详解监控告警系统 Prometheus 与可视化工具 Grafana
楔子
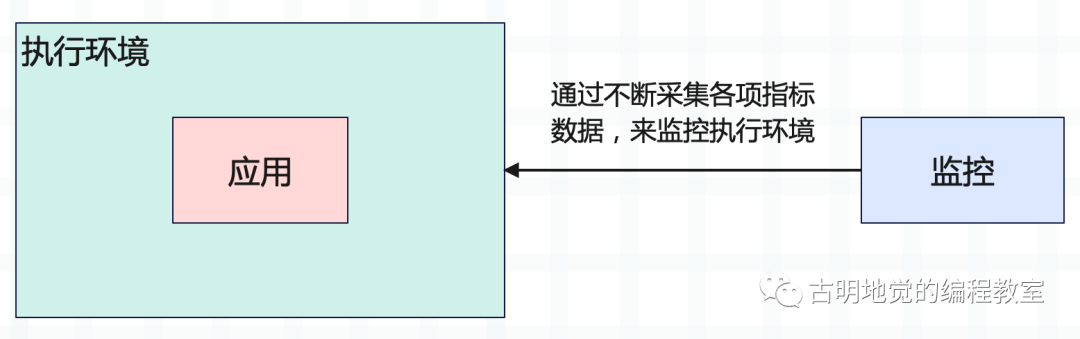
不管是做 Web 开发,还是做大数据开发,不管是离线项目,还是实时项目,最终都要把我们的应用提交到服务器上面,然后运行。但在应用运行的过程中,谁也不能保证百分百不出问题,所以监控就变得非常重要了。要时刻关注运行环境的各项指标是否正常,如果出现问题能够及时告警,然后相关人员在第一时间进行修复。
而要完成上述的这些功能,我们就需要依赖外部的专业监控工具,目前业界比较主流的监控工具有 Zabbix, Prometheus,都可以完成监控功能,也就是不断采集服务器的各项指标数据,比如 CPU、内存、磁盘、网络的使用情况等等。
本篇文章就来介绍 Prometheus。
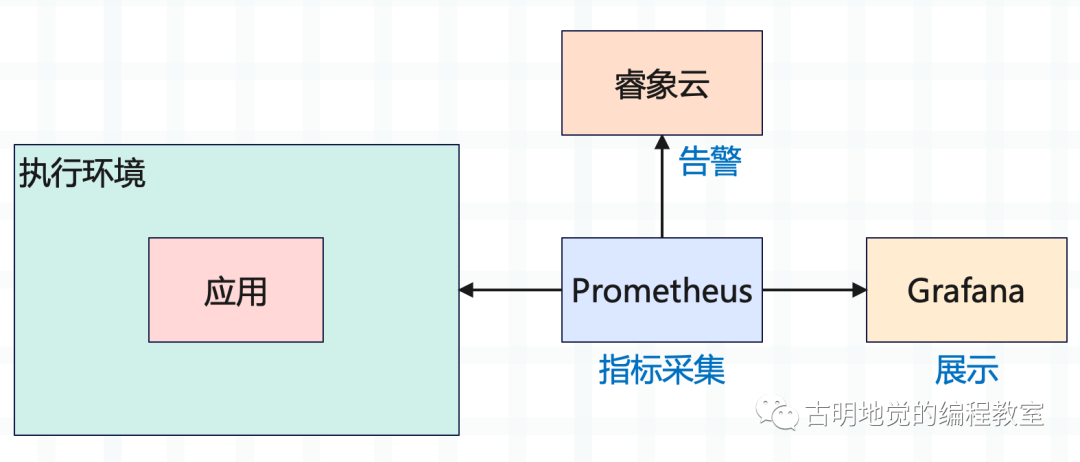
另外 Prometheus 虽然能够完成监控功能,也就是不断采集各项指标数据,但这些密密麻麻的数据,直接观察是不现实的,所以还需要以可视化的方式展示在页面上,而 Grafana 就是做这件事情的。并且当指标出现异常,还要能够及时报警,而报警我们选择睿象云。
其实 Prometheus 内部已经继承了展示和报警的功能,但是相对来说要弱一些,所以这两部分我们由其它的工具的实现,只让 Prometheus 完成监控功能即可。
那么下面我们就来详细介绍一下这几部分。
Prometheus 介绍
正如从 Google 的 Brog 系统演变而来的 Kubernetes 一样,Prometheus 的设计灵感来自于 Google 的 Brogmon 监控系统。从 2012 年开始由前 Google 工程师在 Soundcloud 以开源软件的形式进行研发,并于 2015 年初对外发布早期版本。
作为新一代的云原生监控系统,目前已经有超过 650+ 位贡献者参与到 Prometheus 的研发工作上,并且超过 120+ 项的第三方集成。
Prometheus 是一个开源的完整监控解决方案,它对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。相比于传统监控系统,Prometheus 具有以下优点:
1)易于管理
Prometheus 核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(像数据库, 缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus 基于 Pull 模型 的架构方式,可以在任何地方搭建我们的监控系统。并且对于一些复杂的情况,还可以使用 Prometheus 的服务发现(Service Discovery)能力来动态地管理监控目标。
2)监控服务内部的运行状态
Pometheus 鼓励用户监控服务的内部状态,基于 Prometheus 丰富的 Client 库,用户可以轻松的在应用程序中添加对 Prometheus 的支持,从而让用户可以获取服务和应用内部真正的运行状态。也就是说,Prometheus 不仅可以监控应用外部的执行环境,还可以监控应用内部的执行状态。
3)强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库(TSDB)当中。并且所有的样本除了基本的指标名称以外,还包含一组用于描述样本特征的标签,如下所示:
http_request_status{code='200',
content_path='/api/path1',
environment='produment'
} => [value1@timestamp1, value2@timestamp2, ...]
http_request_status{code='200',
content_path='/api/path2',
environment='produment'
} => [value1@timestamp1, value2@timestamp2, ...]
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)作为唯一标识。每条时间序列,按照时间的先后顺序存储一系列的样本值。
http_request_status:指标名称(Metric Name);{code='200', content_path=.......}:表示维度的标签,基于这些 Label 我们可以方便地对监控数据进行聚合,过滤,裁剪;[value1@timestamp1, value2@timestamp2...]:按照时间的先后顺存储的样本值;
数据格式应该很好理解,如果还有疑惑的话也没关系,我们一会儿单独解释。
4)强大的查询语言 PromQL
Prometheus 内置了一个强大的数据查询语言 PromQL,通过 PromQL 可以实现监控数据的查询、聚合,同时 PromQL 也被应用于数据可视化(如 Grafana)以及告警当中。
通过 PromQL 可以轻松回答类似于以下的问题:
在过去一段时间中 95%应用延迟时间的分布范围?预测在 4 小时后,磁盘空间占用大致会是什么情况?CPU 占用率前 5 位的服务有哪些?
5)高效
对于监控系统而言,大量的监控任务必然导致大量的数据产生。而 Prometheus 可以高效地处理这些数据,对于单一的 Prometheus Server 实例而言,它可以处理数以百万的监控指标,以及每秒处理十万的数据点。
6)可扩展
可以在每个数据中心、每个团队运行独立的 Prometheus Sevrer。Prometheus 对于联邦集群的支持,可以让多个 Prometheus 实例产生一个逻辑集群,当单实例 Prometheus Server 处理的任务量过大时,通过使用功能分区(sharding)+ 联邦集群(federation)可以对其进行扩展。
7)易于集成
使用 Prometheus 可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成,目前支持:Java, JMX, Python, Go, Ruby, .Net, Node.js 等语言的客户端 SDK。基于这些 SDK 可以快速让应用程序纳入到 Prometheus 的监控当中,或者开发自己的监控数据收集程序。
同时这些客户端收集的监控数据,不仅仅支持 Prometheus,还能支持 Graphite 这些其它的监控工具。并且 Prometheus 还支持与其它的监控系统进行集成,比如:
Graphite Statsd Collected Scollector muini Nagios
Prometheus 社区也提供了大量第三方实现的监控数据采集支持,比如:
JMX CloudWatch EC2 MySQL PostgresSQL
Haskell Bash SNMP Consul Haproxy Mesos
Bind CouchDB Django Memcached RabbitMQ
Redis RethinkDB Rsyslog
8)可视化
Prometheus Server 中自带的 Prometheus UI,可以方便地对数据进行查询,并且支持直接以图形化的形式展示数据。同时 Prometheus 还提供了一个独立的基于 Ruby On Rails 的 Dashboard 解决方案 Promdash。
最新的 Grafana 可视化工具也已经提供了完整的 Prometheus 支持,基于 Grafana 可以创建更加精美的监控图表,因此我们几乎不用 Prometheus UI。另外,基于 Prometheus 提供的 API 还可以实现自己的监控可视化 UI。
9)开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持,因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制,对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于 Prometheus 来说,使用 Prometheus 的 client library 的输出格式不仅支持 Prometheus 的格式化数据,也可以输出支持其它监控系统的格式化数据,比如 Graphite。因此你甚至可以在不使用 Prometheus 的情况下,只用 Prometheus 的 client library 就能让你的应用程序支持监控数据采集。
Prometheus 架构
下面来看一下 Prometheus 的基本架构。
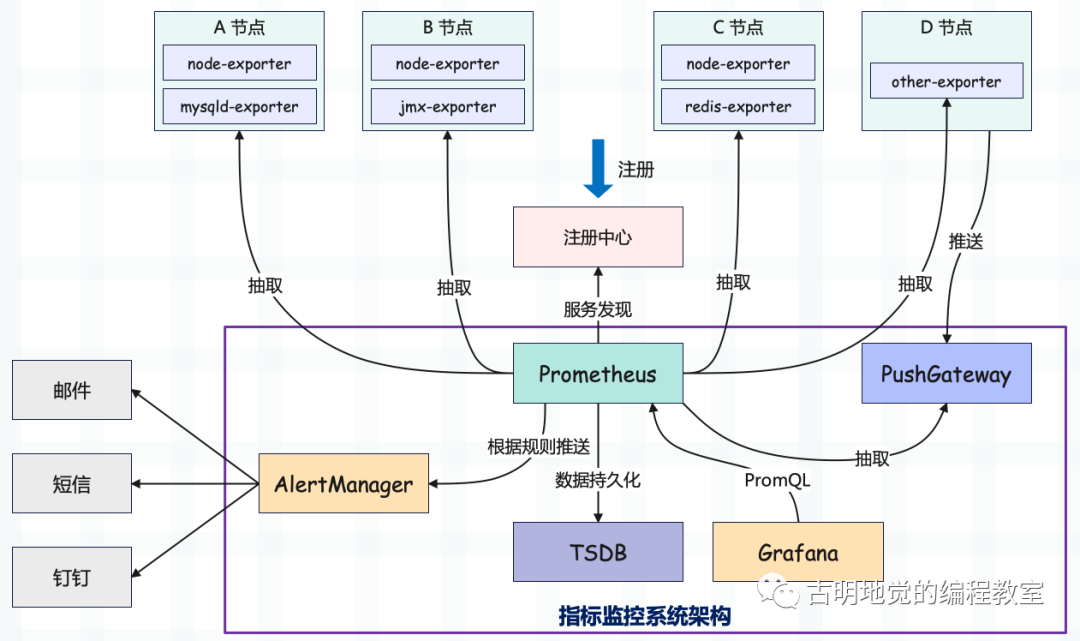
图中的内容比较多,我们一点一点解释。
首先图中有 4 个节点,分别运行不同的服务,我们需要采集相应的指标进行监控,从而时刻了解机器的负载情况以及服务的运行情况。而为了实现这一点,我们需要在各个节点上安装相应的 exporter,exporter 会不断地收集节点以及应用的各项监控指标数据,然后存储在本地。
不同的 exporter 有着不同的职能,比如 node-exporter 会收集操作系统的运行状态数据,像 CPU、内存、磁盘等等;mysqld-exporter 负责收集 MySQL 服务的运行状态数据,redis-exporter 负责收集 Redis 服务的状态数据;当然还有很多其它种类的 exporter,这里就用 other-exporter 代替了。
exporter 将数据采集之后,是存储在节点本地的,而 Prometheus 还要拿到这些数据。所以 Prometheus 要知道这些 exporter 所在节点的 IP 和端口,与之建立连接,定期地抽取 exporter 采集到的指标数据,然后存储在 TSDB 中。
TSDB 的意思是时序数据库,存储的数据是以时间为索引的。显然 TSDB 在这里非常适合,因为指标数据时时刻刻都是与时间相关的。
但有些指标数据比较特殊,没法用官方提供的 exporter 进行收集,所以 Prometheus 无法直接拿到这些数据。于是,我们可以将使用其它途径收集到的数据,统一推送给 PushGateway(可以看成一种特殊的 exporter),Prometheus 也会定期地从 PushGateway 中抽取数据。
因此对于那些无法用官方提供的 exporter 收集的数据,我们也可以通过编码的方式进行采集,然后将数据发给 PushGateway,最终被 Prometheus 获取。
另外在图中我们还看到了注册中心,因为节点是可以水平扩展的,因此 exporter 在启动之后最好将节点信息注册到 Nacos/Eureka/Consul 等注册中心当中,Prometheus 启动之后会从注册中心拉取相应的节点信息。当然没有注册中心也可以,只不过节点就需要写死了。
然后是数据的展示,Prometheus 自带了一个 webUI,但是功能非常简陋。如果我们希望有一个功能丰富且好用的图表面板的话,那么 Grafana 就派上用场了。Grafana 可以配置 Prometheus 作为它的数据源,两者通过 PromQL 进行交互。Grafana 发送 PromQL,Prometheus 在收到之后进行解析,然后从 TSDB 里面查询数据并返回给 Grafana,Grafana 在拿到返回的数据之后再以图表的形式展现出来。
最后是 AlertManager,它就比较简单了,就是告警组件,可以将告警信息推送到邮箱、短信、钉钉当中。
Prometheus 安装
Prometheus 基于 Golang 编写,编译后的软件包,不依赖于任何的第三方依赖。只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动 Prometheus Server。
下载地址:https://prometheus.io/download/ ,我们打开该链接看一下,发现里面有 Prometheus, alertmanager, pushgateway 以及各种各样的 exporter。
首先 Prometheus 我们是必须要下载的,它是服务的核心;然后是 exporter,你想收集什么样的指标数据,就下载相应的 exporter;但如果某些指标数据,没有对应的 exporter,那就要自己手动收集了,然后推送到 pushgateway。
所以这里我们就先下载三个组件:Prometheus, PushGateway, node-exporter,下载完毕之后上传至服务器,我这里是 CentOS。
然后解压 Prometheus 压缩包到 /opt 目录:
可以看到里面的目录结构非常简单,通过可执行文件 prometheus 即可启动服务,然后唯一的一个 .yml 文件则是配置文件。我们来看一下配置文件,由于内容比较少,这里直接贴出来。
# 全局配置
global:
# 每隔多长时间拉取一次,不设置则默认一分钟
scrape_interval: 15s
# 当告警配置更新后,每隔多长时间检测一次
evaluation_interval: 15s
# 告警配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# - "first_rules.yml"
# - "second_rules.yml"
# Prometheus 相关配置,我们需要关注的
scrape_configs:
# job 名称
- job_name: "prometheus"
# Prometheus 监听的 IP 和端口
# 默认是 localhost:9090
static_configs:
- targets: ["0.0.0.0:9090"]
