消息队列RabbitMQ的基础概念和使用方式
初识 RabbitMQ
下面我们来学习一下 RabbitMQ,它是一款实现了高级消息队列协议的消息中间件,可以和不同的进程进行通信,从而实现上下游之间的消息传递。有了消息中间件之后,上游服务和下游服务就无需直接通信了,上游服务将消息发送到队列中,下游从队列中去取即可,从而实现上下游服务之间的 "逻辑解耦 + 物理解耦"。
但是实现解耦有什么好处呢?答案是可以实现异步处理,提高效率,举个栗子:
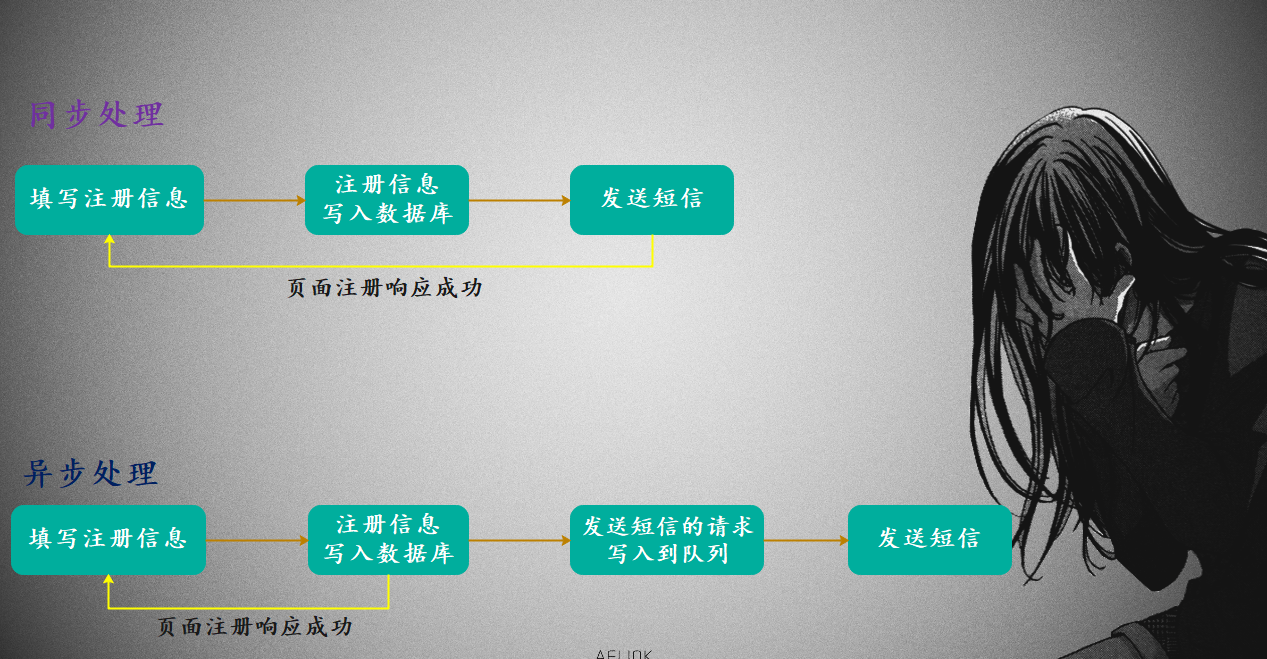
使用消息队列,可以把耗时任务扔到队列里面进行异步调用,从而提升效率,也就是我们所说的解耦。
然而除了解耦,还有没有其他作用呢?答案显然是有的,用一个专业点的名词解释的话,就是削峰填谷。
削峰填谷,名字很形象,就是缓冲瞬时的突发流量,使其更平滑。特别是那种发送能力很强的上游系统,如果没有消息中间件的保护,脆弱的下游系统可能会直接被压垮导致全链路服务雪崩。但是,一旦有了消息中间件,它能够有效的对抗上游的流量冲击,真正做到将上游的 "峰" 填到 "谷" 中,避免了流量的震荡。当然我们这里说的解耦也是一个有点,因为在一定程度上简化了应用的开发,减少了系统间不必要的交互。
直接解释的话,可能没有直观的感受,我们来举一个实际的例子。比如在京东购买商品,当点击购买的时候,会调用订单系统生成对应的订单。然而要处理该订单则会依次调用下游系统的多个子服务,比如查询你的登录信息、验证商品信息、确认地址信息,调用银行等支付接口进行扣款等等。显然上游的订单操作比较简单,它的 TPS 要远高于处理订单的下游服务。因此如果上游和下游直接对接,势必会出现下游服务无法及时处理上游订单从而造成订单堆积的情况。特别是当出现双十一、双十二、类似秒杀这种业务的时候,上游订单流量会瞬间增加,可能出现的结果就是直接压垮下游子系统服务。解决此问题的一个常见的做法就是对上游系统进行限速、或者限制请求数量,但是这种做法显然是不合理的,毕竟问题不是出现在它那里。况且你要是真这么做了,别人家网站双十一成交一千万笔单子,自家网站才成交一百万笔单子,这样钱送到嘴边都赚不到。
所以更常见的办法就是引入消息中间件来对抗这种上下游系统的 TPS 不一致以及瞬时的峰值流量,引入 RabbitMQ 之后,上游系统不再直接与下游系统进行交互。当新订单生成之后它仅仅是向 RabbitMQ 的队列中发送一条消息,而下游消费队列中的消息,从而实现上游订单服务和下游订单处理服务的解耦。这样当出现秒杀业务的时候,RabbitMQ 能够将瞬时增加的订单流量全部以消息的形式保存在队列中,既不影响上游服务的 TPS,同时也给下游服务流出了足够的时间去消费它们,这就是消息中间件存在的最大意义所在。
消息中间件的种类
我们这里学习的是 RabbitMQ,但是除了 RabbitMQ,还有没有其它的消息中间件呢?它们的性能、应用场景、优缺点又如何呢?
注:这篇博客最初是一年多以前写的,有很多不足的地方,因此这里重写了。
1. ActiveMQ
非常老的一个消息中间件了,单机吞吐量在万级,时效性在毫秒级,可用性高。基于主从架构实现高可用性,数据丢失的概率性低。
但是官网社区对 ActiveMQ 5.x 的维护越来越少,并且它的吞吐量和其它消息中间件相比其实是不高的,因此在高吞吐量场景下使用的比较少。
2. Kafka
大数据的杀手锏,谈到大数据领域的消息传输,必离不开 Kafka。这款为大数据而生的消息中间件,有着百分级 TPS 的吞吐量,在数据采集、传输、存储的过程中发挥至关重要的作用,任何的大公司、或者做大数据的公司都离不开 Kafka。
Kafka 的特点就是性能卓越,单机写入 TPS 在百万条每秒,时效性也在毫秒级;并且 Kafka 是分布式的,一个数据多个副本,少数的机器宕机也不会丢失数据;消费者采用 Pull 方式获取消息,消息有序、并且可以保证所有消息被消费且仅被消费一次;此外还有优秀的第三方 Kafka Web 管理界面 Kafka-Manager,在日志领域比较成熟,大数据领域的实时计算以及日志采集等场景中被大规模使用。
但是 Kafka 也有缺点,单机超过 64 个分区,CPU 使用率会发生明显的飙高现象,队列越多 CPU 使用率越高,发送消息响应时间变长;使用短轮询方式,实时性取决于轮询间隔时间,消费失败不支持重试;虽然支持消息有序,但如果某台机器宕机,就会产生消息乱序。
3. RocketMQ
阿里巴巴开源的一款消息中间件,用 Java 语言实现,在设计时参考了 Kafka,并做了一些改进。在阿里内部,广泛应用于订单、交易、重置、流计算、消息推送、日志流式处理、以及 binlog 分发等场景。
RocketMQ 支持单机吞吐量达到十万级,可用性非常高,分布式架构保证消息零丢失。MQ 功能较为完善,扩展性好,支持 10 亿级别的消息堆积,不会因为消息堆积导致性能下降。
但是支持的客户端语言不多,仅支持 Java 和 C++,其中 C++ 还不成熟。社区活跃度一般,没有在 MQ 核心中实现 JMS 等接口,说白了 RocketMQ 就是阿里开发出来给自己用的。
4. RabbitMQ
RabbitMQ 是一个在 AMQP(高级消息队列协议)基础上完成的可复用的企业消息系统,是当前最主流的消息中间件之一。
AMQP: Advanced Message Queuing Protocl,即:高级消息队列协议。它是具有现代特征的二进制协议,是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
RabbitMQ 是采用 Erlang 语言编写,Erlang 语言最初用于交换机领域的架构模式,它有着和原生 socket 一样的延迟。因此性能较好,吞吐量在万级,并且时效性在微妙级;功能也很完善,健壮、稳定、易用、跨平台;最重要的是支持大部分主流语言,文档也丰富,此外还提供了管理界面,并拥有非常高的社区活跃度和更新频率。
但是它的商业版是需要收费的,学习成本高。
到底应该选择哪一种消息中间件
消息中间件这么多,我到底应该选择哪一种呢?
首先是 Kafka,它主要特点是基于 Pull 的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,高吞吐量是 Kakfka 的目标。因此如果要涉及大量数据的收集(比如日志采集),那么首选 Kafka。
然后是 RocketMQ,它天生为金融领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单扣款、以及业务削峰。RocketMQ 在稳定性上绝对值得信赖,毕竟这些业务场景在阿里双十一已经经历了多次考验,如果你的业务也有类似场景,那么建议选择 RocketMQ。
最后是 RabbitMQ,结合 Erlang 语言的并发优势,性能好、时效性微妙级,社区活跃度也高,管理界面用起来非常方便。如果你的数据量没有那么大,那么建议选择 RabbitMQ,其实中小型公司选择 RabbitMQ 是一个非常好的选择。
RabbitMQ 整体架构以及核心概念
那么下面就来学习 RabbitMQ,我们说它是一个消息中间件,负责接收并转发消息。但是注意:RabbitMQ 内部不会对消息进行处理,它只负责消息的的接收、存储和转发。
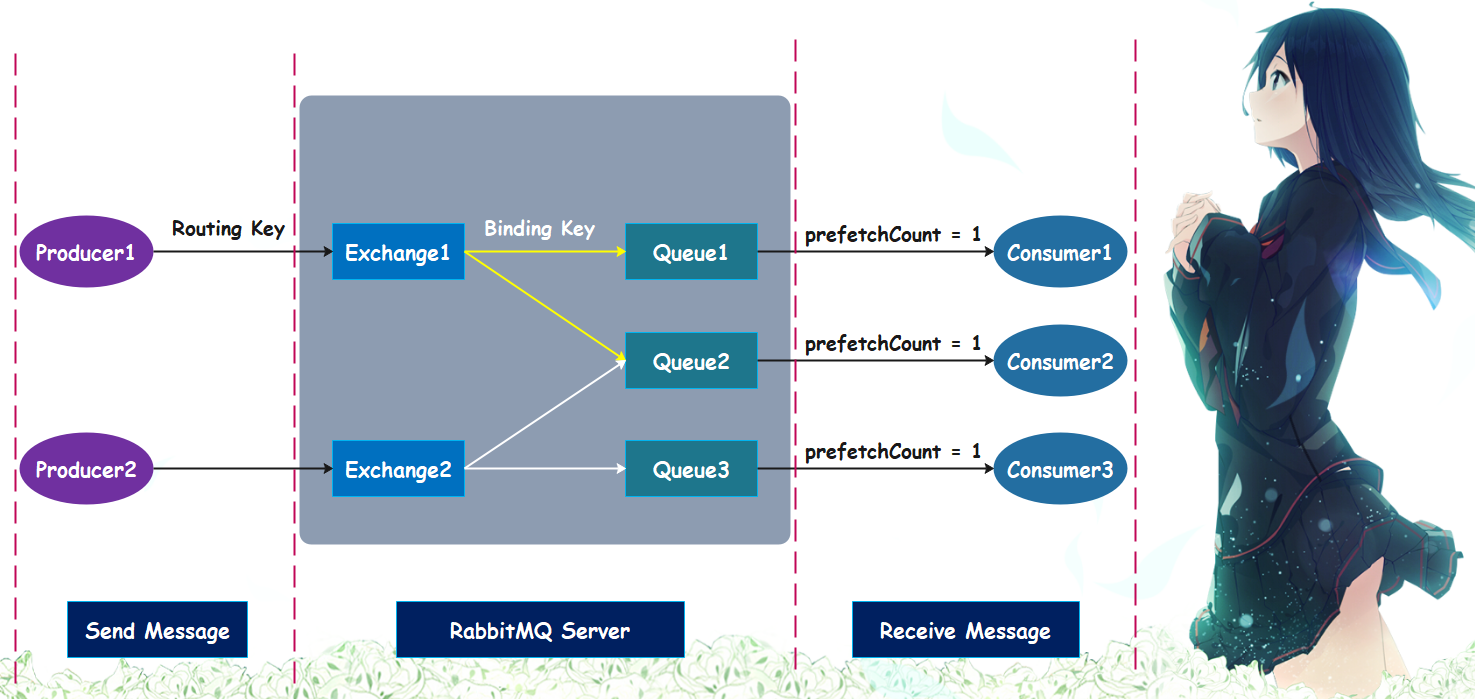
里面涉及的东西比较多,我们慢慢解释。
1. Server:当 RabbitMQ 启动之后,那么对应的整个进程我们称之为 Server,准确来说应该叫 Broker,只不过个人更喜欢叫 Server。
2. Producer:生产者,即消息的发送方,可以是控制台、也可以是 Python、Java 等编程语言;Consumer(消费者)也是同理,只不过它是消息的接收方。而对于 RabbitMQ Server 而言,生产者和消费者统称为客户端。
3. Routing Key:路由键,生产者发送消息时会带上它,可以用它来确定一个消息要进入到哪一个队列中。
4. Message:消息,生产者和消费者之间如果想传递数据,那么必须要将数据包装成消息,然后才可以发送。消息由 Body 和 Properties 组成,前者是消息体,后者是消息属性,里面包含了消息的优先级、延迟等高级特性。
5. Exchange:交换机,负责接收消息,再将消息转发到绑定的队列,交换机和队列之间是一对多的关系。所以消息并不是直接进入到队列里面,而是要先进入到 Exchange、也就是交换机中,然后再被转发到与 Exchange 绑定的队列中。而交换机也是有类型的,交换机的类型决定了消息要如何被处理,是推送到特定的队列、还是多个队列,亦或是把休息丢弃等等,这些都由交换机的类型决定。
6:Queue:队列,RabbitMQ 内部使用的一种数据结构,尽管消息要经过交换机,但消息最终只能被存储在队列中。队列只受主机的内存和磁盘的限制,本质上是一个大的消息缓冲区,生产者生产的消息会被存到队列中,消费者则是获取来自队列的消息。
7:Binding Key:我们说 Exchange 和 Queue 之间是相互绑定的, 而这个绑定的连接就是 Binding。Binding 里面包含了 Binding Key,用于和 Routing Key 进行匹配,这样交换机才知道该将消息推送到哪一个队列。
还有一些重要的点,尽管图中没有画出来,但它确实存在。
8. Virtual Host:虚拟地址,用于进行逻辑隔离,它是最上层的消息路由。一个 Virtual Host 里面可以有若干个 Exchange 和 Queue,但是同一个 Virtual Host 里面不能相同名称的 Exchange 或 Queue。为什么要有虚拟地址这么一个概念呢?主要是为了对服务进行划分,比如有多个应用服务在开发,那么 A 服务就把消息发送到虚拟地址等于 /A 的主机上,B 服务可以把消息都发送到虚拟地址等于 /B 的主机上,然后再经过各自的交换机和队列,这样在逻辑上更具有层次感,也适用于多租户。
9:Connection:客户端和 RabbitMQ Server 建立的网络连接,因为无论是发送消息还是接收消息,都必须先要和 Server 建立连接才可以。
10:Channel:网络信道,建立连接之后还要根据连接创建一个 Channel 对象,它才是消息读写的通道,几乎所有的操作都要在 Channel 中进行。因为如果每一次访问 RabbitMQ Server 都要建立一个 Connection 的话,那么在消息量大的时候意味着建立连接的开销也会非常大,所以就有了 Channel,Channel 是在 Connection 内部建立的逻辑连接。一个 Connection 内部可以创建多个 Channel,如果应用程序需要多线程访问,那么通常是创建一个 Connection,然后使用同一个 Connection 为不同的线程创建单独的 Channel。而客户端和 RabbitMQ Server 可以通过 Channel id 来识别 Channel,因此 Channel 之间是完全隔离的,而 Channel 作为轻量级的 Connection 极大地减少了操作系统建立 TCP 连接的开销。
RabbitMQ 的安装与使用
介绍完 RabbitMQ 之后,我们来看看如何安装,这里我们使用的是阿里云的轻量应用服务器,操作系统是 CentOS 7。
我们说 RabbitMQ 是 Erlang 语言编写的,那么肯定要安装 Erlang 语言,跟使用 Hadoop 要先安装 Java 一样。我们可以去 https://github.com/rabbitmq/erlang-rpm/releases 下载 erlang 的 rpm 包,但是注意:我们后面会使用最新版的 RabbitMQ,所以要保证 erlang 的版本不低于 21.3。
# 这里安装是 23.3.2,当然你也可以选择更新的版本,只要不低于 21.3 即可
rpm -ivh erlang-23.3.2-1.el7.x86_64.rpm --nodeps --force

安装结束之后,输入 erl,如果显示如上内容,说明安装成功。
然后来安装 RabbitMQ,可以去 https://github.com/rabbitmq/rabbitmq-server/releases 下载对应的 rpm 包,这里我们使用的是新版本 3.8.14,所以点击 rabbitmq-server-3.8.14-1.el7.noarch.rpm 进行下载即可。
完事之后,我们先不要安装,因为 RabbitMQ 官网提示我们需要先安装两个依赖:
yum install socat logrotate -y
# 然后再安装 RabbitMQ
rpm -ivh rabbitmq-server-3.8.14-1.el7.noarch.rpm
然后我们就可以启动 RabbitMQ 服务了。
rabbitmq-server:以前台方式启动rabbitmq-server -detached:以后台方式启动rabbitmqctl stop:停止服务,注意停止服务使用的是 rabbitctlrabbitmqctl stop_app:stop 会将 Erlang 虚拟机和 RabbitMQ 服务都关闭,但是 stop_app 只会关闭 RabbitMQ 服务
[root@satori ~]# rabbitmq-server -detached
启动成功,然后我们就可以通过编程语言去连接了,我们后面会演示如何使用 Python 连接 RabbitMQ 并进行消息的发送和接收。而连接的端口是 5672,也就是说,如果我们想要进行 TCP 通信的话,是通过端口 5672 进行通信的。
另外 RabbitMQ 也支持我们使用 webUI 的方式访问,但是需要安装一个插件,安装也很简单,直接命令行输入 rabbitmq-plugins enable rabbitmq_management 即可。然后就可以通过浏览器查看了,webUI 访问的端口是 15672,我们来看一下。

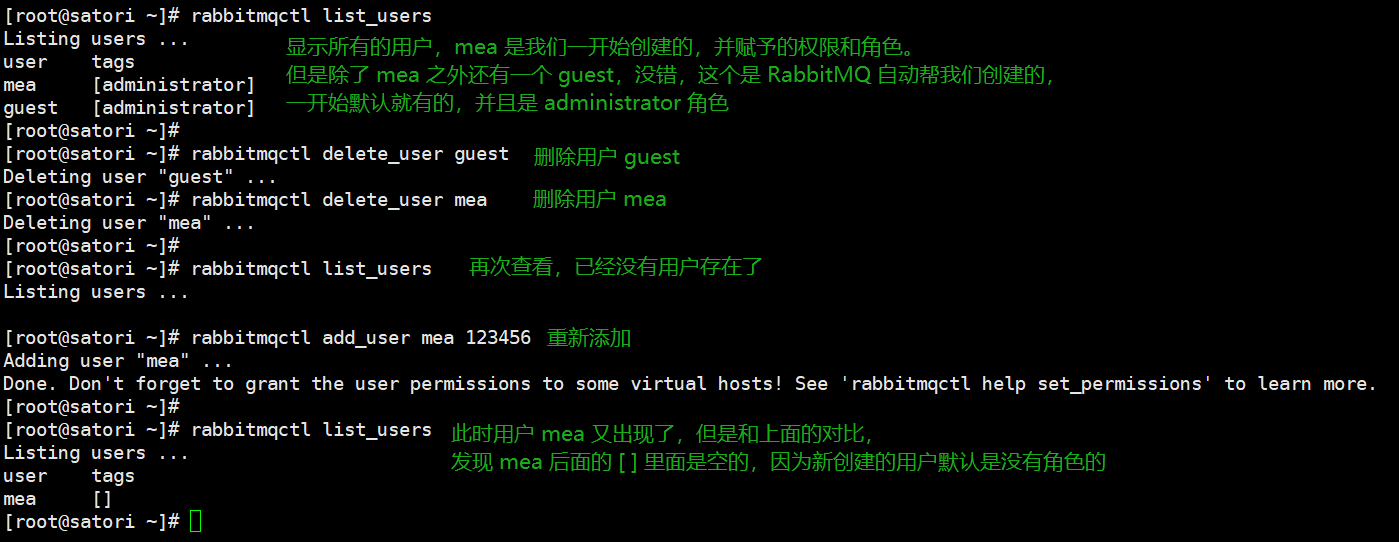
但是我们看到需要输入用户名和密码,所以我们可以创建一个用户。
创建用户:rabbitmqctl add_user 用户名 密码
新创建的用户默认是什么权限也没有的,所以还可以设置权限。
为用户设置权限: rabbitmqctl set_permissions -p / 用户名 ".*" ".*" ".*"
-p 表示指定 Virtual Host(虚拟地址),/ 是 RabbitMQ 默认创建的一个虚拟地址(如果想指定其它的虚拟地址,必须要事先创建好),".*" ".*" ".*" 表示给用户赋予该 Virtual Host 下资源的配置权限、写权限、读权限。
[root@satori ~]# rabbitmqctl add_user mea 123456
Adding user "mea" ...
