复习一下 Rust 的 Option<T>、Result<T, E> 和迭代器
楔子
今天我们一起来回顾一下在 Rust 中高频使用的 Option<T>、Result<T, E>、迭代器,通过学习这些内容,我们可以继续夯实集合中所有权相关的知识点。
Option<T> 和 Result<T, E> 并不是 Rust 的独创设计,在 Rust 之前,OCaml、Haskell、Scala 等已经使用它们很久了。新兴的一批语言 Kotlin、Swift 等也和 Rust 一样引入了这两种类型,而 C++17 之后也引入了它们。这其实能说明使用 Option<T> 和 Result<T, E> 逐渐成了编程语言圈子的一种新共识,而迭代器已经是目前几乎所有主流语言的标配了,所以我们也来看看 Rust 中的迭代器有什么独到的地方。
Option<T> 和 Result<T, E>
先来看看 Option 的定义,说白了它就是个带类型参数枚举。
pub enum Option<T> {
None,
Some(T),
}
Option<T> 定义为包含两个变体的枚举。一个是不带负载的 None,另一个是带一个类型参数作为其负载的 Some。Option<T> 的实例在 Some 和 None 中取值, 表示这个实例有取空值的可能。你可以将 Option<T> 理解为把空值单独提出来了一个维度,在没有 Option<T> 的语言中,空值是分散在其他类型中的。比如空字符串、空数组、数字 0、NULL 指针、None 等。并且有的语言还把空值区分为空值和未定义的值,如 nil、undefined 等。
Rust 做了两件事情来解决这个混乱的场面:第一,Rust 中所有的变量定义后使用前都必须初始化,所以不存在未定义值这个情况。第二,Rust 把空值单独提出来统一定义成 Option<T>::None,并在标准库层面上就做好了规范,上层的应用在设计时也应该遵循这个规范。
let s = String::from("");
let a: Option<String> = Some(s);
变量 a 是携带空字符串的 Option<String> 类型,空字符串的空和 None 所表示的无表达了不同的意义。
Result<T, E> 的定义也很简单:
pub enum Result<T, E> {
Ok(T),
Err(E),
}
它被定义为包含两个变体的枚举,这两个变体各自带一个类型参数作为其负载。Ok(T) 用来表示结果正确,Err(E) 用来表示结果有错误。
对比其他语言函数错误返回的约定,C、CPP、Java 语言里有时用返回 0 来表示函数执行正确,有时又不是这样,你需要根据代码所在的上下文环境来判断返回什么值代表正确,返回什么值代表错误。而 Go 语言强制对函数返回值做出了约定。
ret, err := function()
if err != nil {}
约定要求函数返回两个值,正确的情况下,ret 存放返回值,err 为 nil。如果函数要返回错误值,那么会给 err 变量填充具体的内容,于是就出现了经典的满屏 if err != nil 代码,成了 Go 语言圈的一个梗。可以看到,Go 语言已经朝着把错误信息和正常返回值类型剥离开来的方向走出了一步。
而 Rust 没有像 Go 那样设计,一是因为 Rust 不存在单独的 nil 这种空值,二是 Rust 直接用带类型参数的枚举就可以达到这个目的。
因为一个枚举实例在一个时刻只能是对应枚举类型的某一个变体,所以一个函数的返回值,不论它是正确的情况还是错误的情况,都能用 Result 类型统一表达,这样会显得更紧凑。同时还因为 Result 是一种类型,我们可以在它之上添加很多操作,用起来很方便。
let r: Result<String, String> = function();
这个例子表示将函数返回值赋给变量 r,返回类型是 Result<String, String>。在正确的情况下,返回内容为 String 类型;错误的情况下,被返回的错误类型也是 String。你是不是在想:两种可以一样?当然可以,这两个类型参数可以被任意类型代入。
Result<T, E> 被用来支撑 Rust 的错误处理机制,所以非常重要,尽管前面已经介绍过了,但我们后续还会回顾基于 Result<T, E> 的错误处理。
解包
现在我们遇到了一个问题,像 Some(10u32) 和 10u32 明显已经不是同一种类型了,我们真正想要的值被包裹在了另外一种类型里面,这种包裹是通过枚举变体来实现的。而获取被包在里面的值这一过程叫做解包,那么应该怎么做呢?
