解密 Rust 的 Sized trait
本文转载自微信公众号:《兔子写代码》
概述
Sized 其实是 Rust 中最重要的概念之一,可谓功成不居。它往往以微妙的形式与其他语言特性交织在一起,只有在形如 x doesn't have size known at compile time 的错误信息中才会显露,这些错误信息对于每个 Rustacean 来说都太过熟悉了。在本文中,我们将探讨 Sized 的各种形式,包括固定大小类型、未定大小类型以及零大小类型,同时还将考察它们的用例、优势、痛点及相应解决方案。
[注:本文中出现的"宽度"通常指"指针宽度",也就是机器字长。在 32 位系统中,1 个宽度的大小是 32 位,也就是 4 个字节;在 64 位系统中则是 8 个字节。如果指针是 2 个宽度,那么它就是胖指针或宽指针。]
在 Rust 中,如果一个类型的字节大小可以在编译期确定,那么它就是 固定大小类型(sized type)。确定某类型的大小非常重要,只有这样才能在栈上为该类型的实例分配足够的空间。固定大小类型可以通过值或引用进行传递。如果一个类型的大小无法在编译期确定,那么它被称为 未定大小类型(unsized type) 或 动态大小类型(DST, Dynamically-Sized Type)。由于未定大小类型无法放置在栈上,因此它们只能通过引用进行传递。
以下是一些固定大小和未定大小类型的示例:
use std::mem::size_of;
fn main() {
// 原生类型
assert_eq!(4, size_of::<i32>());
assert_eq!(8, size_of::<f64>());
// 元组
assert_eq!(8, size_of::<(i32, i32)>());
// 数组
assert_eq!(0, size_of::<[i32; 0]>());
assert_eq!(12, size_of::<[i32; 3]>());
struct Point {
x: i32,
y: i32,
}
// 结构体
assert_eq!(8, size_of::<Point>());
// 枚举
assert_eq!(8, size_of::<Option<i32>>());
// 获取指针宽度(即机器字长),
// 在 32 位系统上是 4 个字节
// 在 64 位系统上是 8 个字节
const WIDTH: usize = size_of::<&()>();
// 指向固定大小类型的指针占用 1 个宽度
assert_eq!(WIDTH, size_of::<&i32>());
assert_eq!(WIDTH, size_of::<&mut i32>());
assert_eq!(WIDTH, size_of::<Box<i32>>());
assert_eq!(WIDTH, size_of::<fn(i32) -> i32>());
const DOUBLE_WIDTH: usize = 2 * WIDTH;
// 未定大小的结构体
struct Unsized {
unsized_field: [i32],
}
// 指向未定大小类型的指针占用 2 个宽度
assert_eq!(DOUBLE_WIDTH, size_of::<&str>()); // 切片
assert_eq!(DOUBLE_WIDTH, size_of::<&[i32]>()); // 切片
assert_eq!(DOUBLE_WIDTH, size_of::<&dyn ToString>()); // trait 对象
assert_eq!(DOUBLE_WIDTH, size_of::<Box<dyn ToString>>()); // trait 对象
assert_eq!(DOUBLE_WIDTH, size_of::<&Unsized>()); // 自定义的未定大小类型
// 未定大小类型
size_of::<str>(); // 编译错误
size_of::<[i32]>(); // 编译错误
size_of::<dyn ToString>(); // 编译错误
size_of::<Unsized>(); // 编译错误
}
固定大小类型的大小显而易见:所有原生类型和指针都具有已知大小,而所有的结构体、元组、枚举和数组都是由原生类型、指针或其他嵌套的结构体、元组、枚举和数组组成的,因此可以递归地计算其字节总数,以及内存填充和对齐所需的额外字节。同样显而易见的是,未定大小类型的大小无法确定:切片可以包含任意数量的元素,因此它在运行期具有任意大小;而 trait 对象则可以由任意数量的结构体或枚举实现,因此在运行期也可以具有任意大小。
专业提示:
- 在 Rust 中,指向动态大小数组视图的指针被称为切片(slice)。例如,&str 被称为 字符串切片,&[i32] 被称为 i32 切片;
- 切片占用 2 个宽度,分别存储指向数组的指针和数组中元素的数量
- trait 对象指针占用 2 个宽度,分别存储指向数据的指针和指向虚表(vtable)的指针