# 然后 Prometheus 还要拿数据,从哪里拿呢?
# 所以还要配置 PushGateway 和 node-exporter 监听的 IP 和端口
- job_name: "pushgateway"
# PushGateway 监听的 IP 和端口
# 端口默认是 9091
static_configs:
- targets: ["82.157.146.194:9091"]
- job_name: "node exporter"
# node-exporter 监听的 IP 和端口
# 端口默认是 9100
static_configs:
- targets: ["82.157.146.194:9100"]
配置还是比较简单的,然后保存一下。接下来安装 PushGateway 和 node-exporter,为了方便,这里都安装在同一个节点,但我们知道 Prometheus 同时监听数万节点都不是问题。
安装 PushGateway
解压 PushGateway 压缩包到 /opt 目录:
可以看到它连配置文件都没有,只有一个编译之后的二进制文件,而它默认的监听端口是 9091。
安装 node-exporter
解压 node-exporter 压缩包到 /opt 目录:
同样只有一个二进制文件,默认监听端口是 9100。
接下来我们启动服务,先启动 node-exporter。注意:exporter 和 Prometheus 服务之间可以是独立的,只要 exporter 启动,那么监控便开始了。在当前目录下执行 ./node_exporter,即可前台启动,然后在浏览器中输入 ip:9100/metrics 即可查看指标数据。

可以看到帮我们把信息全部拿出来了,并且信息非常多。这些信息都存储在 node-exporter 监听的节点本地,接下来就要启动 Prometheus,定期地从 exporter 抽取采集到的数据,并保存在相应的 TSDB 中。
不过在此之前,先将 node-exporter 从前台改成后台启动,直接 nohup ./node_exporter & 即可。
启动 PushGateway 和 Prometheus
启动 PushGateway,先进入所在目录,然后执行:
nohup ./pushgateway &
启动 Prometheus,先进入所在目录,然后执行:
nohup ./prometheus --config.file=prometheus.yml &
然后打开 ip:9090,即可查看 Prometheus 提供的 webUI。
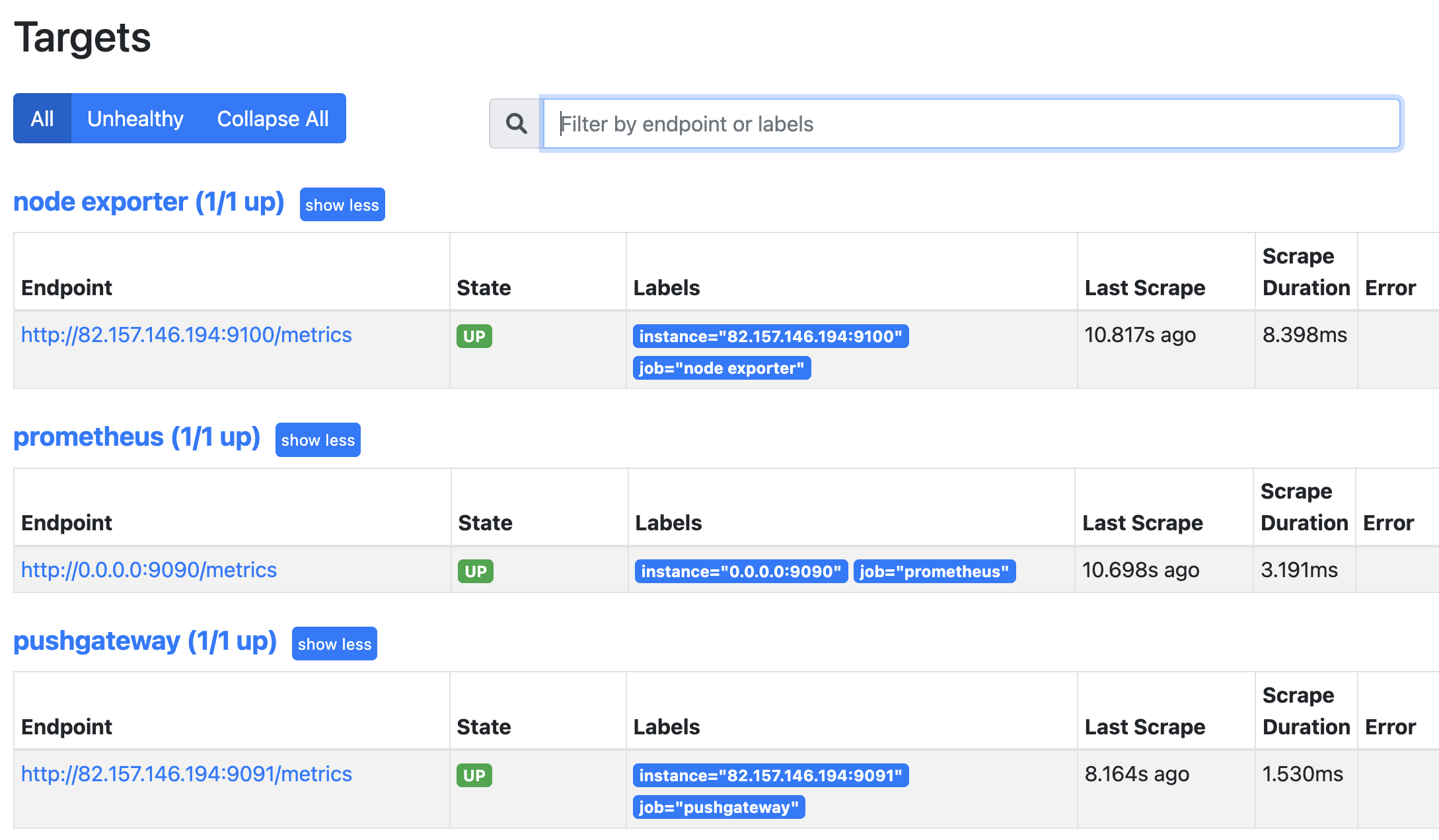
点击 Status 再点击 Targets,即可查看监控的节点。
PromQL
Prometheus 通过指标名称(metrics name)以及对应的一组标签(label)来唯一定义一条时间序列。指标名称反映了监控样本的基本标识,而 label 则在这个基本特征上为采集到的数据提供了多种特征维度。用户可以基于这些特征维度进行过滤、聚合、统计,从而产生新的计算后的一条时间序列。
PromQL 是 Prometheus 内置的数据查询语言,提供对时间序列数据丰富的查询、聚合以及逻辑运算能力的支持,并且被广泛应用在 Prometheus 的日常应用当中,包括对数据的查询、可视化、告警处理等等。