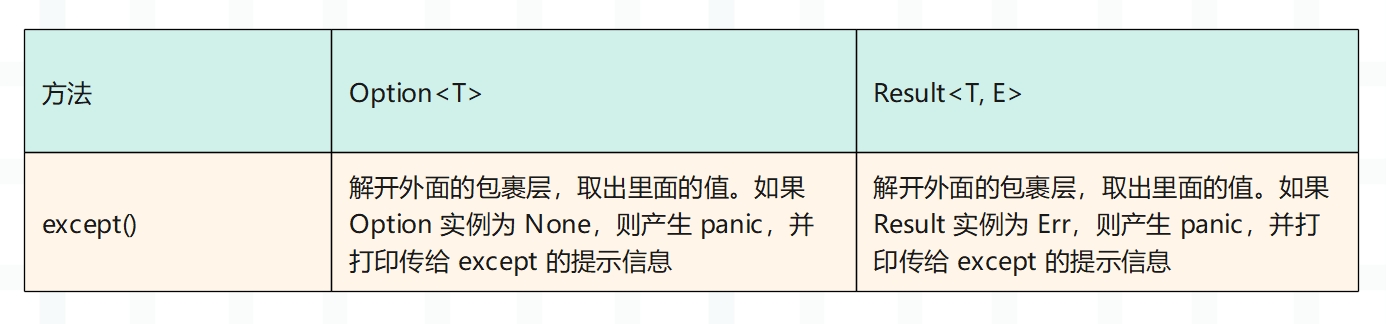
其实有很多办法,这里先列出三种方法,分别是 expect()、unwrap()、unwrap_or()。
举个例子:
fn main() {
let some_n = Some(123);
let n = some_n.expect("我想要的不是 None");
println!("{}", n); // 123
let none: Option<i32> = None;
let n = none.expect("我想要的不是 None");
/*
thread 'main' panicked at '我想要的不是 None', src\main.rs:10:18
stack backtrace:
0: std::panicking::begin_panic_handler
*/
}
Reust 也是如此,如果返回的是 Ok(T),那么将 T 取出来;如果返回的是 Err(E),那么 panic。
fn main() {
let result: Result<&str, &str> = Ok("返回结果");
println!("{}", result.expect("我期待一个结果,不是错误")); // 返回结果
let result: Result<&str, &str> = Err("发生错误");
println!("{}", result.expect("我期待一个结果,不是错误"));
/*
thread 'main' panicked at '我期待一个结果,不是错误: "发生错误"', src\main.rs:9:27
stack backtrace:
0: std::panicking::begin_panic_handler
*/
}
所以 except 解包非常简单,对于 Option<T> 来说,如果是 Some(T),那么将值取出来,如果是 None,那么 panic。对于 Result<T, E> 来说,如果是 Ok(T),那么将值取出来,如果是 Err(E),那么 panic。
说完了 except,再来看看 unwrap,它和 except 的用法一样,但是 unwrap 不接收参数。也就是说调用 unwrap 如果失败,我们无法自定义异常提示信息。
fn main() {
let some_n = Some(123);
println!("{}", some_n.unwrap()); // 123
let result: Result<&str, &str> = Ok("返回结果");
println!("{}", result.unwrap()); // 返回结果
}
最后一个 unwrap_or,它可以给定一个默认值,如果解析失败,返回默认值。
fn main() {
let some_n = Some(123);
println!("{}", some_n.unwrap_or(0)); // 123
let none: Option<&str> = None;
// 因为是 Option<&str>,所以默认值也要是 &str 类型
println!("{}", none.unwrap_or("默认值")); // 默认值
let result: Result<i32, &str> = Err("出现错误");
println!("{}", result.unwrap_or(0)); // 0
}
以上就是三种解包操作,可以看到虽然不麻烦,但要反复解包也挺费劲的。如果我们总是先用 Option<T> 或 Result<T, E> 把值包裹起来,用的时候再手动解包,那其实说明没有真正抓住到 Option<T> 和 Result<T, E> 的设计要义。因为在 Rust 中,很多时候我们不需要解包也能操作里面的值,这样就不用做看起来多此一举的解包操作了。下面我们来看一下在不解包的情况下,我们可以怎样做。
不解包的情况下如何操作?