- 未定大小的结构体指针占用 2 个宽度,分别存储指向结构体数据的指针和结构体的大小
- 未定大小的结构体只能有一个未定大小的字段,并且它必须是结构体中最后一个字段
为了强化“未定大小类型占用 2 个宽度”的观点,此处通过带注释的代码示例,将数组与切片进行了比较。
use std::mem::size_of;
const WIDTH: usize = size_of::<&()>();
const DOUBLE_WIDTH: usize = 2 * WIDTH;
fn main() {
// 类型中存储的数据长度
// [i32; 3] 表示存放三个 i32 的数组
let nums: &[i32; 3] = &[1, 2, 3];
// 1 个指针宽度
assert_eq!(WIDTH, size_of::<&[i32; 3]>());
let mut sum = 0;
// 可以安全地迭代 nums
// Rust 知道其确切有 3 个元素
for num in nums {
sum += num;
}
assert_eq!(6, sum);
// 未定大小强制转换,从 [i32; 3] 转为 [i32]
// 数据长度现在存储在指针中
let nums: &[i32] = &[1, 2, 3];
// 需要 2 个指针宽度来同时存储数据长度
assert_eq!(DOUBLE_WIDTH, size_of::<&[i32]>());
let mut sum = 0;
// 可以安全地迭代 nums
// Rust 知道其确切有 3 个元素
for num in nums {
sum += num;
}
assert_eq!(6, sum);
}
以下是另一个有注释的代码示例,比较了结构体和 trait 对象的区别:
use std::mem::size_of;
const WIDTH: usize = size_of::<&()>();
const DOUBLE_WIDTH: usize = 2 * WIDTH;
trait Trait {
fn print(&self);
}
struct Struct;
struct Struct2;
impl Trait for Struct {
fn print(&self) {
println!("struct");
}
}
impl Trait for Struct2 {
fn print(&self) {
println!("struct2");
}
}
fn print_struct(s: &Struct) {
// 总是打印 "struct",编译期即可知
s.print();
// 单宽度指针
assert_eq!(WIDTH, size_of::<&Struct>());
}
fn print_struct2(s2: &Struct2) {
// 总是打印 "struct2",编译期即可知
s2.print();
// 单宽度指针
assert_eq!(WIDTH, size_of::<&Struct2>());
}
fn print_trait(t: &dyn Trait) {
// 打印 "struct" 还是 "struct2" ? 编译期不可知
t.print();
// Rust 需要在运行期检查指针以确定是使用
// Struct 还是 Struct2 的 "print" 实现,
// 所以指针必须是双宽度的
assert_eq!(DOUBLE_WIDTH, size_of::<&dyn Trait>());
}
fn main() {
// 单宽度指针,指向数据
let s = &Struct;
print_struct(s); // 打印 "struct"
// 单宽度指针,指向数据
let s2 = &Struct2;
print_struct2(s2); // 打印 "struct2"
// 未定大小强制转换,从 Struct 到 dyn Trait
// 双宽度指针,指向数据和 Struct 的虚表
let t: &dyn Trait = &Struct;
print_trait(t); // 打印 "struct"
// 未定大小强制转换,从 Struct2 到 dyn Trait
// 双宽度指针,指向数据和 Struct2 的虚表
let t: &dyn Trait = &Struct2;
print_trait(t); // 打印 "struct2"
}
主要收获:
- 只有固定大小类型的实例可以放在栈上,也就是说,可以按值传递
- 未定大小类型的实例无法放在栈上,必须通过引用进行传递
- 指向未定大小类型的指针是双宽度的,因为除了指向数据之外,它们还有额外的信息要管理,用以跟踪数据的长度或者指向虚表
Sized Trait
在 Rust 中,Sized trait 属于自动 trait,自动 trait 是指在特定条件下自动为类型实现的 trait。如果一个类型的所有成员都是 Sized 类型,那么该类型将自动获得 Sized 实现。成员的具体含义取决于容器类型,例如:结构体的字段,枚举的变体,数组的元素,元组的项等等。一旦某类型被标记为具有 Sized 实现,意味着它的字节大小在编译期便已知。
