聊一聊 Rust 的生命周期:值的生命有多长?
本次来聊一聊生命周期,虽然是已经说过的内容,但难免会有遗漏(特别是看了很多大佬的文章之后),所以适当回顾一下做个补充也是有必要的。
在任何语言里,栈上的值都有自己的生命周期,它和所在栈帧的生命周期保持一致。而 Rust,进一步明确这个概念,并且为堆上的内存也引入了生命周期。我们知道,在其它语言中,堆内存的生命周期是不确定的,或者是未定义的。因此要么开发者手动维护(在 C 里面调用 free),要么语言在运行时做额外的检查(Python、Java 的垃圾回收)。但在 Rust 中,除非显式地做 Box::leak() / Box::into_raw() / ManualDrop 等动作,一般来说,堆内存的生命周期,会默认和其栈内存的生命周期绑定在一起。
fn main() {
// 栈上保存了指针、大小和容量,堆上保存了具体数据
let mut names: Vec<String> = Vec::new();
names.push("古明地觉".to_string());
names.push("古明地恋".to_string());
names.push("芙兰朵露".to_string());
println!("{} {}", names.len(), names.capacity()); // 3 4
}
示意图如下:
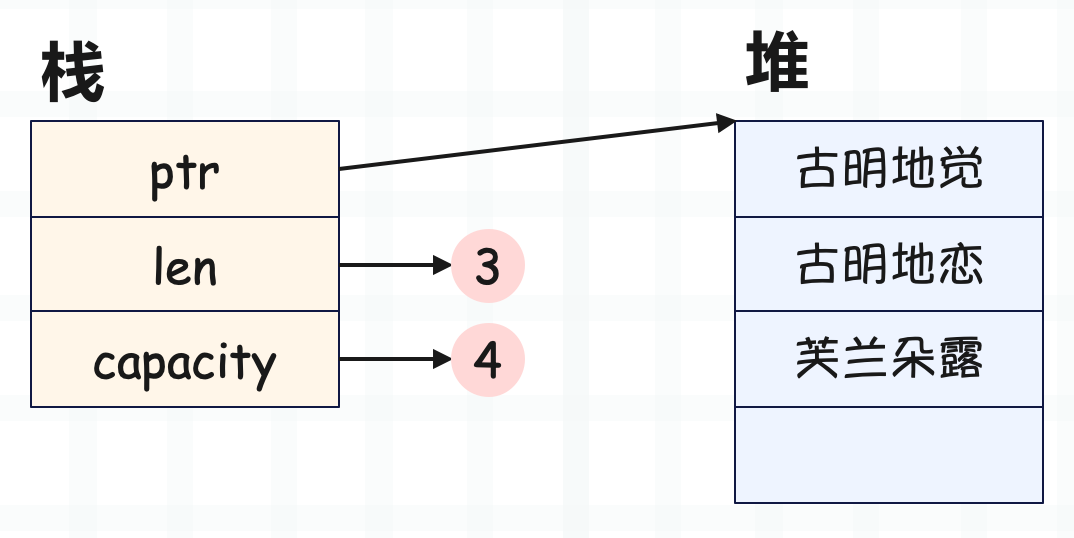
不变的部分位于栈上,动态改变的部分位于堆上,并且堆数据的生命周期会和对应的栈数据绑定在一起。在 C 里面,堆数据和栈数据无关、彼此独立,堆内存需要手动调用 free 才会释放,但容易出现 malloc 之后忘记 free 的情况。而在 Python、Java 等语言中,会使用垃圾回收,比如 Python 会为每个对象都维护额外的引用计数,通过引用计数是否为 0 决定对象是否回收。
但 Rust 没有 GC,而是引入了所有权的概念,每个值都只能拥有一个所有者,只要所有者离开作用域,那么值就会被释放。所以 Python 的引用计数是让一个值可以有多个所有者,并记录所有者的数量,而 Rust 是让每个值只能有一个所有者,这样就不需要额外的维护引用计数了(如果希望多个所有者持有同一个值,那么可以使用 Rc)。
所以对于 Rust 而言,堆内存和创建它的栈内存是紧密绑定的,如果栈内存被销毁,那么内部指针指向的堆内存同样会被释放。所以在这种默认情况下,每个函数的作用域中,编译器就可以对比值和其引用的生命周期,来确保"引用的生命周期不超出值的生命周期"。
那么 Rust 编译器是如何做到这一点的呢?