不解包的情况下如果想要获取被包在里面的值,就需要用到 Option<T> 和 Result<T, E> 里的一些常用方法。
Option<T> 的一些方法
map:在 Option 是 Some 的情况下,通过 map 中提供的函数或闭包对 Some 里的值进行操作。在 Option 是 None 的情况下,保持 None 不变。map() 会消耗原类型,也就是获取所有权。
fn main() {
let some_n = Some(123);
let some_n2 = some_n.map(|c| c * 2);
println!("{:?}", some_n); // Some(123)
println!("{:?}", some_n2); // Some(246)
}
我们看一下 map 的源代码:
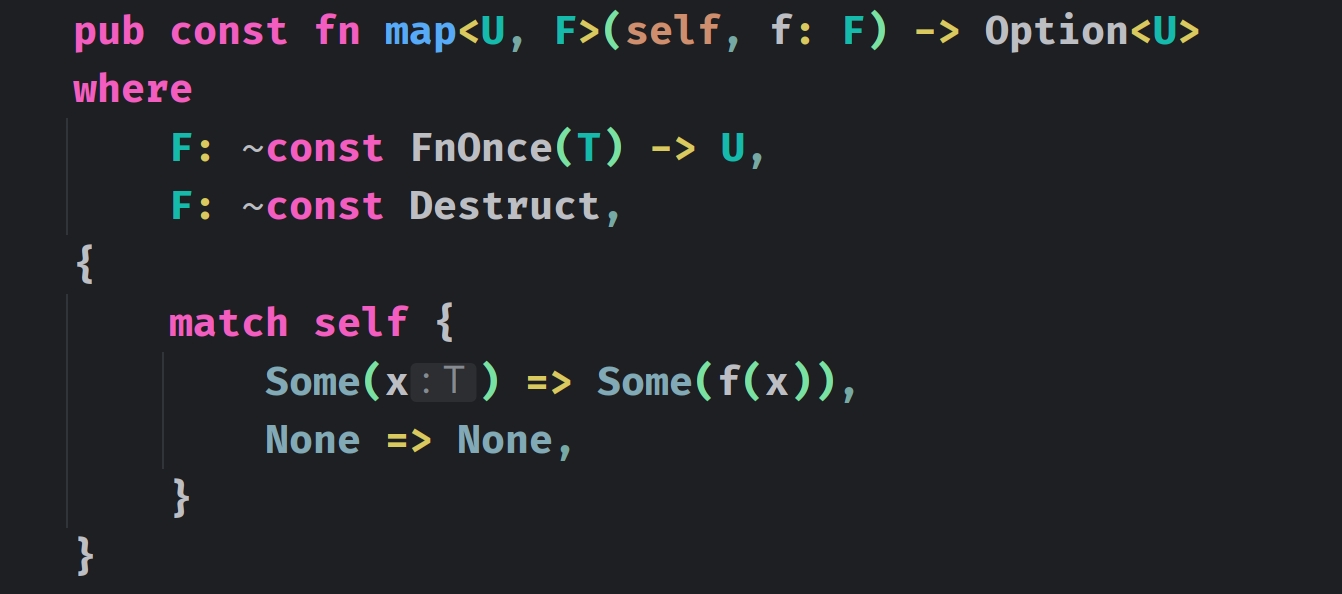
如果 T 是可 Copy 的,那么 Option<T> 也是可 Copy 的,反之亦然。调用的时候,会对 self 进行匹配,如果是 None,那么返回 None;如果是 Some(x),那么 会返回 Some(f(x)),这里的 f 就是我们传给 map 的匿名函数。所以这里的 Some(123) 再 map 之后,就是 Some(123 * 2),即 Some(246)。
那么问题来了,由于 map 会夺走所有权,那么当 Some 里面的 T 不是可 Copy 的该怎么办呢?
fn main() {
let some1 = Some("123".to_string());
let some2 = some1.map(|c| c.len());
println!("{:?}", some2); // 3
}
some1 在传递给 self 的时候,内部的 String 发生了移动,在 match 匹配是哪个 Some(x) 的时候又发生了移动。当 map 方法调用完毕后,String 被销毁,总之在调用 map 的那一刻,外界的 some1 变量就无法再使用了。如果希望外界的 some1 不受影响,那么可以拷贝一份,即 some1.clone().map()。但问题是,我们只是想查看字符串的长度,传引用就好了,没必要将字符串拷贝一份,这个时候就可以使用 as_ref 方法(一会儿介绍)。
and_then:和 map 类似,接收一个函数 f,但返回值需要手动使用 Some 包裹。
fn main() {
let some_n = Some(123);
let some_n2 = some_n.map(|c| c * 2);
// 和 map 用法一样,只不过 map 会自动将返回值用 Some 包起来
// 而 and_then 则需要手动这么做
let some_n3 = some_n.and_then(|c| Some(c * 2));
println!("{:?}", some_n); // Some(123)
println!("{:?}", some_n2); // Some(246)
println!("{:?}", some_n3); // Some(246)
}
as_ref:把 Option<T> 或 &Option<T> 转换成 Option<&T>。也就是创建一个新 Option,里面的类型是原来类型的引用,就是从 Option<T> 到 Option<&T>,原来那个 Option<T> 实例保持不变。
fn main() {
let some1 = Some("123".to_string());
// 此时闭包里面的参数 c 就不再是 String 类型,而是 &String
// 因为 some1.as_ref() 返回的是 Option<&String>,所以闭包里面的参数自然也是 &String
let some2 = some1.as_ref().map(|c| c.len());
println!("{:?}", some2); // Some(3)
// some1 不受影响,没有发生移动
println!("{:?}", some1); // Some("123")
}
cloned:通过克隆 Option 里面的内容,把 Option<&T> 转换成 Option<T>。本来 Option 里面的是 T 的引用,通过 cloned 可以创建一个新的 Option,并且里面的类型是 T。注意:这个过程会将 T 深度拷贝一份,否则原来的值就没法用了。
fn main() {
let name = "古明地觉".to_string();
let some = Some(&name);
println!("{:?}", some.map(|c| c.chars().count())); // Some(4)
// 因为是引用,所以外界的 name 不会发生移动
println!("{}", name); // 古明地觉
// 但如果想将引用对应的值拷贝一份呢?可以通过 cloned 方法
let some2 = some.cloned();
println!("{:?}", some2.map(|c| c.chars().count())); // Some(4)
// 此时 some2 不再有效,因为调用 map 是被消耗掉了
// 但 name 有效,因为 some.cloned() 会将 name 深度拷贝一份
}
这里可能有人好奇 clone() 和 cloned() 方法有什么区别?首先 clone 方法是将值本身拷贝一份,比如上面的变量 some 是 Option<&String> 类型,那么调用 clone 方法后,会将 some 本身拷贝一份,得到的还是 Option<&String>。再比如 String 调用 clone 方法,也是将 String 拷贝一份。
