
'fz大x': '福州大学', 'fzdax': '福州大学', 'fu州daxue': '福州大学', 'f州dx': '福州大学', 'fzhoudx': '福州大学',
'福zhoudaxue': '福州大学', '福zdx': '福州大学', 'fuzdx': '福州大学', 'fuzhoudaxue': '福州大学', 'fzdx': '福州大学'}),
(['happy'], {'happy': 'happy'})
]
char_text = "抚州大学,富洲大雪,辅轴搭薛,拼音称呼fuzhou大学,首字母简称fz大学,全简称FZDX。" \
"zhd现在正在做的这个项目是为了在fz大学的软件工程课上更happy的学习!"
char_text_result_1 = "福州大学福州大学福州大学拼音称呼fuzhou大学首字母简称fz大学全简称fzdx" \
"zhd现在正在做的这个项目是为了在fz大学的软件工程课上更happy的学习"
char_text_result_2 = [0, 1, 2, 3, 5, 6, 7, 8, 10, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 39, 40, 41, 42, 43, 44, 46,
47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66,
67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82]
judge_test = [
("ha132468492^$^%%&%&ap48548&^%py", "happy", "ha132468492^$^%%&%&ap48548&^%py"),
("福5465州456%……&大……%%¥……学", "福州大学", None),
("¥%……#@¥福%…………&州%…………大%……#@#¥&&*学", "福州大学", "¥%……#@¥福%…………&州%…………大%……#@#¥&&*学")
]
keywords_file = "test/words.txt"
input_file = "test/org.txt"
output_file = "test/ans.txt"
compare_file = "test/compare.txt"
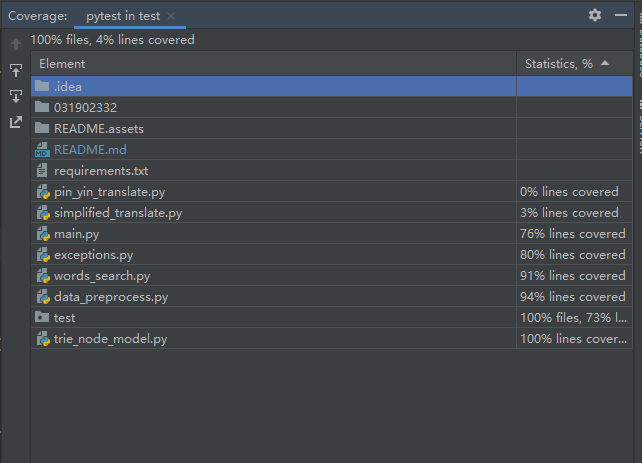
(6)测试覆盖率及其原因分析
下图为pycharm结合pytest第三方包的测试覆盖率图,可以看出
- 大部分文件的测试覆盖率都很高
- 模块中已经记录静态资源即使调用很多次处理文本仍然覆盖率很低
- 模块中没有记录静态资源覆盖率很高
下图为simplified_translate.py繁简体转化模块中的部分静态资源
下图为pin_yin_translate.py汉字拼音模块中的部分静态资源
结果分析:
- 测试中输入文本的量不够大,上述两个模块中静态资源的量太过庞大,导致覆盖率极低
4. 计算模块部分异常处理说明
(1)自定义异常处理需求分析
项目中需要获取三个由用户的输入文件路径,用户的输入路径可能在其电脑上不存在或者不是文件的路径,因此需要一个自定义文件异常类让程序能够正常运行
(2)自定义异常处理代码实现
在项目中exceptions.py模块中定义一个简单的文件异常类,其作用是能被抛出和捕获,在被捕获后能使程序正常运行并给用户异常信息提示
# 文件异常类
class FileProcessException(BaseException):
# 初始化信息
def __init__(self, message):
# 公有属性,能被外部访问
self.message = "[异常]:" + message
# 抛出时能显示异常原因
def __str__(self):
return self.message
(3)应用场景
这个文件异常类使用在main.py模型的核心函数中,用与检测输入文件路径是否存在,是否是文件路径,以下是main.py核心方法data_load_process()的部分代码,针对答案文件路径,因为我所使用的python当不存在文件时可以自动创建文件写入,所以我只设置了验证输入答案路径的父路径是不是存在
def data_load_process(keyword_file, input_file, output_file):
try:
# 检测关键词文件路径是否存在,是否是文件路径
if not os.path.exists(keyword_file) or not os.path.isfile(keyword_file):
# 不是则抛出异常
raise FileProcessException("输入的关键词路径不存在或不是文件 {}".format(keyword_file))
# 检测待检测文件路径是否存在,是否是文件路径
elif not os.path.exists(input_file) or not os.path.isfile(input_file):
# 不是则抛出异常
raise FileProcessException("输入的待检测路径不存在或不是文件 {}".format(input_file))
# 检测答案文件父路径是否存在
elif not os.path.exists(os.path.dirname(output_file)):
# 不是则抛出异常
raise FileProcessException("输入的答案路径不存在 {}".format(output_file))
except FileProcessException as e:
# 捕获异常后,显示信息,正常停止程序
print(e.message)
return
(4)自定义异常的单元检测
下列代是我对该自定义异常类的单元检测,设置了两个不存在的路径,一个不是文件路径进行自定义异常检测
class TestExceptions:
def test_file_exist(self):
# 测试目录
test_path = ["E:/1", "E:/2", "E:/3"]
print("开始测试文件异常类")
try:
# 目录不存在或不是文件则抛出错误
for path in test_path:
if not os.path.exists(path) or not os.path.isfile(path):
raise FileProcessException("输入的关键词路径不存在或不是文件")
elif not os.path.exists(path) or not os.path.isfile(path):
raise FileProcessException("输入的待检测路径不存在或不是文件")
raise BaseException
except FileProcessException as e:
print(e.message)
print("测试文件异常类正常")
三、心得
因为之前有其他事情一直都比较忙,正好上周的博客作业我刚写了绝不会熬夜通宵到4点多,但偏偏打脸来的那么快,我刚好满足了熬夜条件,不得不熬夜,但却是不可多得的回忆,实现了一个本来觉得不能实现的小目标。
本次项目是我在极短时间内肝出来的,算法思路借鉴了一个github上的ToolGood.Words项目,他虽然提供了一些开源的代码但没有给算法的注释和讲解,要花30块买,我可太不像花这个钱了于是自己花了一些时间读懂他的源码,索性不难是个广搜算法,然后基于他的项目我写了很多的数据加工和数据处理的代码将其能应用到我们的作业上,满足需求,不过还是太赶了,原本我是想试试能不能切换成其他算法对比。
本次作业我也学到了很多我以前没有用过的东西,比如性能分析、单元检测,以前 只管敲代码,敲完了一个项目也就结束了,后续也不会优化这个项目,希望我在之后的课程里能学到更多的东西,然后做好我的软工实践,我可就是为了和小伙伴们做出一个能上线有趣的项目才来这里的,要不然我绝不在这里受苦,现在是22:06分,终于肝完了,还有一些想写的,先交了以后再改。
写完了提交了还有一点点的时间,本来看到这个题目的时候我就想到现在手上的一个项目应该会有敏感词检测,敏感词检测我想也能用深度学习、NLP来做,这个我老感兴趣了,还想着做完一个基本的就试试用深度学习来做,之前是有一个想法不知道能不能实现,敏感词检测问题有点类似NLP里的命名实体识别和中文分词的问题,我想到的是通过序列标注的方法对训练文本中的每一个敏感字进行标注,具体方法可以采用中文分词BIO标注法,B是敏感词的开头,I是敏感词的中间部分词,O是敏感词的结束词。按照这样的方法进行训练,我觉得可行,有空试试,这次做算法上的敏感词识别可真让我体会到深度学习的优势,不用管那么多数据标注好全扔进去,效果还比手写的算法好,太舒坦了!
本次项目也给我了一些挑战,短时间内看懂别人的代码手敲一堆自己实现的数据加工和处理以及想一些适配问题的解决方法,就是我已经搁置了几天的英语单词还没有背,快乐又痛苦,这次项目好好保存后面大概会有用到。

