ClickHouse 之 MergeTree 家族中的其它表引擎
楔子
目前在 ClickHouse 中,按照特点可以将表引擎分为 6 个系列,分别是合并树、外部存储、内存、文件、接口和其它,每一个系列的表引擎都有独自的特点和使用场景。而其中最核心的当属 MergeTree 系列,因为它们拥有最为强大的性能和最为广泛的使用场景。
经过之前的介绍,我们知道 MergeTree 有两种含义:
1. 表示合并树表引擎家族2. 表示合并树表引擎家族中最基础的 MergeTree 表引擎
而在整个家族中,除了基础表引擎 MergeTree 之外,常用的表引擎还有 ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree。从名字也能看出来,每一种合并树的变种,在继承了 MergeTree 的基础能力后,又增加了独有的特性,而这些独有的特性都是在触发合并的过程中被激活的。
MergeTree
MergeTree 作为家族系列最基础的表引擎,提供了数据分区、一级索引和二级索引等功能,至于它们的运行机理我们之前已经介绍过了。这里我们来介绍一下 MergeTree 的另外两个功能:数据 TTL 和 存储策略。
数据 TTL
TTL 即 Time To Live,表示数据的存活时间,而在 MergeTree 中可以为某个列字段或整张表设置 TTL。当时间到达时,如果是列字段级别的 TTL,则会删除这一列的数据;如果是整张表级别的 TTL,则会删除整张表的数据;如果同时设置,则会以先到期的为主。
无论是列级别还是表级别的 TTL,都需要依托某个 DateTime 或 Date 类型的字段,通过对这个时间字段的 INTERVAL 操作来表述 TTL 的过期时间,下面我们看一下设置的方式。
1)列级别设置 TTL
如果想要设置列级别的 TTL,则需要在定义表字段的时候为它们声明 TTL 表达式,主键字段不能被声明 TTL,举个栗子:
CREATE TABLE ttl_table_v1 (
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 10 SECOND,
type UInt8 TTL create_time + INTERVAL 10 SECOND
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id
其中 create_time 是日期类型,列字段 code 和 type 均被设置了 TTL,它们的存活时间在 create_time 取值的基础之上向后延续 10 秒。假设某一条数据的 create_time 的值为 dt,那么当系统时间超过了 dt + 10 秒,该条数据的 code、type 就会过期。
除了 SECOND 之外,还有 MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER 和 YEAR。
现在写入两条测试数据,其中第一条的 create_time 取当前的系统时间,第二条的 create_time 比第一条多 5 分钟。
INSERT INTO TABLE ttl_table_v1
VALUES ('A000', now(), 'C1', 1),
('A000', now() + INTERVAL 5 MINUTE, 'C1', 1)
然后马上进行查询(手速要快),然后等 10 秒过后(从写入数据的那一刻起),再查询一次。
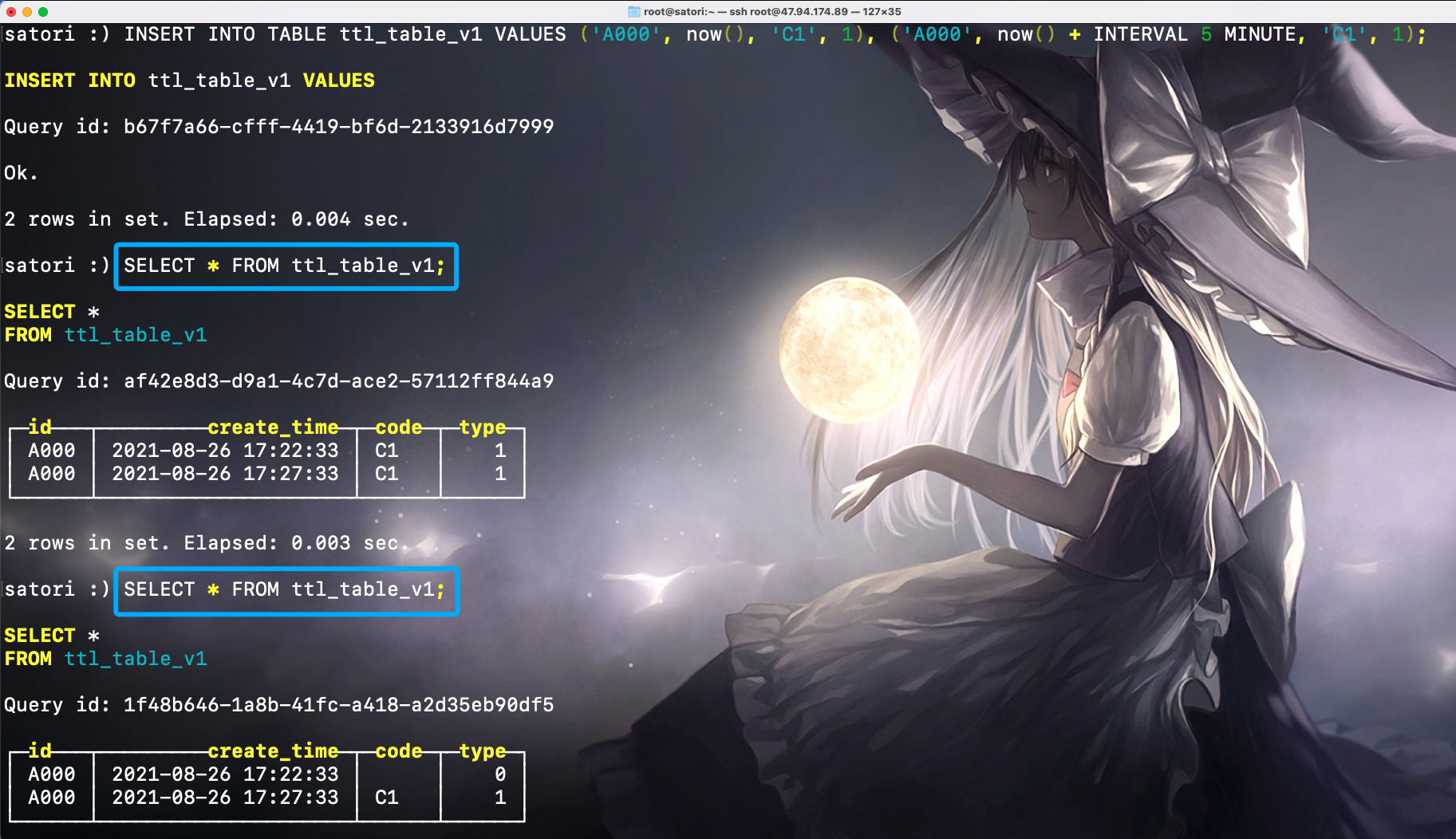
再次查询 ttl_table_v1 会看到,由于第一条数据满足 TTL 过期时间(当前系统时间 >= create_time + 10 秒),它们的 code 和 type 会被还原为数据类型的零值。
如果想要修改列字段的 TTL,或者为已有字段添加 TTL(不可以是主键字段),都可以使用 ALTER 语句,举个栗子:
ALTER TABLE ttl_table_v1 MODIFY COLUMN code String TTL create_time + INTERVAL 1 DAY
2)表级别设置 TTL
如果想为整张表设置 TTL,需要在 MergeTree 的表参数中增加 TTL 表达式,举个栗子:
CREATE TABLE ttl_table_v2 (
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 1 MINUTE,
type UInt8
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
TTL create_time + INTERVAL 1 DAY
ttl_table_v2 整张表被设置了 TTL,当触发 TTL 清理时,那些满足过期时间的数据行将被整行删除。同样,表级别的 TTL 也支持修改,方法如下:
ALTER TABLE ttl_table_v2 MODIFY TTL create_time INTERVAL + 3 DAY
另外表级别的 TTL 也不支持取消。
3)TTL 运行机理
在了解了列级别和表级别 TTL 的运行机理后,现在简单聊一聊 TTL 的运行机理。如果一张 MergeTree 表被设置了 TTL 表达式,那么在写入数据时会以分区为单位,在每个分区目录内生成 ttl.txt 文件。以上面的 ttl_table_v2 为例,它被设置了列级别的 TTL,也被设置了表级别的 TTL,那么在写入数据之后,它的每个分区目录内都会生成 ttl.txt 文件。
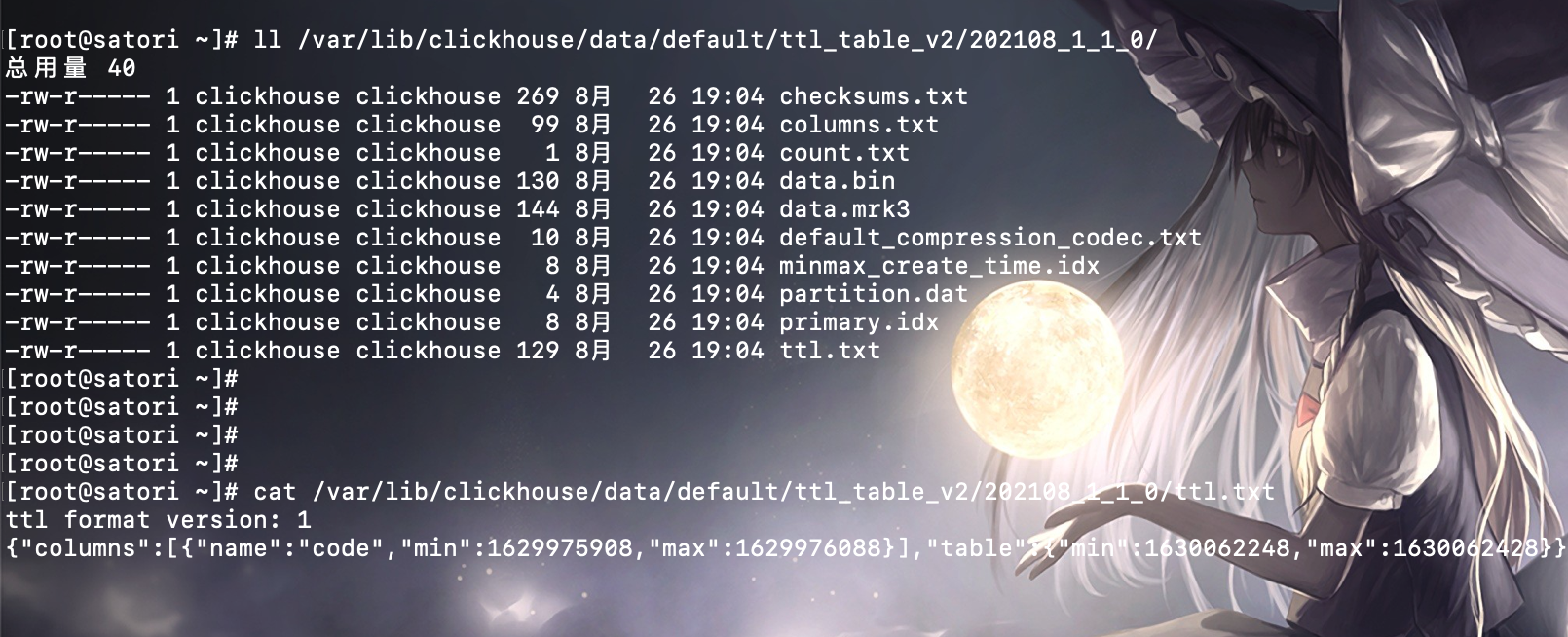
我们查看 ttl.txt 的内容发现,原来 MergeTree 是通过一串 JSON 保存了 TTL 的相关信息,其中:
columns 用于保存列级别的 TTL 信息table 用于表级别的 TTL 信息min 和 max 则保存了当前数据分区内,TTL 指定日期字段的最小值和最大值分别与 INTERVAL 表达式计算后的时间戳
如果将 table 属性中的 min 和 max 时间戳格式化,并分别与 create_time 最小值与最大值进行对比:

则能够印证,ttl.txt 中记录的极值区间恰好等于当前分区内 create_time 的最小值、最大值加 1 天(86400 秒),与 TTL 表达式 create_time + INTERVAL 1 DAY 相符合,同理 ttl_min 和 ttl_max 分别减去一天即可得到 create_time 这一列的最小值和最大值。
在知道了 TTL 信息的记录方式之后,再来看看它的处理逻辑。