光说的话可能不是很好理解,我们打开 Prometheus 界面,点击左上角的 Prometheus。
在此处即可输入 PromQL 进行查询,然后我们说一条时间序列由 指标名称 和 标签 来唯一确定,那么指标名称都有哪些呢?
在 PromQL 输入框的最右侧有一个 Execute 按钮,输入 PromQL 之后点击即可执行,然后 Execute 按钮的旁边有一个小图标,点击它即可查看 Prometheus 提供的所有指标。里面的指标非常非常多,我们没有必要一个个去记,遇到了去查就行了。然后里面有一个记录 Prometheus 请求数量的指标,我们找到它并点击,会自动填充到 PromQL 输入框中,然后再点击 Execute 按钮执行查询。
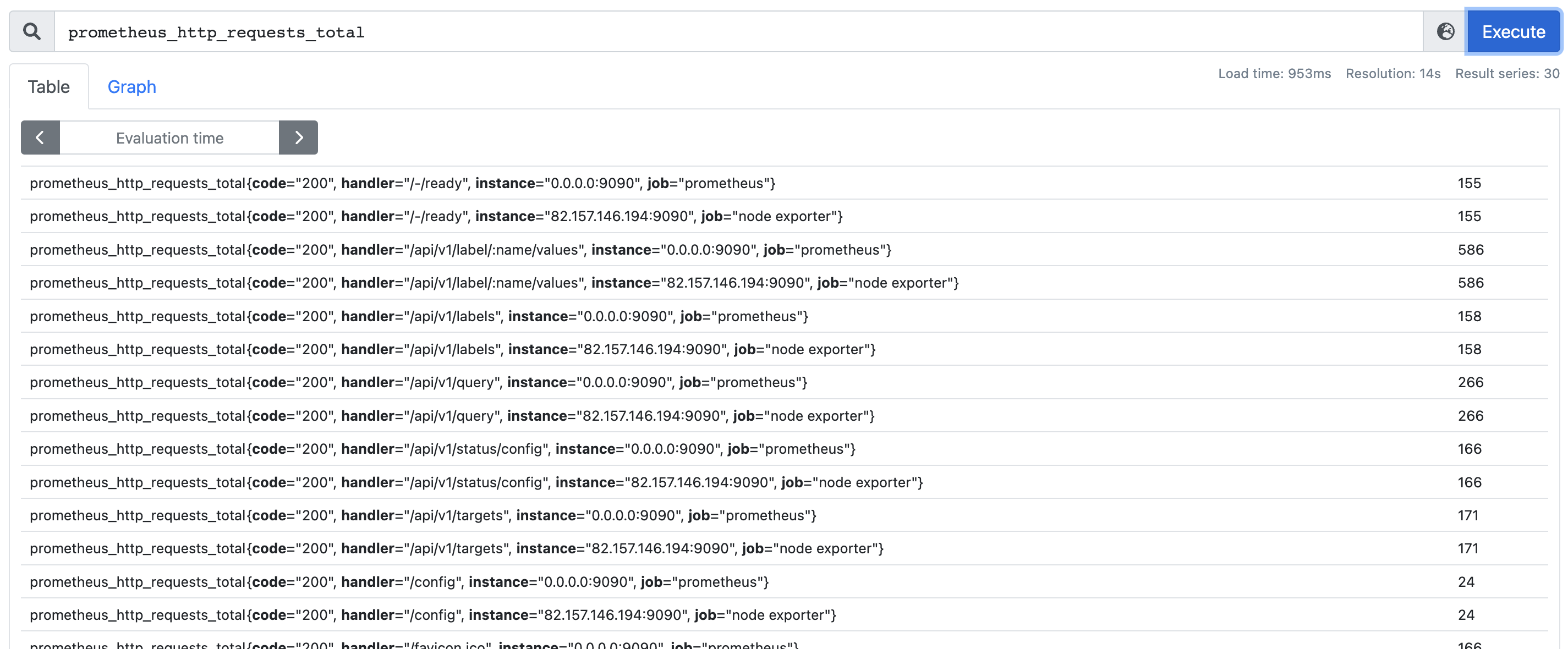
prometheus_http_requests_total 便是指标名称,反映了监控样本的基本标识,当然除了它还有很多其它指标。而 {} 里面的内容则是标签,为采集到的数据提供了多种特征维度,指标名称和标签整体确定一条唯一的时间序列。
如果只输入指标名称,那么会将该指标下的所有时间序列都筛选出来,于是我们还可以基于标签进行过滤。
查询时间序列
PromQL 支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正则匹配。
1)完全匹配
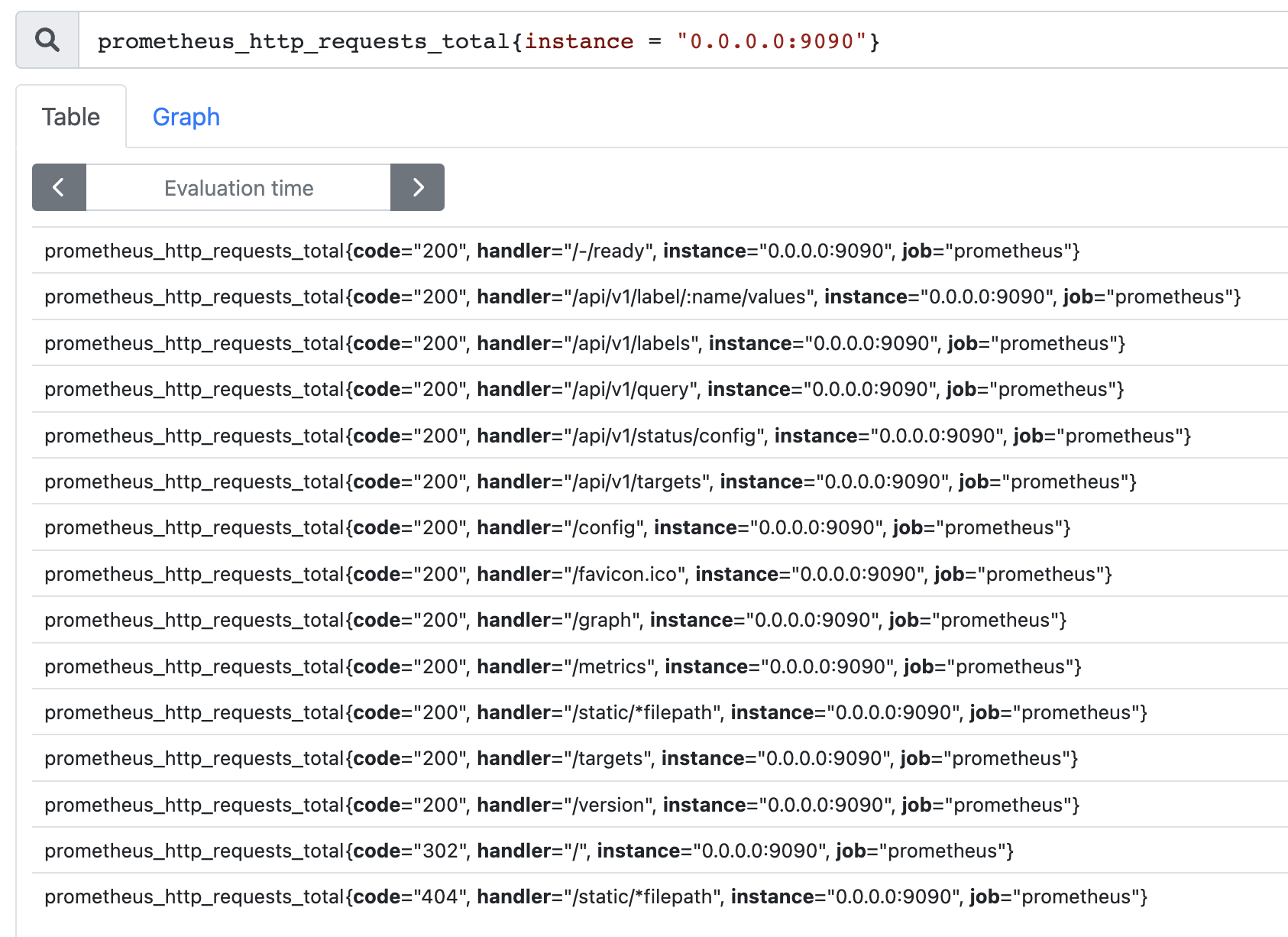
通过使用 label = value 可以选择那些标签满足表达式定义的时间序列;反之使用 label != value 则可以根据标签匹配排除时间序列;
例如,我们只需要查询所有 prometheus_http_requests_total 时间序列中满足标签 instance 为 0.0.0.0:9090 的时间序列,则可以使用如下表达式:
再比如查询 code 不等于 200 的时间序列。
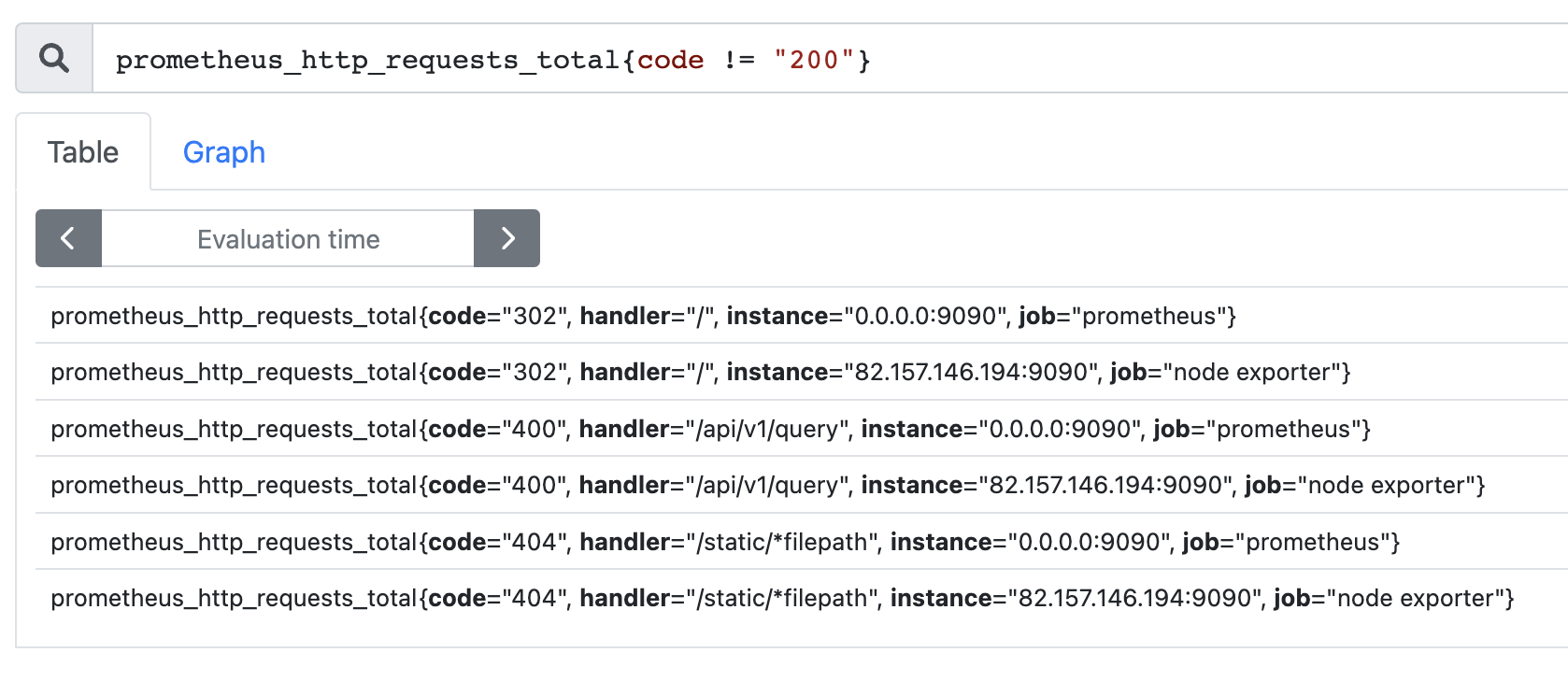
如果 {} 里面没有内容的话,那么 prometheus_http_requests_total 等价于 prometheus_http_requests_total{}。
2)正则匹配
PromQL还可以支持使用正则表达式作为匹配条件,多个表达式之间使用 | 进行分离:
使用 label =~ regx 表示选择那些标签符合正则表达式定义的时间序列;反之使用 label !~ regx 进行排除;
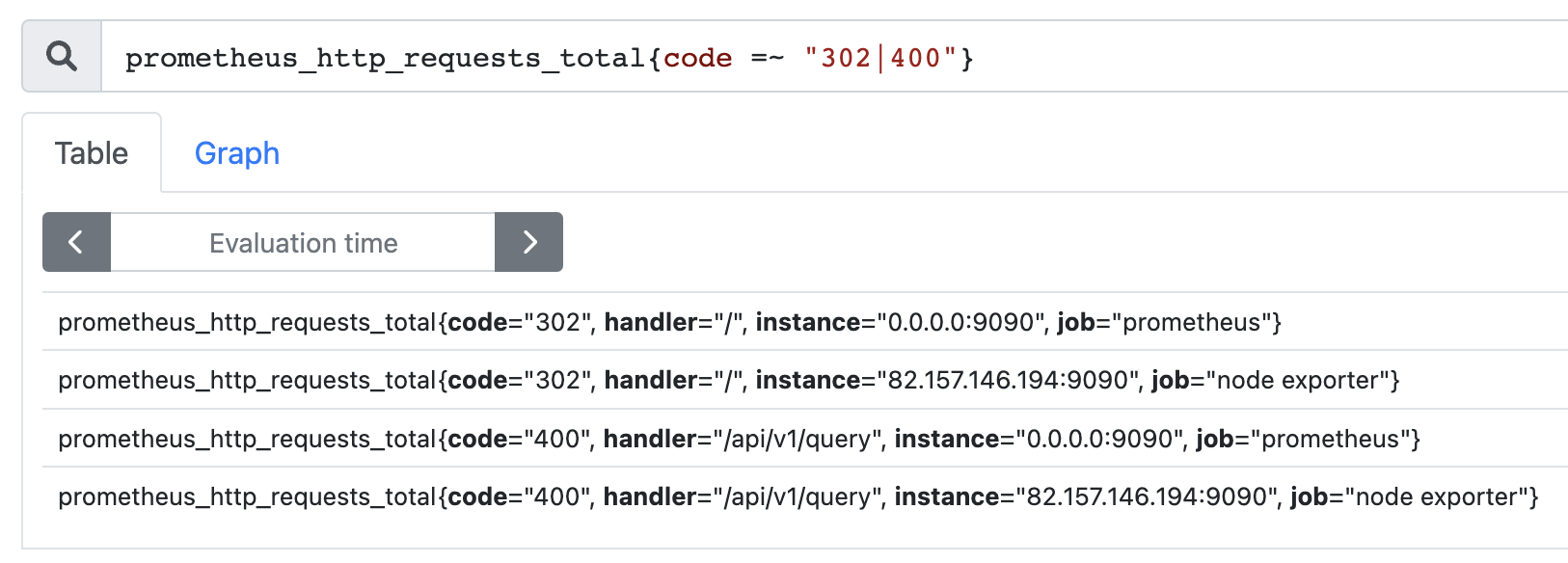
查询 code 为 302 或 400 的时间序列:
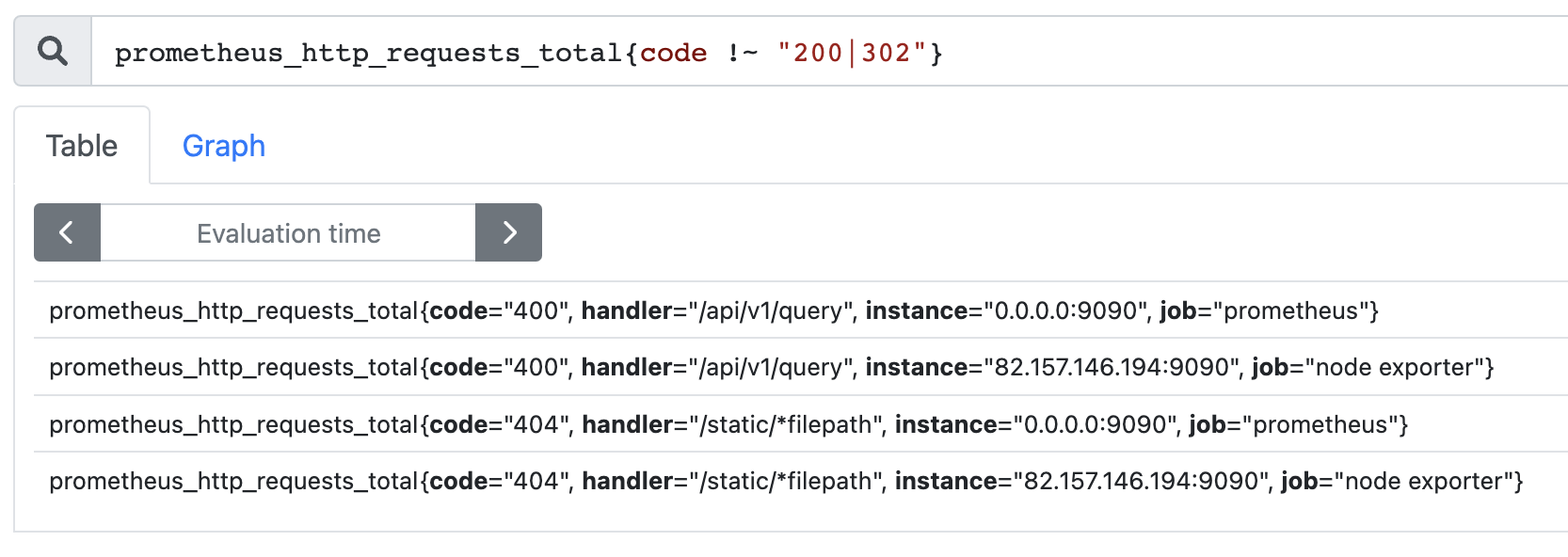
查询 code 不为 200 和 302 的时间序列:
整个过程很好理解,时间序列由指标名和一组标签共同确定。如果只输入指标,那么会选择出所有的时间序列,而通过标签可以实现更细腻度的筛选。但是目前我们只是根据单个标签进行筛选,如果是多个标签该怎么办呢?比如在 code 不为 200 和 302 的基础上,我们还要求 job 为 prometheus 。
