聊一聊标准库中的那些 trait
楔子
上一篇文章我们花费相当大的笔墨复习并补充了 trait 的知识,本次来介绍一下标准库中的 trait(前面文章已经详细说过的,这里就不赘述了)。Rust 标准库中包含大量的 trait 定义,甚至 Rust 自身的某些语言特性就是在这些 trait 的帮助下实现的。这些 trait 和标准库里的各种类型一起,构成了整个 Rust 生态的根基,只有了解它们才算真正了解 Rust。
Default
我们来看 Default trait 的定义,以及对 Default trait 的实现和使用。
trait Default {
fn default() -> Self;
}
显然这个 trait 用于创建指定类型的默认值。
#[derive(Debug)]
struct Color(u8, u8, u8);
impl Default for Color {
fn default() -> Self {
Color(0, 0, 0)
}
}
fn main() {
let n1: i32 = Default::default();
let n2 = i32::default();
let n3 = <i32 as Default>::default();
println!("{} {} {}", n1, n2, n3); // 0 0 0
let s: String = Default::default();
println!("'{}'", s); // ''
let arr: [u8; 3] = Default::default();
println!("{:?}", arr); // [0, 0, 0]
let c1: Color = Default::default();
// 如果 Color 实现了多个 trait,并且存在多个 default,那么这种方法会产生歧义
let c2: Color = Color::default();
let c3: Color = <Color as Default>::default();
println!("{:?}", c1); // Color(0, 0, 0)
println!("{:?}", c2); // Color(0, 0, 0)
println!("{:?}", c3); // Color(0, 0, 0)
}
所以任何实现了 Default trait 的类型,调用 default 方法都会返回自身的实例,或者也可以使用 Default 本身来调用,具体的返回值类型则通过类型标注来指定。
另外还有其它一些地方用到了 Default,比如 Option 的 unwrap_or_default(),在类型参数上调用 default() 函数。
#[derive(Debug)]
struct Color(u8, u8, u8);
impl Default for Color {
fn default() -> Self {
Color(0, 0, 0)
}
}
fn main() {
let s = Some(123);
// 如果是 Some(T),返回 T,否则 panic
println!("{}", s.unwrap()); // 123
// 如果是 Some(T),返回 T,否则返回指定的默认值
let s: Option<&str> = None;
println!("{}", s.unwrap_or("嘿嘿")); // 嘿嘿
// 如果是 Some(T),返回 T,否则返回 Default::default()
let s: Option<[&str; 3]> = None;
println!("{:?}", s.unwrap_or_default()); // ["", "", ""]
let s: Option<Color> = None;
println!("{:?}", s.unwrap_or_default()); // Color(0, 0, 0)
}
对于这些标准库中的 trait,我们没有必要通过 impl 的方式,因为不太方便。Rust 标准库实际给我们提供了一个标注,也就是 #[derive()],方便我们为结构体自动实现指定的 trait。
#[derive(Default)]
struct Color(u8, u8, u8);
#[derive(Default)]
struct Point {
x: i32,
y: i32,
}
注意这里的细节,我们用 #[derive()] 在两个结构体上作了标注,这里面出现的 Default 不是 trait,它是一个同名的派生宏(我们后面会讲到),这种派生宏标注帮助我们实现了 Default trait。Rustc 能正确区分 Default 到底是宏还是 trait,因为它们出现的位置不一样。
那为什么可以自动实现 Default trait 呢?因为 Color 里面的类型是基础类型 u8,而 u8 是实现了 Default trait 的,默认值为 0。
Display
我们看 Display trait 的定义。
trait Display {
fn fmt(&self, f: &mut Formatter<'_>) -> Result;
}
Display trait 对应于格式化符号 "{}",比如 println!("{}", s),用于决定一个类型如何显示,其实就是把类型转换成字符串表达。
use std::fmt::{Display, Formatter};
struct Point {
x: i32,
y: i32,
}