1. MergeTree 以分区目录为单位,通过 ttl.txt 文件记录过期时间,并将其作为后续的判断依据2. 每当写入一批数据时,都会基于 INTERVAL 表达式的计算结果为这个分区生成 ttl.txt 文件3. 只有 MergeTree 在对属于相同分区的多个分区目录进行合并时,才会触发删除 TTL 过期数据的逻辑4. 在选择删除的分区时,会使用贪婪算法,它的算法规则是尽可能找到会最早过期的、同时年纪又是最老的分区(合并次数更多,MaxBlockNum 更大的)5. 如果一个分区内某一列数据因为 TTL 到期全部被删除了,那么在合并之后生成的新分区目录中,将不会再包含该列对应的 bin 文件和 mrk 文件,如果列数据分开存储的话
TTL 默认的合并频率由 MergeTree 的 merge_with_ttl_timeout 参数所控制,默认为 86400 秒、也就是 1 天。它维护的是一个专有的 TTL 任务队列,有别于 MergeTree 的常规合并任务,这个值如果设置的过小,可能会带来性能损耗。当然除了被动触发 TTL 合并外,也可以使用 optimize 强制触发合并:
optimize TABLE table_name PARTITION 分区名:触发一个分区合并optimize TABLE table_name FINAL:触发所有分区合并
最后,ClickHouse 虽然没有提供删除 TTL 的声明方法,但是提供了控制 TTL 合并任务的启停方法。
SYSTEM STOP/START TTL MERGES:控制全局 MergeTree 表启停SYSTEM STOP/START TTL MERGES table_name:控制指定 MergeTree 启停
多路径存储策略
在 ClickHouse 19.15 版本之前,MergeTree 只支持单路径存储,所有的数据都会被写入 config.xml 配置中的 path 指定的路径下。

即使服务器挂载了多块磁盘,也无法有效利用这些存储空间。为了解决这个痛点,从 19.15 版本开始,MergeTree 实现了自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录。
而根据配置策略的不同,目前大致有三类存储策略。
- 默认策略:MergeTree 原本的存储策略,无需任何配置,所有分区会自动保存到 config.xml 配置中 path 指定的路径下。
- JBOD 策略:这种策略适合服务器挂载了多块磁盘,但没有做 RAID 的场景。JBOD 的全称是 Just a Bunch of Disks,它是一种轮询策略,每执行一次 INSERT 或者 MERGE,所产生的新分区会轮询写入各个磁盘。这种策略的效果类似于 RAID 0,可以降低单块磁盘的负载,在一定条件下能够增加数据并行读写的性能。如果单块磁盘发生故障,则会丢掉应用 JBOD 策略写入的这部分数据,但这又会造成数据丢失,因此我们还需要利用副本机制来保障数据的可靠性(副本机制后面说)。
- HOT/COLD 策略:这种策略适合服务器挂载了不同类型磁盘的场景,将存储磁盘分为 HOT 和 COLD 两类区域。HOT 区域使用 SSD 这类高性能存储媒介,注重存储性能;COLD 区域则使用 HDD 这类高容量存储媒介,注重存储经济性。数据在写入 MergeTree 之初,会在 HOT 区域创建分区目录用于保存数据,当分区数据大小累积到阈值时,数据会自动移动到 COLD 区域。而在每个区域的内部,也支持定义多个磁盘,所以在单个区域的写入过程中,也能应用 JBOD 策略。
存储配置需要预先定义在 config.xml 配置文件中,由 storage_configuration 表示,而 storage_configuration 之下又分为 disks 和 policies 两组标签,分别表示磁盘与存储策略。格式如下:
<storage_configuration>
<disks>
<disk_name_a> <!-- 自定义磁盘名称 -->
<path>/ch/data1</path>
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_name_a>
<disk_name_b> <!-- 自定义磁盘名称 -->
<path>/ch/data2</path>
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_name_b>
</disks>
<policies>
<policie_name_a> <!-- 自定义策略名称 -->
<volumes>
<volume_name_a> <!-- 自定义卷名称 -->
<disk>disk_name_a</disk>
<disk>disk_name_b</disk>
<max_data_part_size_bytes>disk_name_a</max_data_part_size_bytes>
</volume_name_a>
</volumes>
<move_factor>0.2</move_factor>
</policie_name_a>
<policie_name_b>
</policie_name_b>
</policies>
</storage_configuration>
解释一下里面标签的含义,首先是 disks 标签:
<disk_name_*>,必填项,必须全局唯一,表示磁盘的自定义名称,显然可以定义多块磁盘<path>,必填项,用于指定磁盘路径<keep_free_space_bytes>:选填项,以字节为单位,用于定义磁盘的预留空间
然后是 policies 标签,在 policies 标签里面需要引用已经定义的 disks 磁盘,并且同样支持定义多个策略:
<policie_name_*>,必填项,必须全局唯一,表示策略的自定义名称<volume_name_*>,必须填,比如全局唯一,表示卷的自定义名称<disk>,必填项,用于关联 <disks> 配置内的磁盘,可以声明多个 disk,MergeTree 会按照声明的顺序选择 disk<max_data_part_size_bytes>,选填项,以字节为单位,表示在这个卷的单个 disk 磁盘中,一个数据分区的最大分区阈值。如果当前分区的数据大小超过阈值,则之后的分区会写入下一个 disk 磁盘<move_factor>,选填项,默认为 0.1,如果当前卷的可用空间小于 factor 因子,并且定义了多个卷,则数据会自动向下一个卷移动
1. JBOD 策略演示
注意:storage_configuration 在 config.xml 里面是没有的,我们需要手动加进去。
<storage_configuration>
<disks>
<disk_hot1> <!-- 自定义磁盘名称 -->
<path>/root/hotdata1/</path>
</disk_hot1>
<disk_hot2> <!-- 自定义磁盘名称 -->
<path>/root/hotdata2/</path>
</disk_hot2>
<disk_cold> <!-- 自定义磁盘名称 -->
<path>/root/colddata/</path>