值的生命周期
在进一步讨论之前,我们先给值可能的生命周期下个定义。如果一个值的生命周期贯穿整个进程的生命周期,那么我们就称这种生命周期为静态生命周期。
当值拥有静态生命周期,其引用也具有静态生命周期。我们在表述这种引用的时候,可以用 'static 来表示,比如 &'static str 代表这是一个具有静态生命周期的字符串引用。一般来说,全局变量、静态变量、字符串字面量(string literal)等,都拥有静态生命周期。我们之前提到的堆内存,如果使用了 Box::leak 后,也具有静态生命周期。
如果一个值是在某个作用域中定义的,也就是说它被创建在栈上或者堆上,那么其生命周期是动态的。
当这个值的作用域结束时,值的生命周期也随之结束。对于动态生命周期,我们约定用 'a 、'b 或者 'hello 这样的小写字符或者字符串来表述。 ' 后面具体是什么名字不重要,它代表某一段动态的生命周期,其中 &'a str 和 &'b str 表示这两个字符串引用的生命周期可能不一致。
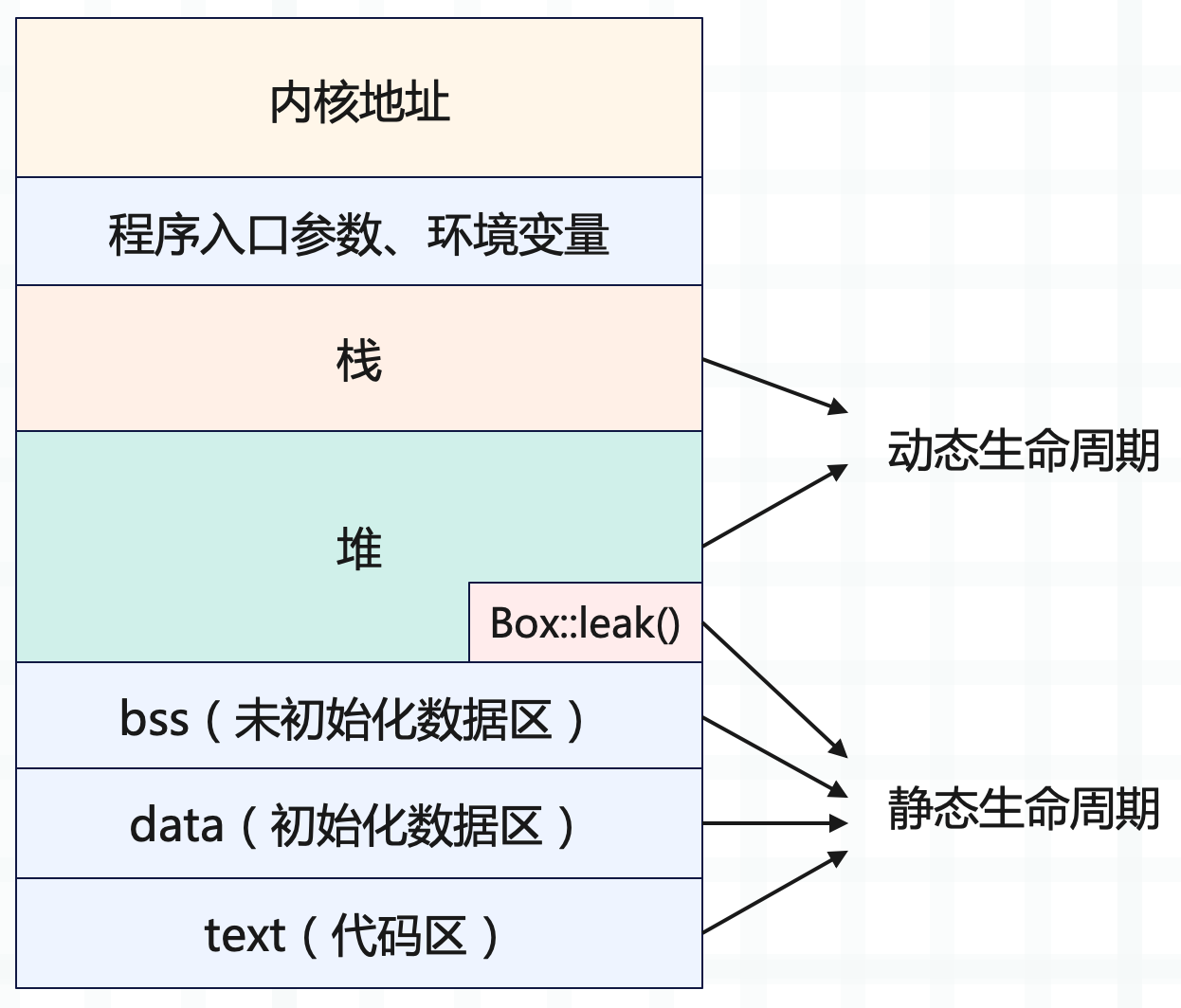
- 分配在堆和栈上的内存有其各自的作用域,它们的生命周期是动态的
- 全局变量、静态变量、字符串字面量、代码等内容,在编译时,会被编译到可执行文件中的 bss/data/text 段,然后在加载时,装入内存。因而它们的生命周期和进程的生命周期一致,所以是静态的。
- 所以,函数指针的生命周期也是静态的,因为函数在 text 段中,只要进程活着,其内存一直存在。
明白了这些基本概念后,我们来看对于值和引用,编译器是如何识别其生命周期的。
编译器如何识别生命周期
我们先从两个最基本最简单的例子开始。

这两个小例子很好理解,我们再看个稍微复杂一些的。
fn get_long_string(s1: &str, s2: &str) -> &str {
if s1.len() > s2.len() {s1} else {s2}
}
fn main() {
let s1 = "abcd".to_string();
let s2 = "abc".to_string();
println!("{}", get_long_string(&s1, &s2));
}
我们定义一个函数,用于比较两个字符串,返回长的那一个。并且为了不夺走原有变量的所有权,参数是 s1、s2 和返回值都是 &str 类型。但当我们执行时,却报错了,告诉我们缺少生命周期。

你是不是很疑惑,站在我们开发者的角度,这个代码理解起来非常直观。在 main() 函数里 s1 和 s2 两个值的生命周期一致,它们的引用传给 get_long_string() 函数之后,无论谁的被返回,生命周期都不会超过 s1 或 s2。所以这应该是一段正确的代码啊?为什么编译器报错了,不允许它编译通过呢?我们把这段代码稍微扩展一下,你就能明白编译器的困惑了。
fn get_long_string(s1: &str, s2: &str) -> &str {
if s1.len() > s2.len() {s1} else {s2}
}
fn main() {
let longer;
let s1 = "abcd".to_string();
{
let s2 = "abcdefg".to_string();
longer = get_long_string(&s1, &s2);
}
}
当出现了多个参数,它们的生命周期可能不一致时,返回值的生命周期就不好确定了。编译器在编译某个函数时,并不知道这个函数将来有谁调用、怎么调用,所以函数本身携带的信息,就是编译器在编译时使用的全部信息。