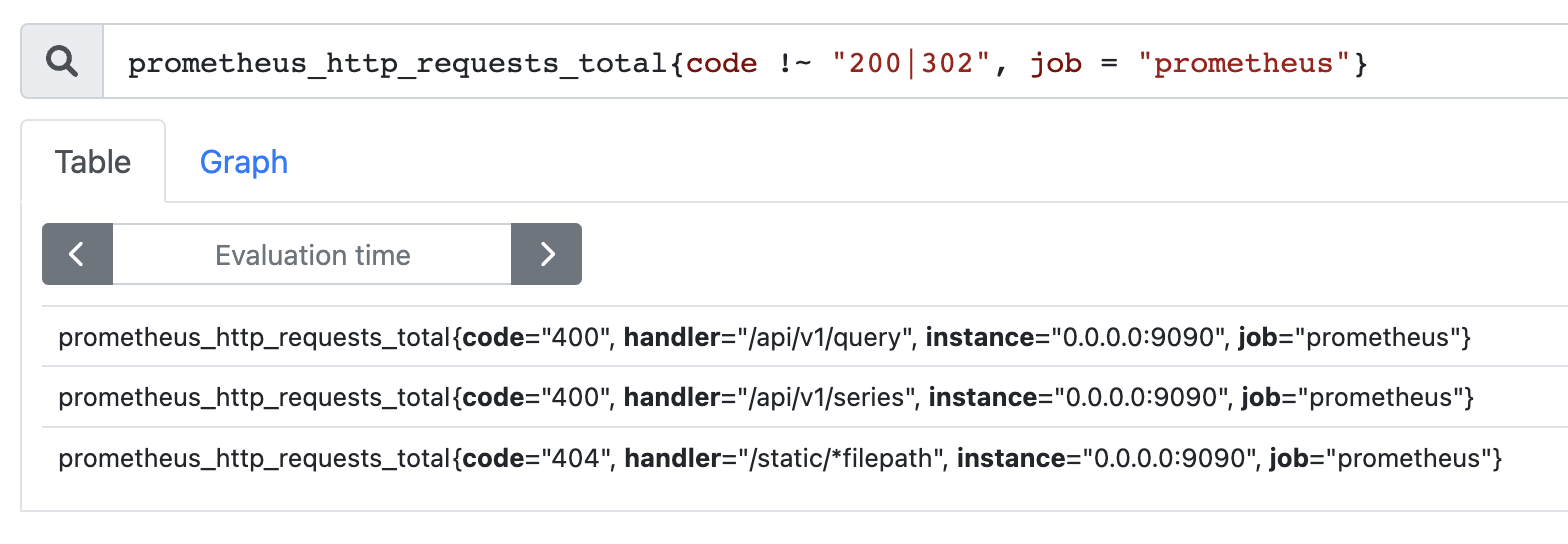
非常简单,就像标签本身一样,多个条件用逗号隔开即可。
范围查询
我们上面一直提到时间序列,那么这个时间序列在哪呢?首先我们使用 PromQL 查询时间序列时,返回值中只包含该时间序列的最新的一个样本值。

基于指标名和标签可以唯一确定一组时间序列,该序列里面包含了很多的时间、和样本值,每一个时间都会对应一个样本值,从而反应服务随时间的运行状态。但我们在查询的时候,默认只会返回最新的,如果想返回指定时间段的,应该通过时间范围选择器来实现。
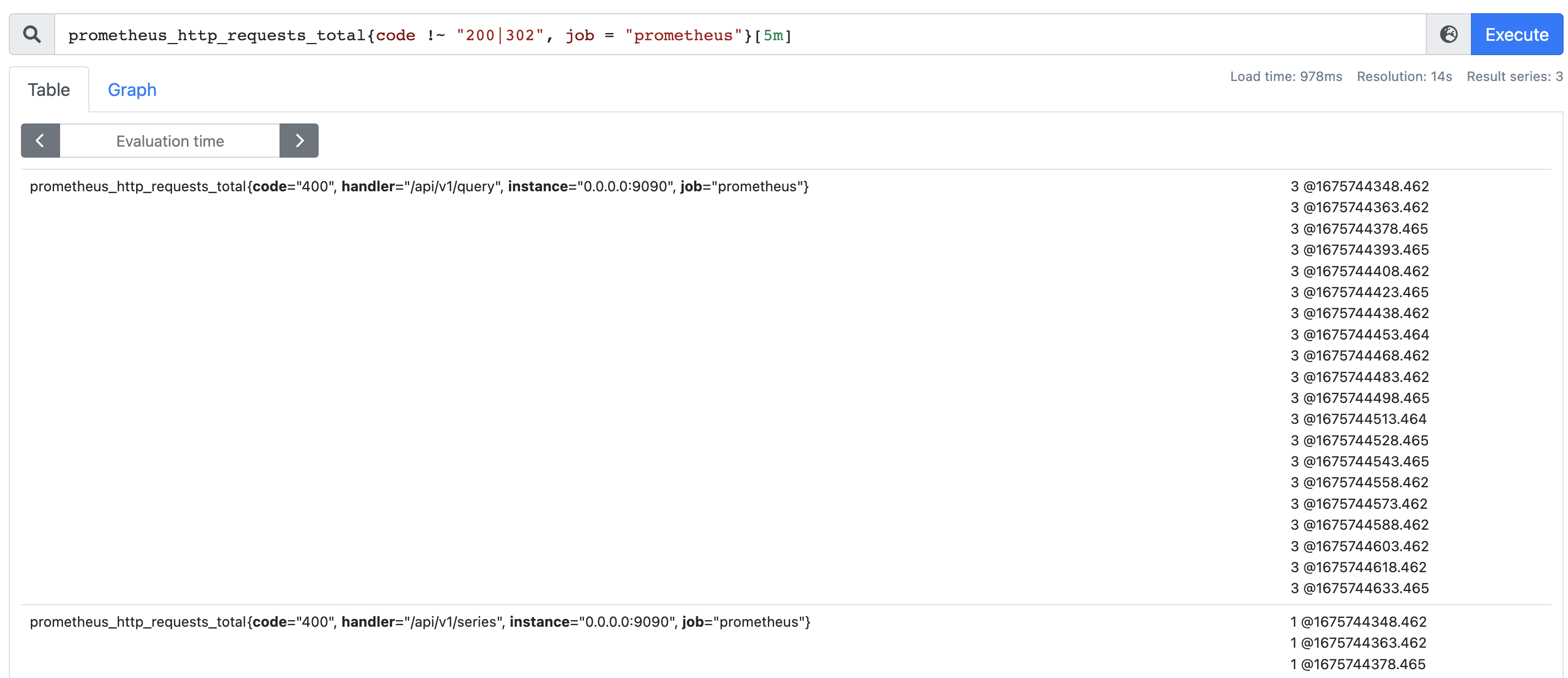
在结尾处加上 [5m],返回的就不是一个元素了,而是一组元素,每个元素都满足样本值@时间戳的格式。而 [5m] 表示选择以当前时间为基准,过去 5 分钟的数据。
除了表示 m 的分钟之外,还有很多其它时间单位:
s:秒m:分钟h:小时d:天w:周y:年
时间位移操作
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准:
prometheus_http_requests_total{} # 瞬时向量表达式,选择当前最新的数据prometheus_http_requests_total{}[5m] # 区间向量表达式,选择以当前时间为基准,5 分钟内的数据
而如果我们想查询,5 分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢?这个时候我们就可以使用位移操作,位移操作的关键字为 offset。
# 选择 5 分钟前的最新数据
prometheus_http_requests_total{} offset 5m
# 选择以 1 天前为基准,过去一天的数据
prometheus_http_requests_total{}[1d] offset 1d
使用聚合操作
一般来说,如果描述样本特征的标签(label)在并非唯一的情况下,通过 PromQL 查询数据,会返回多条满足这些特征维度的时间序列。而 PromQL 提供的聚合操作可以用来对这些时间序列进行处理,形成一条新的时间序列:
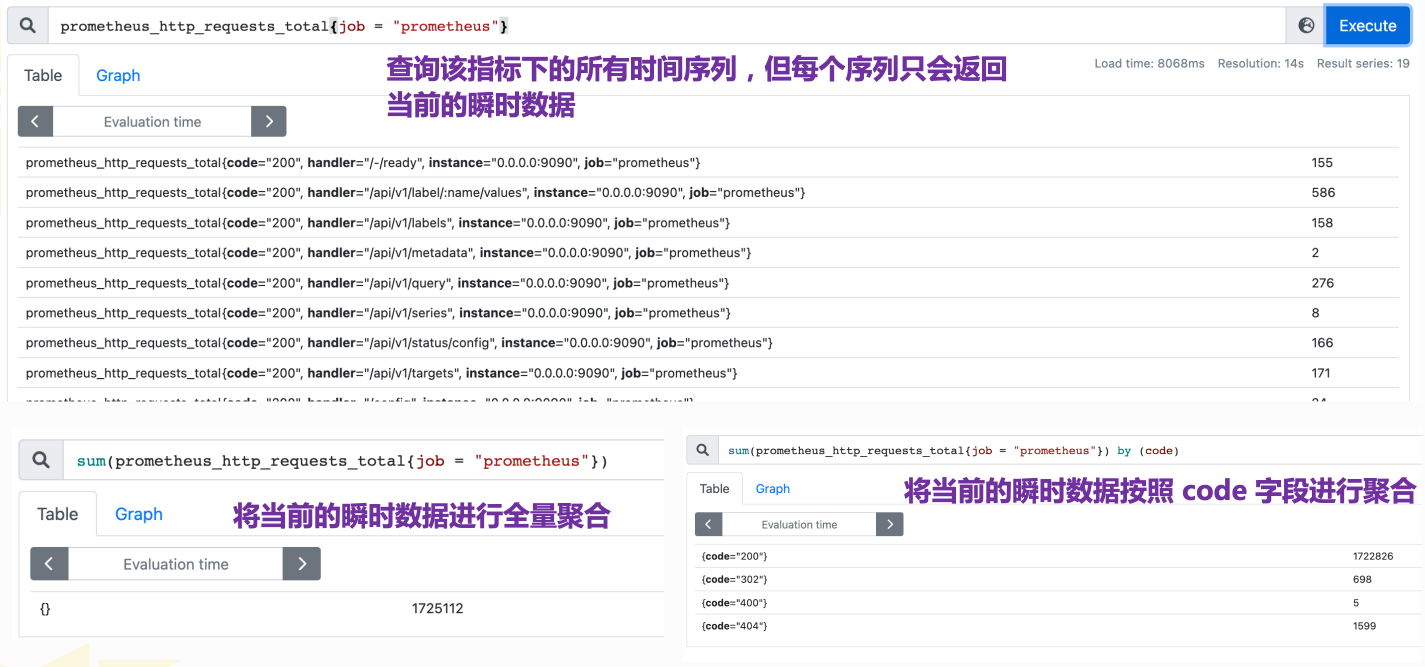
如果想对一分钟前的数据进行聚合的话,也是很方便的。
sum(prometheus_http_requests_total{job = "prometheus"} offset 1m) by (code)
然后聚合相关的运算符除了 sum,还有很多其它的,它们都用于操作瞬时数据,返回一条新的时间序列。
sum (求和)min (最小值)max (最大值)avg (平均值)stddev (标准差)stdvar (标准差异)count (计数)count_values (对 value 进行计数)bottomk (后 n 条时序)topk (前 n 条时序)quantile (分布统计)
PromQL 操作符
使用 PromQL 除了能够方便的按照查询和过滤时间序列以外,PromQL 还支持丰富的 操作符,用户可以使用这些操作符对进一步的对事件序列进行二次加工。这些操作符包括:数学运算符,逻辑运算符,布尔运算符等等。
1)数学运算符