但同时 Size 也是一个标记 trait,它则用于表明类型具有某种特定属性,标记 trait 不包含任何 trait 项——像是方法、关联函数、关联常量或关联类型。所有自动 trait 都是标记 trait ,但不是所有标记 trait 都是自动 trait 。自动 trait 必须是标记 trait ,因为只有这样编译器才能为它们提供自动默认实现,如果某 trait 具有 trait 项,就无法再提供自动默认实现了。
其他自动标记 trait 的例子还有 Send 和 Sync,如果一个类型实现了 Send,则意味着该类型的值可以从一个线程传递到另一个线程。如果一个类型实现了 Sync,则意味着可以在多线程间使用共享引用共享其值。如果一个类型的所有成员都是 Send 和 Sync 类型,那么它将自动获得 Send 和 Sync 实现。Sized 有些特殊之处,与其他自动标记 trait 不同的是,它不可被取消。
#![feature(negative_impls)]
// 该类型是 Sized, Send 及 Sync
struct Struct;
// 取消 Send trait
impl !Send for Struct {} // ✅
// 取消 Sync trait
impl !Sync for Struct {} // ✅
// 不能取消 Sized
impl !Sized for Struct {} // ❌
这倒也合乎情理,毕竟我们可能出于一些原因不希望某类型被在线程之间传递或共享,但是很难想象出这种情景:希望编译器“忘记”某类型的大小,并将其视为一个未定大小的类型。这样做没有任何好处,只会使该类型变得更加难以处理。
此外,非常谨慎地说,Sized 在技术上其实并不是一个自动 trait,因为它并没有使用 auto 关键字进行定义,然而编译器对它的特殊处理方式使其行为非常类似于自动 trait,因此在实践中将其视为自动 trait 是可行的。
泛型中的 Sized
可能不易察觉:当编写泛型代码时,每个泛型类型参数默认都会自动绑定到 Sized trait 上。
// 该泛型函数...
fn func<T>(t: T) {}
// ...去掉语法糖后...
fn func<T: Sized>(t: T) {}
// ...可以通过明确设置为 ?Sized 来取消它...
fn func<T: ?Sized>(t: T) {} // ❌
// ...然而这将无法编译,毕竟它没有已知的大小。
// 因此我们必须将其放在指针后面...
fn func<T: ?Sized>(t: &T) {} // ✅
fn func<T: ?Sized>(t: Box<T>) {} // ✅
专业提示:
- ?Sized 可读作“可选大小的”或“可能具有大小的”,其被添加到类型参数的约束中,表示该类型既可以是固定大小,也可以是未定大小的
- ?Sized 通常被称为“放宽约束”或“宽松约束”,因为它放宽了对类型参数的限制
- ?Sized 是 Rust 中唯一的宽松约束
这个知识点很重要,为什么?这样说吧,每当使用泛型类型并将其置于指针后面时,我们几乎总是希望取消掉默认的 Sized 约束,以使函数在接受参数类型时更加灵活。另一方面,如果不取消掉默认的 Sized 约束,最终将会得到些令人困惑的编译错误信息。
use std::fmt::Debug;
fn debug<T: Debug>(t: T) { // T: Debug + Sized
println!("{:?}", t);
}
fn main() {
debug("my str"); // T = &str, &str: Debug + Sized ✅
}
目前为止一切顺利,但是该函数会获取任何传递给它的值的所有权,这有点让人闹心,所以我将函数改为只接受引用作为参数:
use std::fmt::Debug;
fn dbg<T: Debug>(t: &T) { // T: Debug + Sized
println!("{:?}", t);
}
fn main() {
dbg("my str"); // &T = &str, T = str, str: Debug + !Sized ❌
}
这下报错了:
error[E0277]: the size for values of type `str` cannot be known at compilation time
--> src/main.rs:8:9
|
8 | dbg("my str"); // &T = &str, T = str, str: Debug + !Sized ❌
| --- ^^^^^^^^ doesn't have a size known at compile-time
| |
| required by a bound introduced by this call
|
= help: the trait `Sized` is not implemented for `str`
note: required by a bound in `dbg`