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_cold>
</disks>
<!-- 配置存储策略,在 volumes 卷下面引用上面定义的两块磁盘,组成磁盘组 -->
<policies>
<jbod_policies> <!-- 自定义策略名称 -->
<volumes>
<jbod> <!-- 自定义卷名称 -->
<disk>disk_hot1</disk>
<disk>disk_hot2</disk>
</jbod>
</volumes>
</jbod_policies>
</policies>
</storage_configuration>
至此一个支持 JBOD 的存储策略就配置好了,但在正式应用之前我们还需要做一些准备工作。首先我们要将目录创建好,然后将路径授权,让 ClickHouse 用户拥有相应的读写权限:
[root@satori ~]# mkdir hotdata1 hotdata2 colddata
[root@satori ~]# sudo chown clickhouse:clickhouse -R /root
由于存储配置不支持动态更新,为了使配置生效,还需要重启 ClickHouse 服务,直接 clickhouse restart 即可。重启之后可以查询系统表来验证配置是否生效:

通过 system.disks 系统表可以看到刚才声明的三块磁盘配置已经生效,接着验证配置策略:
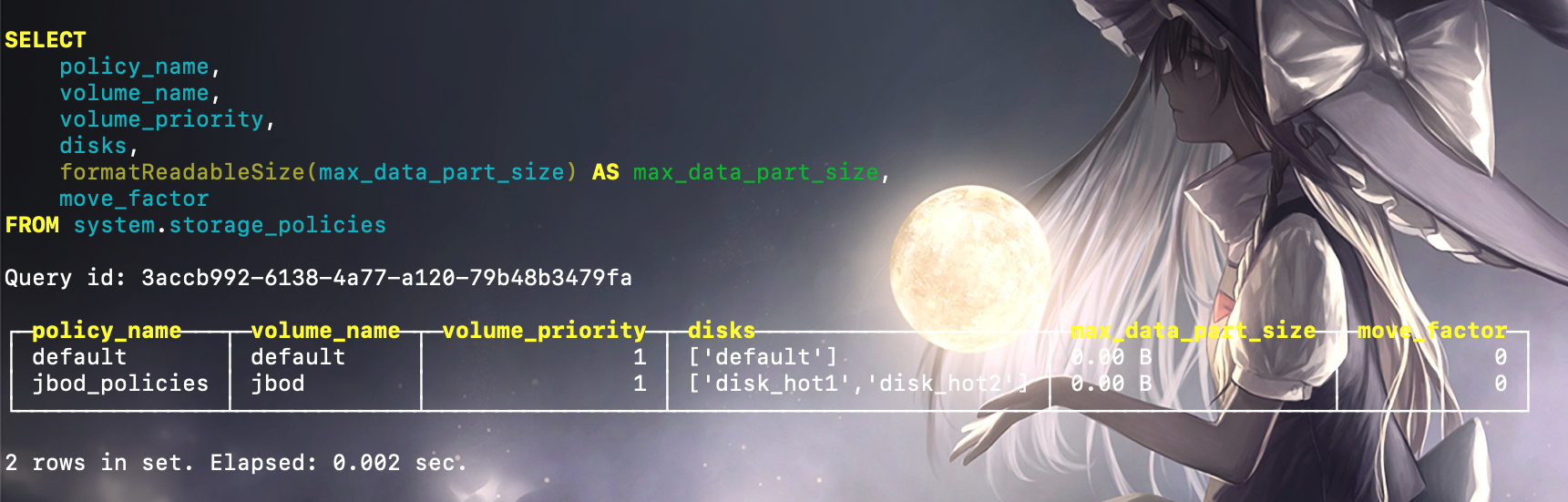
通过 system.storage_policies 系统表可以看到刚才配置的存储策略也已经生效了,现在创建一张 MergeTree 表,用于测试 jbod_policies 存储策略的效果。

在定义 MergeTree 数据表时,可以使用 storage_policy 配置项指定刚才的 jbod_policies 存储策略,注意:存储策略一旦设置,就不能再修改了。下面来测试一下效果:

可以看到第一块分区写入了第一块磁盘 disk_hot1,然后我们再来写入第二批数据,此时会创建第二个分区目录:
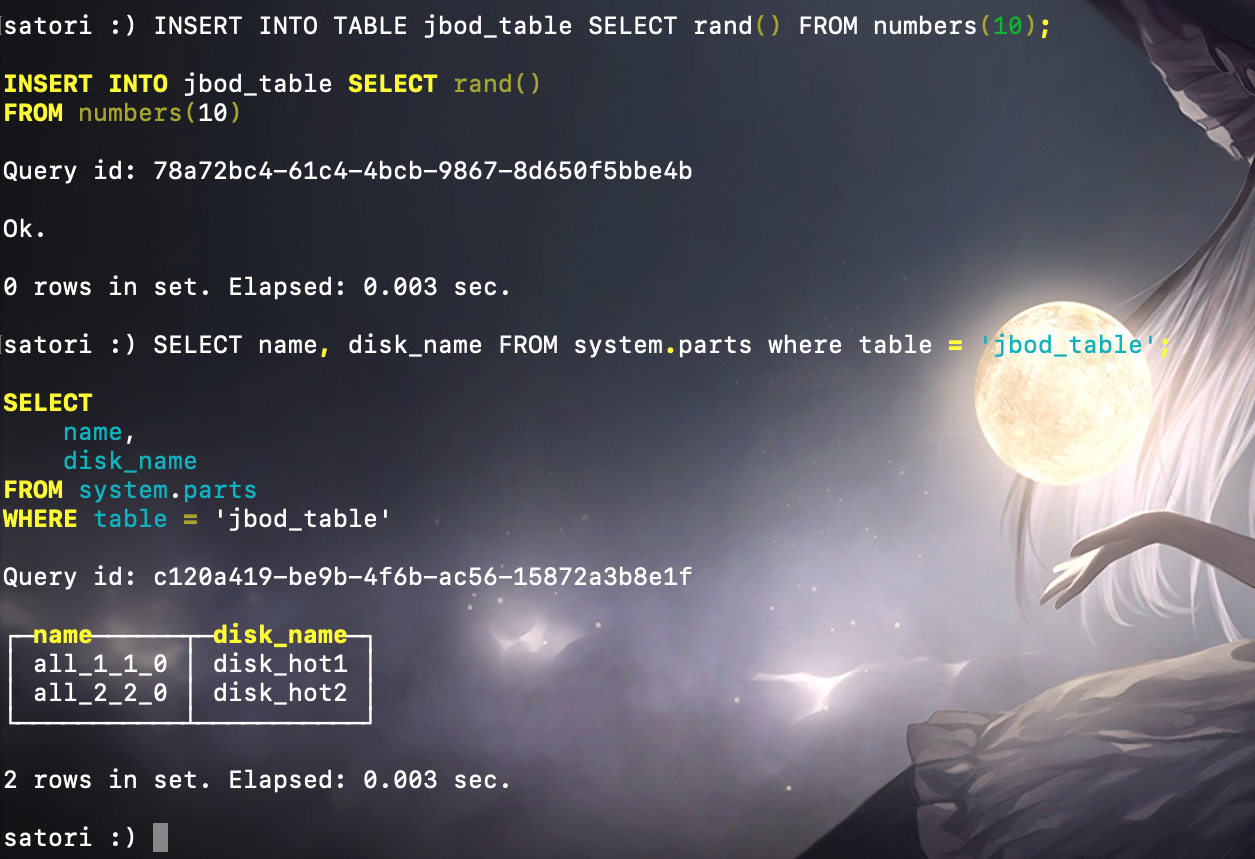
插入数据之后再次查看分区系统表,可以看到第二个分区写入了第二块磁盘。最后再触发一次分区合并动作,生成一个合并后的新分区目录:
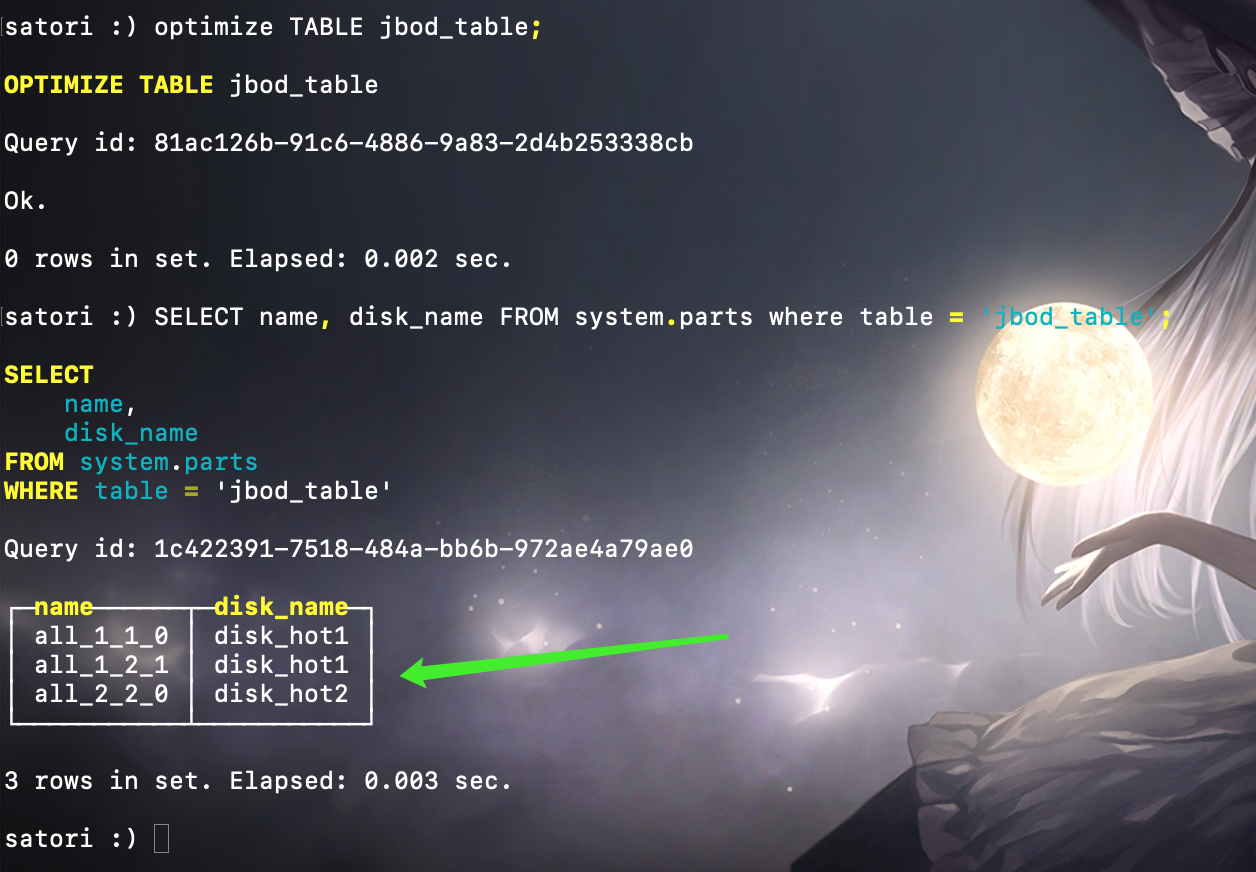
还是查询分区系统表,可以看到合并后生成的 all_1_2_1 分区再次写入了第一块磁盘 disk_hot1。
相信此时应该解释清除 JBOD 策略的工作方式了,在这个策略中,由多个磁盘组成一个磁盘组,即 volume 卷。每当生成一个新数据分区的时候,分区目录会依照 volume 卷中磁盘定义的顺序,依次轮询并写入各个磁盘。
2. HOT/COLD 策略演示
现在介绍 HOT/COLD 策略的使用方法,我们将 JBOD 策略对应的配置原封不动的拷贝过来,然后在里面加一个新策略。
<storage_configuration>
<disks>
<disk_hot1>
<path>/root/hotdata1/</path>
</disk_hot1>
<disk_hot2>
<path>/root/hotdata2/</path>
</disk_hot2>
<disk_cold>
<path>/root/colddata/</path>
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_cold>
</disks>
<policies>
<jbod_policies>
<volumes>
<jbod>
<disk>disk_hot1</disk>
<disk>disk_hot2</disk>
</jbod>
</volumes>
</jbod_policies>
<!-- 添加新策略 -->
<moving_from_hot_to_cold> <!-- 自定义策略名称 -->
<volumes>
<hot> <!-- 自定义名称,hot 区域磁盘 -->
<disk>disk_hot1</disk>
<max_data_part_size_bytes>1048576</max_data_part_size_bytes>
</hot>
<cold> <!-- 自定义名称,cold 区域磁盘 -->
<disk>disk_cold</disk>
</cold>
</volumes>
<move_factor>0.2</move_factor>
</moving_from_hot_to_cold>
</policies>
</storage_configuration>
用新配置将之前的 JBOD 配置给替换掉,或者直接将我们新加的部分添加到配置文件中即可,然后重启 ClickHouse。
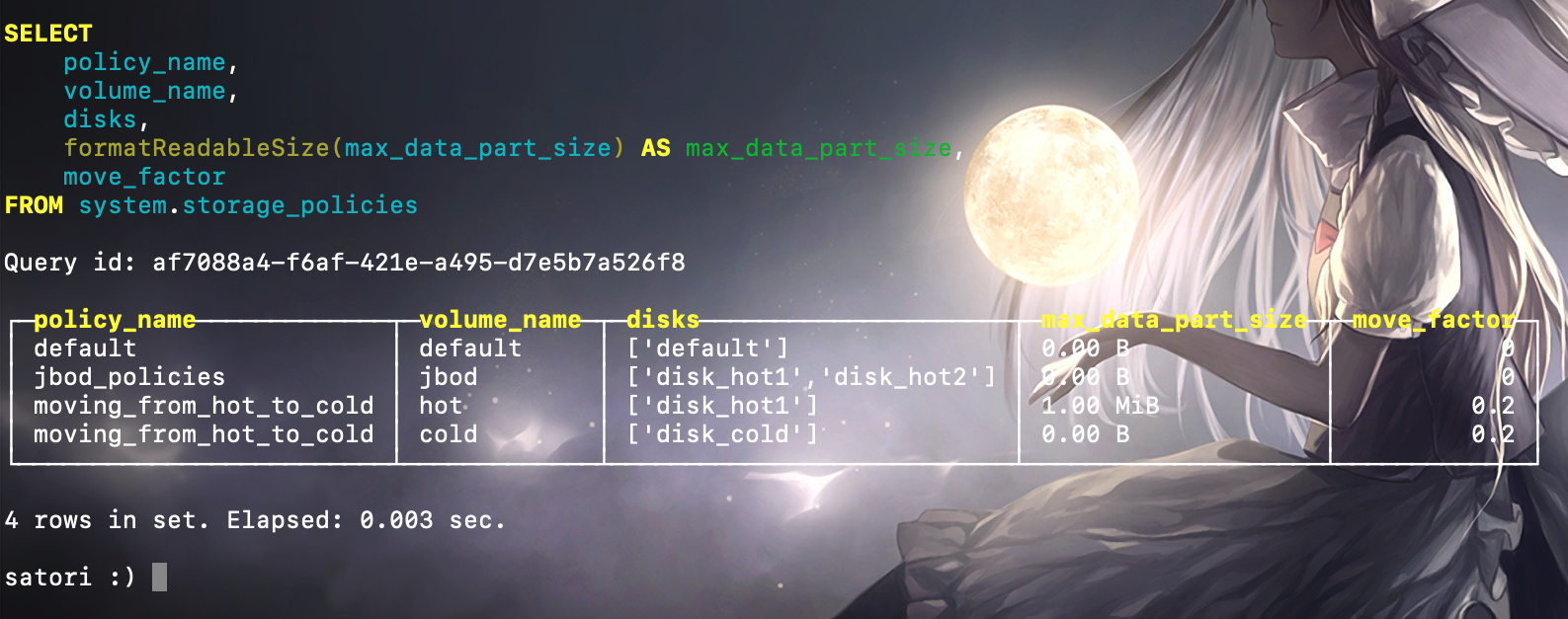
可以看到新配置的存储策略已经生效了,moving_from_hot_to_cold 存储策略拥有 hot 和 cold 两个磁盘卷,在每个卷下各拥有一块磁盘。注意:hot 磁盘卷的 max_data_part_size 列显示的值为 1MB,这个值的含义为,在这个磁盘卷下,如果一个分区的大小超过 1MB,则它需要被移动到紧邻的下一个磁盘。当然这里为了演示效果,实际工作中不会配置的这么小的。
那么下面还是创建一张 MergeTree 表,用于测试 moving_from_hot_to_cold 存储策略的效果。
CREATE TABLE hot_cold_table (id UInt64)
ENGINE = MergeTree()
ORDER BY id
SETTINGS storage_policy = 'moving_from_hot_to_cold'
在定义 MergeTree 时,使用 storage_policy 配置项指定刚才定义的存储策略,当然存储策略一旦定义就不能再修改了。那么接下来就来测试一下效果,首先写入第一批数据(小于 1MB),创建一个分区目录:
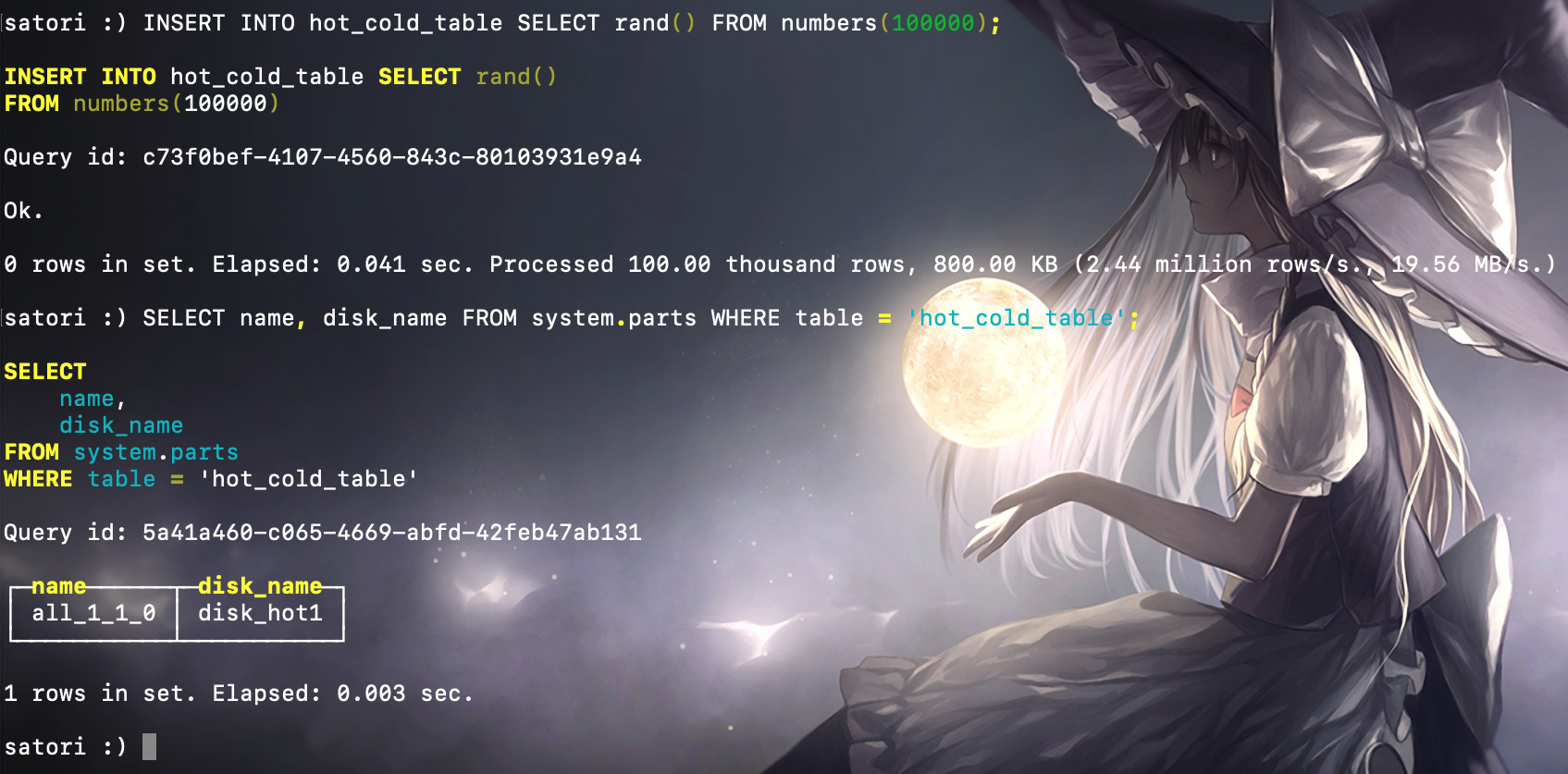
查询分区系统表,可以看到第一个分区写入了 hot 卷。那么下面就来写入第二批数据,数据大小和上次一样,当然此时会创建第二个分区目录:
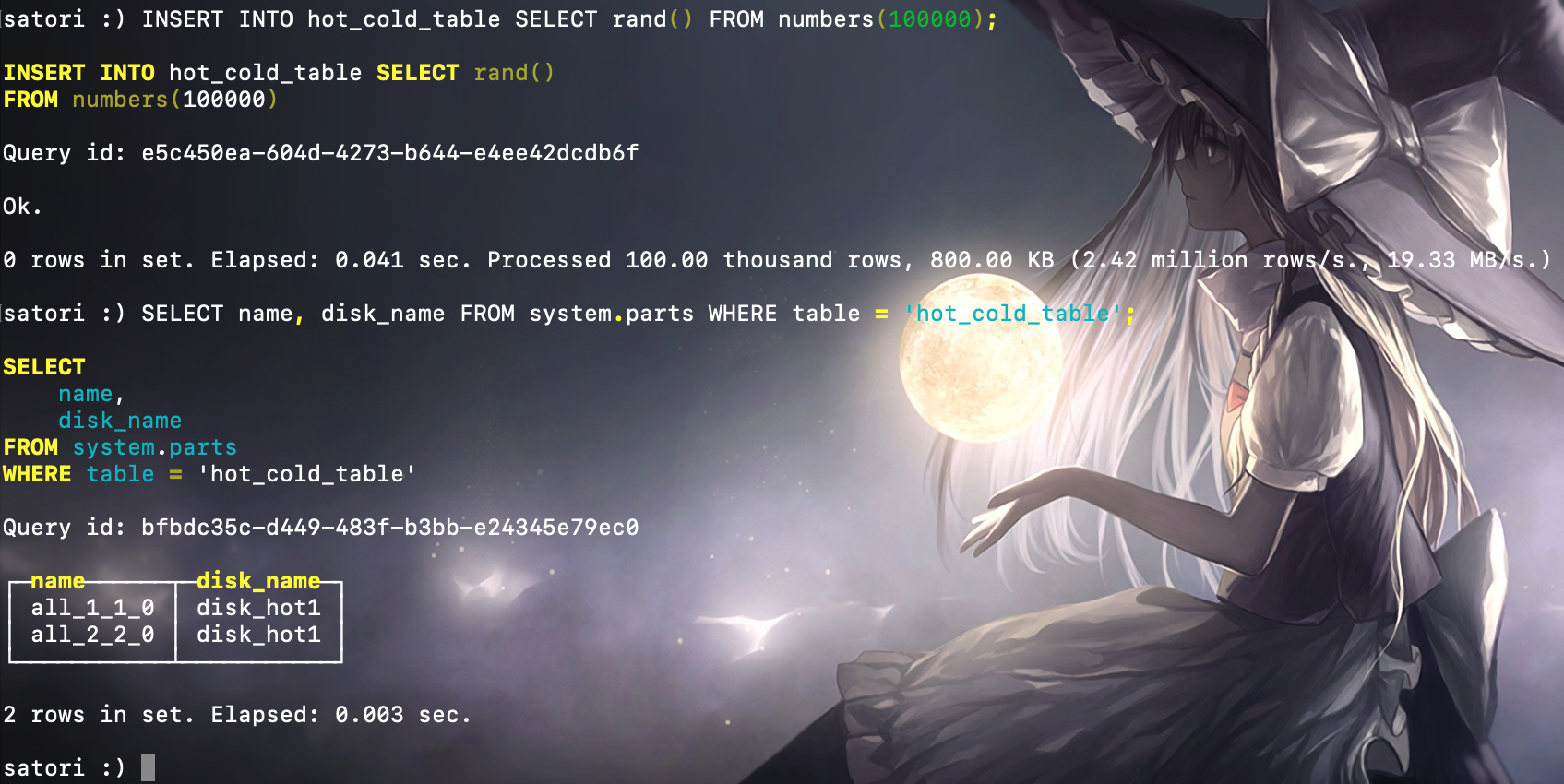
这是我们看到第二个分区仍然写入了 hot 卷,因为 hot 卷的 max_data_part_size 是 1MB,而每次写入数据的大小没有超过 1MB,所以自然都保存到了该磁盘下。那么接下来触发一次分区的合并动作,会生成一个新的分区目录。
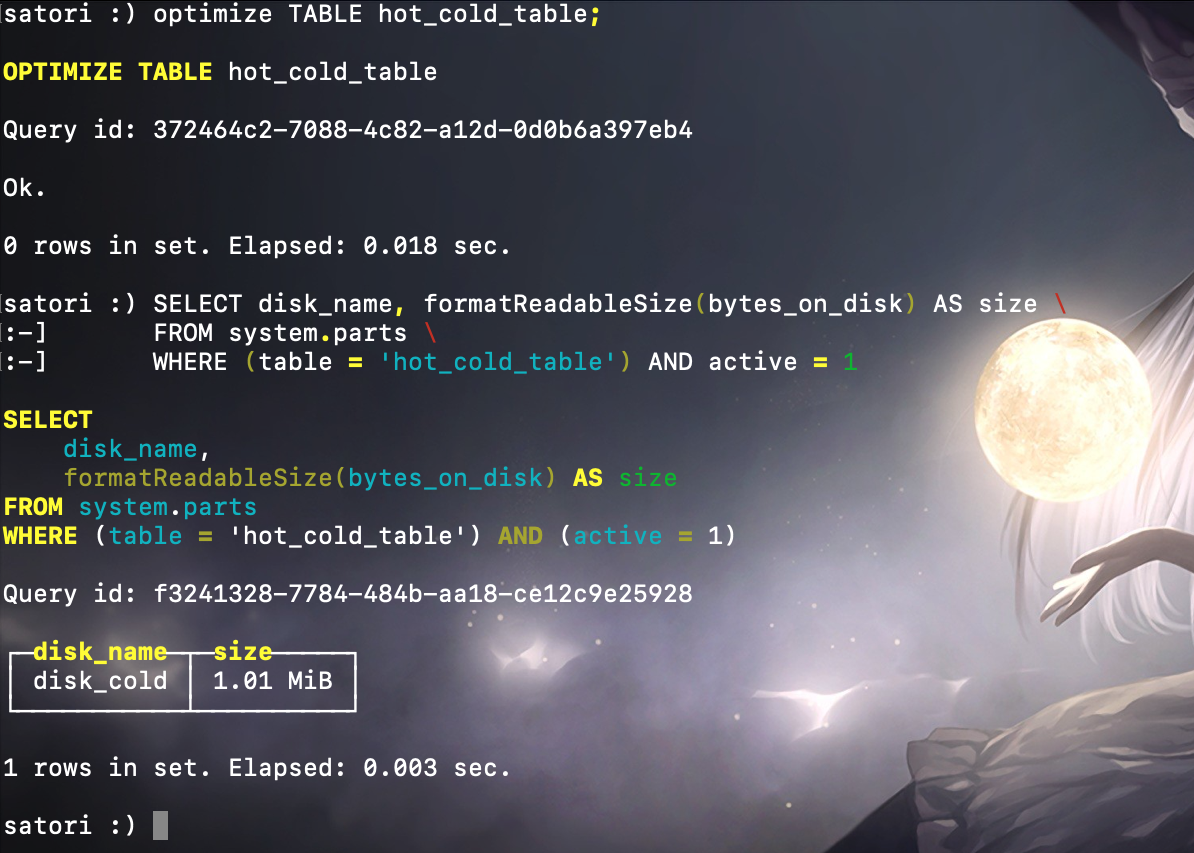
当两个分区合并之后,所创建的新分区的大小超过了 1MB,所以它会被写入 cold 卷。当然一次性写入大于 1MB 的数据,分区也会被写入 cold 卷。