impl Display for Point {
fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
let s = format!("x = {}, y = {}", self.x, self.y);
f.write_str(&s)
}
}
fn main() {
let p = Point{x: 11, y: 22};
println!("{}", p); // x = 11, y = 22
}
上面说了 #[derive()] 里面的不是 trait,而是同名的派生宏,它会帮我们实现指定的 trait。但是 Display 没有相应的派生宏,需要我们自己手动通过 impl 去实现。
ToString
来看 ToString trait 定义。
trait ToString {
fn to_string(&self) -> String;
}
它提供了一个 to_string() 方法,方便把各种类型实例转换成字符串。但实际上不需要自己去给类型实现 ToString trait,因为标准库已经帮我们做了实现,像下面这个样子。
impl<T: Display> ToString for T
也就是说,凡是实现了 Display 的就实现了 ToString,这两个功能本质是一样的,就是把类型转换成字符串表达。只不过 Display 侧重于展现,ToString 侧重于类型转换。所以把一个符合条件的类型实例转换成字符串有两种常用方法:
let s = format!("{}", obj);
// 或
let s = obj.to_string();
比较简单。
Debug
Debug 跟 Display 很像,也主要是用于调试打印。打印就需要指定格式,区别在于 Debug trait 是配对 "{:?}" 格式的,Display 是配对 "{}" 的,它们本身都是将类型表示或转换成 String 类型。一般来说,Debug 的排版信息比 Display 要多一点,因为它是给程序员调试用的,不是给最终用户看的。Debug 还配套了一个美化版本格式 "{:#?}",用来把类型打印得更具结构化一些,适合调试的时候查看,比如 json 结构会展开打印。
Rust 标准库提供了 Debug 宏,一般来说,我们都是以这个宏为目标类型自动生成 Debug trait,而不是由我们自己手动去实现。这一点和 Display 正好相对,std 标准库里并没有提供一个 Display 宏,来帮助我们自动实现 Display trait,需要我们手动实现它。
再次提醒一下,Rust 的结构体类型能够自动被 derive 的条件是,它里面的每个元素都能被 derive。比如下面这个结构体里的每个字段,都是 i32 类型的,这种基础类型在标准库里已经被实现过 Debug trait 了,所以可以直接在 Point 上做 derive 为 Point 类型实现 Debug trait。这个原则适用于所有 trait,后面不再赘述。
#[derive(Debug)]
struct Point {
x: i32,
y: i32,
}
一般来说,实现了 Display 的类型也实现了 Debug,换句话说,能用 {} 打印的也可以用 {:?} 打印,但反过来则不行。
PartialEq 和 Eq
如果一个类型上实现了 PartialEq,那么它就能比较两个值是否相等,这种可比较性满足数学上的对称性和传递性:
对称性(symmetry):a == b 导出 b == a传递性(transitivity):a == b && b == c 导出 a == c
而 Eq 定义为 PartialEq 的 subtrait(实现 Eq 的同时也必须实现 PartialEq),在 PartialEq 的对称性和传递性的基础上,又添加了自反性,也就是对所有 a 都有 a == a。最典型的就是 Rust 中的浮点数只实现了 PartialEq,没实现 Eq,因为根据 IEEE 的规范,浮点数中存在一个 NaN,它不等于自己,也就是 NaN ≠ NaN。而对整数来说,PartialEq 和 Eq 都实现了。
如果一个类型,它的所有字段都实现了 PartialEq,那么使用标准库中定义的 PartialEq 派生宏,我们可以为目标类型自动实现可比较能力,用 == 号,或者用 assert_eq!() 做判断。
#[derive(PartialEq)]
struct Point {
x: i32,
y: i32,
}
fn main() {
let p1 = Point{x: 11, y: 22};
let p2 = Point{x: 11, y: 22};
println!("{}", p1 == p2); // true
}
如果每个字段的值都相等,那么结构体实例就相等。
PartialOrd 和 Ord
PartialOrd 和 PartialEq 差不多,PartialEq 只判断相等或不相等,PartialOrd 在这个基础上进一步判断是小于、小于等于、大于还是大于等于。可以看到,它就是为排序功能准备的。
另外 PartialOrd 被定义为 PartialEq 的 subtrait,它们在类型上可以用过程宏一起 derive 实现。
#[derive(PartialEq, PartialOrd)]
struct Point {
x: i32,
y: i32,
}
#[derive(PartialEq, PartialOrd)]
enum Stoplight {
Red,
Yellow,
Green,
}