--> src/main.rs:3:8
|
3 | fn dbg<T: Debug>(t: &T) { // T: Debug + Sized
| ^ required by this bound in `dbg`
help: consider relaxing the implicit `Sized` restriction
|
3 | fn dbg<T: Debug + ?Sized>(t: &T) { // T: Debug + Sized
| ++++++++
当我头一次看到这些错误信息时也是一脸懵逼,它提示我们还要给 T 设置一个 ?Sized 约束。因为参数 t 要接收 T 的引用,那么当传递 &str 的时候,T 就会被单态化为 str。但 str 是切片,大小不固定,所以还要施加一个 ?Size 约束。
use std::fmt::Debug;
fn dbg<T: Debug>(t: &T) { // T: Debug + Sized
println!("{:?}", t);
}
fn dbg2<T: Debug + ?Sized>(t: &T) { // T: Debug + ?Sized
println!("{:?}", t);
}
fn main() {
dbg(&"my str"); // 合法,因为 &T 是 &&str,所以 T 是 &str,固定大小
dbg2("my str"); // 合法,因为 &T 是 &str,所以 T 是 str,未定大小
}
总结:所有的泛型类型参数默认情况下都会自动绑定为 Sized,要求大小在编译时已知。如果单态化之后的泛型代表的类型大小未知,那么要施加 ?Sized 约束,也就是取消默认的 Sized 约束。
未定大小类型之切片
最常见的切片类型是字符串切片 &str 和数组切片 &[T],切片之好处在于许多其他类型可以自动转换为切片,利用切片和 Rust 的自动类型转换机制,我们可以编写出灵活的 API。
强制类型转换可以发生在很多场景,但最显著的是在函数参数中以及方法调用时。值得关注的类型转换有两种,即 解引用强转(Deref Coercion) 和 未定大小类型强转(Unsized Coercion)。解引用强转是指使用解引用操作将 T 强制转换为 U,即 T: Deref<Target = U>,例如 String.deref() -> str。未定大小类型强转是指将 T 强制转换为 U,其中 T 是一个固定大小的类型,而 U 是一个未定大小的类型,即 T: Unsize<U>,例如 [i32; 3] -> [i32]。
use std::ops::Deref;
fn main() {
let s = "xx".to_string();
// 也可以调用 s.as_str(),一样的
let s2: &str = s.deref();
// *s 等价于 *(s.deref()),会得到 str
// 但 str 是未定类型,并且 Rust 也不允许通过 * 移动变量值
// let s3: str = *s;
}
所以 &str 即可以接收字符串切片,也可以接收字符串引用,因为 &String 会自动调用 deref 返回 &str。
trait Trait {
fn method(&self) {}
}
impl Trait for str {
// 现在可以使用以下类型调用 "method" 方法
// 1) str 或
// 2) String, 因为 String: Deref<Target = str>
}
impl<T> Trait for [T] {
// 现在可以使用以下类型调用 "method" 方法
// 1) 任意 &[T]
// 2) 任意 U 且 U: Deref<Target = [T]>, 比如 Vec<T>
// 3) [T; N] ,N 为任意值, 因为 [T; N]: Unsize<[T]>
}
fn str_fun(s: &str) {}
fn slice_fun<T>(s: &[T]) {}
fn main() {
let str_slice: &str = "str slice";
let string: String = "string".to_owned();
// 函数参数
str_fun(str_slice);
str_fun(&string); // 解引用强转
// 方法调用
str_slice.method();
string.method(); // 解引用强转
let slice: &[i32] = &[1];
let three_array: [i32; 3] = [1, 2, 3];
let five_array: [i32; 5] = [1, 2, 3, 4, 5];
let vec: Vec<i32> = vec![1];
// 函数参数
slice_fun(slice);
slice_fun(&vec); // 解引用强转
slice_fun(&three_array); // 未定大小类型强转
slice_fun(&five_array); // 未定大小类型强转
// 方法调用