+ (加法)- (减法)* (乘法)/ (除法)% (求余)^ (幂运算)
举个例子:
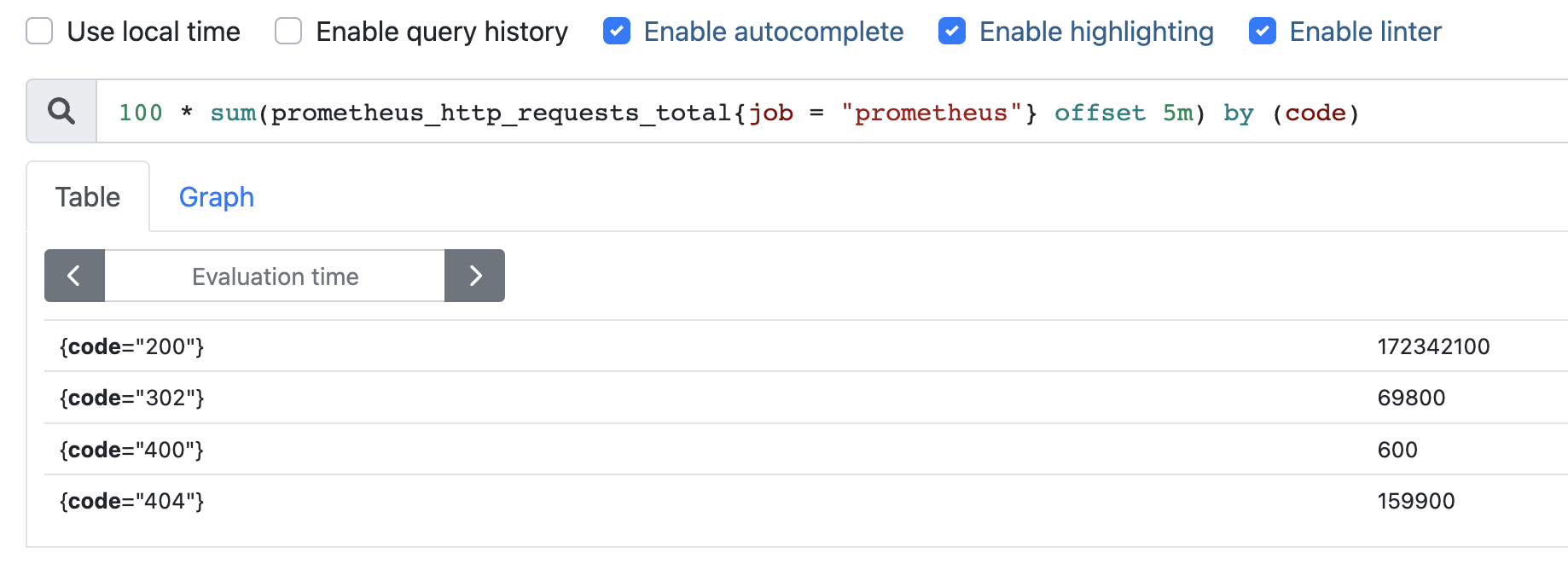
查询 5 分钟前指标为 prometheus_http_requests_total 的时间序列,并基于 job 进行过滤,然后按照 code 进行聚合求总数,并将结果乘以 100。
2)布尔运算符
== (相等)!= (不相等)> (大于)< (小于)>= (大于等于)<= (小于等于)
使用布尔运算符主要是为了对数据进行过滤:
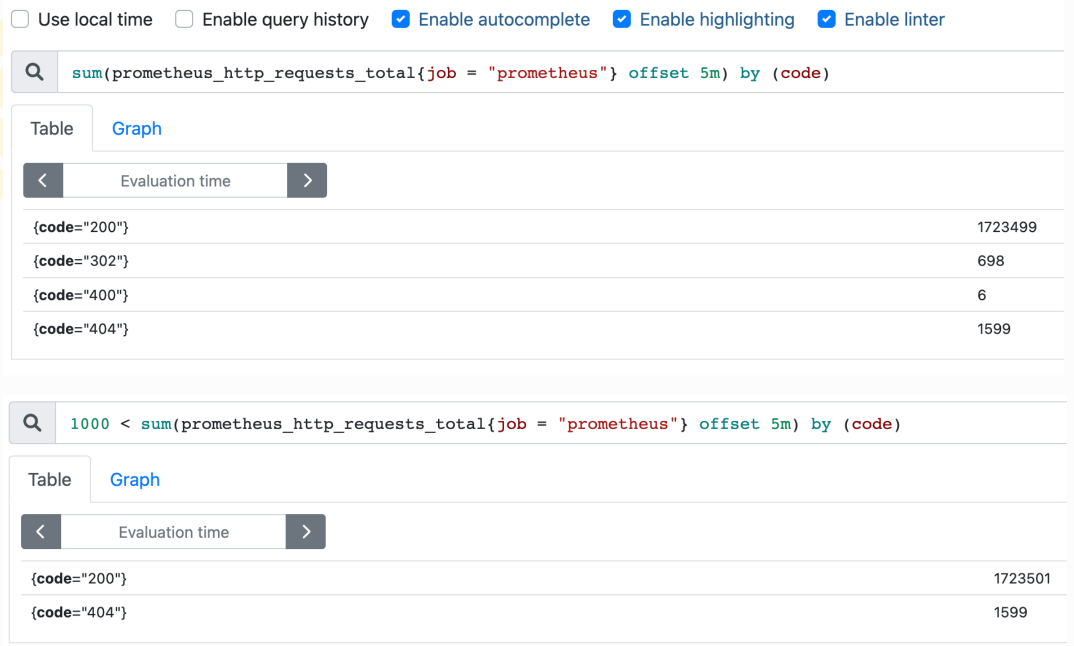
3)集合运算符
使用瞬时向量表达式能够获取到一个包含多个时间序列的集合,每个时间序列只会返回最新的样本值,我们称为瞬时向量。通过集合运算,可以在两个瞬时向量之间进行相应的集合操作。
目前,Prometheus 支持以下集合运算符:
and (并且)or (或者)unless (排除)
vector1 and vector2 会产生一个由 vector1 的元素组成的新的向量,该向量由 vector1 中完全匹配 vector2 的元素组成。
vector1 or vector2 会产生一个新的向量,该向量包含 vector1 中所有的样本数据, 以及 vector2 中没有与 vector1 匹配到的样本数据。
vector1 unless vector2 会产生一个新的向量,新向量中的元素由 vector1 中没有与 vector2 匹配的元素组成。
所以就相当于集合的交集、并集、差集运算。
Prometheus 和 Grafana 集成
grafana 是一款采用 Go 语言编写的开源应用,主要用于大规模指标数据的可视化展现,是网络架构和应用分析中最流行的时序数据展示工具,目前已经支持绝大部分常用的时序数据库。下载地址:https://grafana.com/grafana/download
根据系统选择指定的安装文件,我这里选择第二种。我们可以直接在服务器上通过 wget 获取,也可以点击那个链接,然后下载到本地、再上传至服务器。
然后解压至 /opt 目录,进入 /opt 查看。
grafana 的配置文件都在 conf 目录里面,文件的注释很详细,这里不再赘述。我们启动 grafana:
nohup ./bin/grafana-server web > ./grafana.log 2>&1 &
web 服务默认监听 3000 端口,默认用户名和密码都是 admin。
成功打开页面,我们输入用户名和密码,进入后台。
添加数据源
grafana 负责接收数据,展示图表,那么数据从哪儿来呢?所以我们要配置数据源。
点击之后,进入新页面,然后再点击屏幕中的 Add data source,选择 Prometheus。
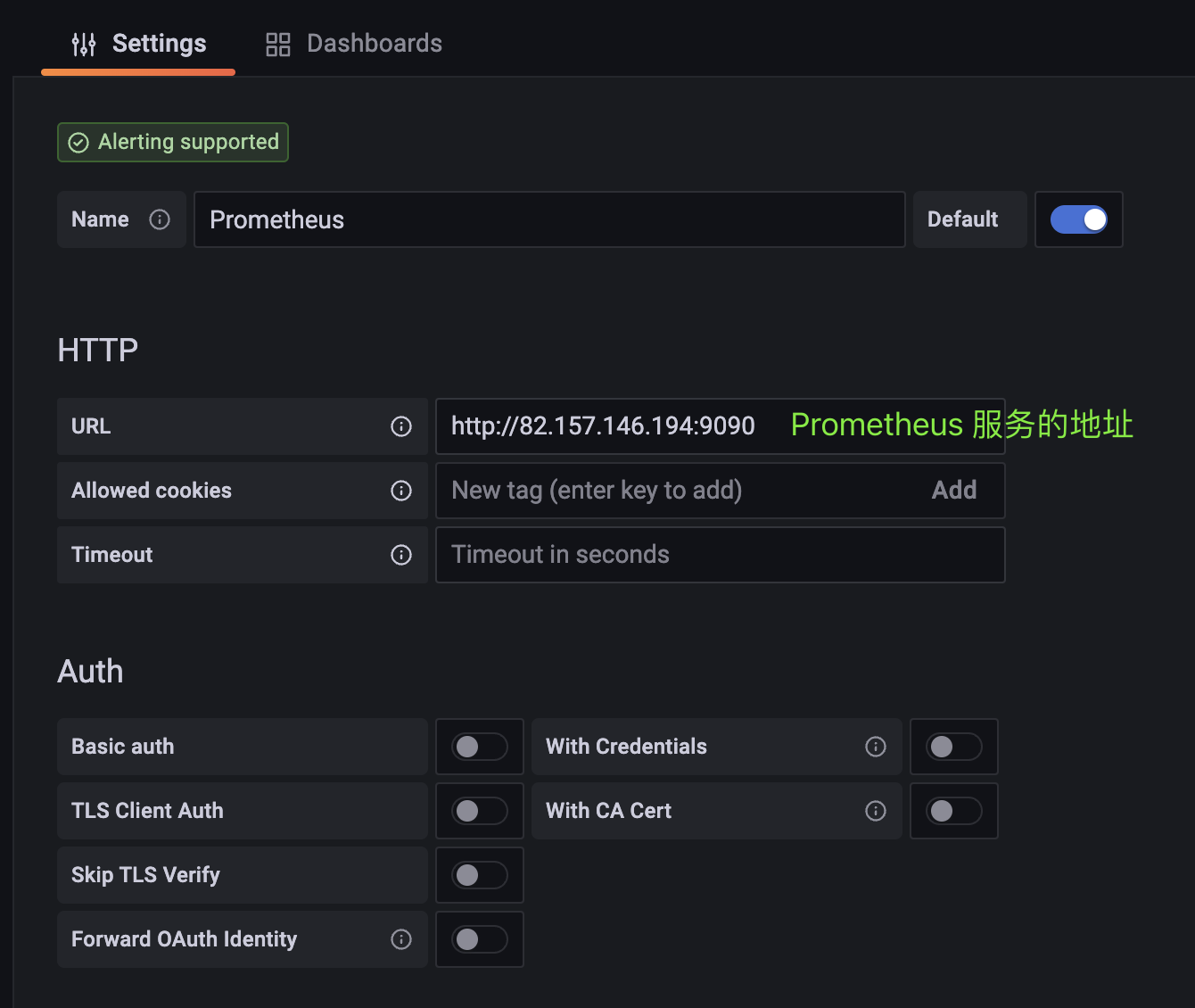
然后页面滑动到底部,点击 save & test,如果出现 Data source is working,那么表示配置成功。然后回到 Data sources 页面,我们配置的 Prometheus 已经显示在页面上了。

当然我们可以继续点击 Add data source 添加数据源。
手动创建仪表盘 Dashboard
然后我们创建仪表盘:
点击之后,会弹出三个选项,我们选择 Add a new panel。一个 panel 你就可以理解为一个图表,一个仪表盘(dashbord)可以包含多个图表(panel)。点击 Add a new panel 之后,进入图表配置页面。
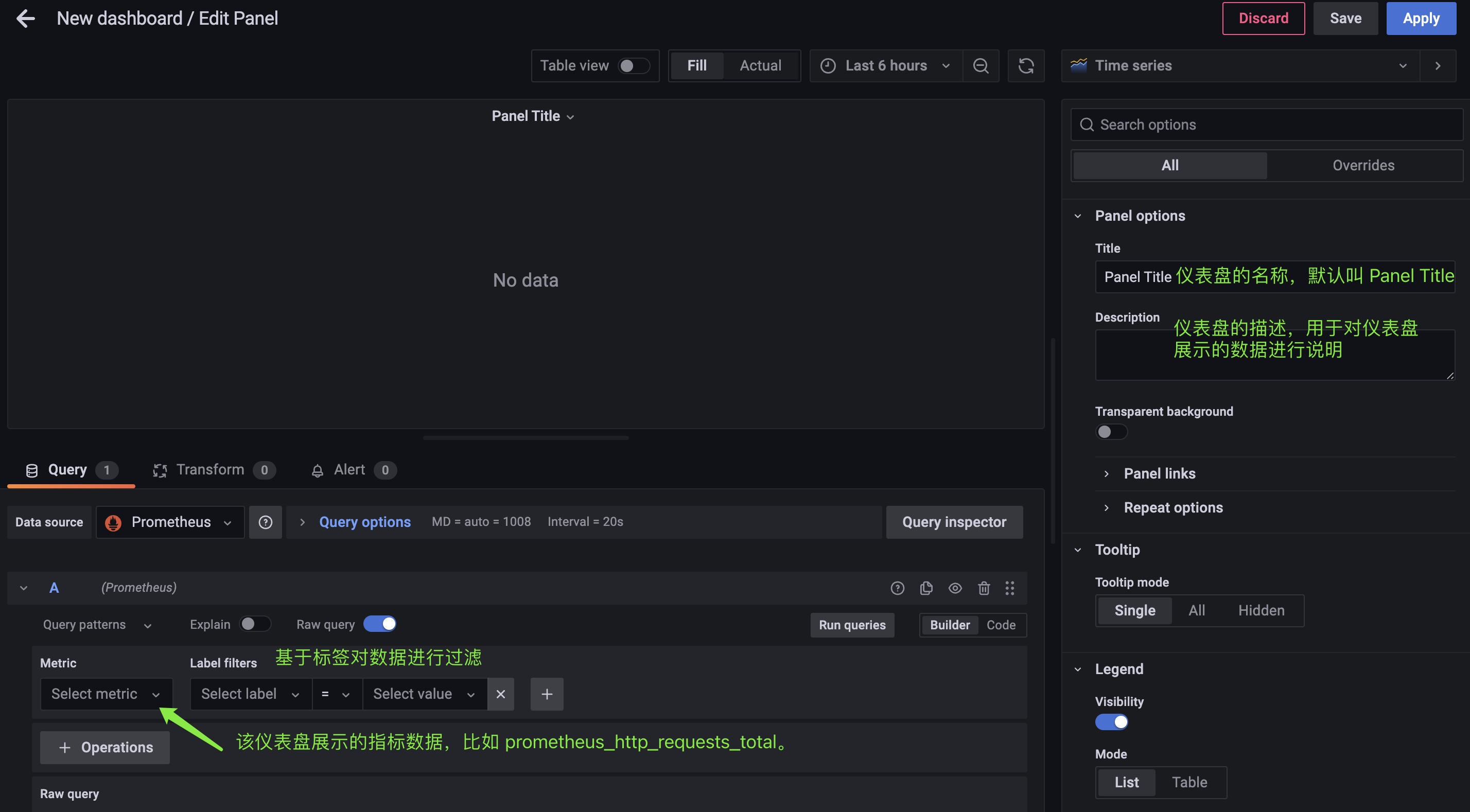
我们配置一下:
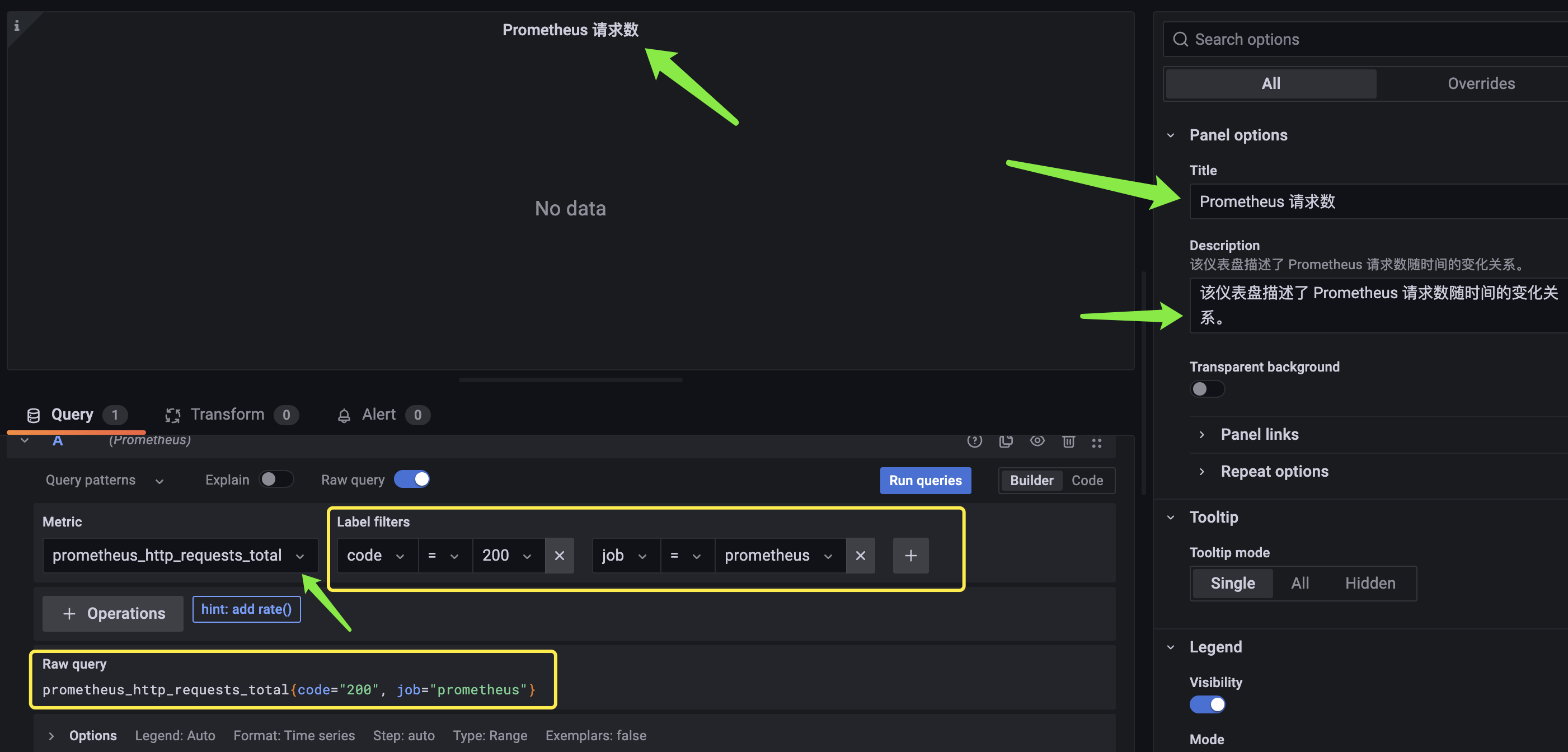
配置完毕之后,点击右上角的 save,使得配置生效。由于每一个 panel 都隶属于一个 dashbord,所以点击 save 之后,会让你给 dashboard 起一个名字(这里仍叫 Prometheus 请求数)。而每一个 dashboard 又都在一个文件夹中,所以选择此 dashboard 所在的文件夹(默认是 general 文件夹)。
然后进入 Dashboards 页面,点击 general 文件夹,会发现我们的仪表盘已经配置好了。
我们点击它,看看效果:

配置完成之后,grafana 会向 Prometheus 发送 PromQL,然后获取数据并展示成图表。此时该仪表盘下面只有一张图表,我们来看看这张图表。首先基于 code="200" 和 job="prometheus" 会查询到多条时间序列,所以图中会有多条线段(轨迹),每条轨迹都对应一个 label。我们可以点击感兴趣的 label,这样其他 label 对应的轨迹就会被隐藏。

点击哪个 label,就显示该 label 对应的轨迹,如果再次点击当前已被点击的 label,那么相当于取消单选,会再次展示全部轨迹。如果想查看指定的多条轨迹,那么就点击的时候按住 command 键(针对 Mac,Windows 应该是 Alt),即可实现多选。
如果想创建新的图标,那么点击 Add panel 进行创建即可。
点击之后,会弹出之前的三个选项,我们点击 Add a new panel。然后像之前一样配置图表属性即可,完事之后点击右上角的 save。
我们继续点击 save,由于我们是在 Prometheus 请求数 这个 dashboard 下点击的 Add a new panel,所以新创建的图表也会隶属于当前这个 dashboard。然后点击完 save,再点击右上角的 apply,那么就会看到新的图表了。
我们刷新页面看一下:
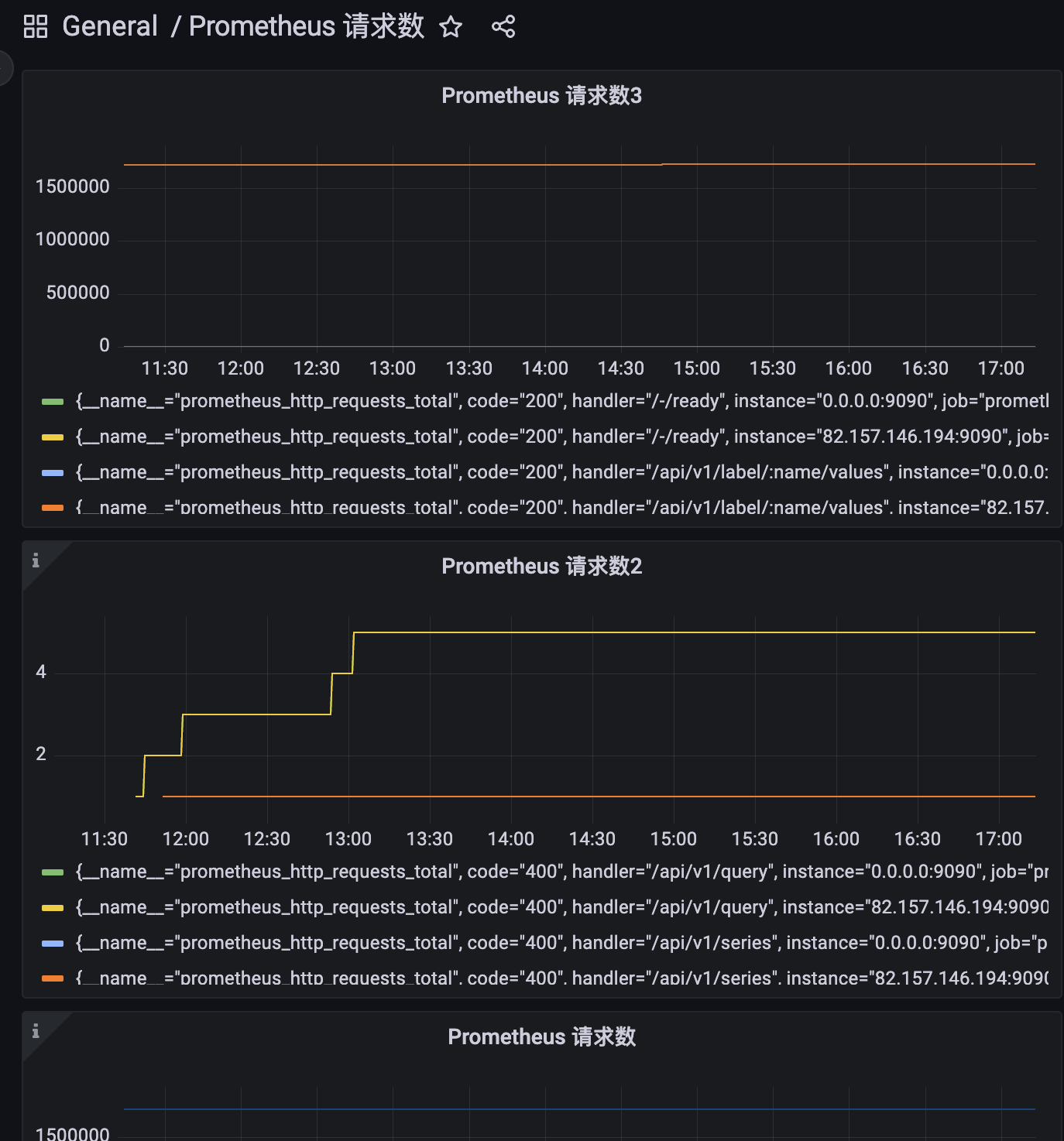
我这里在当前的 dashbord 下创建了 3 个 panel,都正常显示了。
panel 属性设置
目前是所有的 panel 都显示在了一个页面中,如果我想单独查看某个 panel 该怎么做呢?
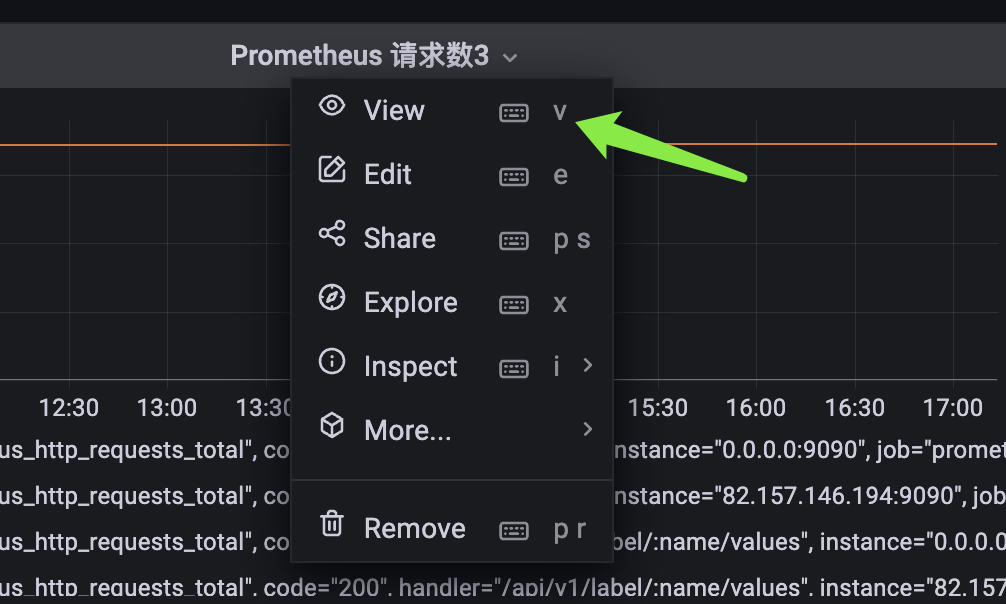
点击标题,再点击 view 即可单独查看指定的 panel。同理点击 Edit,可以重新编辑当前的 panel。比如我们可以添加新的监控项:
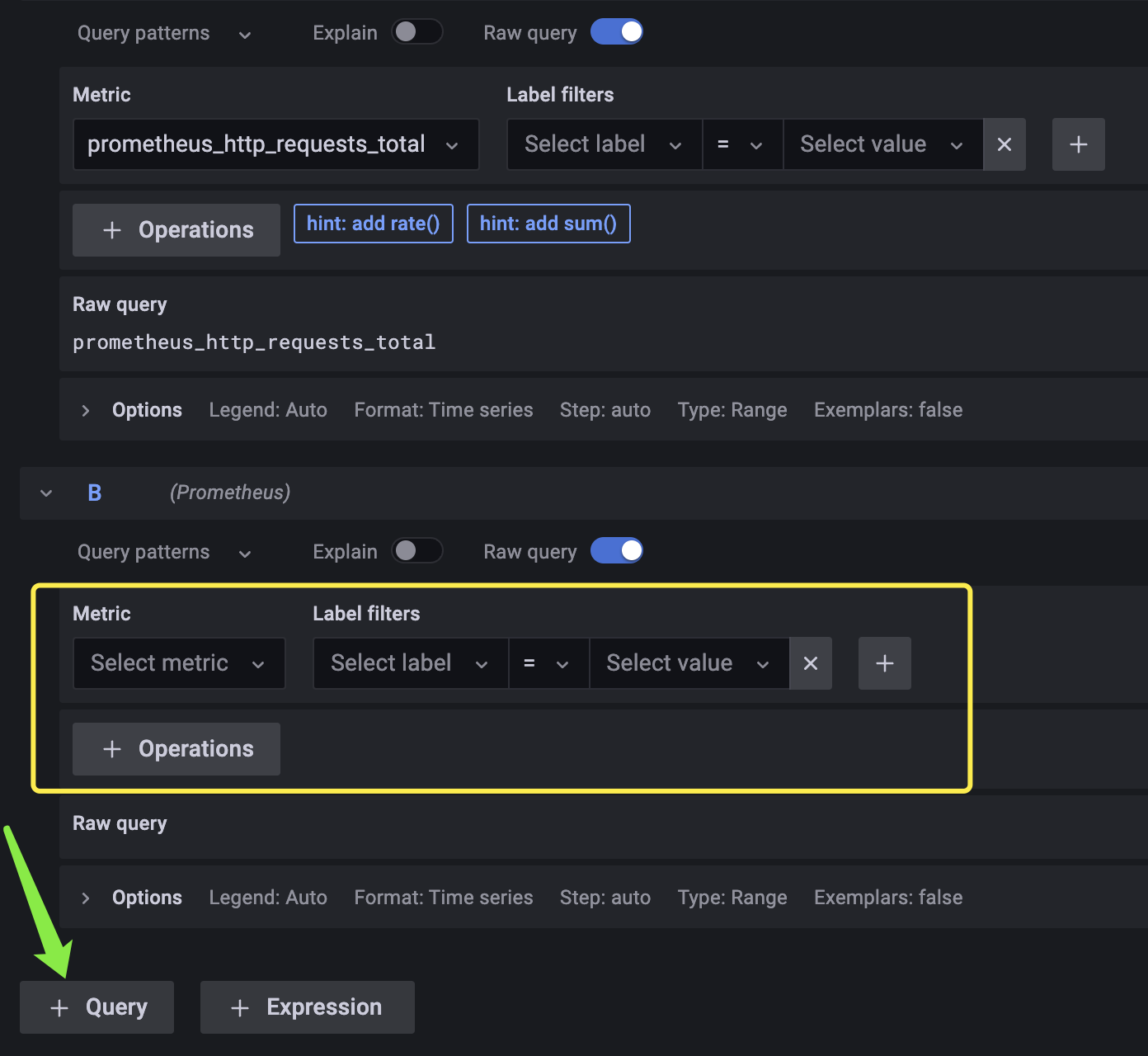
点击 query,我们可以继续添加新的监控项,当然也可以单独创建一个新的 panel 来展示它。
然后再来说一个重点,每个 panel 展示的都是以当前时间为基准、过去 6 个小时的数据,我们如何修改这个时间范围呢?
