一文告诉你如何用 Python 对图片和视频进行高清修复
作者:@古明地盆
喜欢这篇文章的话,就点个关注吧,或者关注一下我的公众号也可以,会持续分享高质量Python文章,以及其它相关内容。:点击查看公众号
估计大家应该在网上看过很多用 AI 修复的高清视频,最近我也有相关需求,需要修复几张图片。于是便去 GitHub 上寻找相关开源项目,结果还真找到一个,效果还很不错,这里特意分享出来给大家。
首先将 https://github.com/xinntao/Real-ESRGAN.git 克隆下来,项目结构如下:
然后我们要安装相关依赖,为了避免污染本地 Python 环境,这里先创建一个虚拟环境,在当前目录中执行以下命令:
# 创建虚拟环境 env,我当前的 Python 版本是 3.10
python -m venv env
接着将依赖安装到虚拟环境中:
# 首先更新 pip
./env/Scripts/python -m pip install pip --upgrade
# 安装依赖
./env/Scripts/pip install basicsr facexlib gfpgan Pillow opencv-python tdqm -i https://mirrors.cloud.tencent.com/pypi/simple
然后安装 torch,可以选择 CPU 版和 GPU 版,由于我当前的显卡是 RTX4080,所以选择 GPU 版本。注意:torch 的安装包比较大,安装可能会失败,建议先将 .whl 文件下载到本地。
# torch
https://download.pytorch.org/whl/cu121/torch-2.1.2%2Bcu121-cp310-cp310-win_amd64.whl
# torchvision
https://download.pytorch.org/whl/cu121/torchvision-0.16.2%2Bcu121-cp310-cp310-win_amd64.whl
# torchaudio
https://download.pytorch.org/whl/cu121/torchaudio-2.1.2%2Bcu121-cp310-cp310-win_amd64.whl
下载下来之后进行安装,注意:下载的时候要根据你当前机器选择一个合适的版本。
./env/Scripts/pip install C:\Users\satori\Desktop\torch-2.1.2+cu121-cp310-cp310-win_amd64.whl
./env/Scripts/pip install C:\Users\satori\Desktop\torchvision-0.16.2+cu121-cp310-cp310-win_amd64.whl
./env/Scripts/pip install C:\Users\satori\Desktop\torchaudio-2.1.2+cu121-cp310-cp310-win_amd64.whl
# 安装当前项目
./env/Scripts/python setup.py develop
到目前为止,相关依赖就已经安装完毕了,然后下载模型。
# 下载完之后丢到当前项目的 weights 目录中
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth
# 下载完之后丢到当前项目的 gfpgan/weights 目录中
https://github.com/xinntao/facexlib/releases/download/v0.1.0/detection_Resnet50_Final.pth
https://github.com/xinntao/facexlib/releases/download/v0.2.2/parsing_parsenet.pth
# 下载完之后丢到当前项目的 env/Lib/site-packages/gfpgan/weights 目录中,env 就是我们刚才创建的虚拟环境
https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth
到此,所有准备工作就算完成了,下面我们来修复图片。
./env/Scripts/python inference_realesrgan.py \
-n [模型名称],默认 RealESRGAN_x4plus,还可以选择 RealESRGAN_x4plus_anime_6B.pth(针对动漫)
-i [目录路径或图片文件路径],默认是当前项目的 inputs 目录,注:不能包含中文
-o [文件输出路径],默认是当前目录的 results 目录,注:不能包含中文
-s [采样比例],默认是 4,值越大,像素越高
--face_enhance 是否开启面部增强
--ext [auto | jpg | png],图片格式,默认 auto,表示和输入图片的格式相同
好,下面我们来试一试。
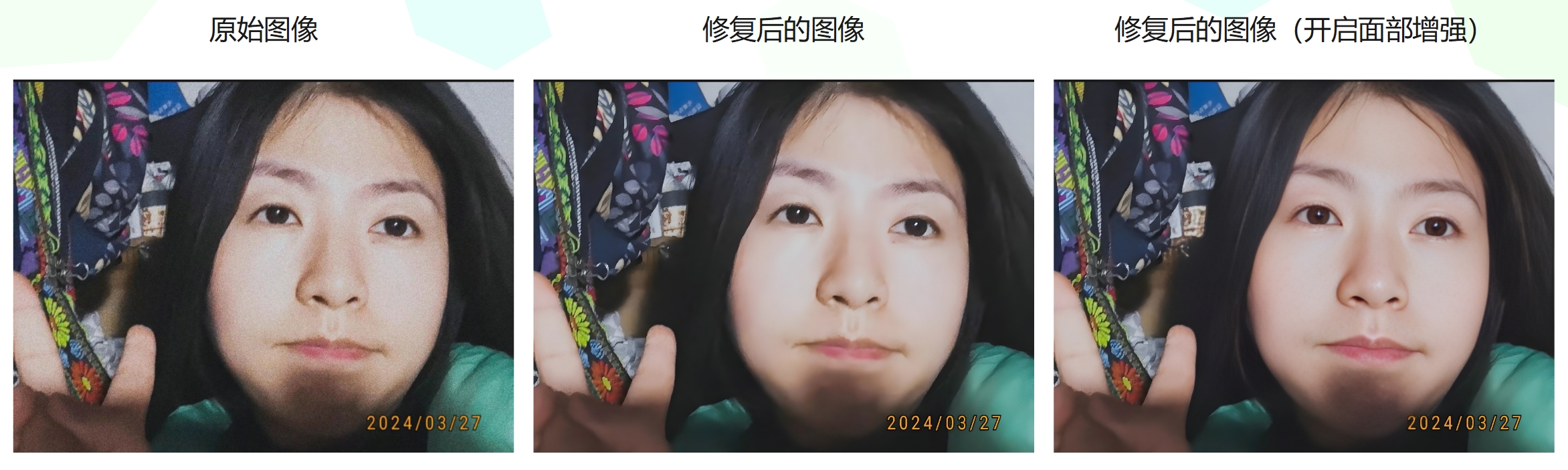
./env/Scripts/python inference_realesrgan.py -i inputs/xiaoyun.jpg -o results -s 1
效果如下:

