Rust 语法梳理与总结(中)
楔子
我们继续来梳理 Rust 语法,本次让我们把目光聚焦于函数、闭包、泛型和 trait 上面,开始接下来的内容。并且在梳理的时候,同样会对之前没有说的内容做一个补充。
函数
函数(function)使用 fn 关键字来声明,函数的参数需要标注类型,就和变量一样。如果函数返回一个值,返回值的类型必须在箭头 -> 之后指定。
函数的最后一个表达式将作为返回值,当然也可以在函数内使用 return 语句来提前返回一个值。
// 一个返回布尔值的函数,判断 b 能够被 a 整除
fn is_divisible_by(a: u32, b: u32) -> bool {
if b == 0 {
false
} else {
a % b == 0
}
}
fn main() {
println!("{}", is_divisible_by(5, 2));
println!("{}", is_divisible_by(5, 0));
println!("{}", is_divisible_by(6, 3));
/*
false
false
true
*/
}
然后函数参数默认都是不可变的,如果希望它可变,那么在声明的时候也要使用 mut 关键字。
fn is_divisible_by(a: u32, mut b: u32) -> bool {
// 此时 b 就是一个可变参数
// 如果 b 等于 0,那么就将它改成 1
if b == 0 {
b = 1
}
a % b == 0
}
fn main() {
println!("{}", is_divisible_by(5, 2));
println!("{}", is_divisible_by(5, 0));
println!("{}", is_divisible_by(6, 3));
/*
false
true
true
*/
}
既然提到了函数,那么就不得不提方法,方法是依附于某个对象的函数,在 impl 代码块内定义。
#[derive(Debug)]
struct Point {
x: f64,
y: f64,
}
// 实现的代码块
impl Point {
// 这是一个静态方法(static method),静态方法不需要被实例调用
// 这类方法一般用作构造器(constructor)
fn origin() -> Point {
Point { x: 0.0, y: 0.0 }
}
// 另一个静态方法,需要两个参数:
fn new(x: f64, y: f64) -> Point {
Point { x: x, y: y }
}
// 计算两个点之间的曼哈顿距离
fn distance(&self, other: &Point) -> f64 {
(self.x - other.x).abs() + (self.y - other.y).abs()
}
// 修改某个点的坐标
fn modify_x(&mut self, x: f64) {
self.x = x;
}
fn modify_y(&mut self, y: f64) {
self.y = y;
}
}
fn main() {
let mut p1 = Point::new(3.2, 1.4);
let mut p2 = Point::new(4.3, 1.5);
println!("{:?}", p1);
println!("{:?}", p2);
/*
Point { x: 3.2, y: 1.4 }
Point { x: 4.3, y: 1.5 }
*/
println!("{}", p1.distance(&p2));
println!("{}", p2.distance(&p1));
/*
1.1999999999999997
1.1999999999999997
*/
p1.modify_x(10.0);
p2.modify_y(10.0);
println!("{:?}", p1);
println!("{:?}", p2);
/*
Point { x: 10.0, y: 1.4 }
Point { x: 4.3, y: 10.0 }
*/
}
函数和方法本身还是很简单的,我们重点来看一下闭包。
闭包
闭包包含两部分:
- 函数,在 Rust 里面必须是匿名函数;
- 环境,由函数捕获的外层作用域中的变量组成;
我们先来看看普通函数和匿名函数在语法上的区别。
fn main() {
fn add1(a: i32, b: i32) -> i32 {
a + b
}
let add2 = |a: i32, b: i32| -> i32 {
a + b
};
}
使用 fn 关键字定义的是普通函数,而匿名函数没有函数名,并且要把参数所在的小括号换成 | |。然后这里我们将匿名函数赋值给了变量 add2,因此在使用上,add1 和 add2 没有区别,普通函数和匿名函数都是函数。