至此我们算是明白了 HOT/COLD 策略的工作方式了,在这个策略中,由多个磁盘卷(volume 卷)组成一个 volume 组。每当生成一个新数据分区的时候,按照阈值大小(max_data_part_size),分区目录会依照 volume 组中磁盘定义的顺序,依次轮询并写入各个卷下的磁盘。
另外,虽然 MergeTree 的存储策略是不能修改的,但分区目录却支持移动,例如将某个分区移动至当前存储策略中 volume 卷下的其它 disk 磁盘:
ALTER TABLE hot_cold_table MOVE PART 'all_1_2_1' TO DISK 'disk_hot1'
或者将某个分区移动至当前存储策略中其它的 volume 卷:
ALTER TABLE hot_cold_table MOVE PART 'all_1_2_1' TO VOLUME 'cold'

ReplacingMergeTree
虽然 MergeTree 拥有主键,但是它的主键却没有唯一的约束,这意味着即便多行数据的主键相同,依旧能够正确写入。而在某些场合我们不希望数据表中有重复的数据,那么这个时候 ReplacingMergeTree 就登场了,它就是为数据去重而设计的,可以在合并分区时删除重复的数据。因此它的出现,确实在一定程度上解决了重复数据的问题,啊嘞嘞,为啥是一定程度?先卖个关子。
创建一张 ReplacingMergeTree 数据表的语法和创建普通 MergeTree 表别无二致,只需要将 ENGINE 换一下即可:
ENGINE = ReplacingMergeTree(ver)
里面的参数 ver 是选填的,可以指定一个整型、Date、DateTime 的字段作为版本号,这个参数决定了去除重复数据时所使用的算法。那么下面我们就来创建一张 ReplacingMergeTree 数据表:
CREATE TABLE replace_table (
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id, code)
PRIMARY KEY id
这里的 ORDER BY 是去除重复数据的关键,不是 PRIMARY KEY,ORDERR BY 声明的表达式是后续判断数据是否重复的依据。在这个栗子中,数据会基于 id 和 code 两个字段进行去重,我们写入几条数据:
INSERT INTO replace_table
VALUES ('A001', 'C1', '2020-11-10 15:00:00'),
('A001', 'C1', '2020-11-11 15:00:00'),
('A001', 'C100', '2020-11-12 15:00:00'),
('A001', 'C200', '2020-11-13 15:00:00'),
('A002', 'C2', '2020-11-14 15:00:00'),
('A003', 'C3', '2020-11-15 15:00:00')
我们插入了 6 条数据,但 create_time 为 2020-11-10 15:00:00、2020-11-11 15:00:00 的两条数据的 id 和 code 是重复的,因此会进行去重,只保留重复数据的最后一条,所以最终只会有 5 条数据。但需要注意的是,我们这 6 条数据是使用一个 INSERT 语句导入的,所以在导入的时候直接就去重了。
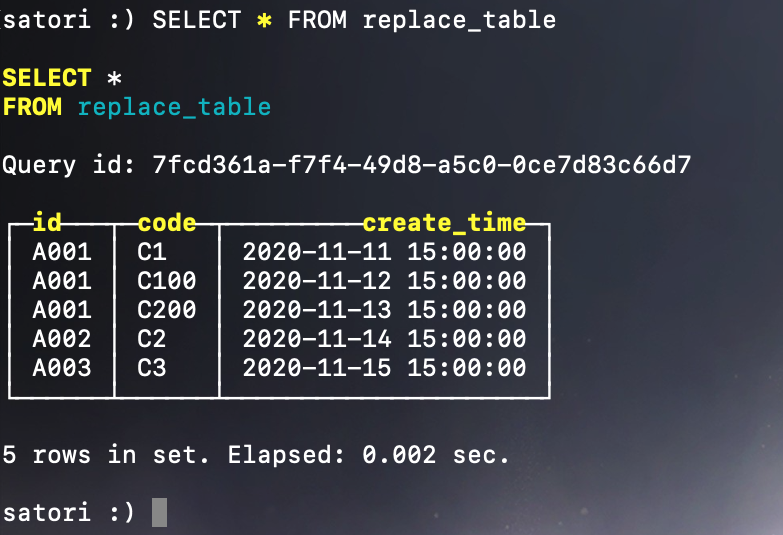
我们看到只保留了最后一条重复数据,因为使用的是一个 INSERT,所以这批数据会写入到同一个分区目录。如果是同一分区的不同分区目录(分多批导入),那么数据是不会去重的,只有在进行合并的时候才会进行去重。举个栗子,我们再写入几条数据:
INSERT INTO replace_table
VALUES ('A001', 'C1', '2020-11-03 15:00:00'),
('A001', 'C1', '2020-11-02 15:00:00')
显然这两条数据会写入新的分区目录,但它们的 id 和 code 也是重复的,因此会去进行去重,最终新生成的分区目录中只会有一条数据。
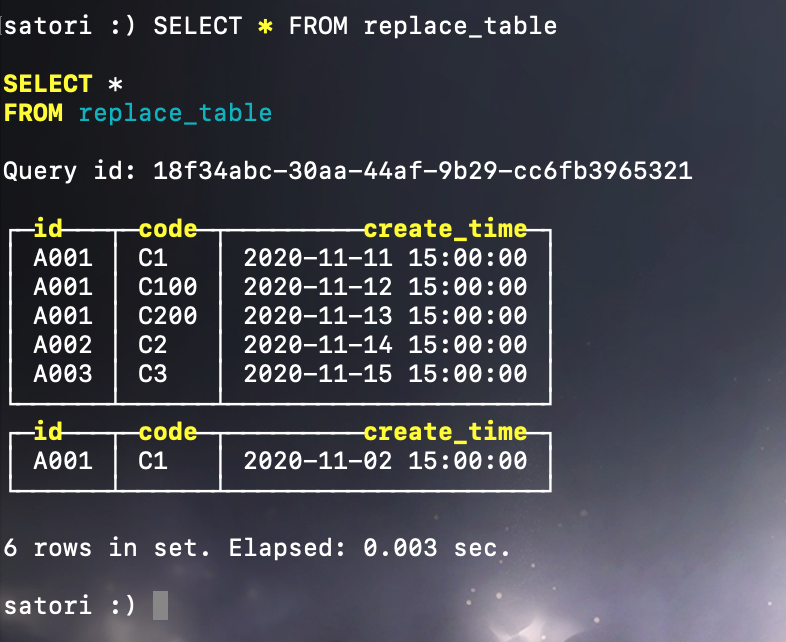
ClickHouse 的控制台做的还是很人性化的,不同分区目录的数据是分开显示的,当然我们在获取到的数据本身是连在一起的,只是 ClickHouse 的控制台方便你观察而分开显示了。我们看到第二个分区目录中只有一条数据,因为导入的两条数据的 id 和 code 是重复的,在写入同一个分区目录的时候会先对数据进行去重。但是不同分区目录的之间的数据是可以重复的,因为去重是以分区目录为单位的,而一个分区可以对应多个分区目录,所以上面出现了两个 A001、C1,因为它们位于不同的分区目录。只有当这些分区目录进行合并、生成新的分区目录时才会进行去重。
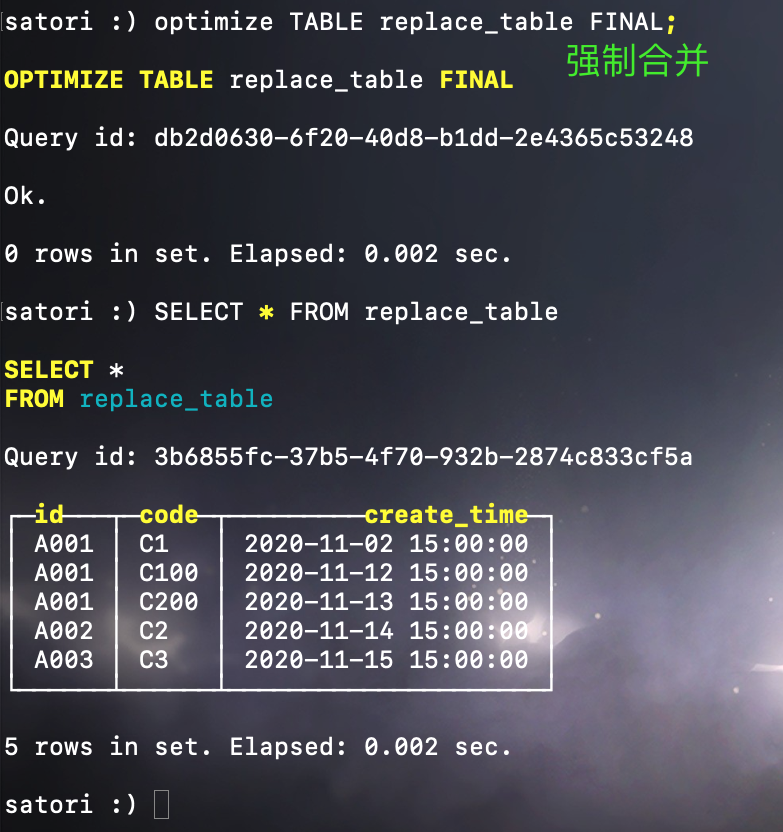
当不同分区目录的数据进行合并时,数据再次进行了去重,会保留后创建的分区目录中的数据,因此 create_time 为 2020-11-02 15:00:00 的数据保留了下来。并且我们也可以看到,ReplacingMergeTree 在去除重复数据时,确实是以排序键为单位的。如果以主键去重的话,那么就不会有 3 条 A001 了。
所以暂时可以得出如下结论:
1. 去重是以排序键为准2. 当数据写入同一个分区目录时,会直接对重复数据进行去重,并且保留的是最后一条3. 同一分区、但位于不同分区目录的数据不会进行去重,只有在合并成新的分区目录时才会进行去重,并且保留的是最后一个分区的数据
不过问题来了,要是不同分区的数据会不会去重呢?其实在开头我们就已经埋下伏笔了,因为我们在开头说了 ReplacingMergeTree 是在一定程度上解决了数据重复的问题,所以不同分区的数据重复它是无法解决的。
我们上面所有的数据都位于 2020-11 这个分区中,那么下面再插入一条数据、创建一个新的分区:
INSERT INTO replace_table VALUES ('A001', 'C1', '2010-11-17 15:00:00')
我们将 2020 改成 2010,然后测试一下:

因此不同分区的数据是无法进行去重的,这也算是 ReplacingMergeTree 的一个局限性。当然说局限性感觉也不是很合适,因为分区的目的就是为了减小查询时的数据量,如果往一个分区导入数据还要在乎其它分区、看数据是否在其它分区中已出现,那这不就相当于丧失了分区的意义了吗?
但是问题来了,这里不同分区的数据先不考虑,因为它无法去重,我们再谈一下同一个分区中数据去重的逻辑。我们说当数据重复时会保留最后一条,但有时我们希望某个字段的值最大的那一条保留下来,这时该怎么做呢?还记得我们之前说在指定 ReplacingMergeTree 的时候可以指定参数吗?