Done. Don't forget to grant the user permissions to some virtual hosts!
See 'rabbitmqctl help set_permissions' to learn more.
[root@satori ~]#
[root@satori ~]# rabbitmqctl set_permissions -p / mea ".*" ".*" ".*"
Setting permissions for user "mea" in vhost "/" ...
[root@satori ~]#
这里我们创建了一个名为 mea 的用户,密码为 123456,虚拟地址为 /,然后赋予了资源的配置权限、写权限、读权限。但是注意:该权限指的是客户端使用该用户连接到 RabbitMQ Server 时所具有的权限,因为客户端连接 RabbitMQ Server 也是需要指定用户的,如果客户端使用的用户具有写权限,那么可以发送消息;如果具有读权限,那么可以接收消息。
但是对于 webUI 而言,此时仍然无法通过用户 mea 进行登陆,如果你尝试输入 mea 和 123456 登录的话,会提示你:Not management user。因为上面设置的权限和 webUI 无关,如果想查看 webUI,那么必须给该用户赋予一个角色,这里的角色就类似于:游客、普通用户、会员、管理员。从提示信息 Not management user 可以看出,我们必须给用户 mea 一个角色,并且角色等级要不低于 management。
注意:用户权限和用户角色是两码事,用户权限指的是客户端使用该用户连接到 RabbitMQ Server 时的权限,用户角色指的是该用户有没有资格查看 webUI、以及通过 webUI 能进行哪些操作。如果你不打算查看 webUI,那么可以不给用户设置角色,只设置权限。
给用户设置角色:rabbitmqctl set_user_tags 用户名 角色
角色有:none、management、policymaker、monitoring、administrator 五种,刚创建的用户默认是没有角色的,这里我们就设置为 administrator。
[root@satori ~]# rabbitmqctl set_user_tags mea administrator
Setting tags for user "mea" to [administrator] ...
此时我们就可以查看 webUI 了:
里面包含了整个 RabbitMQ Server 的信息,此外还可以在里面添加用户、添加 Virtual Host 等等,但是该用户的角色必须要达到一定等级才可以。
然后再来看看 RabbitMQ 的一些命令行操作,也就是 rabbitctl 的一些用法:
rabbitmqctl list_users:列出所有用户rabbitmqctl delete_user 用户名:删除某个用户rabbitmqctl add_user 用户名 密码:添加某个用户rabbitmqctl change_password 用户名 密码
rabbitmqctl set_permissions -p 虚拟地址 用户名 ".*" ".*" ".*":给用户设置权限rabbitmqctl clear_permissions -p 虚拟地址 用户名:清除权限rabbitmqctl list_user_permissions 用户名:列出该用户的权限rabbitmqctl set_user_tags 用户名 administrator:给用户设置角色
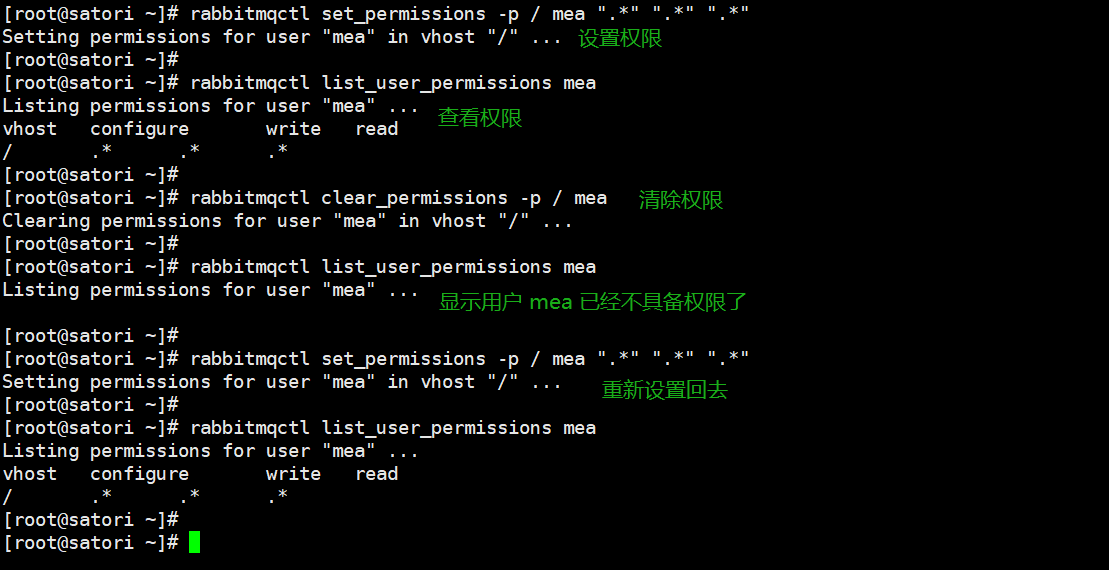
rabbitmqctl list_vhosts:列出所有虚拟地址rabbitmqctl list_permissions -p 虚拟地址:列出该虚拟地址所在主机的权限rabbitmqctl add_vhost 虚拟地址:创建虚拟地址rabbitmqctl delete_vhost 虚拟地址:删除虚拟地址
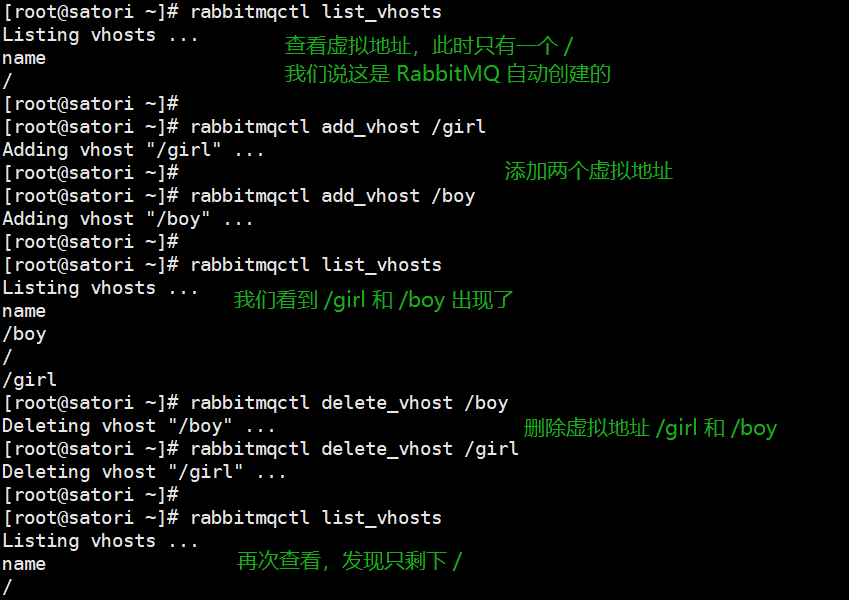
如果你删除了某个虚拟地址,那么用户在该虚拟地址上的权限也会被清空。假设用户 mea 在 /girl 上有权限,但是我们把 /girl 删除了,那么用户 mea 在 /girl 上面的权限也会被清空。如果我们重新添加虚拟地址 /girl,那么用户 mea 在 /girl 权限也要重新设置。
rabbitmqctl list_queues:查看所有队列信息rabbitmqctl delete_queue 队列:删除某个队列rabbitmqctl -p 虚拟地址 purge_queue 队列:清除队列里面的信息rabbitmqctl reset:移除所有队列的所有数据,但是不推荐使用
RabbitMQ 支持的命令非常多,包括还有集群的命令,比如:集群之间如果有机器挂掉了,那么如何将挂掉的机器从集群中移出去、或者指定消息是存储在磁盘中还是内存中等等。但是如果把命令一次性全捞出来,对于学习来讲无疑是个灾难,我们目前就先记住这么多吧。当然不用刻意的去记,多实际操作几波就可以了。
其实在生产中,我们很少会通过 rabbitctl 的方式去操作,更多的是充当客户端去连接 Server。
消息的生产与消费
下面我们来通过 Python 充当客户端连接至 RabbitMQ Server,分别发送消息和接收消息。而 Python 想要连接 RabbitMQ,需要使用一个第三方包:pika,直接 pip install pika 即可,下面我就在 Windows 机器上连接阿里云服务器上的 RabbitMQ。
Python 版本是 3.8.7,pika 版本是 1.2.0
首先是编写生产者的代码:
我们说客户端连接 RabbitMQ Server 也是需要指定用户的,所以首先指定用户,并且该用户要具备相应的权限。
import pika
credentials = pika.PlainCredentials("mea", "123456")
接下来创建连接:
# 连接参数不止下面这几个,具体可以进入源码中查看,注释很详细
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
# 端口可以不用指定,默认是 5672
# 当然如果修改了端口,那么就要重新指定了
port=5672,
# 虚拟地址也可以不用指定,默认是 /
virtual_host="/",
# 用户信息
credentials=credentials)
# 创建了 Connection,相当于建立了 TCP 连接
# 如果连接的时候报出了 pika.exceptions.ProbableAccessDeniedError,那么就要考虑你的用户是否具有相应的权限
connection = pika.BlockingConnection(connection_params)
创建连接之后,我们要再基于连接去创建网络信道(Channel),因为创建 Queue,消息的传输等等都是通过网络信道进行的。
channel = connection.channel()
然后就可以往队列里面发送消息了,但是此时还没有队列,所以我们需要声明一个队列,或者说创建一个队列。
channel.queue_declare(queue="girls", durable=True)
注意:queue_declare 里面的参数有好几个,我们来分别解释一下。
第一个参数 queue:很简单,队列的名字。
第二个参数 passive:默认为 False,声明队列时,队列不存在会自动创建;指定为 True,那么队列不存在时会报错。
第三个参数 durable:持久化,注意这里的持久化指的是队列的持久化,不是消息的持久化。默认是 False,表示不持久化,一旦服务或机器重启,整个队列就没有了,包括里面的消息。指定为 True,那么表示持久化,重启之后队列还在,但里面的消息是否还在就看发送消息时有没有对消息进行持久化。所以如果消息想被持久化,那么首先存储它的队列必须是持久化的,尽管可以将持久化的消息发送到非持久化的队列中,不过没有什么意义。另外,如果队列已存在,那么可以不用 channel.queue_declare 进行声明,但如果无法保证队列一定存在,那么还是最好声明一下。不过当队列已存在、我们还声明该队列的话,那么要注意一个事项:" 我们必须要根据已存在的队列是否是持久化队列来显式地指定 durable 参数 "。比如已存在的队列是持久化队列,那么 durable 必须指定为 True,否则的话会报错:" 队列是持久化的,但传递的参数是 False ";如果已存在的队列是非持久化队列,那么要指定 False(默认值,此时也可以不用指定)。尽管队列已存在,声明之后也不会重复创建,但是指定的参数仍然要和已存在的队列的属性保持一致。其实个人觉得从设计上来讲,当队列已存在时,那么它是否是持久化队列就已经决定了,此时声明一个已存在的队列时应该忽略掉 durable 参数,当然这里我们就不深究了。
第四个参数 exclusive:个人觉得该参数实现的功能有点奇怪,不明白它的意义何在,这里不做介绍。
第五个参数 auto_delete:当队列中的消息都被消费完毕、并且最后一个消费者断开连接时,是否自动删除该队列。注意:自动删除是当消息全部被消费、并且所有的消费者都断开连接时才删除,如果自始至终都没有消费者连接的话,那么是不会删除的。参数默认是 False,表示不删除。但是注意:如果该队列已存在,并且创建的时候指定了 auto_delete 为 True,那么当再次声明该队列的时候,也必须指定 auto_delete 为 True;False 同理,只不过默认是 False。和 durable 参数类似,指定的参数要和已存在的队列的属性保持一致。
第六个参数 arguments:一个字典,用于接收一些额外的参数,主要针对于更高级特性,比如延迟消息、死信消息等等,后面会说。
创建完队列之后,那么就该发送消息了。
channel.basic_publish(exchange="",
routing_key="girls",
body=b"my name is kagura_mea")
这里面的比较重要,我们需要详细说一下。首先我们调用 channel.basic_publish 方法发送消息,但是 channel 要如何得知这个消息应该发送到哪一个交换机当中呢?交换机如果绑定了多个队列,那么交换机要把消息推到哪一个队列中呢?显然我们需要通过 exchange 和 routing_key 参数指定,通过 exchange 参数指定交换机、routing_key 参数指定交换机绑定的队列。
但很明显我们目前还没有创建交换机,所以指定为空字符串即可,因为 RabbitMQ 会有一个默认的交换机,此时消息会发送到默认的交换机中,总之消息首先要经过交换机、再由交换机路由到队列。然后是 routing_key 参数,这里它指的就是队列的名字,告诉默认的交换机请把消息路由到 girls 这个队列里。
准确来说,交换机和绑定在交换机上的队列之间有一个 Binding Key,交换机会根据 Routing Key 将消息路由到和 Binding Key 匹配的队列中,只不过对于当前默认的交换机来说,Binding Key 也是队列的名字。交换机的内容后面会详细介绍。
然后是 body 参数,它表示我们传递的消息内容,可以接收字符串、或者字节串。exchange、routing_key、body 便是该方法的前三个参数,但是还有第四个参数 properties,它表示消息的属性,这里我们暂时不指定,默认为 None。然后会将指定的 body 和 properties 的值包装成 RabbitMQ 能够识别的消息,发送到队列中。
channel.close()
connection.close()
最后消息发送完毕之后关闭信道和连接,程序结束,因此生产者是不会阻塞的,发完消息之后就可以断开连接了。
以上我们就写完了生产者的代码,整体代码如下:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
channel.queue_declare(queue="girls", durable=True)
channel.basic_publish(exchange="",
routing_key="girls",
body=b"my name is kagura_mea")
channel.close()
connection.close()
然后我们来执行一下,执行成功之后通过 rabbitmqctl list_queues 查看队列:
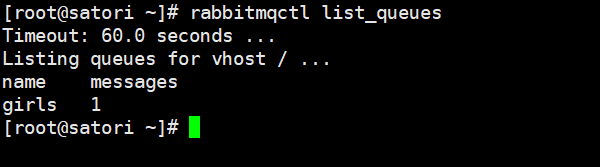
此时队列已经被创建,并且里面有一条消息,就是我们刚才发送的。
或者通过 webUI 来查看,更加的详细:
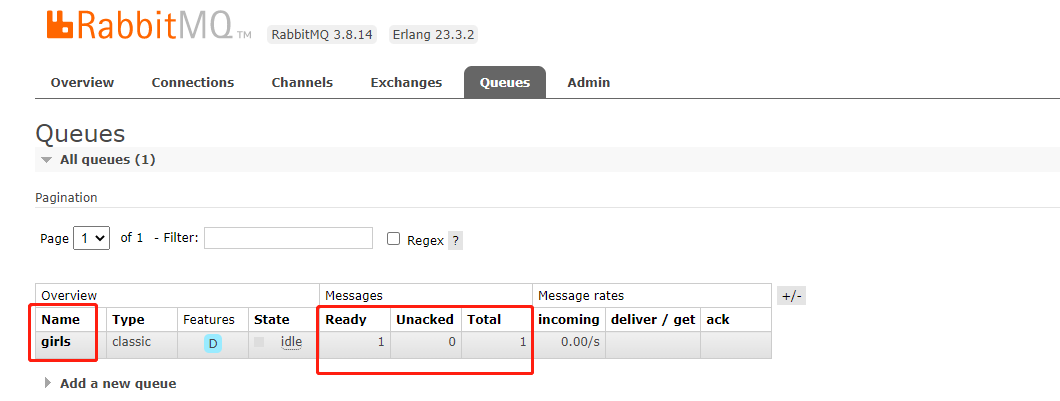
然后编写消费者的代码:
生产者如何生产消息我们知道了,那么消费者要如何消费消息呢?
from pprint import pprint
import pika
# 这几步和生产者是一样的
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 这里还是声明一个 queue,但是问题来了,刚才生产者明明已经声明了,消费者为什么还要再次声明呢?