根据这一点,我们再看示例代码,在编译 get_long_string() 函数时,参数 s1 和 s2 的生命周期是什么关系、返回值和参数的生命周期又有什么关系,编译器是无法确定的。此时,就需要我们在函数签名中提供生命周期的信息,也就是生命周期标注(lifetime specifier)。在生命周期标注时,使用的参数叫生命周期参数(lifetime parameter)。通过生命周期标注,我们告诉编译器这些引用间生命周期的约束。
生命周期参数的描述方式和泛型参数一致,不过只使用小写字母。这里,两个入参 s1、 s2,以及返回值都用 'a 来约束。生命周期参数,描述的是参数和参数之间、参数和返回值之间的关系,并不改变原有的生命周期。
fn get_long_string<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1.len() > s2.len() {s1} else {s2}
}
在我们添加了生命周期参数后,s1 和 s2 的生命周期只要大于等于(outlive) 'a,就符合参数的约束,而返回值的生命周期同理,也需要大于等于 'a 。
只要 Rust 能够基于参数的生命周期推断出返回值的生命周期,那么函数签名就是合法的。上面的函数签名就表示,返回值的生命周期不超过 s1 和 s2 重叠的部分即可。
fn get_long_string<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1.len() > s2.len() {s1} else {s2}
}
fn main() {
let longer;
let s1 = "abcd".to_string();
{
let s2 = "abcdefg".to_string();
longer = get_long_string(&s1, &s2);
}
}
此时编译器会报错,因为它发现了返回值 longer 的生命周期超过了参数 s2 的生命周期,所以这个函数调用是非法的。
fn get_long_string<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1.len() > s2.len() {s1} else {s2}
}
fn main() {
let s1 = "abcd".to_string();
{
let longer;
let s2 = "abcdefg".to_string();
longer = get_long_string(&s1, &s2);
}
}
此时调用就没有问题了,因为返回值的生命周期没有超过 s1 和 s2。所以生命周期标注不会改变原有变量的生命周期,它只是给编译器提供了一个参考信息,告诉编译器这些参数和返回值之间的关系。在调用时,编译器看关系是否满足,不满足则抛出编译错误。
生命周期的省略
到这里你可能会有困惑,为什么之前写的代码,很多函数的参数或者返回值都使用了引用,编译器却没有提示我要额外标注生命周期呢?这是因为编译器希望尽可能减轻开发者的负担,其实所有使用了引用的函数,都需要生命周期的标注,只不过编译器会自动做这件事,省却了开发者的麻烦。
fn f(s: &str) -> &str {
s
}
比如上面这个函数,在早期版本是编译不过的,它需要你这么写:
fn f<'a>(s: &'a str) -> &'a str {
s
}
但是久而久之,Rust 团队发现对于这种场景实在没有必要一遍又一遍地重复编写生命周期,并且这种只有一个参数完全是可以预测的,有明确的模式。于是 Rust 团队就将这些模式写入了借用检查器,可以自动进行推导,而无需显式地写上生命周期标注。
而在 Rust 引用分析中编入的模式被称为生命周期省略规则:
这些规则无需开发者来遵守;对于一些特殊情况,由编译器来考虑;要是你的代码符合这些规则,就无需显式标注生命周期;