即使是实现了 Copy trait 的对象也可以调用 clone 方法,实际上一个类型实现了 Copy,它也可以(必须)实现 Clone。当你对一个 Copy 类型调用 clone() 方法时,这个调用基本上是多余的,因为同样的效果可以通过简单的复制来实现(直接赋值就好)。不过这么做并没有什么坏处,只是可能会给人带来混淆。
所以对于上面的 some2 来说,无论是 let some2 = some.clone() 还是 let some2 = some,都是等价的。因为 &String 是可 Copy 的(通常所有的不可变引用都实现了 Copy trait),那么 Option<&String> 也是可 Copy 的。总之 clone 方法的原理很简单,谁调用了它,那么就将谁深度拷贝一份,当然对于 Copy 类型的值来说,深拷贝和浅拷贝是等价的。
但 cloned() 方法不同,它是 Iterator trait 的一部分。前面介绍迭代器的时候说过,如果迭代器里面保存的是引用,那么遍历得到的也是引用,这是显然的。但如果迭代器调用了 cloned() 方法,那么遍历得到的就不再是引用了,它会将引用指向的值深度拷贝一份,遍历得到的是值。
而对于 Option<&T> 来说,它在调用 cloned 方法时,也会创建一个新的 Option 实例,但里面的值是 T 的深度拷贝。
简而言之,使用 some.clone() 会复制 Option 本身,而 some.cloned() 会复制 Option 内部引用指向的值,当然最终都会创建一个新的 Option 实例。另外只有当内部的值是引用类型时,才可以调用 cloned 方法,如果不是引用,那么直接调用 clone 就好。
is_some:如果 Option 是 Some 值,返回 true,否则返回 false。is_none:如果 Option 是 None 值,返回 true,否则返回 false。
fn main() {
let some = Some(123);
println!("{} {}", some.is_some(), some.is_none()); // true false
let some = None as Option<i32>;
println!("{} {}", some.is_some(), some.is_none()); // false true
}
as_mut:as_ref 是将 Option<T> 或者 &Option<T> 转成 Option<&T>,而 as_mut 是将 Option<T> 或者 &mut Option<T> 转成 Option<&mut T>。
fn main() {
let mut some = Some(123);
let some2 = some.as_mut().map(
|v| {
*v *= 2;
*v
}
);
println!("{:?}", some2); // Some(246)
println!("{:?}", some); // Some(246)
// 但因为 *v *= 2,导致 some 也发生了改变
match some.as_mut() {
Some(v) => *v = *v / 3,
None => ()
}
println!("{:?}", some); // Some(82)
}
take:将 Option 里的值拿出去,在原地留下一个 None 值,相当于把值拿出来用,但是却没有消解原来那个 Option。
fn main() {
let mut some = Some(123);
let some2 = some.take();
println!("{:?}", some); // None
println!("{:?}", some2); // Some(123)
let mut some: Option<i32> = None;
// 如果 some 为 None,那么 some.take() 还是 None
let some2 = some.take();
println!("{:?}", some); // None
println!("{:?}", some2); // None
}
replace:在原地替换新值,同时把原来那个值抛出来。
fn main() {
let mut some = Some(123);
let some2 = some.replace(234);
println!("{:?}", some); // Some(234)
println!("{:?}", some2); // Some(123)
let mut some: Option<u32> = None;
let some2 = some.replace(123);
println!("{:?}", some); // Some(123)
println!("{:?}", some2); // None
}
说完了 Option,再看看 Result。
Result<T, E> 的一些方法
map:在 Result 是 Ok 的情况下,通过 map 中提供的函数或闭包对 Ok 里的值进行操作。在 Result 是 Err 的情况下,原样返回 Err 和它携带的内容。
fn main() {
let result: Result<i32, &str> = Ok(123);
// 因为 result 对应的 E 是 &str 类型,所以返回值对应的 E 也是 &str