# 尽管刚刚生产者已经声明了,但是实际工作中我们说不准生产者和消费者到底哪个先启动
# 如果消费者先启动,但是队列不存在,那么消费者要监听谁呢?
# 因此无论是生产者还是消费者,都要声明 queue。当然,如果你能确保该 queue 一定存在,那么也可以不声明
# 但是需要注意的是,生产者和消费者在声明同一个 queue 的时候,参数必须要一致
# 比如刚才生产者声明 girls 时指定了 durable=True,那么该队列创建之后是一个持久化队列
# 那么消费者在声明的时候也必须指定 durable=True,因为指定的属性要和已存在的队列保持一致
channel.queue_declare(queue="girls", durable=True)
# 定义一个回调函数
def on_message_callback(ch, method, properties, body):
pprint({"ch": ch, "method": method, "properties": properties, "body": body})
# 订阅
channel.basic_consume("girls",
on_message_callback=on_message_callback,
auto_ack=True)
# 这一步才算是真正开始消费,注意:此时消费者会阻塞
channel.start_consuming()
我们来解释一下 basic_consume 的相关参数:
第一个参数很简单,就是队列的名字。
第二个参数 on_message_callback 表示回调函数,消息发送给消费者后,会拆解成四个参数自动传递给回调函数,进行调用。
第三个参数 auto_ack 表示是否自动应答,说人话就是在将消息发送给消费者后,是否自动删除队列中的消息,默认为 False。如果为 True,那么消息发送给消费者后,会将消息从队列中删除;如果为 False,那么消息发送给消费者后,该消息依旧会坚挺在队列里面,不会被删除。我们当前队列里面有 1 条数据,如果设置 auto_ack 为 Flase,那么不管执行多少次,都会取得这条数据,要是再往里面塞两条,那么下一次消费者就会取得 3 条数据。这里我们就设置为 True,表示消息发送给消费者之后就从队列中删除。但是有经验的人可能会想到,万一消费者在消费的过程中出错了怎么办?毫无疑问要重新消费,但问题是该消息在发送给消费者之后就已经被删除了。所以是否有一种机制,就是消息在发送之后先不删除,只是做一个标记,表示该消息已经有消费者接收,而当消费者消费成功之后告诉 Server 自己消费成功、该消息可以删了之后,服务端再真正删除队列中的消息。显然该机制是存在的,因为这是任何一个成熟的消息中间件都必须满足的功能,不过具体怎么做我们一会单独说,目前就先将自动应答设置为 True。
第四个参数 exclusive 表示是否独占该队列,默认为 False。如果消费者在监听时指定为 True,那么其它消费者就无法再监听该队列了,当然指定为 True 的前提是该队列目前还没有被其它消费者监听。
第五个参数 consumer_tag 表示给消费者指定的标签,如果不指定会默认生成一个。
第六个参数 arguments 表示指定的高级特性,一个字典,暂时先不讨论。
然后启动消费者:

我们看到屏幕打印内容了,内容如下:
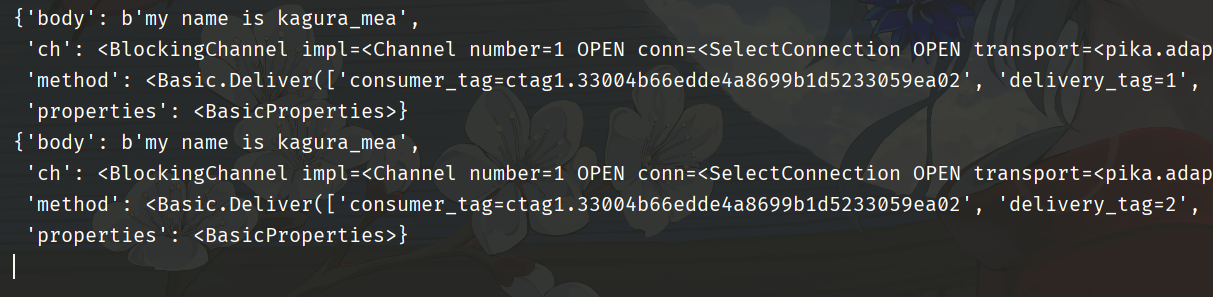
{'body': b'my name is kagura_mea',
'ch': <BlockingChannel impl=<Channel number=1 OPEN conn=<SelectConnection OPEN transport=<pika.adapters.utils.io_services_utils._AsyncPlaintextTransport object at 0x00000262F0D5A400> params=<ConnectionParameters host=47.94.174.89 port=5672 virtual_host=/ ssl=False>>>>,
'method': <Basic.Deliver(['consumer_tag=ctag1.33004b66edde4a8699b1d5233059ea02', 'delivery_tag=1', 'exchange=', 'redelivered=False', 'routing_key=girls'])>,
'properties': <BasicProperties>}
- ch:channel,可以通过 channel.params 拿到 IP、端口、虚拟地址等属性;
- method:生产者发送消息时带的一些参数,类似于 requests 请求网页的时候也会带一些请求头之类的;
- properties:消息的属性,先不管;
- body:消息体;
注意 'method' 对应的 value 里面的 consumer_tag,它就是给消费者指定的标签,可以在监听队列时通过参数指定,但不指定的话会默认生成一个。除此之外 method 里面还有 exchange、routing_key 等等,不过我们需要重点关注里面的 delivery_tag,我们说消息自动删除会导致消费者在消费失败之后没有再次重来的机会,因此应该指定 auto_ack 为 False,但是这就要求消费者消费完毕之后能够主动通知 Server 自己消费完毕了、请把队列中的消息删除掉,否则已经消费过的消息就会堆积在队列里,而 delivery_tag 就与此有关。
另外我们说生产者发送完消息之后程序就结束了,但是消费者会阻塞,因为会一直监听队列、等待消息。如果此时生产者再往队列里面发送一条消息的话,那么消费者会自动取出。
然后我们来查看一下队列:
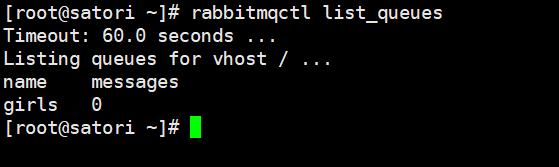
此时队列中消息也已经没了,因为消费的时候指定了 auto_ack 为 True,所以消息在消费者消费完毕之后就从队列中删除了。如果将 basic_consume 中的 auto_ack 参数指定为False,那么消费者消费完之后,队列中的这两条信息还会存在,不会被清除。
消息手动应答
下面说一下消息手动应答,就是上面说的那个问题。消费者完成一个任务可能需要一段时间,如果消费者在处理任务的过程中出错了,那么就没有重来的机会了。因此 RabbitMQ 引入了消息手动应答机制,消费者在接收到消息时,Server 端不会将消息删除,需要等消费者消费完毕之后,手动通知 Server 端自己处理完毕、请把消息删掉,然后 Server 端才会真正删除消息。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
channel.queue_declare(queue="girls", durable=True)
def on_message_callback(ch, method, properties, body):
print("消息处理······")
# 这里的 ch.basic_ack 就表示给服务端一个反馈,告诉服务端自己处理完了,可以将消息删掉了
# 参数 ch 就是下面的 channel,如果打印两者的 id 的话,会发现是一样的
# 但问题是服务端怎么知道自己要删除的消息就是消费者处理完的消息呢?没错就是通过这里的 delivery_tag
# 我们之前说 method 里面有个 delivery_tag,它是消息的一个标识、或者理解为序列号
# 通过指定 delivery_tag 即可确保消费者当前处理过后的,和通知 Server 端从队列中删除的是同一个消息
ch.basic_ack(delivery_tag=method.delivery_tag)
# 这里没有指定 auto_ack,因为不使用自动应答,而且这个参数默认是 False
channel.basic_consume("girls",
on_message_callback=on_message_callback)
channel.start_consuming()
启动消费者之后再启动生产者,会发现和之前一样,消息被消费、并且会从队列中删除。只不过之前是自动应答,现在是手动应答,而手动应答的方式就是通过 ch.basic_ack。
如果回调函数执行出错了,比如我们可以修改一下回调函数 on_message_callback,在 print 语句下面紧接着 raise 一个异常(模拟消费者执行出错),然后生产者发送一条消息,那么你会发现 print 语句正常打印、然后程序出错,但消息仍然在队列中。因为我们没有启用自动应答,那么在没有得到消费者的确认之前,服务端是不会擅自将消息从队列中删除的。然后我们再将 raise 异常这一行给删掉,重新启动消费者,那么之前没有消费成功的消息会重新消费,并且此次会消费成功、消息从队列中删除。
因此以上就解决了消息丢失的问题,但是这也隐含了消费者处理消息的速度和生产者生产消息的速度不能有太大差距。如果消费者的处理速度比生产者慢太多的话,那么消息就会积压在信道中(消息的传输和操作都是在信道中进行的),因为消费者还没有处理完,新的消息就又过来了。而如果积压的消息过多,那么有可能会导致内存耗尽,最终消费者线程会被操作系统强制杀死,所以这种模式仅适用于消费者处理消息的速度和生产者生产消息的速度差别不大的时候使用,当然前者比后者快则更好。
所以指定 auto_ack 为 True,那么消息发送之后会立即删除,消费者出错的话就相当于消息丢失了;指定 auto_ack 为 False,那么消息发送之后不删除,需要消费者主动给服务端一个反馈,然后服务端再删除,但消费者处理速度过慢的话则容易造成消息积压。
因此消息究竟是否采用自动应答,需要我们在高吞吐量和数据传输安全性方面做一个权衡。
那么这背后的机制是什么呢?
就像我们之前说的,在指定 auto_ack=False、然后将数据取走的时候,尽管这条消息不会被删除,但是会打上一个标记,表示这条消息已经被消费者接收了。如果消费者在之后又给服务端一个反馈,也就是手动应答,告诉服务端自己已经消费完了,那么这时候服务端就会将该消息从队列里面删掉,而消费者传递的 method.delivery_tag 则保证了删除的消息是自己消费的那条,而不是别的消息。
注:给消息打标记不是乱打的,它和消费者有关,用于标识该消息发送给了哪个消费者。
但是需要注意的一点,对于我们当前来说,如果启动了多个消费者,那么一条消息也只会被其中一个消费者消费。如果这条消息被已经被某个消费者接收了,那么不管有没有消费完,其它的消费者都不能再消费。另外,即便消费者消费完了(回调函数执行完毕),但如果没有给服务端反馈,那么服务端也会认为没有消费完。因为消费者是否消费完了消息,服务端是感知不到的,它确认的唯一手段就是消费者的反馈。
所以即使某个消费者消费的时间非常非常长,但只要这个消费者连接不断开,那么该消息就不会交给其它消费者,当然更不会删除,因为该消息已经被打上标记了(相当于已经出队)。但如果这个消费者出错、导致连接断开,那么服务端就会感知到该消费者挂掉了,那么之前给消息打的标记就会被清除(相当于重新入队),然后发给其它的某个消费者,并且消费者在断开连接之后,服务端以后也不会再将消息发送给该消费者了。因此手动应答机制便保证了消息不丢失,一定会被某个消费者处理完毕。
多个消费者
然后再来说一说多消费者监听,我们之前声明队列之后只有一个消费者监听,但很明显队列是可以被多个消费者监听的。但如果有多个消费者监听的话,这些消息要怎么发送呢?是把每条消息给所有消费者都发送一遍,还是只发送给其中一个消费者呢,显然我们上面刚说完,只会发给一个消费者。但是只发送给其中一个消费者的话,这个消费者又要如何选择呢?
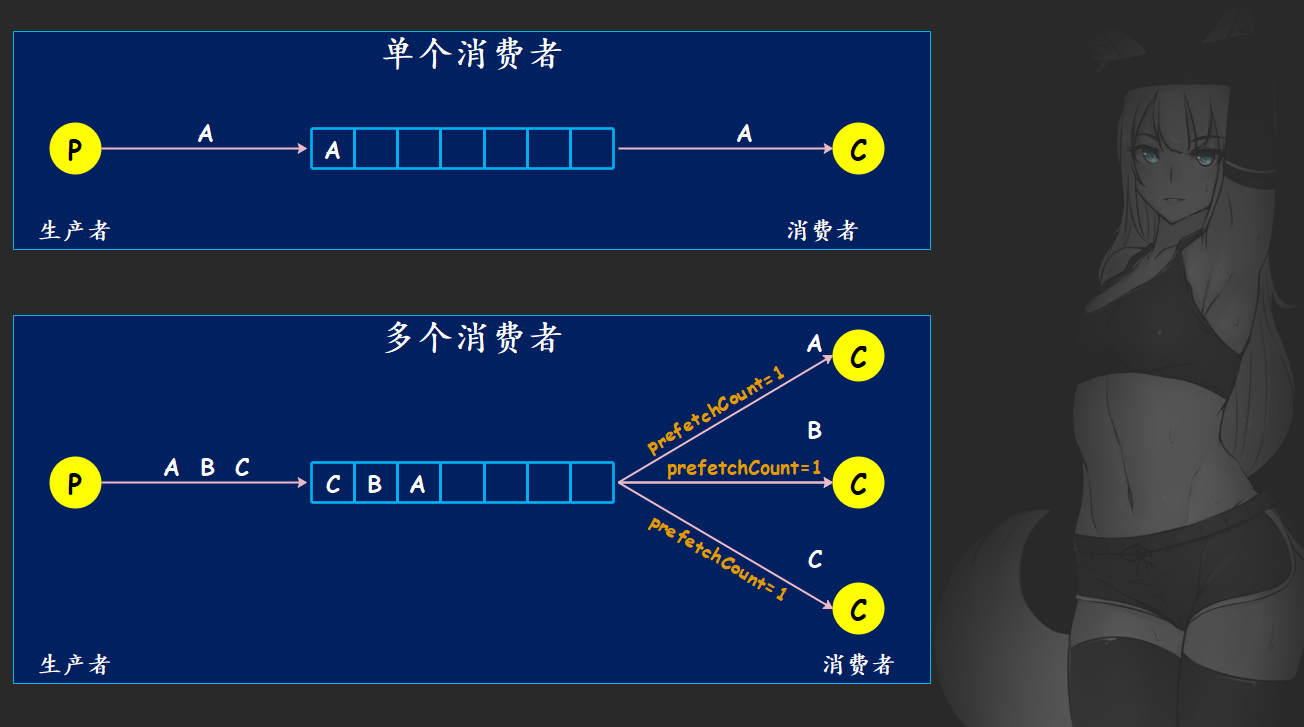
如果只有一个消费者,那么很简单,就是一对一;但如果有多个消费者,那么消息只会发送给其中一个消费者。并且选择消费者的方式也很简单,采用的是类似于轮询的方式,按照消费者先来后到的顺序不断地轮询,轮到谁了就将消息发给谁。因此最终会将队列中所有的消息都一条一条的发送给消费者,最后的结果就是队列中的消息会被消费者们平摊。
但是这里有一个问题,那就是不同的消费者处理消息的速度可能会不一样,这样就造成处理速度快的消费者会有很大一部分时间处于空闲之中。
我们举个栗子:假设有两个消费者 C1 和 C2,C1 处理一条消息要 1 秒钟,C2 处理一条消息要 10 秒钟,而此时队列中有 10 条消息。那么第一条消息给 C1、第二条消息给 C2、第三条消息给 C1、第四条消息给 C2······,然后 5 秒钟之后 C1 就将发给自己的消息全部消费完毕,但是 C2 连第一条消息都还没有消费完。最后的结果就是 C2 一直处于忙碌状态,而 C1 处于空闲之中。我们举个栗子:
消费者 C1:
def on_message_callback(ch, method, properties, body):
time.sleep(1)
print(f"[{datetime.datetime.now():%X}] 消费者 C1 消费了消息,消息内容: {str(body, encoding='utf-8')}")
channel.basic_consume("girls",
on_message_callback=on_message_callback,
auto_ack=True)
channel.start_consuming()
消费者 C2:
def on_message_callback(ch, method, properties, body):
time.sleep(10)
print(f"[{datetime.datetime.now():%X}] 消费者 C2 消费了消息,消息内容: {str(body, encoding='utf-8')}")
channel.basic_consume("girls",
on_message_callback=on_message_callback,
auto_ack=True)
channel.start_consuming()
以上是消费者 C1 和 C2 的代码,模块导入、建立连接、网络信道等部分代码省略了,和之前一样。而在回调函数内部,我们通过 time.sleep 来模拟耗时,当然为了方便这里就采用自动应答了,因为这里程序肯定是不会出错的。
然后是编写生产者代码:
channel.queue_declare(queue="girls", durable=True)
for i in range(1, 11):
channel.basic_publish(exchange="",
routing_key="girls",
body=f"我是第 {i} 条".encode("utf-8"))
同样只保留关键部分,这里我们发送了 10 条数据,我们看看结果是不是像我们之前分析的那样。

结果和我们说的是一样的,第 1、3、5、7、9 条消息发送给了 C1,第 2、4、6、8、10 条消息发送给了 C2。由于 C1 处理完一条消息需要 1 秒、C2 处理完一条消息需要 10 秒,所以 C1 处理完最后一条消息之后的 5 秒,C2 才处理完第一条消息,然后 C1 就一直处于空闲状态。
因此我们不应该采用平摊的方式,应该让处理速度快的消费者多处理一些消息,所以我们可以通过 prefetchCount 参数来限制每次发送给消费者消息的个数。之前不指定 prefetchCount 参数的时候,是消息轮到谁就发到谁的网络信道(Channel)中,即使该消费者当时还在处理当中。比如这里的消费者 C2,第 2 条消息还没有处理完,第 4、6、8、10 条消息就过来了,并存储在对应的网络信道中,即便处理的慢,但是发给某个消费者消息终将还是由该消费者处理完毕,因为消息已经存在对应的网络信道里面了。
但是消费者在消费消息的时候,假设指定了 prefetchCount 等于 n,那么表示该消费者正在处理的消息、加上即将处理的消息(也就是信道里面的消息)不能超过 n 条。比如 C2 在消费的时候指定 prefetchCount 等于 3,那么 Server 只会将第 2、4、6 条消息发给它,第 8 条消息就不会再接收了;因为正在处理的第 2 条消息,和即将处理的第 4、6 条消息加在一起,数量已经是 3 条了,所以 Server 就不会再将消息发给 C2 了。C2 如果想再接收消息,那么首先得把第 2 条消息处理完才行。
因此,如果我们将 prefetchCount 指定为 1,就意味着,必须等到消费者将手头上的消息处理完之后,Server 才能发送下一条。
一旦指定了 prefetchCount 之后,那么就不能采用自动应答了,需要消费者处理完之后手动应答,当手头上的消息小于 prefetchCount 时,服务端才会继续向该消费者发送消息。
消费者 C1:
def on_message_callback(ch, method, properties, body):
time.sleep(1)
print(f"[{datetime.datetime.now():%X}] 消费者 C1 消费了消息,消息内容: {str(body, encoding='utf-8')}")
ch.basic_ack(delivery_tag=method.delivery_tag)
# 将 prefetchCount 设置为 1
channel.basic_qos(prefetch_count=1)
# 将 auto_ack 设置为 False,不能采用自动应答
channel.basic_consume("girls",
on_message_callback=on_message_callback)
channel.start_consuming()
消费者 C2:
def on_message_callback(ch, method, properties, body):
time.sleep(10)
print(f"[{datetime.datetime.now() - datetime.timedelta(hours=1):%X}] 消费者 C2 消费了消息,消息内容: {str(body, encoding='utf-8')}")
ch.basic_ack(delivery_tag=method.delivery_tag)
# 将 prefetchCount 设置为 1
channel.basic_qos(prefetch_count=1)
channel.basic_consume("girls",