再来看看闭包,闭包本质上也是一个匿名函数,但它可以捕获外层作用域的变量,而这是 fn 定义的普通函数所做不到的。
fn main() {
let start = 1;
let add = |a: i32, b: i32| -> i32 {
a + b + start
};
println!("{}", add(2, 1)); // 4
}
因为变量 start 是定义在 main 函数里面的,所以闭包 add 捕获了外层作用域(这里是 main 函数的作用域)的变量。而我们说普通函数做不到这一点,来验证一下。
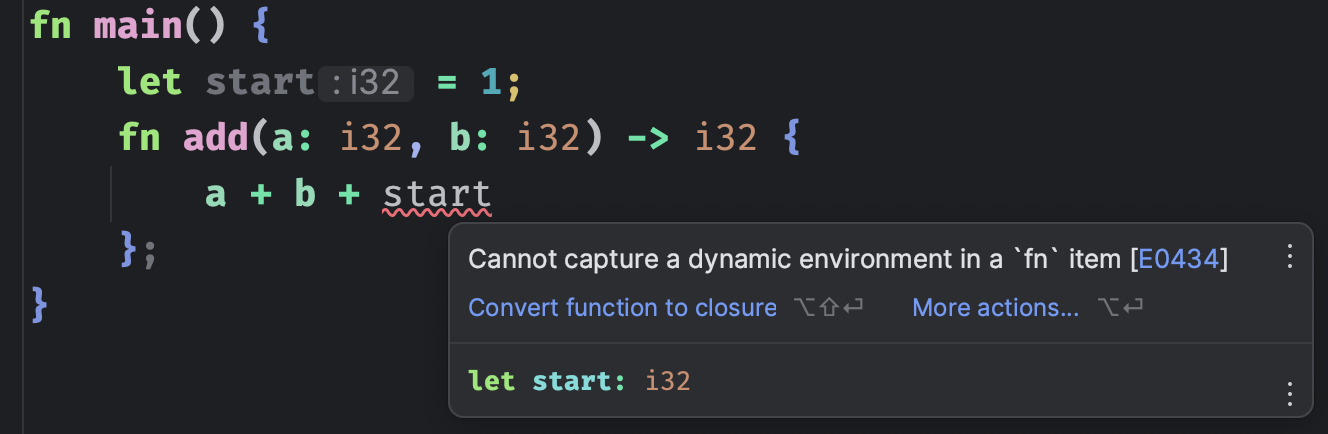
我们都不用执行,IDE 就已经给出提示了。普通函数无法捕获外层作用域的变量,我们应该使用 || {...} 定义的闭包。
捕获变量会产生额外开销。
所以普通函数和匿名函数都是函数,在不涉及外部变量的时候,两者没什么区别。然而要捕获外层作用域的变量,那么必须使用匿名函数,并且此时匿名函数会和外部变量组合起来成为闭包。
然后闭包还可以省略参数的类型,以及返回值类型。
fn main() {
// 不指定参数的类型和返回值类型,Rust 会根据我们后续的使用推断出来
let add = |i, j| {
(i, j)
};
// 这里调用了两次 add,显然 Rust 会进行推断
// 会将参数 i 推断为 f32,将 j 推断为 u16
// 然后返回的是 (i, j),那么返回值类型就是 (f32, u16)
println!("{:?}", add(3.14, 666u16));
println!("{:?}", add(2.71f32, 777));
/*
(3.14, 666)
(2.71, 777)
*/
// 一旦推断出来,那么参数和返回值类型就确定了
// 所以下面的调用是不合法的,因为参数类型错了
// add(12, 13); // 报错,将 12 改成 12.0,那么就没问题了
}
总的来说,Rust 的类型推断还是很智能的,但即便如此,我们也最好明确指定类型。另外,如果代码块只有一行代码的话,那么大括号也可以省略。
fn main() {
let add = |i, j| (i, j);
println!("{:?}", add(3.14, 666u16));
println!("{:?}", add(2.71f32, 777));
/*
(3.14, 666)
(2.71, 777)
*/
}
注意:只有闭包才可以这么干,普通函数是不可以的。不过为了代码的可读性,还是不建议将大括号去掉,另外参数和返回值的类型最好也不要省略。
将闭包作为参数
先来回顾一下函数是怎么作为参数的。
type F = fn(i32, i32) -> i32;
// calc 接收三个参数
// 第一个参数:接收两个 i32 返回一个 i32 的函数
// 第二个参数和第三个参数均是 i32
fn calc(op: F, a: i32, b: i32) -> i32 {
op(a, b)
}
fn main() {
let add = |a: i32, b: i32| -> i32 {
a + b
};
println!("{}", calc(add, 11, 22)); // 33
}
咦,参数 op 接收的是普通函数,而我们传递的 add 是一个闭包,为啥没报错呢?很简单,因为在 Rust 里面闭包本质上就是一个匿名函数,只不过它可以捕获外层作用域的变量罢了。但我们这里没有捕获,因此它和 fn 定义的普通函数是完全等价的,都是函数。如果我们将代码修改一下:
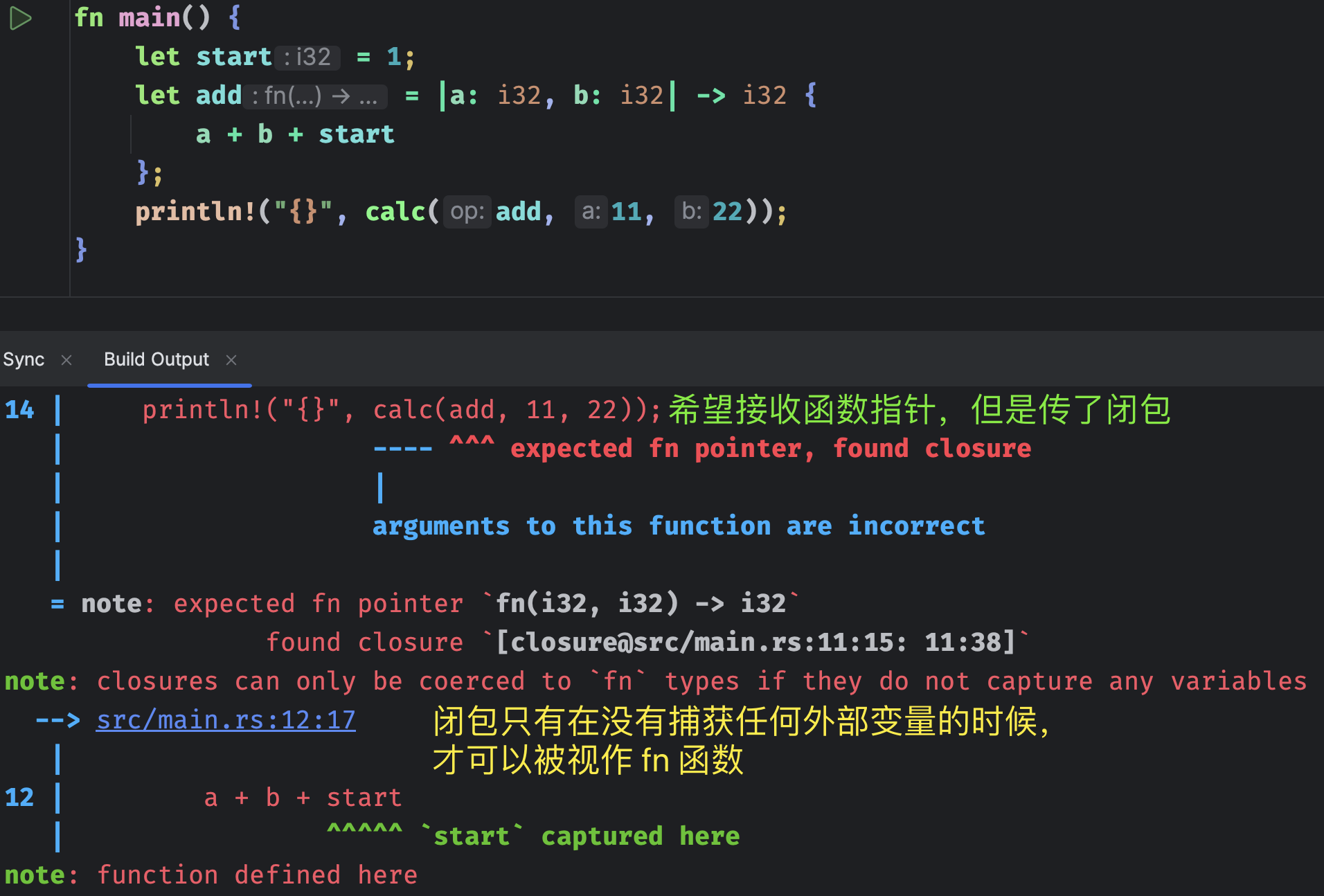
我们看到报错了,提示类型不匹配。由于使用了外部的变量 start,所以闭包 add 就不能作为参数传递了,此时它和 fn 定义的普通函数不是完全等价的,因为后者无法捕获外层作用域的变量。所以我们要修改函数 calc 的第一个参数的类型,将它改成闭包类型,而这需要使用一个叫 Fn 的 trait 来实现(一会儿介绍 trait)。
fn calc<T>(op: T, a: i32, b: i32) -> i32
where
T: Fn(i32, i32) -> i32,
{
op(a, b)
}
// 或者你还可以这么定义:
/*
fn calc(op: impl Fn(i32, i32) -> i32, a: i32, b: i32) -> i32 {
op(a, b)
}
fn calc<T: Fn(i32, i32) -> i32>(op: T, a: i32, b: i32) -> i32 {
op(a, b)
}
*/
fn main() {
let start = 1;
let add = |a: i32, b: i32| -> i32 {
a + b + start
};
println!("{}", calc(add, 11, 22)); // 34
println!("{}", add(11, 22)); // 34