println!("{:?}", result.map(|c| (c * 2).to_string())); // Ok("246")
let result: Result<i32, &str> = Err("除零错误");
// 原样返回
println!("{:?}", result.map(|c| (c * 2).to_string())); // Err("除零错误")
}
and_then:和 map 类似,接收一个函数 f,但返回值需要手动使用 Ok 包裹。
fn main() {
let result: Result<i32, &str> = Ok(123);
println!("{:?}", result.map(|c| (c * 2).to_string())); // Ok("246")
println!("{:?}", result.and_then(|c| Ok((c * 2).to_string()))); // Ok("246")
let result: Result<i32, &str> = Err("除零错误");
// 原样返回
println!("{:?}", result.and_then(|c| Ok((c * 2).to_string()))); // Err("除零错误")
}
is_ok:如果 Result 是 Ok 值,返回 true,否则返回 false。is_err:如果 Result 是 Err 值,返回 true,否则返回 false。
fn main() {
let result: Result<i32, &str> = Ok(123);
println!("{} {}", result.is_ok(), result.is_err()); // true false
let result: Result<i32, &str> = Err("除零错误");
println!("{} {}", result.is_ok(), result.is_err()); // false true
}
as_ref:把 Result<T, E> 转换成 Result<&T, &E>,也就是创建一个新 Result,里面的类型是原来类型的引用,原来那个 Result<T, E> 实例保持不变。
fn main() {
let result: Result<i32, &str> = Ok(123);
println!("{:?}", result.as_ref()); // Ok(123)
println!("{}", result.as_ref() == Ok(&123)); // true
let result: Result<i32, &str> = Err("除零错误");
println!("{:?}", result.as_ref()); // Err("除零错误")
println!("{}", result.as_ref() == Err(&"除零错误")); // true
}
as_mut:把 Result<T, E> 转换成 Result<&mut T, &mut E>,也就是创建一个新 Result,里面的类型是原来类型的可变引用,原来那个 Result<T, E> 实例保持不变。
fn main() {
let mut result: Result<i32, &str> = Ok(123);
let _ = result.as_mut().map(|v| *v *= 3);
println!("{:?}", result); // Ok(369)
let mut result: Result<i32, &str> = Err("除零错误");
match result.as_mut() {
Ok(..) => (),
// Err 里面是 &str,因此拿到可变引用之后,类型就是 &mut &str
// 修改 *v,让 v 保存别的字符串切片
Err(v) => *v = "索引越界"
}
println!("{:?}", result); // Err("索引越界")
}
我们看到对 Ok 做处理时,直接用 map 方法即可,当然使用 match 表达式也可以。但处理 Err 的时候,则需要使用 match,因为 map 默认是对 Ok 做处理,如果是 Err 则原样返回。要是希望也能处理 Err,则需要调用 map_err 方法。
fn main() {
let mut result: Result<i32, &str> = Ok(123);
let _ = result.as_mut().map(|v| *v *= 3);
println!("{:?}", result); // Ok(369)
// map_err 负责处理 Err,但因为值是 Ok,所以调用 map_err 会原样返回
let _ = result.as_mut().map_err(|v| *v = "索引越界");
println!("{:?}", result); // Ok(369)
let mut result: Result<i32, &str> = Err("除零错误");
// 因为值是 Err,所以调用 map 会原样返回
let _ = result.as_mut().map(|v| *v *= 3);
println!("{:?}", result); // Err("除零错误")
let _ = result.as_mut().map_err(|v| *v = "索引越界");
println!("{:?}", result); // Err("索引越界")
}
以上就是 Option 和 Result 的一些方法,怎么样,是不是对这两个枚举有更深的印象了呢?