类似的,Ord 定义为 Eq + PartialOrd 的 subtrait。如果我们为一个类型实现了 Ord,那么对那个类型的所有值,我们可以做出一个严格的总排序,比如 u8,我们可以严格地从 0 排到 255,形成一个确定的从小到大的序列。同样的,浮点数实现了 PartialOrd,但是没实现 Ord。
由于 Ord 严格的顺序性,如果一个类型实现了 Ord,那么这个类型可以被用作 BTreeMap 或 BTreeSet 的 key。
BTreeMap、BTreeSet:相对于 HashMap 和 HashSet,是两种可排序结构。
运算符重载
加减乘除、取余、取模、位运算符等等,都是基于 trait 实现的,通过实现 trait,我们便可重载运算符,我们之前介绍过的。
use std::fmt::{Display, Formatter};
use std::ops::Shl;
#[derive(Debug)]
struct Point {
x: i32,
y: i32,
}
// 左移操作
impl Shl for Point {
type Output = Self;
fn shl(self, rhs: Self) -> Self::Output {
Point{x: self.x << rhs.x, y: self.y << rhs.y}
}
}
fn main() {
let p1 = Point{x: 5, y: 2};
let p2 = Point{x: 2, y: 3};
println!("{:?}", Point{x: 5 << 2, y: 2 << 3}); // Point { x: 20, y: 16 }
println!("{:?}", p1 << p2); // Point { x: 20, y: 16 }
}
实际上,Rust 标准库提供了一套完整的与运算符对应的 trait,你可以在 std::ops 里面找到可重载的运算符(或者直接去官网查看),然后按照类似的方式练习如何自定义各种运算符。
Clone
定义:
trait Clone {
fn clone(&self) -> Self;
}
这个 trait 给目标类型提供了 clone() 方法用来完整地克隆实例,使用标准库里面提供的 Clone 派生宏可以方便地为目标类型实现 Clone trait。
#[derive(Clone)]
struct Point {
x: u32,
y: u32,
}
因为每一个字段(u32 类型)都实现了 Clone,所以通过 derive,自动为 Point 类型实现了 Clone trait。实现后,Point 的实例 point 使用 point.clone() 就可以把自己克隆一份了。
再看一下方法的签名,可以看到它是不可变引用。
fn clone(&self) -> Self;
这里面有两种情况。
第一种是已经拿到实例的所有权,clone 一份生成一个新的所有权并被局部变量所持有第二种是只拿到一个实例的引用,想拿到它的所有权,如果这个类型实现了 Clone trait,那么就可以 clone 一份拿到这个所有权
clone() 是对象的深度拷贝,可能会有比较大的额外负载,但是就大多数情况来说其实还好。不要担心在 Rust 中使用 clone(),先把程序功能跑通最重要。Rust 的代码,性能一般都不会太差,毕竟起点很高。
注:浅拷贝是按值拷贝一块连续的内存,只复制一层,不会去深究这个值里面是否有到其它内存资源的引用。与之相对,深拷贝就会把这些引用对象递归全部拷贝。
实际上在 Rust 生态的代码中,我们经常看到 clone(),因为它把对实例引用的持有转换成了对对象所有权的持有。一旦我们拿到了所有权,很多代码写起来就比较轻松了。
Copy
接下来,我们看 Copy trait 的定义。
trait Copy: Clone {}
Copy 被定义为 Clone 的 subtrait,并且不包含任何内容,仅仅是一个标记(marker)。有趣的是,我们不能自己为自定义类型实现这个 trait。比如下面这个示例就是不行的:
impl Copy for Point {} // 这是不行的
但是 Rust 标准库提供了 Copy 过程宏,可以让我们自动为目标类型实现 Copy trait。
#[derive(Copy, Clone)]
struct SomeType;
因为 Copy 是 Clone 的 subtrait,所以理所当然要把 Clone trait 也一起实现,我们在这里一次性 derive 过来。Copy 和 Clone 的区别是,Copy 是浅拷贝只复制一层,不会去深究这个值里面是否有到其他内存资源的引用。因此对于 Copy 类型来说,它的深拷贝和浅拷贝其实是等价的,我们前面说过。
然后要注意的是,如果你想让结构体是可 Copy 的,那么它内部的字段必须也是可 Copy 的,否则就会报错。
struct Atype {
num: u32,
a_vec: Vec<u32>,
}
fn main() {
let a = Atype {
num: 100,
a_vec: vec![10, 20, 30],
};
let b = a; // 这里发生了移动
}
如果我们给这个结构体实现了 Clone trait 的话,就可以调用 .clone() 来产生一份新的所有权。但如果要给结构体实现 Copy 呢?答案是不能实现 Copy,因为 a_vec 不是可 Copy 的。因为 Vec 是一种所有权结构,如果你在它上面实现了 Copy,那再赋值的时候,就会出现对同一份资源的两个指向,冲突了!