}
以上我们就将闭包作为参数传递了,另外传递一个 fn 关键字定义的普通函数也是可以的。虽然它不是闭包,但它实现了 Fn 这个 trait。
fn calc<T>(op: T, a: i32, b: i32) -> i32
where
T: Fn(i32, i32) -> i32,
{
op(a, b)
}
fn main() {
let add = |a: i32, b: i32| -> i32 {
a + b
};
println!("{}", calc(add, 11, 22)); // 33
fn add(a: i32, b: i32) -> i32 {
a + b
}
println!("{}", calc(add, 11, 22)); // 33
}
在 Rust 里面,闭包(closure)是一个可以捕获外部变量的匿名函数,如果一个匿名函数没有捕获任何外部作用域的变量,技术上它仍然是一个闭包,但它的行为和普通函数是等价的。
闭包作为返回值
再来看看如何将闭包作为返回值,这中间会有一些和其它语言不一样的地方。
fn login(username: String, passwd: String) -> impl Fn() -> String {
move || {
if username.eq(&String::from("satori")) && passwd.eq(&String::from("123456")){
return String::from("欢迎来到编程教室")
} else {
return String::from("用户名密码错误")
}
}
}
fn main() {
let username = String::from("satori");
let passwd = String::from("123456");
let closure = login(username, passwd);
println!("{}", closure());
/*
欢迎来到编程教室
*/
let username = String::from("satori");
let passwd = String::from("654321");
let closure = login(username, passwd);
println!("{}", closure());
/*
用户名密码错误
*/
}
代码非常简单,调用 login 函数之后返回一个闭包,然后调用闭包的时候比较用户名和密码,返回不同的字符串。需要注意的是,字符串的 eq 方法的第一个参数接收的是引用,所以闭包中调用 username.eq 和 passwd.eq 时,拿到的是 username 和 passwd 两个字符串的引用,而不是字符串本身。
但问题是相比之前,这段闭包代码多了一个 move 关键字,这是干啥用的。
我们仔细想一下,当闭包返回之后,login 函数是不是调用结束了,它的相关参数是不是也就销毁了呢。那么后续调用闭包的时候,再使用 username 和 passwd 就会报错,因为引用的对象已经被销毁了。于是 Rust 提供了 move 关键字,会将捕获的外部变量移动到闭包内部,确保闭包在调用的时候能够找得到。如果变量是可 Copy 的,那么移动的时候会拷贝一份;如果不是可 Copy 的,那么移动的时候就转移所有权。
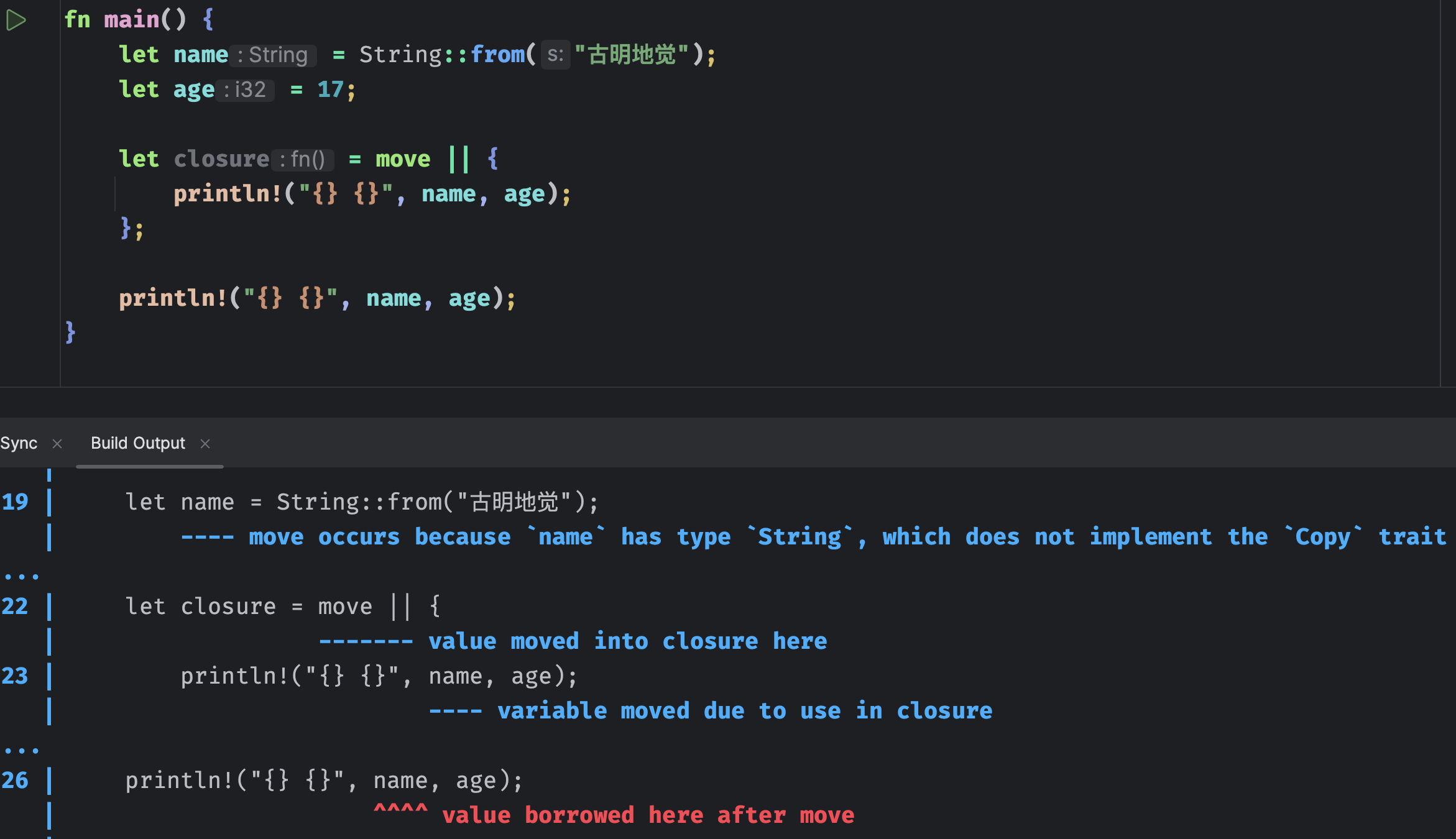
我们看这个例子,定义闭包的时候使用了 move 关键字,那么它会将使用的外部变量,移动到闭包内部。所以在闭包的下面再使用 name 变量就会报错,因为所有权已经被转移了。
至于 age 则没有关系,因为它是可 Copy 的,这种变量的数据都完全分配在栈上,不涉及到堆。而栈上数据在传递的时候只会拷贝一份,所以传递之后你的是你的,我的是我的,两者没有关系,自然也就不会出现所有权的转移,因为数据都是各自独立的。
但对于涉及到堆内存的变量来说就不一样了,由于 Rust 默认不会拷贝堆上数据,那么变量在传递之后就会出现两个栈上指针,指向同一份堆内存。于是 Rust 会转移所有权,只让一个变量拥有操作堆内存的权利。所以 name 在移动之后就不能再用了,因为它已经失去了操作堆内存的权利。
当然啦,对于当前这个例子,即使不使用 move 也是可以的,因为这是在 main 函数里面,闭包的存活时间没有超过它所捕获的变量。但之前那个例子不行,之前那个例子的闭包使用了 login 函数的两个参数,而在参数伴随 login 函数调用结束而销毁之后,闭包却依旧存活,因此报错。
Rust 闭包的实现和所有权的实现,在语义上是统一的。
Fn、FnOnce、FnMut
Rust 一切皆类型,并由 trait 掌握类型的行为逻辑。闭包类型则需要通过 Fn trait 来指定(当然普通函数也实现了 Fn trait),但除了 Fn 之外,还有两个 trait,也就是 FnOnce 和 FnMut。那么它们之间有什么区别呢?