Option<T> 与 Result<T, E> 的相互转换
Option<T> 与 Result<T, E> 之间是可以互相转换的,转换的时候需要注意,Result<T, E> 比 Option<T> 多一个类型参数,所以它带的信息比 Option<T> 多一份,因此核心要点就是要注意信息的添加与抛弃。
先来看看如何从 Option 到 Result:
fn main() {
let s1 = Some("你好");
let s2 = None as Option<String>;
// 如果 Option<T> 是 Some 值,那么调用 ok_or 方法会返回 Ok(T)
// 如果是 None,那么调用 ok_or 会返回 Err,Err 里面的值就是给 ok_or 传递的参数
let r1 = s1.ok_or(123);
let r2 = s2.ok_or(123);
println!("{:?}", r1); // Ok("你好")
println!("{:?}", r2); // Err(123)
// 注意:转化之后,原有的 Option 会被消费,如果它不可 Copy,那么会发生移动
}
然后是从 Result 到 Option:
fn main() {
let r1: Result<&str, &[u8]> = Ok("小云同学");
let r2: Result<i32, &str> = Err("张牙舞爪");
// 如果 Result<T, E> 是 Ok 值,那么返回 Some(T)
// 如果是 Err 值,那么返回 None,Err 里面的值直接丢弃
let s1 = r1.ok();
let s2 = r2.ok();
println!("{:?}", s1); // Some("小云同学")
println!("{:?}", s2); // None
// 如果 Result<T, E> 是 Err 值,那么返回 Some(E)
// 如果是 Ok 值,那么返回 None,Ok 里面的值直接丢弃
let s1 = r1.err();
let s2 = r2.err();
println!("{:?}", s1); // None
println!("{:?}", s2); // Some("张牙舞爪")
// 注意:以上在转化的时候同样会消耗 Result,如果不可 Copy,那么会发生移动
}
说完了 Option 和 Result,再来聊聊迭代器。
迭代器
迭代器我们前面文章中说的很详细了,这里再简单回顾一下。
迭代器其实很简单,就是对一个集合类型进行遍历,比如对 Vec<T>、HashMap<K, V> 等进行遍历。使用迭代器有一些好处,比如:
按需使用,不需要把目标集合一次性全部加载到内存,使用一点加载一点惰性计算,可以用来表达无限区间,比如 range,可以表达 1 到无限这个集合,这种在其它一些语言中很难表达可以安全地访问边界,不需要使用有访问风险的下标操作符
next() 方法
迭代器有一个标准方法,叫作 next(),这个方法返回 Option<Item>,其中 Item 就是组成迭代器的元素。这个方法的字面意思就是迭代出下一个元素,如果这个集合被迭代完成了,那么最后一次执行会返回 None。比如下面的例子,在迭代器上调用 .next() 返回 u32 数字。
fn main() {
let a: Vec<u32> = vec![1, 2, 3, 4, 5];
let mut an_iter = a.into_iter(); // 将 Vec<u32> 转换为迭代器
while let Some(i) = an_iter.next() { // 调用 .next() 方法
print!("{i} "); // 1 2 3 4 5
}
// 迭代完毕后,继续迭代返回 None
println!("\n");
println!("{:?}", an_iter.next()); // None
println!("{:?}", an_iter.next()); // None
println!("{:?}", an_iter.next()); // None
}
对容器调用 into_iter 方法即可创建迭代器,注意:这个过程只会创建迭代器,当然创建迭代器不止这一种方法。
iter()、iter_mut()、into_iter()
Rust 中的迭代器根据所有权三态可以分成三种。
seq.iter():创建一个迭代器,迭代器内部保存的是 seq 的引用,遍历时得到的也是 seq 内部元素的引用;seq.iter_mut():创建一个迭代器,迭代器内部保存的是 seq 的可变引用,遍历时得到的也是 seq 内部元素的可变引用;seq.into_iter():创建一个迭代器,seq 的所有权会转移到迭代器内部,遍历时得到的就是元素本身;
fn main() {
let a = [1, 2, 3, 4, 5];
// 迭代器内部是有状态的,调用 next 时状态会改变,所以要声明为 mut
let mut an_iter = a.iter();
println!("{:?}", an_iter.next() == Some(&1)); // true
let mut a = [1, 2, 3, 4, 5];
let mut an_iter = a.iter_mut();
println!("{:?}", an_iter.next() == Some(&mut 1)); // true
let a = [1, 2, 3, 4, 5];
let mut an_iter = a.into_iter();
println!("{:?}", an_iter.next() == Some(1)); // true
// 如果 a 不是可 Copy 的,那么会夺走所有权,之后 a 就不能再用了
}
再来通过迭代器对比一下 clone 和 cloned 方法:
fn main() {
let a = [1, 2, 3, 4, 5];
// 迭代器内部保存的是引用
let an_iter = a.iter();
// 此时会将迭代器本身拷贝一份,至于新迭代器 an_iter2 的内部保存的仍是调用者 a 的引用
// 因为原来的迭代器内部保存的就是引用,而 clone 方法就是将调用者拷贝一份
let mut an_iter2 = an_iter.clone();
// 因为 an_iter2 内部保存的是原有容器(或者说集合)的引用,那么遍历得到也是元素的引用
println!("{:?}", an_iter2.next() == Some(&1)); // true
// 而 cloned 方法,只有实现了 Iterator trait 的对象才能调用
// 它也是创建一个迭代器,但它会将内部引用指向的值深度拷贝一份
// 原来 an_iter 内部保存的是 a 的引用,那么 cloned 会将 a 深度拷贝一份,然后交给 an_iter3 保存
let mut an_iter3 = an_iter.cloned();
// 因为 an_iter3 内部保存的就是容器本身,所以遍历出的也是容器里的元素(而不是它的引用)
println!("{:?}", an_iter3.next() == Some(1)); // true
// 事实上,cloned 方法的功能也可以通过其它方式实现
// 如果 a 不是可 Copy 的,那么 a.into_iter() 就会将所有权转移到迭代器内部
// 但调用之前通过 a.clone() 深度拷贝一份,这样 a 就不会受到影响了
let mut an_iter3 = a.clone().into_iter();
println!("{:?}", an_iter3.next() == Some(1)); // true
}
整个过程还是很好理解的,不过大部分时候我们都不需要深度拷贝。比如数组里面保存了字符串,如果我们需要计算这些字符串的长度,那么完全没必要深度拷贝一份,直接拿到引用即可,因为计算长度的 len 方法本来接收的就是引用。
fn main() {
let names = vec!["古明地觉".to_string(), "琪露诺".to_string(), "雾雨魔理沙".to_string()];
// names 我们不希望它受到影响,那么不能转移所有权,可以拷贝一份
let lengths = names
.clone()
.into_iter()
.map(|c| c.chars().count())
.collect::<Vec<usize>>();
println!("{:?}", lengths); // [4, 3, 5]
// into_iter 会转移原有变量的所有权,遍历出来也是 String,因为 names 里面存的就是 String
// 所以为了让 names 变量不受到影响,我们选择 clone 一份,但我们计算长度真的需要 String 本身吗?