DROP TABLE replace_table;
CREATE TABLE replace_table (
id String,
code String,
create_time DateTime
-- 指定参数,以后去重的时候会保留 create_time 最大的那一条数据
) ENGINE = ReplacingMergeTree(create_time)
PARTITION BY toYYYYMM(create_time)
ORDER BY (id, code)
PRIMARY KEY id
然后插入几条数据:
INSERT INTO replace_table
VALUES ('A001', 'C1', '2020-11-10 15:00:00'),
('A001', 'C1', '2020-11-21 15:00:00'),
('A001', 'C1', '2020-11-11 15:00:00')
显示此时会保留 create_time 为 2020-11-21 15:00:00 的记录,因为的值最大,我们测试一下:
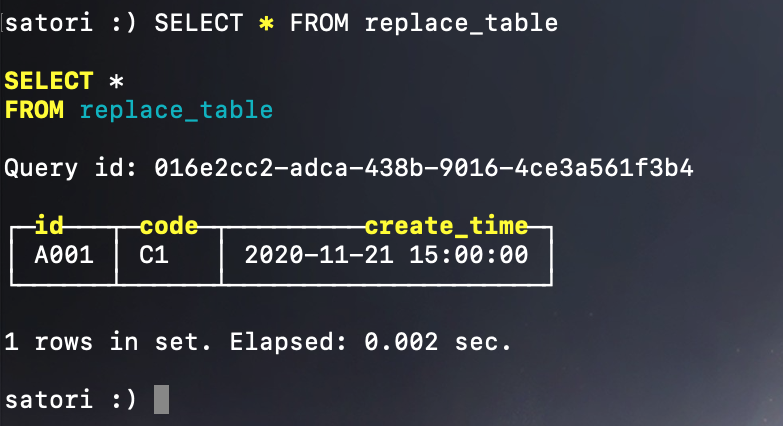
然后再插入两条记录:
INSERT INTO replace_table
VALUES ('A001', 'C1', '2020-11-28 15:00:00');
INSERT INTO replace_table
VALUES ('A001', 'C1', '2020-11-27 15:00:00');
注意:我们要分两批导入,然后进行合并,显然 2020-11-28 15:00:00 这条会保留下来,而不是最后一个分区目录中数据。

所以最后再总结一下 ReplacingMergeTree 的使用逻辑:
1. 使用 ORDER BY 排序键作为判断数据重复的唯一键2. 当导入同一分区目录时,会直接进行去重3. 当导入不同分区目录时,不会进行去重,只有当分区目录合并时,属于同一分区内的重复数据才会去重;但是不同分区内的重复数据不会被删除4. 在进行数据去重时,因为分区内的数据已经是基于 ORDER BY 排好序的,所以能很容易地找到那些相邻的重复的数据5. 数据去重策略有两种:如果没有设置 ver 版本号,则保留同一组重复数据中的最后一条;如果设置了 ver 版本号,则保留同一组重复数据中 ver 字段取值最大的那一行
SummingMergeTree
假设有这样一种查询需求,终端用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的(GROUP BY 条件明确,且不会随意改变)。对于这样的查询场景,ClickHouse 要如何解决呢?
最直接的方案就是使用 MergeTree 存储数据,然后通过 GROUP BY 聚合查询,并利用 SUM 函数汇总结果。这种方案本身完全行的通,但是有两个不完美之处:
存在额外的存储开销:终端用户不会查询任何明细数据,只关心汇总结果,所以不应该一直保存所有的明细数据存在额外的查询开销:终端用户只关心汇总结果,虽然 MergeTree 性能强大,但是每次查询都进行实时聚合计算也是一种性能消耗
而 SummingMergeTree 就是为了应对这类查询场景而生的,顾名思义它能够在合并分区的时候按照预先定义的的条件汇总数据,将同一分组下的多行数据汇总成一行,这样既减少了数据行,又降低了后续汇总查询的开销。
在之前我们说过,MergeTree 的每个分区内,数据都会按照 ORDER BY 表达式排好序,主键索引都会按照 PRIMARY KEY 取值并排好序。而默认情况下 ORDER BY 可以代指 PRIMARY KEY,所以一般情况下我们只需要声明 ORDER BY 即可。但如果需要同时定义 ORDER BY 和 PRIMARY KEY,通常只有一种可能,那就是明确希望 ORDER BY 和 PRIMARY KEY 不同,而这种情况只会在使用 SummingMergeTree 和 AggregatingMergeTree 时才会出现,因为这两者的聚合都是根据 ORDER BY 进行的。
假设有一张 SummingMergeTree 数据表,里面有 A、B、C、D、E、F 六个字段,如果需要按照 A、B、C、D 汇总,那么在创建表结构的时候需要指定:
ORDER BY (A, B, C, D)
但是这样主键也被定义成了 A、B、C、D,而在业务层面其实只需要对业务字段 A 进行查询过滤,所以应该只使用 A 字段创建主键。所以我们应该这么定义:
ORDER BY (A, B, C, D)
PRIMARY KEY A
但如果同时声明了 ORDER BY 和 PRIMARY KEY,那么 MergeTree 会强制要求 PRIMARY KEY 必须是 ORDER BY 的前缀,所以:
-- 不行
ORDER BY (B, C)
PRIMARY KEY A
-- 行
ORDER BY (B, C)
PRIMARY KEY B
这种强制约束保障了即便在定义不同的情况下,主键仍然是排序键的前缀,不会出现索引与数据顺序混乱的问题。假设现在业务发生了细微的变化,需要减少字段,将先前的 A、B、C、D 改为按照 A、B 汇总,则可按照如下方式修改排序键:
ALTER TABLE table_name MODIFY ORDER BY (A, B)
但是需要注意,如果减少字段的话,只能从右往左减少。怎么理解呢?我们之前是按照 A、B、C、D 进行的汇总,那么减少字段的话,最终可以按照 A、B、C 汇总、可以按照 A、B 汇总、可以按照 A 汇总,但是不能按照 A、C 或者 A、D、或者 A、C、D 等等进行汇总。所以减少字段一定是从右往左依次减少,不能出现跳跃。
除此之外,ORDER BY 只能在现有字段的基础上减少字段,如果新增字段,则只能添加通过 ALTER ADD COLUMN 新增的字段。但 ALTER 是一种元数据级别的操作,修改成本很低,相比不能修改的主键,已经非常便利了。
那么介绍 SummingMergeTree 数据表的创建方式,显然都已经猜到了,因为 MergeTree 家族的表引擎创建方式都是类似的,只不过引擎不同罢了。
ENGINE = SummingMergeTree((col1, col2, col3, ...))
其中 col1、col2 为 columns 参数值,这是一个选填参数,用于设置除主键外的其它数值类型字段,以指定被 SUM 汇总的列字段。如果不填写此参数,则会将所有非主键的数值类型字段进行汇总,下面就来创建一张 SummingMergeTree 表:
CREATE TABLE summing_table (
id String,
city String,
v1 UInt32,
v2 Float64,
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
PRIMARY KEY id
ORDER BY (id, city)
接下来插入几条数据:
INSERT INTO summing_table
VALUES ('A001', 'beijing', 10, 20.1, '2020-05-10 17:00:00'),
('A001', 'beijing', 20, 30.2, '2020-05-20 17:00:00'),
('A001', 'shanghai', 20, 30, '2020-05-10 17:00:00');
INSERT INTO summing_table
VALUES ('A001', 'beijing', 10, 20, '2020-05-01 17:00:00');
INSERT INTO summing_table
VALUES ('A001', 'beijing', 60, 50, '2020-10-10 17:00:00');
显然此时会创建三个分区目录,202005_1_\1_0、202005_2_\2_0、202010_1_\1_0。另外 SummingMergeTree 和 ReplacingMergeTree 类似,如果导入同一分区目录的数据有重复的,那么直接就聚合了,不同分区目录则不会聚合,而是在合并生成新分区目录的时候,再对属于同一分区的多个分区目录里的数据进行聚合。
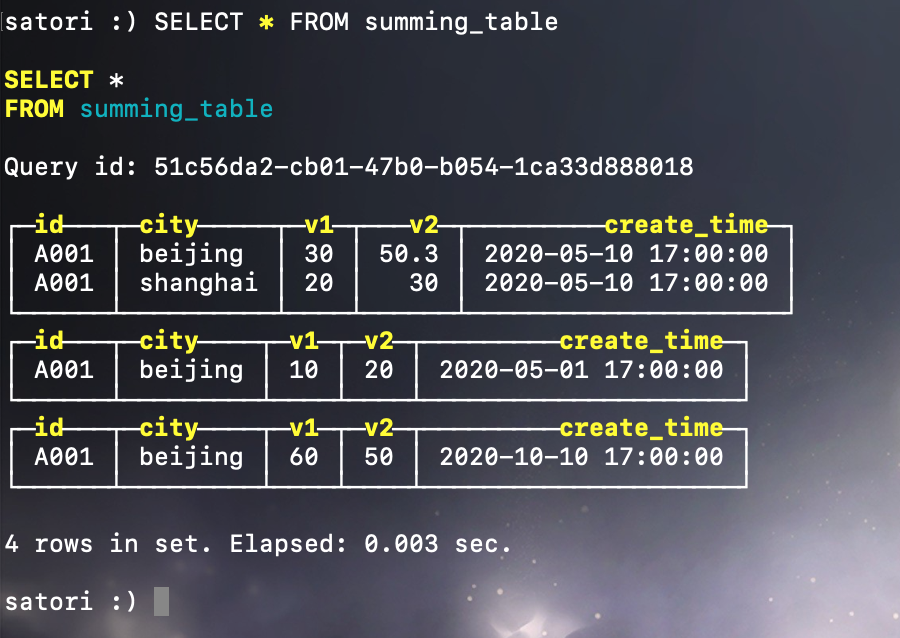
我们看到第一个分区目录中的三条数据聚合成了两条,然后手动触发合并动作:
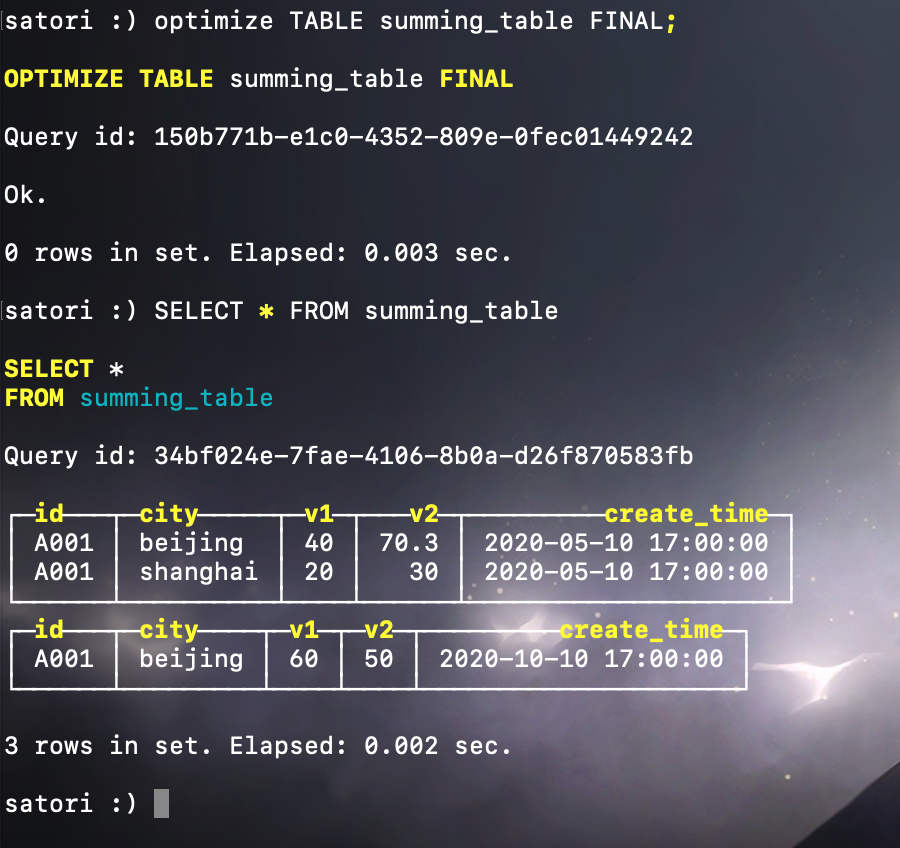
不同分区目录(属于同一分区)里的数据聚合在一起了,至于不在汇总字段之列的 create_time 则取了同组内第一行数据的值;而不同分区对应的分区目录就不会被聚合了,因为不在同一个分区内。
另外 SummingMergeTree 也支持嵌套类型的字段,在使用嵌套类型字段时,需要被 SUM 汇总的字段必须以以 Map 后缀结尾,例如:
CREATE TABLE summing_table_nested (
id String,
nestMap Nested (
id UInt32,
key UInt32,
val UInt64
),
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id
在使用嵌套数据类型时,默认会以嵌套类型中第一个字段作为聚合条件 Key,写入测试数据:
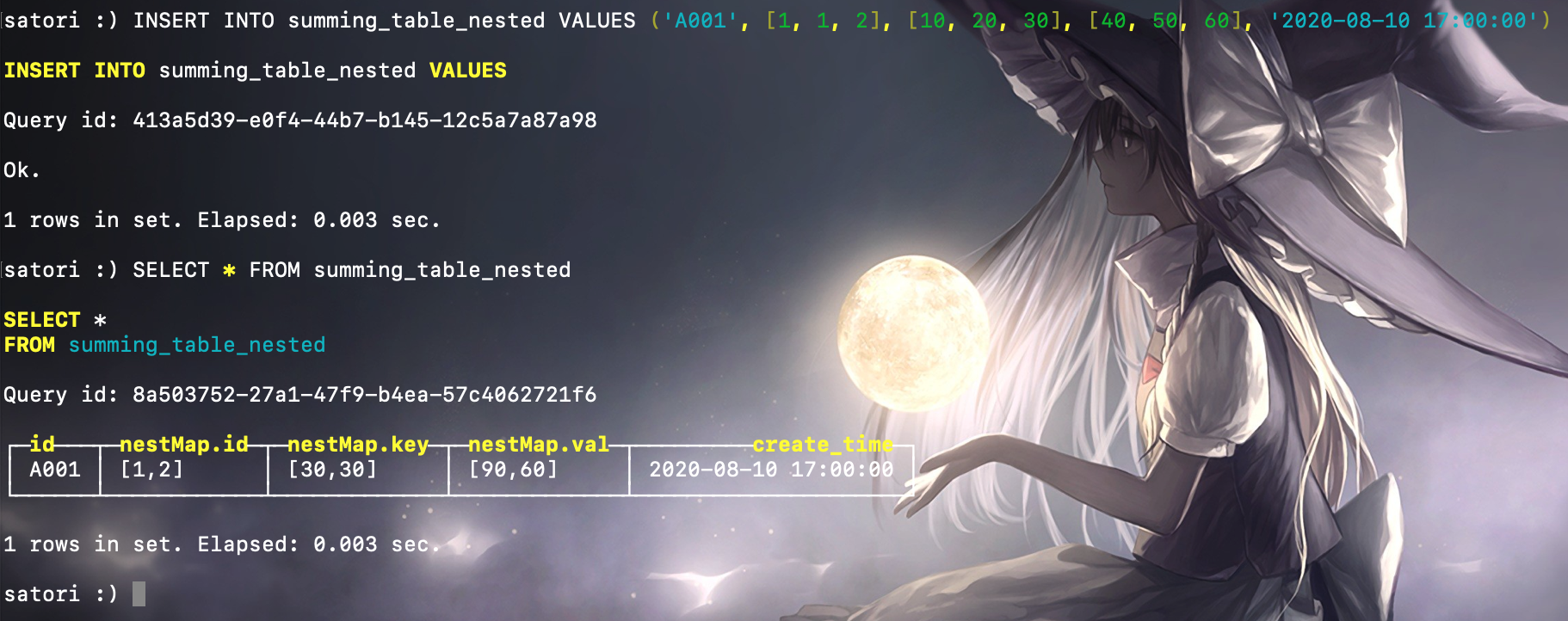
我们看到写入的时候就聚合了,并且按照 nestMap 里面的 id 聚合的,之前我们说过:嵌套类型本质是一种多维数组的结构,里面的每个字段都是一个数组,并且长度要相等。
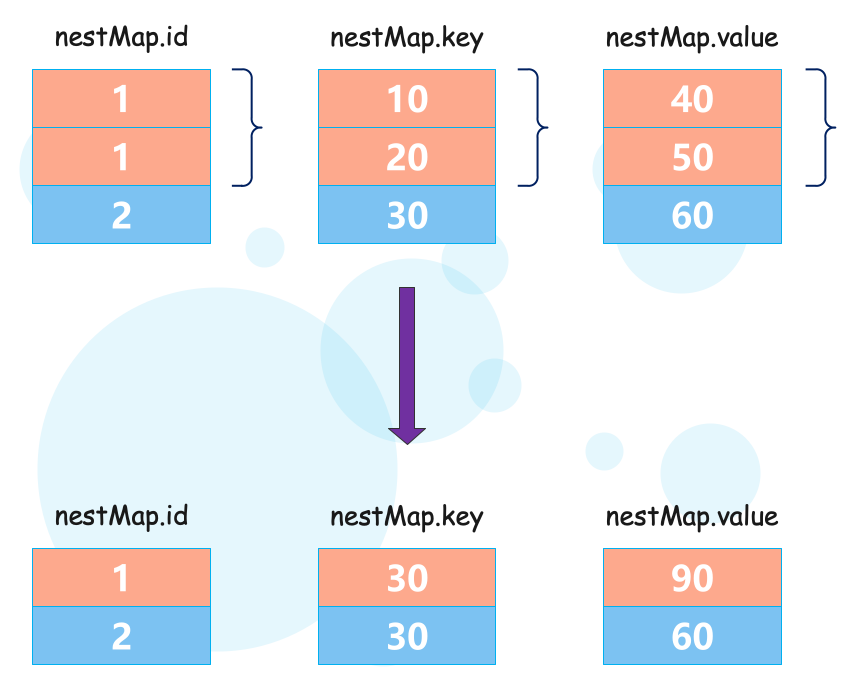
然后我们再写一条数据:
INSERT INTO summing_table_nested VALUES ('A001', [2], [300], [600], '2020-08-10 17:00:00')
显然此时会新创建一个分区目录,然后我们手动触发合并:
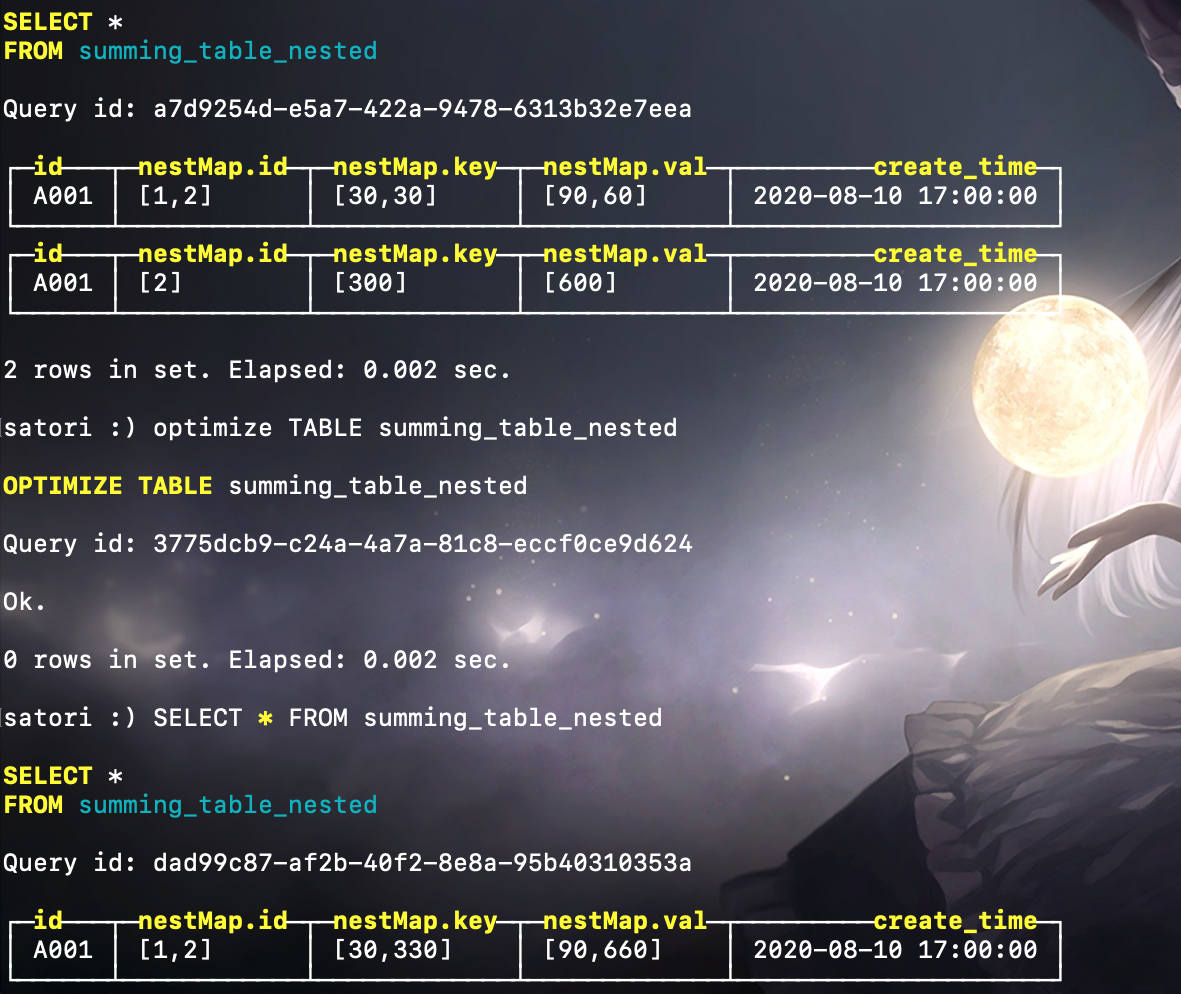
合并的结果显然符合我们的预期,当然如果分区不同,那么就无法合并了。
当然我们上面默认是按 id 进行聚合的,或者说是按嵌套类型中的第一个字段进行聚合,但 ClickHouse 也支持使用复合字段(Key)作为数据聚合的条件。为了使用复合 Key,在嵌套类型的字段中,除了第一个字段以外,任何名称是以 Key、Id 或者 Type 结尾的字段,都将和第一个字段一起组成复合 Key。例如我们将上面的建表逻辑改一下,将小写 key 改成大写 Key:
CREATE TABLE summing_table_nested (
id String,
nestMap Nested (
id UInt32,
Key UInt32, -- 大写 Key
val UInt64
),
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id
该栗子中会以 id 和 Key 作为聚合条件,因此以上就是 SummingMergeTree,我们再来总结一下它的处理逻辑:
只有 ORDER BY 排序键作为聚合数据的条件 Key写入同一分区目录的数据会聚合之后在写入,而属于同一分区的不同分区目录的数据,则会在合并触发时进行汇总不同分区的数据不会汇总到一起如果在定义引擎时指定了 columns 汇总列(非主键的数值类型字段),则 SUM 会汇总这些列字段;如果未指定,则聚合所有非主键的数值类型字段在进行数据汇总时,因为分区内的数据已经基于 ORDER BY 进行排序,所以很容易找到相邻也拥有相同 Key 的数据在汇总数据时,同一分区内相同聚合 key 的多行数据会合并成一行,其中汇总字段会进行 SUM 计算;对于那些非汇总字段,则会使用第一行数据的取值支持嵌套结构,但列字段名称必须以 Map 后缀结尾,并且默认以第一个字段作为聚合 Key。并且除了第一个字段以外,任何名称以 key、Id 或者 Type 为后缀结尾的字段都会和第一个字段组成复合 Key
AggregatingMergeTree
有过数仓建设经验的你一定知道数据立方体的概念,这是一个在数仓领域十分常见的模型,它通过以空间换时间的方式提升查询性能,将需要聚合的数据预先计算出来(预聚合)并保存,在后续需要聚合查询到的时候,直接使用保存好的结果数据。
Kylin 就是一个典型的使用预聚合的数据仓库,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据。它的核心逻辑就是在数据集上定义一个星形模型或者雪花模型,然后基于模型搭建数据立方体(cube)并将结果存储在 HBase 中,最后使用标准 SQL 以及其它 API 进行查询,由于数据已经提前计算好,所以仅需亚秒级响应时间即可获得查询结果。
AggregatingMergeTree 就有些数据立方体的意思,它能够在合并分区的时候按照预先定义的条件聚合数据。同时,根据预先定义的聚合函数计算数据并通过二进制的格式存入表内。通过将同一分组下的多行数据预先聚合成一行,既减少了数据行,又降低了后续聚合查询的开销。可以说 AggregatingMergeTree 是 SummingMergeTree 的升级版,它们的许多设计思路和特性是一致的,例如同时定义 ORDER BY 和 PRIMARY KEY 的原因和目的。但是在用法上两者存在明显差异,应该说 AggregatingMergeTree 的定义方式是 MergeTree 家族中最为特殊的一个。声明使用 AggregatingMergeTree 的方式如下:
ENGINE = AggregatingMergeTree()
AggregatingMergeTree 没有任何额外的设置参数,在分区合并时,在每个数据分区内,会按照 ORDER BY 聚合。而使用何种聚合函数,以及针对哪些列字段进行计算,则是通过定义 AggregateFunction 数据类型实现的。以下面的语句为例:
CREATE TABLE agg_table (
id String,
city String,
code AggregateFunction(uniq, String),
value AggregateFunction(sum, UInt32),
create_time DateTime
) ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id, city)
PRIMARY KEY id
上述的 id 和 city 是聚合条件,等同于在 SQL 语句中指定 GROUP BY id, city;而 code 和 value 聚合字段,其语义等同于 uniq(code)、sum(value)。
AggregateFunction 是 ClickHouse 提供的一种特殊的数据结构,它能够以二进制的形式存储中间状态结果。其使用方法也十分特殊,对于 AggregateFunction 类型的列字段,数据的查询和写入都与众不同。在写入数据时需要调用 *State 函数,查询数据时则调用相应的 *Merge 函数。其中 * 表示定义时使用的聚合函数,例如上面的建表语句中使用了 uniq 和 sum 函数。
那么在写入数据时,需要调用对应的 uniqState 和 sumState 函数,并使用 INSERT SELECT 语法:
INSERT INTO agg_table
SELECT ('A000', 'beijing', uniqState('code1'), sumState(toUInt32(100)), '2020-08-10 17:00:00'),
('A000', 'beijing', uniqState('code1'), sumState(toUInt32(100)), '2020-08-10 17:00:00')
而在查询数据时,如果使用列名 code、value 进行访问的话,虽然也能查询到数据,只不过显示的是无法阅读的二进制,我们需要调用对应的 uniqMerge 和 sumState 函数。
SELECT id, city, uniqMerge(code), sumMerge(value)
FROM agg_table
-- 在 SQL 语句中聚合语句肯定要用 GROUP BY
-- 但在定义表结构的时候,聚合字段是使用 ORDER BY 表示的,当然它指定的也是排序字段
GROUP BY id, city
下面来测试一下:
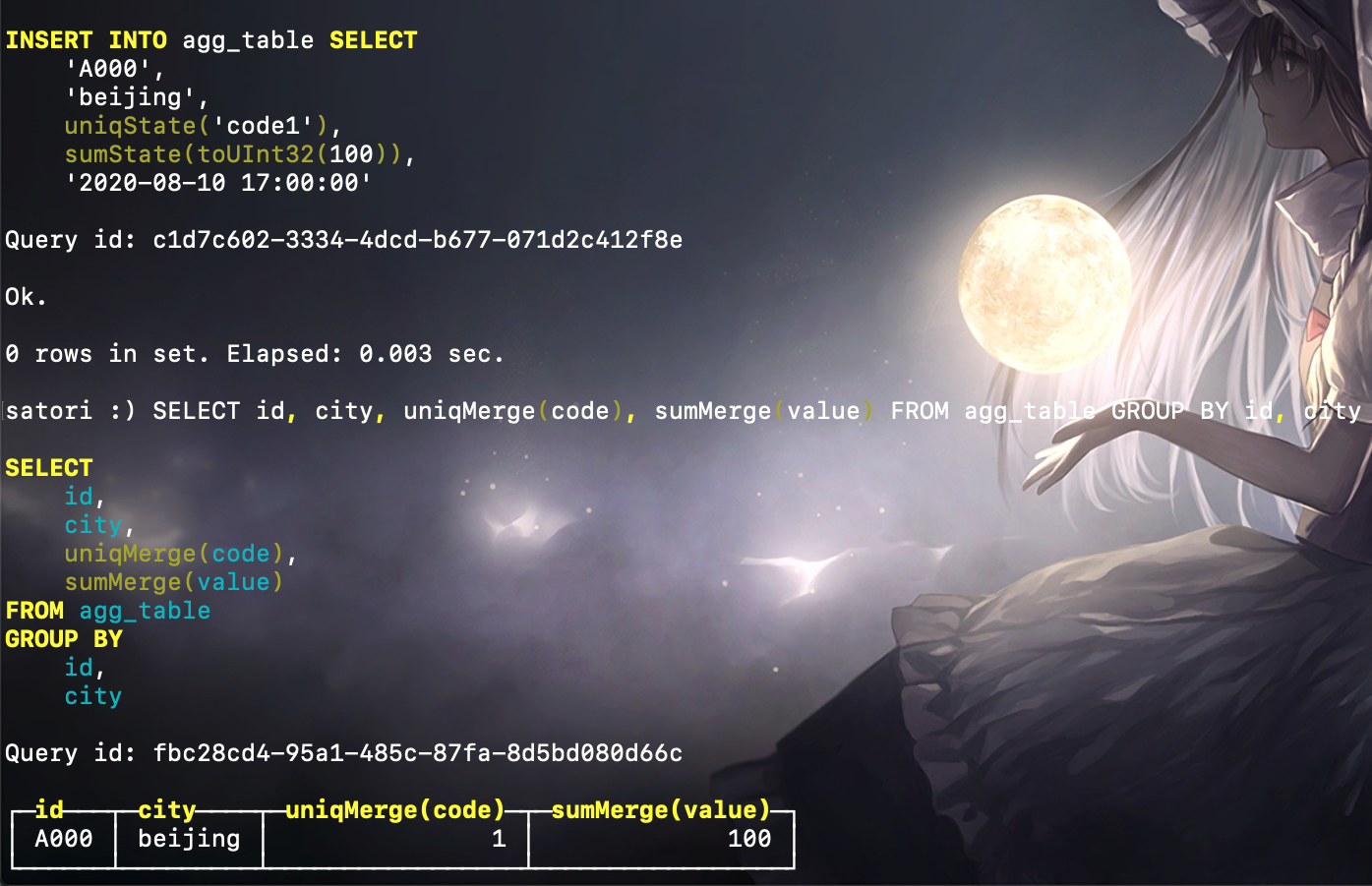
看到这里你可能觉得 AggregatingMergeTree 使用起来有些过去繁琐了,连正常数据写入还要借助 INSERT SELECT、并且调用特殊函数才能实现,没错,如果是上面这种做法的话,确实有些麻烦了。不过无须担心,当前这种用法并不是主流用法。
AggregatingMergeTree 的主流用法是结合物化视图使用,将它作为物化视图的表引擎,这里的物化视图是作为其它数据表上层的一种查询视图。
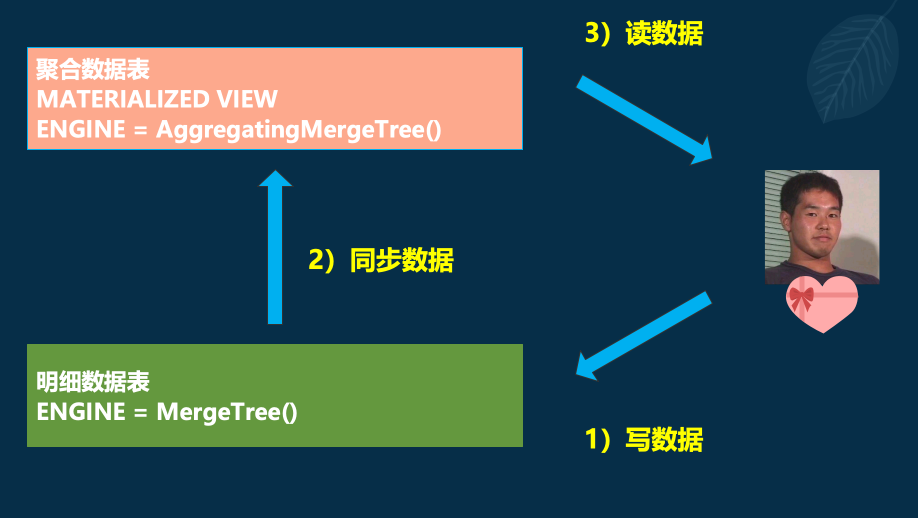
接下来用一组示例进行说明,首先创建明细数据表,也就是俗称的底表:
CREATE TABLE agg_table_basic (
id String,
city String,
code String,
value UInt32
) ENGINE = MergeTree()
PARTITION BY city
ORDER BY (id, city)
通常使用 MergeTree 作为底表,用于存储全量的明细数据,并以此对外提供实时查询。接着,创建一张物化视图:
CREATE MATERIALIZED VIEW agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY city
ORDER BY (id, city)
AS SELECT
id, city,
uniqState(code) AS code,
sumState(value) AS value
FROM agg_table_basic
GROUP BY id, city
物化视图使用 AggregatingMergeTree 表引擎,用于特定场景的数据查询,相比 MergeTree,它拥有更高的性能。但在新增数据时,面向的对象是底表 MergeTree:
INSERT INTO agg_table_basic
VALUES ('A000', 'beijing', 'code1', 100),
('A000', 'beijing', 'code2', 200),
('A000', 'shanghai', 'code1', 200)
数据会自动同步到物化视图,并按照 AggregatingMergeTree 的引擎的规则进行处理。而在查询数据时,面向的对象是物化视图 AggregatingMergeTree:
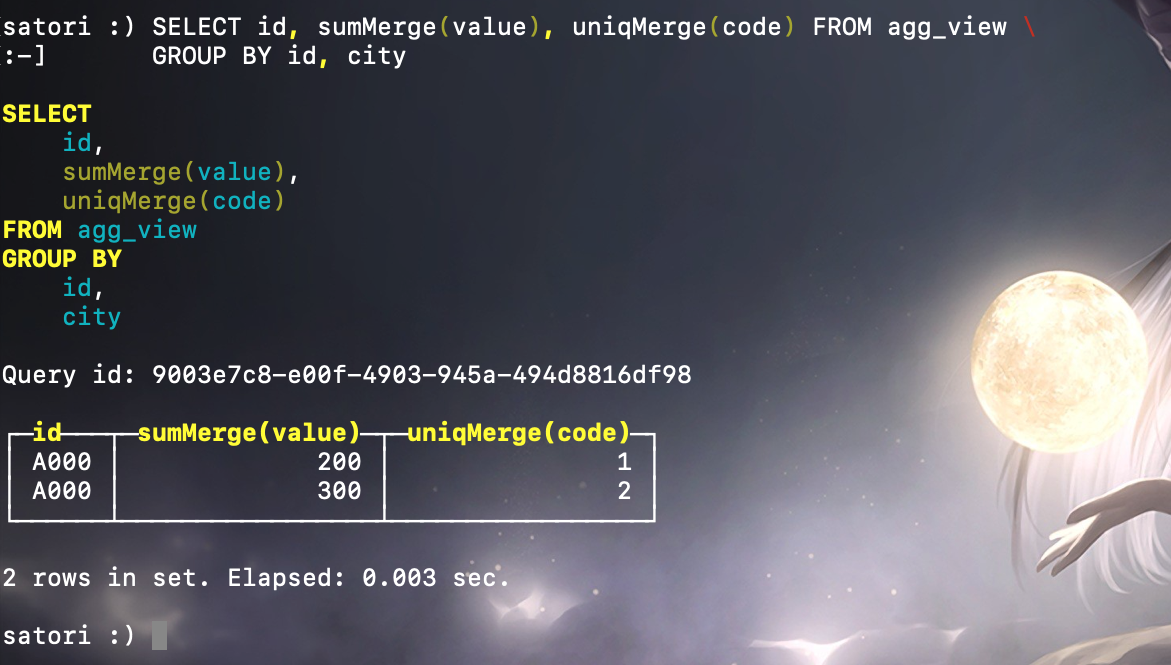
以上就是 AggregatingMergeTree 的整个流程,最常见的用法是作为普通物化视图的表引擎,和普通 MergeTree 数据表搭配使用。
CollapsingMergeTree
假设现在需要设计一款数据库,该数据库支持需要支持对已经存在的数据实现行级粒度的修改和删除,你会怎么设计呢?一种最常见的想法是:首先找到保存数据的文件,接着修改这个文件,比如修改或删除那些需要变化的数据行。然而在大数据领域,对于 ClickHouse 这类高性能分析数据库而言,对数据源文件进行修改是一件非常奢侈且代价昂贵的操作。相较于直接修改源文件,将修改和删除操作转换为新增操作会更合适一些,也就是以增代删。
CollapsingMergeTree 就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个 sign 标记位字段,记录数据行的状态。如果 sign 标记为 1,则表示这是一行有效数据;如果 sign 标记为 -1,则表示这行数据要被删除。当 CollapsingMergeTree 分区合并时,同一数据分区内,sign 标记为 1 和 -1 的一组数据(ORDER BY 字段对应的值相同)会被抵消删除。这种 1 和 -1 相互抵消的操作,犹如将一张瓦楞纸折叠了一般,这种直观的比喻,想必也是折叠合并树(CollapsingMergeTree)的由来。