而一旦一个类型实现了 Copy,它就会具备一个特别重要的特性:再赋值的时候会复制一份自身。那么就相当于新创建一份所有权。我们来看下面这个值全在栈上的类型:
#[derive(Clone)]
struct Point {
x: u32,
y: u32,
}
fn main() {
let a = Point {x: 10, y: 10};
let b = a; // 这里发生了所有权 move,a 在后续不能使用了
}
上面只实现了 Clone,因此调用 clone 拷贝一份是没有问题的,但如果直接赋值的话,那么就会发生移动。尽管它的数据都在栈上,但它没有实现 Copy,没有实现的话,在赋值给其它变量时就会移动。
#[derive(Copy, Clone)]
struct Point {
x: u32,
y: u32,
}
fn main() {
let a = Point {x: 10, y: 10};
let b = a; // 这里发生了复制,a 在后续可以继续使用
let c = a; // 这里又复制了一份,这下有 3 份了
}
仔细体会一下,我们前面所说的复制与移动的语义区别根源。你可能会问,Point 结构体里面的字段其实全都是固定尺寸的,并且 u32 是 copy 语义的,按理说 Point 也是编译时已知固定尺寸的,为什么它默认不实现 copy 语义呢?
这其实是 Rust 设计者故意这么做的,因为 Copy trait 其实关联到赋值语法,仅仅从这个语法(let a = b;),很难一下子看出来这到底是 copy 还是 move,它是一种隐式行为。
而在所有权的第一设计原则框架下,Rust 默认选择了 move 语义。所以方便起见,Rust 设计者就只让最基础的那些类型,比如 u32、bool 等具有 copy 语义,而用户自定义的类型,一概默认 move 语义。如果用户想给自定义类型赋予 copy 语义内涵,那么他需要显式地在那个类型上添加 Copy 的 derive。
我们再回过头来看 Clone,一个类型实现了 Clone 后,需要显式地调用 .clone() 方法才会导致对象克隆,这就在代码里面留下了足迹。而如果一个类型实现了 Copy,那么它在用 = 号对实例再赋值的时候就发生了复制,这里缺少了附加的足迹。这就为潜在的 Bug 以及性能的降低埋下了隐患,并且由于没有附加足迹,导致后面再回头来审查的时候非常困难
试想,如果是.clone(),那么我们只需要用代码搜索工具搜索代码哪些地方出现了 clone 方法就可以了。这个设计,在 Option 和 Result 的 unwrap() 系列函数上也有体现。
显式地留下足迹,是 Rust 语言设计重要的哲学之一。
至于 Copy 为什么要定义成 Clone 的 subtrait,而不是反过来,也是跟这个设计哲学相关。可以这么说,一般情况下,Rust 鼓励优先使用 Clone 而不鼓励使用 Copy,于是让开发者在 derive Copy 的时候,也必须 derive Clone,相当于多打了几个字符,多付出了一点代价。也许开发者这时会想,可能 Clone 就能满足我的要求了,也没必要使用 Copy。
还有一个原因其实是,Clone 和 Copy 在本质上其实是一样的,都是内存的按位复制,只是复制的规则有一些区别。
ToOwned
ToOwned 相当于是 Clone 更宽泛的版本。ToOwned 给类型提供了一个 to_owned() 方法,可以将引用转换为所有权实例。
fn main() {
let a: &str = "123456";
let s: String = a.to_owned();
println!("{} {}", a, s); // 123456 123456
}
个人一般更习惯使用 clone。
Deref
Deref trait 可以用来把一种类型转换成另一种类型,但是要在引用符号 &、点号操作符 . 或其它智能指针的触发下才会产生转换。比如标准库里最常见的 &String 可以自动转换到 &str,就是因为 String 类型实现了 Deref trait。
use std::ops::Deref;
#[derive(Debug)]
struct Girl {
name: String,
}
impl Deref for Girl {
type Target = str;
// 返回 &str
fn deref(&self) -> &Self::Target {
// 或者调用 self.name.as_str() 两者是等价的,都是创建一个字符串切片
&self.name[..]