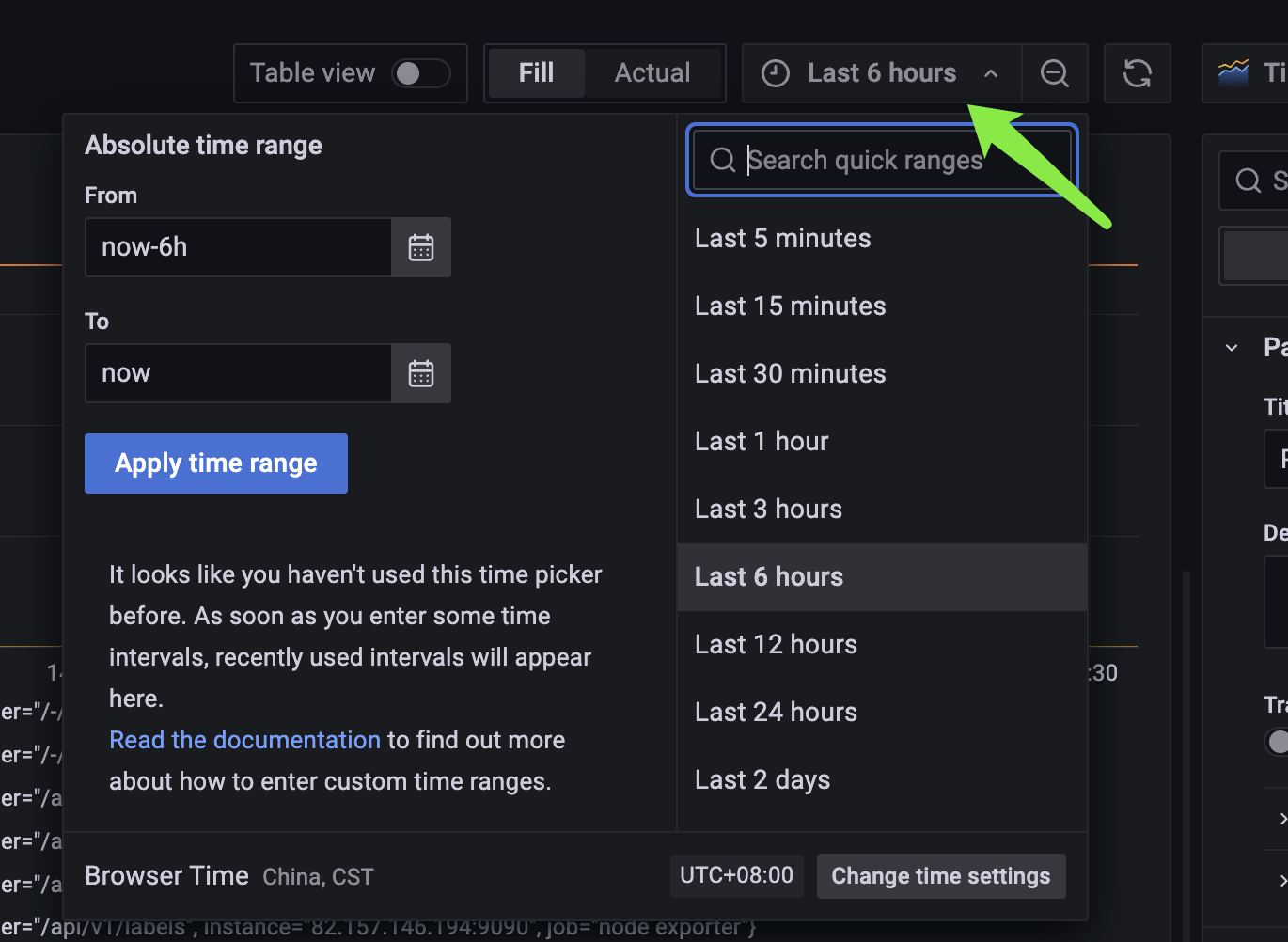
基于自身需求进行修改即可,并且我们也可以使用鼠标进行拖拽,精确查看某个时间段内的数据。
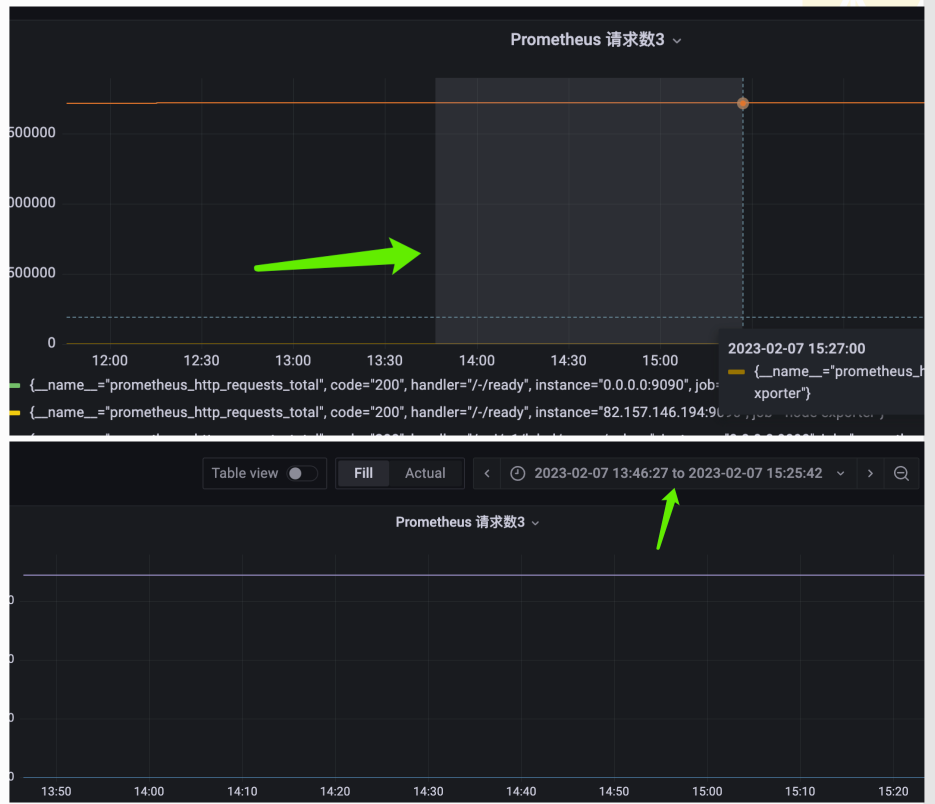
比较简单,可以自己手动操作一下。
如果这时候,我们想继续新建一个 dashboard 怎么办?很简单,和之前一样。
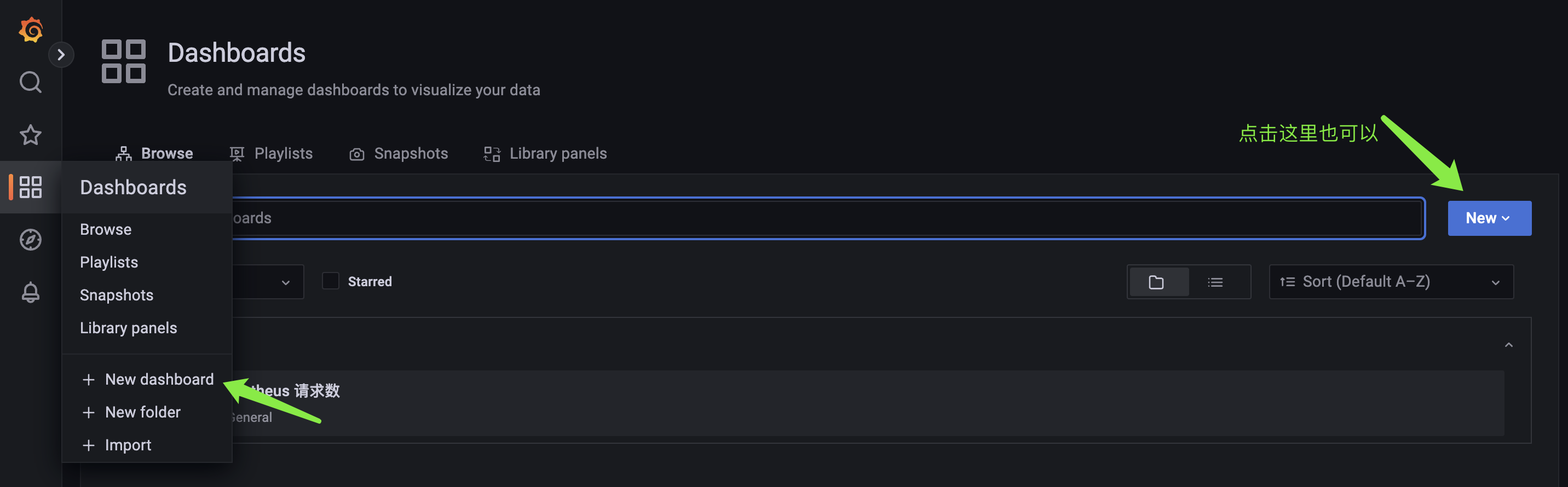
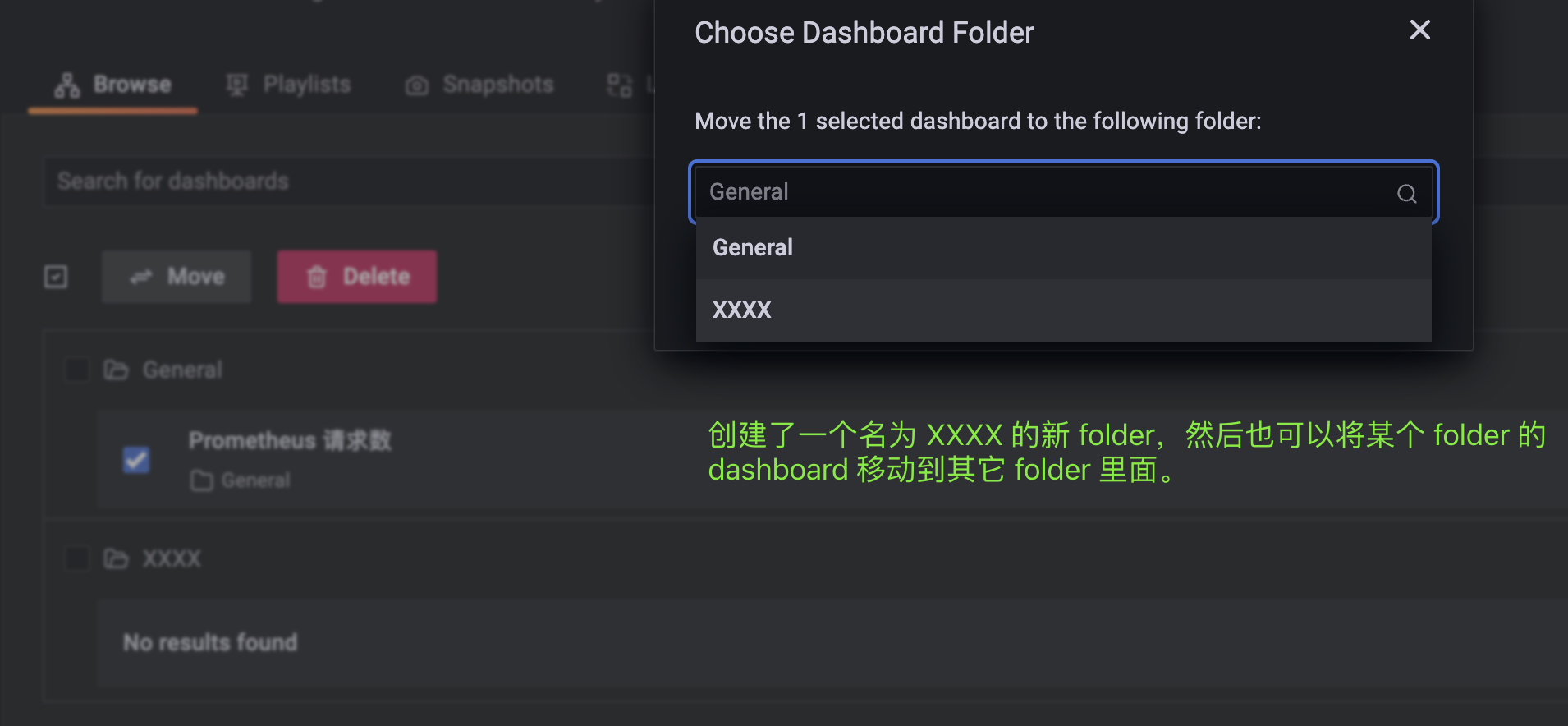
点击之后,选择新建一个 panel,保存 panel 的时候,新建 dashboard。另外我们看到 New dashboard 下面还有一个 New foler,我们说每一个 panel 都隶属于一个 dashboard,每一个 dashboard 都隶属于一个 folder。所以我们也可以新建一个 folder,将 dashboard 分门别类地组织起来。
添加模板
创建完 dashboard 之后,一个个手动创建 panel 比较麻烦。grafana 社区鼓励用户分享 Dashboard,通过 https://grafana.com/dashboards 网站,可以找到大量可直接使用的 Dashboard 模板。grafana 中所有的 Dashboard 都通过 JSON 进行共享,下载并且导入这些 JSON 文件,就可以直接使用这些已经定义好的 Dashboard。