再来试试面部增强效果,会有些耗时。
./env/Scripts/python inference_realesrgan.py -i inputs/xiaoyun.jpg -o results -s 1 --face_enhance
效果如下:
再来试试动漫图片,看看效果如何。
# -s 默认为 4,如果原始图片比较小,那么在修复的时候还会有放大的效果
./env/Scripts/python inference_realesrgan.py -n RealESRGAN_x4plus_anime_6B.pth -i inputs/0030.jpg -o results -s 3

效果还不错,以上就是如何使用 Python 进行图像修复,感兴趣的话可以自己动手试试。
当然,如果你想修复视频的话也是可以的,通过 OpenCV 将视频的每一帧都转成图片,然后对图片进行修复。
import os
from pathlib import Path
import cv2
# 视频路径
video_path = "inputs/video/onepiece_demo.mp4"
# 输出图片的目录路径
output_folder = "inputs/onepiece"
os.makedirs(output_folder, exist_ok=True)
# 读取视频(路径不能包含中文)
cap = cv2.VideoCapture(video_path)
# 获取帧率
fps = cap.get(cv2.CAP_PROP_FPS)
print(f"视频帧率:{fps}") # 视频帧率:23.98
frame_count = 1
# 循环直到视频结束
while cap.isOpened():
# 读取当前帧
ret, frame = cap.read()
if not ret:
break
# 成功读取一帧,保存到指定目录中
output_path = str(Path(output_folder) / f"frame_{frame_count}.png")
cv2.imwrite(output_path, frame)
frame_count += 1

然后对每张图片进行修复:
./env/Scripts/python inference_realesrgan.py -n RealESRGAN_x4plus_anime_6B.pth -i inputs/onepiece -o results/onepiece
将修复后的图片按照原始视频的帧率,再组合成新的视频。
import re
from pathlib import Path
import cv2
# 按照文件名中的数字,对文件进行排序
input_folder = sorted(
Path(r"results\onepiece").glob("*.png"),
key=lambda x: int(re.search(r"(\d+)", str(x)).group(1))
)
input_folder = list(map(str, input_folder))
# 分辨率,从原始视频读取而来
fps = 24
# 读取第一张图片以获取视频分辨率
frame = cv2.imread(input_folder[0])
height, width, layers = frame.shape
# 创建视频写入对象
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
video = cv2.VideoWriter(r"results\onepiece_demo.mp4", fourcc, fps, (width, height))
# 遍历图片列表,将每张图片写入视频
for image in input_folder:
video.write(cv2.imread(image))
# 释放资源
video.release()
当然组合后的视频,是没有声音的,所以还要把原始视频的声道提取出来,然后和新的视频合在一起。
# 提取视频中的音频
ffmpeg -i [原始视频.mp4] -q:a 0 -map a [生成的音频.mp3]
# 将音频和视频合并在一起
ffmpeg -i [视频文件.mp4] -i [音频文件.mp3] -c:v copy -c:a aac [合并后的视频文件.mp4]
以上就是本文的内容,感兴趣的话就试试吧。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~