FnOnce
实现此 trait 的闭包在使用外部变量的时候,可以夺走所有权。
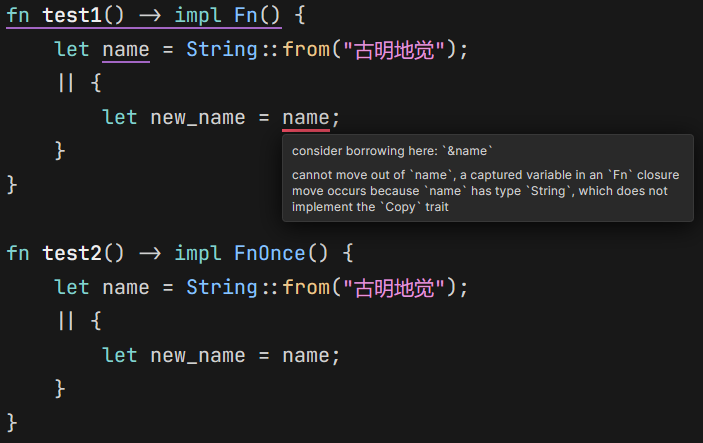
我们看到两个函数的函数体都是一样的,但使用 Fn trait 就有问题,而使用 FnOnce trait 则一切正常。原因就是对于 FnOnce 来说,它可以夺走外部变量的所有权,而 Fn 不能,它需要获取引用。
fn test() -> impl FnOnce() {
let name = String::from("古明地觉");
|| {
let new_name = name;
}
}
fn main() {
// 拿到闭包,test 里变量 name 的所有权会转移给闭包内部的 new_name 变量
let closure = test();
// 调用闭包,结束之后 name 被回收
closure();
// 如果再次调用,那么就会报错
// closure() // 报错,name 已被释放
}
所以这也是它叫 FnOnce 的原因,就是因为它在剥夺外部变量所有权的时候只能调用一次。但如果没有转移所有权,那么需要使用 move 关键字将变量移动到闭包内部,举个例子:
fn test1() -> impl FnOnce() {
let name = String::from("我是闭包");
// 在闭包中将 name 赋值给了 new_name
// 显然所有权会发生转移,这是很合理的
|| {
let new_name = name;
}
}
fn test2() -> impl FnOnce() {
let name = String::from("我是闭包");
// 由于闭包内部用的都是 name 的引用
// 所以这时候不会发生所有权的转移,但很明显这种情况是会出问题的
// 因为后续使用闭包的时候,name 已经被销毁了
// 所以这里要通过 move,手动地将变量转移至闭包内部
move || {
let new_name = &name; // name 的引用
// 这里拿到的也是 name 的引用
println!("{}", name);
}
}
所以实现 FnOnce trait 的闭包,能够转移捕获的外部变量的所有权。而如果不涉及所有权的转移,也就是通过引用的方式使用了外部变量,那么我们需要通过 move 关键字将变量移动到闭包内部,否则后续使用闭包的时候就会出问题。
注意:我们上面捕获的变量是 String 类型,它没有实现 Copy trait,所以一直反复提到所有权。但如果捕获的变量实现了 Copy trait,那么一定要加 move,将变量移动到闭包内部。
Fn
实现此 trait 的闭包在使用外部变量的时候,需要满足一个条件:不可以在闭包内部夺走外部变量的所有权,必须以不可变引用的方式进行操作。
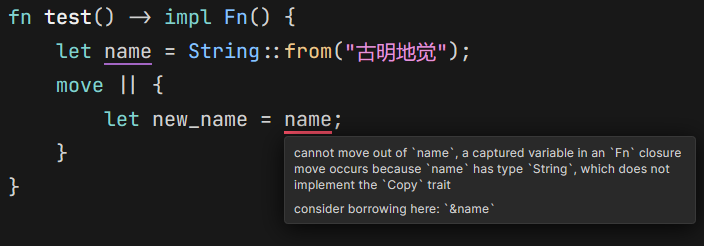
IDE 提示的很明显,我们不能在闭包内部转移外部变量的所有权,即便使用 move 关键字将变量移动到了闭包内部。不过对于实现了 Copy trait 的变量来说是可以的,因为我们说这种变量的数据都完全分配在栈上,传递之后数据都是各自独立的,不存在所有权的转移。
但对于涉及到堆内存的变量来说就不一样了,由于 Rust 默认不会拷贝堆上数据,于是会转移所有权。但对于实现 Fn trait 的闭包,Rust 不允许转移外部变量的所有权,因此只能以引用的方式操作。
fn test() -> impl Fn() {
let name = "satori".to_string();
let age = 17;
let c = move || {
// 虽然在定义闭包的时候,将name移动到了闭包内部
// 但在使用 name 的时候,仍必须以引用的方式
// 否则它的所有权就会转移给 new_name,而 Rust 不允许这种情况出现
let new_name = &name;
// age 是可 Copy 的,不涉及所有权的转移
// 因此使用 age 和 &age 均可
let new_age = age;
};
// age 依然有效,它是可 Copy 的
// 在移动的时候会拷贝一份,所以不影响
println!("{}", age);
// 但 name 就不行了,因为它被移动到了闭包内部
c
}
所以 Fn、FnOnce、FnMut 描述的都是闭包将以何种方式去捕获外部变量。对于当前的 Fn 来说,只能以引用的方式去捕获,而不能夺走所有权,即使我们使用 move 关键字将变量移动到了闭包内部。
FnMut
它和 Fn 一样都只能获取外部变量的引用,但 Fn 在使用的时候只能拿到不可变引用,而 FnMut 还可以获取可变引用。
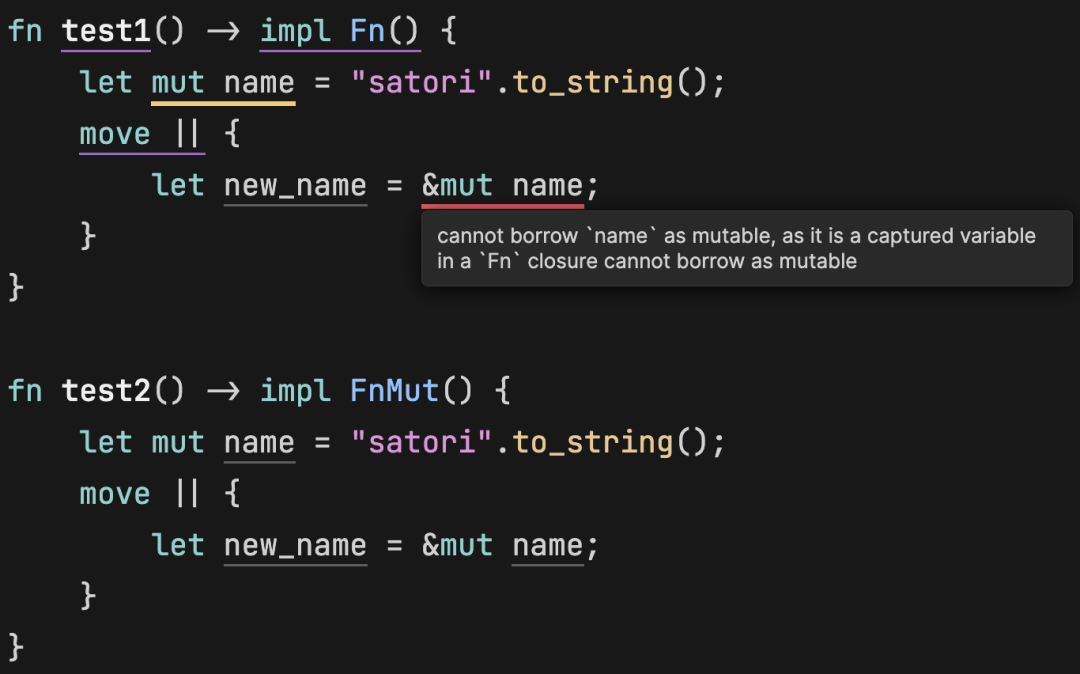
test1 函数是不合法的,实现 Fn trait 的闭包不可以获取外部变量的可变引用。
fn test() -> impl FnMut() -> String {
let mut name = "komeiji".to_string();
move || {
let new_name = &mut name;
new_name.push_str(" satori");
name.clone()
}
}
fn main() {
// 这里闭包也要声明为可变的
let mut c = test();
println!("{}", c());
println!("{}", c());
println!("{}", c());
/*
komeiji satori
komeiji satori satori
komeiji satori satori satori
*/
// name 的所有权自始至终在闭包内部
// 每一次调用都会对其进行修改
}
注意这段代码,里面有几个需要注意的地方。我们在闭包内部创建变量 new_name 的时候,只能将 name 的引用赋值给它,而不能是 name 本身,那样的话所有权就发生转移了。然后要修改字符串,那么 name 必须可变,new_name 也要是可变引用。
最后我们返回了 name.clone(),问题来了,直接返回 name 不行吗?答案是不行,对于 Fn 和 FnMut 来说,Rust 不允许在闭包内部转移外部变量的所有权,纵使这个外部变量被移动到了闭包内部。所以返回 name 是不合法的,因为那样所有权就发生转移了。
再来写一个计数器的例子,我们先看用 Go 如何去写:
package main
import (
"fmt"
)
// ticker 函数返回了一个闭包
// 闭包在调用时会返回一个 uint32
// 而闭包返回的 uint32 来自 ticker 里的 start 变量
func ticker() func() uint32 {
var start uint32 = 0
return func() uint32 {