// 显然不需要,因为不管是 len 方法,还是 chars 方法,接收的是 String 的引用
let lengths = names
.iter()
// .cloned() 这里调用 cloned 之后和上面是等价的,但我们没必要这么做
.map(|c| c.chars().count())
.collect::<Vec<_>>();
println!("{:?}", lengths); // [4, 3, 5]
}
所以还是挺简单的,迭代器属于惰性求值,当调用 collect 要将元素收集起来之后才会真正开始计算。collect 方法的作用是,负责遍历原始容器,然后执行相关操作(比如 map、filter、zip,我们这里只有 map),并将操作完的值收集到一个新的容器里面,至于容器是什么,则由我们指定。比如我们希望转成 Vec,那么就在 collect 后面指定即可,当然也可以通过的类型声明的方式指定在变量后面。
至于 Vec 里面的类型则是由我们的操作决定,比如上面计算的长度是一个 usize,那么我们必须写 Vec<usize>,因为 collect 在遍历时,最终得到的就是 usize。如果指定其它类型则报错,所以我们一般不指定,写上一个下划线即可,Rust 编译器能推断出来。
use std::collections::HashMap;
fn main() {
let names = [(1, "古明地觉".to_string()),
(2, "琪露诺".to_string()),
(3, "雾雨魔理沙".to_string())];
// names 是静态数组,我们转成动态数组
let names2 = names
.iter()
.collect::<Vec<_>>();
println!("{:?}", names2); // [(1, "古明地觉"), (2, "琪露诺"), (3, "雾雨魔理沙")]
// 也可以转成 HashMap,注意:这里必须要深度拷贝一份,HashMap 存储的是具体的值
let names3 = names
.clone()
.into_iter()
.collect::<HashMap<_, _>>();
// HashMap<_, _> 表示将遍历出来的元素转成 HashMap,所以元素需要是二元组
println!("{:?}", names3); // {3: "雾雨魔理沙", 2: "琪露诺", 1: "古明地觉"}
}
比较简单,也是之前说过的内容。
for 语句的真面目
有了迭代器的背景知识后,我们终于要解开 Rust 语言里面 for 语句的真面目了。for 语句是一种语法糖,语句 for item in c {} 会展开成下面这样:
let mut tmp_iter = c.into_iter();
while let Some(item) = tmp_iter.next() {}
也就是说,for 语句默认使用获取元素所有权的迭代器模式,自动调用了 into_iter() 方法。因此 for 语句会消耗集合 c,同时也说明,要将一个类型放在 for 语句里进行迭代,需要这个类型实现了迭代器 into_iter() 方法。
for 语句作为一种基础语法,它会消耗掉原集合。但有时候我们希望不获取原集合元素所有权,比如只是打印一下,这时只需要获取集合元素的引用 ,应该怎么办呢?Rust 中也考虑到了这种需求,提供了配套的辅助语法。
用 for in &c {} 获取元素的不可变引用,相当于调用 c.iter()用 for in &mut c {} 获取元素的可变引用,相当于调用 c.iter_mut()
用这两种形式就不会消耗原集合所有权。
fn main() {
let s1 = String::from("aaa");
let s2 = String::from("bbb");
let s3 = String::from("ccc");
let s4 = String::from("ddd");
let v = vec![s1, s2, s3, s4];
// 这里会夺走的 v 的所有权
for item in v {
print!("{} ", item); // aaa bbb ccc ddd
}
// v 不可以再使用
}
如果不想所有权被夺走,也可以遍历引用:
fn main() {
let s1 = String::from("aaa");
let s2 = String::from("bbb");
let s3 = String::from("ccc");
let s4 = String::from("ddd");
let mut v = vec![s1, s2, s3, s4];
// for item in v 等价于 for item in v.into_iter(),item 是数组元素本身
// for item in &v 等价于 for item in v.iter(),item 是数组元素的不可变引用
// for item in &mut v 等价于 for item in v.iter_mut(),item 是数组元素的可变引用
for item in &v {
print!("{} ", item); // aaa bbb ccc ddd
}
for item in v.iter_mut() {
// item 是内部元素的引用,通过 *item 修改指定的元素
*item += &String::from("...");
// 但是注意:我们不能通过 let x = *item 这种方式进行赋值
// 因为 item 是 &String,但 Rust 默认不会深度拷贝堆数据
// 所以 let x = *item 之后,数组 v 里面 String 的所有权就会转移
// 而我们之所以使用引用,就是为了让所有权不转移,所以此时会出现矛盾
// 于是 Rust 干脆就不让我们这么做了,这和 let x = v[0] 的情况(一会介绍)是相似的
// 以下都是合法的,即便出现了 *item 也没关系,因为我们没有转移所有权
// 换言之只要我们没有明确地将 *item(String)转移给新的变量即可
// 再比如 println!("{}", *item) 也是合法的,因为 println! 接收的是引用
// 所以它等价于 println("{}", &*item),数组里面的 String 依旧没有发生移动
let x = &*item;
let x = &*&*item;
let x = item.clone();
let x = (*item).clone(); // 等价于 item.clone(),因为 clone 接收的本来就是引用
}
println!("\n");
println!("{:?}", v); // ["aaa...", "bbb...", "ccc...", "ddd..."]