如果生命周期在函数 / 方法的参数中,则被称为输入生命周期;在函数 / 方法的返回值中,则被称为输出生命周期。而 Rust 要能够在编译期间基于输入生命周期,来确定输出生命周期,如果能够确定,那么便是合法的。
而当我们省略生命周期时,Rust 就会基于内置的省略规则进行推断,如果推断完成后发现引用之间的关系还是模糊不清,就会出现编译错误。而解决办法就需要我们手动标注生命周期了,表明引用之间的相互关系。
那么 Rust 省略规则到底是怎样的呢?
- 规则一:给所有引用类型的参数添加独立的生命周期,比如 'a 、'b 等;
- 规则二:如果只有一个参数具有生命周期,或者说只有一个输入生命周期,那么该生命周期会赋值给所有的输出生命周期;
- 规则三:如果有多个输入生命周期,但其中一个是 &self 或 &mut self,那么 self 的生命周期会赋值给所有的输出生命周期;
如果 Rust 在应用完这三个规则后,能够推导出返回值的生命周期,那么函数(方法)的签名就是合法的,否则不合法,我们需要手动添加生命周期标注。这些规则同样适用于 fn 定义和 impl 块,我们来举几个例子,感受一下整个过程。
// 函数如下,然后开始应用三个规则
fn first_word(s: &str) -> &str{};
// 1. 每个引用类型的参数都有自己的生命周期,满足
// 所以函数相当于变成如下
fn first_word<'a>(s: &'a str) -> &str{};
// 2. 只有一个输入生命周期,该生命周期被赋给所有的输出生命周期
// 显然也是满足的,所以函数变成如下
fn first_word<'a>(s: &'a str) -> &'a str{};
// 3. 不满足,所以无事发生
但在应用完三个规则之后,计算出了返回值的生命周期,所以合法。再举个例子:
// 函数如下,然后开始应用三个规则
fn first_word(s1: &str, s2: &str) -> &str{};
// 1. 每个引用类型的参数都有自己的生命周期
// 显然满足,所以函数变成如下
fn first_word<'a, 'b>(s1: &'a str, s2: &'b str) -> &str{};
// 2. 只有一个输入生命周期,该生命周期被赋予所有的输出生命周期
// 但是这里有两个,所以不满足
// 3. 不满足
当编译器使用了 3 个规则之后仍然无法计算出返回值的生命周期时,就会出现编译错误,显然上面代码是会报错的。我们需要手动标注生命周期:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {}
从表面上来看 x、y 的生命周期是相同的,都是 'a,但准确来说它表示的是 x、y 生命周期重叠的部分。而返回值的生命周期标注也是 'a,所以此处的含义就表示输出生命周期是(不超过)两个输入生命周期重叠的部分。
小结
以上我们就介绍了静态生命周期和动态生命周期的概念,以及编译器如何识别值和引用的生命周期。
根据所有权规则,值的生命周期可以确认,它可以一直存活到所有者离开作用域;而引用的生命周期不能超过值的生命周期。在同一个作用域下,这是显而易见的。然而当发生函数调用时,编译器需要通过函数的签名来确定,参数和返回值之间生命周期的约束。
大多数情况下,编译器可以通过上下文中的规则,自动添加生命周期的约束。如果无法自动添加,则需要开发者手工来添加约束。一般,我们只需要确定好返回值和哪个参数的生命周期相关就可以了。而对于数据结构,当内部有引用时,我们需要为引用标注生命周期。
本文参考自:极客时间陈天《Rust 编程第一课》
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号