start++
return start
}
}
func main() {
var tk = ticker()
fmt.Println(tk()) // 1
fmt.Println(tk()) // 2
fmt.Println(tk()) // 3
}
还是很简单的,Go 的变量没啥可变不可变,所以读起来就非常简单,然后是 Rust。
fn ticker() -> impl FnMut() -> u32 {
// 后续要修改 start,start 必须可变
let mut start = 0;
// 闭包也要是可变的。然后还要使用 move 关键字,将 start 移动到闭包内部,这是必须的
// 否则后续使用闭包的时候,会发现 start 已被销毁
move || {
start += 1;
start
}
}
fn main() {
// 想在闭包内修改外部变量,则需要使用 FnMut
// 拿到闭包之后,也要声明为可变的
let mut c = ticker();
println!("{}", c());
println!("{}", c());
println!("{}", c());
/*
1
2
3
*/
}
以上我们就用 Rust 实现了一个定时器。
关于 Fn、FnOnce、FnMut 我们再做一下总结:
如果你需要转移外部变量的所有权,使用 FnOnce,并且闭包只能调用一次;如果你不需要转移所有权,并且也不需要修改外部变量,那么使用 Fn;如果你不需要转移所有权,但是需要修改外部变量,那么使用 FnMut;
另外为避免出现悬空引用,记得使用 move 关键字将变量移动到闭包内部。一般来说,如果你将闭包作为了返回值,那么基本上都会使用 move。
泛型
再来看一看泛型,泛型可以出现在结构体、枚举、函数、方法等结构中,用于增强类型的表达能力,以及减少重复代码。
// 结构体使用泛型
struct Point<T, W> {
x: T,
y: W,
z: i32
}
// 枚举使用泛型
enum Cell<T> {
Foo(T),
Bar(String)
}
// 函数使用泛型
fn func<T>(a: T, b: T) {}
用到了哪些泛型,必须提前用尖括号声明好。
struct T;
// S1 的第一个元素的类型为单元结构体 T
struct S1(T);
// S2 的第一个元素的类型为泛型 T
// 这个 T 可以代表任意类型,至于具体代表哪一种
// 则看在实例化的时候,传递的值是什么
struct S2<T>(T);
我们来实例化测试一下:
struct T;
struct S1(T);
struct S2<T>(T);
fn main() {
let s1 = S1(T{});
// 对单元结构体来说,写成 T 也是可以的
// 这里我们将类型也指定一下
let s1: S1 = S1(T);
// 然后是 S2 的实例化
let s2 = S2(123);
let s2 = S2("hello");
let s2 = S2(String::from("hello"));
// 由于 S2 接收的是泛型 T,所以它可以代表任意类型
// 这里的 T 是单元结构体 T,如果没有定义这个单元结构体,那么这里就会报错
let s2 = S2(T);
// 然后是指定类型,在指定类型的同时,还要指定泛型所代表的类型
let s2: S2<u8> = S2(33);
let s2: S2<&str> = S2("hello");
let s2: S2<Vec<f32>> = S2(vec![3.14, 2.71, 1.414]);
}
因此这便是泛型,它可以代表任意类型,这样极大地增强了数据的表达能力。接下来,我们将带泛型的结构体放到函数参数里面。
struct S<T>(T);
// 因为结构体 S 带了一个泛型 T,所以在指定类型的时候,光有一个 S 是不够的
// 我们还要将泛型指定好,比如 S<u32>,那么就只有当 S 实例的第一个元素为 u32 类型时,
// 才能传给这里的 s 参数
fn f1(s: S<u32>) {
println!("f1 被调用")
}
// 针对的是 S(f64)
fn f2(s: S<f64>) {
println!("f2 被调用")
}
fn main() {
f1(S(123)); // f1 被调用
f2(S(3.14)); // f2 被调用
}
然后函数自身也是可以有泛型的。
struct S<T>(T);
// 泛型只是一个符号而已,它可以代表任意类型
// 但具体是哪一种,则取决于我们传递的值
// 另外这里为了区分,刻意写成了 W,但写成 T 仍是可以的
fn f<W>(s: S<W>) {
println!("函数被调用")
}
fn main() {
f(S(123));
f(S(3.14));
f(S("hello"));
/*
函数被调用
函数被调用
函数被调用
*/
}
函数 f 带了一个泛型 W,而参数 s 的类型是 S<W>。这就说明在调用函数的时候,只要传一个结构体 S 的实例即可,而不必管元素是什么类型,因为泛型可以代表任意类型。
以上在确定泛型的时候,都是根据值推断出来的,我们也可以显式地告诉 Rust。
fn test<T>(s: T) {
println!("函数被调用")
}
fn main() {
// 调用时 T 会代表 i32
test(123);
// 调用时 T 会代表 u8
test(123u8);
test::<u8>(123);
}
通过 test::<u8> 则可以告诉编译器,在调用的时候,泛型 T 代表的是 u8 类型。当然啦,此时传递的也必须是一个合法的 u8 类型的值。
泛型不影响性能,Rust 在编译期间会将泛型 T 替换成具体的类型,这个过程叫做单态化。
方法中的泛型
再来看看方法中的泛型。
struct Point<T, U> {
x: T,
y: U
}
// 针对 i32、f64 实现的方法
// 只有传递的 T、U 对应 i32、f64 才可以调用
impl Point<i32, f64> {
fn m1(&self) {
println!("我是 m1 方法")
}
}
fn main() {
let p1 = Point{x: 123, y: 3.14};
p1.m1(); // 我是 m1 方法
let p2 = Point{x: 3.14, y: 123};
// p2.m1();
// 调用失败,因为 T 和 U 不是 i32、f64,而是 f64、i32
// 所以 p2 无法调用 m1 方法
}
可能有人好奇了,声明方法的时候不考虑泛型可不可以,也就是 impl Point {}。答案是不可以,如果结构体中有泛型,那么声明方法的时候必须指定。但这就产生了一个问题,那就是只有指定类型的结构体才能调用方法。比如上述代码,只有当 x 和 y 分别为 i32、f64 时,才可以调用方法,如果我希望所有的结构体实例都可以调用呢?