}
以上就是 for 循环背后的秘密。
获取集合类型中元素的所有权
我们来看一个简单的例子,一般来说,我们想要获取 Vec 里的一个元素,只需要下标操作就可以了。
fn main() {
let s1 = String::from("aaa");
let s2 = String::from("bbb");
let s3 = String::from("ccc");
let s4 = String::from("ddd");
let v = vec![s1, s2, s3, s4];
let a = v[0]; // 这里,我们想访问 s1 的内容
}
这段代码稀松平常,在 Rust 中却没办法编译通过。原因很简单,String 不可 Copy,所以赋值之后会转移所有权,但这样就导致整个数组都没法用了。所以这个时候 Rust 干脆就提示 String 没有实现 Copy trait,如果元素实现了 Copy 就浅拷贝一下,没有实现也不转移所有权了,而是报错。
fn main() {
let s1 = String::from("aaa");
let s2 = String::from("bbb");
let s3 = String::from("ccc");
let s4 = String::from("ddd");
let v = (s1, s2, s3, s4);
let a = v.0;
println!("{}", a); // aaa
// 此时 v 不可以再访问、v.0 也不可以再访问
}
但如果换成元组或者结构体,那么是允许转移部分元素或字段的所有权,比如这里 v.0 的所有权被转移了,但其它元素则不影响。也就是说,我们不能打印 v.0,或者打印 v,但是 v.1、v.2、v.3 还是可以的。那为啥数组不行呢?主要原因是元组属于异构型容器,每个元素之间是彼此独立的,类型、含义都可以不同。
而数组属于同构型容器,内部元素的类型含义都是相同的,比如我们经常会对数组求和、排序、过滤等等,这些都要求数组的元素必须全部有效。因此 Rust 不允许转移数组内部元素的所有权,如果不是可 Copy 的,那么必须手动 clone 一份,否则就会报错:提示你元素的类型没有实现 Copy。
fn main() {
let s1 = String::from("aaa");
let s2 = String::from("bbb");
let s3 = String::from("ccc");
let s4 = String::from("ddd");
let v = vec![s1, s2, s3, s4];
let a = v[0].clone(); // 手动 clone 一份(深拷贝)
println!("{}", a); // aaa
let a = &v[0]; // 或者获取引用
println!("{}", a); // aaa
}
所以所有权的概念还是需要我们好好理解的。
迭代器的性能
下面我们来讨论一个最关键的话题,那就是迭代器的性能如何,我们创建迭代器之后可能会调用各种各样的算子(比如 map、filter、zip、reduce)等等,那么它的效率如何呢?首先在 Rust 中迭代器是一种很高的抽象,因为我们使用起来非常方便,就像函数式编程一样,数据经过一个算子操作之后,然后流向下一个算子。
根据我们的经验,抽象就意味着以性能为代价,但在 Rust 里面则不一样。Rust 对迭代器做了大量的优化,它的抽象开销是零,因此也叫零开销抽象。
v.iter().map()
.filter()
.zip()
.map()
.enumerate()
.fold()
如果你看一些 Rust 项目,经常能看到类似这种代码,这种代码完全没问题,甚至 Rust 官方也鼓励这种做法,它是不影响性能的。不仅仅因为这些操作都是惰性的,只有在收集元素的时候才会执行,最主要的是 Rust 会进行高度优化,优化后的汇编代码和针对指定情况手写的汇编代码几乎差不多。
所以通过迭代器这种模式,既保持了高抽象,方便我们编程,而且也不影响性能。所以在开发中,可以大胆地使用。
小结
以上我们就简单复习了 Option、Result 和迭代器。
本文来自于:极客时间《Rust 语言从入门到实战》
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号