slice.method();
vec.method(); // 解引用强转
three_array.method(); // 未定大小类型强转
five_array.method(); // 未定大小类型强转
}
所以利用切片和 Rust 的自动类型转换可以编写灵活的 API。
未定大小类型之Trait 对象
之前讲过,不能通过值传递未定大小类型,因而限制了 trait 中可定义的方法的类型。理论上讲,不能编写一个以值传递 self 或返回 self 的方法,但令人惊讶的是,以下代码竟然可以编译通过:
trait Trait {
fn method(self); // ✅
}
然而一旦开始尝试实现该方法,无论是通过提供默认实现,还是通过为未定大小类型实现该 trait,都将导致编译错误:
trait Trait {
fn method(self) {} // ❌
}
impl Trait for str {
fn method(self) {} // ❌
}
因为任何类型都可以实现 Trait,那么这个类型是不是 Sized 就不知道,而如果不是 Sized,那么它就不能传值。若是想通过值传递 self,可以通过显式地将 trait 约束为 Sized 来修复第一个错误:
trait Trait: Sized {
fn method(self) {} // ✅
}
impl Trait for str { // ❌
fn method(self) {}
}
str 不是 Sized,所以无法实现 Trait。但如果真想为 str 实现该 trait 呢?解决方案是保持 trait 为 ?Sized(默认行为),并通过引用来传递 self。
trait Trait {
fn method(&self) {} // ✅
}
impl Trait for str {
fn method(&self) {} // ✅
}
与其将整个 trait 标记为 ?Sized 或 Sized,更精微准确的做法是将单个方法标记为 Sized,如下所示:
trait Trait {
fn method(self) where Self: Sized {}
}
impl Trait for str {} // ✅!?
fn main() {
"str".method(); // ❌
}
不可思议,Rust 编译了 impl Trait for str {},没有发出任何警告!好在在未定大小类型上调用 method 时,它最终能捕获到该错误,一切正常。这一表现略显古怪,但它却为实现 trait 时提供了些灵活性——可以为未定大小类型实现具有 Sized 的方法,只要你别去调用这些 Sized 方法即可。
trait Trait {
fn method(self) where Self: Sized {}
fn method2(&self) {}
}
impl Trait for str {} // ✅
fn main() {
// 别去调用 "method" 就没事儿
"str".method2(); // ✅
}
因此即使没有泛型参数,也可以使用 where 子句,它可以对内部的关联类型以及 Self 进行约束。
需要注意的是,如果 Trait: Sized,那么只有固定类型可以实现 Trait;如果是 Trait: ?Sized,那么只有 trait object 才可以实现 Trait。
专业提示:
- 默认情况下,所有 trait 都是
?Sized的 - 若
impl Trait for dyn Trait,必须有Trait: ?Sized - 可以在各个方法上单独采用
Self: Sized - 通过
Sized约束的 trait 无法转换为 trait object
Trait object(trait 对象)的限制
即使某 trait 是对象安全(object-safe)的,仍会存在一些和大小相关的边界情况,它们限制了可以转换为 trait 对象的类型以及 trait 对象可以表示的 trait 数量、类型。
fn generic<T: ToString>(t: T) {}
fn trait_object(t: &dyn ToString) {}
fn main() {
generic(String::from("String")); // ✅
generic("str"); // ✅
trait_object(&String::from("String")); // ✅ - 未定大小类型强转
trait_object("str"); // ❌ - 无法进行未定大小类型强转
}
将 &String 传递给接收 &dyn ToString 的函数能够正常工作,这是由于强制类型转换。String 实现了 ToString,而我们可以通过未定大小强转将固定大小类型(如 String)转换为未定大小类型(如 dyn ToString)。str 也实现了 ToString,将 str 转换为 dyn ToString 也需要未定大小强转,但 str 已经是未定大小的了!那又怎能将一个已是未定大小的类型转换为另一个未定大小的类型呢?