on_message_callback=on_message_callback)
channel.start_consuming()
启动消费者之后,我们再启动生产者,生产者代码不变。

我们看到第一条消息发给了 C1,第二条消息发给了 C2,之后由于 C2 处理的太慢,所以消息全部被 C1 消费了。因此这种方式就避免了出现某个消费者空闲的情况,但是注意的是,消费者处理完毕的时候一定要手动应答,给服务端一个反馈。
消息的持久化
之前我们说了队列的持久化,队列如果不持久化,那么 RabbitMQ 服务重启之后就会丢失。而声明持久化队列的方式可以通过指定 durable 参数为 True 实现,但如果队列已经存在、并且不是持久化队列,那么我们再声明为持久化队列就会报错,需要先将之前的队列删除,然后再重新声明持久化队列。但这只是队列的持久化,并不代表消息的持久化,消息默认是不持久化的,除非我们显式地标记它。
就像之前说的,消息持久化的前提是队列也要持久化,如果队列不持久化,那么消息持久化也没有任何意义。
我们之前创建了一个持久化队列 girls,我们通过 webUI 查看一下:
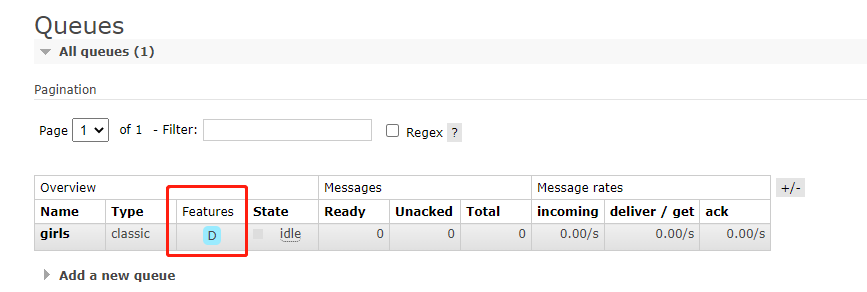
如果是持久化队列,那么 Features 会对应字母 D。
然后我们来看看消息如何持久化,首先消息持久化应该是由生产者设置还是由消费者设置呢?不用想肯定是生产者,因为消息是它发的,消费者只是负责消费。
对于消费者正常消费来说,消息是否持久化是没有任何区别的,消息持久化只是为了保证 RabbitMQ 服务重启之后消息不丢失。
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 队列一定要是持久化的,否则消息持久化没有任何意义
# 因为队列如果不持久化的,那么服务重启整个队列就没有了
channel.queue_declare(queue="girls", durable=True)
channel.basic_publish(exchange="",
routing_key="girls",
body=b"kagura_mea",
# 我们说 properties 表示消息的属性,之前没有指定它
# 现在派上用场了,它接收一个 pika.BasicProperties 对象
# 我们只需要指定 delivery_mode 等于 2 即可让消息持久化,等于 1 则是非持久化
properties=pika.BasicProperties(delivery_mode=2))
channel.close()
connection.close()
执行之后,即使服务重启消息也不丢失,但如果不对消息持久化,那么重启服务之后队列还在、但是消息没了。如果消息持久化但队列不持久化,那么重启之后队列、消息就都没了。所以消息持久化的前提是队列持久化,尽管我们可以将持久化的消息发送到非持久化的队列中,但是这没有任何意义。
注意:将消息标记为持久化并不能完全保证消息不丢失,尽管会告诉 RabbitMQ 将消息写入磁盘,但如果还没来得及写入(会先保存到 cache 中)、或者在写入的时候服务宕掉了,那么依旧会造成消息丢失。当然这种情况确实比较巧合,但也存在,不过对于我们当前这种简单任务队列而言是绰绰有余的,后面会介绍更强有力的持久化策略。
事务保证
我们上面说了,要想消息持久化必须满足两点:1. 队列是持久化的;2. 消息也是持久化的。但是这并不能百分百满足消息不丢失,因为 RabbitMQ 接收到消息并存储到磁盘上也是有一个过程的,但如果在这个过程中宕机了,消息仍然是会丢失的。并且最关键的就是,消息丢了,我们还不知道消息丢的是哪一条。
那么这个时候我们就可以通过事务来保证:
import time
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
channel.queue_declare(queue="girls", durable=True)
start = time.perf_counter()
for i in range(1000):
try:
# 将信道设置为事务模式,因为消息的相关操作都是在信道中进行的
channel.tx_select()
channel.basic_publish(exchange="",
routing_key="girls",
body=b"kagura_mea",
properties=pika.BasicProperties(delivery_mode=2))
# 进行提交,如果写入失败会报错,一旦报错之后我们就知道是哪一条消息丢了
channel.tx_commit()
except Exception:
# 失败了回滚,todo:打印丢失的消息
channel.tx_rollback()
print(time.perf_counter() - start) # 18.4678589
channel.close()
connection.close()
这里我们发送了 1000 条消息,通过发送消息的时候施加事务,可以在发布失败的时候可以打印出对应的消息,从而保证消息不丢失。但我们发现总用时是 18 秒,从效率上讲显然这不是一个令人满意的数字,因为一旦涉及到事务(加锁),都是重量级的操作。
如果我们 batch 化:
import time
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
channel.queue_declare(queue="girls", durable=True)
start = time.perf_counter()
try:
channel.tx_select() # 将信道设置为事务模式
for i in range(1000):
channel.basic_publish(exchange="",
routing_key="girls",
body=b"kagura_mea",
properties=pika.BasicProperties(delivery_mode=2))
# 事务只需要开启一次即可,后续生产者发布消息每次都需要提交
# 可以一条一条的提交,也可以 batch 化、批量提交,这里每一百条提交一次
if (i + 1) % 100 == 0:
channel.tx_commit()
except Exception:
channel.tx_rollback()
print(time.perf_counter() - start) # 0.291027
channel.close()
connection.close()
我们看到速度快的不是一点点,batch 化的好处就是批量提交,减少事务带来的开销,因为事务对性能的影响真的很大。生产环境中还是尽量不要使用事务,因为对性能的影响实在是太大了,如果真的需要,那么一定要 batch 化。然后消费者消费也是成功的,这里就不贴消费者代码了,和之前没有任何区别。
事实上,RabbitMQ 造成的信息丢失还是比较少见的。
交换机
RabbitMQ 消息传递模型的核心思想是:生产者生产的消息不会直接发送到队列,而是要先发送到交换机,尽管我们之前没有指定,但我们说 RabbitMQ 有一个默认的交换机。所以交换机的工作内容就是接收生产者的消息,并且按照指定的规则将消息推入队列,因此交换机必须清楚地知道如何处理接收到的消息,是把这些消息推送到特定队列、还是多个队列,亦或是丢弃它们,这要由交换机的类型决定。
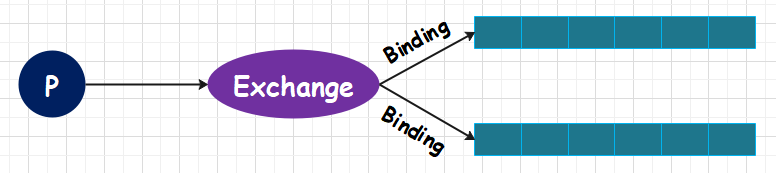
从图中我们看到,RabbitMQ 会通过 Binding 将 Exchange 和 Queue 绑定在一起,并且在绑定 Exchange 和 Queue 的同时,会指定一个 Binding key。而生产者将消息发送到 Exchange 的时候,也会带上一个 Routing key,Exchange 再将消息推送到 Binding Key 和 Routing Key 相匹配的 Queue 中。
但我们说交换机也是有类型的,总共有四种:direct、fanout、topic、headers,不同的类型的交换机会有不同的表现,我们分别介绍。
direct 交换机
默认的交换机类型就是 direct,direct 类型的交换机的路由规则非常简单,就是把消息路由到 Binding Key 和 Routing Key 相匹配的队列中。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 声明一个交换机,名称叫 "exchange"、类型是 "direct"
channel.exchange_declare("exchange", "direct")
# 声明队列,这里消费完了之后就直接删除
channel.queue_declare(queue="queue_1", auto_delete=True)
channel.queue_declare(queue="queue_2", auto_delete=True)
channel.queue_declare(queue="queue_3", auto_delete=True)
# 将交换机和队列进行绑定,前两个参数就是队列和交换机
# 第三个参数表示 Binding Key,只不过这里的参数名叫 routine_key,不影响
# 我们之前在使用默认的交换机的时候,Binding Key 是队列的名字
# 但是现在我们自己指定了,那么以后就要使用这里指定的名字
channel.queue_bind(queue="queue_1", exchange="exchange", routing_key="我是队列1")
channel.queue_bind(queue="queue_2", exchange="exchange", routing_key="我是队列2")
channel.queue_bind(queue="queue_3", exchange="exchange", routing_key="我是队列3")
# 然后我们发送消息,指定交换机、routing_key
# 但是 routing_key 不能用队列的名字,而是要使用我们自己绑定的名字(工作中不建议用中文)
# 我们往 queue_1 里面发一条、queue_2 发两条、queue_3 发三条
channel.basic_publish(exchange="exchange", routing_key="我是队列1", body=b"kagura_mea")
channel.basic_publish(exchange="exchange", routing_key="我是队列2", body=b"kagura_mea")
channel.basic_publish(exchange="exchange", routing_key="我是队列2", body=b"kagura_mea")
channel.basic_publish(exchange="exchange", routing_key="我是队列3", body=b"kagura_mea")
channel.basic_publish(exchange="exchange", routing_key="我是队列3", body=b"kagura_mea")
channel.basic_publish(exchange="exchange", routing_key="我是队列3", body=b"kagura_mea")
channel.close()
connection.close()
执行之后我们可以查看一下队列,这里我使用命令行,更推荐的做法是使用 webUI,更加的直观个清晰。
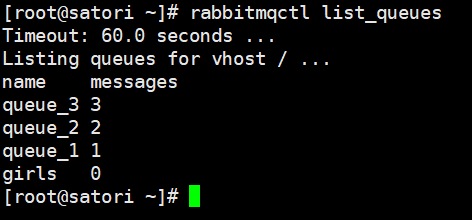
除了 girls 之外,还有我们新创建的三个队列,只不过我们新创建的队列是绑定在我们新创建的交换机上面的。
然后消费者进行消费:
import threading
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
def on_message_callback(ch, method, properties, body):
print(body.decode("utf-8"), f"channel id: {id(ch)}")
ch.basic_ack(delivery_tag=method.delivery_tag)
def consume_message(queue_name: str,
# routing_key: str
):
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
"""
# 对于消费者而言,同样需要声明交换机,理由和之前声明队列是一样的
channel.exchange_declare("exchange1", "direct")
# 生产者声明队列时指定了 auto_delete 为 True,这里也需要指定
channel.queue_declare(queue=queue_name, auto_delete=True)
# 绑定
channel.queue_bind(queue_name, "exchange", routing_key)
"""
# 由于我们可以确认生产者已经将上面的步骤都完成了,所以我们是可以注释掉的
# 如果不确定生产者和消费者谁先启动,那么就都需要重复一遍
# 消费者这里还是跟以前一样指定要监听的队列,但是我们并没有指定交换机,因为队列是唯一的
# 如果多个交换机绑定的队列的名字相同,那么它们绑定就是同一个队列,一会儿详细说
channel.basic_consume(queue_name,
on_message_callback=on_message_callback)
channel.start_consuming()
threading.Thread(target=consume_message, args=("queue_1",)).start()
threading.Thread(target=consume_message, args=("queue_2",)).start()
threading.Thread(target=consume_message, args=("queue_3",)).start()
启动消费者:
我们看到消费成功,然后再来看一下控制台:
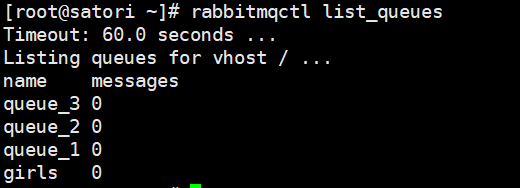
会发现队列中的消息已经没了,因为都被消费了,只不过队列还在。可我们不是指定了 auto_delete 为 True 吗,为啥队列还在呢?原因是消费者还没有断开连接,如果再将消费者停掉的话,那么队列就会被删除,这里我们断开消费者。
然后再来说一下队列和交换机的问题,消费者在消费的时候只指定了队列,却没有指定交换机,那么可能有人会好奇:如果两个交换机 exchange1、exchange2 都绑定了 queue 这个队列,那么消费者监听 queue 的时候监听的是哪一个交换机里面的 queue 呢?
事实上,同名的队列不可能存在多个,一个 Virtual Host 中只会有一个同名的队列,队列的隔离是在虚拟地址层面、不是在交换机层面。两个交换机绑定同一个队列,那么从两个交换机经过的消息最终也会进入到同一个队列中,我们举个栗子:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 声明两个交换机
channel.exchange_declare("exchange1", "direct")
channel.exchange_declare("exchange2", "direct")
# 声明队列
channel.queue_declare(queue="queue", auto_delete=True)
# 将交换机和队列绑定,两个交换机绑定同一个队列
channel.queue_bind(queue="queue", exchange="exchange1", routing_key="我是和 exchange1 绑定的队列")
channel.queue_bind(queue="queue", exchange="exchange2", routing_key="我是和 exchange2 绑定的队列")
# 然后我们发送消息
channel.basic_publish(exchange="exchange1", routing_key="我是和 exchange1 绑定的队列", body=b"kagura_mea")
channel.basic_publish(exchange="exchange2", routing_key="我是和 exchange2 绑定的队列", body=b"kagura_mea")
channel.close()
connection.close()
然后我们来查看队列:
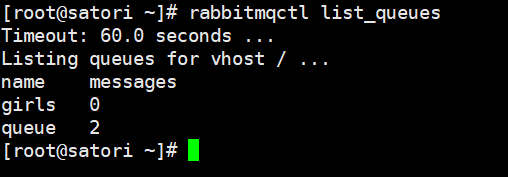
我们看到队列 queue 只有一个,但是里面有两条消息,说明两个交换机将消息都推送到了一个队列中,其实这一点在最开始的 RabbitMQ 架构图中就已经有体现了。
所以消费者在消费的时候不需要指定交换机(如果生产者把一切都弄好了的话),只需要指定队列即可,因为同一个虚拟地址下只会有一个队列。但是生产者发送的时候是需要指定交换机的,以及告诉交换机将消息推送到哪个队列的 routing key,如果我们这么指定的话:
channel.basic_publish(exchange="exchange2", routing_key="我是和 exchange1 绑定的队列", body=b"kagura_mea")
channel.basic_publish(exchange="exchange1", routing_key="我是和 exchange2 绑定的队列", body=b"kagura_mea")
这里我们将两个交换机调换一下位置,执行之后并不会报错,只是消息就直接扔掉了。因为:
和 exchange1 绑定的只有一个队列,binding key 叫 "我是和 exchange1 绑定的队列"和 exchange2 绑定的只有一个队列,binding key 叫 "我是和 exchange2 绑定的队列"
而我们上面将消息发到交换机之后,交换机找不到和 routing key 匹配的 binding key 对应的队列,所以消息就直接丢掉了,因此查看控制台会发现消息还是两条。所以生产者在发消息的时候,交换机和 routing key 要指定对。