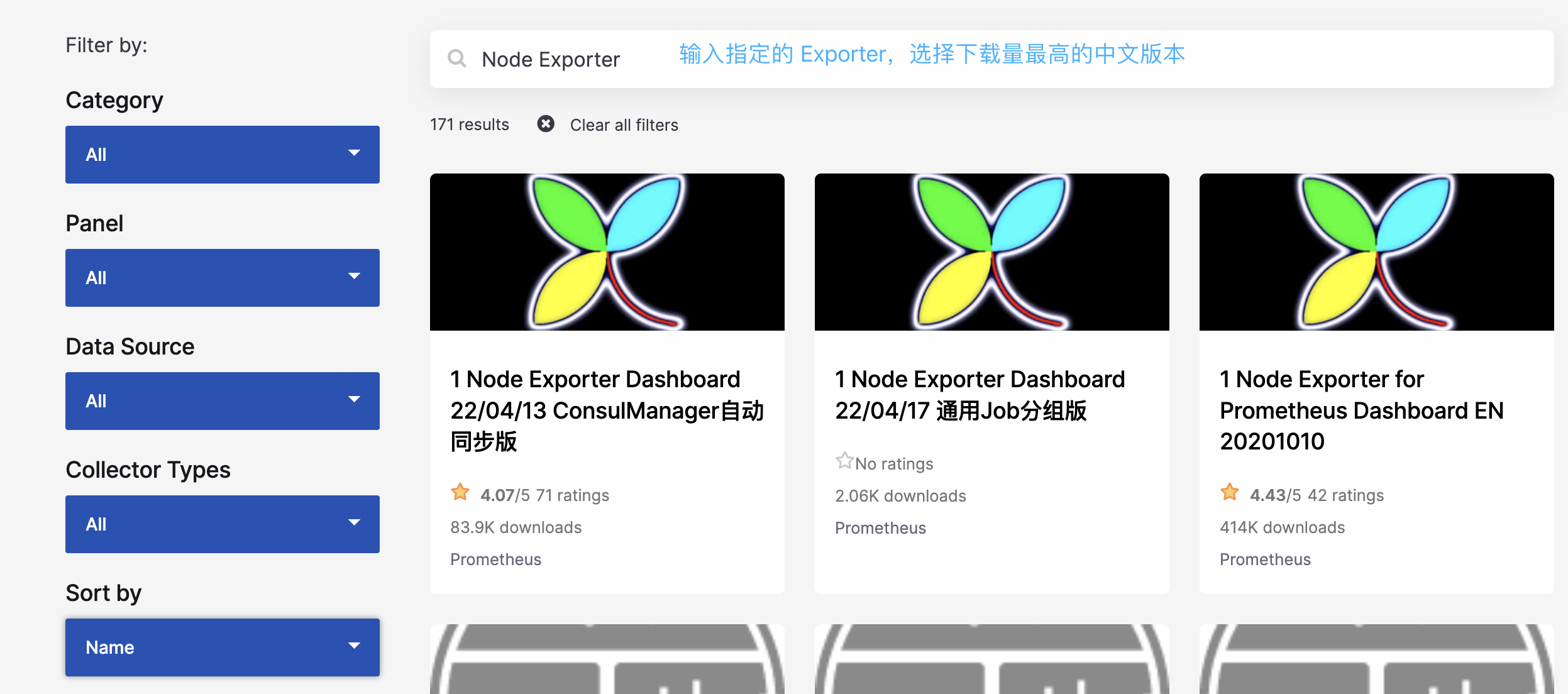
我们点击第一个,下载量为 83.9k 的,然后点击 Download JSON。
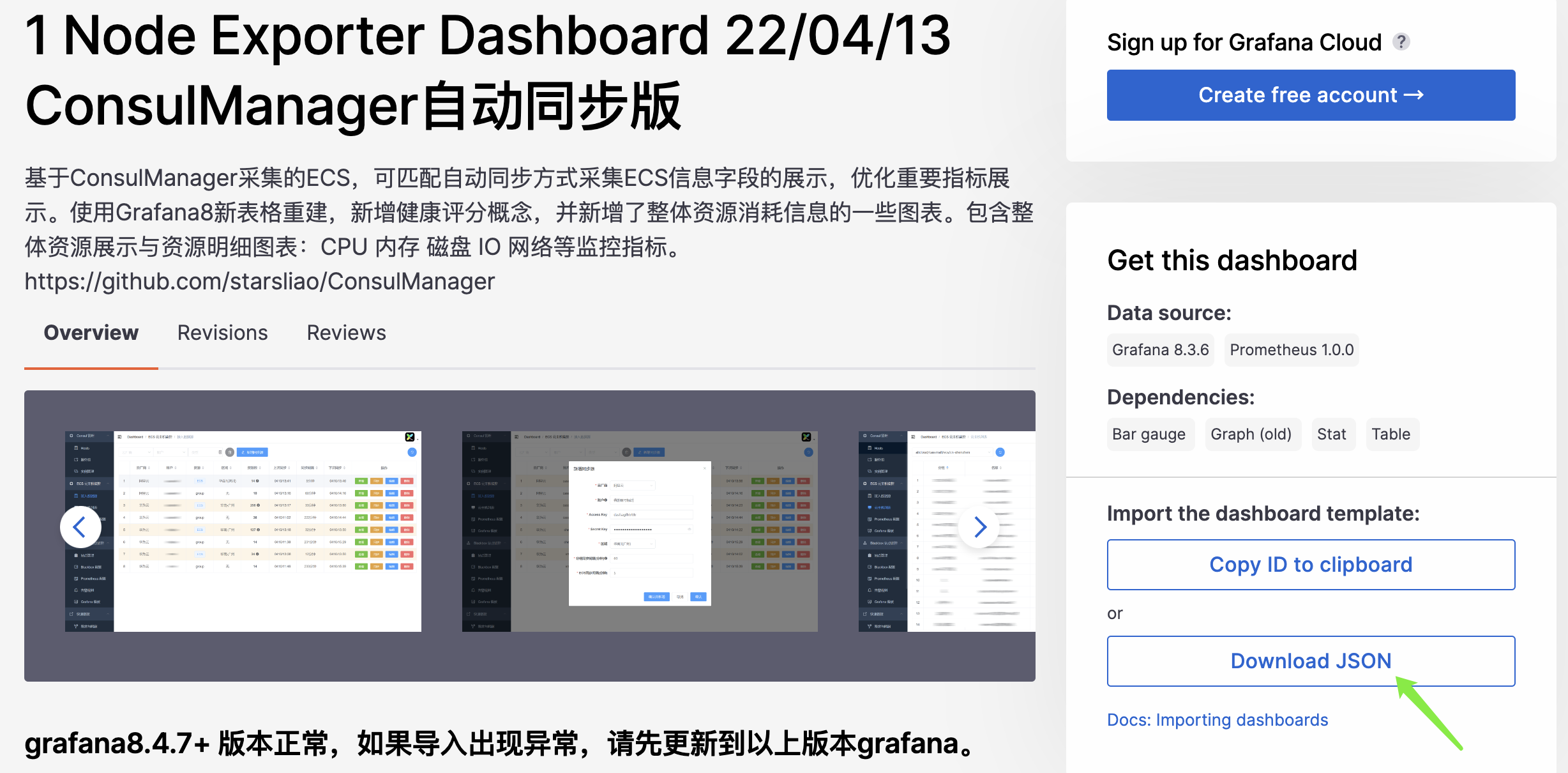
下载之后,在 grafana 中导入模板:
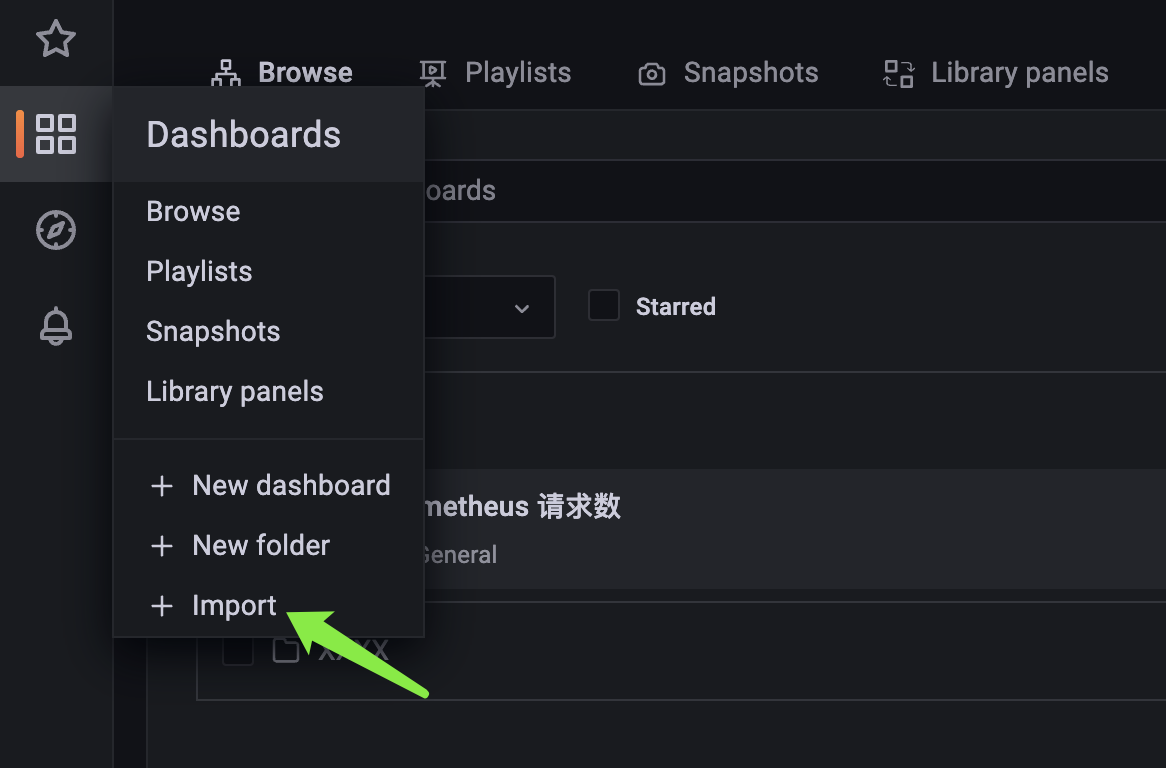
点击 Import:
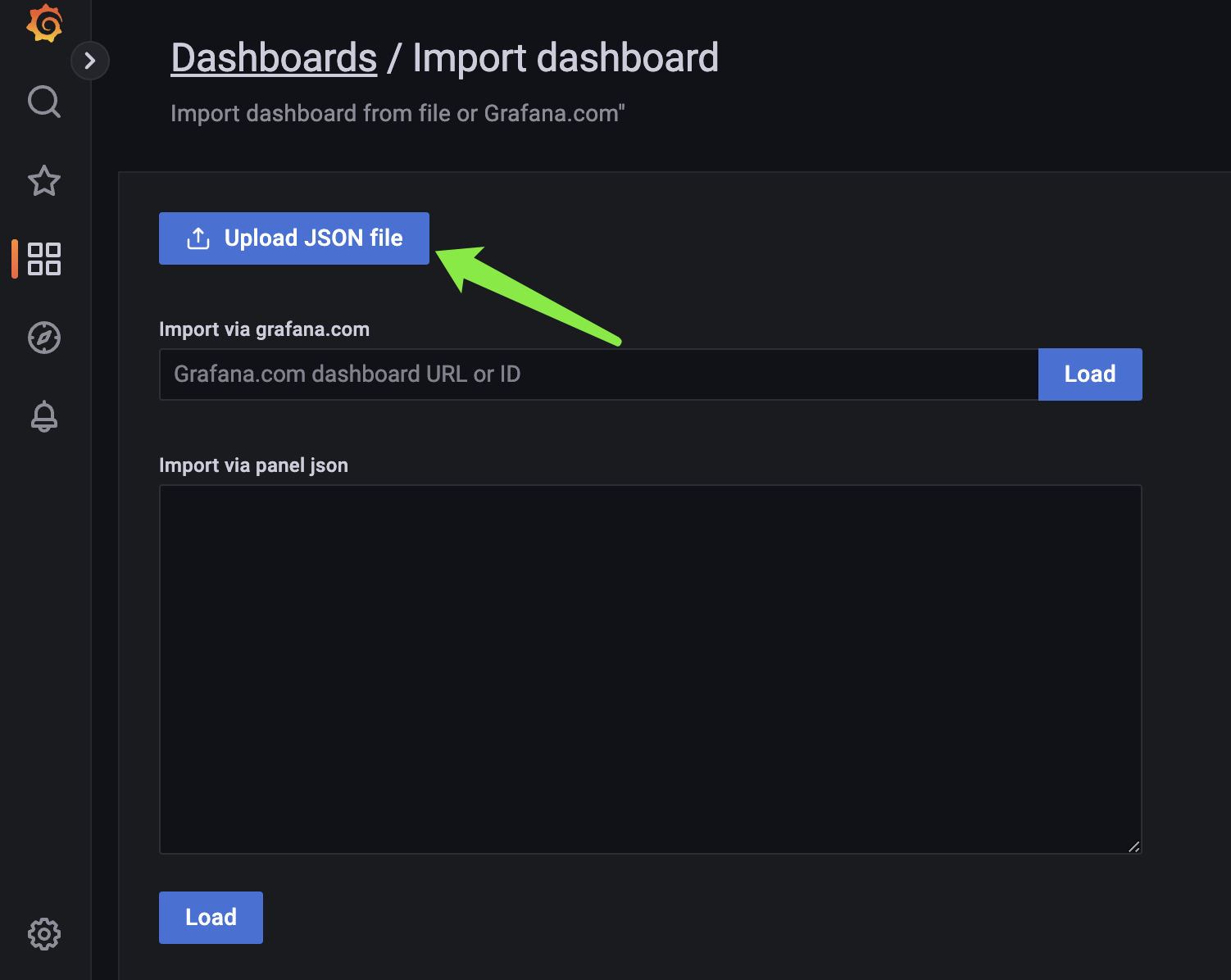
然后点击上传 JSON 文件,将刚才下载的 JSON 文件上传到 grafana。
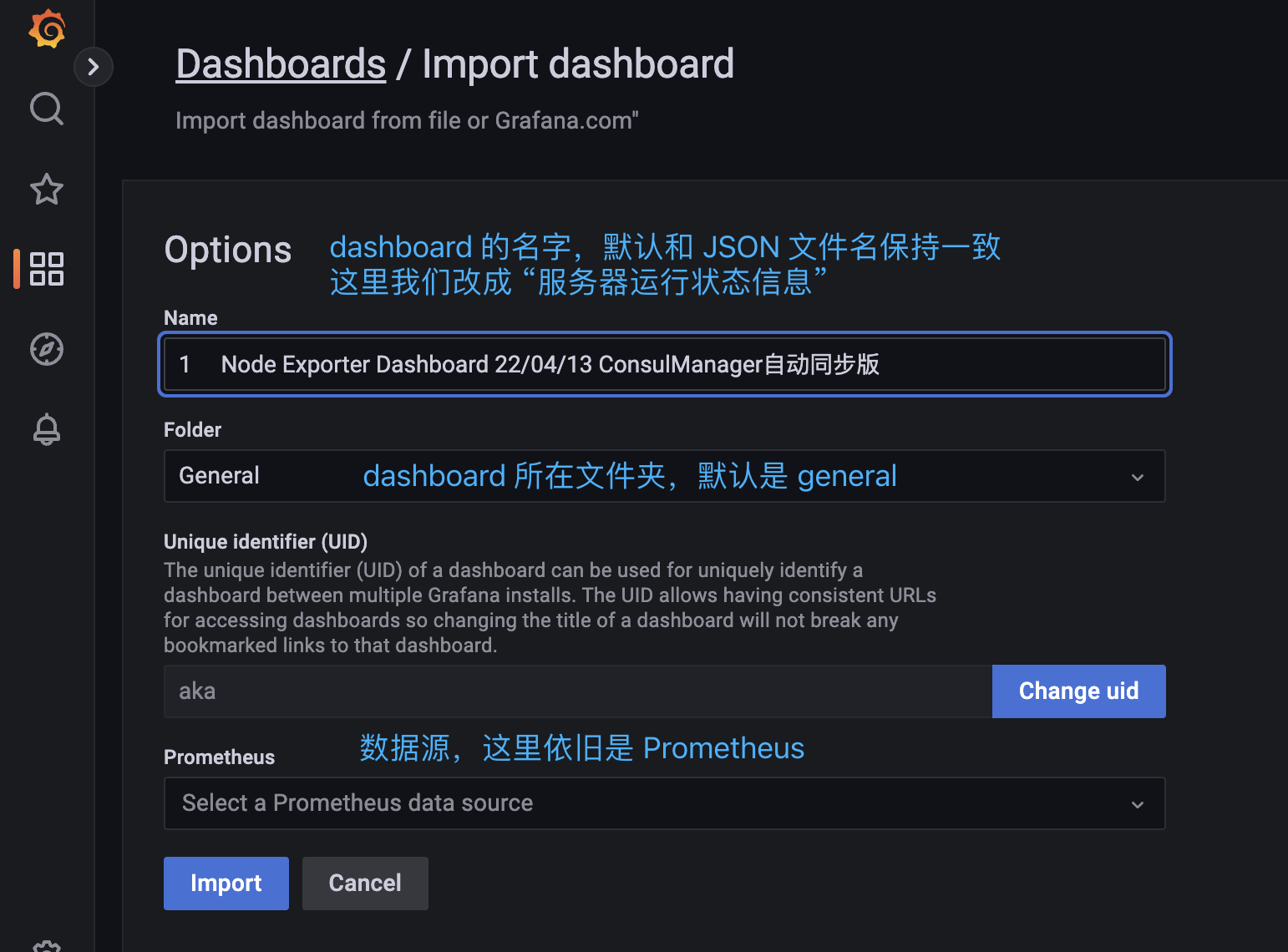
最后点击 Import 导入即可,然后我们看一下效果。

这么多的 panel,如果一个个手动创建无疑是巨大的工作量,但有了模板就方便多了。
小结
以上就是 grafana 相关的内容,不是很难,没事多点一点就熟悉了。然后关于告警的功能,比较简单,这里就不赘述了。
文章参考自:
尚硅谷:"Prometheus 教学视频",可以输入 https://www.bilibili.com/video/BV1HT4y1Z7vR/ 在 B 站上观看IT 老齐:"无监控不运维,基于Prometheus的指标监控架构长啥样?" 可以输入 https://www.bilibili.com/video/BV1wQ4y1e7Nw 在 B 站上观看
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号