}
}
fn main() {
let g = Girl { name: "satori".to_string() };
// 等价于 g.deref()
println!("{:?}", &g); // Girl { name: "satori" }
// *g 也等价于 *(g.deref())
}
比较简单,前面也说过了。
Drop
Drop trait 用于给类型做自定义垃圾清理(回收)。
trait Drop {
fn drop(&mut self);
}
实现了这个 trait 的类型的实例在走出作用域的时候,触发调用 drop() 方法,这个调用发生在这个实例被销毁之前。
struct A;
impl Drop for A {
fn drop(&mut self){
// 可以尝试在这里打印点东西看看什么时候调用
}
}
一般来说,我们不需要为自己的类型实现这个 trait,除非遇到特殊情况,比如我们要调用外部的 C 库函数,然后在 C 那边分配了资源,由 C 库里的函数负责释放,这个时候我们就要在 Rust 的包装类型(对 C 库中类型的包装)上实现 Drop,并调用那个 C 库中释放资源的函数。后续介绍 FFI 编程时,你会看到 Drop 的具体使用。
From<T> 和 Into<T>
From 和 Into,它们用于类型转换。From 可以把类型 T 转为自己,而 Into 可以把自己转为类型 T。
trait From<T> {
fn from(T) -> Self;
}
trait Into<T> {
fn into(self) -> T;
}
可以看到它们是互逆的 trait,实际上,Rust 只允许我们实现 From<T>,因为实现了 From 后,自动就实现了 Into。
struct Point {
x: i32,
y: i32,
}
impl From<(i32, i32)> for Point { // 实现从 (i32, i32) 到 Point 的转换
fn from((x, y): (i32, i32)) -> Self {
Point { x, y }
}
}
impl From<[i32; 2]> for Point { // 实现从 [i32; 2] 到 Point 的转换
fn from([x, y]: [i32; 2]) -> Self {
Point { x, y }
}
}
fn example() {
// 使用from()转换不同类型
let origin = Point::from((0, 0));
let origin = Point::from([0, 0]);
// 使用into()转换不同类型
let origin: Point = (0, 0).into();
let origin: Point = [0, 0].into();
}
注意:From 是单向的,对于两个类型要互相转的话,需要互相实现 From。
From<T> 和 Into<T> 都隐含了所有权,From<T> 的 Self 是具有所有权的,Into<T> 的 T 也是具有所有权的。Into<T> 有个常用的比 From<T> 更自然的场景是,如果你已经拿到了一个变量,想把它变成具有所有权的值,Into 写起来更顺手。因为 into() 是方法,而 from() 是关联函数。
struct Person {
name: String,
}
impl Person {
// 这个方法只接收String参数
fn new1(name: String) -> Person {
Person { name }
}
// 这个方法可接收
// - String
// - &String
// - &str
// - Box<str>
// - char
// 这几种参数,因为它们都实现了Into<String>
fn new2<N: Into<String>>(name: N) -> Person {
Person { name: name.into() } // 调用into(),写起来很简洁
}
}
另外除了 From 和 Into 之外,还有 TryFrom、TryInto,它是可失败版本。
trait TryFrom<T> {
type Error;
fn try_from(value: T) -> Result<Self, Self::Error>;
}
trait TryInto<T> {
type Error;
fn try_into(self) -> Result<T, Self::Error>;
}
可以看到,调用 try_from() 和 try_into() 后返回的是 Result,你需要对 Result 进行处理。
AsRef
实现 AsRef trait,可以将自身的引用转换成目标类型的引用,这种转换通常用于函数和方法参数,使得你可以传递不同的类型,只要它们能被引用为所需的目标类型。
trait AsRef<T> {
fn as_ref(&self) -> &T;
}
AsRef 可以让函数参数中传入的类型更加多样化,不管是引用类型还是具有所有权的类型,都可以传递。
struct MyStruct {
data: String,
}
impl AsRef<str> for MyStruct {
fn as_ref(&self) -> &str {
&self.data
}
}
比如我们之前说过的 Option<T>,它就可以调用 as_ref 将 Option<T> 转成 Option<&T>。
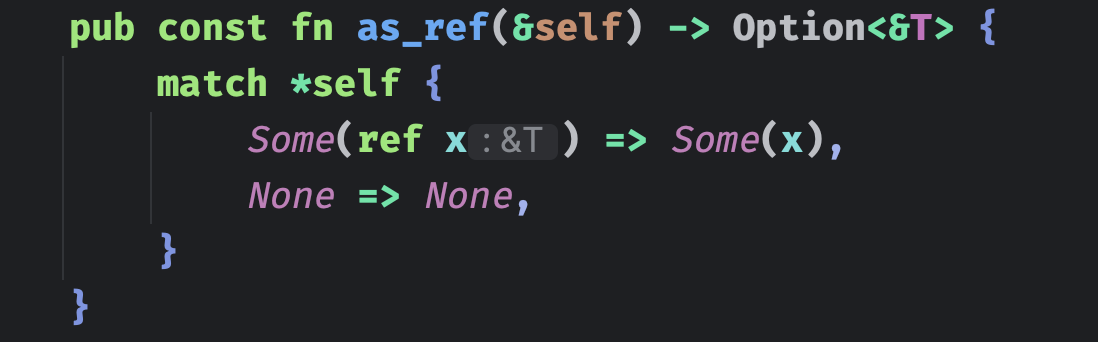
AsRef<T> 还可以让函数参数中传入的类型更加多样化,不管是引用类型还是具有所有权的类型,都可以传递。
fn process<T: AsRef<str>>(input: T) {
let input_str = input.as_ref();
// 处理 input_str
}
现在,你可以传递 String、&String、&str 或任何实现了 AsRef<str> 的自定义类型。
未完待续
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号