这里就不启动消费者消费了,为了方便后续演示,直接将队列 queue 给删掉即可。
不同的队列指定相同的 Binding Key
另外,我们最开始是一个交换机 exchange 绑定了三个队列 queue_1、queue_2、queue_3,它们的 binding key 是不一样的,但其实不同的队列可以有相同的 binding key。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
channel.exchange_declare("exchange", "direct")
channel.queue_declare(queue="queue_1", auto_delete=True)
channel.queue_declare(queue="queue_2", auto_delete=True)
channel.queue_declare(queue="queue_3", auto_delete=True)
# binding key 全部是一样的,再次强调:这里的参数叫 routing_key,但是含义是 binding_key
channel.queue_bind(queue="queue_1", exchange="exchange", routing_key="我是队列")
channel.queue_bind(queue="queue_2", exchange="exchange", routing_key="我是队列")
channel.queue_bind(queue="queue_3", exchange="exchange", routing_key="我是队列")
# 我们进行发送,然后交换机会进行 routing_key 和 binding_key 的匹配
# 显然都可以匹配的上,因此这一条消息会发到三个队列中
channel.basic_publish(exchange="exchange", routing_key="我是队列", body=b"kagura_mea")
channel.close()
connection.close()
我们验证一下是不是这样子的:
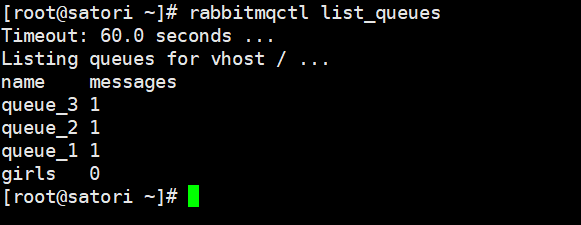
结果和我们想象的是一样的,其实这有点类似于发布订阅了,一旦发布,会推送到所有的队列中,不过对于这种场景,我们推荐使用 fanout 类型的交换机。
这里手动删除 queue_1、queue_2、queue_3 三个队列。
一个队列指定多个 Binding Key
除了不同的队列可以有相同的 binding key 之外,一个队列也可以有多个 binding key,举个栗子:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
channel.exchange_delete("exchange")
channel.exchange_declare("exchange", "direct")
channel.queue_declare(queue="queue_1", auto_delete=True)
channel.queue_declare(queue="queue_2", auto_delete=True)
channel.queue_declare(queue="queue_3", auto_delete=True)
# 我们看到给 queue_3 绑定了三次
channel.queue_bind(queue="queue_1", exchange="exchange", routing_key="我是队列1")
channel.queue_bind(queue="queue_2", exchange="exchange", routing_key="我是队列2")
channel.queue_bind(queue="queue_3", exchange="exchange", routing_key="我是队列1")
channel.queue_bind(queue="queue_3", exchange="exchange", routing_key="我是队列2")
channel.queue_bind(queue="queue_3", exchange="exchange", routing_key="我是队列3")
# routing_key 为 "我是队列1" 的时候,显然消息会传到 queue_1 和 queue_3
# routing_key 为 "我是队列2" 的时候,显然消息会传到 queue_2 和 queue_3
# routing_key 为 "我是队列3" 的时候,显然消息会传到 queue_3
channel.basic_publish(exchange="exchange", routing_key="我是队列1", body=b"kagura_mea")
channel.basic_publish(exchange="exchange", routing_key="我是队列2", body=b"kagura_mea")
channel.basic_publish(exchange="exchange", routing_key="我是队列3", body=b"kagura_mea")
channel.close()
connection.close()
一个队列可以有多个 Binding key,那么只要有一个能匹配上 Routing Key,消息就会发送到该队列里。因此 queue_1 里面有一条、queue_2 里面有两条、queue_3 里面有三条。
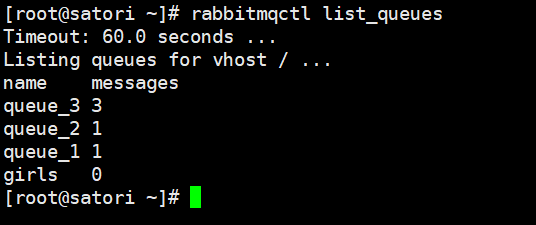
打印的结果和我们分析的是一样的,这里就不消费了,消费者代码不需要改变。当然为了后续方便,这里仍然手动将队列删除,但是队列 girls 就不删了,毕竟从一开始就陪着我们,人总是会念旧的。
fanout 交换机
然后是 fanout 类型的交换,它的路由规则更加简单,它会把消息推送到所有与它绑定的队列中。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 我们之前已经声明了一个交换机叫 exchange,类型为 direct
# 如果再次声明一个已存在的交换机,那么类型要和已存在的交换机保持一致,否则报错
# 但这里我们就是想修改交换机的类型,所以只能先删掉,然后重新创建
# 当然你也可以创建一个名字不为 exchange 的交换机,这样就不需要先删除、再创建了
channel.exchange_delete("exchange")
# 删除之后重新创建
channel.exchange_declare("exchange", "fanout")
channel.queue_declare(queue="queue_1", auto_delete=True)
channel.queue_declare(queue="queue_2", auto_delete=True)
channel.queue_declare(queue="queue_3", auto_delete=True)
channel.queue_bind(queue="queue_1", exchange="exchange")
channel.queue_bind(queue="queue_2", exchange="exchange")
channel.queue_bind(queue="queue_3", exchange="exchange")
# 此时绑定的时候就不需要 binding key 和 routing key 了,因为会广播给每一个队列
# 但由于发布消息的 routing_key 是一个必传参数,所以直接指定为空字符串
channel.basic_publish(exchange="exchange", routing_key="", body=b"kagura_mea")
channel.close()
connection.close()
查看一下控制台:
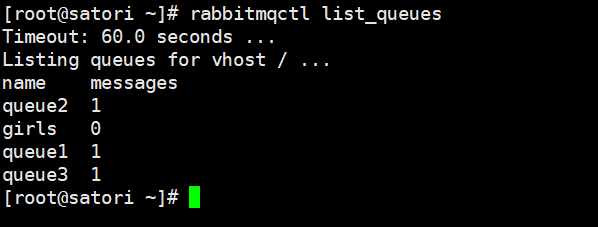
我们看到每个队列都接收到了消息,还是比较简单的。不过我们上面包含了将交换机删除这一步,因为一个交换机已经存在的话,那么它的类型就固定了,我们再声明的时候类型就要与其保持一致,这和队列是类似的。但我们就是想修改类型,所以采取了先删除、再创建的做法。除了删除交换机之外,还有其它的一些 API:
channel.queue_delete:删除某个队列channel.queue_unbind:取消队列和交换机的绑定,比如你在绑定之后发现 binding key 写错了,那么就可以先取消绑定、再重新绑定。因为一旦绑定到某个交换机之后,binding key 就无法改变了,即使重新绑定也是没有作用的,必须先取消绑定channel.queue_purg:清空队列中的所有消息
像删除队列、清空队列、删除交换机,在工作中不推荐使用。
以上就是 fanout,这种交换机适合发布订阅,不过上面用 direct 类型的交换机也可以实现类似的效果。
topic 交换机
无论是 direct 交换机还是 fanout 交换机,它们都有点不够灵活,为什么这么说呢。direct 交换机要求 routing key 和 binding key 必须完全匹配,而 fanout 交换机则是不管 routing key 和 binding key、直接将消息推送至所有队列。但很多时候,我们希望将消息推送到指定的一批队列里面,比如很多关于日志的队列,但是按照功能分成了正常日志和错误日志,我现在就想将消息只推送到错误日志对应的队列里面、或者只推送到正常日志对应的队列里面。当然采用 direct 交换机是可以实现的,只要把所有错误日志的队列以相同的 binding key(比如 "info")、正常日志的队列也以相同 binding key(比如 "info")绑定在交换机上即可。
但我们更推荐的做法是采用 topic,它的规则是采用模糊匹配,只要 routing key 和 binding key 能匹配上即可。只不过它的模糊匹配和一般的模糊匹配还不太一样,一般的模糊匹配是以字符为单位,而 topic 对应的模糊匹配则是以单词为单位。
对于 topic 类型的交换机,binding key 应该是以 . 号分隔的字符串(被 . 号分隔开的每一段独立的字符串称为一个单词),比如:"hello.cruel.world"、"hello.beautiful.world" 等等。但是 binding key 内部存在两种特殊字符 * 和 #,其中 * 可以匹配任意一个单词,# 可以匹配任意多个单词(也可以是 0 个)。
我们举例说明:
binding key 等于 hello.cruel.world,那么 routing key 也必须为 hello.cruel.world 才能匹配binding key 等于 hello.*.world,那么 routing key 可以是 hello.cruel.world、hello.beautiful.world,都能匹配binding key 等于 *.*.world,那么 routing key 可以是 hello.cruel.world、hello.beautiful.world、fuck.you.world,都能匹配binding key 等于 *.*,那么 hello.world 可以匹配,hello.cruel.world 不能匹配,因为单词数量不一样binding key 等于 #.world,那么 hello.cruel.world、hello.world 都可以匹配,因为 # 代表任意个单词binding key 等于 #,那么所有的 routing key 都可以匹配
所以这里的模糊匹配是以单词为基准的,另外我们可以看出,如果 binding key 中不包含 * 或 #,那么交换机类型等价于 direct;如果 binding key 等于 #,那么交换机类型等价于 fanout。我们测试一下:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 这里将之前的交换机和队列全删掉
channel.exchange_delete("exchange")
for queue_name in ("queue_1", "queue_2", "queue_3"):
channel.queue_delete(queue_name)
# 创建一个新的交换机,名字叫 logs、类型是 topic
channel.exchange_declare("logs", "topic")
# 声明队列
channel.queue_declare(queue="info1", auto_delete=True)
channel.queue_declare(queue="info2", auto_delete=True)
channel.queue_declare(queue="error1", auto_delete=True)
channel.queue_declare(queue="error2", auto_delete=True)
channel.queue_bind(queue="info1", exchange="logs", routing_key="info.*.log")
channel.queue_bind(queue="info2", exchange="logs", routing_key="info.*.log")
channel.queue_bind(queue="error1", exchange="logs", routing_key="error.*.log")
channel.queue_bind(queue="error2", exchange="logs", routing_key="error.*.log")
# 发送到 info1 和 info2 中
channel.basic_publish(exchange="logs", routing_key="info.day1.log", body=b"kagura_mea")
# 发送到 info1 和 info2 中
channel.basic_publish(exchange="logs", routing_key="info.day2.log", body=b"kagura_mea")
# 发送到 error1 和 error2 中
channel.basic_publish(exchange="logs", routing_key="error.day1.log", body=b"kagura_mea")
# 无法匹配,直接丢弃
channel.basic_publish(exchange="logs", routing_key="info.error", body=b"kagura_mea")
# 所以发布之后,队列 info1 和 info2 里面都有 2 条
# error1、error2 里面只有 1 条
channel.close()
connection.close()
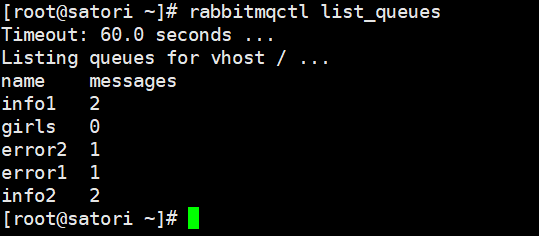
结果是正确的,当然我们上面的 binding key 设置的没有什么技术含量,完全可以用 direct 替代,所以可以再考虑一个场景:有三个队列,负责存放书籍信息,如果这本书是 Python web 方向的,那么发送到第一个队列中;如果是 Python 大数据方向的,那么发送到第二个队列中;如果是 Python 方向的(包含 web 和大数据),那么发送到第三个队列。此时就可以这么绑定:
channel.queue_bind(queue="python_web", exchange="book", routing_key="python.web.*")
channel.queue_bind(queue="python_bigdata", exchange="book", routing_key="python.bigdata.*")
# 如果进入了前两个队列,那么必定也会进入第三个队列
channel.queue_bind(queue="python", exchange="book", routing_key="python.#")
如果是这个场景,那么用 topic 要远比 direct 方便。比如一本书是 FastAPI,那么发送消息的时候就可以将 routing key 指定为 python.web.fastapi,那么消息就会进入第一个队列和第三个队列。
headers 交换机
headers 类型的 Exchange 不依赖于 routing key 与 binding key 的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。
在绑定 Queue 与 Exchange 时指定一组键值对,当消息发送到 Exchange 时,RabbitMQ 会取到该消息的 headers(也是一个键值对),对比其中的键值对是否完全匹配 Queue 与 Exchange 绑定时指定的键值对,如果完全匹配则消息会路由到该 Queue,否则不会路由到该 Queue。
下面演示一下:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 为方便观察,这里将之前的交换机和队列全删掉
channel.exchange_delete("logs")
for queue_name in ("info1", "info2", "error1", "error2"):
channel.queue_delete(queue_name)
# 创建一个新的交换机,名字叫 logs、类型是 headers
# 通过指定 auto_delete 参数为 True,当绑定在交换机上的队列被删除之后,该交换机也会被删除
channel.exchange_declare("exchange", "headers", auto_delete=True)
# 声明队列
channel.queue_declare(queue="queue1", auto_delete=True)
channel.queue_declare(queue="queue2", auto_delete=True)