&str 指针是双宽的,分别存储了指向数据的指针和数据的长度,&dyn ToString 指针也是双宽的,存储了指向数据和指向虚表的指针。而将 &str 强制转换为 &dyn ToString需要三个宽席的指针,用于存储指向数据的指针、数据的长度和指向虚表的指针。Rust 不支持三个宽度的指针,因此无法将未定大小类型转换为 trait 对象。
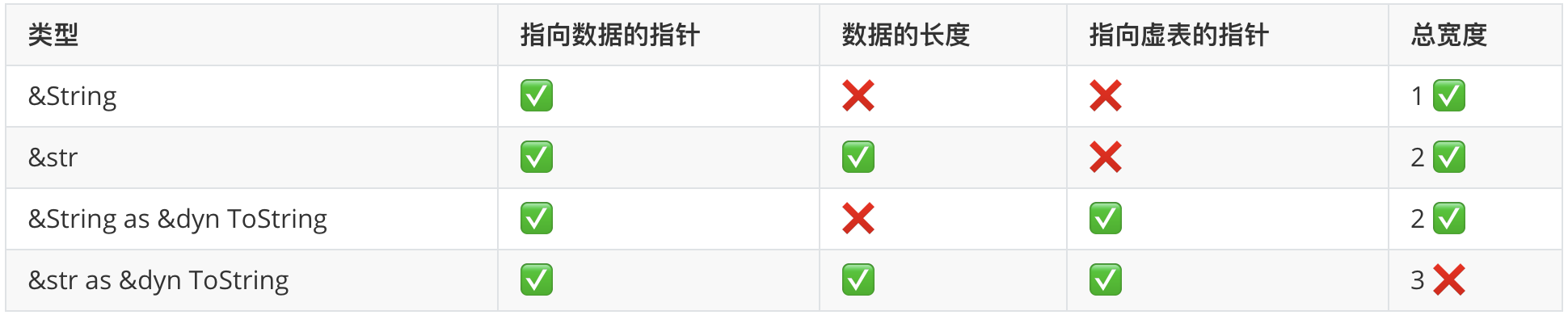
另外也无法创建多 trait 对象
trait Trait {}
trait Trait2 {}
fn function(t: &(dyn Trait + Trait2)) {}
记住,trait 对象的指针是双宽的:它存储着一个指向数据的指针和另一个指向虚表的指针,但此处有两个 trait,也就有两个虚表,这就需要将 &(dyn Trait + Trait2) 指针扩展为 3 个宽度(所以上述代码会报错)。而自动 trait(如 Sync 和 Send)是被允许的,毕竟它们没有方法,也就没有虚表。
解决此问题的方法是使用另一个 trait 将虚表合并起来,如下所示:
trait Trait {
fn method(&self) {}
}
trait Trait2 {
fn method2(&self) {}
}
// Trait3 是一个空 trait,它的目的只是起到一个合并作用
// 如果想实现 Trait3,必须实现 Trait 和 Trait2
trait Trait3: Trait + Trait2 {}
// 为同时实现了 Trait 和 Trait2 的类型 Trait3 自动提供默认实现
impl<T: Trait + Trait2> Trait3 for T {}
// 将 `dyn Trait + Trait2` 改为 `dyn Trait3`
// 这样只要实现了 Trait3,那么就一定实现了 Trait 和 Trait2
fn function(t: &dyn Trait3) {
t.method(); // ✅
t.method2(); // ✅
}
该变通方法的一个缺点是:Rust 不支持向上转换回 supertrait 类型。也就是说,对于 dyn Trait3,并不能将其用在需要 dyn Trait 或 dyn Trait2 的地方。以下程序无法编译:
trait Trait {
fn method(&self) {}
}
trait Trait2 {
fn method2(&self) {}
}
trait Trait3: Trait + Trait2 {}
impl<T: Trait + Trait2> Trait3 for T {}
struct Struct;
impl Trait for Struct {}
impl Trait2 for Struct {}
fn takes_trait(t: &dyn Trait) {}
fn takes_trait2(t: &dyn Trait2) {}
fn main() {
let t: &dyn Trait3 = &Struct;
takes_trait(t); // ❌
takes_trait2(t); // ❌
}
原因是在于尽管 dyn Trait3 包含了 dyn Trait 和 dyn Trait2 的所有方法,但它在某种意义上算作一个不同的类型,它与 dyn Trait 和 dyn Trait2 有着不同的虚表。再次变通的办法是添加显式的类型转换方法:
trait Trait {}
trait Trait2 {}
trait Trait3: Trait + Trait2 {
fn as_trait(&self) -> &dyn Trait;
fn as_trait2(&self) -> &dyn Trait2;
}
impl<T: Trait + Trait2> Trait3 for T {
fn as_trait(&self) -> &dyn Trait {
self
}
fn as_trait2(&self) -> &dyn Trait2 {
self
}
}
struct Struct;
impl Trait for Struct {}
impl Trait2 for Struct {}
fn takes_trait(t: &dyn Trait) {}
fn takes_trait2(t: &dyn Trait2) {}
fn main() {
let t: &dyn Trait3 = &Struct;