struct Point<T, U> {
x: T,
y: U
}
// 针对 K、f64 实现的方法,由于 K 是一个泛型,所以它可以代表任何类型(泛型只是一个符号)
// 因此不管 T 最终是什么类型,i32 也好、&str 也罢,K 都可以接收,只要 U 是 f64 即可
// 然后注意:如果声明方法时结构体后面指定了泛型,那么必须将使用的泛型在 impl 后面声明
impl <K> Point<K, f64> {
fn m1(&self) {
println!("我是 m1 方法")
}
}
// 此时 K 和 S 都是泛型,那么此时对结构体就没有要求了
// 因为不管 T 和 W 代表什么,K 和 S 都能表示,因为它们都是泛型
impl <K, S> Point<K, S> {
fn m2(&self) {
println!("我是 m2 方法")
}
}
// 这里我们没有使用泛型,所以也就无需在 impl 后面声明
// 但很明显,此时结构体实例如果想调用 m3 方法,那么必须满足 T 是 u8,W 是 f64
impl Point<u8, f64> {
fn m3(&self) {
println!("我是 m3 方法")
}
}
fn main() {
// 显然 p1 可以同时调用 m1 和 m2 方法,但 m3 不行
// 因为 m3 要求 T 是一个 u8,而当前是 &str
let p1 = Point{x: "hello", y: 3.14};
p1.m1(); // 我是 m1 方法
p1.m2(); // 我是 m2 方法
// 显然 p2 可以同时调用 m1、m2、m3
// 另外这里的 x 可以直接写成 123,无需在结尾加上 u8
// 因为 Rust 看到我们调用了 m3 方法,会自动推断为 u8
let p2 = Point{x: 123u8, y: 3.14};
p2.m1(); // 我是 m1 方法
p2.m2(); // 我是 m2 方法
p2.m3(); // 我是 m3 方法
// 显然 p3 只能调用 m2 方法,因为 m2 对 T 和 W 没有要求
// 但是像 m3 就不能调用,因为它是为 <u8, f64> 实现的方法
// 只有当 T、W 为 u8、f64 时才可以调用,显然此时是不满足的,因为都是 &str
// 至于 m1 方法也是同理,所以 p3 只能调用 m2,这个方法是为 <K, S> 实现的
// 而 K 和 S 也是泛型,可以代表任意类型,因此没问题
let p3 = Point{x: "3.14", y: "123"};
p3.m2(); // 我是 m2 方法
}
然后注意:我们上面的泛型本质上针对的还是结构体,而我们定义方法的时候也可以指定泛型,其语法和在函数中定义泛型是一样的。
#[derive(Debug)]
struct Point<T, U> {
x: T,
y: U,
}
// 使用 impl 时 Point 后面的泛型名称可以任意
// 比如我们之前起名为 K 和 S,但这样容易乱,因为字母太多了
// 所以建议:使用 impl 时的泛型和定义结构体时的泛型保持一致即可
impl<T, U> Point<T, U> {
// 方法类似于函数,它是一个独立的个体,可以有自己独立的泛型
// 然后返回值,因为 Point 里面是泛型,可以代表任意类型
// 那么自然也可以是其它的泛型
fn m1<V, W>(self, a: V, b: W) -> Point<U, W> {
// 所以返回值的成员 x 的类型是 U,那么它应该来自于 self.y
// 成员 y 的类型是 W,它来自于参数 b
Point { x: self.y, y: b }
}
}
fn main() {
// T 是 i32,U 是 f64
let p1 = Point { x: 123, y: 3.14 };
// V 是 &str,W 是 (i32, i32, i32)
println!("{:?}", p1.m1("xx", (1, 2, 3)))
// Point { x: 3.14, y: (1, 2, 3) }
}
以上就是 Rust 的泛型,当然在工作中我们不会声明的这么复杂,这里只是为了更好地掌握泛型的语法。
然后注意一下方法里面的 self,不是说方法的第一个参数应该是引用吗?理论上是这样的,但此处不行,而且如果写成 &self 是会报错的,会告诉我们没有实现 Copy 这个 trait。
之所以会有这个现象,是因为我们在返回值当中将 self.y 赋值给了成员 x。那么问题来了,如果方法的第一个参数是引用,就意味着结构体在调用完方法之后还能继续用,那么结构体内部所有成员的值都必须有效,否则结构体就没法用了。这和动态数组相似,如果动态数组是有效的,那么内部的所有元素必须都是有效的,否则就可能访问非法的内存。
因此在构建返回值、将 self.y 赋值给成员 x 的时候,就必须将 self.y 拷贝一份,并且还要满足拷贝完之后数据是各自独立的,互不影响。如果 self.y 的数据全部在栈上(可 Copy 的),那么这是没问题的;如果涉及到堆,那么只能转移 self.y 的所有权,因为 Rust 默认不会拷贝堆数据,但如果转移所有权,那么方法调用完之后结构体就不能用了,这与我们将第一个参数声明为引用的目的相矛盾。
所以 Rust 要求 self.y 必须是可 Copy 的,也就是数据必须都在栈上,这样才能满足在不拷贝堆数据的前提下,让 self.y 赋值之后依旧保持有效。但问题是 self.y 的类型是 U,而 U 代表啥类型 Rust 又不知道,所以 Rust 认为 U 不是可 Copy 的,或者说没有实现 Copy 这个 trait,于是报错。
因此第一个参数必须声明为 self,此时泛型是否实现 Copy 就不重要了,没实现的话会直接转移所有权。因为该结构体实例在调用完方法之后会被销毁,不再被使用(或者说所有权已经转移给 self 了),那么此时内部成员的所有权也是可以转移的。
使用泛型和使用具体类型的速度是一样的,因此这就要求 Rust 在编译的时候能够推断出泛型的具体类型,所以类型要明确。
枚举中的泛型
枚举也是支持泛型的,比如之前使用的 Option<T> 就是一种泛型,它的结构如下:
enum Option<T> {
Some(T),
None
}
里面的 T 可以代表任意类型,然后我们再来自定义一个枚举。
// 签名中的泛型参数必须都要使用
// 比如函数签名的泛型,要全部体现在参数中
// 枚举和结构体签名的泛型,要全部体现在成员中
enum MyOption<A, B, C> {
// 这里 A、B、C 都是我们随便定义的,可以代指任意类型
// 具体是哪种类型,则看我们传递了什么
Some1(A),
Some2(B),
Some3(C),
}
fn main() {
// 泛型不影响效率,是因为 Rust 要进行单态化,所以泛型究竟代表哪一种类型要提前确定好
// 这里必须要显式指定 x 的类型。枚举和结构体不同,结构体每个成员都要赋值,所以 Rust 能够基于赋的值推断出所有的泛型
// 但枚举的话,每次只会用到里面的一个成员,如果还有其它泛型,那么 Rust 就无法推断了
// 比如这里只能推断出泛型 C 代表的类型,而 A 和 B 就无法推断了
// 因此每个泛型代表什么类型,需要我们手动指定好
let x: MyOption<i32, f64, u8> = MyOption::Some3(123);
match x {
MyOption::Some1(v) => println!("我是 i32"),
MyOption::Some2(v) => println!("我是 f64"),
MyOption::Some3(v) => println!("我是 u8"),
}
// 泛型可以代表任意类型,指定啥都是可以的
let y: MyOption<u8, i32, String> =
MyOption::Some3(String::from("xxx"));
match y {
MyOption::Some1(v) => println!("我是 u8"),
MyOption::Some2(v) => println!("我是 i32"),
MyOption::Some3(v) => println!("我是 String"),
}
/*
我是 u8
我是 String
*/
}
如果觉得上面的例子不好理解的话,那么再举个简单的例子:
enum MyOption<T> {
MySome1(T),
MySome2(i32),
MySome3(T),
MyNone
}
fn main() {
// 这里我们没有指定 x 的类型,这是因为 MyOption 只有一个泛型
// 通过给 MySome1 传递的值,可以推断出 T 的类型
let x = MyOption::MySome1(123);
// 同样的道理,Rust 可以自动推断,得出 T 是 &str
let x = MyOption::MySome3("123");
// 但此处就无法自动推断了,因为赋值的是 MySome2 成员
// 此时 Rust 获取不到任何有关 T 的信息,无法执行推断
// 因此我们需要手动指定类型,但仔细观察一下声明
// 首先,如果没有泛型的话,那么直接 let x: MyOption = ... 即可
// 但里面有泛型,所以此时除了类型之外,还要连同泛型一起指定,也就是 MyOption<f64>
let x: MyOption<f64> = MyOption::MySome2(123);