# 这里无需指定 binding key,因为路由消息不再依赖它
# 但是需要指定键值对,通过参数 arguments 指定
channel.queue_bind(queue="queue1", exchange="exchange", arguments={"a": 1, "b": 2})
channel.queue_bind(queue="queue2", exchange="exchange", arguments={"a": 11, "b": 22})
# 发布消息也指定键值对,会将两个键值对进行匹配,所以消息会进入到 queue1 中,不会进入到 queue2
channel.basic_publish(exchange="exchange", routing_key="", body=b"kagura_mea",
properties=pika.BasicProperties(headers={"a": 1, "b": 2}))
channel.close()
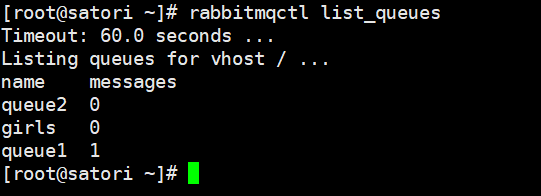
connection.close()
以上就是交换机的几种类型,功能还是蛮丰富的,但是我们需要注意的是:声明交换机的时候也可以指定 passive、durable、auto_delete 等参数,声明交换机和声明队列的参数类似,因此交换机也有持久化和非持久化。如果声明交换机不指定持久化,那么服务重启之后该交换机就会被删除,绑定在该交换机上的队列会与之脱离关系,并且移交给默认的交换机(前提是队列是持久化的,否则也会被删除)。
仍然删除队列,队列删除之后交换机也会被删除,因为我们在声明交换机的时候指定了 auto_delete 为 True。
死信队列
一般来说,生产者将消息发送到交换机、交换机再推送到队列之后,消费者就可以从队列中取出消息进行消费,但因为某些特定的原因导致队列中的消息无法被消费者正常消费,这样的消息如果没有后续的处理,那么我们称之为死信,有死信自然就有死信队列。
当消费者消费失败时,可以把消费失败的消息投入死信队列,当故障排查完毕之后,再将死信队列中的消息重新消费,从而防止消息丢失;再比如用户下单之后,可以不立刻付钱,但是会有一个时间限制,比如在多少时间未付款,订单将被取消,这也是由死信队列负责记录的。
那么死信是如何产生的呢?主要有以下三点:
1. 消息 TTL 过期,假设某条消息存活时间是 10 秒钟,如果在 10 秒钟之内没有被消费,那么此消息就过期了,一旦过期就不能被消费了。
2. 队列满了,无法再添加数据到队列,此时也会产生死信。
3. 消息被拒绝,我们之前是通过 channel.basic_ack 给服务端一个反馈,这个反馈是正向反馈,表示消费完了。但也可以给一个表示拒绝的反馈,意思是这条消息我处理不了(否定应答),并且也不把消息重新放回正常队列中,那么这种消息也会转移到死信队列中,因为消费者处理不了,所以先拒绝掉,等到后续再处理。
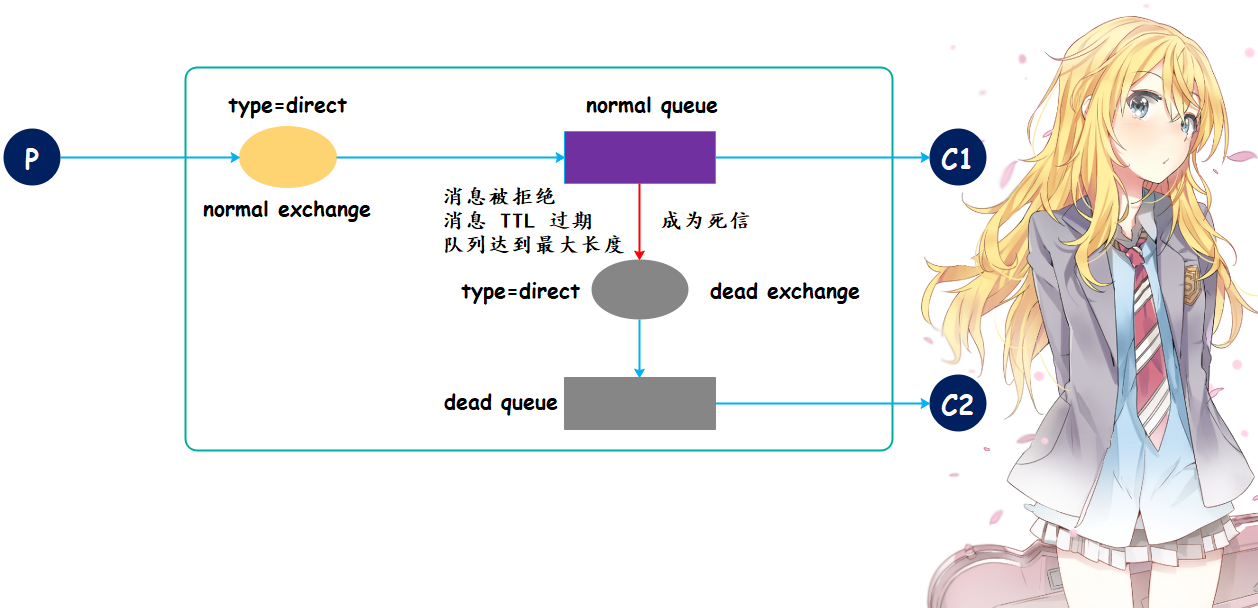
正常情况下消息会被 C1 消费,但是因为某些原因导致无法被消费,那么消息就会被转移到死信交换机、再推送到死信队列,然后由 C2 专门负责消费,因为消息不能丢。下面编写代码,首先编写消费者 C1,因为它最复杂。
import pika
class Consumer:
NORMAL_EXCHANGE = "normal_exchange"
NORMAL_QUEUE = "normal_queue"
DEAD_EXCHANGE = "dead_exchange"
DEAD_QUEUE = "dead_queue"
def __init__(self):
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
self.channel = connection.channel()
def declare(self):
"""声明普通和死信交换机、队列"""
# 通过指定 auto_delete 参数为 True,当绑定在交换机上的队列被删除之后,该交换机也会被删除
self.channel.exchange_declare(self.NORMAL_EXCHANGE, "direct")
self.channel.exchange_declare(self.DEAD_EXCHANGE, "direct")
# 然后声明队列,注意:我们说正常队列里面的消息在无法消费的时候,要转移到死信交换机、再进入到死信队列
# 而这一步是由正常队列来做的,但是我们必须要设置一些参数才能实现这一点,而这个参数就是通过 arguments 来设置的
self.channel.queue_declare(
self.NORMAL_QUEUE,
arguments={
# key 是固定写法,表示当消息不能被消费时转移到死信交换机
"x-dead-letter-exchange": self.DEAD_EXCHANGE,
# 但是死信交换机在收到消息之后如何推送到死信队列呢?所以还要指定 routing key
# 这个 routing key 和后续绑定死信交换机与死信队列时的 routing key 要保持一致
# 如果不一致,那么显然消息就推不到死信队列中了
"x-dead-letter-routing-key": "dead",
# 但我们还要让消息能够成为死信,因为就我们目前来说,消息是很难成为死信的
# 所以我们可以设置一个过期时间,表示此队列中的消息必须在指定时间内被消费,否则就会成为死信,就不能被消费了
# "x-message-ttl": 1000 * 10,通过这种方式即可设置,单位是毫秒
# 但是这里一旦设置之后就不可以改了,不够灵活,应该由生产者发消息的时候指定过期时间
# 事实上,如果队列设置了 "x-message-ttl",那么该队列会有一个专有名词:延迟队列,我们后面会说
}
)
self.channel.queue_declare(self.DEAD_QUEUE)
# 正常队列设置的有点多,但是死信队列不需要做什么工作,下面进行绑定
# 注意:queue_bind 里面也有一个 arguments 参数,不过它是 headers 类型的交换机路由用的,不要搞混了
self.channel.queue_bind(self.NORMAL_QUEUE, self.NORMAL_EXCHANGE, routing_key="normal")
self.channel.queue_bind(self.DEAD_QUEUE, self.DEAD_EXCHANGE, routing_key="dead")
def on_message_callback(self, ch, method, properties, body):
print(f"消费者 C1 收到消息:{body.decode('utf-8')}")
ch.basic_ack(delivery_tag=method.delivery_tag)
def main(self):
self.declare()
self.channel.basic_consume(self.NORMAL_QUEUE,
on_message_callback=self.on_message_callback)
self.channel.start_consuming()
c1 = Consumer()
c1.main()
以上就是生产者 C1,这里我们先启动它,然后会创建死信交换机、死信队列、正常交换机、正常队列,以及关系绑定。另外我们在声明正常队列时设置了 arguments 参数,指定了死信交换机,表示当消息无法被消费的时候就转移到指定的死信交换机中。
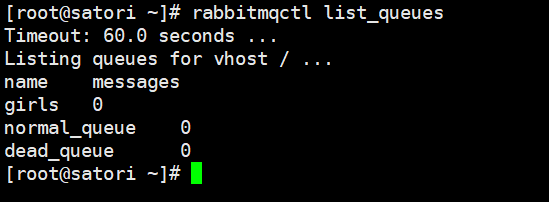
队列已经创建完毕,再来看一下 webUI:
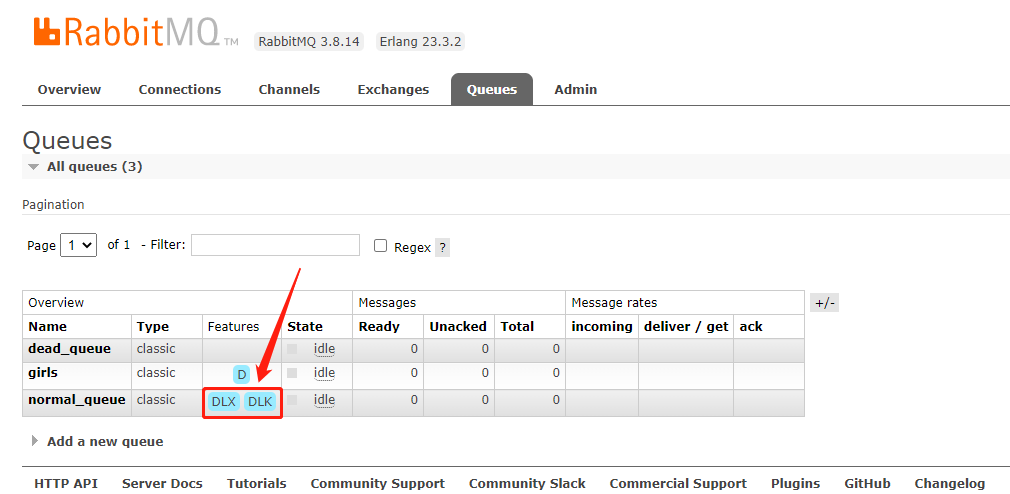
通过 Features 也证明了 normal_queue 绑定了死信交换机。
然后我们编写生产者的代码,由生产者发送带时间限制的消息。但是这里的消费者 C1 需要暂时先停掉,因为不停掉的话生产者发消息会直接被 C1 接收并处理,所以这里我们停掉 C1,然后等待让生产者发的消息过期,转移到死信队列。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 我们先启动消费者,消费者已经声明了,所以生产者这里就直接发了
channel.basic_publish(exchange="normal_exchange",
routing_key="normal",
body=b"kagura_mea",
# 生产者给消息指定的过期时间,算是消息的一个属性,因此通过 properties 参数设置
# 这里设置 10 秒后过期,但是我们需要转成字符串
properties=pika.BasicProperties(expiration=str(1000 * 10)))
channel.close()
connection.close()
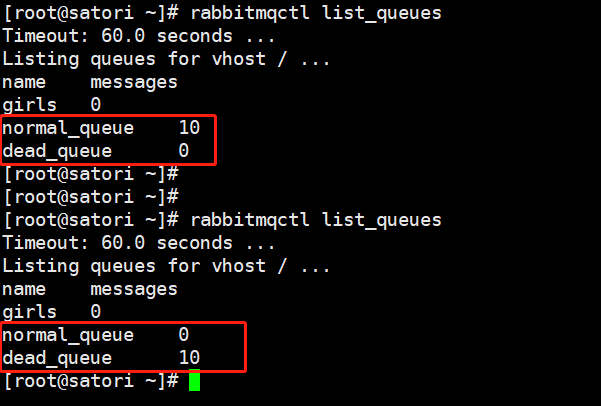
首先消息会进入到正常交换机,然后被推送到正常队列,所以 normal_queue 里面的消息数量是 1;然后 10 秒钟之后,由于消息一直没有被消费,那么会被转移到死信交换机、再被推送到死信队列,所以 10 秒中之后 normal_queue 的消息数量会变成 0,dead_queue 的消息数量会变成 1。
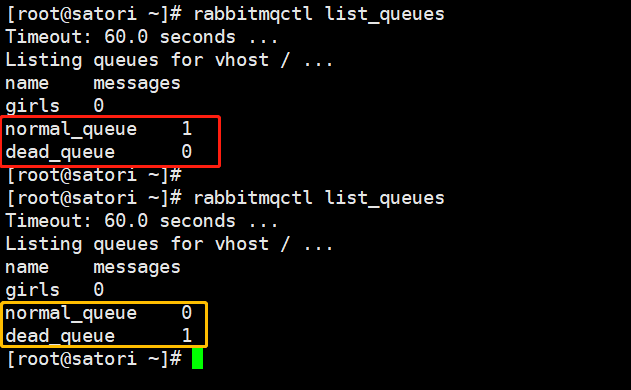
结果和我们想象的是一样的,然后 C2 负责监听死信队列,然后消费里面的消息。但显然 C2 就非常简单了,就是一个普通的消息消费,不需要像 C1 那样要做很多额外的工作。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
def on_message_callback(ch, method, properties, body):
print(body.decode("utf-8"))
ch.basic_ack(delivery_tag=method.delivery_tag)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
channel.basic_consume("dead_queue", # 指定死信队列,说白了也是一个普通的队列
on_message_callback=on_message_callback)
channel.start_consuming()

成功接收到消息,如果以订单为例,那么用户下单之后就相当于往 normal_queue 里面发一条消息,但是用户必须在两个小时内付款,因此发消息的时候要设置超时时间。如果用户在两个小时内没有付款,那么订单就会因为超时被取消,消息就会进入死信队列 dead_queue 中,再由专门的消费者负责记录这些超时的订单。
然后再来查看一下控制台:
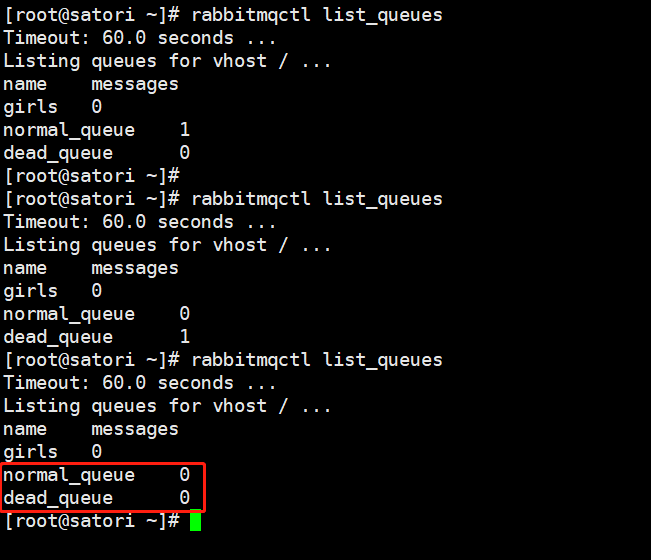
消息都是 0,因此以上就是死信队列的原理和相关操作,说白了就是在消息无法被消费的时候转移到一个新的队列中,而这个队列被称为死信队列,但是死信队列也是一个队列,它的消费和正常队列并无二致。
队列达到最大长度
上面消息能成为死信是因为我们设置了过期时间,但我们说还有两种情况,其中一个是队列达到最大长度,下面来看一下。
self.channel.queue_declare(
self.NORMAL_QUEUE,
arguments={
"x-dead-letter-exchange": self.DEAD_EXCHANGE,
"x-dead-letter-routing-key": "dead",
"x-max-length": 6 # 队列的最大长度是 6
}
)
之前的消费者 C1 不需要变,只需要在声明正常的队列的时候指定一个容量即可。但是这个队列之前已经声明了,容量是没有限制的,所以这里直接执行的话会报错,因为属性必须保持一致。所以这里需要先将之前的正常队列给删掉,然后再执行消费者 C1,这样就创建了一个容量为 6 的正常队列。
for i in range(10):
channel.basic_publish(exchange="normal_exchange",
routing_key="normal",
body=b"kagura_mea")
这里生产者发送 10 条消息,由于队列的容量是 6,所以先往正常队列里面发 6 条,然后剩余的 4 条进入死信队列。注意:执行生产者的时候需要先将消费者 C1 给暂停掉。
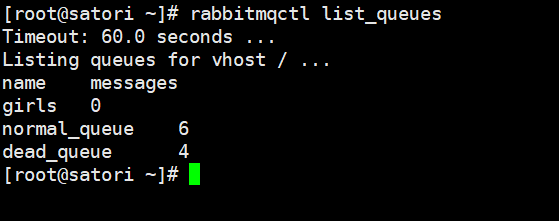
结果和我们分析的一样,下面手动将队列删除。
消息被拒
消息称为死信我们已经介绍了两种,还剩下最后一种,也就是消息被拒绝。消息发送给 C1 之后,C1 表示这消息我不处理、我拒绝(だが、断る),消息也会进入死信队列,而 C1 拒绝的方式就是通过否定应答。
import pika
class Consumer:
NORMAL_EXCHANGE = "normal_exchange"
NORMAL_QUEUE = "normal_queue"
DEAD_EXCHANGE = "dead_exchange"
DEAD_QUEUE = "dead_queue"
def __init__(self):
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
self.channel = connection.channel()
def declare(self):
self.channel.exchange_declare(self.NORMAL_EXCHANGE, "direct")
self.channel.exchange_declare(self.DEAD_EXCHANGE, "direct")
self.channel.queue_declare(
self.NORMAL_QUEUE,
arguments={
"x-dead-letter-exchange": self.DEAD_EXCHANGE,
"x-dead-letter-routing-key": "dead",
}
)
self.channel.queue_declare(self.DEAD_QUEUE)
self.channel.queue_bind(self.NORMAL_QUEUE, self.NORMAL_EXCHANGE, routing_key="normal")
self.channel.queue_bind(self.DEAD_QUEUE, self.DEAD_EXCHANGE, routing_key="dead")
def on_message_callback(self, ch, method, properties, body):
# 生产者一会儿会发送 10 条消息,内容是:"kagura_mea1"、"kagura_mea2"、......、"kagura_mea10"
if body in (b"kagura_mea2", b"kagura_mea5"):
# 当 body 为 "kagura_mea2" 或者 "kagura_mea5" 的时候,我们给拒绝掉
print(f"消费者 C1 从正常队列收到消息:{body.decode('utf-8')},但是拒绝了")
# 我们说拒绝消息需要给一个否定应答,表示一下
# 不过上面该打印还是可以打印的
# 肯定应答是通过 basic_ack,否定应答是通过 basic_reject
# delivery_tag 参数不需要解释,requeue=False 表示不放回正常队列,不放回正常队列就会成为死信
ch.basic_reject(delivery_tag=method.delivery_tag, requeue=False)
else:
print(f"消费者 C1 从正常队列收到消息:{body.decode('utf-8')}")
ch.basic_ack(delivery_tag=method.delivery_tag)
def main(self):
self.declare()
self.channel.basic_consume(self.NORMAL_QUEUE,
on_message_callback=self.on_message_callback)
self.channel.start_consuming()
c1 = Consumer()
c1.main()
以上是 C1,然后编写 C2,C2 的代码和之前是一样的。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
def on_message_callback(ch, method, properties, body):
print(f"消费者 C2 从死信队列接收到消息:{body.decode('utf-8')}")
ch.basic_ack(delivery_tag=method.delivery_tag)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
channel.basic_consume("dead_queue",
on_message_callback=on_message_callback)
channel.start_consuming()
这里我们将 C1 和 C2 都启动起来,然后生产者发送 10 条消息:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
for i in range(1, 11):
channel.basic_publish(exchange="normal_exchange",
routing_key="normal",
body=f"kagura_mea{i}".encode("utf-8"))
channel.close()
connection.close()
启动完毕之后查看控制台输出:
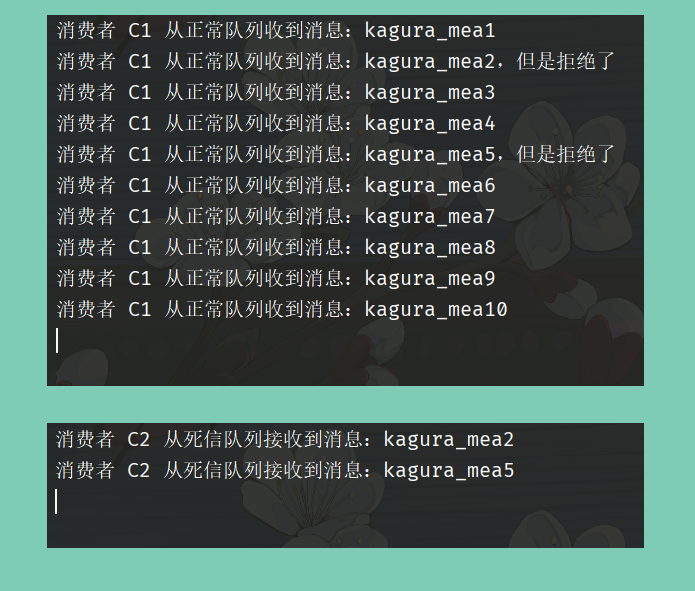
以上就是死信的产生以及死信队列使用方式,这里就全部介绍完了,另外个人强烈建议多查看一下 webUI,交换机、队列的所有信息都在上面,非常的直观。
延迟队列
如果一个消息需要在指定时间之后、或者截止到指定时间之前被消费,那么该消息就可以看做是延迟消息,而存放延迟消息的队列自然就是延迟队列。
那么延迟队列都有哪些使用场景呢?比如:
订单在十分钟之内未支付则自动取消新创建的店铺,如果十天内都没有上传过商品,则自动发送短信提醒用户注册后,如果三天内没有进行登录,则发送短信提醒用户发起退款,如果三天内没有得到处理则通知相关相关运营人员预定会议后,需要在预定的时间点之前十分钟通过各个与会人员参加会议
关于延迟我们在介绍死信队列的时候说过,只不过我们当时在模拟延迟的时候,是生产者发送的消息带有延迟属性,而延迟队列是只要消息存到该队列里面了,那么就有延迟属性。而一个队列如果想成为延迟队列,那么通过 "x-message-ttl" 设置延迟时间即可,只不过当时我们说这么做不够灵活,应该由生产者发送消息时设置延迟时间。但其实有些业务场景的延迟时间是固定的,那么这个时候将队列声明为延迟队列是很合适的。
以上这些场景都有一个特点,那就是需要在某个事件发生之后或者之前的指定时间点完成某一项任务,比如:订单生成事件,在十分钟之后检查该订单支付状态,然后将未支付的订单进行关闭。看起来似乎使用定时任务,一直轮询数据,取出需要被处理的数据进行处理,这种做法也很方便。当然如果数据量比较少,并且 "账单一周内未支付则进行自动结算" 这样的需求对于时间不是严格限制,而是宽松意义上的一周,那么每天晚上跑个定时任务检查一下所有未支付的账单,确实也是一个可行的方案。但对于数据量比较大,并且时效性较强的场景,如:"订单十分钟内未支付则关闭"这种短期内未支付的订单数据可能会有很多,活动期间甚至会达到百万甚至千万级别,对这么庞大的数据量仍旧使用轮询的方式显然是不可取的,很可能在一秒内无法完成所有订单的检查,同时会给数据库带来很大压力,无法满足业务要求而且性能低下。
我们举个实际的栗子:
以在 12306 抢票为例,用户抢到票之后会前往付款页面,此时会生成一个状态为未支付的订单,生成订单之后提醒用户三十分钟内付款,同时将订单信息记录到延迟队列中(时间为三十分钟)。如果用户在三十分钟内付了款,那么将订单状态改为已支付,并修改票的状态(此票已被购买);三十分钟之后监听延迟队列的消费者会从中获取到消息,不管用户是否付款,该消息三十分钟后都会被消费者接收,而消费者要做的事情就是确认订单状态,如果查询之后发现用户已经付款了,那么就什么也不做,但如果没有付款,那么就修改的票的状态(此票可以购买)。
因为票除了 "可购买" 和 "已被购买" 之外还有一个状态,就是用户已经下单、但是还没有付款时候的状态,处于这个状态,那么票也是不可以被购买的。如果在规定时间内用户付了款,那么就将票的状态改成 "已被购买",如果此用户不退票、那么其它人就真的没法再买了;同时三十分钟后,消费者会收到消息,根据消息查询订单的付款状态,如果付了钱、那没事了;但如果没有付钱,就要将票的状态重新改成 "可购买"。
下面我们来演示一下,还是以之前的代码为例,只需要声明正常队列的时候设置一个延迟时间即可。注意:我们依旧需要使用死信队列,只不过消息 TTL 过期的方式变了,之前是通过生产者设置的,现在是通过将正常队列声明为延迟队列。
import pika
class Consumer:
NORMAL_EXCHANGE = "normal_exchange"
NORMAL_QUEUE = "normal_queue"
DEAD_EXCHANGE = "dead_exchange"
DEAD_QUEUE = "dead_queue"
def __init__(self):
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
self.channel = connection.channel()
def declare(self):
self.channel.exchange_declare(self.NORMAL_EXCHANGE, "direct")
self.channel.exchange_declare(self.DEAD_EXCHANGE, "direct")
self.channel.queue_declare(
self.NORMAL_QUEUE,
arguments={
"x-dead-letter-exchange": self.DEAD_EXCHANGE,
"x-dead-letter-routing-key": "dead",
"x-message-ttl": 1000 * 5 # 延迟时间为 5 秒
}
)
self.channel.queue_declare(self.DEAD_QUEUE)
self.channel.queue_bind(self.NORMAL_QUEUE, self.NORMAL_EXCHANGE, routing_key="normal")
self.channel.queue_bind(self.DEAD_QUEUE, self.DEAD_EXCHANGE, routing_key="dead")
def on_message_callback(self, ch, method, properties, body):
print(f"消费者 C1 从正常队列收到消息:{body.decode('utf-8')}")
ch.basic_ack(delivery_tag=method.delivery_tag)
def main(self):
self.declare()
self.channel.basic_consume(self.NORMAL_QUEUE,
on_message_callback=self.on_message_callback)
self.channel.start_consuming()
c1 = Consumer()
c1.main()
以上是消费者 C1 的代码,不需要做什么改动,只需要声明正常队列的时候设置一个延迟时间即可。注意:执行之前需要先将已存在的队列(正常队列)删除,否则执行的时候报错。
启动 C1 之后就将其停掉,然后启动生产者,生产者代码和之前一样:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
for i in range(1, 11):
channel.basic_publish(exchange="normal_exchange",
routing_key="normal",
body=f"kagura_mea{i}".encode("utf-8"))
channel.close()
connection.close()
下面我们来看一下队列,刚开始正常队列中有 10 条,5 秒钟之后会都进入到死信队列。
不过问题来了,如果队列是延迟的,并且生产者发送消息还自带了过期时间,那么以哪个为准呢?答案是以短的时间为准。我们测试一下,首先将两个队列给删掉,然后重新创建。
channel.basic_publish(exchange="normal_exchange",
routing_key="normal",
body=f"kagura_mea".encode("utf-8"),
properties=pika.BasicProperties(expiration=str(1000 * 2)))
channel.basic_publish(exchange="normal_exchange",
routing_key="normal",
body=f"kagura_mea".encode("utf-8"),
properties=pika.BasicProperties(expiration=str(1000 * 100)))
下面生产者发送两条消息,一个过期时间为两秒,一个过期时间为一百秒:
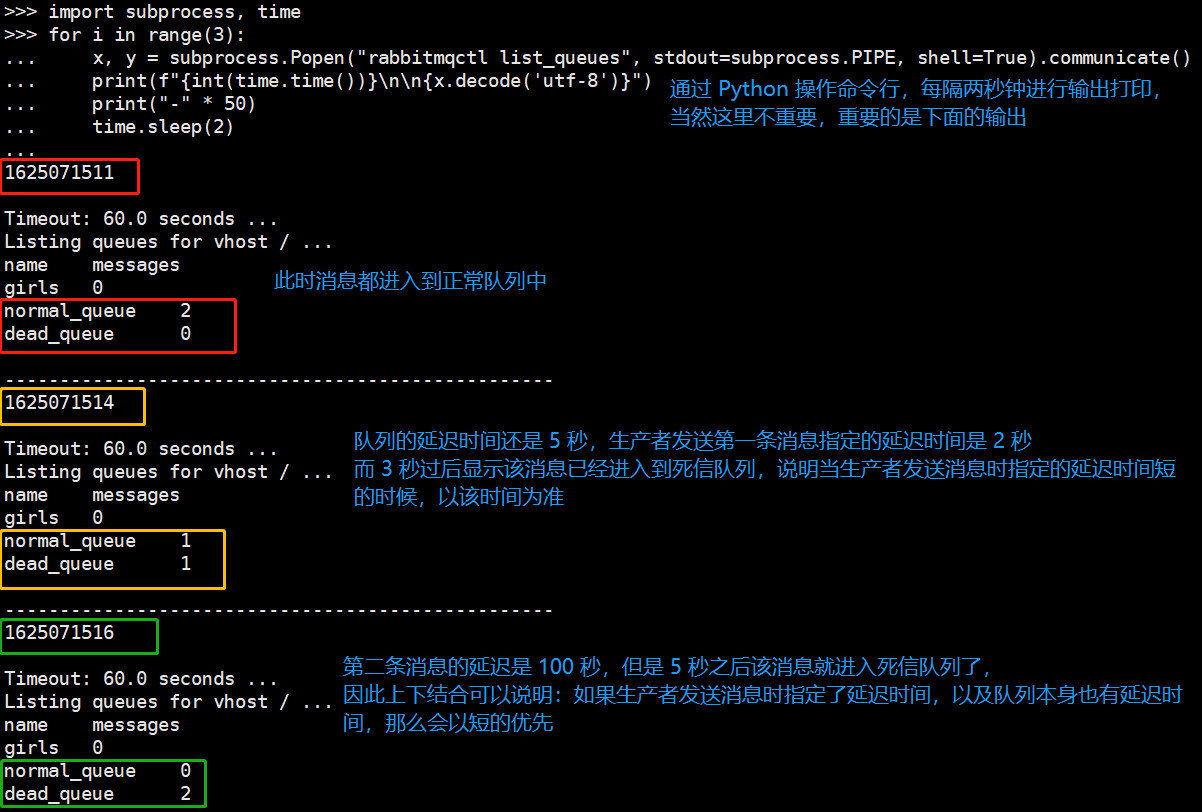
因此以上就是延迟队列,它适合在延迟时间非常固定的场景下使用,如果延迟时间不固定,那么队列就不要设置成延迟队列,而是通过生产者发送消息时指定延迟时间。
但是生产者发送消息时指定延迟时间会有一个问题,并且这个问题还很严重,那就是队列检测消息是否过期只会检测队列中的第一条消息。如果第一条消息没有过期、并且还没有被取走,那么第二条消息即使过期了也不会进入到死信队列。假设发送第一条消息指定延迟时间是 100 秒,第二条消息指定的是 10 秒,此时队列是正常的(没有设置延迟属性),那么 10 秒过后第二条消息并不会进入死信队列,因为它前面还有一个延迟 100 秒的消息,只有等第一条消息处理完之后,才轮到第二条消息,因此消费者如果不消费,那么最终结果就是 100 秒之后这两条消息一块进入死信队列。
同理发送第一条消息如果不指定延迟时间,队列也是正常队列,而发送第二条消息指定延迟时间,那么不管过去多长时间,只要消费者不消费,第二条消息永远不会进入死信。因为第一条消息没有过期时间,所以它会一直存在于队列中,尽管第二条消息有过期时间,但是它排在后面,所以只要有第一条消息在,就永远也轮不到它,这也符合队列先进先出的特点。
因此以上算是生产者发送消息指定延迟的一个缺陷,这个缺陷还是比较致命的,那么问题来了,我们能不能解决它呢?如果不能在消息的粒度上实现 TTL,那么就无法设计成一个通用的延迟队列。
解决办法是有的,是通过插件的形式。
安装延迟消息插件
访问 https://www.rabbitmq.com/community-plugins.html 页面可以看到里面有很多的插件,我们需要下载的是 rabbitmq_delayed_message_exchange 这个插件。
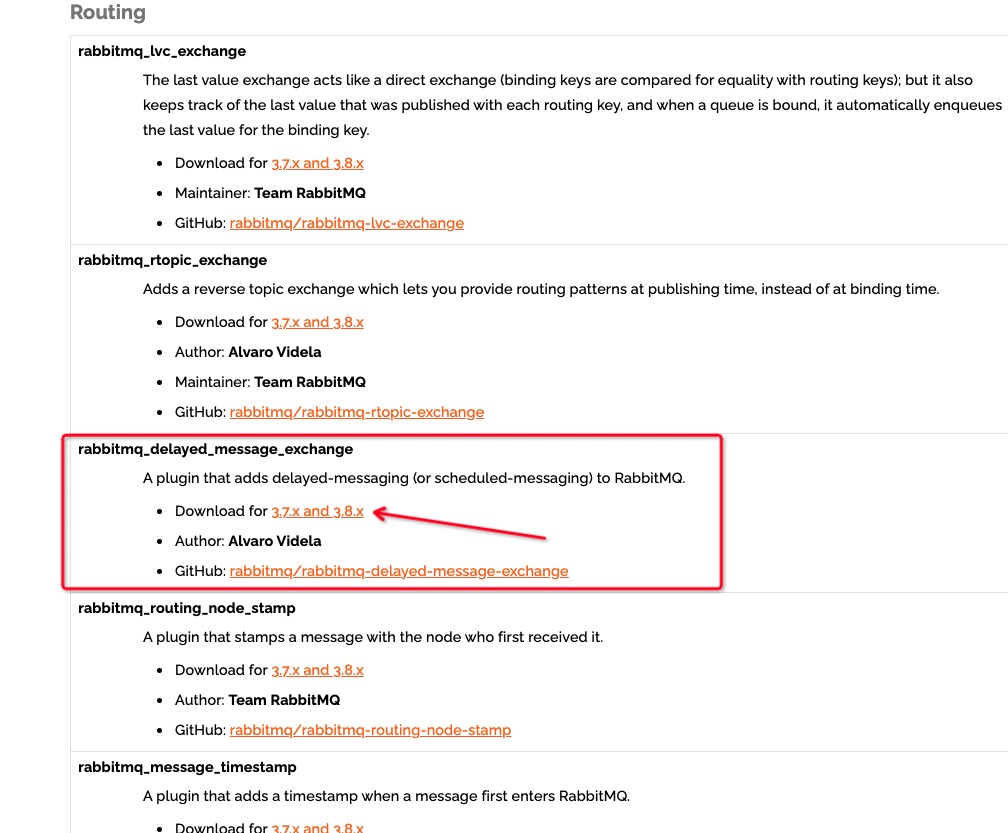
点击 Downdload for 之后,下载 rabbitmq_delayed_message_exchange-3.8.0.ez 并丢到 RabbitMQ 的插件目录(/usr/lib/rabbitmq/lib/rabbitmq_server-3.8.14/plugins)中,该目录中包含了大量的插件。
将插件扔进去之后,我们还要让插件生效才可以:rabbitmq-plugins enable rabbitmq_delayed_message_exchange
然后别忘记重启服务:
[root@satori ~]# rabbitmqctl stop
Stopping and halting node rabbit@satori ...
[root@satori ~]# rabbitmq-server -detached
这个时候我们查看一下 webUI,会发现意想不到的情况:
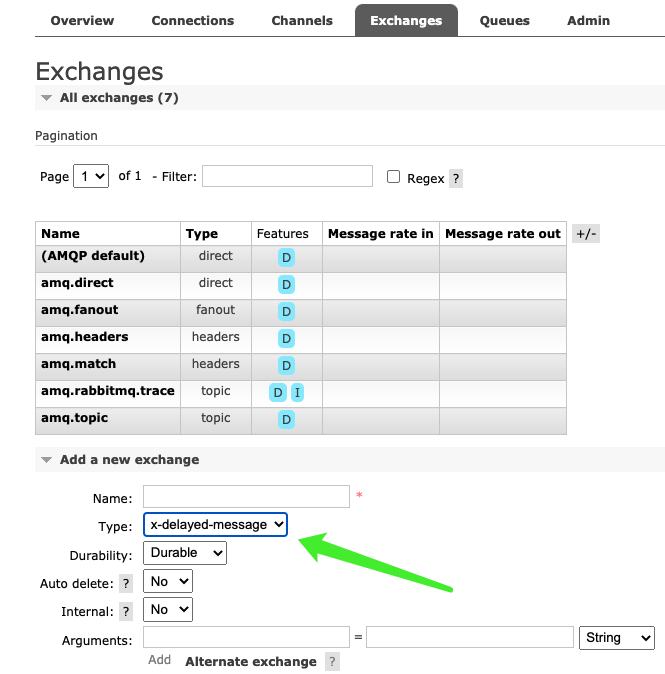
点击 Exchanges 之后再点击 Add a new exchange,然后我们看一下 Type,它表示指定交换机的类型,但是里面除了我们之前介绍的 direct、fanoput、topic、headers 之外,还多了一个 x-dealyed-message,所以这个插件是作用在交换机上的。
首先我们之前实现延迟有两种方式:第一种是生产者发消息时指定延迟;第二种则是声明队列为延迟队列。针对第二种情况,我们说它适用于消息延迟时间比较固定的场景,如果延迟不固定,那么就不要声明为延迟队列,直接还保持正常队列即可,然后让生产者发消息时指定延迟时间。此时会进入正常交换机、推送到正常队列,如果消息过期了就再发送到死信交换机、再推送到死信队列,最终被监听死信队列的消费者消费。
但我们说队列只会检测第一个消息是否过期,如果它的延迟时间过长,那么会阻塞后面所有的消息,所以我们只能在交换机上动手脚。对于 direct、fanout、topic、headers 类型的交换机而言,虽然路由的规则不同,但无论哪一种,都是只要接收到消息就会立刻推到队列。但安装了插件之后,如果将交换机声明为 x-delayed-message 类型,那么当该类型的交换机接收到带有延迟时间的消息时,就不会发送到队列了,而是等到延迟时间过了之后才会发送,并且此时是哪个延迟时间先到就先发哪一个。
下面我们来编写代码,这里手动将之前的队列删除。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
def on_message_callback(ch, method, properties, body):
print(body.decode("utf-8"))
ch.basic_ack(delivery_tag=method.delivery_tag)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 声明 x-delayed-message 类型的延迟交换机
# 然后 arguments 里面的 "x-delayed-type": "direct" 表示时间到了直接推送消息
channel.exchange_declare("delay_exchange", "x-delayed-message",
arguments={"x-delayed-type": "direct"})
# 通过插件的方式就不需要死信队列了,直接声明一个普通的队列即可
channel.queue_declare("queue")
# 然后两者进行绑定,指定 binding key
channel.queue_bind("queue", "delay_exchange", routing_key="queue")
channel.basic_consume("queue",
on_message_callback=on_message_callback)
channel.start_consuming()
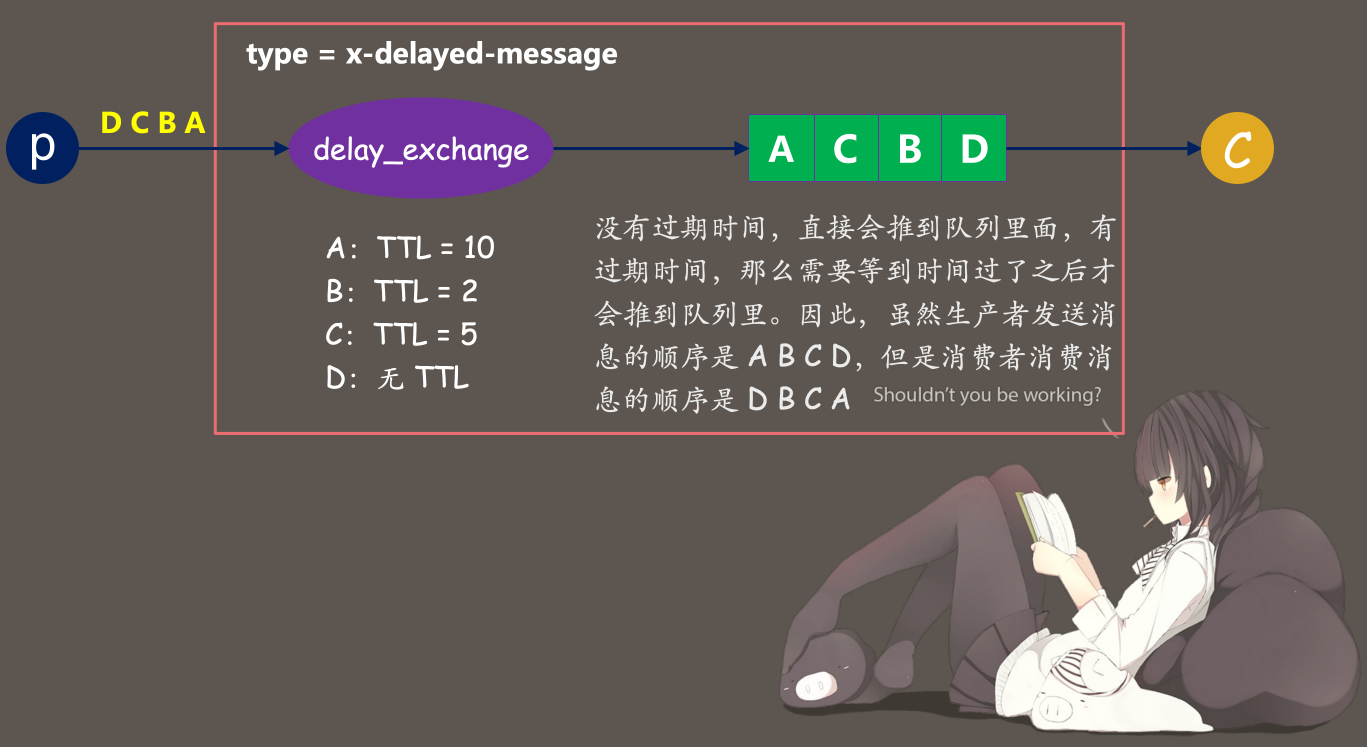
如果生产者先发送一个延迟 10 秒的消息 A、再发送一个延迟 3 秒的消息 B,那么 3 秒过后消费者就会收到 B。因为消费者监听的是队列,但是 x-delayed-message 类型的交换机并没有直接将消息推入队列,它会等到消息的延迟结束之后再推,而哪个消息的延迟先结束就先推哪个消息,所以此时就解决了某个消息延迟过长导致后面消息阻塞的问题。
消费者启动之后,相应的交换机和队列就创建好了,然后我们再暂停掉,因为我们还要观察队列中消息数量的变化。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
port=5672,
virtual_host="/",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
for body, ttl in [(b"A", 1000 * 10), (b"B", 1000 * 2), (b"C", 1000 * 5), (b"D", 0)]:
# 发送消息,body 是消息内容,ttl 是延迟时间,延迟依旧通过消息属性 properties 参数设置
# 但是注意:此时的延迟时间不能通过 expiration 指定,expiration 表示消息发送到队列中具有延迟时间
# 这里我们是让消息停在交换机中,所以延迟需要通过 headers 指定,"x-delay": ttl
channel.basic_publish(exchange="delay_exchange",
routing_key="queue",
body=body,
properties=pika.BasicProperties(headers={"x-delay": ttl}))
channel.close()
connection.close()
然后我们启动消费者并查看队列,需要在启动之后立刻查看:
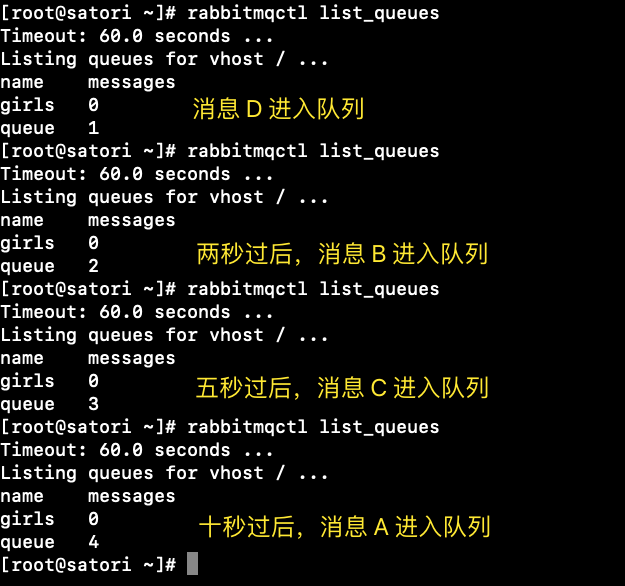
跟我们分析的是一样的,然后再启动消费者,看看它消费消息的顺序是不是 D B C A。

结果显然是正确的,通过插件就完美地实现了延迟队列,只不过虽然叫延迟队列,但核心在于交换机。每个消息的延迟时间既可以不一样,而且还能保证延迟时间先到的消息先被处理(被交换机发送到队列)。
延迟队列总结
延迟队列在需要延迟处理的场景下非常有用,使用 RabbitMQ 来实现延迟队列可以很好地利用 RabbitMQ 的特性:如消息可靠发送、消息可靠投递、死信队列来保证消息至少被消费一次以及未被正确处理的消息不会被丢弃。另外通过 RabbitMQ 集群的特性,可以很好的解决单点故障,不会因为单个节点挂掉而导致延迟队列不可用或者信息丢失。
当然延迟队列除了 RabbitMQ 之外还有其它选择,比如 Redis 的 zset、Kafka 的时间轮等等,这些方式各有特点,具体看使用场景。
消息的 RPC 通信
假设在 B 机器上有一个服务,比如一个函数,但我们想在 A 机器上访问,这个时候该怎么做呢?首先啃腚有人想到了 gRPC,这个毫无疑问是可以的,但我们的需求是和 RabbitMQ 结合。
思考一下不难想出,首先让 A 充当生产者往 "队列一" 里面发消息(函数的相关参数),B 作为消费者从 "队列一" 中取出进行函数调用;B 调用完毕之后再充当生产者往 "队列二" 里面发消息(调用结果),然后 A 作为消费者从 "队列二" 中取出结果。注意: 必须是两个队列,一个队列的话是行不通的。
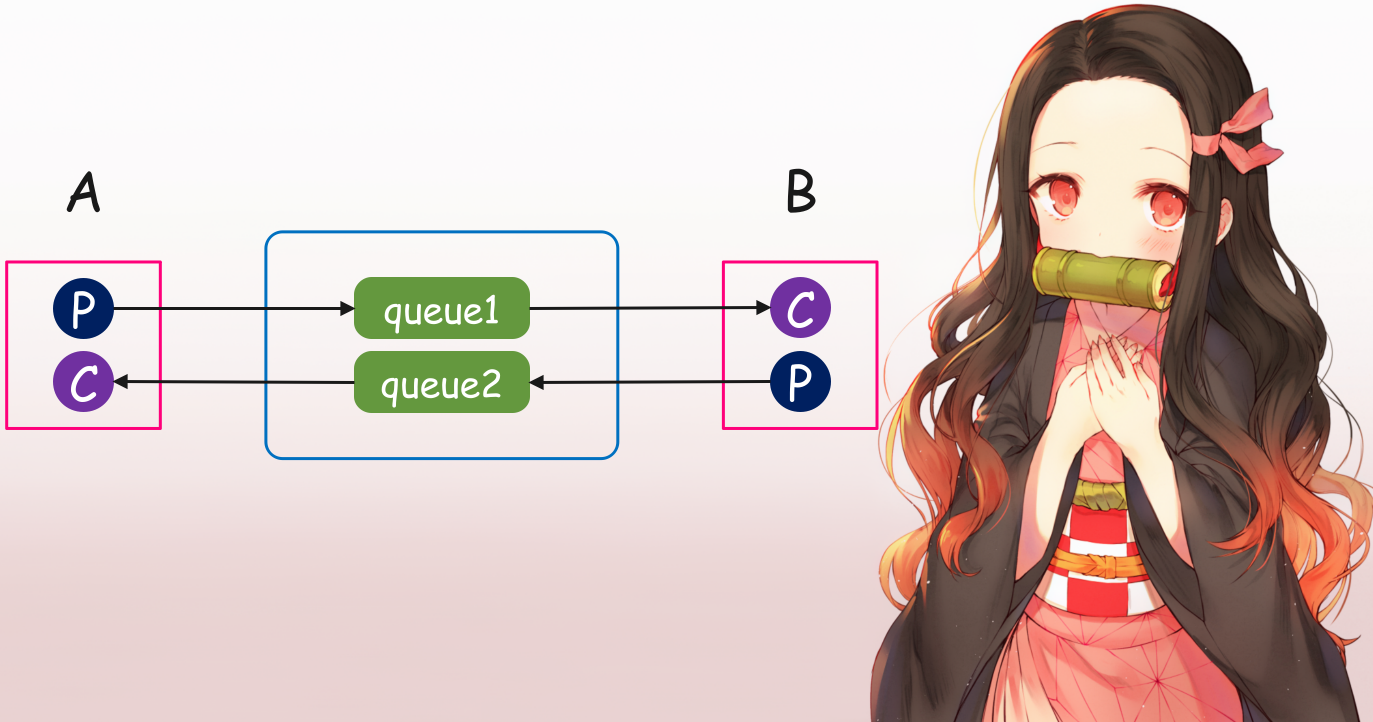
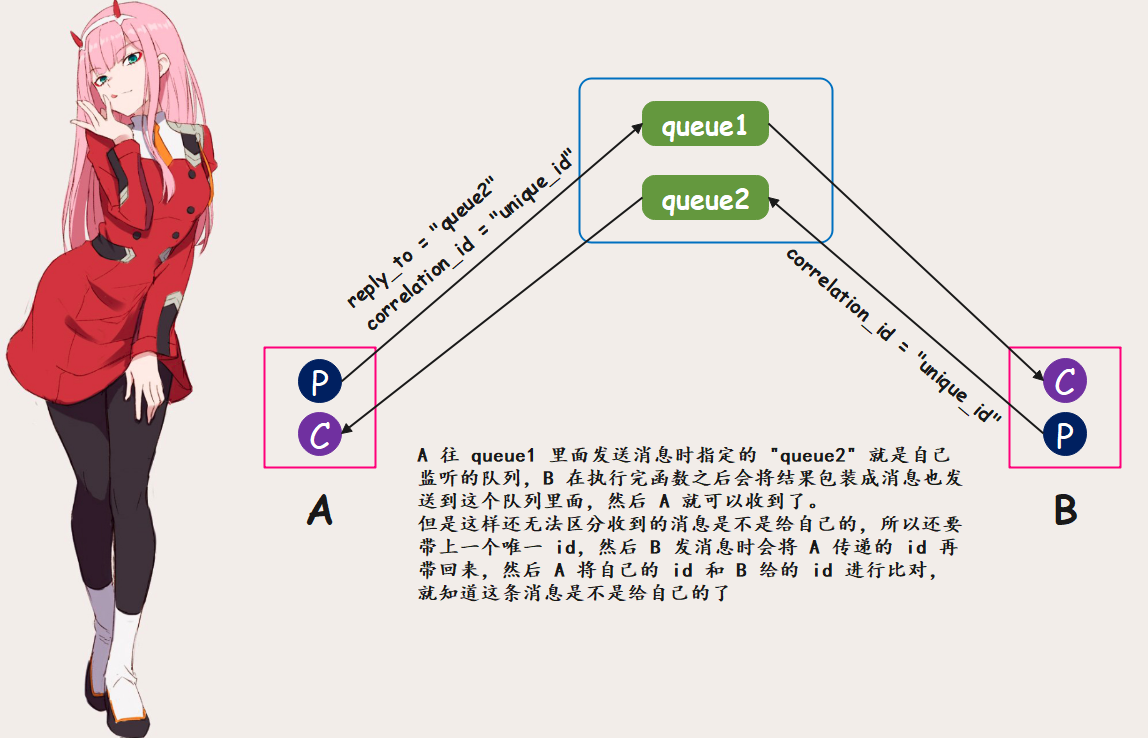
A 往 queue1 里面发消息(函数参数),B 接收;然后 B 往 queue2 里面发(调用结果),A 接收。但是这里面有一个问题,就是 B 怎么知道要往 queue2 里面发(虽然站在上帝视角,我们可以直接写死),因此 A 在发送消息的时候必须携带一个队列名称,这个队列就是自己监听的队列,然后 B 在收到消息时会拿到这个队列名,将调用的结果扔到该队列里面这样 A 就能收到了。
虽然消息是可以接收到了,但如果除了 A 之外,还有一个 A2 也调用了 B 机器上的某个函数,如果 A 和 A2 在发送消息时携带的队列名称不一样(监听不同的队列)倒还好,这样互不影响;但问题时 A 和 A2 监听同一个队列,然后同时调用 B 机器上的函数,那么当 B 执行完函数将结果扔到队列的时候,A 和 A2 要如何确定取出的结果是不是自己的呢?因此 A 和 A2 发送消息时除了要带上自己监听的队列之外,还要带上一个用于标识的唯一 id,然后 B 在取出消息时也会拿到这个 id,当执行完将消息扔到指定的队列的时候同样会把这个 id 再带回去,这样 A 和 A2 在拿到消息时也能拿到 B 传来的 id。如果这个 B 传来的 id 和自己传过去的 id 是一样的,那么就代表这条消息里面的结果是自己传过去的参数调用返回的结果,然后通过 ch.basic_ack 手动应答;如果两个 id 不一样,那么就说明这条消息里面的结果不是自己的,是其它人的,所以此时就什么也不做。