takes_trait(t.as_trait()); // ✅
takes_trait2(t.as_trait2()); // ✅
}
这一解决办法简单又直接,而且看起来像是 Rust 编译器可以自动搞定的事情。Rust 在执行解引用和未定大小强转时表现得毫不犹豫,但又为什么没有向上游 trait 的强制转换呢?这个问题很好,答案也很熟悉:Rust 核心团队正在致力于其他优先级更高、影响更大的功能。
Rust 不支持超过 2 个宽度的指针,因此:
无法将未定大小类型转换为 trait 对象无法创建多 trait 对象,但可以通过将多个 trait 合并为一个来解决该问题
用户自定义的未定大小类型
Sized 是自动 trait,如果结构体内部的所有字段都是 Sized,那么该结构体也是 Sized,反之亦然。
struct Unsized {
unsized_field: [i32],
}
可以通过给结构体添加一个未定大小的字段来定义一个未定大小的结构体。未定大小的结构体只能有一个未定大小的字段,而且该字段必须是结构体的最后一个字段。这样做是为了让编译器能够在编译时确定结构体中各个字段的起始偏移量,以便高效、快速地访问它们。此外,使用双宽度指针最多只能追踪一个未定大小的字段,毕竟更多的未定大小字段将需要更多的宽度。
那么我们该如何实例化这个结构体呢?和其它未定大小类型一样,首先需要创建一个固定大小的版本,然后将其转换为未定大小的版本。然而根据定义,Unsized 总是未定大小的,无法创建一个固定大小的版本。唯一的解决方法是将该结构体定义为泛型,这样它就可以同时存在固定大小和未定大小的版本:
struct MaybeSized<T: ?Sized> {
maybe_sized: T,
}
fn main() {
// 未定大小强转,从 MaybeSized<[i32; 3]> 至 MaybeSized<[i32]>
let ms: &MaybeSized<[i32]> = &MaybeSized { maybe_sized: [1, 2, 3] };
}
它有何使用场景呢?实际上,并没有什么特别引人注目的使用场景。用户自定义的未定大小类型目前还是个不成熟的特性,其限制超过了其好处。此处提及只是为了本文完整性的考虑。
小知识: std::ffi::OsStr和std::path::Path 是标准库中的两个未定大小类型的结构体,之前你可能使用过它们却没有意识到。
零大小类型之单元类型(Unit Type)
零大小类型(ZST)一开始听起来很奇特,但其实它们在各种场景都在被使用。最常见的零大小类型是单元类型:(),所有空代码块 {} 的求值结果均是 ()。若代码块非空但其最后一个表达式使用分号 ; 舍弃时,其求值结果也是 ()。例如:
fn main() {
let a: () = {};
let b: i32 = {
5
};
let c: () = {
5;
};
}
默认情况下,没有显式指定返回类型的函数均返回 ()。
// 带语法糖
fn function() {}
// 去糖后
fn function() -> () {}
由于 () 占用零字节,所有 () 的实例都相同,这使得实现其 Default、PartialEq 及 Ord 非常简单:
use std::cmp::Ordering;
impl Default for () {
fn default() {}
}
impl PartialEq for () {
fn eq(&self, _other: &()) -> bool {
true
}
fn ne(&self, _other: &()) -> bool {
false
}
}
impl Ord for () {
fn cmp(&self, _other: &()) -> Ordering {
Ordering::Equal
}
}
编译器能够理解 () 为零大小,并优化与 () 实例相关的交互操作。例如,Vec<()> 不会进行任何堆分配,从 Vec 中 push 或 pop () 只会递增或递减其 len 字段:
fn main() {
// “存储”无限多个 () 所需的全部容量是:零容量
let mut vec: Vec<()> = Vec::with_capacity(0);
// 不会导致堆分配或 vec 容量的变化
vec.push(()); // len++
vec.push(()); // len++
vec.push(()); // len++
vec.pop(); // len--