// 当然泛型可以代表任意类型,此时的 T 则是一个 Vec<i32> 类型
let x: MyOption<Vec<i32>> = MyOption::MySome2(123);
}
所以一定要注意:在声明变量的时候,如果 Rust 不能根据我们赋的值推断出泛型代表的类型,那么我们必须要手动声明类型,来告诉 Rust 泛型的相关信息,这样才可以执行单态化。
trait
Rust 一切皆类型,并由 trait 掌握类型的行为逻辑,我们看个例子。
#[derive(Debug)]
struct Point<T> {
x: T,
}
impl<T> Point<T> {
fn m(&self) {
let var = self.x;
}
}
fn main() {
let p = Point { x: 123 };
}
你觉得这段代码有问题吗?不用想,肯定是有问题的。因为方法 m 的第一个参数是引用,这就意味着方法调用完毕之后,结构体实例依旧保持有效,也意味着实例的所有成员值都保持有效。但在方法 m 里面,我们将成员 x 的值赋给了变量 var。如果成员 x 的类型不是可 Copy 的,也就是数据不全在栈上,还涉及到堆,那么就会转移所有权,因为 Rust 默认不会拷贝堆数据。所以调用完方法 m 之后,成员 x 的值不再有效,进而使得结构体不再有效。
所以 Rust 为了避免这一点,在赋值的时候强制要求 self.x 的类型必须是可 Copy 的,但泛型 T 可以代表任意类型,它不满足这一特性。或者说 T 最终代表的类型是不是可 Copy 的,Rust 是不知道的,所以 Rust 干脆认为它不是可 Copy 的。
那么问题来了,虽然 T 可以代表任意类型,但如果我们赋的值决定了 T 代表的类型一定是可 Copy 的,那么可不可以告诉 Rust,让编译器按照可 Copy 的类型来处理呢?答案是可以的,而实现这一功能的机制就叫做 trait。
给泛型施加约束
trait 类似于 Go 里面的接口,相当于告诉编译器,某种类型具有哪些可以与其它类型共享的功能。
#[derive(Debug)]
struct Point<T> {
x: T,
}
// 这里便给泛型 T 施加了一个 Copy 的约束
// 此时的 T 代表的是实现了 Copy trait 的任意类型
impl<T: Copy> Point<T> {
fn m(&self) {
let var = self.x;
}
}
// 上面代码还有另一种写法
/*
impl<T> Point<T>
where T: Copy
{
}
*/
fn main() {
let p = Point { x: 123 };
}
此时这段代码就没问题了,因为 T 是可 Copy 的。并且当调用 p.m 的时候,编译器会检查成员 x 的值是不是可 Copy 的,如果不是,则不允许调用 p.m 方法。
以上是在定义方法时,在 impl 块里面指定了 trait,但结构体里面的泛型也是可以指定 trait 的。
use std::fmt::Display;
use std::fmt::Debug;
// 成员 x 的类型要实现 Display
// 成员 y 的类型要实现 Debug
struct Point<T: Display, W: Debug> {
x: T,
y: W
}
// 写成下面这种形式也可以
/*
struct Point<T, W>
where T: Display, W: Debug
{
x: T,
y: W
}
*/
fn main() {
// Display 要求变量能够以 "{}" 的方式打印
// Debug 要求变量能够以 "{:?}" 的方式打印
let s1 = Point{x: 123, y: 345};
let s2 = Point{x: 123, y: (1, 2, 3)};
// 下面的 s3 不合法,因为元组没有实现 Display
// let s3 = Point{x: (1, 2, 3), y: 123};
}
所以这就是 trait,它描述了类型的行为。如果我们希望某个类型的变量不受限制,但必须满足某个特性,那么便可以给泛型施加一些制约。比如定义一个函数,接收两个相同类型的变量,变量具体是什么类型不重要,只要能够比较大小即可。
fn compare<T>(a: T, b: T) -> String
where T: PartialOrd
{
if a > b {
String::from("大于")
} else if a < b {
String::from("小于")
} else {
String::from("等于")
}
}
fn main() {
println!("{}", compare(1, 2));
println!("{}", compare(3.14, 2.71));
println!("{}", compare("a", "b"));
println!("{}", compare("你好", "你好"));
/*
小于
大于
小于
等于
*/
}
如果 compare 里面的 T 不使用 trait,那么它可以代表任意类型,显然会报错,因为不是所有类型的变量都能够比较。于是便可以使用 trait 给 T 施加一些约束,PartialOrd 表示 T 代表的类型必须能够比较。如果在调用 compare 时,传递的值不能比较,那么编译器就能够检查出来,从而报错。
自定义 trait
标准库内置了很多 trait,但我们也可以自定义 trait。
#[derive(Debug)]
struct Girl {
name: String,
age: i32
}
// trait 类似 Go 里面的接口,然后里面可以定义一系列的方法
// 这里我们创建了一个名为 Summary 的 trait,并在内部定义了一个 summary 方法
trait Summary {
// trait 里面的方法只需要写声明即可
fn summary(&self) -> String;
}
// Go 里面只要实现了接口里的所有方法,便实现了该接口
// 但是在 Rust 里面必须显式地指明实现了哪一个 trait
// impl Summary for Girl 表示为类型 Girl 实现 Summary 这个 trait
impl Summary for Girl {
fn summary(&self) -> String {
// format! 宏用于拼接字符串,它的语法和 println! 一样
// 并且这两个宏都不会获取参数的所有权
// 比如这里的 self.name,format! 拿到的只是引用
format!("name: {}, age: {}", self.name, self.age)
}
}
fn main() {
let g = Girl{name: String::from("satori"), age: 16};
println!("{}", g.summary()); // name: satori, age: 16
}
所以 trait 里面的方法只需要写上声明即可,实现交给具体的结构体来做。当然啦,trait 里面的方法也是可以有默认实现的。
#[derive(Debug)]
struct Girl {
name: String,
age: i32
}
trait Summary {
// 我们给方法指定了具体实现
fn summary(&self) -> String {
String::from("hello")
}
}
impl Summary for Girl {
// 如果要为类型实现 trait,那么要实现 trait 里面所有的方法,这一点和 Go 的接口是相似的
// 但 Go 里面实现接口是隐式的,只要你实现了某个接口所有的方法,那么默认就实现了该接口
// 而在 Rust 里面,必须要显式地指定实现了哪个 trait,同时还要实现该 trait 里的所有方法
// 但 Rust 的 trait 有一点特殊,Go 接口里面的方法只能是定义
// 而 trait 里面除了定义之外,也可以有具体的实现
// 如果 trait 内部已经实现了,那么这里就可以不用实现
// 不实现的话则用 trait 的默认实现,实现了则调用我们实现的
// 因此这里不需要定义任何的方法,它依旧实现了 Summary 这个 trait
// 只是我们仍然要通过 impl Summary for Girl 显式地告诉 Rust
// 如果只写 impl Girl,那么 Rust 则不认为我们实现了该 trait
}
fn main() {
let g = Girl{name: String::from("satori"), age: 16};
// 虽然没有 summary 方法,但因为实现了 Summary 这个 trait
// 而 trait 内部有 summary 的具体实现,所以不会报错
// 但如果 trait 里面的方法只有声明没有实现,那么就必须要我们手动实现了
println!("{}", g.summary()); // hello
}
总结一下就是 trait 里面可以有很多的方法,这个方法可以只有声明,也可以同时包含实现。如果要为类型实现某个 trait,那么要通过 impl some_trait for some_struct 进行指定,并且实现该 trait 内部定义的所有方法。但如果 trait 的某个方法已经包含了具体实现,那么我们也可以不实现,会使用 trait 的默认实现。
trait 作为参数
假设有一个函数,只要是实现了 info 方法,都可以作为参数传递进去,这时候应该怎么做呢?