声明 CollapsingMergeTree 的方式如下:
ENGINE = CollapsingMergeTree(sign)
其中,sign 用于指定一个 Int8 类型的标志位字段,一个完整的 CollapsingMergeTree 数据表声明如下:
CREATE TABLE collapse_table (
id String,
code Int32,
create_time DateTime,
sign Int8
) ENGINE = CollapsingMergeTree(sign)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
与其它的 MergeTree 变种引擎一样,CollapsingMergeTree 同样是以 ORDER BY 排序键作为后续判断数据唯一性的依据。按照之前的介绍,对于上述 collapse_table 数据表而言,除了常规的新增操作之外,还能支持其它两种操作:
其一:删除一行数据
-- 插入一条数据,后续对它进行删除
INSERT INTO collapse_table VALUES ('A000', 100, '2020-02-20 00:00:00', 1)
删除一条数据,显然不能像关系型数据库那样使用 DELETE,正确做法是插入一条"要删除的数据"的镜像数据,ORDER BY 字段与原数据相同(其它字段可以不同),然后 sign 取反为 -1,它会和原数据折叠,然后相互抵消。
INSERT INTO collapse_table VALUES ('A000', 100, '2020-02-20 00:00:00', -1)
测试一下:
satori :) SELECT * FROM collapse_table
SELECT *
FROM collapse_table
Query id: f02e3e84-7837-4db7-af2b-d42957c5a63b
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A000 │ 100 │ 2020-02-20 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A000 │ 100 │ 2020-02-20 00:00:00 │ -1 │
└──────┴──────┴─────────────────────┴──────┘
2 rows in set. Elapsed: 0.002 sec.
其二:修改一行数据
-- 插入一条数据,后续对它进行修改
INSERT INTO collapse_table VALUES ('A001', 100, '2020-02-20 00:00:00', 1)
其中 code 的值是 100,我们要将其修改成 120,该怎么做呢?显然不能像关系型数据那样使用 UPDATE,正确的做法是以增代删。先创建镜像数据将原数据折叠,然后将修改后的原数据再插入到表中即可。
INSERT INTO collapse_table
VALUES ('A001', 100, '2020-02-20 00:00:00', -1),
-- 然后将原数据修改之后作为新数据,插入到表中,sign 为 1
('A001', 120, '2020-02-20 00:00:00', 1)
测试一下:
satori :) SELECT * FROM collapse_table
SELECT *
FROM collapse_table
Query id: bfb8afec-e672-416f-a7b8-5fcdf6470e59
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A000 │ 100 │ 2020-02-20 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A000 │ 100 │ 2020-02-20 00:00:00 │ -1 │
└──────┴──────┴─────────────────────┴──────┘
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A001 │ 100 │ 2020-02-20 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A001 │ 100 │ 2020-02-20 00:00:00 │ -1 │
│ A001 │ 120 │ 2020-02-20 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘
5 rows in set. Elapsed: 0.003 sec.
satori :)
还是很好理解的,然后 CollapsingMergeTree 在折叠数据时遵循如下规则:
如果 sign = 1 比 sign = -1 的数据多一行,则保留最后一行 sign = 1 的数据如果 sign = -1 比 sign = 1 的数据多一行,则保留第一行 sign = -1 的数据如果 sign = 1 和 sign = -1 的数据行一样多,并且最后一行是 sign = 1,则保留第一行 sign = -1 和最后一行 sign = 1 的数据如果 sign = 1 和 sign = -1 的数据行一行多,并且最后一行是 sign = -1,则什么也不保留其余情况,ClickHouse 会打印告警日志,但不会报错,在这种情形下打印结果不可预知
当然折叠数据并不是实时触发的,和所有的其它 MergeTree 变种表引擎一样,这项特性只有在多个分区目录合并的时候才会触发,触发时属于同一分区的数据会进行折叠。而在分区合并之前,用户还是可以看到旧数据的,就像上面演示的那样。
如果不想看到旧数据,那么可以在聚合的时候可以改变一下策略:
-- 原始 SQL 语句
SELECT id, sum(code), count(code), avg(code), uniq(code)
FROM collapse_table GROUP BY id
-- 改成如下
SELECT id, sum(code * sign), count(code * sign), avg(code * sign), uniq(code * sign)
FROM collapse_table GROUP BY id HAVING sum(sign) > 0
或者在查询数据之前使用 optimize TABLE table_name FINAL 命令强制分区合并,但是这种方法效率极低,在实际生产环境中慎用。
satori :) SELECT * FROM collapse_table
SELECT *
FROM collapse_table
Query id: 0cf9d813-5dcc-4a58-a02a-de3d6fb38c60
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A001 │ 120 │ 2020-02-20 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘
1 rows in set. Elapsed: 0.002 sec.
satori :)
我们看到 A000 的数据已经没有了,只剩下了 A001,并且 code 是 120,不是原来的 100。
另外只有相同分区内的数据才有可能被折叠,不过这项限制对于 CollapsingMergeTree 来说通常不是问题,因为修改或删除数据的时候,这些数据的分区规则通常都是一致的,并不会改变。但 CollapsingMergeTree 还有一个非常致命的限制,那就是对数据的写入顺序有着严格要求,举个例子:
-- 先写入 sign = 1
INSERT INTO collapse_table VALUES ('A002', 102, '2020-02-20 00:00:00', 1)
-- 先写入 sign = -1
INSERT INTO collapse_table VALUES ('A002', 102, '2020-02-20 00:00:00', -1)
显然此时是可以正常折叠的,我们刚才已经实验过了,但如果将写入的顺序置换一下,就无法折叠了。
-- 先写入 sign = 1
INSERT INTO collapse_table VALUES ('A003', 102, '2020-02-20 00:00:00', -1)
-- 先写入 sign = -1
INSERT INTO collapse_table VALUES ('A003', 102, '2020-02-20 00:00:00', 1)
我们测试一下,执行 optimize TABLE collapse_table FINAL,然后进行查询:
satori :) select * from collapse_table
SELECT *
FROM collapse_table
Query id: 3aaf02d2-7089-42f6-9d3b-a697b196bd42
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A001 │ 120 │ 2020-02-20 00:00:00 │ 1 │
│ A003 │ 102 │ 2020-02-20 00:00:00 │ -1 │
│ A003 │ 102 │ 2020-02-20 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘
3 rows in set. Elapsed: 0.002 sec.