assert_eq!(2, vec.len());
}
上面的例子并没什么实际用处,但是,是否可以在某种情况下以一种有意义的方式利用上述理念呢?必然可以,比如可以将 Value 设置为 (),再从 HashMap<Key, Value> 中获得高效的 HashSet<Key> 实现,而这正是 Rust 标准库中 HashSet 的工作方式:
// std::collections::HashSet
pub struct HashSet<T> {
map: HashMap<T, ()>,
}
除了 () 之外还有单元结构体,它也是 ZST,表示内部没有任何字段(成员变量)的结构体,例如:
struct Struct;
有一些特性使得单元结构体比 () 更具价值:
可以在自定义的单元结构体上实现任意想要的 trait,Rust trait 所遵从的孤儿原则会阻止我们为 () 实现 trait,这是由于其在标准库中已经定义可以根据程序上下文,为单元结构体赋予有意义的名称单元结构体和所有结构体一样,默认情况下都是不可复制的,这在程序上下文中可能很重要
总之:
所有 ZST 实例互相都是等价的Rust 编译器清楚如何优化与 ZST 的交互
零大小类型之 Never 类型
Never 类型可算作第二常见的零大小类型(ZST):!。它之所以被称为 never 类型,是因为其代表的计算永远不会解析成任何值。
! 与 () 不同,它有一些有趣的特性:
!可以强制转换为任意其他类型- 不可能创建
!的实例
第一个特性非常有用,使得我们能够像下面这样便捷地使用宏:
// 便于快速形成原型
fn example<T>(t: &[T]) -> Vec<T> {
unimplemented!() // ! 强转为 Vec<T>
}
fn example2() -> i32 {
// 可以看出此次调用 parse 永远不会失败
match "123".parse::<i32>() {
Ok(num) => num,
Err(_) => unreachable!(), // ! 强转为 i32
}
}
fn example3(some_condition: bool) -> &'static str {
if !some_condition {
panic!() // ! 强转为 &str
} else {
"str"
}
}
break、 continue 及 return 表达式也是 ! 类型
fn example() -> i32 {
// 此处 x 可以设为任意类型,因为该代码块不返回任何值
let x: String = {
return 123 // ! 强转为 String
};
}
fn example2(nums: &[i32]) -> Vec<i32> {
let mut filtered = Vec::new();
for num in nums {
filtered.push(
if *num < 0 {
break // ! 强转为 i32
} else if *num % 2 == 0 {
*num
} else {
continue // ! 强转为 i32
}
);
}
filtered
}
第二个有趣的特性是:! 允许在类型层面上将某些状态标记为“不可能的”,以下面这个函数签名为例:
fn function() -> Result<Success, Error>;
我们知道,如果函数成功返回,Result 将包含某个类型为 Success 的实例,如果出现错误,Result 将包含某个类型为 Error 的实例。但如果我们能保证函数一定返回成功呢?
fn function() -> Result<Success, !>;
我们知道,如果函数成功返回,Result 将包含某个类型为 Success 的实例,如果出现错误...等等,它永远不会出错,因为无法创建 ! 的实例。根据上述函数签名可知该函数永远不会出错,那么下面这个函数签名呢:
fn function() -> Result<!, Error>;
与之前相反,如果该函数返回,我们知道它一定是出错了,毕竟它不可能成功。
另外在 Rust 内部使用 never 类型是可行的,但在用户代码层面使用它仍被视为实验性质的,因此需要使用 never_type 特性标识。
!可以强制转换为其他任何类型- 不能创建
!的实例,但可以使用它在类型层面上标记某些不可能的状态
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号