struct Girl {
name: String,
age: i32,
}
struct Boy {
name: String,
age: i32,
salary: u32,
}
trait People {
fn info(&self) -> String;
}
// 为 Girl 和 Boy 实现 People 这个 trait
impl People for Girl {
fn info(&self) -> String {
format!("{} {}", self.name, self.age)
}
}
impl People for Boy {
fn info(&self) -> String {
format!("{} {} {}", self.name, self.age, self.salary)
}
}
// 定义一个函数,注意参数 p 的类型
// 如果是 p: xxx,则表示参数 p 的类型为 xxx
// 如果是 p: impl xxx,则表示参数 p 的类型任意,只要实现了 xxx 这个 trait 即可
fn get_info(p: impl People) -> String {
p.info()
}
fn main() {
let g = Girl {
name: String::from("satori"),
age: 16,
};
let b = Boy {
name: String::from("可怜的我"),
age: 26,
salary: 3000,
};
// 只要实现了 People 这个 trait
// 那么实例都可以作为参数传递给 get_info
println!("{}", get_info(g)); // satori 16
println!("{}", get_info(b)); // 可怜的我 26 3000
}
然后以 trait 作为参数的时候,还有另外一种写法,我们之前一直在用:
// 如果是 <T> 的话,那么 T 表示泛型,可以代表任意类型
// 但这里是 <T: People>,那么就不能表示任意类型了
// 它表示的应该是实现了 People 这个 trait 的任意类型
fn get_info<T: People>(p: T) -> String {
p.info()
}
// 或者使用 where 子句
fn get_info<T>(p: T) -> String where T: People{
p.info()
}
以上几种写法是等价的,但是后两种写法在参数比较多的时候,会更优雅。
fn get_info(p1: impl People, p2: impl People) -> String {
}
fn get_info<T: People>(p1: T, p2: T) -> String {
}
fn get_info<T>(p1: T, p2: T) -> String
where T: People
{
}
当然啦,一个类型并不仅仅可以实现一个 trait,而是可以实现任意多个 trait。
struct Girl {
name: String,
age: i32,
gender: String
}
trait People {
fn info(&self) -> String;
}
trait Female {
fn info(&self) -> String;
}
// 不同的 trait 内部可以有相同的方法
impl People for Girl {
fn info(&self) -> String {
format!("{} {}", &self.name, self.age)
}
}
impl Female for Girl {
fn info(&self) -> String {
format!("{} {} {}", &self.name, self.age, self.gender)
}
}
// 这里在 impl People 前面加上了一个 &
// 表示调用的时候传递的是引用
fn get_info1(p: &impl People) {
println!("{}", p.info())
}
fn get_info2<T: Female>(f: &T) {
println!("{}", f.info())
}
fn main() {
let g = Girl {
name: String::from("satori"),
age: 16,
gender: String::from("female")
};
get_info1(&g); // satori 16
get_info2(&g); // satori 16 female
}
不同 trait 内部的方法可以相同也可以不同,而 Girl 同时实现了 People 和 Female 两个 trait,所以它可以传递给 get_info1,也可以传递给 get_info2。然后为 trait 实现了哪个方法,就调用哪个方法,所以两者的打印结果不一样。
那么问题来了,如果我在定义函数的时候,要求某个参数同时实现以上两个 trait,该怎么做呢?
// 我们只需要使用 + 即可
// 表示参数 p 的类型必须同时实现 People 和 Female 两个 trait
fn get_info1(p: impl People + Female) {
// 但由于 Poeple 和 Female 里面都有 info 方法
// 此时就不能使用 p.info() 了,这样 Rust 不知道该使用哪一个
// 应该采用下面这种做法,此时需要手动将引用传过去
People::info(&p);
Female::info(&p);
}
// 如果想接收引用的话,那么需要这么声明
// 因为优先级的原因,需要将 impl People + Female 整体括起来
fn get_info2(p: &(impl People + Female)) {}
// 或者使用泛型的写法
fn get_info3<T: People + Female>(p: T) {}
当然还可以使用 where 子句。
// 显然这种声明方式要更加优雅,如果没有 where 的话,那么这个 T 就是可以代表任意类型的泛型
// 但这里出现了 where,因此 T 就表示实现了 People 和 Female 两个 trait 的任意类型
fn get_info<T>(p: T)
where
T: People + Female
{
}
如果要声明多个实现 trait 的泛型,那么使用逗号分隔。
fn get_info<T, W>(p1: T, p2: W)
where
T: People + Female,
W: People + Female
{
}
可以看出,Rust 的语法表达能力还是挺丰富的。
trait 作为返回值
trait 也是可以作为返回值的。
struct Girl {
name: String,
age: i32,
gender: String,
}
trait People {
fn info(&self) -> String;
}
impl People for Girl {
fn info(&self) -> String {
format!("{} {}", &self.name, self.age)
}
}
fn init() -> impl People {
Girl {
name: String::from("satori"),
age: 16,
gender: String::from("female"),
}
}
fn main() {
let g = init();
println!("{}", g.info()); // satori 16
}
注意代码中的变量 g,它具体是什么类型 Rust 其实是不知道的。init 返回的不是一个具体的类型,因为一个 trait 可以有很多种类型实现,返回任意一个都是可以的。这个时候我们应该显式地指定变量 g 的类型,即 let g: Girl = init()。
最后 trait 也是可以带泛型的。
struct Number(i32);
trait SomeTrait<T: PartialOrd> {
fn compare(&self, n: T) -> bool;
}
// 为 Number 实现 T 为 i32 的 SomeTrait
impl SomeTrait<i32> for Number {
fn compare(&self, n: i32) -> bool {
self.0 >= n
}
}
fn main() {
let num = Number(66);
println!("{:?}", num.compare(67)); // false
println!("{:?}", num.compare(65)); // true
}
以上就是 trait 相关的内容,如果一个 trait 里面没有定义任何方法,那么相当于不起任何约束作用,也就是空约束。
小结
本篇文章我们复习了函数、闭包、泛型和 trait,内容还是蛮多的,建议私底下也可以多动手敲一敲。
总而言之,Rust 的学习门槛确实不是一般的高,但努力总有收获。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号