satori :)
我们看到两个 A003 没办法进行折叠,原因就是这两条数据的 sign = -1 在前、sign = 1 在后,如果我们在写入一条 A003、sign = -1 会有什么结果呢?显然会和 sign = 1 的 A003 进行合并,只留下一条 sign = -1 的 A003。
satori :) select * from collapse_table
SELECT *
FROM collapse_table
Query id: 82226926-6f2a-4ab8-80b4-ce8980ec1eec
┌─id───┬─code─┬─────────create_time─┬─sign─┐
│ A001 │ 120 │ 2020-02-20 00:00:00 │ 1 │
│ A003 │ 102 │ 2020-02-20 00:00:00 │ -1 │
└──────┴──────┴─────────────────────┴──────┘
2 rows in set. Elapsed: 0.002 sec.
satori :)
这种现象是 CollapsingMergeTree 的处理机制所导致的,因为它要求 sign = 1 和 sign = -1 的数据相邻,而分区内的数据严格按照 ORDER BY 排序,要实现 sign = 1 和 sign = -1 的数据相邻,则只能严格按照顺序写入。
如果数据的写入顺序是单线程执行的,则能够比较好的控制写入顺序;但如果需要处理的数据量很大,数据的写入程序通常是多线程的,那么此时就不能保障数据的写入顺序了。而在这种情况下,CollapsingMergeTree 的工作机制就会出现问题,而为了解决这个问题,ClickHouse 额外提供了一个名为 VersionedCollapsingMergeTree 的表引擎。
VersionedCollapsingMergeTree
VersionedCollapsingMergeTree 表引擎的作用和 CollapsingMergeTree 完全相同,它们的不同之处在于 VersionedCollapsingMergeTree 对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都可以完成折叠操作。那么 VersionedCollapsingMergeTree 是如何做到这一点的呢?其实从它的名字就能看出来,因为相比 CollapsingMergeTree 多了一个 Versioned,那么显然就是通过版本号(version)解决的。
在定义 VersionedCollapsingMergeTree 数据表的时候,除了指定 sign 标记字段之外,还需要额外指定一个 UInt8 类型的 ver 版本号字段。
ENGINE = VersionedCollapsingMergeTree(sign, ver)
一个完整的 VersionedCollapsingMergeTree 表定义如下:
CREATE TABLE ver_collapse_table (
id String,
code Int32,
create_time DateTime,
sign Int8,
ver UInt8
) ENGINE = CollapsingMergeTree(sign, ver)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
那么 VersionedCollapsingMergeTree 是如何使用版本号字段的呢?其实很简单,在定义 ver 字段之后,VersionedCollapsingMergeTree 会自动将 ver 作为排序条件并增加到 ORDER BY 的末端。以上面的 ver_collapse_table 为例,在每个分区内,数据会按照 ORDER BY id, ver DESC 排序。所以无论写入时数据的顺序如何,在折叠处理时,都能回到正确的顺序。
-- 首先是删除数据
INSERT INTO ver_collapse_table VALUES ('A000', 101, '2020-02-20 00:00:00', -1, 1);
INSERT INTO ver_collapse_table VALUES ('A000', 101, '2020-02-20 00:00:00', 1, 1);
-- 然后是修改数据
INSERT INTO ver_collapse_table VALUES ('A001', 101, '2020-02-20 00:00:00', -1, 1);
INSERT INTO ver_collapse_table VALUES ('A001', 102, '2020-02-20 00:00:00', 1, 1);
INSERT INTO ver_collapse_table VALUES ('A001', 103, '2020-02-20 00:00:00', 1, 2);
以上数据均能正常折叠。
各种 MergeTree 之间的关系总结
经过上述介绍是不是觉得 MergeTree 特别丰富呢?但还是那句话,任何事都有两面性,功能丰富就意味着很容易被这么多表引擎弄晕,那么下面我们就以继承和组合这两种关系来理解整个 MergeTree。
继承关系
首先为了便于理解,可以使用继承关系来理解 MergeTree,MergeTree 表引擎向下派生出 6 个变种表引擎。
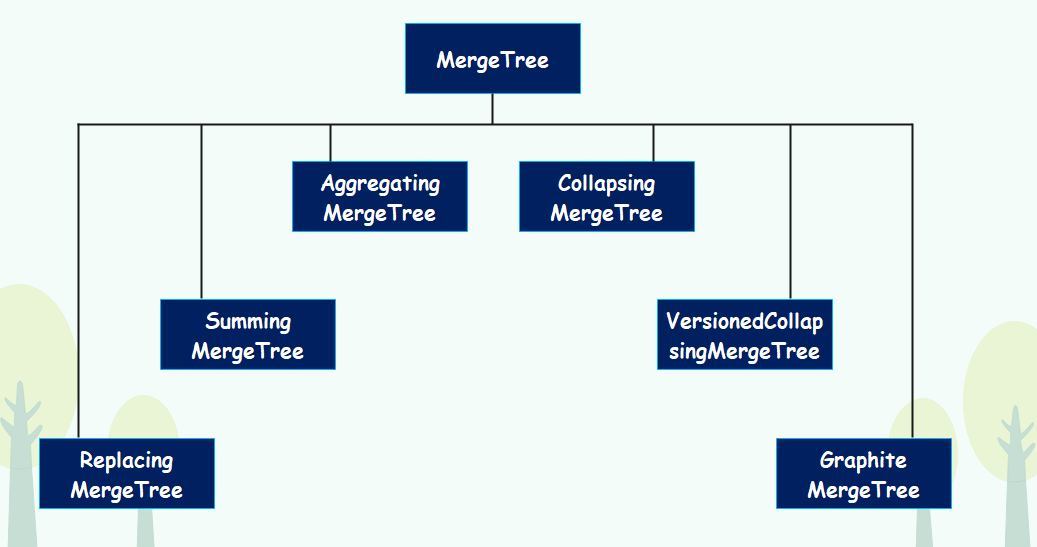
在 ClickHouse 底层的实现方法中,上述 7 种表引擎的区别主要体现在 Merge 合并的逻辑部分,简化后的对象关系如下图所示:

可以看到在具体的实现部分,7 种 MergeTree 共用一个主体,而在触发 Merge 动作时,它们调用了各自独有的合并逻辑。
MergeTree 之外的其它 6 个变种表引擎的 Merge 合并逻辑,全部都是建立在 MergeTree 基础之上的,且均继承于 MergeTree 的 MergingSortedBlockInputStream,如下图所示:
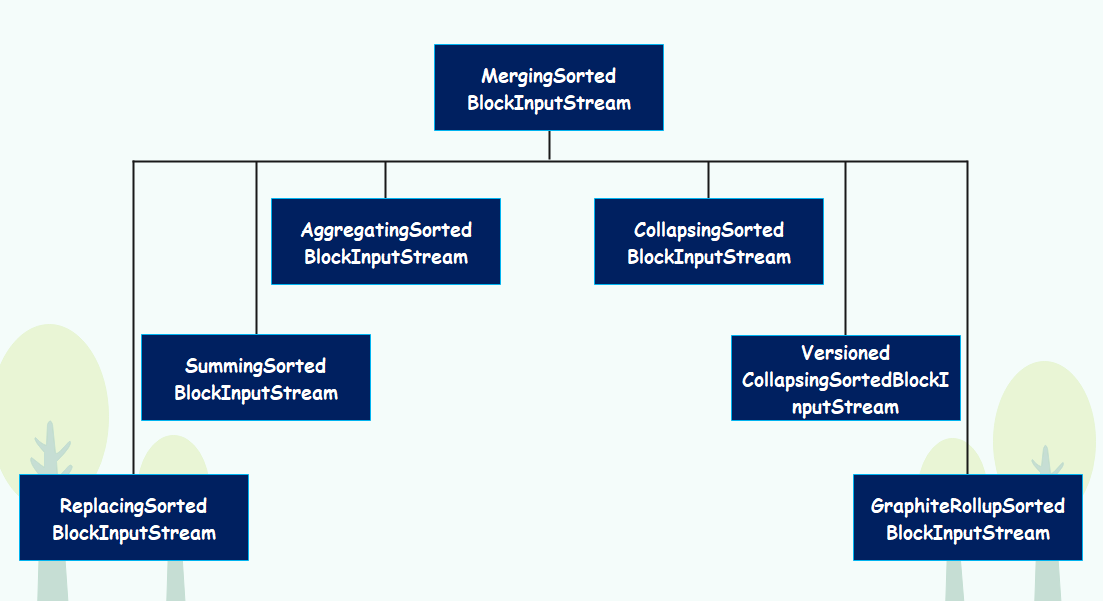
MergingSortedBlockInputStream 的主要作用是按照 ORDER BY 的规则保证分区内数据的有序性,而其它 6 种变种 MergeTree 的合并逻辑,则是在有序的基础之上各有所长,例如将排序后相邻的重复数据消除,或者将重复数据累加汇总等等。
组合关系
了解完 7 种 MergeTree 的关系,下面再来说一下它们的组合,我们说如果 MergeTree 加上 Replicated 的话,则表示支持副本,那么 ReplicatedMergeTree 和普通的 MergeTree 有什么区别呢?
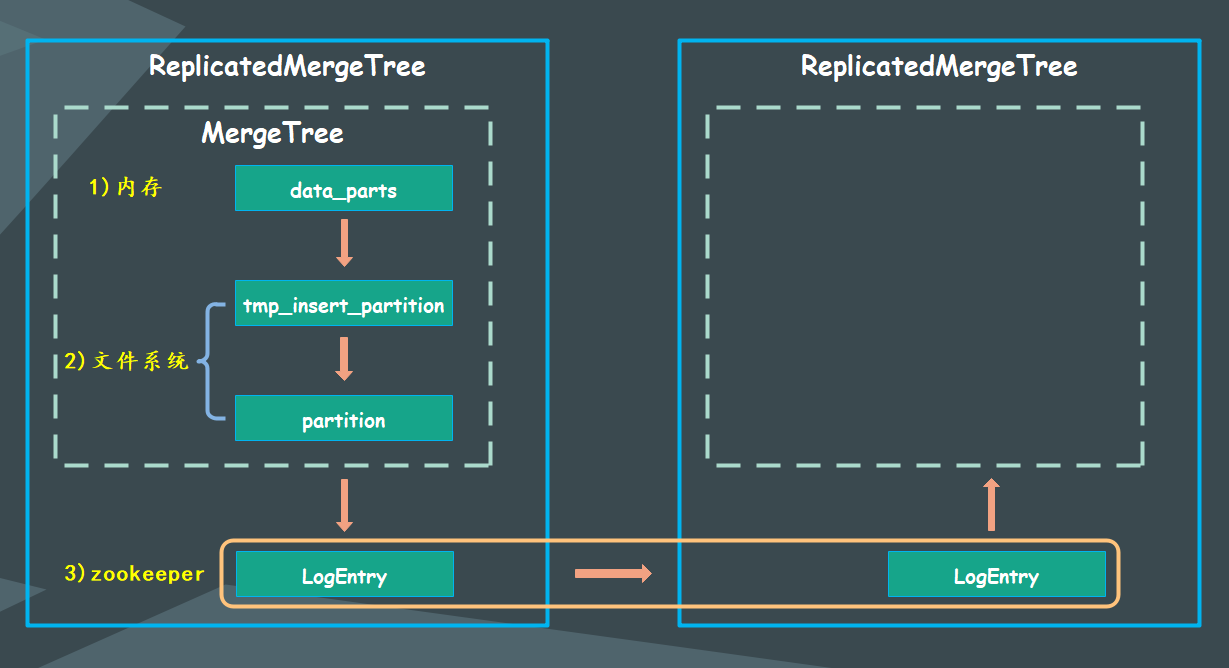
上图中的虚线框部分是 MergeTree 的能力边界,而 ReplicatedMergeTree 则在 MergeTree 能力的基础之上增加了分布式协同的能力,其借助 zookeeper 的消息日志广播功能,实现了副本实例之间的数据同步功能。
ReplicatedMergeTree 系列可以用组合关系来理解,如下图所示:
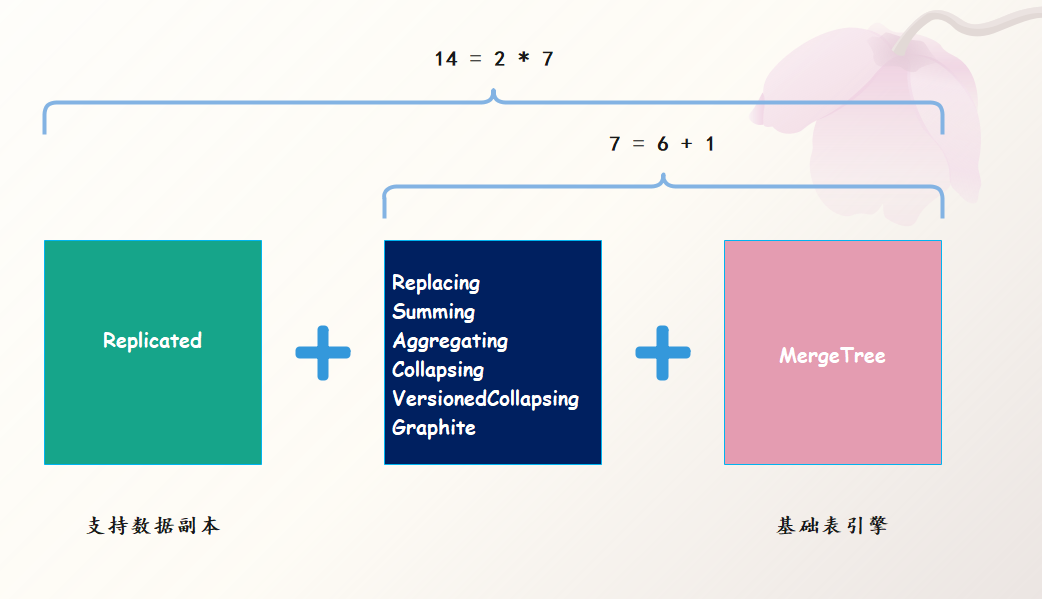
当我们为 7 种 MergeTree 加上 Replicated 前缀之后,又能组合出 7 种新的表引擎,而这些 ReplicatedMergeTree 拥有副本协同的能力。关于 ReplicatedMergeTree,后续会详细说。
以上我们就介绍完了 MergeTree 以及整个家族系列的表引擎,MergeTree 系列表引擎在生产中是使用频率最高的表引擎,我们是非常有必要彻底掌握它的。但我们说除了 MergeTree,还有很多其它表引擎,虽然使用频率不是那么高,不过还是有适合自身的场景的,所以我们也需要掌握,那么后续就来看一看其它种类的表引擎。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号