下面来编写代码,这里没有生产者和消费者,我们把 A 当成是客户端,把 B 当成是服务端。首先是客户端:
import uuid
import pika
class Client:
def __init__(self):
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
self.connection = pika.BlockingConnection(connection_params)
self.channel = self.connection.channel()
# 声明一个队列,客户端往里面发送参数,服务端进行接收,这里就绑定在默认的交换机上
self.channel.queue_declare("send")
# 声明一个队列,服务端计算完毕之后就将结果发送到这个队列里面
# 这里我们指定空字符,那么 RabbitMQ 会自动帮我们给队列指定一个名字
# queue_declare().method.queue 即可拿到队列名
self.receive_queue_name = self.channel.queue_declare("").method.queue
# 给消息起一个 id,这个 id 在 RabbitMQ 里面叫做 correlation_id,这里使用 uuid 生成
self.corr_id = str(uuid.uuid4())
# 服务端返回的消息内容,会在回调函数中设置
self.body = None
def remote_server(self, n):
"""给服务端传递参数,进行调用
传输一个整数 n,服务端返回 1 + 2 + 3 + ... + n-1
"""
self.channel.basic_publish(
exchange="",
routing_key="send",
body=str(n).encode("utf-8"),
properties=pika.BasicProperties(
# 告诉服务端将结果返回到这个队列里面来
reply_to=self.receive_queue_name,
# 给消息起一个 id
correlation_id=self.corr_id
)
)
# 发送完消息之后还没有万事大吉,此时客户端还要进行监听
# 这里监听的队列也可以指定为 "",会自动监听上面声明的队列
# 当然也可以指定具体的名字,因为这个名字我们是可以拿到的
self.channel.basic_consume(self.receive_queue_name, on_message_callback=self.on_message_callback)
# 我们下面可以通过 self.channel.start_consuming() 开启监听,但是这样做会一直处于阻塞状态了
# 但有时我们不希望它阻塞,而是希望存在一个方法:
# 当队列中有消息,调用该方法后会自动调用 channel.basic_consume 中绑定的回调函数
# 如果没有消息,那么该方法什么也不做,程序往下执行
# 而该方法就是 connection.process_data_events
while self.body is None:
# 这里我们没有什么要做的,所以还是采用死循环的方式,一直等待队列中有消息
# 但如果是在生产中,可以在没有消息的时候先去干别的事情
# 等到队列中有消息后,会在回调中设置 self.body,设置完之后由于 self.body 不为 None,所以循环结束
self.connection.process_data_events()
# 返回结果
return int(self.body)
def on_message_callback(self, ch, method, properties, body):
# correlation_id 通过 properties 获取,这个 properties 就是 pika.BasicProperties 对象
# 两个 id 一样,那么证明消息是自己的
if self.corr_id == properties.correlation_id:
self.body = body.decode("utf-8")
# 手动应答
ch.basic_ack(delivery_tag=method.delivery_tag)
# 如果消息不是自己的,那么什么也不做
client = Client()
print(client.remote_server(1000))
然后是服务端,服务端的编写非常简答,这里我们就不封装了:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
def on_message_callback(ch, method, properties, body):
# 计算完毕,此时就算是服务调用结束了,当然这里只是举栗子
# 然后我们要把 res 发送到队列中
res = sum(range(int(body.decode("utf-8"))))
# 那么发送到哪一个队列呢?我们说这里的几个参数都是根据消息进行拆分得到的
# 比如 body 是消息内容,而 properties.reply_to 很明显就是客户端指定的队列
# 因为客户端发送的时候就是在 properties.reply_to 里面设置的,那么服务端也要从 properties.reply_to 里面取
ch.basic_publish("",
routing_key=properties.reply_to,
# 同样取出里面 id,然后返回消息的时候,也加上这个 id,不然客户端是不会消费的
properties=pika.BasicProperties(correlation_id=properties.correlation_id),
body=str(res).encode("utf-8"))
ch.basic_ack(delivery_tag=method.delivery_tag)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 监听 send 队列
channel.basic_consume("send",
on_message_callback=on_message_callback)
channel.start_consuming()
由于我们只在客户端里面声明了队列,所以我们需要先启动客户端,此时会进入死循环。然后启动服务端,那么服务端会立刻从 send 队列中取出消息,进行计算,完事之后再将结果发送到客户端监听的队列中。此时客户端会从中取出消息执行回调,然后设置 self.body,最终返回结果。
以上便是消息的 RPC 通信,虽然涉及的东西有点多,但是整体并不难理解。然后是队列,除了 send 队列之外,还有一个名字很长的队列,因为这是 RabbitMQ 自动帮我们生成的名字。
优先队列
优先队列比较简单,我们说普通队列没有轻重缓急的优先级,只有先到后到的顺序。但有时候我们希望能给消息指定一个优先级,优先级越大越先被处理,比如你有很多客户,但有些客户是大客户,他们的订单很明显应该优先被处理。所以对于大客户而言,给一个高优先级,普通客户就是默认的优先级。
在 RabbitMQ 中也可以将一个队列声明为优先队列,同时指定一个最大优先级,然后根据生产者发送的消息的优先级进行排序,优先级大的先被处理。
生产者发消息时指定的优先级不要超过队列设定的最大优先级。
下面我们来编写代码:
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
# 声明队列,设置优先级
channel.queue_declare("priority_queue",
# 官方允许的最大优先级范围是 0 ~ 255,但是不建议设置的过高,因为浪费 CPU 和内存
# 这里我们设置为 10 即可
arguments={"x-max-priority": 10})
# 发送消息,指定优先级
channel.basic_publish("", "priority_queue", b"message_1",
properties=pika.BasicProperties(priority=3))
channel.basic_publish("", "priority_queue", b"message_2",
properties=pika.BasicProperties(priority=6))
channel.basic_publish("", "priority_queue", b"message_3",
properties=pika.BasicProperties(priority=2))
connection.close()
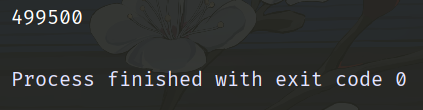
生产者发了三条消息,优先级分别是 3、6、2,相信你已经知道消费者消费消息的顺序了。不过需要注意的是,生产者发消息的时候不能启动消费者,否则话就直接消费了。应该先让生产者把消息都发到队列之后,根据优先级排好序,然后再启动消费者。
import pika
credentials = pika.PlainCredentials("mea", "123456")
connection_params = pika.ConnectionParameters(
host="47.94.174.89",
credentials=credentials)
connection = pika.BlockingConnection(connection_params)
channel = connection.channel()
def on_message_callback(ch, method, properties, body):
print(body.decode("utf-8"))
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume("priority_queue",
on_message_callback)
# 队列里面有消息,那么会直接消费,没有消息什么也不做
connection.process_data_events()
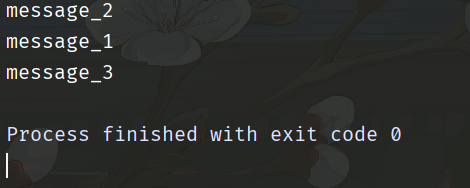
确实是按照消息的优先级进行消费,如果没有指定优先级,那么优先级则为最低。
惰性队列
RabbitMQ 从 3.6.0 版本开始引入了惰性队列,惰性队列会尽可能的将消息存入磁盘中,而在消费者消费到指定的消息时才会被加载到内存中,所以惰性队列的性能是不高的。但之所以要有惰性队列显然是为了让队列能容纳更多的消息,尤其当消费者因为各种原因(消费者下线、宕机等等)长时间不能消费消息而导致消息堆积时,惰性队列就很有必要了。
默认情况下,当生产者将消息发送到 RabbitMQ 时,队列中的消息会尽可能地存储在内存中,这样可以更加快速地发送给消费者,即使是持久化的消息,在被写入磁盘的同时也会在内存中驻留一份备份。当 RabbitMQ 需要释放内存的时候,会将内存中的消息换页至硬盘中,但这个操作会耗费较长的时间,也会阻塞队列的操作,进而无法接收新的消息。虽然 RabbitMQ 的开发者们一直在升级相关算法,但是效果始终不太理想,尤其是消息量特别大的时候。
而声明一个惰性队列也很简单:
channel.queue_declare("lazy_queue",
arguments={"x-queue-mode": "lazy"})
依旧通过 arguments 参数指定,这里我们就不演示了,直接给出一个结论吧。发送一百万条 1kb 的消息,那么普通队列占用内存 1.2 GB,而惰性队列仅仅占用 1.5 MB,因为惰性队列只存放了索引,具体的消息内容在磁盘上。但惰性队列消费消息慢,因为要先到磁盘上加载消息。
RabbitMQ 集群
再来看看 RabbitMQ 集群搭建,之前都是单机版的,如果 RabbitMQ 服务遇到内存崩溃、机器掉电或者主板故障等情况,该怎么办呢?此外单台机器的处理能力是有限的,如果我们希望 RabbitMQ 服务的吞吐量达到 10 万又该怎么办?没错显然是要搭建集群。
我上面用的都是阿里云的服务器,主机名为:satori,ip 为 47.94.174.89,但实际上我的阿里云上有三台服务器,配置分别如下:
47.94.174.89,主机名为 satori,2 核心 8GB 内存47.93.39.238,主机名为 matsuri,2 核心 4GB 内存47.93.235.147,主机名为 aqua,2 核心 4GB 内存
那么接下来我们就搭建一个三节点的 RabbitMQ 集群,这里将 satori 主机上的 Erlang 和 rabbitmq-server 的 rpm 包发到另外两个节点上进行安装。因为搭建集群,所以 Erlang 和 RabbitMQ 版本最好要保持一致,另外节点之间一定要能访问,并且配置免密码登陆。
matsuri 和 aqua 主机安装完毕之后,首先需要做一步操作:
[root@satori ~]# scp /var/lib/rabbitmq/.erlang.cookie root@47.93.39.238:/var/lib/rabbitmq/.erlang.cookie
[root@satori ~]# scp /var/lib/rabbitmq/.erlang.cookie root@47.93.235.147:/var/lib/rabbitmq/.erlang.cookie
.erlang.cookie 是 Erlang 实现分布式的必要文件,Erlang 分布式的每一个节点上要持有相同的 .erlang.cookie 文件,因为我们的 satori 主机上已经启动服务了,所以将该节点上 cookie 文件发送过去即可。
然后别忘记赋予权限:chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie,因为服务使用的是 rabbitmq 用户。
然后在剩余两个节点上执行 rabbitmq-server -detached,后台启动服务,此时会启动 Erlang 虚拟机和 RabbitMQ 服务。
注意:显然还没有结束,我们还需要执行如下命令
# 先关闭 RabbitMQ 服务,但是 Erlang 虚拟机不关闭
rabbitmqctl stop_app
# 从管理数据库中移除所有数据,例如配置过的用户、虚拟主机,删除所有持久化的消息
# 需要在 rabbitmqctl stop_app 之后使用,不过我们的 matsuri 和 aqua 节点是刚安装的,所以也没有什么东西可以删
rabbitmqctl reset
# 将自己加入到集群中,因为 satori 节点上的服务已经启动了,所以直接加入进去即可
rabbitmqctl join_cluster rabbit@47.94.174.89
# 启动 RabbitMQ 服务
rabbitmqctl start_app
两个节点上都执行上面这些命令即可,然后即可组成一个三节点的 RabbitMQ 集群,不过需要注意的是 rabbitmqctl join_cluster,它表示加入某个节点所在的集群,所以集群中任何一个节点都是可以的。比如我们上面的 satori、matsuri、aqua 组成了一个集群,现在又来一个节点也想加进去,那么:
rabbitmqctl join_cluster rabbit@47.94.174.89
# 或者
rabbitmqctl join_cluster rabbit@47.93.39.238
# 或者
rabbitmqctl join_cluster rabbit@47.93.235.147
以上三条命令没有任何区别,然后可以通过 rabbitmqctl cluster_status 查看集群状态,由于多个节点共同组成一个集群,因此无论你在哪个节点访问都是没有区别的。
最后别忘了重新设置一个用户,然后设置权限,以后就可以通过该用户访问集群,当然设置用户在任意一个节点上设置即可。然后通过 webUI 访问,也可以输入任意一个节点的 IP。
如果想把某个节点从集群中踢出去,那么可以这么做:
# 首先在要被踢出去的节点上执行以下命令
rabbitmqctl stop_app # 关闭服务
rabbitmqctl reset # 重置数据
rabbitmqctl start_app # 该节点从集群中脱离之后如果还继续提供服务,那么就再启动即可
# 然后在集群中的任意一个节点上执行,表示 xxx 以后就不是集群中的一员了
rabbitmqctl forget_cluster_node rabbit@xxx
这里我们只是文字描述,并没有实际演示,原因是 matsuri 和 aqua 两台主机已经到期了,所以这里就不实际操作了,有兴趣可以自己试一下。
pika 适配器
接下来的内容和 RabbitMQ 没有直接关系,因为 pika 专门为 Tornado、Twisted、Asyncio 等框架进行了适配,所以我们还是需要了解一下。
我们之前创建的连接都是通过 BlockingConnection 创建的,但除了 BlockingConnection 之外,还有很多其它的连接。
from pika.adapters.blocking_connection import BlockingConnection
from pika.adapters.select_connection import SelectConnection
from pika.adapters.gevent_connection import GeventConnection
from pika.adapters.tornado_connection import TornadoConnection
from pika.adapters.twisted_connection import TwistedChannel
from pika.adapters.asyncio_connection import AsyncioConnection
pika 提供的适配器个人用的不是很多,有兴趣可以查看 https://pika.readthedocs.io/en/latest/intro.html ,这里不多说啦。
总的来说,RabbitMQ 是一款非常值得我们学习的消息中间件,在项目中不妨多试一下吧。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号